C++ 编程的幕后花絮
在C++的世界中,精准与创造力相结合,程序员们正在构建改变人们生活的非凡应用程序。我们希望这本书能帮助你成为那个社区不可或缺的一部分。
下面,你将通过C++基础知识的速成。我们将涉及诸如C++中的应用程序构建过程、C++应用程序的底层细节,以及面向对象编程技术的快速介绍等主题。
将讨论以下主题:
- C++及其最新标准简介
- 源代码编译、预处理和链接的幕后原理
- 可执行文件的加载和运行过程
- 函数调用和递归背后的复杂性
- 数据类型、内存段和寻址基础
- 指针、数组和控制结构
- 面向对象编程的基础
- 类关系、继承和多态
让我们开始吧!
构建C++应用程序
你可以使用任何文本编辑器来编写代码,因为最终代码只是文本。在编写代码时,你可以自由选择简单的文本编辑器,如Vim,或高级的集成开发环境(IDE),如MS Visual Studio。普通文本文件和源代码之间的唯一区别是,后者可能会被一个称为编译器的特殊程序解释(虽然情书不能编译成程序,但它可能会让你心动)。
为了区分普通文本文件和源代码,使用了特殊的文件扩展名。C++使用的扩展名是.cpp和.h(你也可能偶尔遇到.cxx和.hpp)。在深入细节之前,将编译器看作是将源代码转换为可运行程序的工具,这个可运行程序被称为可执行文件或简称为可执行文件。将源代码制作成可执行文件的过程称为编译。编译C++程序是一系列复杂任务的序列,最终生成机器代码。机器代码是计算机的本机语言——这就是为什么它被称为机器代码。
通常,C++编译器会解析和分析源代码,然后生成中间代码,对其进行优化,并最终在称为对象文件的文件中生成机器代码。你可能已经遇到过对象文件;它们有单独的扩展名——Linux中是.o,Windows中是.obj。创建的对象文件不仅包含计算机可以运行的机器代码。编译通常涉及多个源文件,编译每个源文件会产生一个单独的对象文件。然后,这些对象文件由一个称为链接器的工具链接在一起,形成一个单一的可执行文件。这个链接器使用存储在对象文件中的附加信息来正确地链接它们(链接将在本章后面讨论)。
以下示意图展示了程序构建阶段:
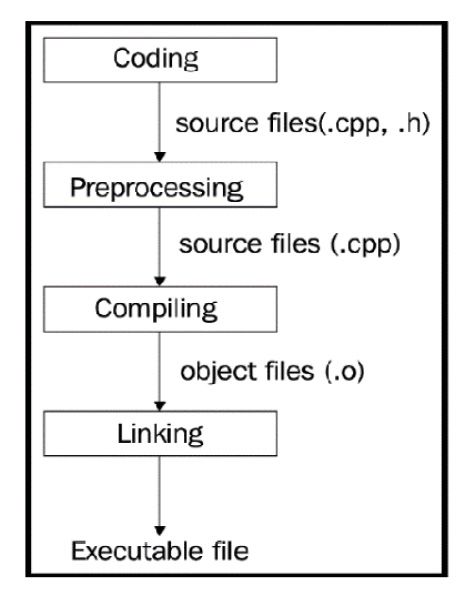
C++应用程序的构建过程包含三个主要步骤:
- 预处理
- 编译
- 链接
所有这些步骤都使用不同的工具完成,但现代编译器将它们封装在一个工具中,从而为程序员提供了一个单一且更直接的接口。
生成的可执行文件持久存储在计算机的硬盘上。要运行它,应将其复制到主内存,即RAM。复制工作由另一个名为加载器的工具完成。加载器是操作系统(OS)的一部分,知道应从可执行文件的内容中复制什么以及复制到何处。将可执行文件加载到主内存后,原始的可执行文件不会从硬盘上删除。
程序由操作系统加载和运行。操作系统管理程序的执行,使其优先于其他程序,完成后卸载它等等。正在运行的程序副本称为进程。进程是可执行文件的一个实例。
预处理
预处理器旨在处理源文件以使它们准备好进行编译。预处理器使用预处理器指令工作,如#define、#include等。指令不代表程序语句,而是对预处理器的命令,告诉它如何处理源文件的文本。编译器无法识别这些指令,所以当你在代码中使用预处理器指令时,预处理器会在实际编译代码开始之前相应地解析它们。
例如,以下代码在编译器开始编译之前会被更改:
#define NUMBER 41
int main() {
int a = NUMBER + 1;
return 0;
}
使用#define指令定义的所有内容称为宏。预处理后,编译器获得的转换后的源码如下:
int main() {
int a = 41 + 1;
return 0;
}
使用在语法上正确但逻辑上有错误的宏是危险的:
#define SQUARE_IT(arg) (arg * arg)
预处理器将SQUARE_IT(arg)的任何出现替换为(arg * arg),因此以下代码将输出16:
int st = SQUARE_IT(4);
std::cout << st;
编译器将接收如下代码:
int st = (4 * 4);
std::cout << st;
当我们使用复杂表达式作为宏参数时,问题就出现了:
int bad_result = SQUARE_IT(4 + 1);
std::cout << bad_result;
直观上,这段代码将产生25,但实际上预处理器除了文本处理外什么也不做,在这种情况下,它像这样替换宏:
int bad_result = (4 + 1 * 4 + 1);
std::cout << bad_result; // 输出9,而不是25
要修复宏定义,请用额外的括号包围宏参数:
#define SQUARE_IT(arg) ((arg) * (arg))
现在,表达式将采取这种形式:
int bad_result = ((4 + 1) * (4 + 1));
提示
作为经验法则,避免使用宏定义。宏容易出错,C++提供了一组构造,使宏的使用变得过时。
前面的例子如果使用constexpr函数,将在编译时进行类型检查和处理:
constexpr int double_it(int arg) { return arg * arg; }
int bad_result = double_it(4 + 1);
使用constexpr说明符,使得函数的返回值(或变量的值)可以在编译时求值。
头文件
预处理器最常见的用途是#include指令,它旨在将头文件包含到源代码中。头文件包含函数、类等的定义:
// 文件:main.cpp
#include 预处理器检查main.cpp后,它将用iostream和rect.h的相应内容替换#include指令。
C++17引入了__has_include预处理器常量表达式,如果找到指定名称的文件,则计算为1;如果没有找到,则计算为0:
#if __has_include("custom_io_stream.h")
#include "custom_io_stream.h"
#else
#include 声明头文件时,强烈建议使用所谓的包含保护(#ifndef、#define和#endif)以避免双重声明错误。
使用模块
模块解决了带有烦人的include-guard问题的头文件。我们现在可以摆脱预处理器宏。模块包含两个关键字——import和export。要使用模块,我们import它。要声明带有其导出属性的模块,我们使用export。在我们列出使用模块的好处之前,让我们看一个简单的使用示例。
以下代码声明了一个模块:
export module test;
export int square(int a) { return a * a; }
第一行声明了名为test的模块。接下来,我们声明了square()函数并将其设置为export。这意味着我们可以有一些未导出的函数和其他实体,因此它们在模块外部是私有的。通过导出一个实体,我们将其设置为模块用户的public。要使用module,我们必须导入它,如下代码所示:
import test;
int main() {
square(21);
}
以下特性使模块与常规头文件相比更加优越:
- 一个模块只导入一次,类似于由自定义语言实现支持的预编译头文件。这大大减少了编译时间。未导出的实体不影响导入模块的翻译单元。
- 模块允许我们通过选择哪些单元应该导出哪些不应该导出来表达代码的逻辑结构。模块可以捆绑到更大的模块中。
- 我们可以摆脱诸如之前描述的包含保护等变通方法。我们可以以任何顺序导入模块。不再担心宏重定义的问题。
模块可以与头文件一起使用。我们可以在同一个文件中同时导入和包含头文件,如下例所示:
import <iostream>;
#include 创建模块时,你可以自由地在模块的接口文件中导出实体,并将实现移动到其他文件中。逻辑与管理.h和.cpp文件的逻辑相同。
编译
C++编译过程包含几个阶段。其中一些阶段旨在分析源代码,而其他阶段则生成和优化目标机器代码。
以下示意图显示了编译的阶段:
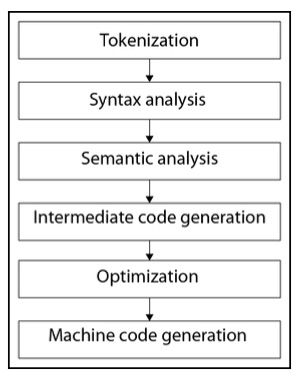
让我们详细了解其中一些阶段。
语法分析
在谈论编程语言编译时,我们通常区分两个术语——语法和语义:
- 语法是代码的结构;它定义了组合令牌(tokens)使其在结构上有意义的规则。例如,"day nice"在英语中是一个语法上正确的短语,因为它在令牌中没有错误。
- 另一方面,语义关注代码的实际含义——即"day nice"在语义上是不正确的,应该更正为"nice day"。
语法分析是源代码分析的重要部分,因为令牌将在语法和语义上进行分析——即它们是否符合一般语法规则的含义。
让我们来看一个例子:
int b = a + 0;
这对我们来说可能没有意义,因为向变量添加零不会改变其值,但编译器在这里不会考虑逻辑意义——它寻找的是代码的语法正确性(缺少分号、缺少闭合括号等)。在编译的语法分析阶段,检查代码的语法正确性。词法分析部分将代码划分为令牌;语法分析检查语法正确性,这意味着如果我们漏掉了一个分号,上述表达式将产生语法错误:
int b = a + 0
g++将抱怨在声明结束处预期有';'错误。
优化
生成中间代码有助于编译器对代码进行优化。编译器尝试大量优化代码。优化在不止一个阶段完成。例如,请看下面的代码:
int a = 41;
int b = a + 1;
在编译期间,上述代码将被优化为以下形式:
int a = 41;
int b = 41 + 1;
这将再次被优化为以下形式:
int a = 41;
int b = 42;
一些程序员毫不怀疑,如今,编译器编写的代码比程序员更好。
生成机器代码
编译器在中间代码和生成的机器代码中都进行了优化。编译器通常生成包含除机器代码以外的许多其他数据的对象文件。
对象文件的结构取决于平台;例如,在Linux中,它以可执行和链接格式(ELF)表示。平台是程序执行的环境。在这个上下文中,通过平台,我们指的是计算机架构(更具体地说,是指令集架构)和操作系统的组合。硬件和操作系统是由不同的团队和公司设计和创建的。他们每个人都有解决设计问题的不同方案,这导致平台之间存在重大差异。平台在许多方面都有所不同,这些差异也反映在可执行文件的格式和结构上。例如,Windows系统中的可执行文件格式是可移植可执行(PE),其结构、数量和部分顺序与Linux中的ELF不同。
对象文件被划分为节(sections)。对我们来说最重要的是代码节(标记为.text)和数据节(.data)。.text节包含程序的指令,而.data节包含指令使用的数据。数据本身可能被分为几个部分,如已初始化、未初始化和只读数据。
除了.text和.data节之外,对象文件的一个重要部分是符号表。符号表存储字符串(符号)到对象文件中位置的映射。在前面的例子中,编译器生成的输出有两个部分,第二部分被标记为information:,其中包含代码中使用的函数的名称和它们的相对地址。这个information:是对象文件实际符号表的抽象版本。符号表包含代码中定义的符号和代码中使用的需要解析的符号。这些信息随后被链接器用来将对象文件链接在一起,形成最终的可执行文件。
链接
让我们看看以下项目结构:
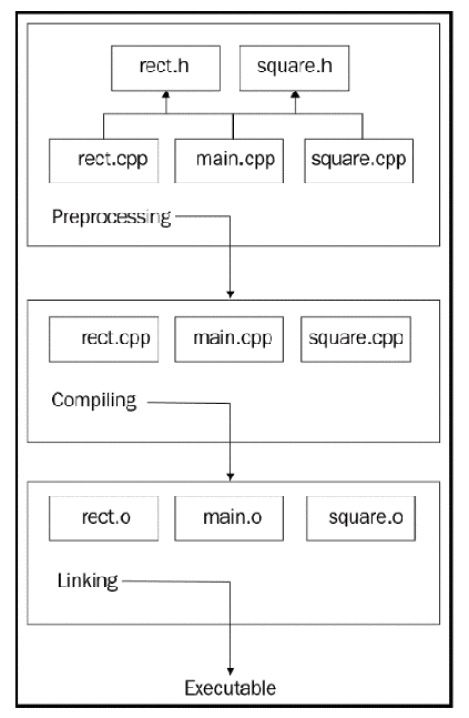
编译器将单独编译每个单元。编译单元,也被称为源文件,在某种程度上是彼此独立的。
当编译器编译main.cpp时,该文件中有对Rect中的get_area()函数的调用,但它不会在main.cpp中包含get_area()的实现。相反,它确信该函数在项目的某处有实现。当编译器处理rect.cpp时,它不知道get_area()函数是否在其他地方被使用。以下是编译器在main.cpp通过预处理阶段后获得的内容:
// iostream的内容
struct Rect {
private:
double side1_;
double side2_;
public:
Rect(double s1, double s2);
const double get_area() const;
};
struct Square : Rect {
Square(double s);
};
int main() {
Rect r(3.1, 4.05);
std::cout << r.get_area() << std::endl;
return 0;
}
在分析main.cpp之后,编译器生成以下中间代码(为了简单表达编译背后的思想,省略了许多细节):
struct Rect {
double side1_;
double side2_;
};
void _Rect_init_(Rect* this, double s1, double s2);
double _Rect_get_area_(Rect* this);
struct Square {
Rect _subobject_;
};
void _Square_init_(Square* this, double s);
int main() {
Rect r;
_Rect_init_(&r, 3.1, 4.05);
printf("%d\n", _Rect_get_area(&r));
// 为了简洁起见,我们有意使用printf替换了cout
// 假设编译器生成C语言的中间代码
return 0;
}
因为Square结构体及其构造函数(我们命名为_Square_init_)在源代码中从未使用过,所以编译器在优化代码时会移除它们。
此时,编译器只操作main.cpp,所以它看到我们调用了_Rect_init_和_Rect_get_area_函数,但没有在同一个文件中提供它们的实现。然而,由于我们事先提供了它们的声明,编译器相信我们并认为这些函数在其他编译单元中有实现。基于这种信任和有关函数签名的最少信息(其返回类型、名称以及参数的数量和类型),编译器生成一个对象文件,该文件包含main.cpp中的工作代码,并以某种方式标记那些没有实现但被信任将在以后解析的函数。这种解析由链接器完成。
以下示例是生成的对象文件的简化版本,它包含两个部分——代码和信息。代码部分有每条指令的地址(十六进制值):
code:
0x00 main
0x01 Rect r;
0x02 _Rect_init_(&r, 3.1, 4.05);
0x03 printf("%d\n", _Rect_get_area(&r));
information:
main: 0x00
_Rect_init_: ????
printf: ????
_Rect_get_area_: ????
看一下信息部分。编译器将代码部分中未在同一编译单元中找到的所有函数标记为????。链接器将这些问号替换为在其他单元中找到的函数的实际地址。处理完main.cpp后,编译器开始编译rect.cpp文件:
// 文件: rect.cpp
struct Rect {
// 预处理阶段用rect.h文件的内容替换#include "rect.h"
// 为了简洁起见,代码省略
};
Rect::Rect(double s1, double s2)
: side1_(s1), side2_(s2)
{}
const double Rect::get_area() const {
return side1_ * side2_;
}
按照同样的逻辑,这个单元的编译产生以下输出(别忘了,我们仍在提供抽象示例):
code:
0x00 _Rect_init_
0x01 side1_ = s1
0x02 side2_ = s2
0x03 return
0x04 _Rect_get_area_
0x05 register = side1_
0x06 reg_multiply side2_
0x07 return
information:
_Rect_init_: 0x00
_Rect_get_area_: 0x04
这个输出包含了所有函数的地址,所以不需要等待某些函数稍后解析。
链接器的任务是将这些对象文件组合成一个单独的对象文件。合并文件会导致相对地址的变化;例如,如果链接器将rect.o文件放在main.o之后,则rect.o的起始地址将从之前的0x00变为0x04:
code:
0x00 main
0x01 Rect r;
0x02 _Rect_init_(&r, 3.1, 4.05);
0x03 printf("%d\n", _Rect_get_area(&r)); 0x04 _Rect_init_
0x05 side1_ = s1
0x06 side2_ = s2
0x07 return
0x08 _Rect_get_area_
0x09 register = side1_
0x0A reg_multiply side2_
0x0B return
information (符号表):
main: 0x00
_Rect_init_: 0x04
printf: ????
_Rect_get_area_: 0x08
_Rect_init_: 0x04
_Rect_get_area_: 0x08
相应地,链接器更新符号表地址(在我们的示例中是information:部分)。如前所述,每个对象文件都有一个符号表,它将符号的字符串名称映射到文件中的相对位置(地址)。链接的下一步是解析对象文件中所有未解析的符号。
现在链接器已经将main.o和rect.o组合在一起,它知道未解析符号的相对位置,因为它们现在位于同一个文件中。printf符号的解析方式也是一样,只不过这次它会将对象文件与标准库链接。一旦所有的对象文件被组合(为了简洁起见,我们省略了square.o的链接),所有的地址都被更新,所有的符号都被解析,链接器输出一个最终的对象文件,可以由操作系统执行。正如本章前面所讨论的,操作系统使用一个称为加载器的工具将可执行文件的内容加载到内存中。
链接库
库与可执行文件类似,但有一个主要区别:它没有main()函数,这意味着它不能像常规程序那样被调用。库用于组合可能会在多个程序中重用的代码。例如,您已经通过包含
库可以作为静态或动态库与可执行文件链接。当您将它们作为静态库链接时,它们会成为最终可执行文件的一部分。动态链接库也应由操作系统加载到内存中,以便为您的程序提供调用其函数的能力。假设我们想要找到一个函数的平方根:
int main() {
double result = sqrt(49.0);
}
C++标准库提供了sqrt()函数,它返回其参数的平方根。如果您编译前面的示例,它将产生错误,坚持sqrt函数尚未声明。我们知道要使用标准库函数,应该包含相应的std命名空间中),然后包含在我们的源文件中:
#include 编译器将sqrt符号的地址标记为未知,链接器应在链接阶段解决它。如果源文件未与标准库实现(包含库函数的对象文件)链接,链接器将无法解决它。链接器生成的最终可执行文件将由我们的程序和标准库组成,如果链接是静态的。另一方面,如果链接是动态的,链接器将标记sqrt符号以在运行时找到。
现在,当我们运行程序时,加载器还会加载动态链接到我们程序的库。它还会将标准库的内容加载到内存中,然后在内存中解析sqrt()函数的实际位置。已经加载到内存中的同一库可以被其他程序使用。
使用C++进行低级编程
最初,C++被视为C语言的继承者;然而,从那时起,它已经发展成为一种庞大、有时令人恐惧甚至难以驾驭的东西。随着最近语言的更新,它现在代表了一个需要时间和耐心来驯服的复杂野兽。我们将从介绍几乎每种语言都支持的基本构造开始这一章,如数据类型、条件和循环语句、指针、结构体和函数。我们将从低级系统程序员的角度来看待这些构造,他们好奇的是计算机如何执行甚至一个简单的指令。深入理解这些基本构造是构建更高级和抽象主题(如面向对象 编程(OOP))的坚实基础的前提。
函数
程序执行以main()函数开始,这是标准中规定的程序的指定起点。一个输出Hello, World!消息的简单程序将如下所示:
#include 您可能已经遇到或使用过main()函数的参数。它有两个参数argc和argv,允许从环境中传递字符串。这些通常被称为命令行参数。
argc和argv的名称是惯例,可以替换为您想要的任何内容。argc参数保存传递给main()函数的命令行参数数量;argv参数保存必要的参数
例如,我们可以使用以下参数编译并运行前面的示例:
$ my-program argument1 hello world --some-option
这将在屏幕上输出以下内容:
传递的参数数量是:5
参数包括:
argument1
hello
world
--some-option
当您查看参数数量时,会注意到它是5。第一个参数始终是程序的名称;这就是为什么我们在这个示例中通过从数字1开始循环来跳过它。
注意
很少见,您可能会看到一个广泛支持但未标准化的第三个参数,通常命名为envp。envp的类型是char指针数组,它保存系统的环境变量。
程序可以包含许多函数,但程序的执行总是从main()函数开始,至少从程序员的角度来看。让我们尝试编译以下代码:
#includeg++在foo();调用上引发了一个错误,即C++ requires a type specifier for all declarations。调用被解析为声明而不是执行指令的方式。我们尝试在main()之前调用函数的方式对于经验丰富的开发人员来说可能看起来愚蠢,那么让我们尝试另一种方式。如果我们声明在初始化期间调用函数的东西会怎样呢?我们定义了一个具有构造函数打印消息的BeforeMain结构体,然后在全局作用域中声明了BeforeMain类型的对象。
该示例成功编译,程序输出以下内容:
Constructing BeforeMain
Calling main()
如果我们向BeforeMain添加成员函数并尝试调用它会怎样?请看以下代码以理解这一点:
struct BeforeMain {
// constructor code omitted for brevity
void test() {
std::cout << "test function" << std::endl;
}
};
BeforeMain b;
b.test(); // compiler error
int main() {
// code omitted for brevity
}
对test()的调用不会成功。所以,我们不能在main()之前调用函数,但我们可以声明变量——对象默认会被初始化。所以,在main()被调用之前,有些东西执行了初始化。事实证明,main()函数并不是程序的真正起点。程序的实际起始函数准备了环境——即收集传递给程序的参数,然后调用main()函数。这是必需的,因为C++支持在程序开始之前需要初始化的全局和静态对象,这意味着在main()函数被调用之前。在Linux世界中,这个函数被称为__libc_start_main。编译器增加了对__libc_start_main的调用,这反过来又可能会或不会在调用main()函数之前调用其他初始化函数。从抽象的角度来看,只需想象前面的代码将被改变为类似于以下内容:
void __libc_start_main() {
BeforeMain b;
main();
}
__libc_start_main(); // 调用入口点
递归
main()的另一个特殊属性是它不能被递归调用。从操作系统的角度来看,main()函数是程序的入口点,所以再次调用它意味着重新开始一切;因此,这是被禁止的。然而,仅仅因为一个函数调用自己而称其为递归是部分正确的。例如,print_number()函数调用自己且永远不会停止:
void print_number(int num) {
std::cout << num << std::endl;
print_number(num + 1); // 递归调用
}
调用print_number(1)函数将输出数字1、2、3等。这更像是一个无限调用自身的函数,而不是一个正确的递归函数。我们应该添加几个更多的属性,使print_number()函数成为一个有用的递归函数。首先,递归函数必须有一个基本情况,一个进一步函数调用停止的场景,这意味着递归停止传播。我们可以为print_number()函数制定这样一个场景,例如,如果我们想打印到100:
void print_number(int num) {
if (num > 100) return; // 基本情况
std::cout << num << std::endl;
print_number(num + 1); // 递归调用
}
一个函数要成为递归的,还有一个属性:解决最终会导致基本情况的较小问题。在前面的例子中,我们已经通过为函数解决一个较小的问题来实现了这一点——即打印一个数字。打印一个数字后,我们转向下一个小问题:打印下一个数字。最后,我们到达了基本情况,我们就完成了。一个函数调用自己并没有什么神奇的;将其视为一个函数调用另一个具有相同实现的不同函数。有趣的是递归函数如何整体影响程序的执行。
当一个函数被调用时,为其参数和局部变量分配内存空间。程序从main()函数开始,在这个示例中,它只是通过传递11和22字面值来调用calculate()函数。控制跳转到calculate()函数,main()函数有点悬而未决;它等待calculate()函数返回以继续执行。calculate()函数有两个参数,a和b;虽然我们为sum()、max()和calculate()命名不同,但我们可以在所有函数中使用相同的名称。为这两个参数分配内存空间。假设一个int占用4字节内存,因此至少需要8字节内存才能成功执行calculate()函数。分配了8字节后,11和22应该被复制到相应的位置(有关详细信息,请参见以下图表):

calculate()函数调用了sum()和max()函数,并将其参数值传递给它们。相应地,它等待这两个函数依次执行以形成要返回给main()的值。sum()和max()函数不是同时调用的。首先调用sum(),这导致a和b变量的值从为sum()的参数分配的位置复制到名为n和m的位置,这再次总共占用了8字节。请看以下图表以更好地理解这一点:
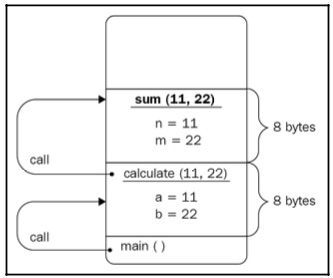
它们的sum被计算并返回。函数执行完毕并返回值后,内存空间被释放。这意味着n和m变量不再可访问,它们的位置可以被重用。
重要说明
此时我们没有考虑临时变量。我们将稍后重新访问这个示例,以展示函数执行的隐藏细节,包括临时变量以及如何尽可能避免它们。
在sum()返回值之后,调用了max()函数。它遵循相同的逻辑:为x和y参数以及res变量分配内存。我们故意将三元运算符(?:)的结果存储在res变量中,以使max()函数在这个示例中分配更多的空间。因此,max()函数总共分配了12字节。此时,x main()函数仍在等待,等待calculate(),而calculate()反过来又在等待max()函数完成(详细信息请参见以下图表):

当max()函数完成时,分配给它的内存被释放,其返回值被calculate()使用以形成要返回的值。类似地,当calculate()返回时,内存被释放,main()函数的局部变量result将包含calculate()返回的值。
然后main()函数完成其工作,程序退出——即操作系统释放为程序分配的内存,并可稍后为其他程序重用。为函数分配和释放内存(取消分配)的描述过程是使用称为栈的概念完成的。
注意
栈是一种数据结构适配器,它有插入和访问其中数据的规则。在函数调用的上下文中,栈通常指为程序提供的自动管理自己的内存段,同时遵循栈数据结构适配器的规则。我们将在本章后面更详细地讨论这一点。
回到递归,当函数调用自己时,应该为新调用的函数的参数和局部变量(如果有的话)分配内存。函数再次调用自己,这意味着栈将继续增长(以提供空间给新函数)。我们调用相同的函数并不重要;从栈的角度来看,每个新的调用都是对完全不同函数的调用,因此它会认真地为其分配空间,同时吹着它最喜欢的歌。请看以下图表:
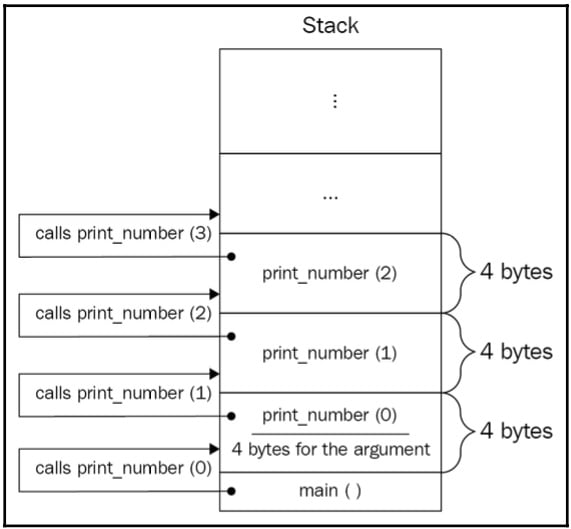
递归函数的第一次调用被搁置,等待同一个函数的第二次调用,而第二次调用又被搁置,等待第三次调用完成并返回一个值,接着第三次调用又被搁置,依此类推。如果函数中存在bug或递归基础难以达到,迟早栈会过度增长,导致程序崩溃。这就是所谓的栈溢出。
尽管递归为问题提供了更优雅的解决方案,但在编程时应尽量避免使用递归,而使用迭代方法(循环)。在诸如火星探测车导航系统的关键任务系统开发指南中,完全禁止使用递归。
数据和内存
当我们提到计算机内存时,默认考虑的是随机存取存储器(RAM)。此外,RAM是SRAM或DRAM的通称;除非另有说明,我们默认指的是DRAM。为了澄清这一点,让我们看一下下面的图表,它展示了内存层次结构:

当我们编译一个程序时,编译器将最终的可执行文件存储在硬盘上。为了运行可执行文件,其指令被加载到RAM中,然后由CPU逐一执行。这让我们得出结论,任何需要执行的指令都应该在RAM中。这部分是正确的。负责运行和监控程序的环境扮演着主要角色。
我们编写的程序在托管环境中执行,即在操作系统(OS)中。操作系统不是直接将程序的内容(其指令和数据,即进程)加载到RAM中,而是加载到虚拟内存中,这是一种既便于处理进程又能在进程间共享资源的机制。每当我们提到进程被加载到的内存时,我们指的是虚拟内存,而虚拟内存又将其内容映射到RAM中。
让我们从内存结构的介绍开始,然后研究内存中的数据类型。
虚拟内存
内存由许多盒子组成,每个盒子可以存储指定数量的数据。我们将这些盒子称为内存单元,考虑到每个单元可以存储1字节代表8位的数据。即使存储相同的值,每个内存单元也是独一无二的。通过对单元进行寻址来实现这种独特性,使得每个单元在内存中都有其独特的地址。第一个单元的地址是0,第二个单元的地址是1,依此类推。
下面的图表展示了内存的一部分,每个单元都有一个独特的地址,并且能够存储1字节的数据:
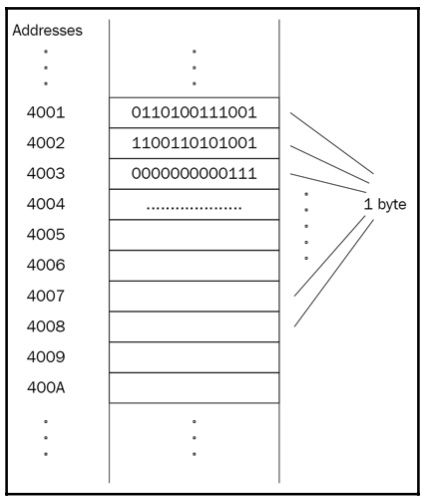
上述图表可以用来抽象地表示物理内存和虚拟内存。添加一个抽象层的目的是为了便于管理进程,并提供比物理内存更多的功能。例如,操作系统可以执行大于物理内存的程序。以占用近2GB空间的电脑游戏为例,而电脑的物理内存只有512MB。虚拟内存允许操作系统通过从物理内存卸载旧部分并映射新部分来逐部分加载程序。
虚拟内存还更好地支持在内存中同时有多个程序,从而支持多个程序的并行(或伪并行)执行。这还提供了共享代码和数据的高效使用,如动态库。当两个不同的程序需要同一库时,内存中可以存在一个库的单一实例,并被两个程序使用,而它们彼此不知道。
让我们看一下下面的图表,它描述了加载到内存中的三个程序:

上述图表中有三个正在运行的程序;每个程序在虚拟内存中占用一定空间。我的程序完全包含在物理内存中,而计算器和文本编辑器部分映射到物理内存中。
地址寻址
如前所述,每个内存单元都有一个独一无二的地址,这保证了每个单元的唯一性。地址通常以十六进制形式表示,因为它更短,且转换为二进制比转换为十进制数更快。加载到虚拟内存中的程序操作并看到逻辑地址。这些地址,也称为虚拟地址,是由操作系统提供的假地址,操作系统在需要时将它们转换为物理地址。为了优化转换过程,CPU提供了转址旁路缓存,它是其内存管理单元(MMU)的一部分。转址旁路缓存缓存了最近的虚拟地址到物理地址的转换。因此,高效的地址转换是一个软件/硬件任务。我们将在[第5章],内存管理和智能指针中深入探讨地址的结构和转换细节。
地址的长度定义了系统可以操作的内存总大小。当你遇到诸如32位系统或64位系统之类的说法时,这意味着地址的长度——即地址是32位或64位长。地址越长,内存越大。为了澄清这一点,让我们比较一个8位长的地址和一个32位长的地址。如前所约定,每个内存单元可以存储1字节的数据,并具有唯一的地址。如果地址长度是8位,那么第一个内存单元的地址是全零 - 0000 0000。下一个单元的地址大1 - 即它是0000 0001 - 以此类推。
8位可以表示的最大值是1111 1111。那么,使用8位长的地址可以表示多少个内存单元?这个问题值得更详细地回答。1位可以表示多少不同的值?两个!为什么?因为1位可以表示1或0。2位可以表示多少不同的值?嗯,00是一个值,01是另一个值,然后是10,最后是11。所以,总共有四个不同的值可以由2位表示。
让我们做一个表格:
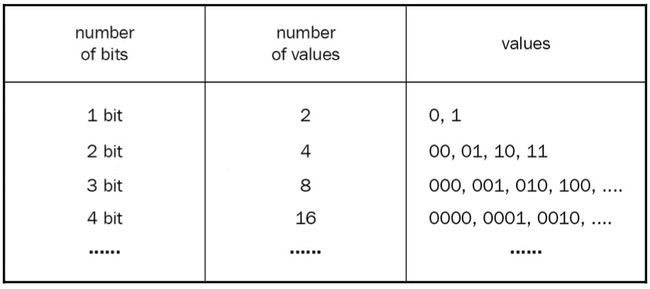
我们在这里可以看到一个模式。数字中的每个位置(每个位)可以有两个值,所以我们可以通过找到2N*来计算*N*位可以代表的不同值的数量;因此,8位可以代表的不同值数量是*256*。这意味着一个8位系统最多可以寻址256个内存单元。另一方面,32位系统可以寻址*232 = 4,294,967,296个内存单元,每个存储1字节的数据——即存储4294967296 * 1字节 = 4GB的数据。
数据类型
为什么要有数据类型呢?为什么我们不能用一些var关键字在C++中声明变量,然后忘记short、long、int、char、wchar等变量类型呢?实际上,C++确实支持一个类似的结构,称为auto关键字,我们在本章前面已经使用过了,它是一种所谓的占位类型指示符。之所以称为占位符,是因为它确实是一个占位符。我们不能(也绝不应该能够)声明一个变量,然后在运行时改变它的类型。以下代码可能是有效的JavaScript代码,但它不是有效的C++代码:
var a = 12;
a = "Hello, World!";
a = 3.14;
想象一下,如果C++编译器可以编译这段代码,应该为变量a分配多少内存?当声明var a = 12;时,编译器可以推断其类型为int并指定4字节的内存空间,但当变量的值改变为Hello, World!时,编译器必须重新分配空间或发明一个名为a1的新隐藏变量,类型为std::string。然后,编译器尝试找到每一个访问变量的代码,并将其作为字符串而不是整数或双精度浮点数来访问,并用隐藏的a1变量替换原变量。编译器可能会放弃并开始质疑生命的意义。
我们可以在C++中声明类似于前面代码的变量,如下所示:
auto a = 12;
auto b = "Hello, World!";
auto c = 3.14;
前两个示例之间的区别在于,第二个示例声明了三个不同类型的不同变量。之前的非C++代码仅声明了一个变量,然后将不同类型的值赋给它。在C++中,你不能改变一个变量的类型,但编译器允许你使用auto占位符,并根据赋予它的值推断变量的类型。
需要理解的关键是,类型是在编译时推断出来的,而像JavaScript这样的语言允许在运行时推断类型。后者之所以可能,是因为这类程序运行在虚拟机等环境中,而运行C++程序的唯一环境是操作系统。C++编译器必须生成一个有效的可执行文件,可以复制到内存中并在没有支持系统的情况下运行。这迫使编译器事先知道变量的实际大小。知道大小对于生成最终的机器代码很重要,因为访问变量需要其地址和大小,为变量分配内存空间需要它应占用的字节数。
C++类型系统将类型分类为两个主要类别:
- 基本类型(
int、double、char、void) - 复合类型(
pointers、arrays、classes)
该语言甚至支持特殊的类型特征,如std::is_fundamental和std::is_compound,用于确定类型的类别。这里有一个例子:
#include <iostream>
#include <type_traits>
struct Point {
float x;
float y; };
int main() {
std::cout << std::is_fundamental_v<Point> << " "
<< std::is_fundamental_v<int> << " "
<< std::is_compound_v<Point> << " "
<< std::is_compound_v<int> << std::endl;
}
大多数基本类型都是算术类型,如int或double;甚至char类型也是算术类型。它保存的是一个数字而不是字符,如下所示:
char ch = 65;
std::cout << ch; // 打印 A
char变量保存1字节的数据,这意味着它可以代表256个不同的值(因为1字节是8位,8位可以用*28*种方式来代表一个数字)。如果我们将其中一个位用作*符号位*,例如,允许该类型支持负值呢?这就留下了7位来代表实际的值。按照相同的逻辑,它允许我们代表27个不同的值 - 即128个(包括0)不同的正数值和相同数量的负数值。不包括0,我们得到带符号的char变量的范围为-127到+127。这种有符号与无符号的表示适用于几乎所有整数类型。
因此,每当你遇到例如int大小为4字节的说法时,你应该已经知道,它可以用无符号表示法表示从0到232的数字,用有符号表示法表示从-231到+2^31的值。
指针
C++是一种独特的语言,它提供了对诸如变量地址这样的底层细节的访问。我们可以使用&运算符获取程序中声明的任何变量的地址,如下所示:
int answer = 42;
std::cout << &answer;
这段代码将输出类似于以下内容:
0x7ffee1bd2adc
注意地址的十六进制表示。尽管这个值只是一个整数,但它用于存储在称为指针的特殊变量中。指针只是一个可以存储地址值的变量,并支持*运算符(解引用),使我们能够找到存储在该地址的实际值。
例如,要将前面示例中的变量answer的地址存储起来,我们可以声明一个指针并将地址分配给它:
int* ptr = &answer;
变量answer被声明为int,通常占用4字节的内存空间。我们已经同意,每个字节都有一个独一无二的地址。我们能否得出结论说answer变量有四个独一无二的地址?嗯,是也不是。它确实占用了四个不同但相邻的内存字节,但是当对变量使用地址运算符时,它返回其第一个字节的地址。让我们看看一段声明了几个变量的代码,然后展示它们在内存中的布局:
int ivar = 26;
char ch = 't';
double d = 3.14;
数据类型的大小是实现定义的,尽管C++标准规定了每种类型支持的最小值范围。假设实现为int提供了4字节,为double提供了8字节,为char提供了1字节。前述代码的内存布局应该是这样的:
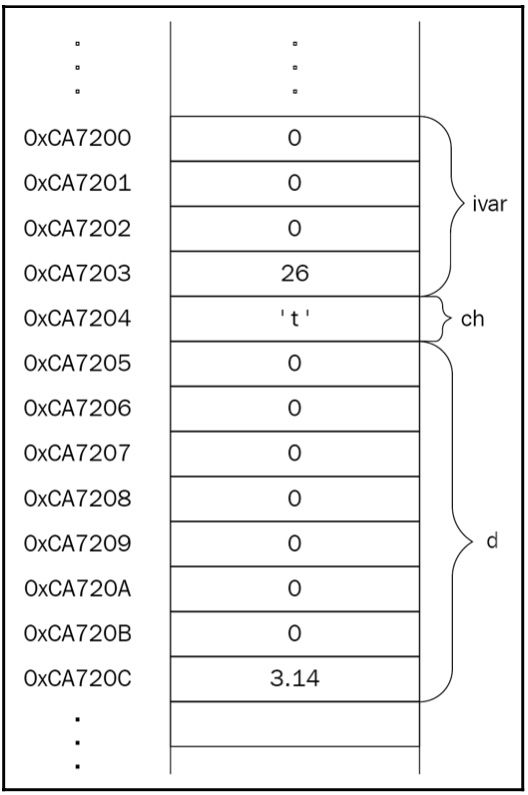
在内存布局中,请特别注意ivar;它占据了四个连续的字节。
每当我们获取变量的地址时,不管它占用一个字节还是多个字节,我们得到的都是变量第一个字节的地址。如果大小不影响地址运算符背后的逻辑,那么为什么我们必须声明指针的类型呢?为了在前面的示例中存储ivar的地址,我们应该将指针声明为int*:
int* ptr = &ivar;
char* pch = &ch;
double* pd = &d;
前述代码在下图中表示:

图1.12:插图,展示了一块内存,其中包含指向其他变量的指针
事实证明,指针的类型对于使用该指针访问变量至关重要。C++提供了解引用运算符来实现这一点(指针名称前的*符号):
std::cout << *ptr; // 打印 26
其工作原理如下:
- 它读取指针的内容。
- 它找到与指针中的地址相等的内存单元的地址。
- 它返回存储在该内存单元中的值。
问题是,如果指针指向占用多个内存单元的数据怎么办?这就是指针类型发挥作用的地方。当解引用指针时,它的类型被用来确定它应该从指针指向的内存单元开始读取并返回多少字节。
现在我们知道,指针存储变量第一个字节的地址,我们可以通过向前移动指针来读取变量的任何字节。我们应该记住,地址只是一个数字,所以从它加上或减去另一个数字将产生另一个地址。如果我们用char指针指向一个整数变量会怎样呢?
int ivar = 26;
char* p = (char*)&ivar;
当我们尝试解引用p指针时,它只会返回ivar的第一个字节。
现在,如果我们想移动到ivar的下一个字节,我们可以向char指针添加1:
// 第一个字节
*p;
// 第二个字节
*(p + 1);
// 第三个字节
*(p + 2);
// 危险的操作,前一个字节
*(p - 1);
看看下面的图表;它清楚地展示了我们如何访问ivar整数的字节:
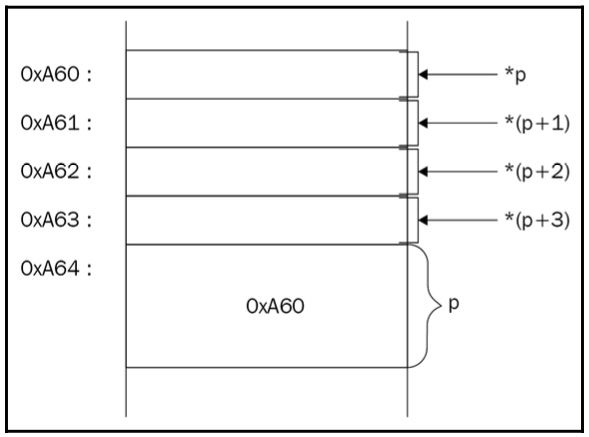
图 1.13 描述访问 ivar 整数的字节
如果你想读取第一个或最后两个字节,可以使用短指针:
short* sh = (short*)&ivar;
// 打印 ivar 的前两个字节的值
std::cout << *sh;
// 打印 ivar 的最后两个字节的值
std::cout << *(sh + 1);
注意
你应该小心指针运算,因为加上或减去一个数字会按照定义的数据类型大小移动指针。给一个 int 指针加 1 将会在实际地址上加上 sizeof(int) * 1。
那么指针的大小呢?如前所述,指针只是一个特殊的变量,它可以存储内存地址,并提供一个解引用运算符,返回位于该地址的数据。所以,如果指针只是一个变量,它也应该存在于内存中。我们可能会认为 char 指针的大小小于 int 指针的大小,仅仅因为 char 的大小小于 int。
但这里有个问题:存储在指针中的数据与指针指向的数据类型无关。无论是 char 还是 int 指针,都存储变量的地址,因此在定义指针大小时,我们应该考虑地址的大小。地址的大小由我们工作的系统定义。例如,在一个32位系统中,地址大小是32位长,在一个64位系统中,地址大小是64位长。这就导致了一个逻辑结论:不管指针指向什么类型的数据,指针的大小都是一样的:
std::cout << sizeof(ptr) << " = "
<< sizeof(pch) << " = " << sizeof(pd);
在32位系统中,它将输出 4 = 4 = 4;在64位系统中,输出 8 = 8 = 8。
栈和堆
内存由段组成,程序段在加载时分布在这些内存段中。这些是人为划分的内存地址范围,有助于操作系统更容易管理程序。二进制文件也被分为段,如代码和数据段。我们之前提到的代码和数据作为部分。部分是二进制文件的划分,这是链接器需要的,链接器使用这些部分来工作,并将为加载器准备的部分组合成段。
当我们从运行时的角度讨论二进制文件时,我们指的是段。数据段包含程序所需和使用的所有数据,代码段包含处理这些数据的实际指令。然而,当我们提到数据时,并不是指程序中使用的每一块数据。让我们看一个例子:
#include <iostream>
int max(int a, int b) { return a > b ? a : b; }
int main() {
std::cout << "11和22的最大值是:" <<
max(11, 22);
}
上述程序的代码段由 main() 和 max() 函数的指令组成,其中 main() 使用 cout 对象的 operator<< 打印消息,然后调用 max() 函数。那么数据段中有什么数据呢?它包含 max() 函数的 a 和 b 参数吗?事实证明,数据段中唯一包含的数据是字符串 “11和22的最大值是:”,以及其他静态、全局或常量数据。我们没有声明任何全局或静态变量,所以唯一的数据就是上述消息。
有趣的是 11 和 22 这两个值。它们是字面量,意味着它们没有地址;因此,它们不位于内存的任何位置。如果它们不位于任何地方,那么它们在程序中的唯一合理解释是它们位于代码段。它们是 max() 调用指令的一部分。
那么 max() 函数的 a 和 b 参数呢?这就涉及到负责存储具有自动存储期的变量的虚拟内存段——栈。如前所述,栈自动处理为局部变量和函数参数分配/释放内存空间。当调用 max() 函数时,a 和 b 参数将位于栈中。一般来说,如果说一个对象具有自动存储期,那么内存空间将在包围块的开始处被分配。因此,当函数被调用时,其参数被推入栈中:
int max(int a, int b) {
// 为 "a" 参数分配空间
// 为 "b" 参数分配空间
return a > b ? a : b;
// 释放 "a" 参数的空间
// 释放 "b" 参数的空间
}
当函数执行完毕后,自动分配的空间将在封闭代码块的末尾被释放。
人们说参数(或局部变量)被从栈中弹出。推入 和 弹出 是与栈相关的术语。你通过推入数据来向栈中插入数据,通过弹出数据来检索(并移除)栈中的数据。你可能遇到过术语 后进先出(LIFO)。这完美地描述了栈的推入和弹出操作。
当程序运行时,操作系统提供固定大小的栈。栈可以增长,如果增长到没有更多空间的程度,它会因为栈溢出而崩溃。
我们描述栈作为管理具有自动存储期变量的管理器。单词自动表明程序员不应该关心实际的内存分配和回收。只有在数据的大小或数据的集合预先已知的情况下,才能实现自动存储期。这样,编译器就知道函数参数和局部变量的数量和类型。到目前为止,这似乎已经足够好,但程序倾向于处理动态数据——未知大小的数据。我们将在 [第5章]中详细研究动态内存管理,内存管理和智能指针;现在,让我们来看一个简化的内存段图,了解堆是用来做什么的:

图 1.14:内存段的简化图
程序使用堆段来请求比之前需要的更多的内存空间。这是在运行时完成的,这意味着内存是在程序执行期间动态分配的。每当需要时,程序会向操作系统请求新的内存空间。操作系统不知道所需内存是用于整数、用户定义的 Point,还是用户定义的 Point 数组。程序通过传递它所需的字节数的实际大小来请求内存。例如,要请求 Point 类型对象的空间,可以使用 malloc() 函数,如下所示:
#include <cstdlib>
struct Point {
float x;
float y;
};
int main() {
std::malloc(sizeof(Point));
}
malloc() 函数分配 sizeof(Point) 字节的连续内存空间——假设是 8 字节。然后,它返回该内存的第一个字节的地址,因为这是提供对空间访问的唯一方式。重点是,malloc() 不知道我们是为 Point 对象还是 int 请求内存空间,它简单地返回 void*。void* 存储分配内存的第一个字节的地址,但绝对不能通过解引用指针来获取实际数据,因为 void 并没有定义数据的大小。请看下图;它显示 malloc 在堆上分配内存:
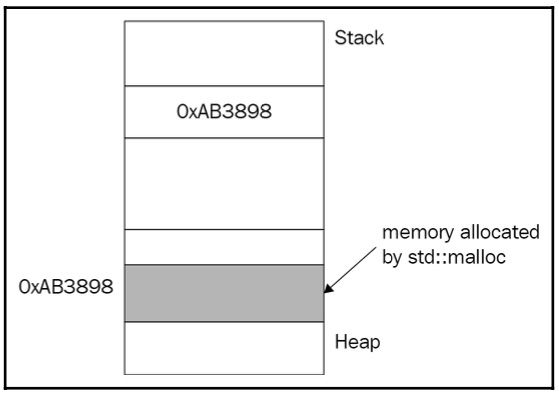
图 1.15:堆上的内存分配
要使用这块内存空间,我们需要将 void 指针转换为所需类型:
Point* p = static_cast<Point*>(std::malloc(sizeof(Point)));
C++ 通过 new 操作符解决了这个问题,它自动获取要分配的内存空间的大小,并将结果转换为所需类型:
Point* p = new Point;
控制流
很难想象一个不包含条件语句的程序。检查函数的输入参数以确保其安全执行几乎成了一种习惯。例如,divide() 函数接受两个参数,将一个除以另一个,并返回结果。显然,我们需要确保除数不为零:
int divide(int a, int b) {
if (b == 0) {
throw std::invalid_argument("除数为零");
}
return a / b;
}
条件语句是编程语言的核心;毕竟,程序是一系列动作和决策的集合。
前面的示例是故意过于简化的,以表达 if-else 语句的使用。然而,最让我们感兴趣的是这样一个条件语句的实现。当编译器遇到 if 语句时,它会生成什么?CPU 逐条顺序执行指令,而指令是执行确切一件事的简单命令。我们可以在 C++ 这样的高
面向对象编程的细节
C++ 支持面向对象编程(OOP),这是一种基于将实体分解为相互紧密交流的对象的范式。想象一下现实世界中的一个简单场景:你拿起遥控器换电视频道。在这个动作中,至少有三个不同的对象参与:遥控器、电视,以及最重要的,你自己。要使用编程语言表达这些现实世界中的对象及其关系,我们不一定非要使用类、类继承、抽象类、接口、虚拟函数等。这些特性和概念使设计和编码过程变得更加容易,因为它们允许我们优雅地表达和共享想法,但它们并不是强制性的。正如 C++ 的创造者 Bjarne Stroustrup 所说:“并不是每个程序都应该是面向对象的。” 为了理解 OOP 范式的高级概念和特性,我们将尝试探究幕后的原理。在本书中,我们将深入研究面向对象程序的设计。理解对象的本质及其关系,然后使用它们来设计面向对象的程序,是本书的目标之一。
大多数时候,我们处理的是在某个名称下分组的数据集合,从而形成了抽象。如果单独看待,像 is_military、speed 和 seats 这样的变量没有太多意义。但把它们组合在 Spaceship 这个名称下,我们对存储在变量中的数据的感知方式就发生了变化。我们现在提到的是许多变量作为一个单一对象打包在一起。为此,我们使用抽象;也就是说,我们从观察者的角度收集现实世界对象的各个属性。抽象是程序员工具链中的关键工具,因为它允许他们处理复杂性。C 语言引入了 struct 作为一种聚合数据的方式,如下代码所示:
struct Spaceship {
bool is_military;
int speed;
int seats;
};
数据分组对于 OOP 来说有些必要。每一组数据被称为一个对象。
C++ 尽最大努力支持与 C 语言的兼容性。虽然 C 结构体只是允许我们聚合数据的工具,但 C++ 使它们等同于类,允许它们拥有构造函数、虚拟函数、继承其他结构体等。struct 和 class 之间唯一的区别是默认的可见性修饰符:结构体是 public,而类是 private。通常使用结构体而不是类(或反之)没有什么区别。OOP 需要的不仅仅是数据聚合。为了充分理解 OOP,让我们找出如果我们只有提供数据聚合的简单结构体,我们将如何融入 OOP 范式。
电子商务市场(如亚马逊或阿里巴巴)的核心实体是 Product,我们以以下方式表示它:
struct Product {
std::string name;
double price;
int rating;
bool available;
};
如果有必要,我们将向 Product 添加更多成员。Product 类型对象的内存布局可以这样描绘:
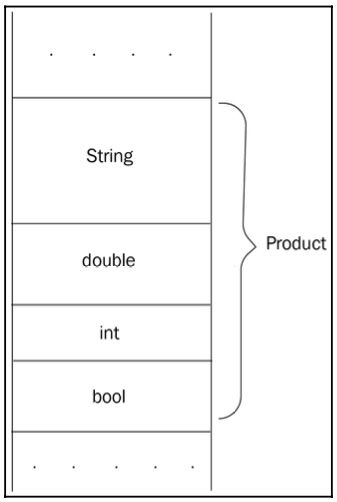
图 1.16:Product 对象的内存布局
声明一个 Product 对象在内存中占用 sizeof(Product) 的空间,而声明指向该对象的指针或引用只占用存储地址所需的空间(通常是 4 或 8 字节)。参见以下代码块:
Product book;
Product tshirt;
Product* ptr = &book;
Product& ref = tshirt;
我们可以如下图所示来描述上述代码:
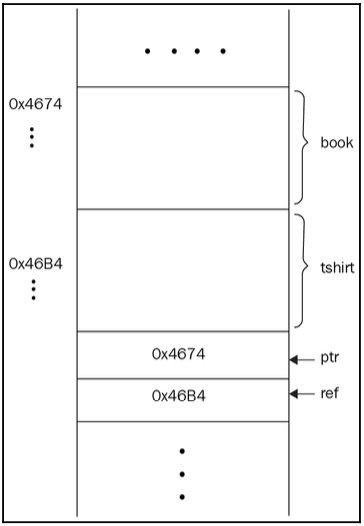
图 1.17:内存中的 Product 指针和 Product 引用的示意图
首先,让我们来看看 Product 对象在内存中占用的空间。我们可以通过计算其成员变量的大小之和来计算 Product 对象的大小。boolean 变量的大小是 1 字节。double 或 int 的确切大小在 C++ 标准中没有规定。在 64 位机器中,double 变量通常占用 8 字节,而 int 变量占用 4 字节。
std::string 的实现在标准中没有规定,因此其大小取决于库的实现。string 存储了指向字符数组的指针,但它可能还存储了分配字符的数量,以便在调用 size() 时有效返回。一些 std::string 的实现占用 8、24 或 32 字节的内存,但我们的示例中将坚持使用 24 字节。将它们相加,Product 的大小如下:
24 (std::string) + 8 (double) + 4 (int) + 1 (bool) = 37 字节。
打印 Product 的大小会输出不同的值:
std::cout << sizeof(Product);
它输出的是 40 而不是计算出的 37 字节。多出的字节是由于结构体的填充,这是编译器为了优化对对象各个成员的访问而采用的技术。中央处理单元(CPU)以固定大小的字为单位读取内存。字的大小由 CPU 定义(通常是 32 或 64 位)。如果数据从字对齐的地址开始,CPU 可以一次性访问数据。例如,Product 的 boolean 数据成员需要 1 字节的内存,可以放在评级成员之后。结果表明,编译器对数据进行了对齐,以便更快地访问。假设字的大小是 4 字节。这意味着,如果变量从一个可被 4 整除的地址开始,CPU 将能够无需多余步骤地访问该变量。编译器通过在结构体前面增加额外的字节来使成员对齐到字边界地址。
对象的高级细节
我们将对象视为表示抽象结果的实体。我们已经提到了观察者的角色——即定义对象的程序员,他们基于问题领域定义对象。程序员定义这一点代表了抽象的过程。以电子商务市场及其产品为例。两个不同的程序员团队可能对同一产品有不同的看法。实现网站的团队关心的是对网站访问者来说至关重要的对象属性:买家。我们之前在 Product 结构体中展示的属性主要是为网站访问者准备的,比如销售价格、产品评分等。实现网站的程序员接触问题领域,并验证定义 Product 对象所必需的属性。
实现帮助仓库管理产品的在线工具的团队关心的是产品放置、质量控制和运输方面的对象属性。这个团队不应关心产品的评分或甚至是价格。这个团队主要关心的是产品的重量、尺寸和条件。下图显示了感兴趣的属性:
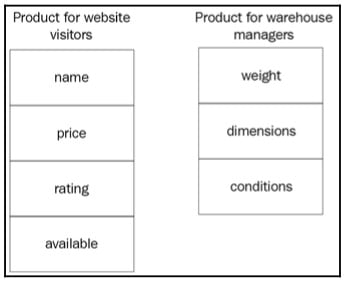
图 1.18:网站访问者和仓库管理员关注的属性
程序员在开始项目时应该做的第一件事是分析问题并收集需求。换句话说,他们应该熟悉问题领域并定义项目需求。分析过程导致定义对象及其类型,如我们之前讨论的Product。为了从分析中获得适当的结果,我们应该用对象的方式思考,用对象的方式思考意味着考虑对象的三个主要属性:状态、行为和标识。
每个对象都有一个状态,这个状态可能与其他对象的状态相同,也可能不同。我们已经介绍过代表物理(或数字)产品抽象的Product结构体。一个Product对象的所有成员共同代表了对象的状态。例如,Product包含诸如available这样的成员,它是一个布尔值;如果产品有库存,则等于true。成员变量的值定义了对象的状态。如果你给对象成员赋予新的值,它的状态将改变:
Product cpp_book; // 声明对象
...
// 改变对象cpp_book的状态
cpp_book.available = true;
cpp_book.rating = 5;
对象的状态是其所有属性和值的组合。
标识是区分一个对象和另一个对象的因素。即使我们尝试声明两个在物理上无法区分的对象,它们仍然会有不同的变量名——也就是说,不同的标识:
Product book1;
book1.rating = 4;
book1.name = "Book";
Product book2;
book2.rating = 4;
book2.name = "Book";
上例中的对象状态相同,但它们通过我们引用它们的名称——即book1和book2来区分。假设我们能以某种方式创建具有相同名称的对象,如下代码所示:
Product prod;
Product prod; // 不会编译,但还是"如果呢?"
如果是这种情况,它们在内存中的地址仍然会不同:

图 1.19:如果可能的话,存储具有相同名称的变量的内存片段的示意图
在前面的例子中,我们先后将 5 和 4 赋值给了 rating 成员变量。通过向对象赋予无效的值,我们可以很容易地造成意想不到的错误,比如这样:
cpp_book.rating = -12;
-12 在产品评分方面是无效的,如果允许这样的值,将会使用户感到困惑。我们可以通过提供设置器(setter)函数来控制对对象所做更改的行为:
void set_rating(Product* p, int r) {
if (r >= 1 && r <= 5) {
p->rating = r;
}
// 否则忽略
}
...
set_rating(&cpp_book, -12); // 不会改变状态
对象对其他对象的请求作出行动和反应。这些请求通过函数调用实现,这些函数调用又被称为消息:一个对象向另一个对象传递消息。在前面的例子中,传递相应set_rating消息给cpp_book对象的对象代表我们在其中调用set_rating()函数的对象。在这种情况下,我们假设我们从main()函数调用该函数,而它根本不代表任何对象。我们可以说它是全局对象,也就是操作main()函数的对象,尽管在 C++ 中并不存在这样的实体。
我们在概念上而不是物理上区分对象。这是以对象为思考方式的主要观点。OOP 某些概念的物理实现并未标准化,所以我们可以将Product结构体命名为类,并声称cpp_book是Product的实例,并且它有一个名为set_rating()的成员函数。C++的实现几乎做了同样的事情:它提供了语法上方便的结构(类、可见性修饰符、继承等)并将它们转换为简单的结构体和全局函数,如前面示例中的set_rating()。现在,让我们深入了解 C++ 对象模型的细节。
使用类工作
类在处理对象时使事情变得简单得多。它们在 OOP 中做最简单必要的事情:它们将数据和操作数据的函数结合起来。让我们用类及其强大的功能重写Product结构体的示例;
类声明看起来更加有组织,即使它暴露了比我们用来定义类似结构体的更多函数。以下是我们应该如何描述该类:

图 1.20:Product 类的 UML 图
前面的图形有些特别。如你所见,它有组织的部分、函数名前的符号等。这种图被称为统一建模语言(UML)类图。UML 是标准化类及其关系描绘过程的一种方式。第一部分是类的名称(以粗体显示),接下来是成员变量部分,然后是成员函数部分。函数名称前的 +(加号)表示该函数是公共的。成员变量通常是私有的,但如果需要强调这一点,可以使用 -(减号)符号。
初始化、销毁、复制和移动
如前所述,创建对象是一个两步过程:内存分配和初始化。内存分配是对象声明的结果。C++ 不关心变量的初始化;它分配内存(无论是自动还是手动的),然后就完成了。实际的初始化应由程序员完成,这就是为什么我们首先需要构造函数的原因。
析构函数也遵循同样的逻辑。如果我们跳过默认构造函数或析构函数的声明,编译器应该隐式地生成它们;如果它们为空,则会移除它们(以消除对空函数的冗余调用)。如果声明了任何带参数的构造函数,包括copy构造函数,编译器将不会生成默认构造函数。我们可以强制编译器隐式生成默认构造函数:
class Product {
public:
Product() = default;
// ...
};
我们也可以使用delete说明符来阻止编译器生成它,如下所示:
class Product {
public:
Product() = delete;
// ...
};
这将禁止默认初始化对象声明——也就是说,Product p;将无法编译。
对象在创建时初始化。销毁通常在对象不再可访问时发生。当对象在堆上分配时,后者可能会很棘手。看看下面的代码;它在不同的作用域和内存段声明了四个Product对象:
static Product global_prod; // #1
Product* foo() {
Product* heap_prod = new Product(); // #4 heap_prod->name
// = "Sample";
return heap_prod;
}
int main() {
Product stack_prod; // #2 if (true) {
Product tmp; // #3
tmp.rating = 3;
}
stack_prod.price = 4.2;
foo();
}
global_prod具有静态存储期限,放置在程序的全局/静态部分;它在main()被调用之前初始化。当main()开始时,stack_prod被分配在栈上,并将在main()结束时销毁(函数的闭合大括号被视为其结束)。尽管条件表达式看起来很奇怪和人为,但它是表达块作用域的好方法。
tmp对象也将被分配在栈上,但其存储期限限制在其声明的作用域内:当执行离开if块时,它将自动销毁。这就是为什么栈上的变量具有自动存储期限。最后,当调用foo()函数时,它声明了指针heap_prod,该指针指向在堆上分配的Product对象的地址。
前面的代码包含内存泄漏,因为heap_prod指针(本身具有自动存储期限)将在执行到达foo()的末尾时被销毁,而在堆上分配的对象不会受到影响。不要混淆指针和它指向的实际对象:指针只包含对象的地址,但它并不代表对象。
当函数结束时,其参数和局部变量的内存(分配在栈上)将被释放,但global_prod将在程序结束时被销毁——即在main()函数结束后。当对象即将被销毁时,将调用析构函数。
复制对象有两种类型:深度复制和浅度复制。语言允许我们通过复制构造函数和赋值运算符管理复制初始化和赋值对象。这对程序员来说是必要的功能,因为我们可以控制复制的语义。看看下面的例子:
Product p1;
Product p2;
p2.set_price(4.2);
p1 = p2; // p1 现在有相同的价格 Product p3 = p2;
// p3 有相同的价格
p1 = p2;这行是对赋值运算符的调用,而最后一行是对复制构造函数的调用。等号不应该让你对它是赋值还是复制构造函数调用感到困惑。每次你看到声明后跟赋值时,都应该将其视为复制构造。对于新的初始化语法(Product p3{p2};)也是如此。
编译器将生成以下代码:
Product p1;
Product p2;
Product_set_price(p2, 4.2);
operator=(p1, p2);
Product p3;
Product_copy_constructor(p3, p2);
代码中到处都有临时对象。大多数时候,它们是使代码按预期工作所必需的。例如,当我们将两个对象相加时,会创建一个临时对象来保存operator+的返回值:
Warehouse small;
Warehouse mid;
// ... some data inserted into the small and mid objects
Warehouse large{small + mid}; // operator+(small, mid)
让我们看看Warehouse对象的operator+()全局实现:
// considering declared as friend in the Warehouse class Warehouse operator+(const Warehouse& a, const Warehouse& b) {
Warehouse sum; // temporary
sum.size_ = a.size_ + b.size_;
sum.capacity_ = a.capacity_ + b.capacity_;
sum.products_ = new Product[sum.capacity_];
for (int ix = 0; ix < a.size_; ++ix) {
sum.products_[ix] = a.products_[ix];
}
for (int ix = 0; ix < b.size_; ++ix) {
sum.products_[a.size_ + ix] = b.products_[ix];
}
return sum;
}
前面的实现声明了一个临时对象,并在填充必要数据后返回它。前面示例中的调用可以转换为以下内容:
Warehouse small;
Warehouse mid;
// ... some data inserted into the small and mid objects
Warehouse tmp{operator+(small, mid)};
Warehouse large;
Warehouse_copy_constructor(large, tmp);
__destroy_temporary(tmp);
C++11 中引入的移动语义允许我们通过移动返回值到Warehouse对象来跳过临时创建。为此,我们应该为Warehouse声明一个移动构造函数,它可以区分*临时对象并有效地对待它们:
class Warehouse {
public:
Warehouse(); // 默认构造函数
Warehouse(const Warehouse&); // 复制构造函数 Warehouse(Warehouse&&); // 移动构造函数
// 省略代码以简洁
};
类关系
对象间通讯是面向对象系统的核心。关系是对象之间的逻辑链接。我们能够区分或者建立正确的对象类关系方式,定义了系统设计的整体性能和质量。考虑Product和Warehouse类;它们之间的关系被称为聚合,因为Warehouse包含产品——也就是说,Warehouse聚合了Product:
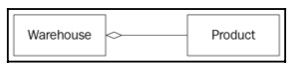
图 1.21:展示Warehouse和Product之间聚合关系的UML图
在纯粹的面向对象编程(OOP)中,有几种关系类型,如关联、聚合、组合、实例化、泛化等等。
聚合和组合
我们在Warehouse类的例子中遇到了聚合。Warehouse类存储了一个产品数组。更一般的说,它可以被称为关联,但为了强调确切的包含关系,我们使用聚合或组合这样的术语。在聚合的情况下,包含其他类实例或实例的类可以不含聚合体而实例化。这意味着我们可以创建并使用Warehouse对象,而不必要创建包含在Warehouse中的Product对象。聚合的另一个例子是Car和Person。Car对象可以包含一个Person对象(作为驾驶员或乘客),因为它们是相关联的,但包含关系不强。我们可以创建没有Driver对象的Car对象
强包含关系通过组合来表达。以Car为例,需要一个Engine类的对象才能构成完整的Car对象。在这个物理表示中,当创建Car对象时,Engine成员会自动创建。
以下是聚合和组合的UML表示:
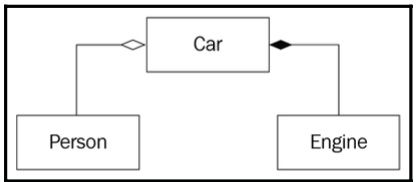
图 1.22:展示聚合和组合示例的UML图
在设计类时,我们必须决定它们之间的关系。定义两个类之间组合的最佳方式是has-a(有一个)关系测试。一个Car对象有一个Engine成员,因为车有引擎。任何时候你无法确定关系是否应该以组合的形式表达,问has-a问题。聚合和组合在某种程度上是相似的;它们只是描述连接的强度。对于聚合,适当的问题是can have a(可以有一个);例如,一个Car对象可以有一个Driver对象(Person类型);也就是说,包含关系是弱的。
继承
继承是一种允许我们重用类的编程概念。编程语言提供了继承的不同实现,但通常规则始终有效:类关系应该回答is-a(是一个)问题。例如,一个Car对象是一个Vehicle类,这允许我们将Car继承自Vehicle:
class Vehicle {
public:
void move();
};
class Car : public Vehicle { public: Car();
// ...
};
Car 现在具有从 Vehicle 派生的 move() 成员函数。继承本身代表泛化/特化关系,父类(Vehicle)是泛化,子类(Car)是特化。
只有在必要时,你才应该考虑使用继承。正如我们之前提到的,类应该满足 is-a(是一个)的关系,有时这可能有点棘手。