【PostgreSQL】PG左模糊 右模糊匹配查询,如何走btree索引

目录
- 前言
- 后模糊 建表
- 查询分析
- 前模糊 建表
- 查询分析
- 总结
- 参考资料
前言
PG如果直接使用左右模糊查询,可能会不走btree索引,这里记录一下模糊匹配走索引的方法。
这里使用DBeaver来操作本地数据库。
注:DBeaver 是一个流行的免费、开源数据库管理工具,适用于各种关系型和非关系型数据库。它支持多种数据库系统,包括 MySQL、PostgreSQL、Oracle、Microsoft SQL Server、IBM DB2、SQLite 等,并且具有跨平台特性,可以在 Windows、Linux 和 macOS 上运行。
后模糊 建表
首先打开SQL编辑页:

我们建表为 test.user_content ,维护了主键id,username,user_id和content字段,并且插入一点数据,语句如下:
CREATE TABLE test.user_content (
id serial PRIMARY key NOT null,
username varchar(128) NOT NULL,
user_id varchar(128) NOT null,
content varchar(128)
);
-- CREATE INDEX test_user_content_username ON user_content (username);
--CREATE INDEX test_user_username_idx on user_content using btree(username collate "C");
CREATE INDEX test_user_username_idx on user_content using btree(username varchar_pattern_ops);
CREATE INDEX test_user_content_user_id ON user_content (user_id);
CREATE INDEX test_user_content_content ON user_content (content);
INSERT INTO test.user_content (id,username,user_id,"content")
VALUES (1,'admin123','123456','asdiignipasdpj123i-185-91j-sa=<>-2=oe=1,2''11.24,1');
INSERT INTO test.user_content (id,username,user_id,"content")
VALUES (2,'admin124','424211','onfffaaqq');
如果使用以下
CREATE INDEX test_user_content_username ON user_content (username);
是无法走索引的,因此需要改写为:
CREATE INDEX test_user_username_idx on user_content using btree(username collate "C");
或者是:
CREATE INDEX test_user_username_idx on user_content using btree(username varchar_pattern_ops);
其中 varchar_pattern_ops 是 PG 中一个用于创建 B-Tree 索引的选项,在 VARCHAR 类型的列上创建索引时,使用 varchar_pattern_ops 可以优化对包含模式匹配操作(如 LIKE 和 ~)的查询。
在 VARCHAR 上创建 B-Tree 索引时不指定任何额外选项时,索引将按照字符串的字典顺序排序和存储数据,这对等值比较( =)、范围比较( BETWEEN)比较有效。但是包含模式匹配操作的查询( LIKE ‘%apple’ 或 ~ ‘^apple.*’),默认的 B-Tree 索引不支持,选择在创建 B-Tree 索引时使用 varchar_pattern_ops 选项可以适用模式匹配操作。
btree(xxx collate "C") 指定了索引的键列和排序规则,collate "C" 是一个排序规则选项,用于指定字符串如何进行比较和排序。collate "C" 表示使用 C 本地化(或“POSIX”本地化),对所有字符按照它们在 ASCII 字符集中对应的数值进行排序,在这个排序规则下,大小写敏感,并且特殊字符如标点符号可能会出现在字母之前或之后。使用 C 本地化的排序规则来决定字符串如何进行比较和排序,这样可以加速涉及 username 列的查询操作。
执行SQL编辑页:
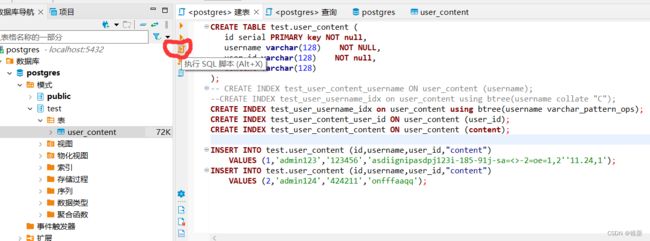
得到我们的test.user_content:
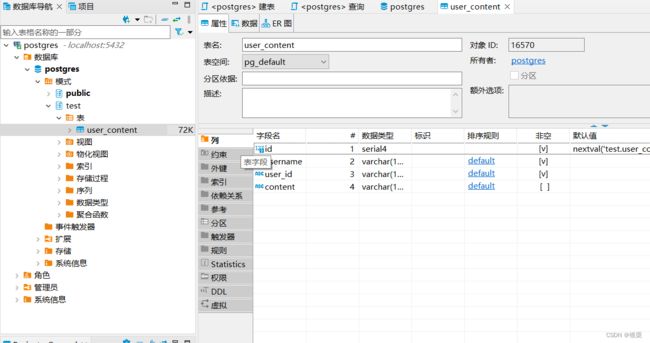
可以看到索引和依赖关系:


查询分析
之后我们对username字段进行模糊查询:
SELECT id, username, user_id, "content"
FROM test.user_content
WHERE username LIKE 'adm%'
;
EXPLAIN SELECT id, username, user_id, "content"
FROM test.user_content
WHERE username LIKE 'adm%'
;


可以看到成功走了索引。
前模糊 建表
前模糊,其实就是后模糊做字符串翻转,因此我们有建表语句:
CREATE TABLE test.user_content (
id serial PRIMARY key NOT null,
username varchar(128) NOT NULL,
user_id varchar(128) NOT null,
content varchar(128)
);
-- CREATE INDEX test_user_content_username ON user_content (username);
--CREATE INDEX test_user_username_idx on user_content using btree(REVERSE(username) collate "C");
CREATE INDEX test_user_username_idx on user_content using btree(REVERSE(username) varchar_pattern_ops);
CREATE INDEX test_user_content_user_id ON user_content (user_id);
CREATE INDEX test_user_content_content ON user_content (content);
INSERT INTO test.user_content (id,username,user_id,"content")
VALUES (1,'admin123','123456','asdiignipasdpj123i-185-91j-sa=<>-2=oe=1,2''11.24,1');
INSERT INTO test.user_content (id,username,user_id,"content")
VALUES (2,'admin124','424211','onfffaaqq');
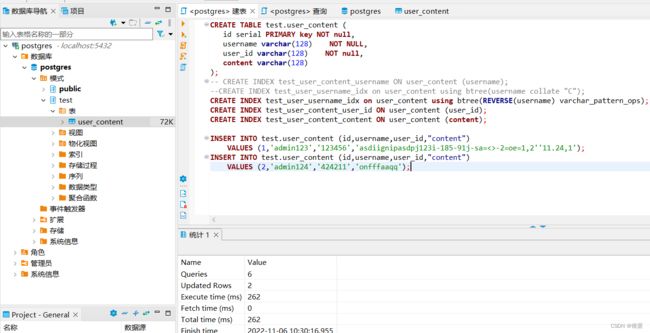
执行之后:
查询分析
我们对username字段做模糊查询有:
SELECT id, username, user_id, "content"
FROM test.user_content
WHERE REVERSE(username) LIKE '321%'
;
EXPLAIN SELECT id, username, user_id, "content"
FROM test.user_content
WHERE REVERSE(username) LIKE '321%'
;
执行有:
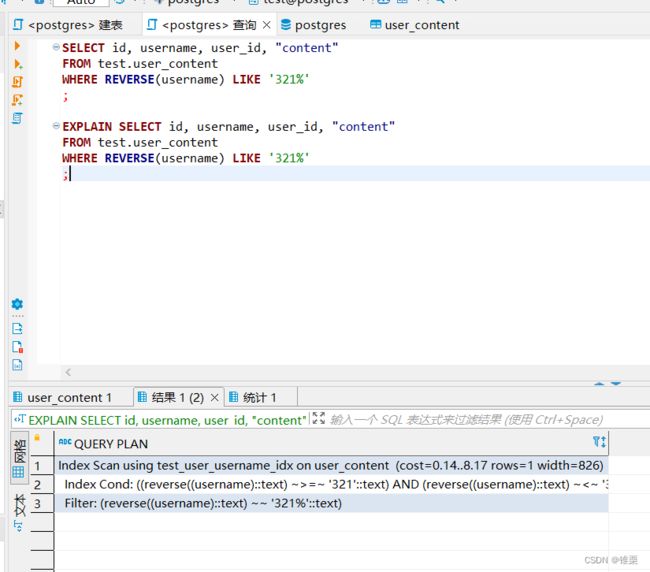
可以看到我们走了索引

并且通过321%实现了123%的前模糊查询
总结
前模糊查询(以 % 开头的LIKE 查询)和后模糊查询(以 % 结尾 LIKE 查询)都可以用来进行字符串匹配。选择哪个取决于你的具体需求和数据特性。
前模糊查询适用于想要查找以特定后缀结尾的字符串的情况,后模糊查询后模糊查询适用于你想要查找以特定前缀开头的字符串的情况。对于 B-Tree 索引,前后模糊查询也可以利用索引加速查询,默认的 B-Tree 索引不支持对中间或后缀部分进行高效的搜索,可以在创建 B-Tree 索引时使用 varchar_pattern_ops 选项。
如果需要执行大量模糊查询,可以考虑使用特殊类型的索引GIN、Trigram 、全文索引等。
参考资料
https://blog.csdn.net/weixin_39540651/article/details/100655683