大数据----4.hadoop分布式框架搭建
hadoop分布式框架搭建
一、Hadoop的三种运行模式(启动模式)
1.1、单机模式(独立模式)(Local或Standalone Mode)
-默认情况下,Hadoop即处于该模式,用于开发和调式。
-不对配置文件进行修改。
-使用本地文件系统,而不是分布式文件系统。
-Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
-用于对MapReduce程序的逻辑进行调试,确保程序的正确。
1.2、伪分布式模式(Pseudo-Distrubuted Mode)
-Hadoop的守护进程运行在本机机器,模拟一个小规模的集群
-在一台主机模拟多主机。
-Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
-在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,
以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
-修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
-格式化文件系统
1.3、全分布式集群模式(Full-Distributed Mode)
-Hadoop的守护进程运行在一个集群上
-Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
-在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
-在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
-修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和 JobTraker的位置和端口,设置文件的副本等参数-格式化文件系统
1.检查系统的相关信息
1.检查系统的版本:cat /etc/redhat-release
![]()
2.检查系统中安装的jdk版本:

3.检查时间同步:date
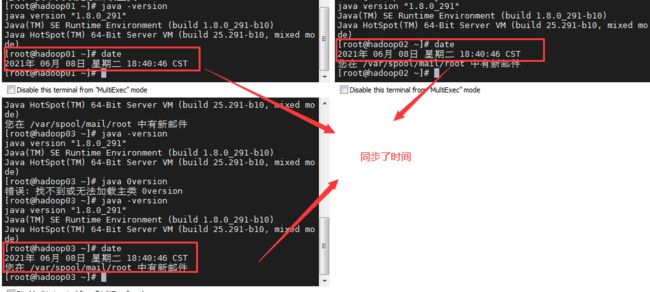
4.检查下防火墙:firewall-cmd --state

这个地方:/var/spool/mail/root 中有新邮件提示处理 可以去掉:
这是LINUX的邮年提示功能。LINUX会定时查看LINUX各种状态做汇总,每经过一段时间会把汇总的信息发送的root的邮箱里,以供有需之时查看。
关闭Linux系统的邮件自动提示功能即可
[root@master ~]# echo "unset MAILCHECK" >> /etc/profile
[root@master ~]# source /etc/profile
2.hadoop的安装
1.使用的系统环境和软件版本;
操作系统;centos7.2
jdk:java1.8
hadoop : hadoop2.7.3 hadoop 2.x比较多,因为企业开发追求的是稳定性
说明:Hadoop从版本2开始加入了Yarn这个资源管理器,Yarn并不需要单独安装。只要在机器上安装了JDK就可以直接安装Hadoop,单纯安装Hadoop并不依赖Zookeeper之类的其他东西。
2.hadoop的简单介绍:
例子:
小明接到一个任务:计算一个100M的文本文件中的单词的个数,这个文本文件有若干行,每行有若干个单词,每行的单词与单词之间都是以空格键分开的。对于处理这种100M量级数据的计算任务,小明感觉很轻松。他首先把这个100M的文件拷贝到自己的电脑上,然后写了个计算程序在他的计算机上执行后顺利输出了结果。
后来,小明接到了另外一个任务,计算一个1T(1024G)的文本文件中的单词的个数。再后来,小明又接到一个任务,计算一个1P(1024T)的文本文件中的单词的个数……
先按顺序给出所有单位:Byte、KB、MB、GB、TB、PB、EB、ZB、YB、DB、NB
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
3.hadoop安装和部署
1.下载hadoop
https://hadoop.apache.org/releases.html(后边他有很多其他的框架只需要换apache)

这个是最新版本的;
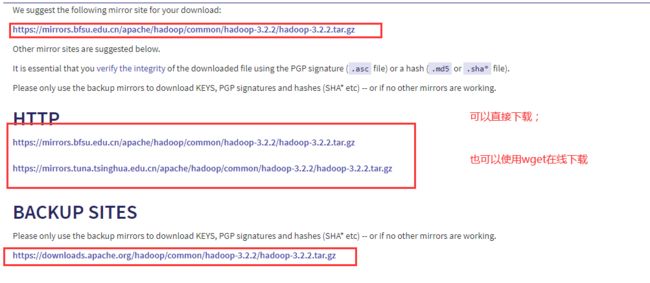
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
在线直接下载;
可以去获取旧的版本: http://archive.apache.org/dist/hadoop/core/ 这个没有在官方出现;
现在完成之后直接上传:


2.解压hadoop文件;
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/local/

查看 /usr/local/hadoop2.7.3 目录


/bin 目录存放对Hadoop相关服务(HDFS, YARN)进行操作的脚本;(单台的命令)
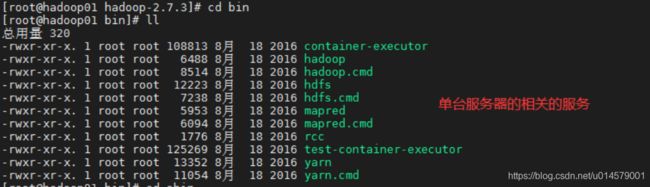
/etc 目录存放Hadoop的配置文件
/lib 目录存放Hadoop的本地库(对数据进行压缩解压缩功能)
/sbin 目录存放启动或停止Hadoop相关服务的脚本(单台和多台的命令)

/share 目录存放Hadoop的依赖jar包、文档、和官方案例
3.对hadoop进行配置文件的配置:
在/usr/local/hadoop-2.7.3/etc/hadoop/下就是我们要进行的配置信息的文件;(一个配置好后;其他的节点进行传入即可;)

一般要对配置文件进行配置都要关闭服务;重启启动集群操作;
4.配置hadoop的环境变量—vim /etc/profile
#Configure environment variables for cluster environment
export JAVA_HOME=/usr/local/java/jdk1.8.0_291
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

同时要用到bin和sbin中的命令;

source /etc/profile 对这个配置文件进行更新; source主要的作用就是更新配置文件;当配置文件进行了修改需要进行更新操作;
hadoop version 查看他的版本;

4.配置hadoop中的相关文件;
这些是hadoop中的需要配置的文件(可以参考;也可以查看官方):https://blog.csdn.net/wjt199866/article/details/106473174
1.配置hadoop中的hadoop-2.7.3/etc/hadoop/hadoop-env.sh(后边很多框架配置环境都是xxx.env.sh)
配置hadoop的环境变量的,一般有Java home,hadoopconfdir等这些软件、配置目录,有运行过程中使用的变量,如hadoop栈大小配置,java 运行内存大小配置等等。
用工具直接打开进行配置即可;

默认是已经开启的,如果前面有#,只需要去掉即可;
2.配置hadoop的访问目录(配置ip主机和端口号;提供出来进行访问);修改配置文件 etc/hadoop/core-site.xml

用于定义系统级别的参数,如HDFS URL、Hadoop的临时目录等;
| Parameter | Value | Notes |
|---|---|---|
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | Size of read/write buffer used in SequenceFiles. |
其中,fs.defaultFS表示要配置的默认文件系统,io.file.buffer.size表示设置buffer的大小。
Namenode在哪里 ,临时文件存储在哪里
fs.defaultFS
hdfs://hadoop01:9000 //NameNode 是哪个服务器;
hadoop.tmp.dir
/usr/local/hadoop-2.7.3/tmp // 临时文件在哪个地方存储

最简单的方法,使用工具直接找到文件打开进行配置;
在这个里边还有很多的配置信息,需要我们去官方找过来配置;
3.配置元数据和block块;其实就是去配置我们的hdfs中数据存储的block块;
HDFS也是采用块管理的,但是比较大,在Hadoop1.x中默认大小是64M,Hadoop2.x中大小默认为128M;他就是把一个大的文件分割成多个128M的block块来分布式存储数据;
HDFS的元数据包含三部分:
抽象目录树
数据和块映射关系
数据块的存储节点
元数据有两个存储位置:
内存:1、2、3
3在集群启动时,Datanode 通过心跳机制向Namenode发送。
磁盘:1、2
集群启动时需要将磁盘中的元数据加载到内存中,所以磁盘中的元数据不适宜过多。
元数据的存储格式:data/hadoopdata/目录下有三个文件夹
data
数据的真实存储目录,即datanode存储数据的存储目录
name:元数据存储目录
namenode存储元数据的存储目录
需要对/usr/local/hadoop-2.7.3/etc/hadoop/hdfs-site.xml 其实就是hadoop的文件系统进行配置;
-
配置计算框架:mapreduce框架; 需要对这个文件进行修改: mapred-site.xml
但是我们的hadoop2.x中没有这个文件;只有 vi mapred-site.xml.template 这个临时文件;需要对他的后缀进行修改;
mv mapred-site.xml.template mapred-site.xml 修改文件的后缀名字;
然后对这个文件进行配置:
mapreduce.framework.name yarn

5.对yarn的资源调度的配置: resourcemanager(资源调度管理者–针对的是nameNode) 和nodemanager (节点管理者–针对的是我们具体的节点) 主要是在 yarn-site.xml中进行配置:
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle

6.配置从节点:也就是指定那些节点是从节点:就是这个文件:slaves

这个地方把原来的localhost删除;加入你的从节点即可;
到此hadoop的配置基本完成;就可以把这个分发给从节点中去;
把配置好的hadoop的内容分发给hadoop02中的usr/local目录中;
scp -r /usr/local/hadoop-2.7.3/ hadoop02:/usr/local/

把配置好的hadoop的内容分发给hadoop03中的usr/local目录中;
scp -r /usr/local/hadoop-2.7.3/ hadoop03:/usr/local/

到此我们的hadoop的配置就完成了。
hadoop集群的启动;
1.检查每个节点上的时间同步;因为我们配置了时间的服务器;一般都是同步的;
2.检查每个节点上的防火墙关闭;
3.然后对我们的hadoop集群进行初始化:
在第一台服务器上执行即可;
hadoop namenode -format
如果有报错就会在info中体现:
![]()
这个的原因是:在这个配置文件中写了中文的注释;(大家注意: 不要在配置文件中写中文的注释)
如果要修改后,要把他们进行二次分发到每个节点上去;
然后再进行初始化:hadoop namenode -format
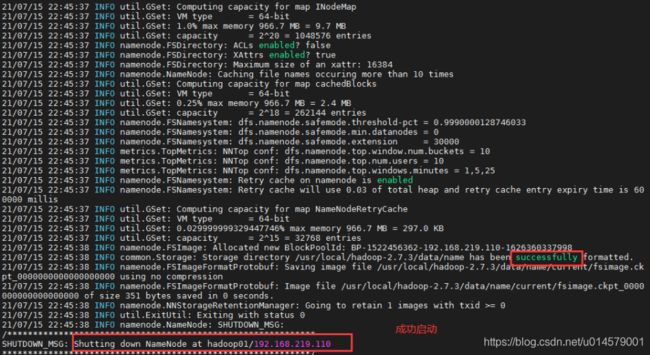
如果你的info中没有任何的error就是没有错误;就会启动 successfully 然后出现nameNode的机器和地址;
4.开始启动我们的集群:
1.一键启动在hadoop01号机子上执行:start-all.sh

这个内容:
hadoop01 启动namenode 并且他的日志文件打入到了 对应的logs的目录中;
hadoop02;hadoop03就是我们的datanode 他的日志打到对应的logs的目录中;
secondary namenode 也是我们的hadoop01;他的日志打印了logs的目录中;
yarn(任务调度)的守护线程daemons启动;
resourcemanager 的日志位置所在logs的目录中; hadoop01
nodemanager 在hadoop02;hadoop03上的日志位置 logs位置;
如果有错误我们要对应到这个位置上去找错;
2.通过jps查看节点启动情况; 有这三个节点就成功启动了;

如果启动有问题的化,对应到的节点就启动不起来;
3.查看每个节点上的运行情况;

到此我们的每个节点都已经成功了。
4.然后就可以通过web访问:http://192.168.219.110:50070/ 通过他的地址或者机器的名字都可以; 50070是hadoop默认的web服务器的端口号;
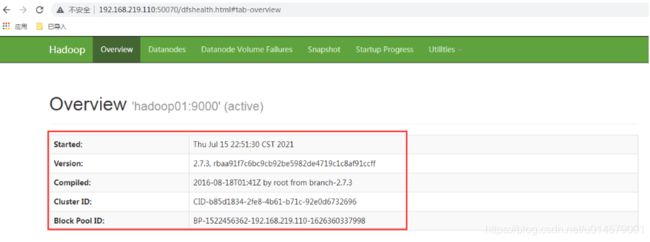
这就是活着的节点;以及一些其他的信息详细内容;在他的其他项中;

点击live Nodes(活着的节点;就可以查看当前这个分布式系统中的存货节点详细信息;)

查看对应的文件系统中的信息:
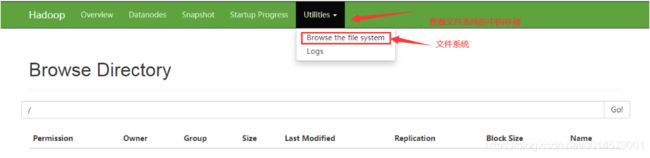
注意:
1.如果执行两次初始化操作;会引起clusterID 不一样;造成datanode启动不了;,初始化第一册时候回生成一个uid给分发给每个节点; 第二的时候就不会分发,但是datanode中的clusterID 重写发生变化;具体操作是找到对应的位置修改 clusterID; 这个id发生了变化
循环要在进行初始化:

解决办法:修改datanode中的配置文件中的clusterID; 或者修改nameNode中的配置文件中的id;
/usr/local/hadoop-2.7.3/data/data/current 下有一个VERISION文件; 修改他里边的clusterID 即可;
2.当进行挂起虚拟机的时候,出现下次打来启动不了网卡;连接不上的问题;是因为挂起的时候网卡信息丢失造成;
解决办法:
1)在linux终端:停止并禁用虚拟机 NetworkManager 服务
systemctl stop NetworkManager
systemctl disable NetworkManager
2)修改配置

3)在linux终端:重启虚拟机网络服务
systemctl restart network
二.Windows访问的时候的映射:
有的时候我们在访问的时候非常的不习惯使用ip地址去进行访问; 能不能配置这个ip地址映射到一个名字;例如: hadoop01;
原先访问:http://192.168.219.110:50070/ 使用地址来进行访问;
现在配置映射:http://hadoop01:50070/ 就完全可以使用这个域名(我们弄的模拟的域名); 并没有备案;
只需要修改:去windows下去改变映射关系
C/windows/system32/drivers/etc/hosts —修改这个文件

但是一般这个文件不让修改;那就拷贝出去,然后修改完毕再复制进来即可;
建议: 我们使用ip地址来进行访问;因为配置了映射;有的时候回影响我们访问;

三. hadoop存储数据:
1.往hadoop中存储数据:
hadoop fs 命令;

1 hadoop fs -ls
列出指定目录下的内容,支持pattern匹配。输出格式如filename(full path)size.n代表备份数。
2 hadoop fs -lsr
递归列出该路径下所有子目录信息
3 hadoop fs -du
显示目录中所有文件大小,或者指定一个文件时,显示此文件大小
4 hadoop fs -dus
显示文件大小 相当于 linux的du -sb s代表显示只显示总计,列出最后的和 b代表显示文件大小时以byte为单位
5 hadoop fs -mv
将目标文件移动到指定路径下,当src为多个文件,dst必须为目录
6 hadoop fs -cp
拷贝文件到目标位置,src为多个文件时,dst必须是个目录
7 hadoop fs -rm [skipTrash]
删除匹配pattern的指定文件
8 hadoop fs -rmr [skipTrash]
递归删除文件目录及文件
9 hadoop fs -rmi [skipTrash]
为了避免误删数据,加了一个确认
10 hadoop fs -put <> …
从本地系统拷贝到dfs中
11 hadoop fs -copyFromLocal…
从本地系统拷贝到dfs中,与-put一样
12 hadoop fs -moveFromLocal …
从本地系统拷贝文件到dfs中,拷贝完删除源文件
13 hadoop fs -get [-ignoreCrc] [-crc]
从dfs中拷贝文件到本地系统,文件匹配pattern,若是多个文件,dst必须是个目录
14 hadoop fs -getmerge
从dfs中拷贝多个文件合并排序为一个文件到本地文件系统
15 hadoop fs -cat
输出文件内容
16 hadoop fs -copyTolocal [-ignoreCre] [-crc]
与 -get一致
17 hadoop fs -mkdir
在指定位置创建目录
18 hadoop fs -setrep [-R] [-w]
设置文件的备份级别,-R标志控制是否递归设置子目录及文件
19 hadoop fs -chmod [-R]
修改文件权限, -R递归修改 mode为a+r,g-w,+rwx ,octalmode为755
20 hadoop fs -chown [-R] [OWNER][:[GROUP]] PATH
递归修改文件所有者和组
21 hadoop fs -count[q]
统计文件个数及占空间情况,输出表格列的含义分别为:DIR_COUNT.FILE_COUNT.CONTENT_SIZE.FILE_NAME,如果加-q 的话,还会列出QUOTA,REMAINING_QUOTA,REMAINING_SPACE_QUOTA
也可以直接访问:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
官方会给你每个命令的解释:
现在开始操作:
1.在hadoop中创建一个目录:
![]()

2.上传文件导hfc中:
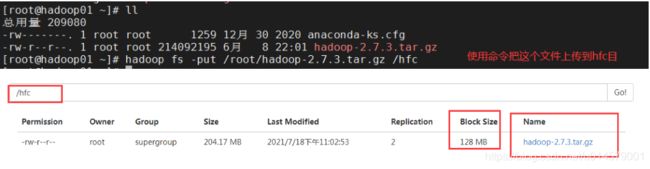
默认的hadoop1 .x的默认大小是64M; hadoop 2.x 的默认大小为128M; 超过就是加块; 没有超过就是128M;

这个文件没有超过128的时候就是一个块;

拷贝到两个数据节点上去;
2.下载的时候:
hadoop fs -get hadoop-2.7.3.tar.gz /hfc 命令行的方式;
图形接界面:
