5分钟搞懂MySQL半连接优化⭐️多种半连接的优化策略
5分钟搞懂MySQL半连接优化⭐️多种半连接的优化策略
前言
前文已经描述过MySQL的多种优化措施,如:回表的优化、索引合并的优化、连接的优化等
本篇文章来聊聊MySQL中子查询的半连接优化
在阅读本篇文章前,需要了解连接的原理、内连接等知识
不了解前置知识的同学可以查看MySQL连接的原理⭐️4种优化连接的手段性能提升240%
为了更好的描述,我们使用班级、学生两张表
class表为班级表:class_num为班级的编码,class_name为班级名称
student表为学生表,其中包含学生信息,还包含class_num(该学生对应哪个班级编码)
班级表与学生表处于一对多的关系
想看官方文档的同学也可以点链接进入:子查询优化文档
子查询
来看这样一条SQL:
SELECT class.class_num, class.class_name
FROM class
INNER JOIN student
WHERE class.class_num = student.class_num;在内连接中,关联条件on与where的作用一致,该SQL等同于以下SQL
SELECT class.class_num, class.class_name
FROM class
INNER JOIN student
on class.class_num = student.class_num;对班级表和学生表进行内连接,其中关联条件为班级编码,查询出班级信息
如果有学生对应相同的班级,那么查询结果就会出现重复班级(比如:小菜和菜菜这两位同学都对应A班级)
假设优化器选择student表为驱动表,class表为被驱动表,则流程如下图

如果想要对结果去重,可以转换成以下子查询SQL
SELECT class_num, class_name
FROM class
WHERE class_num IN
(SELECT class_num FROM student);在子查询SELECT class_num FROM student中会查询学生表中所有的班级编码
当小菜和菜菜都处于A班级时结果还是会出现重复,但是在外层查询使用in进行查询时,相当于作一次去重
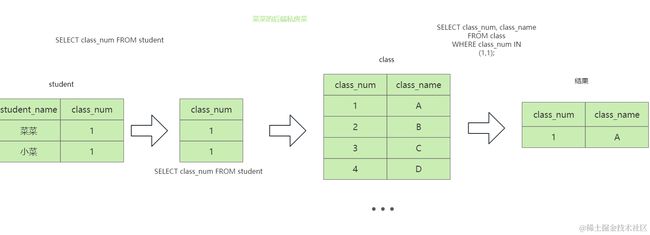
从这个案例可以发现:在某些场景下,in的子查询可以被可以被优化为内连接,但是需要解决内连接的重复结果问题
物化
MySQL将子查询结果转换变成临时表称为物化,临时表称为物化表
物化默认是开启的,并不一定所有的子查询都会进行物化,基于成本评估是否物化也是默认开启的
materialization=on开启物化
subquery_materialization_cost_based=on 开启基于成本评估是否物化
半连接
MySQL将上述这种子查询转化为内连接称为半连接
半连接是一种对子查询的优化,将子查询转换为内连接后,由优化器评估哪个表为驱动表的成本最低
使用半连接不仅需要将子查询转化为内连接,还需要对其进行去除重复记录
MySQL提供几种半连接策略进行去重,默认情况下开启所有半连接策略semijoin=on
FirstMatch
对于一种内层子查询与外层查询有关联的查询
select *
from a
where a.id in (select b.id from b where a.a1 = b.b1)子查询表b中的查询条件需要外层查询表a相关信息
使用FirstMatch策略(firstmatch=on默认开启),循环查找
- 从外层表a中获取记录
- 拿到该记录的a1去表b中寻找满足条件(a1=b1)的记录
- 满足条件则放入结果并停止在表b中寻找(去重)
- 找不到则继续遍历外层表a
步骤1-3为循环
TablePullout
如果子查询结果不会出现重复,那么就不需要解决去重了
可以通过主键值或者唯一索引来构建子查询的结果,避免重复
在MySQL中通过主键或唯一索引避免重复的半连接策略称为table pullout
LooseScan
在我们的案例中,班级编码肯定不是唯一的,因此不能使用这种策略
当不能使用唯一值时,就需要通过其他手段进行去重
当物化表作为驱动表并且包含关联条件的二级索引时,可以使用LooseScan策略,loosescan=on默认开启
当student表作为驱动表,并且拥有查询值class_num的二级索引,在索引中class_num就是有序的
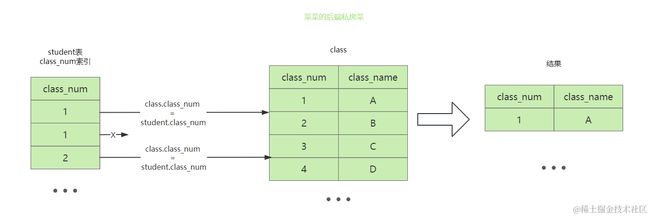
当class_num相同时,只需要取第一条相同的记录进行关联,然后跳过后续相同的记录即可(图中第一条和第二天记录)
DuplicateWeedout
duplicateweedout=on 默认开启DuplicateWeedout半连接策略
当无法使用索引时,可以在结果集使用临时表记录来进行判断是否重复
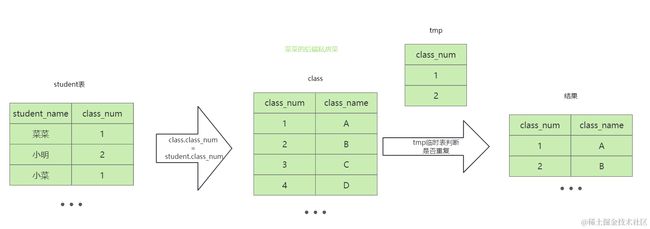
当第三条记录(学生名为小菜)最后加入结果集时,判断tmp临时表中是否已存在class_num为1的值,已存在则不加入结果
因此第三条记录不会被加入结果集中
总结
将子查询的结果存储在临时表中的过程为物化,存储子查询结果的临时表为物化表
子查询在某些场景下可以转换成内连接,让优化器选择成本低的驱动表,这被称为半连接
使用半连接需要将结果进行去重,提供多种策略对其进行去重
FirstMatch通过循环外层查询,从外层查询获取记录,将记录拿到内层表中进行匹配,如果满足条件则放入结果集并停止在内层查找,后续继续循环外层查询,以此保证去重
TablePullout通过使用主键值或者唯一索引,让其记录没有重复值来保证去重
LooseScan通过物化表为驱动表并且拥有查询列的二级索引,保证查询列有序,当查询列相同时,拿第一条记录进行匹配,后续相同记录跳过,以此保证去重
DuplicateWeedout通过使用临时表记录结果,当出现重复时进行过滤不加入结果集,以此保证去重
最后(不要白嫖,一键三连求求拉~)
本篇文章被收入专栏 由点到线,由线到面,构建MySQL知识体系,感兴趣的同学可以持续关注喔
本篇文章笔记以及案例被收入 gitee-StudyJava、 github-StudyJava 感兴趣的同学可以stat下持续关注喔~
有什么问题可以在评论区交流,如果觉得菜菜写的不错,可以点赞、关注、收藏支持一下~
关注菜菜,分享更多干货,公众号:菜菜的后端私房菜
本文由博客一文多发平台 OpenWrite 发布!