disruptor (史上最全之1):伪共享原理&性能对比实战
推荐:尼恩Java面试宝典(持续更新 + 史上最全 + 面试必备)具体详情,请点击此链接
尼恩Java面试宝典,34个最新pdf,含2000多页,不断更新、持续迭代 具体详情,请点击此链接

disruptor 史上最全 系列文章:
作为Java领域最高性能的 队列,没有之一, 大家不光要懂,而是 需要深入骨髓的搞懂。 所以,给大家奉上了下面的三篇文章,并且配备了视频进行 详细介绍:
-
1 disruptor 史上最全 之1:伪共享 原理&性能对比实战
-
2 disruptor 使用和原理 图解
-
3 disruptor 源码 分析
在介绍 无锁框架 disruptor 之前,作为前置的知识,首先给大家介绍 伪共享 原理&性能对比实战 。
CPU的结构
下图是计算的基本结构。
L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。
-
L1缓存很小但很快,并且紧靠着在使用它的CPU内核;
-
L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;
-
L3更大、更慢,并且被单个插槽上的所有CPU核共享;
-
最后是主存,由全部插槽上的所有CPU核共享。
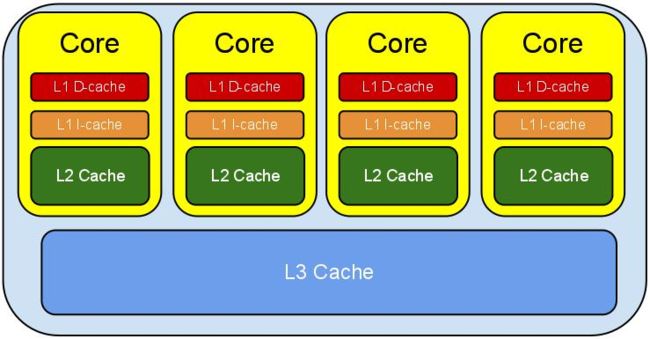
级别越小的缓存,越接近CPU, 意味着速度越快且容量越少。
L1是最接近CPU的,它容量最小**(比如256个字节)**,速度最快,
每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache);
L2 Cache 更大一些**(比如256K个字节)**,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;
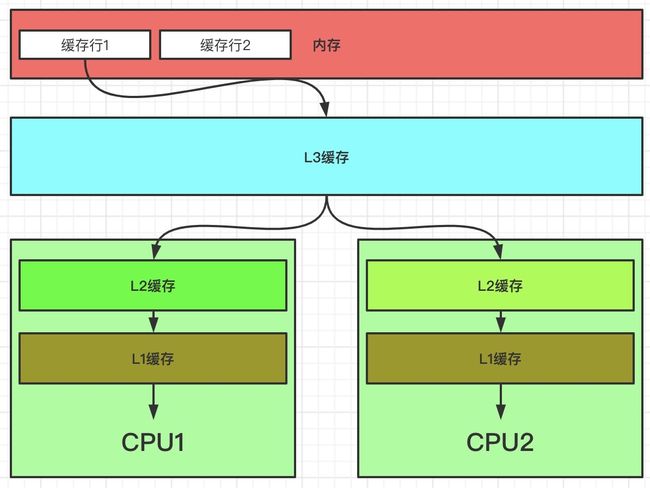
二级缓存就是一级缓存的存储器:
一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些CPU处理时需要用到、一级缓存又无法存储的数据。
L3 Cache是三级缓存中最大的一级,例如**(比如12MB个字节)**,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。
三级缓存和内存可以看作是二级缓存的存储器,它们的容量递增,但单位制造成本却递减。
L3 Cache和L1,L2 Cache有着本质的区别。
L1和L2 Cache都是每个CPU core独立拥有一个,而L3 Cache是几个Cores共享的,可以认为是一个更小但是更快的内存。
缓存行 cache line
为了提高IO效率,CPU每次从内存读取数据,并不是只读取我们需要计算的数据,而是一批一批去读取的,这一批数据,也叫Cache Line(缓存行)。
也可以理解为批量读取,提升性能。 为啥要一批、一批的读取呢? 这也满足 空间的局部性原理(具体请参见葵花宝典)。
从读取的角度来说,缓存,是由缓存行Cache Line组成的。
所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;
换句话说,CPU存取缓存都是按照一行,为最小单位操作的。并不是按照字节为单位,进行操作的。
一般而言,读取一行数据时,是将我们需要的数据周围的连续数据一次性全部读取到缓存中。这段连续的数据就称为一个缓存行。
一般一行缓存行有64字节。intel处理器的缓存行是64字节。目前主流的CPU Cache的Cache Line大小都是64Bytes。
假设我们有一个512 Bytes 的一级缓存,那么按照64 Bytes 的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个。
所以,Cache Line可以简单的理解为CPU Cache中的最小缓存单位。
什么是 伪共享(False Sharing)问题?
提前说明: 翻译 有瑕疵, 伪共享(False Sharing), 应该翻译为 “错共享”, 才更准确
CPU的缓存系统是以缓存行(cache line)为单位存储的,一般的大小为64bytes。
在多线程程序的执行过程中,存在着一种情况,多个需要频繁修改的变量存在同一个缓存行当中。
假设:有两个线程分别访问并修改X和Y这两个变量,X和Y恰好在同一个缓存行上,这两个线程分别在不同的CPU上执行。
那么每个CPU分别更新好X和Y时将缓存行刷入内存时,发现有别的修改了各自缓存行内的数据,这时缓存行会失效,从L3中重新获取。
这样的话,程序执行效率明显下降。
为了减少这种情况的发生,其实就是避免X和Y在同一个缓存行中,
如何操作呢?可以主动添加一些无关变量将缓存行填充满,
比如在X对象中添加一些变量,让它有64 Byte那么大,正好占满一个缓存行。
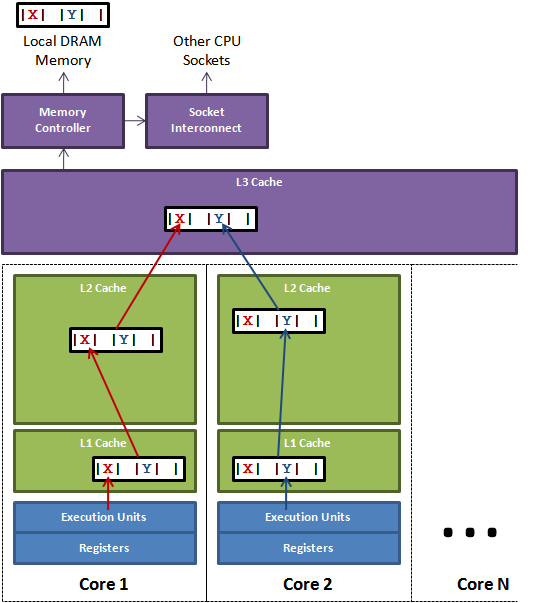
两个线程(Thread1 和 Thread2)同时修改一个同一个缓存行上的数据 X Y:
如果线程1打算更改a的值,而线程2准备更改b的值:
Thread1:x=3;
Thread2:y=2;
由x值被更新了,所以x值需要在线程1和线程2之间传递(从线程1到线程2),
x、y的变更,都会引起 cache line 整块 64 bytes 被刷新,因为cpu核之间以cache line的形式交换数据(cache lines的大小一般为64bytes)。
在并发执行的场景下,每个线程在不同的核中被处理。
假设 x,y是两个频繁修改的变量,x,y,还位于同一个缓存行.
如果,CPU1修改了变量x时,L3中的缓存行数据就失效了,也就是CPU2中的缓存行数据也失效了,CPU2需要的y需要重新从内存加载。
如果,CPU2修改了变量y时,L3中的缓存行数据就失效了,也就是CPU1中的缓存行数据也失效了,CPU1需要的x需要重新从内存加载。
x,y在两个cpu上进行修改,本来应该是互不影响的,但是由于缓存行在一起,导致了相互受到了影响。
伪共享问题(False Sharing)的本质
出现伪共享问题(False Sharing)的原因:
-
一个缓存行可以存储多个变量(存满当前缓存行的字节数);64个字节可以放8个long,16个int
-
而CPU对缓存的修改又是以缓存行为最小单位的; 不是以long 、byte这样的数据类型为单位的
-
在多线程情况下,如果需要修改“共享同一个缓存行的其中一个变量”,该行中其他变量的状态 就会失效,甚至进行一致性保护
所以,伪共享问题(False Sharing)的本质是:
对缓存行中的单个变量进行修改了,导致整个缓存行其他不相关的数据也就失效了,需要从主存重新加载
如果 其中有 volatile 修饰的变量,需要保证线程可见性的变量,还需要进入 缓存与数据一致性的保障流程, 如mesi协议的数据一致性保障 用了其他变量的 Core的缓存一致性。
缓存一致性是根据缓存行为单元来进行同步的,假如 y是 volatile 类型的,假如a修改了x,而其他的线程用到y,虽然用到的不是同一个数据,但是他们(数据X和数据Y)在同一个缓存行中,其他的线程的缓存需要保障数据一致性而进行数据同步,当然,同步也需要时间。
一个CPU核心在加载一个缓存行时要执行上百条指令。如果一个核心要等待另外一个核心来重新加载缓存行,那么他就必须等在那里,称之为stall(停止运转)。
伪共享问题 的解决方案
减少伪共享也就意味着减少了stall的发生,其中一个手段就是通过填充(Padding)数据的形式,来保证本应有可能位于同一个缓存行的两个变量,在被多线程访问时必定位于不同的缓存行。
简单的说,就是 以空间换时间: 使用占位字节,将变量的所在的 缓冲行 塞满。
disruptor 无锁框架就是这么干的。
一个缓冲行填充的例子
下面是一个填充了的缓存行的,尝试 p1, p2, p3, p4, p5, p6为AtomicLong的value的缓存行占位,将AtomicLong的value变量的所在的 缓冲行 塞满,
代码如下:
package com.crazymakercircle.demo.cas;
import java.util.concurrent.atomic.AtomicLong;
public class PaddedAtomicLong extends AtomicLong {
private static final long serialVersionUID = -3415778863941386253L;
/**
* Padded 6 long (48 bytes)
*/
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
/**
* Constructors from {@link AtomicLong}
*/
public PaddedAtomicLong() {
super();
}
public PaddedAtomicLong(long initialValue) {
super(initialValue);
}
/**
* To prevent GC optimizations for cleaning unused padded references
*/
public long sumPaddingToPreventOptimization() {
return p1 + p2 + p3 + p4 + p5 + p6;
}
}
例子的部分结果如下:
printable = com.crazymakercircle.basic.demo.cas.busi.PaddedAtomicLong object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 50 08 01 f8 (01010000 00001000 00000001 11111000) (-134150064)
12 4 (alignment/padding gap)
16 8 long AtomicLong.value 0
24 8 long PaddedAtomicLong.p1 0
32 8 long PaddedAtomicLong.p2 0
40 8 long PaddedAtomicLong.p3 0
48 8 long PaddedAtomicLong.p4 0
56 8 long PaddedAtomicLong.p5 0
64 8 long PaddedAtomicLong.p6 7
Instance size: 72 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
伪共享False Sharing在java 8中解决方案
JAVA 8中添加了一个@Contended的注解,添加这个的注解,将会在自动进行缓存行填充。
在LongAdder在java8中的实现已经采用了@Contended。
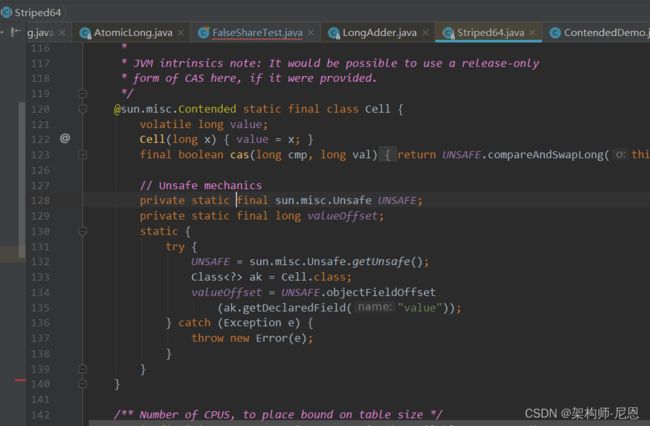
下面有一个@Contended的例子:
package com.crazymakercircle.basic.demo.cas.busi;
import sun.misc.Contended;
public class ContendedDemo
{
//有填充的演示成员
@Contended
public volatile long padVar;
//没有填充的演示成员
public volatile long notPadVar;
}
以上代码使得padVar和notPadVar都在不同的cache line中。@Contended 使得notPadVar字段远离了对象头部分。
printable = com.crazymakercircle.basic.demo.cas.busi.ContendedDemo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 50 08 01 f8 (01010000 00001000 00000001 11111000) (-134150064)
12 4 (alignment/padding gap)
16 8 long ContendedDemo.padVar 0
24 8 long ContendedDemo.notPadVar 0
Instance size: 32 bytes
Space losses: 4 bytes internal + 0 bytes external = 4 bytes total
执行时,必须加上虚拟机参数-XX:-RestrictContended,@Contended注释才会生效。
很多文章把这个漏掉了,那样的话实际上就没有起作用。
新的结果;
printable = com.crazymakercircle.basic.demo.cas.busi.ContendedDemo object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 50 08 01 f8 (01010000 00001000 00000001 11111000) (-134150064)
12 4 (alignment/padding gap)
16 8 long ContendedDemo.notPadVar 0
24 128 (alignment/padding gap)
152 8 long ContendedDemo.padVar 0
160 128 (loss due to the next object alignment)
Instance size: 288 bytes
Space losses: 132 bytes internal + 128 bytes external = 260 bytes total
在Java 8中,使用@Contended注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。我们目前的缓存行大小一般为64Byte,这里Contended注解为我们前后加上了128字节绰绰有余。
注意:如果想要@Contended注解起作用,需要在启动时添加JVM参数-XX:-RestrictContended 参数后 @sun.misc.Contended 注解才有。
可见至少在JDK1.8以上环境下, 只有@Contended注解才能解决伪共享问题, 但是消耗也很大, 占用了宝贵的缓存, 用的时候要谨慎。
另外:
@Contended 注释还可以添加在类上,每一个成员,都会加上。
伪共享性能比对实操:结论,差6倍
三个实操:
-
首先存在伪共享场景下的 耗时计算
-
其次是消除伪共享场景下的 耗时计算
-
再次是使用unsafe访问变量时的耗时计算
存在伪共享场景下的 耗时计算
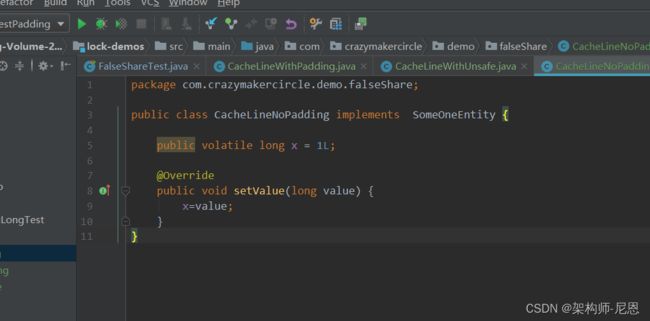
entity类
并行的执行数据修改,这里抽取成为了一个通用的方法
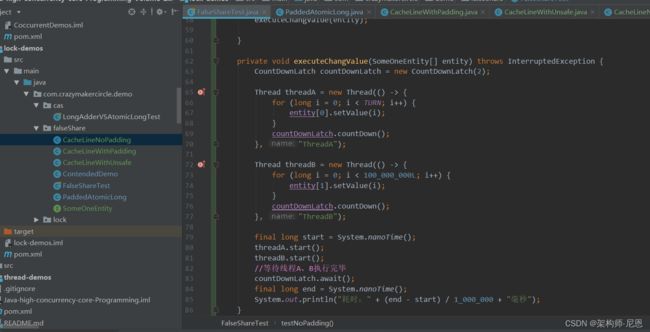
测试用例
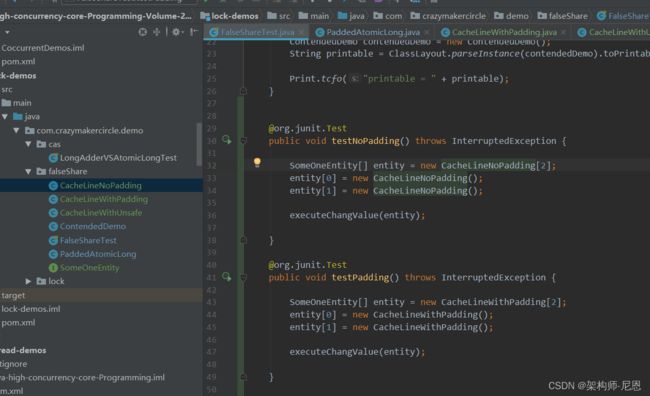
执行的时间
消除伪共享场景下的 耗时计算
entity类
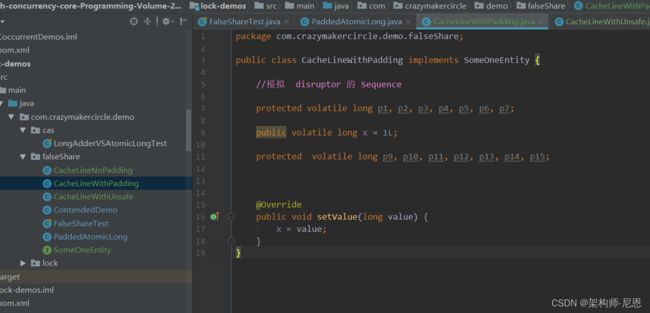
测试用例
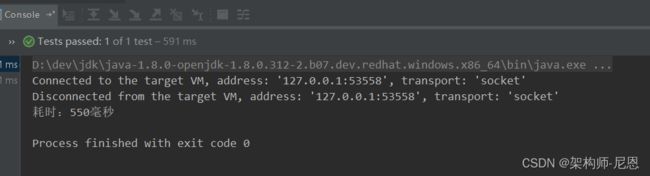
消除伪共享场景下的 耗时计算 (550ms)
使用unsafe访问变量的耗时计算
entity
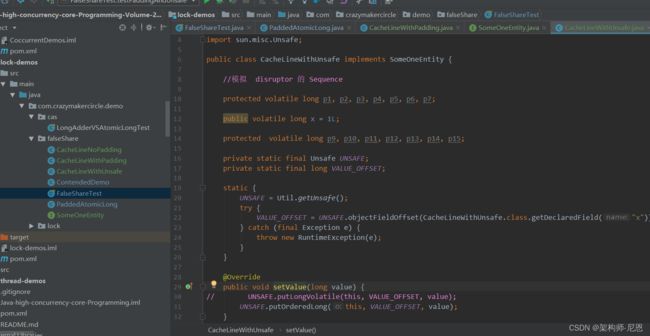

使用unsafe访问变量的耗时计算:
54ms
性能总结
消除伪共享场景 ,比存在伪共享场景 的性能 , 性能提升 6倍左右
使用 unsafe 取消内存可见性,比消除伪共享场景 ,性能提升 10 倍左右
通过实验的对比, 可见Java 的性能,是可以大大优化的,尤其在高性能组件
以上实操的 详细介绍 ,请参见 《100wqps 日志平台实操》
对于伪共享,我们在实际开发中该怎么做?
通过上面大篇幅的介绍,我们已经知道伪共享的对程序的影响。
那么,在实际的生产开发过程中,我们一定要通过缓存行填充去解决掉潜在的伪共享问题吗?
其实并不一定。
首先就是多次强调的,伪共享是很隐蔽的,我们暂时无法从系统层面上通过工具来探测伪共享事件。
其次,不同类型的计算机具有不同的微架构(如 32 位系统和 64 位系统的 java 对象所占自己数就不一样),如果设计到跨平台的设计,那就更难以把握了,一个确切的填充方案只适用于一个特定的操作系统。
还有,缓存的资源是有限的,如果填充会浪费珍贵的 cache 资源,并不适合大范围应用。
最后,目前主流的 Intel 微架构 CPU 的 L1 缓存,已能够达到 80% 以上的命中率。
综上所述,并不是每个系统都适合花大量精力去解决潜在的伪共享问题
参考文献
https://blog.csdn.net/hxg117/article/details/78064632
http://openjdk.java.net/projects/jdk8/features
http://beautynbits.blogspot.co.uk/2012/11/the-end-for-false-sharing-in-java.html
http://openjdk.java.net/jeps/142
http://mechanical-sympathy.blogspot.co.uk/2011/08/false-sharing-java-7.html
http://stackoverflow.com/questions/19892322/when-will-jvm-use-intrinsics
https://blogs.oracle.com/dave/entry/java_contented_annotation_to_help
https://www.jianshu.com/p/b38ffa33d64d
https://blog.csdn.net/MrYushiwen/article/details/123171635