LLM - Transformer 的 Q/K/V 详解
目录
一.引言
二.传统 Q/K/V
三.Transformer Q/K/V
- Input Query
- Q/K/V 获取
- Q/K 相似度计算
- 注意力向量
- Multi Head
四.代码测试
- 初始化
- Attention
- Main
五.总结
一.引言
Transformer 的输入是我们的一个 query 句子,例如 "我爱中国",但是 Transformer 处理时却 1 生 3 得到了 Q/K/V,下面我们从传统机器学习和 Transformer 两个角度看一下 Q/K/V 从哪里来,去哪里去。
二.传统 Q/K/V
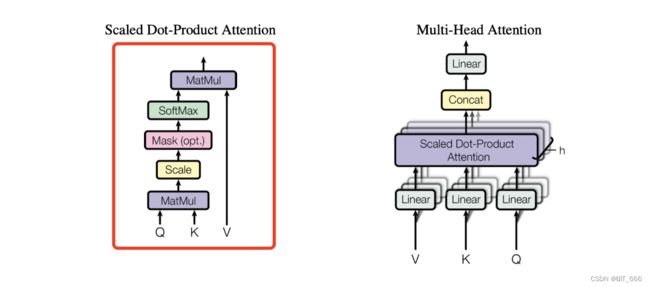
对于传统机器学习的 Attention 而言,Q/K 分别代表 Query 和 Keys 即我们候选物品与另一个物品的向量,通过 matmul(Q,K) 即可计算二者的相似度,最后 softmax 归一化乘上 valuse 即可得到。MatMul 后的 Scala 是除以当前 sqrt(dim) 的缩放操作,防止乘积结果太大。
最常见的就是电商场景,例如我们浏览了一件羽绒服,这个就是我们的 Q,而我们历史浏览过多个商品例如鞋子、包包、大衣,这些都是 K,通过 matmul(Q,K) 可以计算出羽绒服与我们浏览的 N 个商品每个商品的相似度,归一化后的值有大有小,从而代表当前商品 K 对 Q 向量的贡献度衡量,进行加权求和即可得到候选集 Q 在浏览记录 K 下的注意力向量表征。

三.Transformer Q/K/V
Transformer 场景下,我们的输入只有 text = "我爱中国",此时不存在上面类似候选商品 Q 和历史浏览商品 K 的关系,怎门办,也好办,Q/K 都是自己就可以,也就是 Self-Attention,下面我们看下如何操作。
- Input Query
对于给定的句子 text,其长度为 L,以 "我想吃酸菜鱼" 为例,其 seq_len = 6, dim = [L x 768]

这里我们可以构建 Embedding 层,将 text 使用 Tokenizer 分词后,得到其对应的 Embedding 表征。除此之外,我们定义 Attention Module,同时根据传入的 Head 数计算拆分后的 head_dim。
class BitDDDAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(BitDDDAttention, self).__init__()
self.embed_dim = embed_dim # embedding 维度
self.num_heads = num_heads # head 数量
assert embed_dim % num_heads == 0
self.head_dim = embed_dim // num_heads
# 构建 Q/K/V 向量以及最后的全连接 MLP
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.fc_out = nn.Linear(embed_dim, embed_dim)- Q/K/V 获取
这里 Q/K/V 都是通过一层 Linear 映射得到的,torch 的话就是 nn.Linear,映射后的 Q/K/V 维度不变,依然是 L x 768:
def forward(self, x):
batch_size, seq_len, _ = x.size()
# Split the embedding into num_heads and reshape to (batch_size, num_heads, seq_len, head_dim)
query = self.query(x).view(batch_size, seq_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
key = self.key(x).view(batch_size, seq_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
value = self.value(x).view(batch_size, seq_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)初始化 Q/K/V 的转换 Linear 矩阵,并根据 head_num 与 head_dim 转换,转换后的维度为:
(bsz, num_heads, seq_len, head_dim)
- Q/K 相似度计算
![]()
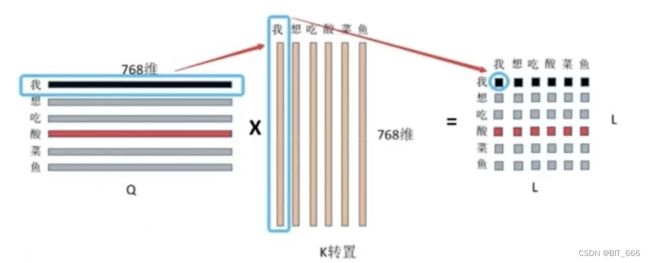
相似度计算考虑如上 Scale-Dot-Attention 公式,Q 的维度为 L x 768,K 转置后为 768 x L,二者 MatMul 得到 L x L 的方阵,其中 (0,0) 位置代表 "我想吃酸菜鱼" 中 "我" 对 V 中 "我" 字向量的注意力权重,以此类推,整个结果表示 "我想吃酸菜鱼" 中每个字对其他字的注意力,当然也包括自己,所以这种操作也被称为自注意力。
# Compute the attention scores
attention_scores = torch.matmul(query, key.permute(0, 1, 3, 2)) / self.head_dim ** 0.5
attention_probs = torch.softmax(attention_scores, dim=-1)Q Dim: (bsz, num_heads, seq_len, head_dim)
K.T Dim: (bsz, num_heads, head_dim, seq_len)
相乘后得到 (bsz, num_heads, seq_len, seq_len) 的注意力权重。
Tips:
这里做了除以 sqrt(dim) 的操作,主要是为了缩小点积范围,确保 softmax 梯度稳定性,而为什么需要做 softmax 一是为了保证权重的非负性,同时增加非线性操作。第 row 行归一化的权重,就是第 row 个元素对其他元素的注意力权重。
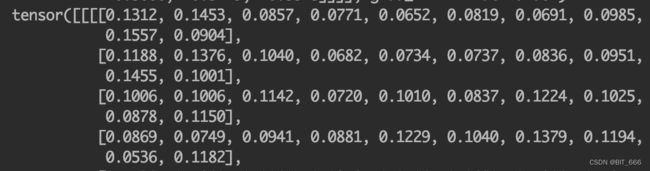
- 注意力向量
经过 softmax 后的 LxL 的注意力权重矩阵分别与 LxDim 的 Value 相乘,最终得到自注意力后的矩阵。第一行代表 "我" 对 "我想吃酸菜鱼" 中每个注意力权重在 "我" 向量上的加权平均结果,以此类推,最后得到 seq_len 即 L 个加权平均的表征。
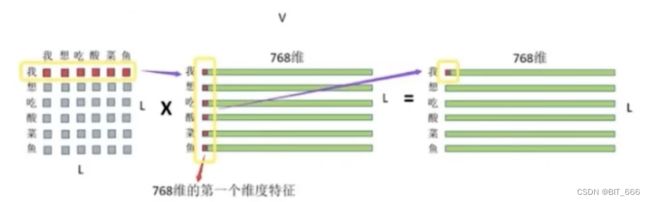
attention_output = torch.matmul(attention_probs, value)
.permute(0, 2, 1, 3)
.contiguous()
.view(batch_size, seq_len, self.embed_dim) 计算后通过 view 将多个 head 的向量合并,恢复为原始的 embed_dim,此时维度依然为
(bsz, seq_len, head_num x head_dim)
- Multi Head

实践场景中很多都使用 multi-head Attention 即多头注意力,我们可以理解为把原始向量进行拆分,将其多个部分分别进行上面的 Attention 操作。比如还是 "我想吃酸菜鱼",我们得到的 Q/K/V 都是 L x 768 维,此时令 head = 4,则 L x 768 会切分为 4 份 L x 192,分别将 L x 192 做 Self-Attention 后再 Concat,即可再次得到 L x 768。Multi-Head 的思想意在学习向量不同位置对语义的不同表征。
四.代码测试
- 初始化
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
from transformers import BertModel, BertTokenizer
class BitDDDAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(BitDDDAttention, self).__init__()
self.embed_dim = embed_dim # embedding 维度
self.num_heads = num_heads # head 数量
assert embed_dim % num_heads == 0
self.head_dim = embed_dim // num_heads
# 构建 Q/K/V 向量以及最后的全连接 MLP
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.fc_out = nn.Linear(embed_dim, embed_dim)定义 head_num、head_dim 以及 Q/K/V 的 Linear 线性层。
- Attention
def forward(self, x):
batch_size, seq_len, _ = x.size()
# Split the embedding into num_heads and reshape to (batch_size, num_heads, seq_len, head_dim)
query = self.query(x).view(batch_size, seq_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
key = self.key(x).view(batch_size, seq_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
value = self.value(x).view(batch_size, seq_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)
# Compute the attention scores
attention_scores = torch.matmul(query, key.permute(0, 1, 3, 2)) / self.head_dim ** 0.5
attention_probs = torch.softmax(attention_scores, dim=-1)
# Apply the attention weights to the value
attention_output = torch.matmul(attention_probs, value).permute(0, 2, 1, 3).contiguous().view(batch_size,
seq_len,
self.embed_dim)
# Apply a linear layer to the output
x = self.fc_out(attention_output)
return x执行 Scale-Dot-Attention,Multi-Head 可以看作是分开做了多个 Self-Attention。
- Main
if __name__ == '__main__':
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
pretrained_bert = BertModel.from_pretrained('bert-base-uncased')
input_texts = ["This is a test sentence.", "Here is another test sentence."]
input_ids = [tokenizer.encode(text, add_special_tokens=True, max_length=10, padding='max_length', truncation=True,
return_tensors='pt') for text in input_texts]
input_ids = torch.cat(input_ids, dim=0) # Concatenate and add batch dimension
with torch.no_grad():
embedded_output = pretrained_bert(input_ids)[0] # Get the output of the BERT model
print(embedded_output.size()) # Output shape should be (2, 10, embedding_dim)
embed_dim = embedded_output.size(-1)
num_heads = 4
model = BitDDDAttention(embed_dim, num_heads)
output = model(embedded_output)
print(output.size()) # Output shape should be (2, 10, embed_dim)输入两条样本,batch 为 2,seq_len 为 10,最终调用 Attention 进行 forward 即可得到一次 Attention 的结果,维度为: torch.Size([2, 10, 768])。
五.总结
本节内容基于 Torch 实现了 MultiHeadAttention,由于 Q/K/V 都是来自于同一句话,故其名为自注意力即 Self-Attention,如果想要类似推荐算法中的不同商品比较,则 Q 是一句话,KV 换成另一句话即可。这里有一点需要注意,我们在 K/V 中调整任意两个字的位置,其对最终的计算没有影响,即在注意力机制中是没有位置信息的,这也是为什么 LLM 要引入 Position Embedding 的原因。