深度学习知识学习笔记
一 相关的深度学习基础知识
(1)线性回归
设房屋的⾯积为 x 1 x_1 x1 ,房龄为 x 2 x_2 x2 ,售出价格为 y y y 。我们需要建⽴基于输⼊ x 1 x_1 x1 和 x 2 x_2 x2来计算输出 的表达式, y y y也就是模型(model)。顾名思义,线性回归假设输出与各个输⼊之间是线性关系:
y = w 1 x 1 + w 2 x 2 + b y=w_1x_1+w_2x_2+b y=w1x1+w2x2+b
在模型训练中,我们需要衡量价格预测值与真实值之间的误差。通常我们会选取⼀个⾮负数作为误差,且数值越小表示误差越小。这就是机器学习问题当中Loss函数的定义,在线性回归当中我们使用的Loss函数如下( n n n为训练样本个数):
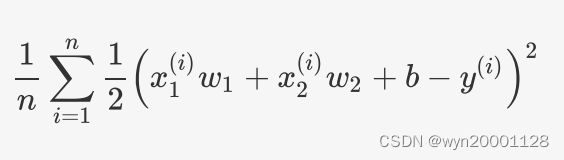
⼤多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。在求数值解的优化算法中,⼩批量随机梯度下降是一个不错的方法,下面是线性回归当中使用小批量随机梯度下降的参数方法:
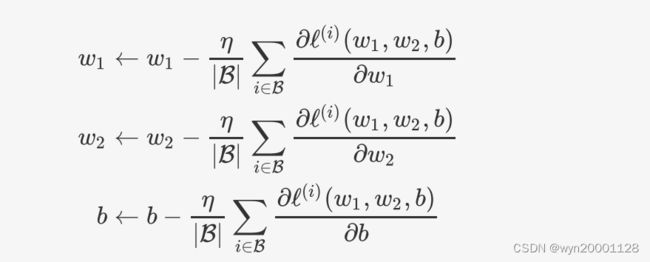
概括来说就是每一个batch的样本都可以同果链式求导法则对每一个模型的参数 ( w 1 , w 2 , b ) (w_1 ,w_2,b) (w1,w2,b)求出一个梯度 Δ w i = ( Δ w 1 i , Δ w 2 i , Δ b i ) \Delta w_i=(\Delta w_{1i} ,\Delta w_{2i},\Delta b_{i}) Δwi=(Δw1i,Δw2i,Δbi),而后模型参数的增量就是一个batch的所有的样本的 Δ w \Delta w Δw的平均值的负数,如下所示:
Δ w = − η ∣ β ∣ ∑ i ∈ β Δ w i , 其 中 η 为 学 习 率 \Delta w=-\frac{\eta}{|\beta|}\sum_{i \in \beta }\Delta w_i,其中\eta为学习率 Δw=−∣β∣ηi∈β∑Δwi,其中η为学习率
(2)SOFTMAX回归模型
softmax回归跟线性回归⼀样将输⼊特征与权重做线性叠加。与线性回归的⼀个主要不同在于,softmax回归的输出值个数等于标签⾥的类别数。如果我们的任务当中的类别数量为3,那么输出就是三维,如下所示:
我们在这里一般将 o i o_i oi定义为模型认定输入类别为 i i i的置信度。五哦一我们将值最⼤的输出所对应的类作为预测输出。此外,为了让模型的输出满足一个合法且合理的概率分布。理想状态一个输出类别为3的预测向量为 ( 0 , 0 , 1 ) (0,0,1) (0,0,1),softmax运算会输出层的3个数值做以下操作使得输出概率的和为1。
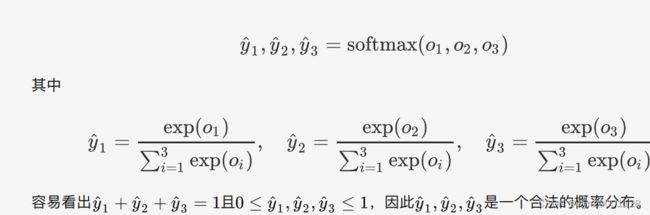
在这一个运算当中我们可以像线性回归那样使⽤平⽅损失函数 :
L o s s = ∑ i = 1 n 1 2 ∣ ∣ 预 测 向 量 i − 真 实 向 量 i ∣ ∣ 2 Loss=\sum_{i=1}^n \frac{1}{2}||预测向量_i-真实向量_i||^2 Loss=i=1∑n21∣∣预测向量i−真实向量i∣∣2
然⽽,想要预测分类结果正确,我们其实并不需要预测概率完全等于标签概率,我们只需要正确分类的那个分类概率尽可能大就行。对于次需求,我们打算采用以下的名为交叉熵损失函数的东西:(只有正确分类的 y ^ j \hat y_j y^j才为1,所以训练的时候只关注正确分类的那个分类概率)
![]()
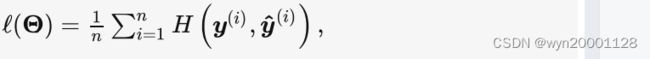
(3)多层感知机
上文中提到的线性回归和softmax回归都是单层的神经网络。我们将其拓展为多层:

上面的变换过程都是线性变换,为了增加模型的拟合能力我们加入非线性变换也就是损失函数。所以我么定义上的多层感知机的定义就是:多层感知机就是含有⾄少⼀个隐藏层的由全连接层组成的神经⽹络。输入,隐藏层,输出之间的连接方式都是全连接层,其中数据通过隐藏层节点的时候都要经过激活函数来进行非线性映射。:
( 1 ) H = W X + b ( 2 ) H n e w = f ( H ) (1)H=WX+b \\(2)H_{new}=f(H) (1)H=WX+b(2)Hnew=f(H)
(4)两个常见的处理过拟合的方法
①正则化(直接在损失函数出加大w的比重)
正则化通过为模型损失函数添加 L 2 L_2 L2惩罚项使学出的模型参数值较小。公式如下:
L o s s ( w ) + ∣ ∣ w ∣ ∣ 2 Loss(w)+||w||^2 Loss(w)+∣∣w∣∣2
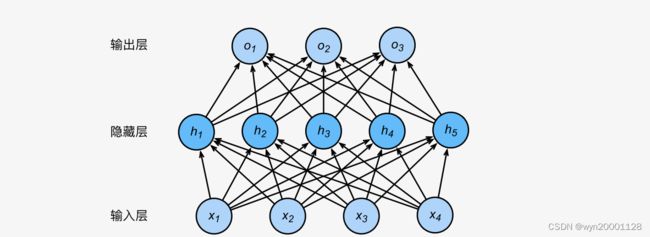
②Dropout(让模型无法过度依赖某个节点,不会过拟合)

以上图为例,我们设置一个参数 p p p,使得隐藏层节点 h 1 到 h 5 h_1到h_5 h1到h5每一个节点都有一定的概率被丢弃。使用Dropout要更新隐藏层的输入 h i h_i hi,公式如下:
h ^ i = 1 1 − p h i \hat h_i=\frac{1}{1-p}h_i h^i=1−p1hi
这样使得网络输入的期望不变。如果 h 2 和 h 5 h_2和h_5 h2和h5被丢弃了以后(如图所示):
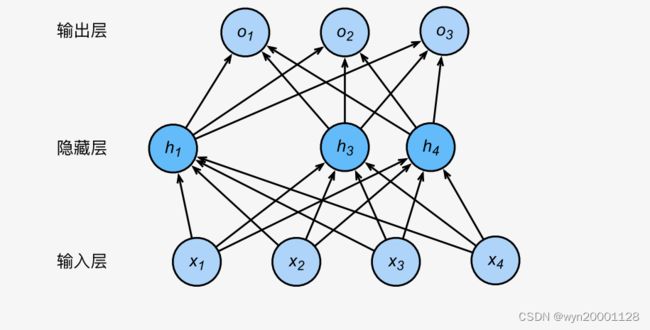
输出值的计算不再依赖 h 2 和 h 5 h_2和h_5 h2和h5,在反向传播时, h 2 和 h 5 h_2和h_5 h2和h5的梯度均为0。在每一次迭代的过程中,隐藏层神经元的丢弃是随机的,即所有的隐藏层节点都有可能被丢弃,输出层的计算⽆法过度依赖隐藏层中的某个节点,所以训练模型时起到正则化的效果。
(5)反向传播过程
以图中的多层感知机为例子:

我们在输进去输出 X X X以后根据正向传播的计算图可以从输入层到输出层,并且可以知道在损失函数的计算过程中涉及到了网络架构里面的每一个参数,因此通过损失函数(可视作一个多元函数)可以通过链式求导求出所有参数 W W W的梯度
Δ W = ( Δ w 1 , Δ w 2 . . . . . . , Δ w n , Δ b 1 , Δ b 2 . . . . . . , Δ b n ) \Delta W=(\Delta w_1,\Delta w_2......,\Delta w_n,\Delta b_1,\Delta b_2......,\Delta b_n) ΔW=(Δw1,Δw2......,Δwn,Δb1,Δb2......,Δbn)
然后我们就可以用这些梯度去更新参数 W W W,使得整个验证集的损失值下降(验证集上的损失值是考核网络性能的一个标准)。
二 卷积神经网络
(1)二维卷积层
⼆维卷积层中,⼀个⼆维输⼊数组和⼀个⼆维核(kernel)数组通过互相关运算输出⼀个⼆维数组。 我们⽤⼀个具体例⼦来解释⼆维互相关运算的含义。如下图所示:
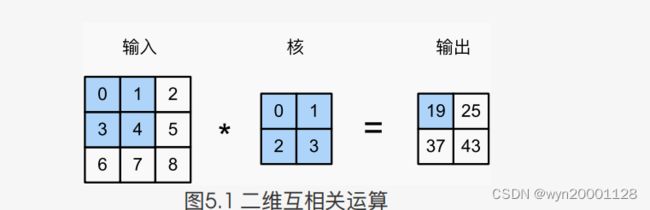
⼆维卷积层将输⼊和卷积核做互相关运算,并加上⼀个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。定义的代码如下:
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
#随机初始化卷积核参数权重w
self.bias = nn.Parameter(torch.randn(1))#初始化bias
def forward(self, x):
return corr2d(x, self.weight) + self.bias#卷积核的计算
卷积核的一个经典应用就是边缘检测:例如一张照片为下面矩阵,
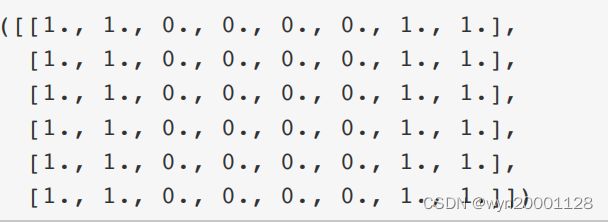
很容易看出来第3列和倒数第2列左右是边界,用一个维数为 1 ∗ 2 1*2 1∗2的卷积核 [ 1 , − 1. ] [1,-1.] [1,−1.]来对这个矩阵进行二维互运算得到的结果是:

经过卷积核运算以后”边缘“这一特征在新的映射空间里面更好地表达了出来。由此,我们可以看出,卷积层可通过重复复使用卷积核有效地表征局部空间。 可以理解为是一个特征抽取的过程。
卷积层的模型参数 w e i g h t weight weight和 b i a s bias bias是可以通过反向传播来更新的,下面代码所示:
for i in range(step):
#前项传播
Y_hat = conv2d(X)
l = ((Y_hat - Y) ** 2).sum()
#反项求导
l.backward()
# 梯度下降
conv2d.weight.data -= lr * conv2d.weight.grad
conv2d.bias.data -= lr * conv2d.bias.grad
# 梯度清0
conv2d.weight.grad.fill_(0)
conv2d.bias.grad.fill_(0)
输出为与开始的卷积核的数值定义相似,可见我们可以通过数据来学习卷积核的参数

二维卷积运算可以理解为是一种特征映射。⼆维卷积层输出的⼆维数组(图中的 2 ∗ 2 2*2 2∗2数组)可以看作是输⼊(输入的 3 ∗ 3 3*3 3∗3数组)在空间维度(宽和⾼)上某⼀级的特征映射,也叫特征图(feature map)。其中feature map中的 “ 19 ” “19” “19”的感受域就是输入的阴影部分。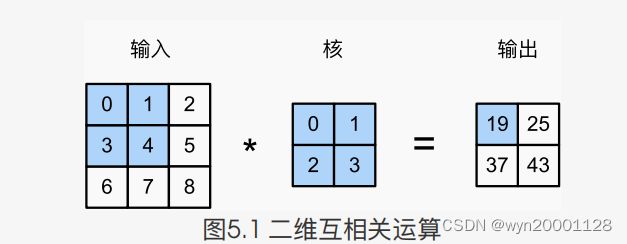
下面是pytorch的官方文档,卷积层的输入应当包括4个维数:
(1) N N N:一个 b a t c h batch batch所包含的样本数的多少
(2) C C C:输入的通道数
(3) H H H:输入的一个通道的 H e i g h t Height Height
(3) H H H:输入的一个通道的 H e i g h t Height Height

(2)填充和步幅
输⼊形状是 a ∗ b a*b a∗b,卷积核窗⼝形状是 c ∗ d c*d c∗d ,那么输出形状将会是
( a − c + 1 ) ∗ ( b − d + 1 ) (a-c+1)*(b-d+1) (a−c+1)∗(b−d+1)
所以卷积层的输出形状由输⼊形状和卷积核窗⼝形状决定。本节我们将介绍卷积层的两个超参数,即填充和步幅。填充可以增加输出的高和宽,这常⽤来使输出与输⼊具有相同的高和宽。步幅可以减⼩输出的高和宽
①padding(填充)
填充(padding)是指在输⼊⾼和宽的两侧填充元素(通常是0元素)。这样使得输入和输出的尺寸是一样的。以上面的公式为例,假若我们填充 e e e行, f f f列,则卷积过后的输出的维度为:
( a − c + 1 + e ) ∗ ( b − d + 1 + f ) (a-c+1+e)*(b-d+1+f) (a−c+1+e)∗(b−d+1+f)
显然如果要尺寸不变,则显然 e = c − 1 e=c-1 e=c−1, f = d − 1 f=d-1 f=d−1,具体过程如下图所示:

②步幅
⽬前我们看到的例⼦⾥,在⾼和宽两个⽅向上步幅均为1。我们也可以使⽤更⼤步幅。下面就是高和宽上步幅分别为3和2的⼆维互相关运算。步幅可以减⼩输出的⾼和宽,例如输出的⾼和宽仅为输⼊的⾼和宽的 1 n \frac{1}{n} n1)。
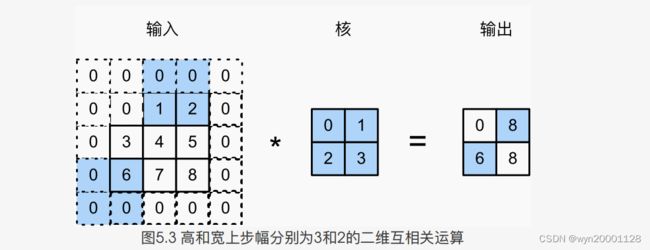
(3)多输入通道和多输出通道
前⾯输⼊和输出都是⼆维数组,但真实数据的维度经常更高。例如,彩⾊图像在高和宽2个维度外还有RGB(红、绿、蓝)3个颜⾊通道。假设彩色图像的⾼和宽分别是 h h h和 w w w(像素),那么它可以表示为⼀个 3 ∗ h ∗ w 3*h*w 3∗h∗w的多维数组。当输入不是一个二维数组且是多通道的时候,那么我么也需要一个多通道的卷积核。例如在上述例子中如果输入的通道数为 a ∗ b ∗ w a*b*w a∗b∗w,则我们所要的卷积核为 c ∗ d ∗ w c*d*w c∗d∗w。如下图所示
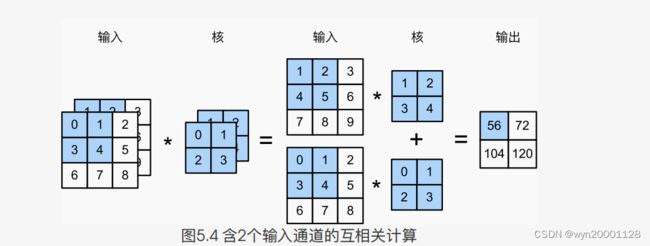
当输⼊通道有多个时,因为我们对各个通道的结果做了累加,所以不论输⼊通道数是多少,输出通道数。总是为1。如果我们需要一个输出通道为 y y y的输出的话,那么我们可以为每个输出通道都创建形状为 c ∗ d ∗ w c*d*w c∗d∗w 的卷积,然后把 y y y个卷积的输出拼接起来就可以了,也就是说我们创造了一个 y ∗ c ∗ d ∗ w y*c*d*w y∗c∗d∗w 的联合卷积核。
(4)池化(池化层也有padding和stride之分)
同卷积层⼀样,池化层每次对输⼊数据的⼀个固定形状窗⼝(⼜称池化窗⼝)中的元素计算输出。不同于卷积层⾥计算输⼊和核的互相关性,池化层直接计算池化窗⼝内元素的最⼤值或者平均值。该运算也分别叫做最⼤池化或平均池化。运算的进行方式和卷积运算差不多,具体的运算过程如下:

上一幅图演示的是最大池化的过程,还有均值池化。对于多通道输入,池化操作不用像卷积操作一样,池化层对每个输⼊通道分别池化,而不是像卷积层那样将各通道的输入按通道相加。和卷积层一样,池化层也有填充和步幅之分
(5)LeNet
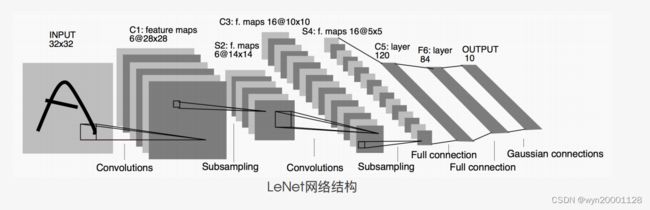
subsampling就是池化操作代码如下:(卷积层和全连接层)
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 6, 5), # in_channels, out_channels,kernel_size
nn.Sigmoid(),
nn.MaxPool2d(2, 2), # kernel_size, stride
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
(6)批量归⼀化:利用一个 b a t c h batch batch上在某个中间网络层(可以是某个卷积层,也可以是某个全连接层)上面的输出的均值和标准差调整对应中间网络层的中间输出。这样可以减少靠近输出层输出的不稳定性。
我们在进行机器学习任务的时候一般都会把数据集的特征进行归一化,这样可以训练出一个稳定的模型。但是现在随着网络深度的叠加,就算一开始把特征进行归一化之后,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。
在模型训练时,批量归⼀化利用一个 b a t c h batch batch上在某个层(可以是某个卷积层,也可以是某个全连接层)上面的输出的均值和标准差,不断调整神经⽹络中间输出,从⽽使整个神经⽹络在各层的中间输出的数值更稳定。下面就是几个例子:
对全连接层做批量归⼀化
通常,我们将批量归⼀化层置于全连接层中的仿射变换和激活函数之间。全连接层在进行激活函数映射之前的表达式为 X X X,其中
X = x 1 , x 2 , x 3 , . . . . . x n , 其 中 n 为 b a t c h β 的 样 本 数 大 小 X=x_1,x_2,x_3,.....x_n,其中n为batch \beta的样本数大小 X=x1,x2,x3,.....xn,其中n为batchβ的样本数大小
对小批量 X X X求均值和 u u u⽅差 σ \sigma σ,而后每一个 x i x_i xi做如下变换:
x ^ i = x i − u σ 2 + ϵ \hat x_i=\frac{x_i-u}{\sqrt{\sigma^2+\epsilon}} x^i=σ2+ϵxi−u

(7)Resnet
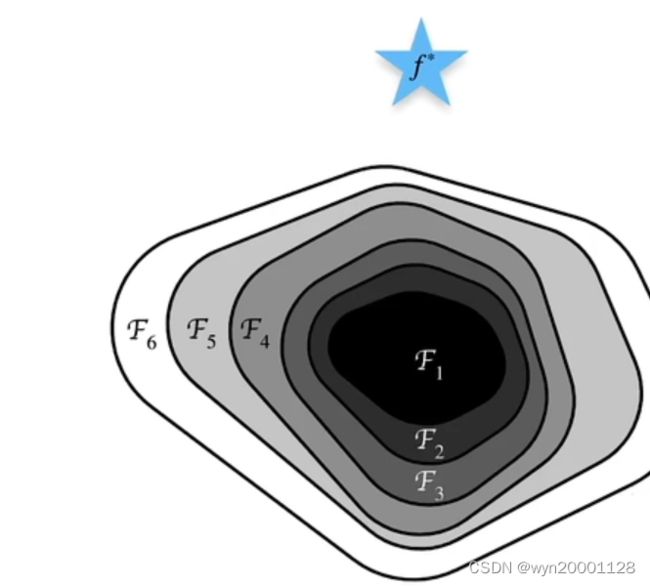
网络结构设置得越深,网络道德拟合范围数据虽然变大,但是不一定就取得很好得效果,如下面得图所示:
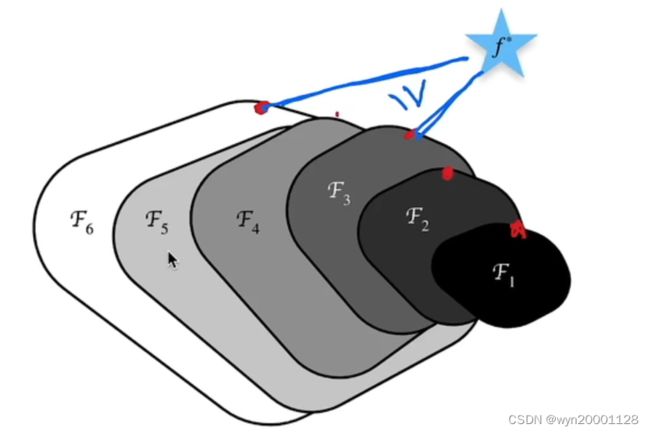
χ 6 \chi6 χ6虽然 χ 3 \chi3 χ3得基础上叠加了许多得模型,但是它离最优解反而变远了。所以一味堆叠网络并不一定可以得到最优解,因为大神们提出了Resnet,我们先看看Resnet与普通网络的区别: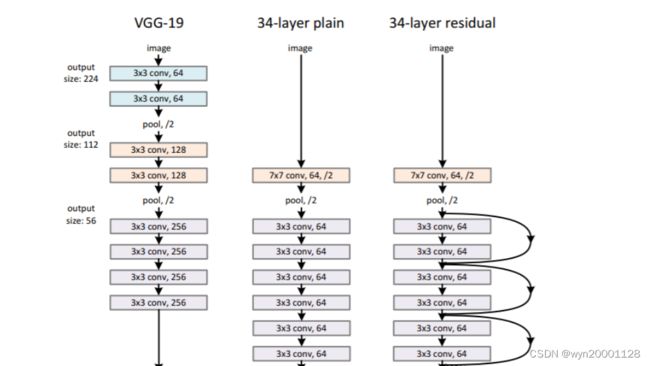
细致一点就是下面这张图:
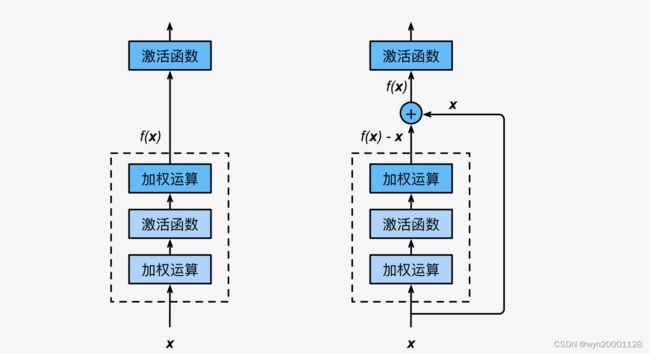
其实很简丹,就是在引进下一个网络部分之后把前面网络输出的部分加过去了而已,下面是正常堆叠网络的架构和搜索的图:(我们假设上面的 x x x是 i n p u t input input经过 f ( x ) f(x) f(x)之后才变成的,虚线框起来的映射为 g ( x ) g(x) g(x),如果按照正常网络堆叠的方式组织网络,那么解空间的搜索过程可能是像下面的图形:反而取不到很好的效果。
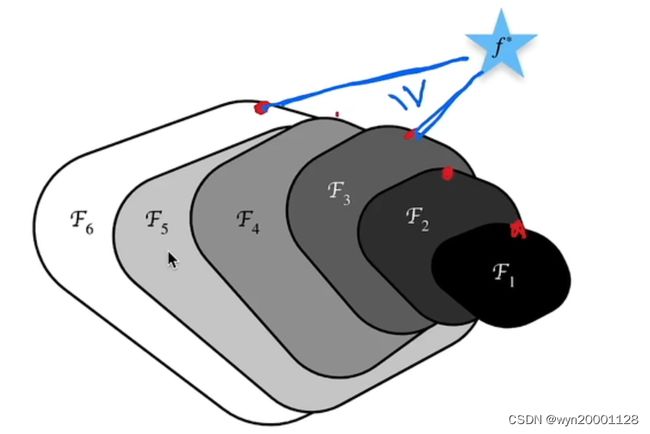
相反的是如果采样Renet的方法组织网络,我们的解的搜索空间的过程就会向下面一样:
我们可以发现随着网络的加深,解的搜索空间在保留了原先取得得成功得基础上不断靠近最优解。这种方法就是在保留成功得基础上一点一点向外拓展。这种搜索得方法是合理的。
三 深度学习的时序模型
(1)RNN(多层感知机加隐藏层而已)
以多层感知机为例子,RNN网络和平常的神经网络的最大的区别就是RNN网络隐藏层的在时间步 t t t输出 h t h_t ht和隐藏层在时间步 t − 1 t-1 t−1的输出 h t − 1 h_{t-1} ht−1也有关,具体的表现如下图:
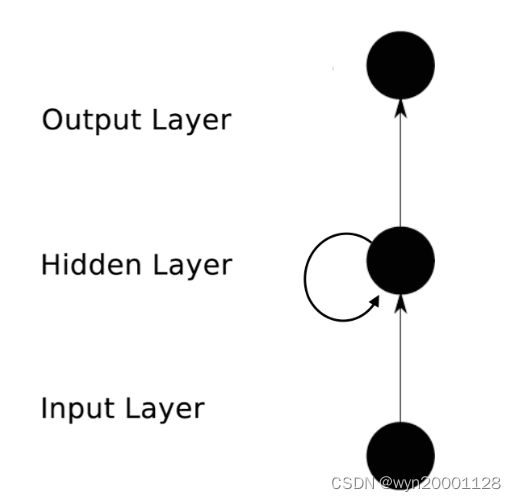
普通的多层感知机的隐藏层输出的公式是
H = ϕ ( W I H X + b ) H=\phi(W_{IH}X+b) H=ϕ(WIHX+b)
带有时间步的RNN的公式是
H t = ϕ ( W I H X t + W t i m e H t − 1 + b ) H_t=\phi(W_{IH}X_t+W_{time}H_{t-1}+b) Ht=ϕ(WIHXt+WtimeHt−1+b)
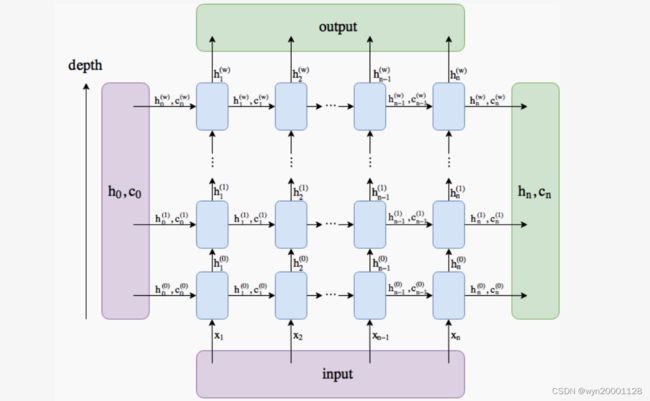
网络在时间步 t t t的输出是隐藏状态的输出 h t h_t ht,所有时间步的总输出就是这个网络的输出。如下图:(这个图是LSTM,所有的RNN类网络都是这样的)
RNN在时间步 t t t的损失函数表示为 L o s s ( o t , h t ) Loss(o_t,h_t) Loss(ot,ht),则时间步为T的样本的损失函数为:
L o s s = 1 T ∑ t = 1 T L o s s ( o t , h t ) Loss=\frac{1}T{}\sum_{t=1}^{T}Loss(o_t,h_t) Loss=T1t=1∑TLoss(ot,ht)
公式的计算图如下:
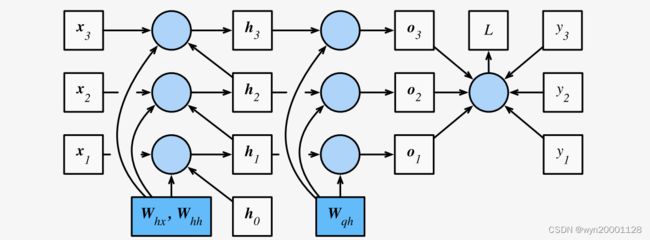
从公式的计算图我们可以知道从损失函数 L L L到矩阵 W h x W_{hx} Whx有很多条路径,而最终反向传播的梯度和就是所有路径的梯度加起来。且当 T T T很差的时候也会出现很多路径,则我们可以知道时间步 T T T太多RNN模型很容易发生梯度爆炸和梯度衰减。
从上述过程我们可以看出从普通的多层感知机到RNN只是认为训练过程当中 b a t c h batch batch与 b a t c h batch batch之间有关系。所以RNN模型很适用于“”上下文“有关的任务,如预测文章的下一句话,下一个词等等。后面的GRU,LSTM都是这样的原理,只不过在隐藏层加入了更加复杂的结构让网络的拟合能力变得更好而已