java学习-day05
个人曾经学习java的一些记录,仅供参考
java学习-day05
- 常用系统
-
- 包装类(每个基本数据类型都对应着一个包装类)
- String\StringBuilder\StringBuffer
-
- 字符串常量池
- 字符串的比较
- 字符串常用API
- 输入输出
- Math
- Date
- Random
- javabean
- 泛型
- 集合
-
- List
-
- ArrayList
- LinkedList
- Vector
- Set
-
- hashet
- TreeSet
- Map
-
- HashMap
- TreeSet
- 比较器
- Collections
- 数据结构
常用系统
包装类(每个基本数据类型都对应着一个包装类)
String\StringBuilder\StringBuffer
public class Test {
public static void main(String[] args) {
/*
String str = "ABC";
//返回一个新的字符串
String str1 = str+"ABC";
System.out.println(str);//ABC
System.out.println(str1);//ABCABC
//返回一个新的字符串
String str2 = str.concat("ABC");
//通过concat方法进行拼接后原来的字符串并没有改变
System.out.println(str2);//ABCABC
System.out.println(str);//ABC
*/
/*
StringBuffer sbf = new StringBuffer("ABC");
System.out.println(sbf);
StringBuffer sbf1 = sbf.append("ABC");
System.out.println(sbf1);
// 通过append方法进行字符串拼接后 sbf 也改变了
System.out.println(sbf);
*/
StringBuilder sbd = new StringBuilder("ABC");
StringBuilder sbd1 = sbd.append("ABC");
System.out.println(sbd1);
//通过append的拼接后 原来的sbd也改变了
System.out.println(sbd);
System.out.println(sbd==sbd1);//true
}
}
总结:
1、String是不可变字符串,StringBuffer、StringBuilder是可变字符串,String的字符串连接总会返回一个新的字符串,而原来的字符串不会改变。StringBuffer、StringBuilder 返回的字符串和原来的字符串是同个对象
2、StringBuffer、StringBuilder的区别:StringBuffer的所有方法都是synchronized修饰的,线程同步的。而StringBuilder不能保证线程同步。
public class Test {
public static void main(String[] args) {
String str = "ABC";
//获取循环之前的系统时间
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
str += "ABC";
}
//获取循环之后的系统时间
long end = System.currentTimeMillis();
System.out.println("String循环所消耗的时间:" + (end - start));
StringBuilder sb = new StringBuilder("ABC");
start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
sb.append("ABC");
}
end = System.currentTimeMillis();
System.out.println("StringBuilder循环所消耗的时间:" + (end - start));
}
}
运行结果
![]()
内存分析:为什么StringBuilder和StringBuffer比String的性能好
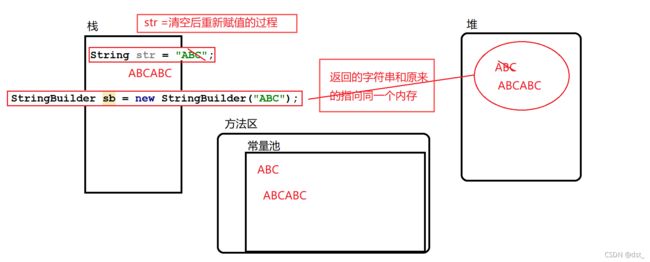
什么时候使用String,什么时候使用StringBuilder: 如果字符串的连接很短,使用String,因为代码简单。如果出现大量的字符串连接则使用StringBuilder
字符串常量池
每个生成一个新的字符串都会去创建一个新的对象,new一定会创建对象:
# 请问下面创建了对少个对象
String str = "a"+"b"+new String("ab")+"c";// 7
对于字符串常量池,最初是空的,如果需要一个字符串会先到字符串常量池中去获取,如果常量池中不存在则创建一个新的字符串,并将这个新的字符串加入到常量池中。可以看下面这个例子:
public class Test {
public static void main(String[] args) {
String str = "abc";
for (int i = 0; i < 1000000000; i++) {
str += "abc";
str.intern();//强行加入
}
System.out.println("over");
}
}
总结:以上代码在执行的过程中会发生内存溢出。因为我们每生成一个新的字符串都加入常量池中,常量池最终会容量不够!
字符串的比较
字符串常量的比较
public class Test {
public static void main(String[] args) {
String a = "abc";
String b = "abc";
// 字面量的赋值
System.out.println(a==b);
String a1 = new String("abc");
String b1 = new String("abc");
// 因为 a1 和 b1 保存都是堆内存地址 所以不会拆箱
System.out.println(a1 == b1);//false
System.out.println(a == a1);//也不会拆箱 因为声明的类型相同
// 字符串的比较稳妥的说使用 equals()
System.out.println(a1.equals(b1));//true
System.out.println(a.equals(b1));//true
/*需要去看一下equals的源代码 8版本和10版不一样*/
}
}
字符串变量
public class Test {
public static void main(String[] args) {
StringBuilder sb1 = new StringBuilder("abc");
StringBuilder sb2 = new StringBuilder("abc");
System.out.println(sb1==sb2);//false
// StringBuilder 没有重写 equals sb1.equals(sb2) 和 sb1==sb2 是一个意思
System.out.println(sb1.equals(sb2)); //false
// StringBuilder 重写了 toString() 返回的是一个String 对象 需要借助于String的equals()
System.out.println(sb1.toString().equals(sb2.toString()));
}
}
字符串常用API
equals:字符串比较
split:字符串切割
intern:加入常量池
public class Test {
public static void main(String[] args) {
//String str = "hello java艾瑞";
//System.out.println(str.charAt(0));
//System.out.println(str.compareTo("ABB"));//1
//System.out.println(str.contains("hello"));
//System.out.println("abc.mp3".endsWith(".mp3"));
/*
byte[] bytes = str.getBytes();
for (int i = 0; i < bytes.length; i++) {
System.out.println(bytes[i]);
}
*/
//字符串的转码
/*
String word = "南京艾瑞";
byte[] bytes = word.getBytes(Charset.forName("GBK"));
System.out.println(new String(bytes, Charset.forName("UTF-8")));
System.out.println(new String(bytes, Charset.forName("GBK")));
*/
/*
// 哈希: 对于不同的数据类型哈希值的计算方式是不同 对于整数类型而言 他的值就是数值本身
// 对应Object 而言哈希值就是内存地址对应的int值
// 对于对象类型而言哈希值标记着这个对象在内存中的唯一性
// 对于字符串而言 有可能存在两个不同的字符串他的hashcode值相同
String word = "A";
System.out.println(word.hashCode());
*/
// System.out.println("abc".indexOf("ab"));
// System.out.println(" ".isEmpty());//false
// System.out.println("".isEmpty());//true
// ... 表示0个或n个参数 ...只能用于形参的最后 也可以接受数组
//System.out.println(String.join("|", "a", "b", "c"));
// String word = "hello"; // h e l l o
// System.out.println(String.join(" ",word.split("")));
// String word = "hello";
//注意区分数组的length,数组的length是属性,字符串的length()是方法
// System.out.println(word.length());
// System.out.println("hello12314b".matches("^(hello).*b$"));// g
// System.out.println(Pattern.matches("hello", "hello java"));
// System.out.println("hello java java".replace("java","html"));
// System.out.println("abcdefg".substring(2));
// System.out.println("abcdefg".substring(2,4));
// toLowerCase()
// toUpperCase()
// System.out.println(" abc ".length());
// System.out.println(" abc ".trim().length());
// valueOf(boolean b)
}
}
练习:
“The Apache Tomcat Project is proud to announce the release of version 8.5.47 of Apache Tomcat. Apache Tomcat 8.5.x replaces 8.0.x and includes new features pulled forward from Tomcat 9.0.x. The minimum Java version and implemented specification versions remain unchanged. The notable changes compared to 8.5.46 include”
找出以上字符中出现次数最多的单词,不区分大小写
输入输出
public class Test {
public static void main(String[] args) {
System.out.println("abc");
System.err.println("abc");
Scanner sc = new Scanner(System.in);
System.out.println(sc.next());
System.out.println(System.currentTimeMillis());
System.gc();//垃圾回收
// Java的GC是自动垃圾回收,什么是回收收呢? 当对象不可达、当对象操作他的作用域范围的时候
// JVM 会对不使用的对象进行垃圾回收 而调用gc() 只会让JVM 积极去垃圾回收,不一定会垃圾回收
}
}
Math
是一个最终类。提供了一些数学的函数。所有的方法都是static
去看API
Date
public class Test {
public static void main(String[] args) {
/*
Date date = new Date();
System.out.println(date);// 默认的格式
//日期的格式化
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
String dateStr = sdf.format(date);
System.out.println(dateStr);
// 转成时间戳
System.out.println(System.currentTimeMillis());
System.out.println(date.getTime());
//由时间戳转成时间字符串
long longDate = System.currentTimeMillis();
Date date1 = new Date(longDate);
String format = sdf.format(date1);
System.out.println(format);
*/
// 时间的计算
Date date = new Date();
Calendar calendar = Calendar.getInstance();
// 获取年月日
calendar.setTime(date);//生成日历
System.out.println(calendar.get(Calendar.YEAR));
System.out.println(calendar.get(Calendar.MONTH)+1);
System.out.println(calendar.get(Calendar.WEDNESDAY));
// 增加多少天 增加多少月
calendar.add(Calendar.MONTH,3);
Date time = calendar.getTime();
System.out.println(time);
}
}
练习:
移动公司对于话费的计算: 8:00 - 20:00 2毛/分 20:00- 8:00 1毛/分
开发一个计算花费的系统,计算用户每次通话的费用
Random
public class Test { public static void main(String[] args) { Random random = new Random(); double d = random.nextDouble(); System.out.println(d);// 0 - 1 System.out.println(random.nextInt()); System.out.println(random.nextInt(10));// 0 - 10 System.out.println(Math.random());// == random.nextDouble() }}
练习1:
定义一个方法:返回指定区间的int型
练习2:
返回字母和数字组合的长度8位的验证码(大小写混合)
javabean
定义:JavaBean 是一个可重用java对象。
4个条件
1、实现Serializable
2、所有属性必须是私有的
3、必须提供无参的构造函数
4、必须提供公共的set/get方法
public class Emp implements Serializable {
private Integer empno;
private String ename;
private Date hiredate;
public Emp() {
}
public Integer getEmpno() {
return empno;
}
public void setEmpno(Integer empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public Date getHiredate() {
return hiredate;
}
public void setHiredate(Date hiredate) {
this.hiredate = hiredate;
}
}
总结:
javabean的作用:就是用来保存数据和读取数据的。
泛型
泛型的定义: 泛型就是一种泛指,只能指定引用数据类型,在声明该类型的时候指定了泛型的类型,那么后就都是这个类型。
集合
Collection:是所有集合的父接口,提供了 add size remove ...
Collection继承了Iterable,Iterable提供了iterator方法返回要给迭代器(Iterator),而Iterator提供了迭代的方法hasNext、next
List
常用子类:ArrayList、LinkedList、Vector。有序的,可以有重复元素
ArrayList: 底层是数组,特性查询快(索引),增删慢(每次增加或者删除后都需要去重新维护索引)
LinkedList:底层是链表,特性增删快,查询慢(二分法)
Vector:底层是数组,所有的方法都是线程同步的,数组安全。查询和增删都是比较慢(多线程)
ArrayList
public class Test {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
//添加元素
list.add("A");//在尾部追加
list.add(0,"B");//插入
System.out.println(list.size());//有多少元素
// 存取有序
System.out.println(list.get(0));//第一个元素
System.out.println(list.get(1));//第二个元素
//遍历
System.out.println("获取所有元素1:");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
System.out.println("获取所有元素2:");
for(String e : list){
System.out.println(e);
}
System.out.println("迭代遍历:");
Iterator<String> its = list.iterator();
while (its.hasNext()){
System.out.println(its.next());
}
//JDK1.8 函数
list.forEach( e -> System.out.println(e));
System.out.println("==============");
}
}
容量增长截图:

LinkedList
public class Test {
public static void main(String[] args) {
LinkedList<User> users = new LinkedList<>();
users.add(new User("jack",20));//追加
users.add(0,new User("tom",30));//插入
System.out.println(users.size());// 元素的数量
System.out.println(users.get(0));
System.out.println(users.getFirst()); //特有的方法
System.out.println(users.getLast()); // 特有的
System.out.println("-----------------------");
for (int i = 0; i < users.size(); i++) {
System.out.println(users.get(i));
}
}
}
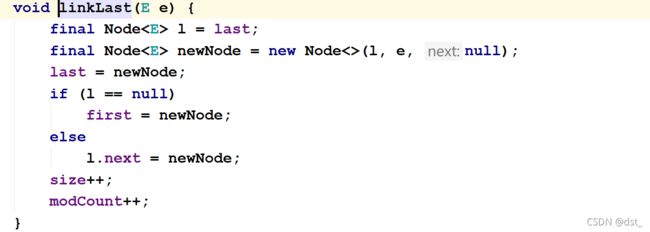
追加的维护
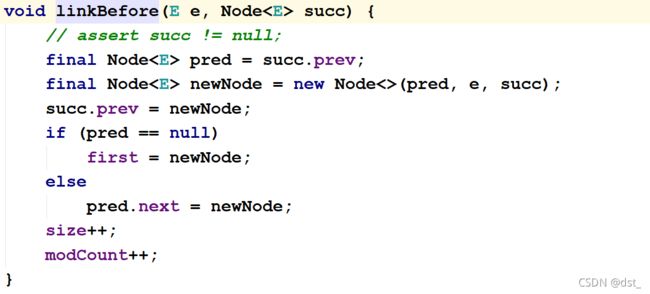
插入的节点维护
搜索的方式

Vector
自己写: 参照ArrayList写
Set
HashSet、TreeSet 无序的、不能有重复元素(唯一)
HashSet:底层是哈希算法,添加元素特别快,首先会比较元素的哈希值,如果哈希值不同则保存,如果hash值相同,则调用equal() .如果不同则保存,相同则丢弃
TreeSet : 底层是二叉树,自然排序(数据字典的顺序)。 调用compareTo方法 如果不同则保存,相同则不保存,元素不能是null,因为要调用compareTo方法
hashet
import java.util.HashSet;
import java.util.Iterator;
public class Test {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("C");
set.add("A");
set.add("A");//A 重复元素
set.add("B");
System.out.println(set.size());//3
System.out.println("-------------------");
// 遍历
Iterator<String> its = set.iterator();
while (its.hasNext()) {
System.out.println(its.next());
}
System.out.println("-------------------");
for (String e : set) {
System.out.println(e);
}
System.out.println("---------------------");
set.forEach(e -> System.out.println(e));
System.out.println("=====================");
//自己去尝试
// set.remove()
// set.contains()
}
}
验证重复元素的比较
自己重写hashcode 和equals方法
public class User {
private String name;
public User(String name) {
this.name = name;
}
// @Override
// public int hashCode() {
// return 0;
// }
@Override
public boolean equals(Object obj) {
return true;
}
}
public class Test {
public static void main(String[] args) {
HashSet<User> set = new HashSet<>();
set.add(new User("jack"));
set.add(new User("tom"));
System.out.println(set.size());
}
}
TreeSet
public class Test {
public static void main(String[] args) {
/*String*/
/*
TreeSet set = new TreeSet<>();
set.add("A");
// 会调用compareTo 比大小
set.add("A");
set.add("B");
set.add("C");
// 方法和hashset都一样只是底层数据结构不一样,实现的方式不一样
System.out.println(set.size());// 3
// 遍历自己参照hashset去写一下: 增强for 迭代器
*/
/*
TreeSet set = new TreeSet<>();
set.add(1);
set.add(2);
set.add(3);
System.out.println(set.size());
*/
TreeSet<User> set = new TreeSet<>();
set.add(new User("jack",20));
set.add(new User("jack",10));
System.out.println(set.size());
Iterator<User> its = set.iterator();
while (its.hasNext()){
System.out.println(its.next());
}
}
}
Map
映射: 数据是以键值对的方式存在,key唯一,不能重复。可以通过key去存放数据和获取数据
HashMap(常用): 底层是哈希,key 唯一的保证是先调用hashcode再调用equals
TreeMap:底层二叉树,key自然排序。通过调用compareTo比较key的大小
HashTable:哈希,key 唯一的保证是先调用hashcode再调用equals。所有方法都是线程同步。
HashMap
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class Test {
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
//添加元素
map.put("A", "AA");
map.put("B", "BB");
map.put("B", "BBB");
map.put(null, "null");
//map的大小
System.out.println(map.size());//3
//通过key获取元素
System.out.println(map.get("B"));//BBB
//判断元素中是否保存某个key
System.out.println(map.containsKey("A"));
System.out.println(map.containsValue("AA"));
System.out.println("-------------------");
//Map 的遍历:Map自己本身并没有提供遍历的方式,但是它提供了2个方法
//方法1 : keySet 获取Map中所有的key 返回一个set
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println(key + "=>" + map.get(key));
}
System.out.println("----------------");
//方法2 : Map扩展了一个内部接口 EntryMap 通过entrySet 或的Set EntryMap提供了获取key和value的方法
Set<Entry<String, Object>> entries = map.entrySet();
Iterator<Entry<String, Object>> its = entries.iterator();
while (its.hasNext()) {
Entry<String, Object> element = its.next();
System.out.println(element.getKey() + "=>" + element.getValue());
}
}
}
TreeSet
public class Test {
public static void main(String[] args) {
TreeMap<String, Object> map = new TreeMap<>();
//添加元素
map.put("B", "BB");
map.put("B", "BBB");
map.put("A", "AA");
map.put("null", "null");
//map的大小
System.out.println(map.size());
//遍历
//方法1:
Set<String> keys = map.keySet();
Iterator<String> its = keys.iterator();
while (its.hasNext()) {
String key = its.next();
System.out.println(key + "=>" + map.get(key));
}
System.out.println("=================");
Set<Map.Entry<String, Object>> entries = map.entrySet();
Iterator<Map.Entry<String, Object>> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> element = iterator.next();
System.out.println(element.getKey() + "=>" + element.getValue());
}
}
}
比较器
Comparable之外还有一个叫做Comparator
场景: 一个自定义的javabean由其他工程引用,但是没有重写Comparable接口,二我们的业务又需要将User保存到一个TreeSet中。我们又不能去修改别人的代码
定义一个User类
public class User implements Serializable {
private String name;
public User() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
定义一个工具类
public class Utils {
/*
* (User a, User b) -> {
return a.getName().compareTo(b.getName());
}
*
* */
public static int comparator(User a, User b){
return a.getName().compareTo(b.getName());
}
}
测试
public class Test {
public static void main(String[] args) {
/*
TreeSet set = new TreeSet<>(new Comparator() {
@Override
public int compare(User o1, User o2) {
return o1.getName().compareTo(o2.getName());
}
});
User u1 = new User();
u1.setName("jack");
User u2 = new User();
u2.setName("tom");
set.add(u1);
set.add(u2);
Iterator its = set.iterator();
while (its.hasNext()){
User user = its.next();
System.out.println(user.getName());
}
*/
/*
TreeSet set = new TreeSet<>(
(User a, User b) -> {
return a.getName().compareTo(b.getName());
}
);
*/
// TreeSet set = new TreeSet<>(Comparator.comparing(User::getName));
TreeSet<User> set = new TreeSet<>(Utils::comparator);
User u1 = new User();
u1.setName("jack");
User u2 = new User();
u2.setName("tom");
set.add(u1);
set.add(u2);
set.forEach( e -> System.out.println(e.getName()));
}
}
Collections
集合的工具类:Collections,提供了一些对集合的操作API,比如说创建一个List、反转、旋转、洗牌
数组的工具类:Arrays
Collections和Collection的区别:
1、Collection是集合的父接口,Collections集合的工具类
2、Collection提供了集合对外访问的接口声明。
数据结构
堆、栈、链表、数组、hash、二叉树