死锁 (史上最全)
-
疯狂创客圈 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 面试必备 + 面试必备 【博客园总入口 】
-
疯狂创客圈 经典图书 : 《SpringCloud、Nginx高并发核心编程》 大厂必备 + 大厂必备 + 大厂必备 【博客园总入口 】
-
入大厂+涨工资 必备的 高并发社群: 【博客园总入口 】
系列:如果整个 地表最强 的开发环境?
| 工欲善其事 必先利其器 |
|---|
| 地表最强 开发环境: vagrant+java+springcloud+redis+zookeeper镜像下载(&制作详解) |
| 地表最强 热部署:java SpringBoot SpringCloud 热部署 热加载 热调试 |
| 地表最强 发请求工具(再见吧, PostMan ):IDEA HTTP Client(史上最全) |
| 地表最强 PPT 小工具: 屌炸天,像写代码一样写PPT |
| 无编程不创客,疯狂创客圈,一大波编程高手正在交流、学习中!,GO |
疯狂创客圈 springCloud 高并发系列
| 推荐阅读 |
|---|
| nacos 实战(史上最全) |
| sentinel (史上最全+入门教程) |
| springcloud + webflux 高并发实战 |
| Webflux(史上最全) |
| SpringCloud gateway (史上最全) |
| 无编程不创客,疯狂创客圈,一大波编程高手正在交流、学习中!,GO |
导读:
首先介绍大厂的死锁面试题,然后对死锁做一个全面的解读。
大厂的死锁面试题
什么是死锁?
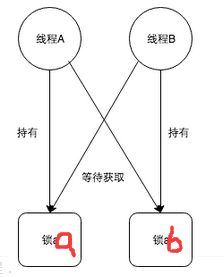
所谓死锁,是指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。 因此我们举个例子来描述,如果此时有一个线程A,按照先锁a再获得锁b的的顺序获得锁,而在此同时又有另外一个线程B,按照先锁b再锁a的顺序获得锁。如下图所示:
产生死锁的原因?
可归结为如下两点:
a. 竞争资源
- 系统中的资源可以分为两类:
- 可剥夺资源,是指某进程在获得这类资源后,该资源可以再被其他进程或系统剥夺,CPU和主存均属于可剥夺性资源;
- 另一类资源是不可剥夺资源,当系统把这类资源分配给某进程后,再不能强行收回,只能在进程用完后自行释放,如磁带机、打印机等。
- 产生死锁中的竞争资源之一指的是竞争不可剥夺资源(例如:系统中只有一台打印机,可供进程P1使用,假定P1已占用了打印机,若P2继续要求打印机打印将阻塞)
- 产生死锁中的竞争资源另外一种资源指的是竞争临时资源(临时资源包括硬件中断、信号、消息、缓冲区内的消息等),通常消息通信顺序进行不当,则会产生死锁
b. 进程间推进顺序非法
- 若P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,因为这两个进程再向前推进,便可能发生死锁
- 例如,当P1运行到P1:Request(R2)时,将因R2已被P2占用而阻塞;当P2运行到P2:Request(R1)时,也将因R1已被P1占用而阻塞,于是发生进程死锁
死锁产生的4个必要条件?
产生死锁的必要条件:
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
解决死锁的基本方法
一、预防死锁:
- 资源一次性分配:一次性分配所有资源,这样就不会再有请求了:(破坏请求条件)
- 只要有一个资源得不到分配,也不给这个进程分配其他的资源:(破坏请保持条件)
- 可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
- 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
1 以确定的顺序获得锁
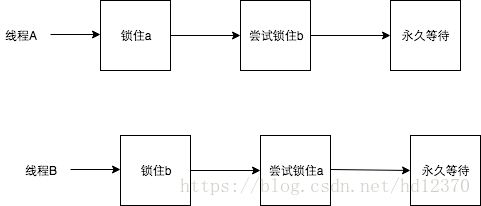
如果必须获取多个锁,那么在设计的时候需要充分考虑不同线程之前获得锁的顺序。按照上面的例子,两个线程获得锁的时序图如下:
如果此时把获得锁的时序改成:
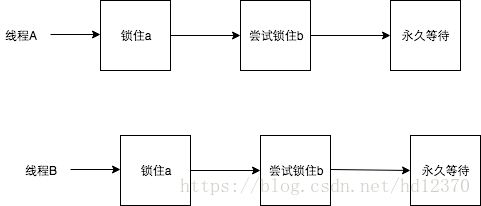
那么死锁就永远不会发生。 针对两个特定的锁,开发者可以尝试按照锁对象的hashCode值大小的顺序,分别获得两个锁,这样锁总是会以特定的顺序获得锁,那么死锁也不会发生。问题变得更加复杂一些,如果此时有多个线程,都在竞争不同的锁,简单按照锁对象的hashCode进行排序(单纯按照hashCode顺序排序会出现“环路等待”),可能就无法满足要求了,这个时候开发者可以使用银行家算法,所有的锁都按照特定的顺序获取,同样可以防止死锁的发生,该算法在这里就不再赘述了,有兴趣的可以自行了解一下。
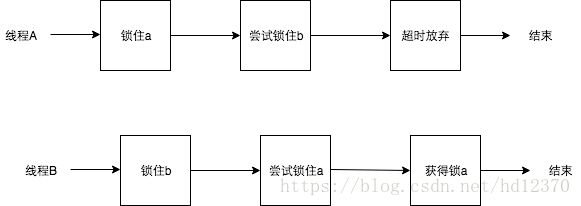
2 超时放弃
当使用synchronized关键词提供的内置锁时,只要线程没有获得锁,那么就会永远等待下去,然而Lock接口提供了boolean tryLock(long time, TimeUnit unit) throws InterruptedException方法,该方法可以按照固定时长等待锁,因此线程可以在获取锁超时以后,主动释放之前已经获得的所有的锁。通过这种方式,也可以很有效地避免死锁。 还是按照之前的例子,时序图如下:
二、避免死锁:
- 预防死锁的几种策略,会严重地损害系统性能。因此在避免死锁时,要施加较弱的限制,从而获得 较满意的系统性能。由于在避免死锁的策略中,允许进程动态地申请资源。因而,系统在进行资源分配之前预先计算资源分配的安全性。若此次分配不会导致系统进入不安全的状态,则将资源分配给进程;否则,进程等待。其中最具有代表性的避免死锁算法是银行家算法。
- 银行家算法:首先需要定义状态和安全状态的概念。系统的状态是当前给进程分配的资源情况。因此,状态包含两个向量Resource(系统中每种资源的总量)和Available(未分配给进程的每种资源的总量)及两个矩阵Claim(表示进程对资源的需求)和Allocation(表示当前分配给进程的资源)。安全状态是指至少有一个资源分配序列不会导致死锁。当进程请求一组资源时,假设同意该请求,从而改变了系统的状态,然后确定其结果是否还处于安全状态。如果是,同意这个请求;如果不是,阻塞该进程知道同意该请求后系统状态仍然是安全的。
三、检测死锁
-
首先为每个进程和每个资源指定一个唯一的号码;
-
然后建立资源分配表和进程等待表。
死锁检测的工具
1、Jstack命令
jstack是java虚拟机自带的一种堆栈跟踪工具。jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息。 Jstack工具可以用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。
2、JConsole工具
Jconsole是JDK自带的监控工具,在JDK/bin目录下可以找到。它用于连接正在运行的本地或者远程的JVM,对运行在Java应用程序的资源消耗和性能进行监控,并画出大量的图表,提供强大的可视化界面。而且本身占用的服务器内存很小,甚至可以说几乎不消耗。
四、解除死锁:
当发现有进程死锁后,便应立即把它从死锁状态中解脱出来,常采用的方法有:
- 剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
- 撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态.消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
ok,介绍大厂的死锁面试题之后,接下来,对死锁做一个全面的解读。
一、什么是死锁
多线程以及多进程改善了系统资源的利用率并提高了系统 的处理能力。然而,并发执行也带来了新的问题——死锁。
死锁是指两个或两个以上的进程(线程)在运行过程中因争夺资源而造成的一种僵局(Deadly-Embrace) ) ,若无外力作用,这些进程(线程)都将无法向前推进。
下面我们通过一些实例来说明死锁现象。
先看生活中的一个实例,2个人一起吃饭但是只有一双筷子,2人轮流吃(同时拥有2只筷子才能吃)。某一个时候,一个拿了左筷子,一人拿了右筷子,2个人都同时占用一个资源,等待另一个资源,这个时候甲在等待乙吃完并释放它占有的筷子,同理,乙也在等待甲吃完并释放它占有的筷子,这样就陷入了一个死循环,谁也无法继续吃饭。。。
在计算机系统中也存在类似的情况。例如,某计算机系统中只有一台打印机和一台输入设备,进程P1正占用输入设备,同时又提出使用打印机的请求,但此时打印机正被进程P2 所占用,而P2在未释放打印机之前,又提出请求使用正被P1占用着的输入设备。这样两个进程相互无休止地等待下去,均无法继续执行,此时两个进程陷入死锁状态。
关于死锁的一些结论:
- 参与死锁的进程数至少为两个
- 参与死锁的所有进程均等待资源
- 参与死锁的进程至少有两个已经占有资源
- 死锁进程是系统中当前进程集合的一个子集
- 死锁会浪费大量系统资源,甚至导致系统崩溃。
举一个例子:
如何解决上面的问题呢?正所谓知己知彼方能百战不殆,我们要先了解什么情况会发生死锁,才能知道如何避免死锁,很幸运我们可以站在巨人的肩膀上看待问题
一个银行转账经典案例:
账户 A 给账户 B 转账,账户 A 余额减少 100 元,账户 B 余额增加 100 元,这个操作要是原子性的
先来看程序:
class Account {
private int balance;
// 转账
synchronized void transfer(
Account target, int amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
用 synchronized 直接保护 transfer 方法,然后操作 资源「Account 的A 余额」和资源「Account的B 余额」就可以了
其中有两个问题:
- 单纯的用 synchronized 方法起不到保护作用(不能保护 target)
- 用 Account.class 锁方案,锁的粒度又过大,导致涉及到账户的所有操作(取款,转账,修改密码等)都会变成串行操作
如何解决这两个问题呢?咱们先换好衣服穿越回到过去寻找一下钱庄,一起透过现象看本质,dengdeng deng…

来到钱庄,告诉柜员你要给铁蛋儿转 100 铜钱,这时柜员转身在墙上寻找你和铁蛋儿的账本,此时柜员可能面临三种情况:
- 理想状态: 你和铁蛋儿的账本都是空闲状态,一起拿回来,在你的账本上减 100 铜钱,在铁蛋儿账本上加 100 铜钱,柜员转身将账本挂回到墙上,完成你的业务
- 尴尬状态: 你的账本在,铁蛋儿的账本被其他柜员拿出去给别人转账,你要等待其他柜员把铁蛋儿的账本归还
- 抓狂状态: 你的账本不在,铁蛋儿的账本也不在,你只能等待两个账本都归还
放慢柜员的取账本操作,他一定是先拿到你的账本,然后再去拿铁蛋儿的账本,两个账本都拿到(理想状态)之后才能完成转账,用程序模型来描述一下这个拿取账本的过程:
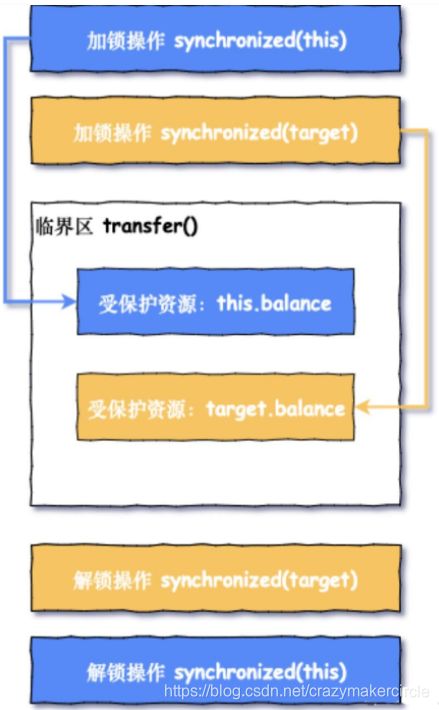
我们继续用程序代码描述一下上面这个模型:
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
// 锁定转出账户
synchronized(this) {
// 锁定转入账户
synchronized(target) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}
}
这个解决方案看起来很完美,解决了文章开头说的两个问题,但真是这样吗?
我们刚刚说过的理想状态是钱庄只有一个柜员(既单线程)。随着钱庄规模变大,墙上早已挂了非常多个账本,钱庄为了应对繁忙的业务,开通了多个窗口,此时有多个柜员(多线程)处理钱庄业务。
柜员 1 正在办理给铁蛋儿转账的业务,但只拿到了你的账本;柜员 2 正在办理铁蛋儿给你转账的业务,但只拿到了铁蛋儿的账本,此时双方出现了尴尬状态,两位柜员都在等待对方归还账本为当前客户办理转账业务。
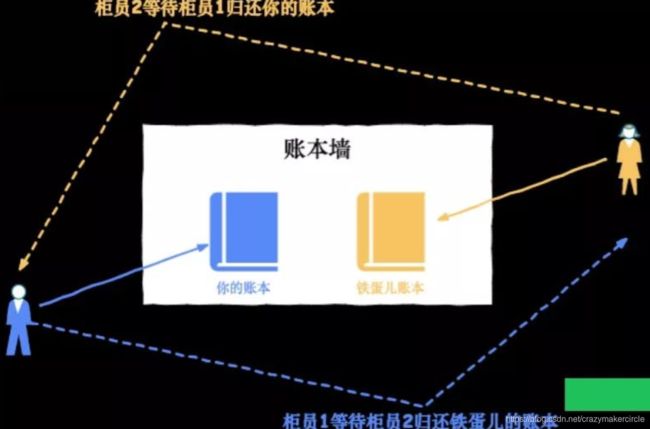
现实中柜员会沟通,喊出一嗓子 老铁,铁蛋儿的账本先给我用一下,用完还给你,但程序却没这么智能,synchronized 内置锁非常执着,它会告诉你「死等」的道理,最终出现死锁
如何解决死锁呢?
Java 有了 synchronized 内置锁,还发明了显示锁 Lock,是不是就为了治一治 synchronized 「死等」的执着呢??
如果你捉急,可以直接去阅读第四节。
二、死锁与饥饿
饥饿(Starvation)指一个进程一直得不到资源。
死锁和饥饿都是由于进程竞争资源而引起的。饥饿一般不占有资源,死锁进程一定占有资源。
三、资源的类型
3.1 可重用资源和消耗性资源
3.1.1 可重用资源(永久性资源)
可被多个进程多次使用,如所有硬件。
- 只能分配给一个进程使用,不允许多个进程共享。
- 进程在对可重用资源的使用时,须按照请求资源、使用资源、释放资源这样的顺序。
- 系统中每一类可重用资源中的单元数目是相对固定的,进程在运行期间,既不能创建,也不能删除。
3.1.2 消耗性资源(临时性资源)
又称临时性资源,是由进程在运行期间动态的创建和消耗的。
- 消耗性资源在进程运行期间是可以不断变化的,有时可能为0。
- 进程在运行过程中,可以不断地创造可消耗性资源的单元,将它们放入该资源类的缓冲区中,以增加该资源类的单元数目。
- 进程在运行过程中,可以请求若干个可消耗性资源单元,用于进程自己消耗,不再将它们返回给该资源类中。
可消耗资源通常是由生产者进程创建,由消费者进程消耗。最典型的可消耗资源是用于进程间通信的消息。
3.2 可抢占资源和不可抢占资源
3.2.1 可抢占资源
可抢占资源指某进程在获得这类资源后,该资源可以再被其他进程或系统抢占。对于这类资源是不会引起死锁的。
CPU 和主存均属于可抢占性资源。
3.2.2 不可抢占资源
一旦系统把某资源分配给该进程后,就不能将它强行收回,只能在进程用完后自行释放。
磁带机、打印机等属于不可抢占性资源。
四、死锁产生的原因
-
竞争不可抢占资源引起死锁
通常系统中拥有的不可抢占资源,其数量不足以满足多个进程运行的需要,使得进程在运行过程中,会因争夺资源而陷入僵局,如磁带机、打印机等。只有对不可抢占资源的竞争 才可能产生死锁,对可抢占资源的竞争是不会引起死锁的。 -
竞争可消耗资源引起死锁
-
进程推进顺序不当引起死锁
进程在运行过程中,请求和释放资源的顺序不当,也同样会导致死锁。例如,并发进程 P1、P2分别保持了资源R1、R2,而进程P1申请资源R2,进程P2申请资源R1时,两者都会因为所需资源被占用而阻塞。
信号量使用不当也会造成死锁。进程间彼此相互等待对方发来的消息,结果也会使得这 些进程间无法继续向前推进。例如,进程A等待进程B发的消息,进程B又在等待进程A 发的消息,可以看出进程A和B不是因为竞争同一资源,而是在等待对方的资源导致死锁。
4.1 竞争不可抢占资源引起死锁
如:共享文件时引起死锁
系统中拥有两个进程P1和P2,它们都准备写两个文件F1和F2。而这两者都属于可重用和不可抢占性资源。如果进程P1在打开F1的同时,P2进程打开F2文件,当P1想打开F2时由于F2已结被占用而阻塞,当P2想打开1时由于F1已结被占用而阻塞,此时就会无线等待下去,形成死锁。
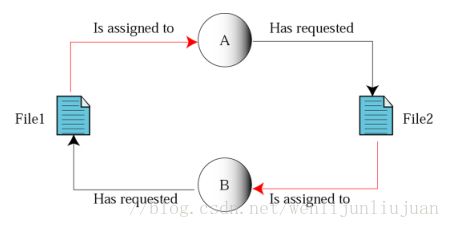
4.2 竞争可消耗资源引起死锁
如:进程通信时引起死锁
系统中拥有三个进程P1、P2和P3,m1、m2、m3是3可消耗资源。进程P1一方面产生消息m1,将其发送给P2,另一方面要从P3接收消息m3。而进程P2一方面产生消息m2,将其发送给P3,另一方面要从P1接收消息m1。类似的,进程P3一方面产生消息m3,将其发送给P1,另一方面要从P2接收消息m2。
如果三个进程都先发送自己产生的消息后接收别人发来的消息,则可以顺利的运行下去不会产生死锁,但要是三个进程都先接收别人的消息而不产生消息则会永远等待下去,产生死锁。

4.3 进程推进顺序不当引起死锁
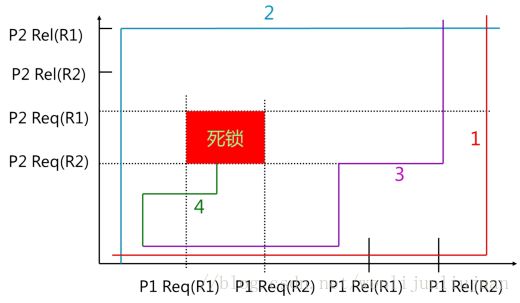
上图中,如果按曲线1的顺序推进,两个进程可顺利完成;如果按曲线2的顺序推进,两个进程可顺利完成;如果按曲线3的顺序推进,两个进程可顺利完成;如果按曲线4的顺序推进,两个进程将进入不安全区D中,此时P1保持了资源R1,P2保持了资源R2,系统处于不安全状态,如果继续向前推进,则可能产生死锁。
五、产生死锁的四个必要条件
Coffman 总结出了四个条件说明可以发生死锁的情形:
Coffman 条件
**互斥条件:**指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
**不可剥夺条件:**指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
**请求和保持条件:**指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
**环路等待条件:**指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P1,P2,···,Pn}中的 P1 正在等待一个 P2 占用的资源;P2 正在等待 P3 占用的资源,……,Pn 正在等待已被 P0 占用的资源。
这几个条件很好理解,其中「互斥条件」是并发编程的根基,这个条件没办法改变。但其他三个条件都有改变的可能,也就是说破坏另外三个条件就不会出现上面说到的死锁问题
5.1 互斥条件:
进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
5.2 不可剥夺条件:
进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)。
5.3 请求与保持条件:
进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
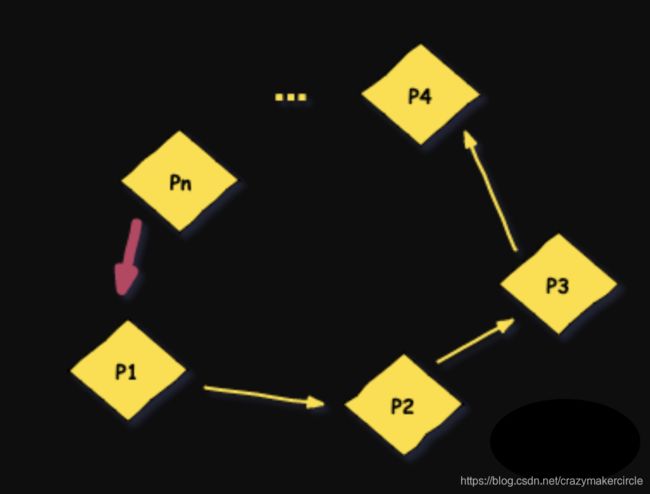
5.4 循环等待条件:
存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被 链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中Pi等 待的资源被P(i+1)占有(i=0, 1, …, n-1),Pn等待的资源被P0占有,如图2-15所示。
直观上看,循环等待条件似乎和死锁的定义一样,其实不然。按死锁定义构成等待环所 要求的条件更严,它要求Pi等待的资源必须由P(i+1)来满足,而循环等待条件则无此限制。 例如,系统中有两台输出设备,P0占有一台,PK占有另一台,且K不属于集合{0, 1, …, n}。
Pn等待一台输出设备,它可以从P0获得,也可能从PK获得。因此,虽然Pn、P0和其他 一些进程形成了循环等待圈,但PK不在圈内,若PK释放了输出设备,则可打破循环等待, 如图2-16所示。因此循环等待只是死锁的必要条件。
资源分配图含圈而系统又不一定有死锁的原因是同类资源数大于1。但若系统中每类资 源都只有一个资源,则资源分配图含圈就变成了系统出现死锁的充分必要条件。
以上这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
产生死锁的一个例子:
/**
* 一个简单的死锁类
* 当DeadLock类的对象flag==1时(td1),先锁定o1,睡眠500毫秒
* 而td1在睡眠的时候另一个flag==0的对象(td2)线程启动,先锁定o2,睡眠500毫秒
* td1睡眠结束后需要锁定o2才能继续执行,而此时o2已被td2锁定;
* td2睡眠结束后需要锁定o1才能继续执行,而此时o1已被td1锁定;
* td1、td2相互等待,都需要得到对方锁定的资源才能继续执行,从而死锁。
*/
public class DeadLock implements Runnable {
public int flag = 1;
//静态对象是类的所有对象共享的
private static Object o1 = new Object(), o2 = new Object();
@Override
public void run() {
System.out.println("flag=" + flag);
if (flag == 1) {
synchronized (o1) {
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o2) {
System.out.println("1");
}
}
}
if (flag == 0) {
synchronized (o2) {
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o1) {
System.out.println("0");
}
}
}
}
public static void main(String[] args) {
DeadLock td1 = new DeadLock();
DeadLock td2 = new DeadLock();
td1.flag = 1;
td2.flag = 0;
//td1,td2都处于可执行状态,但JVM线程调度先执行哪个线程是不确定的。
//td2的run()可能在td1的run()之前运行
new Thread(td1).start();
new Thread(td2).start();
}
}
六、处理死锁的方法
- 预防死锁:通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或几个条件,来防止死锁的发生。
- 避免死锁:在资源的动态分配过程中,用某种方法去防止系统进入不安全状态,从而避免死锁的发生。
- 检测死锁:允许系统在运行过程中发生死锁,但可设置检测机构及时检测死锁的发生,并采取适当措施加以清除。
- 解除死锁:当检测出死锁后,便采取适当措施将进程从死锁状态中解脱出来。
七、 预防死锁
通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或几个条件,来防止死锁的发生
破坏死锁的条件:
-
破坏“互斥”条件:
就是在系统里取消互斥。若资源不被一个进程独占使用,那么死锁是肯定不会发生的。但一般来说在所列的四个条件中,“互斥”条件是无法破坏的。因此,在死锁预防里主要是破坏其他几个必要条件,而不去涉及破坏“互斥”条件。注意:互斥条件不能被破坏,否则会造成结果的不可再现性。
-
破坏“占有并等待”条件:
破坏“占有并等待”条件,就是在系统中不允许进程在已获得某种资源的情况下,申请其他资源。即要想出一个办法,阻止进程在持有资源的同时申请其他资源。
方法一:创建进程时,要求它申请所需的全部资源,系统或满足其所有要求,或什么也不给它。这是所谓的 “ 一次性分配”方案。
方法二:要求每个进程提出新的资源申请前,释放它所占有的资源。这样,一个进程在需要资源S时,须先把它先前占有的资源R释放掉,然后才能提出对S的申请,即使它可能很快又要用到资源R。 -
破坏“不可抢占”条件:
破坏“不可抢占”条件就是允许对资源实行抢夺。
方法一:如果占有某些资源的一个进程进行进一步资源请求被拒绝,则该进程必须释放它最初占有的资源,如果有必要,可再次请求这些资源和另外的资源。
方法二:如果一个进程请求当前被另一个进程占有的一个资源,则操作系统可以抢占另一个进程,要求它释放资源。只有在任意两个进程的优先级都不相同的条件下,方法二才能预防死锁。 -
破坏“循环等待”条件:
破坏“循环等待”条件的一种方法,是将系统中的所有资源统一编号,进程可在任何时刻提出资源申请,但所有申请必须按照资源的编号顺序(升序)提出。这样做就能保证系统不出现死锁。
银行转账经典案例中的死锁的避免
解决前面的银行转账经典案例的死锁, 有以下方法
方法一:破坏请求和保持条件
每个柜员都可以取放账本,很容易出现互相等待的情况。要想破坏请求和保持条件,就要一次性拿到所有资源。
可以不允许柜员都可以取放账本,账本要由单独的账本管理员来管理
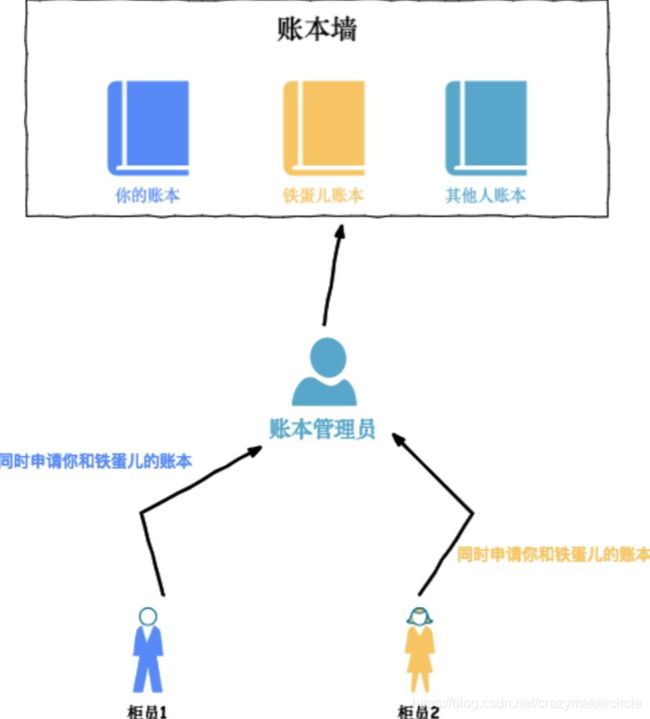
也就是说账本管理员拿取账本是临界区,如果只拿到其中之一的账本,那么不会给柜员,而是等待柜员下一次询问是否两个账本都在
//账本管理员
public class AccountBookManager {
synchronized boolean getAllRequiredAccountBook( Object from, Object to){
if(拿到所有账本){
return true;
} else{
return false;
}
}
// 归还资源
synchronized void releaseObtainedAccountBook(Object from, Object to){
归还获取到的账本
}
}
public class Account {
//单例的账本管理员
private AccountBookManager accountBookManager;
public void transfer(Account target, int amt){
// 一次性申请转出账户和转入账户,直到成功
while(!accountBookManager.getAllRequiredAccountBook(this, target)){
return;
}
try{
// 锁定转出账户
synchronized(this){
// 锁定转入账户
synchronized(target){
if (this.balance > amt){
this.balance -= amt;
target.balance += amt;
}
}
}
} finally {
accountBookManager.releaseObtainedAccountBook(this, target);
}
}
}
方法二:破坏不可剥夺条件
上面已经给了你小小的提示,为了解决内置锁的执着,Java 显示锁支持通知(notify/notifyall)和等待(wait),也就是说该功能可以实现喊一嗓子 老铁,铁蛋儿的账本先给我用一下,用完还给你 的功能,
还有,可以通过 加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)去解决。
下面是一个类似的例子。
在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。这段随机的等待时间让其它线程有机会尝试获取相同的这些锁,并且让该应用在没有获得锁的时候可以继续运行(译者注:加锁超时后可以先继续运行干点其它事情,再回头来重复之前加锁的逻辑)。
以下是一个例子,展示了两个线程以不同的顺序尝试获取相同的两个锁,在发生超时后回退并重试的场景:
Thread 1 locks A
Thread 2 locks B
Thread 1 attempts to lock B but is blocked
Thread 2 attempts to lock A but is blocked
Thread 1’s lock attempt on B times out
Thread 1 backs up and releases A as well
Thread 1 waits randomly (e.g. 257 millis) before retrying.
Thread 2’s lock attempt on A times out
Thread 2 backs up and releases B as well
Thread 2 waits randomly (e.g. 43 millis) before retrying.
在上面的例子中,线程2比线程1早200毫秒进行重试加锁,因此它可以先成功地获取到两个锁。这时,线程1尝试获取锁A并且处于等待状态。当线程2结束时,线程1也可以顺利的获得这两个锁(除非线程2或者其它线程在线程1成功获得两个锁之前又获得其中的一些锁)。
需要注意的是,由于存在锁的超时,所以我们不能认为这种场景就一定是出现了死锁。也可能是因为获得了锁的线程(导致其它线程超时)需要很长的时间去完成它的任务。
此外,如果有非常多的线程同一时间去竞争同一批资源,就算有超时和回退机制,还是可能会导致这些线程重复地尝试但却始终得不到锁。如果只有两个线程,并且重试的超时时间设定为0到500毫秒之间,这种现象可能不会发生,但是如果是10个或20个线程情况就不同了。因为这些线程等待相等的重试时间的概率就高的多(或者非常接近以至于会出现问题)。
(译者注:超时和重试机制是为了避免在同一时间出现的竞争,但是当线程很多时,其中两个或多个线程的超时时间一样或者接近的可能性就会很大,因此就算出现竞争而导致超时后,由于超时时间一样,它们又会同时开始重试,导致新一轮的竞争,带来了新的问题。)
这种机制存在一个问题,在Java中不能对synchronized同步块设置超时时间。需要使用 JUC 的显式锁。
方法三:破坏环路等待条件
破坏环路等待条件,就是按照相同的顺序获得锁。
如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。看下面这个例子:
Thread 1:
lock A
lock B
Thread 2:
wait for A
lock C (when A locked)
Thread 3:
wait for A
wait for B
wait for C
如果一个线程(比如线程3)需要一些锁,那么它必须按照确定的顺序获取锁。它只有获得了从顺序上排在前面的锁之后,才能获取后面的锁。
例如,线程2和线程3只有在获取了锁A之后才能尝试获取锁C(译者注:获取锁A是获取锁C的必要条件)。因为线程1已经拥有了锁A,所以线程2和3需要一直等到锁A被释放。然后在它们尝试对B或C加锁之前,必须成功地对A加了锁。
按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁(译者注:并对这些锁做适当的排序),但总有些时候是无法预知的。
破坏环路等待条件也很简单,我们只需要将资源序号大小排序获取就会解决这个问题,将环路拆除
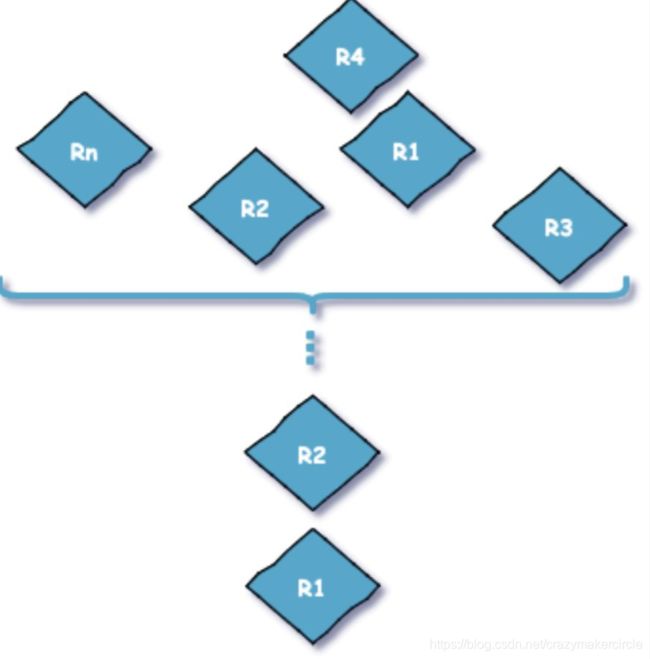
按照id大小的顺序来加锁,先锁住id 小的,然后才锁住 id 大的
class Account {
private int id;
private int balance;
// 转账
void transfer(Account target, int amt){
Account smaller = this
Account larger = target;
// 排序
if (this.id > target.id) {
smaller = target;
larger = this;
}
// 锁定序号小的账户
synchronized(smaller){
// 锁定序号大的账户
synchronized(larger){
if (this.balance > amt){
this.balance -= amt;
target.balance += amt;
}
}
}
}
}
当 smaller 被占用时,其他线程就会被阻塞,也就不会存在死锁了.
八 避免死锁
理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何让这四个必要条件不成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。
预防死锁和避免死锁的区别:
预防死锁是设法至少破坏产生死锁的四个必要条件之一,严格的防止死锁的出现,而避免死锁则不那么严格的限制产生死锁的必要条件的存在,因为即使死锁的必要条件存在,也不一定发生死锁。避免死锁是在系统运行过程中注意避免死锁的最终发生。
常用避免死锁的方法
有序资源分配法
这种算法资源按某种规则系统中的所有资源统一编号(例如打印机为1、磁带机为2、磁盘为3、等等),申请时必须以上升的次序。系统要求申请进程:
1、对它所必须使用的而且属于同一类的所有资源,必须一次申请完;
2、在申请不同类资源时,必须按各类设备的编号依次申请。例如:进程PA,使用资源的顺序是R1,R2; 进程PB,使用资源的顺序是R2,R1;若采用动态分配有可能形成环路条件,造成死锁。
采用有序资源分配法:R1的编号为1,R2的编号为2;
PA:申请次序应是:R1,R2
PB:申请次序应是:R1,R2
这样就破坏了环路条件,避免了死锁的发生。
银行家算法
详见银行家算法.
九 检测死锁
死锁检测是一个更好的死锁预防机制,它主要是针对那些不可能实现按序加锁并且锁超时也不可行的场景。
每当一个线程获得了锁,会在线程和锁相关的数据结构中(map、graph等等)将其记下。除此之外,每当有线程请求锁,也需要记录在这个数据结构中。
当一个线程请求锁失败时,这个线程可以遍历锁的关系图看看是否有死锁发生。例如,线程A请求锁7,但是锁7这个时候被线程B持有,这时线程A就可以检查一下线程B是否已经请求了线程A当前所持有的锁。如果线程B确实有这样的请求,那么就是发生了死锁(线程A拥有锁1,请求锁7;线程B拥有锁7,请求锁1)。
当然,死锁一般要比两个线程互相持有对方的锁这种情况要复杂的多。线程A等待线程B,线程B等待线程C,线程C等待线程D,线程D又在等待线程A。线程A为了检测死锁,它需要递进地检测所有被B请求的锁。从线程B所请求的锁开始,线程A找到了线程C,然后又找到了线程D,发现线程D请求的锁被线程A自己持有着。这是它就知道发生了死锁。
下面是一幅关于四个线程(A,B,C和D)之间锁占有和请求的关系图。像这样的数据结构就可以被用来检测死锁。
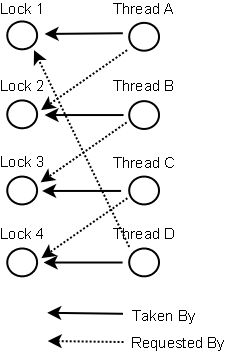
一般来说,由于操作系统有并发,共享以及随机性等特点,通过预防和避免的手段达到排除死锁的目的是很困难的。这需要较大的系统开销,而且不能充分利用资源。为此,一种简便的方法是系统为进程分配资源时,不采取任何限制性措施,但是提供了检测和解脱死锁的手段:能发现死锁并从死锁状态中恢复出来。因此,在实际的操作系统中往往采用死锁的检测与恢复方法来排除死锁。
死锁检测与恢复是指系统设有专门的机构,当死锁发生时,该机构能够检测到死锁发生的位置和原因,并能通过外力破坏死锁发生的必要条件,从而使得并发进程从死锁状态中恢复出来。
这时进程P1占有资源R1而申请资源R2,进程P2占有资源R2而申请资源R1,按循环等待条件,进程和资源形成了环路,所以系统是死锁状态。进程P1,P2是参与死锁的进程。
下面我们再来看一看死锁检测算法。算法使用的数据结构是如下这些:
占有矩阵A:nm阶,其中n表示并发进程的个数,m表示系统的各类资源的个数,这个矩阵记录了每一个进程当前占有各个资源类中资源的个数。
申请矩阵R:nm阶,其中n表示并发进程的个数,m表示系统的各类资源的个数,这个矩阵记录了每一个进程当前要完成工作需要申请的各个资源类中资源的个数。
空闲向量T:记录当前m个资源类中空闲资源的个数。
完成向量F:布尔型向量值为真(true)或假(false),记录当前n个并发进程能否进行完。为真即能进行完,为假则不能进行完。
临时向量W:开始时W:=T。
算法步骤:
(1)W:=T,
对于所有的i=1,2,…,n,
如果A[i]=0,则F[i]:=true;否则,F[i]:=false
(2)找满足下面条件的下标i:
F[i]:=false并且R[i]〈=W
如果不存在满足上面的条件i,则转到步骤(4)。
(3)W:=W+A[i]
F[i]:=true
转到步骤(2)
(4)如果存在i,F[i]:=false,则系统处于死锁状态,且Pi进程参与了死锁。什么时候进行死锁的检测取决于死锁发生的频率。如果死锁发生的频率高,那么死锁检测的频率也要相应提高,这样一方面可以提高系统资源的利用率,一方面可以避免更多的进程卷入死锁。如果进程申请资源不能满足就立刻进行检测,那么每当死锁形成时即能被发现,这和死锁避免的算法相近,只是系统的开销较大。为了减小死锁检测带来的系统开销,一般采取每隔一段时间进行一次死锁检测,或者在CPU的利用率降低到某一数值时,进行死锁的检测。
十 解除死锁
一旦检测出死锁,就应立即釆取相应的措施,以解除死锁。
死锁解除的主要方法有:
- 资源剥夺法。挂起某些死锁进程,并抢占它的资源,将这些资源分配给其他的死锁进程。但应防止被挂起的进程长时间得不到资源,而处于资源匮乏的状态。
- 撤销进程法。强制撤销部分、甚至全部死锁进程并剥夺这些进程的资源。撤销的原则可以按进程优先级和撤销进程代价的高低进行。
- 进程回退法。让一(多)个进程回退到足以回避死锁的地步,进程回退时自愿释放资源而不是被剥夺。要求系统保持进程的历史信息,设置还原点。
参考文档:
https://cloud.tencent.com/developer/article/1541513
https://blog.csdn.net/fdoubleman/article/details/97238420
http://www.voidcn.com/article/p-gjtwwpmp-ws.html
https://blog.csdn.net/hd12370/article/details/82814348