论文阅读:A Survey of Embodied AI: From Simulators toResearch Tasks

介绍
具身智能可粗略定义为,智能体(可以是生物或机械),通过与环境产生交互后,通过自身的学习,产生对于客观世界的理解和改造能力。具身智能假设,智能行为可以被具有对应形态的智能体通过适应环境的方式学习到。因此,地球上所有的生物,都可以说是具身智能。
但就目前而言,具身智能是将视觉、语言和推理等传统智能概念融入人工智能体中,以帮助解决虚拟环境中的人工智能问题。
具身智能模拟器
具身智能模拟器

具身AI模拟器概述。 环境:基于游戏的场景构建(G)和基于世界的场景构建(W)。 物理:基础物理特征(B)和高级物理特征(A)。 对象类型:数据集驱动环境(D)和对象资产驱动环境(O)。 对象属性:可交互对象(I)和多状态对象(M)。 控制器:直接Python API控制器(P)、虚拟机器人控制器(R)和虚拟现实控制器(V)。 行动:导航(N)、原子行动(A)和人机交互(H)。 多智能体:基于虚拟角色的(AT)和基于用户的(U)。 这七个特征可以进一步归类到三个二级评价特征下; 真实感、可扩展性和交互性。
环境

构建具身智能模拟器环境的方法主要有两种:基于游戏的场景构建(G)和基于世界的场景构建(W)。 基于游戏的场景是由3D资产构建的,而基于世界的场景是由真实世界的物体和环境扫描构建的。 完全由3D资产构建的3D环境通常具有内置的物理特性和对象类,与由现实世界扫描生成的环境的3D网格相比,这些特性和对象类被很好地分割。 3D资产清晰的对象分割使得将它们建模为具有可移动关节的铰接对象变得容易,例如PartNet中提供的3D模型。 相比之下,对环境和对象的真实世界扫描提供了更高的保真度和更准确的真实世界表示,有助于更好地将智能体的性能从模拟转移到真实世界。
物理

模拟器不仅要构建真实的环境,还要构建智能体与对象之间的真实交互,或者对象与对象之间的真实交互,以模拟真实世界的物理特性。 我们研究了模拟器的物理特性,将其大致分为基本物理特性(B)和高级物理特性(A)。 基本物理特征包括碰撞、刚体动力学和重力模型,高级物理特征包括布、流体和软体物理。 由于大多数具身智能模拟器使用内置的物理引擎构建基于游戏的场景,它们配备了基本的物理特性。 另一方面,对于像ThreedWorld这样的模拟器,其目标是了解复杂的物理环境如何塑造环境中人工代理的决策,它们配备了更先进的物理能力。 对于专注于基于交互式导航任务的模拟器,基本的物理特性通常就足够了
对象类型
用于创建模拟器的对象有两个主要来源。 第一种类型是数据集驱动环境,其中的对象主要来自现有的对象数据集,如SunCG[33]数据集、MatterPort3D数据集[34]和Gibson数据集[35]。 第二种类型是资产驱动环境,其中的对象来自网络,如Unity 3D Game Asset Store。 这两个源之间的区别在于对象数据集的可持续性。 数据集驱动的对象比资产驱动的对象收集成本更高,因为任何人都可以在线为3D对象模型做出贡献。 然而,与数据集驱动的对象相比,资产驱动的对象更难保证三维对象模型的质量。 基于我们的回顾,基于游戏的具身智能模拟器更有可能从资产存储中获取其对象数据集,而基于世界的模拟器倾向于从现有的3D对象数据集导入其对象数据集。
对象属性
一些模拟器仅启用具有基本交互性(例如碰撞)的对象。高级模拟器使对象具有更细粒度的交互性,例如多状态更改。例如,当一个苹果被切片时,它会经历一个状态变化,变成苹果片。因此,我们将这些不同级别的对象交互分为具有可交互对象 (I) 和多状态对象 (M) 的模拟器。参考表 1,一些模拟器,如 AI2-THOR 和 VRKitchen,支持多种状态变化,提供了一个平台来理解物体在现实世界中受到影响时将如何反应和改变它们的状态。
控制器

在用户和模拟器之间有不同类型的控制器接口,从直接的Python API控制器(P)和虚拟机器人控制器(R)到虚拟现实控制器(V)。 具身化的智能体允许诸如Universal Robot 5(UR5)和Turtlebot V2的现有现实世界机器人的虚拟交互,并且可以直接使用ROS接口来控制。 虚拟现实控制器接口提供了更沉浸式的人机交互,并便于使用现实世界中的相应接口进行部署。 例如,像Igibson和AI2-Thor这样的模拟器主要是为视觉导航而设计的,它们也配备了虚拟机器人控制器,以便于在现实世界中部署,例如Igibson的Castro和Robothor。
动作
在所体现的AI模拟器中,智能体的动作能力的复杂性存在差异,从只能执行主要的导航操作到通过虚拟现实界面进行更高级别的人机操作。 本文将其划分为三个层次:导航(N)、原子动作(A)和人机交互(H)。 导航是最低层,是所有包含AI模拟器的共同特性。 它是由智能体在其虚拟环境中导航的能力定义的。 原子动作为智能体提供了对感兴趣的对象执行基本离散操作的手段,在大多数具身智能模拟器中都有。 人机交互是虚拟现实控制器的结果,因为它使人能够控制虚拟智能体实时地学习和与模拟世界交互。 大多数较大规模的基于导航的模拟器,如AI2-Thor、Igibson和Habitatsim,往往具有导航、原子动作和ROS,这使得它们能够在执行点导航或对象导航等任务时更好地控制和操纵环境中的对象。 另一方面,诸如ThreedWorld和VRKitchen等模拟器属于人机交互范畴,因为它们被构造为提供高度逼真的基于物理的模拟和多种状态变化。这只有在人机交互中才有可能,因为当与这些虚拟对象交互时,需要人的灵巧度。
多智能体
目前关于多智能体强化学习的研究还很少,只有AI2-Thor、Igibson和ThreeDworld等几个模拟器配备了多智能体系统。 一般说来,模拟器需要有丰富的对象内容,然后才有任何实用价值来构造这种多智能体特征,用于人工智能体的对抗训练和协作训练。 由于缺乏多Agent支持的模拟器,在这些具体的人工智能模拟器中利用多Agent特性的研究任务较少。
对于基于多智能体强化学习的训练,它们目前仍在OpenAI Gym环境中进行。 有两种不同的多智能体设置。 第一个是ThreeDWorld中基于虚拟角色的多智能体,它允许智能体和模拟器虚拟角色之间的交互。 第二种是AI2Thor中的基于用户(U)的多智能体,它可以扮演双重学习网络的角色,在模拟中通过与其他人工智能体的交互来学习,以实现共同的任务。
对比具身智能模拟器
在这七个特征的基础上,结合Allen Institute of Artificial Intelligence对具身智能的研究,我们提出了模拟器的二级评估特征集。 它包括三个关键特征:真实感、可伸缩性和交互性。三维环境的真实感可以归因于模拟器的环境和物理。 环境模拟了现实世界的物理外观,而物理模拟了现实世界中复杂的物理属性。 三维环境的可伸缩性可以归因于对象类型。 扩展可以通过为数据集驱动的对象收集更多的真实世界的3D扫描或为资产驱动的对象购买更多的3D资产来完成。 交互性包括对象属性、控制器、动作和多智能体。

具身智能研究任务
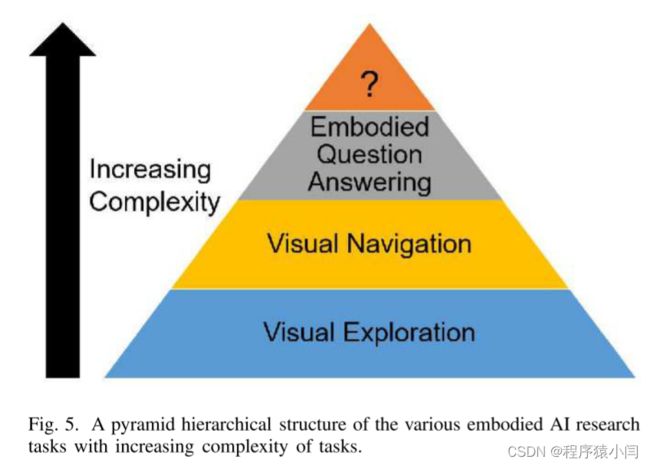
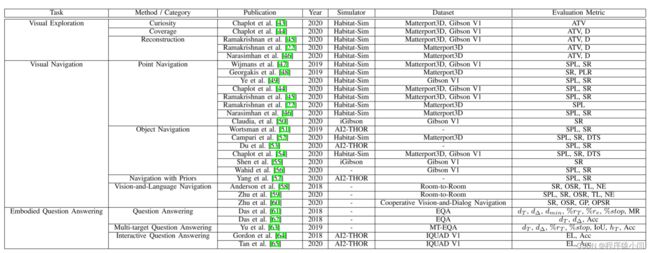
视觉探索
在视觉探索任务中,智能体通常通过运动和感知收集关于3D环境的信息,以更新其环境的内部模型,这可能对下游任务如视觉导航有用。 目的是尽可能有效地做到这一点(例如,用尽可能少的步骤)。 内部模型可以是拓扑图、语义图、占用图或空间存储器等形式。 这些基于地图的体系结构可以捕获几何和语义,与反应性和递归神经网络策略相比,允许更有效的策略学习和规划。 视觉探索通常要么在导航任务之前进行,要么与导航任务同时进行。 在第一种情况下,视觉探索将internal memory构建为先验信息,用于下游导航任务中的路径规划。 在导航开始前,智能体可以在一定的预算范围内(例如,有限的步骤数)自由地探索环境。 在后一种情况下,智能体在导航一个看不见的测试环境时构建映射,这使得它与下游任务更加紧密地集成在一起。
在经典机器人学中,探索是通过被动或主动的同时定位和绘图(SLAM)来建立环境地图。 然后将此地图用于导航任务的定位和路径规划。 SLAM已经得到了很好的研究,但是纯几何方法还有改进的余地。 由于它们依赖于传感器,它们容易受到测量噪声的影响,需要进行广泛的微调。 另一方面,通常使用RGB和深度传感器的基于学习的方法对噪声更鲁棒。 此外,视觉探索中基于学习的方法允许智能体结合语义理解(例如环境中的对象类型)并概括其以前看到的环境的知识,以帮助以无监督的方式理解新的环境。 这减少了对人的依赖,从而提高了效率。
学习以地图的形式创建有用的环境内部模型可以提高智能体的性能,无论是在之前(即未指定的下游任务)还是与下游任务同时进行。 智能探索在智能体必须探索随着时间动态展开的新环境的情况下也特别有用,如救援机器人和深海探索机器人。
方法
在本节中,视觉探索中的非基线方法通常被形式化为部分观察马尔可夫决策过程。 POMDP可以用7元组(S,A,T,R,Ω,O,γ)表示,其中状态空间S,作用空间A,转移分布T,奖赏函数R,观测空间Ω,观测分布O,折扣因子γ∈[0,1]。 一般而言,这些方法在POMDP中被视为一种特殊的奖励函数。
1、基线
视觉探索有几个共同的基线。 对于random-actions,智能体从所有动作的均匀分布中取样。 对于前向动作,它总是选择前向动作。 对于前向动作+,代理选择前向动作,但如果碰撞则向左转。 对于frontier-exploration,它使用地图迭代地访问自由空间和未探索空间之间的边缘。
2、好奇心(探索)
在好奇心方法中,智能体寻找难以预测的状态。 预测误差被用作强化学习的奖励信号。这关注内在的奖励和动机,而不是来自环境的外部奖励(内在奖励,指探索奖;外在奖励,指游戏中直接体现的奖励,如游戏分值),这在外部奖励稀少的情况下是有益的。 通常有一个使损失最小的前向动力学模型:L(^ST+1,ST+1)。 在这种情况下,如果Agent在状态ST时采取行动AT,^ST+1是预测的下一个状态,而ST+1是Agent最终将进入的实际下一个状态。 最近的工作列出了好奇心的实际考虑因素,例如使用近端策略优化(PPO)进行策略优化。 好奇心在最近的工作中被用来生成更高级的地图,比如语义地图。 随机性对好奇心方法提出了严重的挑战,因为前向动力学模型可以利用随机性来实现高预测误差(即高回报)。 这可能是由于诸如“noisy-TV”问题(即环境给出的状态具有误导性,环境的状态中包含一个输出随机噪声的 TV,它是不可控和不可预测的,将能够吸引基于好奇心的探索机制的智能体的注意力)或智能体执行动作时的噪声等因素引起的。[68]提出的一个解决方案是使用逆动力学模型,该模型估计Agent从其以前的状态ST-1移动到当前状态ST时采取的行动AT-1,这有助于Agent理解其行动在环境中可以控制什么。 虽然这种方法试图解决环境造成的随机性,但它可能不足以解决智能体行为造成的随机性。 一个例子是智能体使用遥控器随机改变电视频道,允许它积累奖励而没有进展。 为了解决这个更具挑战性的问题,最近提出了一些方法。 随机蒸馏网络[82]是一种预测随机初始化神经网络输出的方法,因为答案是其输入的确定性函数。 另一种方法是分歧探索[81],其中激励智能体探索在一组前向动力学模型的预测之间存在最大分歧或方差的行动空间。 模型收敛于均值,减小了集合的方差,避免了集合陷入随机陷阱。
补充:
预测误差的三个因素:一号因素,预测误差很高,预测器无法从之前看到的例子中泛化。后面的经历会受到高预测误差的影像。二号因素,预测误差很高,因为预测目标是随机 (Stochastic) 的。三号因素,预测误差很高,因为缺少必要信息,或者预测器模型的局限性太大,无法适应复杂的目标函数。
3、覆盖(利用)
在覆盖方法中,智能体试图最大化它直接观察的目标数量。 通常,这将是在环境中看到的区域。 由于智能体使用以自我为中心的观察,它必须基于可能阻碍的3D结构进行导航。 最近的一种方法结合了经典和基于学习的方法。 它使用分析路径规划器和一个学习的SLAM模块,该模块维护空间地图,以避免在训练端到端策略时涉及的高样本复杂性(机器学习算法的样本复杂度(sample complexity)表示成功学习目标函数所需的训练样本数。更准确地说,样本复杂度是开发者需要提供给算法的训练样本的数量,以使算法返回的函数在最佳函数的任意小误差范围内,并且概率任意接近1。)。 该方法还包括噪声模型,以提高物理真实感,从而对现实世界的机器人技术具有推广性。 另一个最近的工作是一个场景记忆转换器,它在其策略网络中的场景记忆上使用自注意力机制,自注意力机制是从Transformer模型改编的。 场景记忆嵌入并存储所有遇到的观察,与需要归纳偏差(归纳偏置使模型具有一定的泛化能力)的地图式记忆相比,允许更大的灵活性和可伸缩性。
4、重构
在重建方法中,智能体试图从观察到的视图重新创建其他视图。 过去的工作主要集中在360度全景图和CAD模型的像素重建,这些模型通常是经过整理的人体照片数据集。 最近的工作已经将这种方法应用于具身智能,具身智能更加复杂,因为模型必须根据智能体的自我中心观察和自身传感器的控制(即主动感知)来执行场景重建。 在最近的一项工作中,智能体利用其以自我为中心的RGB-D观测来重建可见区域以外的占用状态,并将其随时间的预测聚合起来,形成精确的占用地图。 占用率预测是一个按像素分类的任务,在摄像机前面的V×V个单元的局部区域中,每个单元被分配被探索和占用的概率。 与覆盖方法相比,预测占用状态允许智能体处理那些不能直接观察到的区域。 最近的另一项工作侧重于语义重建而不是像素化重建。 该智能体被设计用来预测在采样的查询位置是否存在像“门”这样的语义概念。 使用K-means方法,查询位置的真正重构概念是与其特征表示的J个最近的聚类中心。 如果Agent获得的视图帮助它预测采样查询视图的真实重构概念,它就会得到奖励。
评估指标
访问的目标数量。 考虑不同类型的目标,如区域和感兴趣的对象。 访问面积度量有几个变体,如绝对覆盖面积(以M2为单位)和在场景中探索面积的百分比。
视觉探索性能也可以通过它对下游任务如视觉导航的影响来衡量。这种评价度量范畴在最近的作品中更常见。 利用视觉探索输出(即地图)的下游任务的示例包括图像导航、点导航和对象导航。
数据集
对于视觉探索,一些流行的数据集包括MatterPort3D和Gibson V1。 MatterPort3D和Gibson V1都是具有真实感的RGB数据集,这些数据集包含对具身智能有用的信息,比如深度和语义分割。 Habity-SIM模拟器允许使用这些具有额外功能的数据集,如可配置智能体和多个传感器。Gibson V1还增强了互动和逼真的机器人控制等功能,形成了iGibson。 然而,最近的3D模拟器,如在第二节中提到的那些,都可以用于视觉探索,因为它们都至少提供RGB观测。
视觉导航
在视觉导航中,智能体在有或没有外部先验信息或自然语言指令的情况下,将三维环境导航到目标。 许多类型的目标被用于这项任务,如点、对象、图像和区域。 在本文中,我们将把点和对象作为视觉导航的目标,因为它们是最常见和最基本的目标。 它们可以进一步与感知输入和语言等规范相结合,以构建更复杂的视觉导航任务,如先验导航、视觉和语言导航,甚至具身QA。 在点导航中,智能体的任务是导航到特定点,而在对象导航中,智能体的任务是导航到特定类的对象。
经典的导航方法通常由手工设计的子组件组成,如定位、映射、路径规划和移动。 具身AI中的视觉导航旨在从数据中学习这些导航系统,以减少特定案例的手工工程,从而简化与下游任务的集成,这些任务具有数据驱动的学习方法的优越性,如问答。 也有混合方法旨在结合这两个世界的最佳方案。 如前面在第二节中提到的,基于学习的方法对传感器测量噪声更鲁棒,因为它们使用RGB和深度传感器,并且能够结合对环境的语义理解。 此外,它们使智能体能够概括其以前看到的环境的知识,以无监督的方式帮助理解新的环境,减少人类的努力。
任务分类

1、点导航
在点导航中,智能体的任务是导航到离特定点一定固定距离内的任何位置。 通常,智能体在环境中的原点(0,0,0)处初始化,固定目标点由相对于原点/初始位置的3D坐标(x,y,z)指定。为了成功地完成任务,智能体需要具备多种技能,如视觉感知、情景记忆构建、推理/规划和导航。智能体通常配备了GPS和指南针,允许它访问他们的位置坐标,并隐含他们相对于目标位置的方位。 目标的相对目标坐标可以是静态的(即只在事件开始时给出一次),也可以是动态的(即在每个时间步骤给出)。最近,由于室内环境中的定位不完善, Habitat Challenge 2020转向了更具挑战性的任务,即没有GPS和指南针的基于RGBD在线定位。
在最近的文献中有许多基于学习的点导航方法。 早期的一项工作使用端到端的方法来处理具有不同感觉输入的现实自主导航设置(即没有ground-truth map和ground-truth agent's poses的看不见的环境)中的点导航。 基本的导航算法是直接未来预测(DFP),其中相关的输入,如彩色图像、深度图和来自四个最近观测的动作,由适当的神经网络(例如,用于感觉输入的卷积网络)处理,并连接到一个双流完全连接的动作-期望网络中。 输出是对所有动作和未来时间步骤的未来测量预测。
作者还介绍了信念DFP(BDFP),该方法通过引入中间的类图表示(intermediate map-like representation),使DFP的黑箱策略在未来测量预测中具有更好的解释性。 这是受神经网络中的注意机制和强化学习中的successor representation和特征的启发。 实验表明,BDFP在大多数情况下都优于DFP,经典的导航方法通常优于RGB-D输入的基于学习的导航方法。 [98]提供了一种更加模块化的方法。 对于点导航,SplitNet的体系结构由一个视觉编码器和多个解码器组成,用于不同的辅助任务(如自我预测)和策略。 这些解码器旨在学习有意义的表征。 使用相同的PPO算法和行为克隆训练,SplitNet可以在以前看不见的环境中优于可比的端到端方法。
2、对象导航
对象导航是具身智能中最简单的任务之一,但也是最具挑战性的任务之一。 对象导航关注于在未被探索的环境中导航到由其标签指定的对象的基本思想。 智能体将在一个随机位置初始化,并负责在该环境中查找对象类别的实例。对象导航通常比点导航更复杂,因为它不仅需要许多相同的技能,如视觉感知和情节记忆构建,而且还需要语义理解。 这些使得对象导航任务更具挑战性,但也值得解决。
对象导航的任务可以通过自适应来演示或学习,这有助于在没有直接监督的环境中进行导航。这项工作[51]通过一种元强化学习方法实现了这一点,因为智能体学习一个自监督的交互损失,这有助于鼓励有效的导航。与传统的导航方法不同的是,智能体在推理过程中冻结学习模型,该工作允许智能体以自监督的方式学习自适应,并在事后调整或纠正其错误。 这种方法防止智能体在实现之前犯太多错误,并进行必要的纠正。 另一种方法是在执行导航的规划之前学习对象之间的对象关系。 该工作[53]实现了一个对象关系图(ORG),它不是来自外部先验知识,而是在可视化探索阶段建立的知识图。该图由对象关系组成,如类别贴近度和空间相关性。
3、基于先验的导航
基于先验的导航技术主要是将语义知识或先验知识以多模态输入的形式注入,如知识图或音频输入,或者在可见和不可见的环境中帮助训练具身智能智能体的导航任务。 过去的工作[57]将人类的知识先验集成到深度强化学习框架中,已经表明智能体可以利用类似人类的语义/功能先验来帮助A它学习导航和在看不见的环境中寻找看不见的对象。 这样的例子利用了这样一种理解,即人们会倾向于从逻辑位置开始寻找感兴趣的项目,比如在厨房里找到一个苹果。 这些知识被编码在一个图网络中,并在一个深度强化学习框架中进行训练。
还有使用人类先验的其他示例,例如人类感知和捕获音频信号模式与对象的物理位置之间的对应关系的能力,从而执行到信号源的导航。(这也是当前很火的一个导航任务) 在这项工作[103]中,智能体选择目标物体的视觉和声音信号等多种感觉观察,并计算出从其起始位置到声源的最短导航轨迹。 本工作通过视觉感知映射器、声音感知模块和动态路径规划器来实现。
4、视觉语言导航(VLN)
视觉语言导航(VLN)是Agent学习通过自然语言指令在环境中导航的任务。 这项任务的挑战性方面是依次感知视觉场景和语言。VLN仍然是一项具有挑战性的任务,因为它要求Agent根据过去的行为和指令对未来的行为做出预测。 此外,智能体可能无法将其轨迹与自然语言指令无缝地对齐。 虽然视觉语言导航和视觉问题回答(VQA)看起来很相似,但这两个任务有很大的不同。 这两个任务都可以表述为基于视觉的序列到序列的代码转换问题。 然而,与VQA相比,VLN序列要长得多,并且要求视觉数据作为输入不断地被馈送,以及操纵摄像机视点的能力,在VQA中,单个输入问题被馈送并生成答案。 我们现在能够给机器人一个自然语言指令,并期望它们执行任务。这些都是随着递归神经网络方法的进步而实现的。
VLN的一种方法是辅助推理导航框架。 它解决了四个辅助推理任务:轨迹复述、进度估计、角度预测和跨模态匹配。 智能体学习对以前的操作进行推理,并预测任务的未来信息。
视觉对话导航是VLN的最新扩展,因为它的目标是训练智能体发展与人类进行持续自然语言对话的能力,以帮助其导航。 目前这方面的工作[60]使用的是跨模态记忆网络(CMN),它通过单独的语言记忆和视觉记忆模块来记忆和理解与过去导航动作相关的有用信息,并进一步用于为导航做出决策。
评估指标
1、SPL,计算公式为:
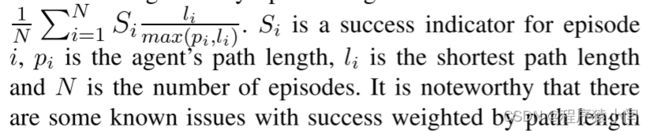
2、success rate:智能体在时间预算内达到目标的次数的分数
3、path length ratio:预测路径与最短路径长度之间的比值,仅针对成功的episode计算
4、distance to success/navigation error:分别度量了Agent的最终位置与最近目标或目标位置周围的成功阈值边界之间的距离。
5、除了上述四个指标之外,用于评估VLN任务的两个指标:
(1)Oracle成功率,即Agent在其轨迹上最接近目标点处停止的速率
(2)轨迹长度。 一般来说,对于VLN任务,最好的度量仍然是SPL,因为它考虑了所采取的路径,而不仅仅是目标。
6、对于视觉对话导航,除了成功率和Oracle成功率外,还使用了另外两个度量指标:
(1)目标进度(goal progress),即Agent向目标位置的平均进度
(2)Oracle路径成功率:即Agent沿着最短路径在离目标最近的点停止的成功率
数据集
与视觉探索一样,MatterPort3D和Gibson V1是最流行的数据集。 值得注意的是,Gibson V1中的场景更小,通常有更短的episodes(从开始位置到目标位置的GDSP更低)。 AI2-Thor模拟器/数据集也被使用。 与其他视觉导航任务不同,VLN需要不同类型的数据集。 大多数VLN工作都使用MatterPort3D模拟器[104]中的room-to-room(R2R)数据集。 它由21567条导航指令组成,平均长度为29个字。 在视觉对话导航[59]中,使用协同视觉与对话导航(CVDN)[105]数据集。 它在MatterPort3D模拟器中包含2050个人对人对话框和7000多个轨迹。
具身QA
在近年来的具身智能模拟器中,具身QA任务是通用智能系统领域的一个重要进展。 为了在物理状态下执行QA,智能体需要具有广泛的AI能力,如视觉识别、语言理解、问答、常识推理、任务规划和目标驱动导航。 因此,具身QA可以说是目前具体化AI研究中最繁重、最复杂的任务。
任务分类
1、具身QA(Embodied QA,EQA)
对于具身QA,一种将任务分成两个子任务的通用框架:导航任务和QA任务。 导航模块是必不可少的,因为在回答有关对象的问题之前,智能体需要探索环境以查看对象。 例如,[61]提出了规划者-控制器导航模块(PACMAN),它包括导航模块的分层结构,规划者选择动作(方向),控制器决定跟随每个动作移动多远。 一旦智能体决定停止,QA模块通过使用沿其路径的帧序列来执行。 导航模块和视觉问题回答模块首先单独训练,然后通过Restence[106]进行联合训练。 [62]和[63]用神经模块控制(NMC)进一步改进了Pacman模型,在该模型中,高级主策略提出了由子策略执行的语义子目标。
2、多目标具身QA(Multi-target embodied QA ,MT-EQA)
研究包含多个目标的问题,例如“卧室里的苹果比客厅里的橘子大吗?”,使得Agent必须导航到“卧室”和“客厅”来定位“苹果”和“橘子”,然后进行比较来回答这些问题。
3、交互式QA(Interactive Question Answering ,IQA)
交互式问答(IQA)是在AI2-Thor环境中解决具身问答任务的另一个工作。 IQA是EQA的一个扩展,因为Agent必须与对象进行交互才能成功地回答某些问题(例如,Agent需要打开冰箱才能回答存在性问题“冰箱里有鸡蛋吗?”)。 [64]提出使用分层交互记忆网络(HIMN),这是一个帮助系统跨多个时间尺度操作、学习和推理的控制器层次结构,同时降低每个子任务的复杂性。 以自我为中心的空间门控递归单元(GRU)充当存储单元,用于保存环境的空间和语义信息。 规划器模块将控制其他模块,如导航器运行A*搜索以找到到达目标的最短路径,扫描器执行旋转以检测新图像,机械手被调用以执行改变环境状态的操作,最后是回答提交给AI代理的问题的回答器。 [65]从多Agent的角度研究了IQA,其中几个Agent共同探索一个交互场景来回答一个问题。 [65]提出了多层结构和语义记忆作为场景记忆,由多个Agent共享,首先重建三维场景,然后进行QA。
评估指标
具体化QA和IQA包括两个子任务:1)导航和2)问题回答,这两个子任务是基于不同的度量来评估的。
评价导航性能的指标是:(1)导航终止时与目标的距离,即导航误差(Dt); (2)从初始位置到最终位置的目标距离的变化,即目标进度(d); (3)在一个eipsode中任意点距目标的最小距离(dmin);(4)在达到最大episode长度之前,智能体终止导航应答的episode百分比(%stop); (5)智能体在包含目标对象的房间中终止的问题的百分比(%RT); (6)智能体至少一次进入包含目标对象的房间的问题百分比(%RE); (7)目标对象的并集上的交集(IOU); (8)基于IOU(Ht)的命中精度; (9)episode长度,即轨迹长度。 度量(1)、(2)和(9)也被用作视觉导航任务的评估度量。
评价QA性能的指标是:(1)预测中的基本真值答案的平均秩(MR); (2)准确性。
数据集
EQA[61]数据集基于House3D,它是流行的SUNCG[33]数据集的子集,具有Replica数据集[107]相似的合成房间和布局。 House3D将SunCG的静态环境转换为虚拟环境,在虚拟环境中,智能体可以在物理约束下导航(例如,它不能穿过墙壁或物体)。 为了测试Agent在语言基础、常识推理和导航方面的能力,[61]使用CLEVR[108]中的一系列函数程序来合成关于对象及其属性(例如颜色、存在、位置和相对介词)的问题和答案。 总共在750个环境中有5000个问题,涉及7个独特房型中的45个独特对象。
对于MT-EQA[63],作者介绍了MT-EQA数据集,该数据集包含6类组合问题,用于比较多个目标(对象/房间)之间的对象属性属性(颜色、大小、距离)。
对于IQA[64],作者注释了一个由75,000个选择题组成的大规模数据集IQUAD V1。 与EQA数据集类似,IQUAD V1也有关于对象存在、计数和空间关系的问题。
洞察及挑战
对具身智能的洞察
VLN以前的工作并不要求其模拟器具有交互性的特点; 因此MatterPort3D模拟器就足够了。 然而,随着VLN任务的深入,我们可以预期VLN任务中交互的需求,因此需要使用具体化的人工智能模拟器。
每个具身智能研究任务对下一个具身智能研究任务都有贡献。 例如,视觉探索有助于视觉导航的发展,而视觉导航有助于创造具身QA。 这种建立方法也与任务的日益复杂相关联。 基于具身智能的可预见趋势,我们假设实体人工智能研究金字塔的下一个进展是基于任务的交互式问答(Task-based Interactive Question Answering,TIQA),它旨在将任务与回答特定问题结合起来。 例如,这样的问题可以是“鸡蛋煮沸需要多长时间? 柜子里有苹果吗?“。 这些问题不能通过传统的方法来回答。 它们要求具身智能体执行与问题相关的特定任务,以解锁在回答这些QA问题时非常重要的新见解。 我们假设的TIQA代理可以执行一系列一般的家庭任务,这允许他们推断有用的环境信息,这对帮助他们获得QA问题的答案至关重要。 TIQA可能掌握了在模拟中推广任务规划和开发通用人工智能的关键,这些人工智能随后可以部署到现实世界中。
具身智能模拟器的挑战
具身智能模拟器在真实感、可伸缩性和交互性等方面仍然存在一些挑战。
真实性
重点讨论了模拟器的保真度和物理特性。 具有高逼真度和逼真物理特性的模拟器为各种机器人任务提供了理想的实验平台,如导航和交互任务。 然而,目前还缺乏同时具备世界场景和先进物理的具身智能模拟器。
对于逼真度而言,基于世界的场景模拟器在模拟真实任务方面无疑将优于基于游戏的场景模拟器。 尽管如此,只有Habit-SIM和Igibson是基于世界的场景模拟器。 这种基于世界的场景模拟器的缺乏是具身智能Agent从模拟到真实任务的瓶颈,这进一步阻碍了具身智能研究向真实世界部署的转移。 对于物理学,基于物理的预测模型的进一步发展强调了具有高级物理特征的具身智能模拟器的重要性,因为它们为训练具身智能agent执行具有复杂物理交互的任务提供了理想的测试床。尽管需要一个先进的基于物理的具身智能模拟器,但目前只有一个模拟器,即ThreeDWorld符合这一标准。 因此,非常缺乏具有先进物理特性的具身智能模拟器,如布料物理、流体物理和软体物理。 我们相信3D重建技术和物理引擎的进步将提高具身智能的真实感。
可伸缩性
与基于图像的数据集不同,这些数据集可以很容易地从众包或互联网上获得。 收集大规模的基于世界的三维场景数据集和三维对象资产的方法和工具是稀缺的。 这些三维场景数据集对于构建各种具身智能模拟器至关重要。 目前收集逼真3D场景数据集的方法需要通过摄影测量扫描物理房间,例如Matterport 3D扫描仪、Meshroom,甚至移动3D扫描应用程序。 然而,它们对于收集大规模的三维物体和场景扫描并不具有商业可行性。 这在很大程度上是由于用于摄影测量的3D扫描仪昂贵且不可访问。 因此,可扩展性的瓶颈在于开发用于大规模采集高保真三维物体或场景扫描的工具。 希望随着基于三维学习的方法的进一步发展,这些方法旨在从单个或少量图像甚至通过场景生成方法来绘制三维对象网格,我们将能够扩大大规模三维数据集的收集过程。
交互性
在具身智能模拟器中,与功能对象进行细粒度操作交互的能力对于复制与现实世界对象的人类级交互至关重要。 大多数基于游戏的场景模拟器都提供了细粒度的对象操作功能和符号交互功能(例如:<在Y上下拉对象X>动作)或简单的“点-选”。 然而,由于基于游戏的场景模拟器的性质,在这种环境中执行的许多研究任务将选择它的象征性交互能力,而不是细粒度的对象操纵[3],除了少数同时利用两者。
另一方面,基于世界的场景模拟器中的智能体具有总体运动控制能力,而不是符号交互能力。 然而,这些模拟器中对象的对象属性在表面上很大程度上是可交互的,这允许总体的运动控制,但缺乏多状态对象类,即对象的状态变化数量。 因此,需要在其对象属性中的对象功能和具身智能 Agent在环境中可以执行的操作的复杂性之间取得平衡。
AI2-THOR[13]、Igibson[18]和Habitaby-SIM[17]等主流模拟器为推进各自具身智能研究提供了良好的环境。 然而,它们确实有其优点和局限性需要克服。 随着计算机图形学和计算机视觉的发展,以及创新的真实世界数据集的引入,Real to SIM领域的自适应是改进具身智能模拟器的明确途径之一。 Real-to-SIM的概念围绕着捕捉现实世界的信息,如触觉感知、人类级别的运动控制和音频输入,以及视觉感官输入,并将它们集成,以开发更真实的具身智能模拟器,从而有效地连接物理和虚拟世界。
具身智能研究的挑战
在具身智能研究任务中,复杂性也有所增加,从视觉探索到VLN和具身QA,分别增加了语言理解和QA等新组件。 每一个新的组件都导致智能体的训练更难,尤其是因为当前的方法通常是完全基于学习的。 这一现象导致了两个有希望的进步,以减少搜索空间和样本复杂度,同时提高鲁棒性:结合经典和基于学习的算法的混合方法[44],[74]和先验知识融合[23],[57]。 此外,对于更复杂的任务,消融研究更难管理[31],因为具身智能中的每个新组件都更难测试其对智能体性能的贡献,因为它被添加到现有的组件集上,而具身智能模拟器在特性和问题上差异很大。 研究任务的数量也迅速增加,这使情况更加复杂。 因此,虽然一些基本任务,如视觉探索得到了更多的关注,从而有了更多的方法来解决它们,但更新的任务,如MT-EQA,却很少得到解决。 新任务通常在方法、评估度量[22]、输入类型和模型组件等重要方面引入新的考虑因素,如表III所示,因此比像视觉探索这样的简单任务需要更多的评估。
最后,缺乏对多Agent设置的关注,而多Agent设置可以提供有用的新任务[65]。 这种缺乏关注可以归因于直到最近还缺乏具有多智能体功能的模拟器。 用于协作和通信的多Agent系统在现实世界中很普遍[134],[135],但目前受到的关注相对较少[31]。 随着最近具有多智能体特性的模拟器的增加[13],[20],[55],多智能体支持(例如,对多智能体算法的支持)是否足够还有待观察。