第 3 章:文件系统
在本章中,我们将重新审视文件的概念,这些概念在[第 1 章]中已经简要讨论过。你将详细了解 Linux 中的文件系统(FS)及其特点。我们不会深入探讨特定的文件系统实现,因为你会看到有很多种,但我们将确立与它们交互的基本原则。你将更多地了解 Linux 的 FS 层次结构——它的分区、对象类型以及一些常用操作。
你将熟悉 C++ 中的文件系统库,它允许你独立于平台执行系统操作。我们将使用 C++ 示例向你展示文件管理的简单应用。你还将了解 string_views。你在这里学到的一些操作将在[第 5 章中再次讨论,届时我们将讨论错误处理。
最后但同样重要的是,你将亲手了解基本的进程间通信(IPC)机制,即管道。我们还将讨论信号作为系统实体及其对通信的影响。如果你不熟悉进程间的数据传输,那么这是你应该开始的地方。如果你有经验,你可能会注意到代码可能更复杂——例如,使用管道实现服务器-客户端应用。我们意识到这一点,但我们相信这些示例是一个良好的起点——这种机制的额外可扩展性会带来不希望的连锁反应。我们将在第 7 章中更多地讨论这一点。
本章将涵盖以下主要主题:
- 探究 Linux 文件系统的基础知识
- 使用 C++ 执行文件系统操作
- 通过匿名管道和命名管道进行 IPC
- 简要观察信号处理
技术要求
为了运行代码示例,读者必须准备以下内容:
- 一套能够编译和执行 C 和 C++20 的基于 Linux 的系统(例如,Linux Mint 21):
- gcc12.2 编译器:https://gcc.gnu.org/git/gcc.git gcc-source
- g++ 编译器,使用 -std=c++2a 标志编译 C++ 代码
- gcc 编译器,无需标志编译 C 代码
- 对于所有示例,你也可以选择使用 https://godbolt.org/.
- 代码示例可以在这里找到:[https://github.com/PacktPublishing/C-Programming-for-Linux-Systems/tree/main/Chapter%203](https://github.com/PacktPublishing/C-Programming-for-Linux-Systems/tree/main/Chapter 3)
探究 Linux 的文件系统基础知识
我们在[第 1 章]中已经讨论了一些 Unix(包括 Linux)文件系统的定义。让我们看看它们在系统编程的更大图景中真正意味着什么。你可能还记得 Linux 系统中有哪些类型的文件——普通文件、目录、特殊文件、链接、套接字和命名管道。我们将在本章处理其中的大多数,并了解它们的用途。关于 Unix(包括 Linux)中的文件,有一个简单的陈述方式:
“在 UNIX 系统上,一切都是文件;如果某物不是文件,那么它就是 进程。”
因此,所有不是进程的东西都有一个 API,其中包括文件操作系统调用。我们同意文件是逻辑数据组织的主要工具。那么必然存在某种是文件组织的主要工具。好吧,这就是文件管理系统,或者简单地说,FS 的角色。它负责在物理介质上——非易失性内存(NVM)上的文件布局,它们在该介质上的组织,操作抽象(如 open()、write())等。
FS 还允许用户暂时忘记硬件的特性,专注于数据操作,以及像使用有序目录一样使用 FS。它有助于文件结构和数据在 UI 或 CLI 上的可视化、访问权限和资源的有效使用。尽管用户有机会专注于文件的创建、删除、修改和共享,但 FS 更关心数据准确性、设备驱动程序错误处理、多用户访问等。这是一个重要的观点,因为我们稍后将在书中观察到一些错误状态——例如,在[第 5 章],其中 FS 是创建异常情况的实体。它还影响任务调度,正如我们之前提到的。让我们看看 Linux 中的 FS 结构及其特点。
Linux 的 FS
我们必须提到有许多种 FS。它们各自适合自己的用途,因为用户体验意味着多种偏好,并非所有偏好都能共存。Linux 的优势在于支持超过 100 种 FS。它们可以在单个系统上同时运行。这为用户提供了优化操作它们的机会,并从所有这些 FS 中受益。如果 FS 只是用来组织文件结构,那么普通的 FS 就可以解决问题——例如 ext2 或 FAT。如果我们想要文件一致性和减少错误操作,那么需要 日志 FS,如 ext4、ReiserFS 或 XFS。对于在线数据存储,网络 FS,如 NFS 和 CIFS,可能会派上用场。大文件和大量小文件也需要特定管理,因此 卷管理 FS,如 ZFS 和 btrfs,是有用的。最后但同样重要的是,有些 FS 不是由物理存储支持的,而是代表 主内存 中的实体,对系统程序员特别有用——proc、sys、ram 和 tmp。然而,在抽象层面上,文件操作似乎是相同的。因此,我们可以有一个统一的接口。它不仅允许系统程序员以相同的方式使用不同的 FS,还允许操作系统的 UI 以相同的 FS 树下可视化文件结构——所有的文件和目录。Linux 通过 虚拟文件系统(VFS)实现了这一点。它也被称为 虚拟 FS 开关——位于内核中的一层,为程序提供通用接口。在我们详细了解之前,让我们看看它从设计角度看起来是什么样的。

图 3.1 - Linux 内核中的 VFS 软件层
此外,VFS 是面向对象的。不幸的是,这对我们的 C++ 代码帮助不大。尽管如此,它是 C 中面向对象编程的一个很好的例子,因为对象实际上是 struct 类型,包含文件数据和指向文件操作的函数指针。我们将在本章稍后讨论这些对象。现在,让我们看看目录结构和标准分区。
目录结构和分区
Linux 中的目录结构在文件系统层次标准(FHS)中有很好的呈现。但重要的是要注意,包括目录在内的文件,是以树结构的分支方式排列的。它们的字符名称区分大小写,文件后缀(在 Windows 中称为扩展名)在某些情况下可能没有用处——记住,普通文件被视为二进制文件,它们的扩展名主要是帮助用户了解它们的角色。对于新手来说,这可能会令人困惑,尤其是如果他们使用终端而不是操作系统的 UI。真正的文件类型是通过魔法数字或Magic Bytes在内部确定的。例如,可执行脚本以 #! 开头。你可以执行以下命令了解更多信息:
$ man magic
回到 FS 结构 - 它以 root 目录开始,用 / 表示。root 文件系统在系统引导序列的早期阶段被挂载到该目录。操作系统启动期间或甚至在正常操作期间,其他文件系统被挂载。你可以按如下方式检查自己的配置:
$ cat /etc/fstab
# /etc/fstab: static file system information.
...
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda5 during installation
UUID=618800a5-57e8-43c1-9856-0a0a14ebf344 / ext4 errors=remount-ro 0 1
# /boot/efi was on /dev/sda1 during installation
UUID=D388-FA76 /boot/efi vfat umask=0077 0 1
/swapfile none swap sw 0 0
它提供了关于挂载点和相应文件系统类型的信息。在这个文件之外,文件系统将在系统中作为具有确切路径的单独目录可见。每个目录都可以通过 root 目录访问。一个重要的点是 / 和 /root 是不同的目录,因为前者是 root 目录,而后者是根用户的家目录。一些其他重要的分区和目录包括:
/bin:包括常见用户可执行文件。/boot:包括 Linux 系统启动文件、内核的静态部分和引导程序配置。/dev:包括对所有外围硬件的引用,它们通过特殊文件类型(‘c’ 或 ‘b’)表示,并提供对实际设备的访问。我们在第 1 章中提到了这些特殊文件类型。/etc:包括系统配置文件。/home:这是用户文件可用的顶级目录,所有用户在那里都有各自的公共子目录。/lib:包括启动系统所需的共享库文件。/mnt:外部文件系统的临时挂载点。它与/media很好地结合在一起,后者是诸如 USB 闪存驱动器之类的媒体设备被挂载的地方。/opt:包括可选文件和第三方软件应用程序。/proc:包含有关系统资源的信息。/tmp:操作系统和多个程序用于临时存储的临时目录 - 重启后将被清理。/sbin:包括系统二进制文件,通常由系统管理员使用。/usr:包括大多数时间为只读的文件,但也有例外。它用于程序、库和二进制文件、man 文件和文档。/var:包括变量数据文件 - 通常是日志文件、数据库文件、归档电子邮件等。
让我们回到挂载点和文件系统分区。由于很多人对这些不熟悉,我们将借此机会简要解释它们。一个好的理由是,正如已经提到的,系统程序员一次与许多文件系统打交道,其中一些与网络驱动器或不同设备有关。
Linux 不像 Windows 那样为分区分配一个字母;因此,你可能会轻易地将单独的设备误认为是简单的目录。大多数时候,这不应该是一个大问题,但当你关心资源管理、弹性和安全性时,它可能成为一个问题。例如,整体上,车辆对硬件耐用性有严格要求,这延伸到 10-15 年的可服务性。考虑到这一点,如果你频繁写入或无意义地填满整个空间,你必须意识到设备的特性。文件系统管理数据的方式对于外围设备的内存随时间耗尽也至关重要,因此这个选择很重要。
fstab 展示了文件系统的挂载位置,但它还描述了其他内容。首先,让我们记住文件系统分区的目的是将单个设备 - 例如硬盘 - 分成多个分区。这主要用于具有安全要求的嵌入式系统。然而,Linux 还提供了逻辑卷管理器(LVM),它允许灵活的设置。换句话说,文件系统可以轻松地缩小或扩大,这在大规模系统上是首选。
创建多个文件系统不仅作为用户数据分组工具,还允许在一个分区由于故障而失效时,其他分区保持完好。另一个用途是当设备的存储不可用时 - 通常,它只是数据已满。整个系统可能会停止工作,因为它也依赖于存储空间。因此,最好只填满单个文件系统并引发错误。其他文件系统将保持完好,系统将继续工作。从这个角度来看,它是一个安全和稳健的解决方案。只需记住,它并不能保护你免受整个设备故障的影响。出于这个原因,许多网络存储设备依赖于廉价磁盘的冗余阵列(RAID)。我们在这里不会处理它,但我们鼓励你阅读更多关于它的信息。
现在,你可能已经在之前的 fstab 输出中观察到了一些额外的数据。除了根分区之外,我们实际上将分区类型划分为数据分区和交换分区:
- 数据分区:这包括根分区,以及系统启动和正常运行所需的所有必要信息。它还包括 Linux 上的标准数据。
- 交换分区:这在
fstab中用swap表示,它为系统提供了在内存溢出的情况下将数据从主内存移动到非易失性内存(NVM)的选项。它只对系统本身可见。这并不意味着你应该让你的 RAM 溢出,而只是保持额外的灵活性,以免影响系统的可用性。请记住,NVM 比主内存芯片慢得多!
重要提示
系统管理员通常配置分区布局。有时,一个分区会分布在多个 NVM 设备上。这种设计严格与系统的目的相关。一旦分区对你作为用户可用,你只能添加更多。我们强烈建议你在非常清楚自己在做什么以及为什么的情况下才更改它们的属性。
那么挂载点呢?分区通过挂载点附加到系统上。这是文件系统识别给定空间用于特定数据的方式 - 最佳示例是我们之前提到的目录列表。你可以使用 df 命令显示系统上可用挂载点的信息,除了交换分区。在我们的情况下,如下所示:
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 5,9G 0 5,9G 0% /dev
tmpfs 1,2G 1,3M 1,2G 1% /run
/dev/sda5 39G 24G 14G 64% /
tmpfs 6,0G 0 6,0G 0% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 6,0G 0 6,0G 0% /sys/fs/cgroup
/dev/sda1 511M 4,0K 511M 1% /boot/efi
tmpfs 1,2G 16K 1,2G 1% /run/user/29999
很容易看出文件系统类型和挂载点之间的关系,例如 文件系统 和 挂载点 列。我们不会更详细地讨论这一点,但我们鼓励你阅读更多关于 parted 工具的信息,它正是用于创建和编辑分区的。
Linux FS 对象
正如我们在前一节中提到的,文件系统是通过对象实现的,我们关心的主要有四种类型:
-
超级块(Superblock):这代表已挂载文件系统的元数据 - 相应的设备、修改标志、相应的文件系统类型、文件系统访问权限、修改过的文件等。
-
索引节点(i-node 或 inode):每个文件都有自己的inode,它通过一个唯一的编号引用文件本身,并存储其元数据。此对象包含 VFS 可以调用的函数,但不是用户级代码,例如
open()、create()、lookup()、mkdir()。普通文件、特殊文件、目录和命名管道都通过inodes表示。换句话说,文件系统中的所有实体都有一个inode,其中包含有关它们的元数据。你可以通过stat命令可视化这一点:$ stat test File: test Size: 53248 Blocks: 104 IO Block: 4096 regular file Device: 805h/2053d Inode: 696116 Links: 1 Access: (0775/-rwxrwxr-x) Uid: (29999/ oem) Gid: (29999/ oem) ...现在,看看权限位 -
0775/-rwxrwxr-x。数字和符号标志有相同的含义,但表示不同。-表示标志未设置。r表示文件可由当前用户、组或所有人(从左到右读取)读取。w表示可写,x代表可执行。最左边的位有特定的作用 - 如果前面有额外的p,它标记这个文件为管道。你可以在本章后面看到这一点。如果没有,你可以继续前进并检查稍后相应示例中符号链接的权限位。注意它的权限位以1开始。在你的操作中可能会看到的其他符号包括d代表目录、b代表块设备、c代表字符设备和s代表套接字。 -
目录条目(dentry):为了可用性,我们不会使用 inode 中的数字来引用物理文件,而是使用名称和位置。因此,我们需要一个翻译表,将符号名称(对用户来说)映射到 inode 编号(对内核来说)。通过路径名表示这最简单,例如以下示例:
$ ls -li test 696116 -rwxrwxr-x 1 oem oem 53248 Jul 30 08:29 test正如你所看到的,inode 与之前的示例相同 -
696116,符号名称是test。 -
文件:此对象类型用于向进程表示打开的文件的内容。它通过
open()创建并在close()时销毁。这个对象包含的一些成员是dentry 指针、uid 和 gid、文件位置指针,以及 inode 方法集,这与特定文件系统可以为这个确切文件执行的方法相关。内核分配新的文件结构及其唯一的文件描述符。dentry 指针和 inode 定义的方法集被初始化。调用特定文件系统的open()方法,并将文件放入调用进程的文件描述符表中。在用户空间中,文件描述符用于应用程序的文件操作。
以下图表提供了通过多个进程访问单个文件的概览:

图3.2 - 文件访问组织
在这里,我们可以看到一些有趣的事情。尽管进程打开的是同一个文件,但它们在到达真正数据之前经历了不同的执行路径。首先,每个进程都有自己的打开文件表;因此,它们拥有自己的描述符。每当一个进程调用fork()时,子进程获得相同的打开文件表。独立进程指向一个单独的文件表。接下来,假设我们有两个dentries指向同一个文件,而我们的文件对象指向它。当我们通过不同的路径名到达同一个物理文件时,就会出现这种情况。当我们处理同一个文件时,这些条目将指向单个inode和超级块实例。从那时起,文件所在的确切文件系统将接管其特定功能。
不过,有一点需要声明 - 操作系统不是多个进程同时更新文件的仲裁者。它会按照我们在上一章讨论的规则来调度这些操作。如果您想为这些操作制定特定的策略,则必须明确设计和应用。尽管文件系统提供文件锁定作为互斥技术,您将在本书后面了解到,但Linux通常不会自动锁定打开的文件。如果您使用sudo rm -rf删除文件,可能会删除当前正在使用的文件。这可能导致不可逆的系统问题。我们使用文件锁定来确保对文件内容的安全、并发访问。它只允许一个进程在给定时间访问文件,从而避免可能的竞争条件,您将在第6章中了解到。Linux支持两种类型的文件锁 - 咨询锁和强制锁,您可以在这里阅读更多相关信息:https://www.kernel.org/doc/html/next/filesystems/locking.html。
重要提示
通过相应的inodes对物理文件进行唯一编号的方式并非无限的。VFS可能包含如此多的小文件,以至于它耗尽了创建新文件的能力,而NVM上仍有可用空间。这种错误在大规模系统上观察到的频率可能比您想象的要高。
您可能还想知道通过不同的路径名访问同一个文件的方法。好吧,您还记得我们在[第1章]中关于链接文件的讨论吗?我们谈到了硬链接和符号链接。对于给定的文件,总是有硬链接可用 - 例如,当至少有一个与数据相关的硬链接时,相应的文件被认为在文件系统中存在。通过它,路径名直接与NVM上文件所在的点相关联,并可以从中打开。多个路径名指向设备上的同一点会导致多个硬链接的构建。让我们来检查一下。首先,我们将列出我们某些文件的数据:
$ ls -li some_data
695571 -rw-rw-r-- 1 oem 5 May 28 18:13 some_dataCopyExplain
然后,我们将通过ln命令为同一个文件创建一个硬链接,并列出两个文件:
$ ln some_data some_data_hl
$ ls -li some_data some_data_hl
695571 -rw-rw-r-- 2 oem oem 5 May 28 18:13 some_data
695571 -rw-rw-r-- 2 oem oem 5 May 28 18:13 some_data_hl
如您所见,它们都有相同的inode,因为它们有不同的字符名称,但它们是同一个文件。文件的唯一真实表示是inode号 - 695571。这意味着它们确实指向硬盘上的同一块。然后,我们看到硬链接计数器已经从1增加到2(在访问权限和uid列之间)。
符号链接是通过其各自的路径名指向其他文件或目录的文件,这些路径名称为目标。文件系统创建一个新文件,其中只包含指向目标的路径名,并且删除所有指向文件的符号链接不会导致其从系统中删除。让我们再次通过ln命令创建一个符号链接,但这次我们将添加-s选项。我们将列出到目前为止的所有文件:
$ ln -s some_data some_data_sl
$ ls -li some_data some_data_hl some_data_sl
695571 -rw-rw-r-- 2 oem oem 5 May 28 18:13 some_data
695571 -rw-rw-r-- 2 oem oem 5 May 28 18:13 some_data_hl
694653 lrwxrwxrwx 1 oem oem 9 May 28 18:16 some_data_sl -> some_data
您可以轻松看出,新文件 - some_data_sl - 与原始文件及其硬链接有不同的inode。它指向NVM中的新位置,并拥有自己的访问权限。此外,它还直观地显示了它真正指向的路径名。即使有一个符号链接指向另一个符号链接,ls -li仍然会展示符号链接设置为指向的文件,例如以下情况:
696063 -rw-rw-r-- 1 oem oem 4247 Jul 2 13:25 test.dat
696043 lrwxrwxrwx 1 oem oem 8 Aug 6 10:07 testdat_sl -> test.dat
696024 lrwxrwxrwx 1 oem oem 10 Aug 6 10:07 testdat_sl2 -> testdat_sl
请注意字节大小 - 原始文件只有4247字节大小,而符号链接是8字节,下一个是10。实际上,原始文件的大小对于符号链接的大小并不重要,但其他东西确实如此 - 您可以通过计算所指文件的路径名中的字符数量来弄清楚。
所有前述的文件名都为您提供了访问和修改文件的能力。它们还为您提供了从多个访问点获取数据的灵活性,而无需重复和无意义地使用额外的存储空间。许多系统程序员使用符号链接来重新排序文件系统,仅仅为了便于一些专门的用户进程的数据管理。Linux系统本身也这样做,仅仅为了重新排序文件系统层次结构以达到相同的目的。让我们通过以下图表概述这个例子:
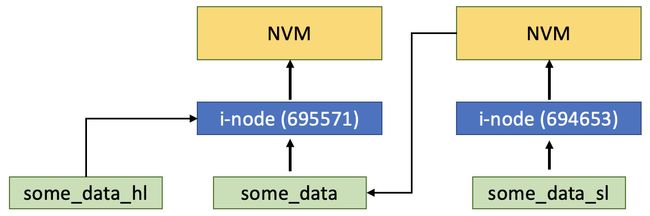
图3.3 - 硬链接和符号链接概述
重要提示
即使原始文件被移动或删除,符号链接仍将继续指向其路径名作为目标,而硬链接必须指向现有文件。符号链接可以跨分区工作,但硬链接不会链接不同卷或文件系统上的路径。
在下一节中,我们将继续通过C++代码操作文件。
使用C++执行文件系统操作
随着C++17的出现,更接近系统编程的文件系统操作得到了便利。文件系统库允许C++开发人员区分Linux文件系统类型并对它们执行特定操作。让我们看一个示例接口:
bool is_directory(const std::filesystem::path& p)
此方法检查给定的路径名是否是目录。类似地,我们可以做其他类型的检查 - is_fifo()、is_regular_file()、is_socket()和is_symlink()。您能告诉我们为什么没有is_hardlink()方法吗?没错 - 如果两个具有不同字符名称的文件指向单个inode,那么它们都提供对同一内容的访问。尽管我们可以通过hard_link_count()方法获得inode的硬链接计数器是否高于1,但这并不重要。
由于C++语言可以在多个操作系统上编译,因此文件系统函数也依赖于这些系统的相应文件系统。例如,FAT不支持符号链接;因此,与它们相关的方法将失败,错误处理留给系统程序员。您可以使用std::filesystem::filesystem_error异常对象来获取当前错误的文件系统错误状态的详细信息。[第5章]中有相关讨论。
我们之前提到,必须由软件工程师管理并发文件访问,否则操作系统将按照它认为合适的方式调度操作。这个库也是如此。不要期望它自己处理竞争条件或修改冲突。现在,让我们看看如何使用其中的一些操作。不过有一点声明 - 正如提到的,错误条件将在后面讨论,所以我们在这里不会关注它们。
我们将创建一个新目录(以下代码段中的标记{1}):
#include <iostream>
#include <filesystem>
using namespace std;
using namespace std::filesystem;
int main() {
auto result = create_directory("test_dir"); // {1}
if (result)
cout << "Directory created successfully!\n";
else
cout << "Directory creation failed!\n";
return 0;
}
现在,让我们看看文件系统上发生了什么:
$ ./create_dir
Directory created successfully!
如果您再次调用该程序,它将失败,因为目录已经存在:
.$ /create_dir
Directory creation failed!
我们填充新目录,如前面的示例所描述(参见 图3*.3*),但这次使用C++代码(以下代码中的标记{1}和{2}):
...
int main() {
if (exists("some_data")) {
create_hard_link("some_data", "some_data_hl");// {1}
create_symlink("some_data", "some_data_sl"); // {2}
}
...
当然,重要的是从some_data所在的目录调用程序,或相应地提供其路径名 - 通过对它的绝对或相对路径。如果一切顺利,我们继续。这次我们为some_data添加了一些字符,所以它的大小是9字节。不过,情况几乎相同 - 当然,inodes是不同的:
79105062 rw-rw-r-- 2 oem oem 9 May 29 16:33 some_data
79105062 rw-rw-r-- 2 oem oem 9 May 29 16:33 some_data_hl
79112163 lrwxrwxrwx 1 oem oem 9 May 29 17:04 some_data_sl -> some_data
我们还手动创建了一个名为inner_test_dir的新内部目录,以及一个名为inner_some_data的新文件。让我们迭代目录,非递归地(以下代码中的标记{1})和递归地,并打印出目录内容(以下代码中的标记{2}):
...
int main() {
const path path_to_iterate{"test_dir"};
for (auto const& dir_entry :
directory_iterator{path_to_iterate}) { // {1}
cout << dir_entry.path() << endl;
}
cout << endl;
for (auto const& dir_entry :
recursive_directory_iterator{path_to_iterate}) {
cout << dir_entry.path() << endl; // {2}
}
return 0;
}
输出并不令人惊讶:
"test_dir/inner_test_dir"
"test_dir/some_data"
"test_dir/some_data_sl"
"test_dir/some_data_hl"
"test_dir/inner_test_dir"
"test_dir/inner_test_dir/inner_some_data"
"test_dir/some_data"
"test_dir/some_data_sl"
"test_dir/some_data_hl"
现在,我们想检查一些文件是否是符号链接(以下代码中的标记{1}),如果是,让我们打印出它们的目标:
...
int main() {
const path path_to_iterate{"test_dir"};
for (auto const& dir_entry :
recursive_directory_iterator{path_to_iterate}) {
auto result = is_symlink(dir_entry.path()); // {1}
if (result) cout << read_symlink(dir_entry.path());
}
}
再次,输出如预期 - 目标是初始源文件:
$ ./sym_link_check
"some_data"
让我们尝试重命名符号链接文件(以下代码段中的标记{1}),然后我们继续进行一些其他修改:
...
int main() {
if (exists("some_data_sl")) {
rename("some_data_sl", "some_data_sl_rndm"); // {1}
}
...
我们看到重命名是成功的:
79112163 lrwxrwxrwx 1 oem oem 9 May 29 17:04 some_data_sl_rndm -> some_data
让我们删除初始文件 - some_data(以下代码中的标记{2}),并观察系统上的空闲空间变化(以下代码中的标记{1}和{3}):
...
int main() {
if (exists("some_data")) {
std::filesystem::space_info space_obj =
space(current_path());// {1}
cout << "Capacity: "
<< space_obj.capacity << endl;
cout << "Free: "
<< space_obj.free << endl;
cout << "Available: "
<< space_obj.available << endl;
remove("some_data"); // {2}
space_obj = space(current_path()); // {3}
cout << "Capacity: "
<< space_obj.capacity << endl;
cout << "Free: "
<< space_obj.free << endl;
cout << "Available: "
<< space_obj.available << endl;
}
...
这里是输出:
Capacity: 41678012416
Free: 16555171840
Available: 14689452032
Capacity: 41678012416
Free: 16555175936
Available: 14689456128
如您所见,虽然文件只有9字节大小,但已释放4096字节。这是因为我们实际使用的最小值是NVM块的大小 - 操作系统可以从文件中写入或读取的数据的最小单位。在这种情况下,它是4KB。如果细节对您来说并不重要,但您只想检查空间值是否已更新,那么在C++ 20中,您还有==运算符重载;因此您可以直接比较两个space_info对象,这实际上是space()返回值的背后(标记{1}和{3})。
我们使用这些代码示例快速浏览了C++文件系统库。我们希望这对您有所帮助,尽管我们在功能之间跳跃了一点。这应该对您的工作有用。下一节将讨论非常重要的内容 - 多进程通信的基础知识。正如您在本章开始时已经知道的那样,Linux将所有不是进程的东西都视为文件。通信资源也是如此,我们将用我们的C++知识深入探讨它们。将会有更多理论内容,所以请继续关注!
通过匿名管道和命名管道进行IPC
在我们开始研究这个话题之前,让我问您一个问题。您是否曾经做过以下操作:
$ cat some_data | grep data
some data
如果是,那么您可能称|为管道。这是从哪里来的?实际上,您将一个进程的输出作为另一个进程的输入进行了管道传输。您也可以用自己的代码来做到这一点 - 我们不仅限于系统应用程序。我们还可以在自己的代码中编程实现这种管道通信。这是进程间数据传输的基本工具。您还记得之前关于FIFO文件和命名管道的阅读吗?没错 - 它们是同一回事,但是带有|符号的管道和它们是一样的吗?不!那是匿名管道。系统程序员区分所谓的匿名管道和命名管道。它们具有不同的用途,因此在当今的Linux系统上都能找到它们。它们是由pipefs创建和管理的,而用户执行标准的VFS系统调用。我们将使用管道作为示例,来直观展示一些对文件系统的观察。那么,让我们开始吧!
匿名管道或未命名管道
匿名管道在文件系统中无法观察到,因为它们没有字符名称。它们是通过特殊的系统调用创建的,正如您将在下一个示例中看到的那样。它们驻留在内核中,其中创建了特定的文件缓冲区。从带有|符号的示例中,您可以轻松得出结论,这种实现更多地与短期通信相关,而且不是持久的。匿名管道有两个端点 - 一个读端和一个写端。这两个都由文件描述符表示。只要两个端点都关闭,管道就会被销毁,因为没有更多的方法可以通过打开的文件描述符引用它。此外,这种类型的通信被称为单工FIFO通信 - 例如,它创建了一个单向数据传输 - 最常见的是从父进程到子进程。让我们看一个示例,它使用系统调用创建一个匿名管道和简单的数据传输:
#include <iostream>
#include <unistd.h>
#include <string.h>
using namespace std;
constexpr auto BUFF_LEN = 64;
constexpr auto pipeIn = 0;
constexpr auto pipeOut = 1;
我们需要一个整数数组来保存表示管道输入和输出端点的文件描述符 - a_pipe。然后,这个数组被传递给pipe()系统调用,如果有错误,它将返回-1,成功则返回0(见标记{1}):
int main() {
int a_pipe[2]{};
char buff[BUFF_LEN + 1]{};
if (pipe(a_pipe) == -1) { // {1}
perror("Pipe creation failed");
exit(EXIT_FAILURE);
}
else {
if (int pid = fork(); pid == -1) {
perror("Process creation failed");
exit(EXIT_FAILURE);
}
else if (pid == 0) {
// 子进程:将是读者!
sleep(1); // 只是为了多给一些时间!
close(a_pipe[pipeOut]); // {2}
read(a_pipe[pipeIn], buff, BUFF_LEN); // {3}
cout << "Child: " << buff << endl;
}
我们通过fork()创建了一个新进程,就像我们在[第2章]中所做的那样。知道这一点,您能告诉最后创建了多少个管道吗?没错 - 创建了一个管道,并且文件描述符在进程之间共享。
由于数据传输是单向的,我们需要关闭每个进程的未使用端点 - 标记{2}和{4}。如果进程写入并读取其自己的管道输入和输出文件描述符,它只会得到之前写入那里的信息:
else {
// 父进程:将是写者!
close(a_pipe[pipeIn]); // {4}
const char *msg = {"Sending message to child!"};
write(a_pipe[pipeOut], msg, strlen(msg) + 1);
// {5}
}
}
return 0;
}
换句话说,我们禁止孩子回应父亲,父亲只能向孩子发送数据。通过写入文件并从中读取数据来发送数据(见标记{3}和{5})。这是一个非常简单的代码片段,通常通过匿名管道的通信就是这么简单。但是要小心 - write()和read()是阻塞调用;如果管道中没有可读的内容(管道缓冲区为空),相应的进程-读者将被阻塞。如果管道容量耗尽(管道缓冲区满),进程-写者将被阻塞。如果没有读者消费数据,将触发SIGPIPE。我们将在本章的最后一节提供这样的示例。正如我们将在第6章中介绍的那样,这种方式没有竞争条件的风险,但数据创建和消费的同步仍然掌握在程序员手中。下图为您提供了一些关于我们使用匿名管道时发生的情况的额外信息:
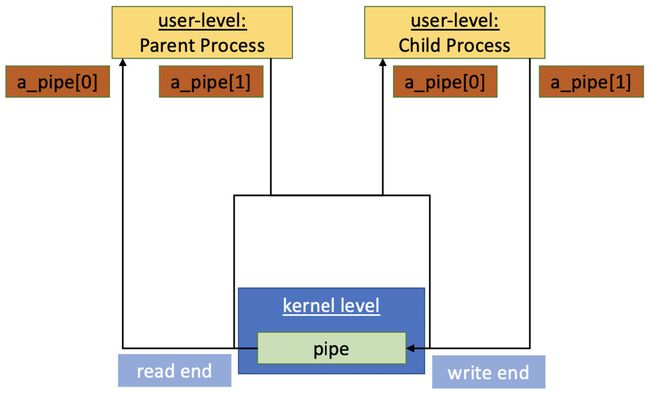
图3.4 - 匿名管道通信机制
在后台,内核级别,还有一些更多的操作在进行:

图3.5 - 匿名管道创建
可以分别使用fcntl(fd, F_GETPIPE_SZ)和F_SETPIPE_SZ操作来检查和设置管道的容量。您可以看到,默认情况下管道有16个页面。页面是虚拟内存可以管理的最小数据单位。如果单个页面是4096KB,那么它可以在溢出之前传输65536字节的数据。我们将在本章后面讨论这一点。但请记住,一些系统可能有所不同,图3.5中的信息对您来说可能是错误的。以类似的方式,我们可以表示在read()和write()操作期间在较低层次发生的情况。
在下图中,使用文件系统作为共享(全局)内存的问题出现了。请注意,尽管文件系统通过互斥锁拥有自己的保护机制,但这在用户级别并不能帮助我们正确同步数据。如前所述,通过多个进程简单地修改常规文件将引起麻烦。用管道这样做会引起较少的麻烦,但我们仍然不在安全边缘。如您所见,调度器参与其中,我们可能最终陷入不断等待的进程的死锁。与命名管道相比,匿名管道更容易避免这种情况。

图3.6 - 管道读写操作
现在我们已经建立了通信,为什么我们还需要像命名管道这样的额外文件类型呢?我们将在下一节中讨论这个问题。
命名管道
命名管道比匿名管道稍微复杂一些,因为它们有更多可编程的上下文。例如,它们有字符名称,并且用户可以在文件系统中观察到它们。它们不会在进程完成使用后被销毁,而是在执行特定的文件删除系统调用unlink()时被销毁。因此,我们可以说它们提供了持久性。与匿名管道类似,我们可以在下面的CLI命令中展示命名管道,创建结果为fifo_example:
$ ./test > fifo_example
$ cat fifo_example
$ Child: Sending message to child!
此外,通信是双工的 - 例如,数据传输可以双向工作。不过,您的工作可能会推动您将系统调用用C++代码包装起来。下一个示例提供了一个示例概览,但声明它只是示例性的,当C++上下文被添加到代码中时,程序的大小会变得更大。让我们从前面的管道示例中获取一个示例,我们可以用C++代码进行修改,但行为保持不变:
#include
#include <unistd.h>
#include <array>
#include <iostream>
#include <filesystem>
#include <string_view>
using namespace std;
using namespace std::filesystem;
static string_view fifo_name = "example_fifo"; // {1}
static constexpr size_t buf_size = 64;
void write(int out_fd,
string_view message) { // {2}
write(out_fd,
message.data(),
message.size());
}
在标记{1}处,我们引入了string_view对象。它代表一个字符串或数组的指针对以及其相应的大小。作为一个view-handle类类型,我们更倾向于并且更便宜地通过值传递它(见标记{2}),连同预期的子字符串操作接口。它总是const,所以您不需要声明为此。所以,它是一个对象,它的大小更大,但它有一个无条件安全的好处 - 处理典型的C字符串错误情况,如NULL-termination。任何问题都将在编译时处理。在我们的情况下,我们可以简单地将其用作const char*或const string的替代品。让我们继续阅读器:
string read(int in_fd) { // {3}
array <char, buf_size> buffer;
size_t bytes = read(in_fd,
buffer.data(),
buffer.size());
if (bytes > 0) {
return {buffer.data(), bytes}; // {4}
}
return {};
}
int main() {
if (!exists(fifo_name))
mkfifo(fifo_name.data(), 0666); // {5}
if (pid_t childId = fork(); childId == -1) {
perror("Process creation failed");
exit(EXIT_FAILURE);
}
标记{2}和{3}显示了write()和read()的C++包装器。您可以看到,我们使用string_view和array的data()和size(),而不是进行strlen()或sizeof()的杂技表演,因为它们通过相应的对象打包在一起。一个重要的点是,我们使用array来明确缓冲区的大小和类型。同样,我们可以使用string代替array,因为它被定义为basic_string,我们可以用reserve(buf_size)限制其大小。这个选择真的取决于您稍后在函数中的需求。在我们的案例中,我们将使用array作为从管道中读取固定大小的char缓冲区的直接表示。之后我们构造结果string或将其保留为空(见标记{4})。
现在,我们将使用已知的exists()函数来排除第二个到达的进程的第二次mkfifo()调用。然后,我们检查该文件是否真的是FIFO(见标记{6}):
else {
if(is_fifo(fifo_name)) { // {6}
if (childId == 0) {
if (int named_pipe_fd =
open(fifo_name.data(), O_RDWR);
named_pipe_fd >= 0) { // {7}
string message;
message.reserve(buf_size);
sleep(1);
message = read(named_pipe_fd); // {8}
string_view response_msg
= "Child printed the message!";
cout << "Child: " << message << endl;
write(named_pipe_fd,
response_msg); // {9}
close(named_pipe_fd);
}
现在看看标记{7}和{10}。您看到我们在哪里打开管道,保留这个结果,以及在哪里检查它的值吗?正确 - 我们将这些操作打包在if语句中,从而将我们的范围集中在相同的逻辑位置。然后,我们通过新添加的函数包装器从管道中读取(标记{8}和{12})。然后我们通过write()包装器向管道中写入(标记{9}和{11})。注意在标记{9}处,我们向函数传递string_view,而在标记{11}处,我们传递string。这两种情况都适用,因此进一步证明了我们使用string_views作为此类接口的点,而不是const string、const char *等:
else {
cout << "Child cannot open the pipe!"
<< endl;
}
}
else if (childId > 0) {
if (int named_pipe_fd =
open(fifo_name.data(), O_RDWR);
named_pipe_fd >= 0) { // {10}
string message
= "Sending some message to the child!";
write(named_pipe_fd,
message); // {11}
sleep(1);
message = read(named_pipe_fd); // {12}
cout << "Parent: " << message << endl;
close(named_pipe_fd);
}
}
else {
cout << "Fork failed!";
}
在标记{13}处移除管道,但我们将保留它用于实验。例如,我们可以列出命名管道:
$ ls -la example_fifo
prw-r--r-- 1 oem oem 0 May 30 13:45 example_fifo
请注意,它的大小是0。这意味着写入的所有内容都被消费了。在close()时,内核将刷新文件描述符,并将销毁主内存中的FIFO对象,就像它对匿名管道所做的那样。有时读者可能没有完全消费数据。正如您可能记得的那样,它可以存储16页的数据。这就是为什么我们鼓励您使用read()和write()函数返回的字节数来决定是否需要终止进程。现在看看权限位 - 您看到有趣的东西了吗?是的 - 权限位前面有一个额外的p,将这个文件标记为管道。您在本章前面的某个地方观察到这一点了吗?如果没有,您可以回去检查inode的权限位。
让我们继续最后一个代码片段:
remove(fifo_name); // {13}
}
}
return 0;
}
这是一个简单的一次性乒乓应用程序,输出如下:
Child: Sending some message to the child!
Parent: Child printed the message!
您仍然可以使用IO操作发送消息,但那时string_view就不行了。在下一节中,我们将简要概述当通过管道的通信受到干扰时会发生什么。为了保持对系统调用的关注,我们现在将暂时搁置C++。
现在让我们回到C++文件系统库。我们可以通过库操作检查当前文件是否真的是FIFO文件。如果是,那么让我们用remove()函数删除它。这与unlink()相同,尽管它在系统调用本身之上有一层抽象。再次,这将给我们一些平台独立性:
...
int main() {
if (exists("example_fifo") && is_fifo("example_fifo")){
remove("example_fifo");
cout << "FIFO is removed";
} ...
正如您所看到的,我们使用了前面章节中解释过的已知方法。现在,让我们看看现在在VFS和内核级别发生了什么:

图3.7 - 命名管道创建系统操作
这个图表,以及接下来的一个图表,为您展示了为什么匿名管道被认为更轻量一些的原因。看看从进程调用者的初始系统调用到实际执行文件系统inode操作之间有多少函数调用。话虽如此,再加上关闭和删除文件的额外工作,可以轻易得出结论,即相关代码也更大。尽管如此,命名管道用于持久性和不同进程间的通信,包括那些没有父子关系的进程。想想看 - 您在文件系统中有通信资源的端点,您知道它的字符名称,然后您只需从两个独立的进程中打开它,并开始数据传输。其他IPC机制也采用类似的方法,我们将在[第7章]中讨论。在那之前,请查看以下图表,了解在简单的open()函数和内核中创建FIFO缓冲区之间有多少操作:

图3.8 - 命名管道打开和转换为管道
文件系统库不允许您直接处理文件描述符。同时,系统调用需要它们。将来,C++标准可能会有所不同。
注意
有一个已知的非标准方法将文件描述符与iostream关联起来。您可以在这里参考:http://www.josuttis.com/cppcode/fdstream.html。
我们将在下一节中简要概述通过管道通信受到干扰时会发生什么。
简要观察信号处理
Linux中的信号是一种强大且简单的方式,通过向进程发送软件中断来同步进程,表明发生了重要事件。它们的性质不同,取决于它们的角色。有些信号可以忽略,而其他信号不能忽略,会导致进程被阻塞、解除阻塞或终止。我们在上一章中讨论了这些行为,但我们能做些什么来优雅地处理它们吗?我们将使用匿名管道示例来触发SIGPIPE信号。
让我们看看以下示例:
...
void handle_sigpipe(int sig) { // {1}
printf("SIGPIPE handled!\n");
}
int main() {
int an_pipe[2] = {0};
char buff[BUFF_LEN + 1] = {0};
if (pipe(an_pipe) == 0) {
int pid = fork();
if (pid == 0) {
close(an_pipe[pipeOut]); // {2}
close(an_pipe[pipeIn]);
}
我们定义了一个SIGPIPE处理程序(标记{1}),如果触发此信号,我们可以提供额外的功能。我们故意关闭子进程的管道两端,这样就没有进程会从中读取。然后,我们声明一个信号动作,它将信号处理程序映射到动作本身(标记{3}和{4})。我们提供了一些时间让子进程关闭文件描述符,然后我们尝试写入管道:
else {
struct sigaction act = {0};
sigemptyset(&act.sa_mask);
act.sa_handler = handle_sigpipe; // {3}
if(sigaction(SIGPIPE, &act, 0) == -1) {// {4}
perror("sigaction"); return (1);
}
close(an_pipe[pipeIn]);
sleep(1);
const char *msg = {"Sending message to child!"};
write(an_pipe[pipeOut], msg, strlen(msg) + 1);
// {5} ...
内核将触发SIGPIPE,意图阻塞父进程,直到有人从中读取。在这种情况下,我们打印出一条消息,告诉用户收到了信号,并且父进程将被终止。实际上,这是处理此类信号的默认行为。我们使用处理程序相应地通知用户:
$ ./sighandler_test
SIGPIPE handled!
然而,我们也可以通过在标记{3}上进行以下简单的更改来忽略信号:
act.sa_handler = SIG_IGN; // {3}
再次调用程序不会触发处理程序,这意味着信号被忽略,进程将根据其工作流程继续进行。您可以在代码中使用这两种方法,但要小心 - 有些信号不能被忽略。我们将在本书后面使用这些知识。
总结
在本章中,我们没有展示通过C++修改文件数据的任何示例。我们的目标主要是解释不同Linux文件系统实体。我们使用C++文件系统库丰富了这方面的知识 - 例如,提高系统编程意识。您了解了不同文件系统对象的角色及其特点。您还拥有C++工具来管理文件资源并提升您的抽象水平。还有一些实际示例,展示了如何通过匿名管道和命名管道在进程之间进行通信。它们在操作系统级别的实现也被讨论了,我们还简要探讨了Linux中的信号处理。
在下一章中,我们将深入探讨C++语言,为其安全和安全的使用奠定基础,符合最新标准。稍后在本书中,我们将重新访问本章中展示的一些代码段。我们将通过使用新的C++功能不断改进它们。