sql 优化 具体案例分析-基于pgsql数据库
我们来对sql是否使用索引来进行分析, 要用到的sql语句如下:
explain (ANALYZE on ,TIMING on, VERBOSE on, BUFFERS on, COSTS on ) select cons_name from c_cons where cons_name like '45%'
explain (ANALYZE on ,TIMING on, VERBOSE on, BUFFERS on, COSTS on ) select * from e_mp_day_read where data_date <> '2020-06-30 00:00:00'
explain (ANALYZE on ,TIMING on, VERBOSE on, BUFFERS on, COSTS on ) select * from e_mp_day_read where data_date in ('2020-06-30 00:00:00')
explain (ANALYZE on ,TIMING on, VERBOSE on, BUFFERS on, COSTS on ) select * from e_mp_day_read where data_date = '2020-06-30 00:00:00'
explain (ANALYZE on ,TIMING on, VERBOSE on, BUFFERS on, COSTS on ) select * from e_mp_day_read where data_date not in ('2020-06-30 00:00:00')第一条语句:
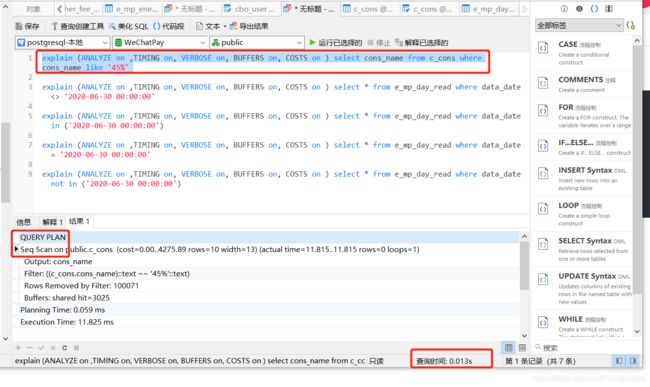
解析: 对于c_cons表 , cons_name是建立了索引的 。 但是对于like 来说, 模糊表达式% 在‘45’后面,按照规则是应该走索引的,但是实际执行缺没有走索引。 这是为什么?
个人猜测: pgsql在实际执行前,会有一次预估执行, 对于数据量小的列做where时, 使用全表扫描比索引扫描效率更高。 所以pgsql选择了全表扫描的方式,而没有使用cons_name的索引。
为什么数据量少的时候全表扫描的效率会更高呢? 因为基于全表扫描,只需要按行数对列进行读取。 而基于索引扫描,需要执行两次I/O操作。 读取索引一次I/O, 读取 数据列一次I/O。
第二条语句执行情况分析:
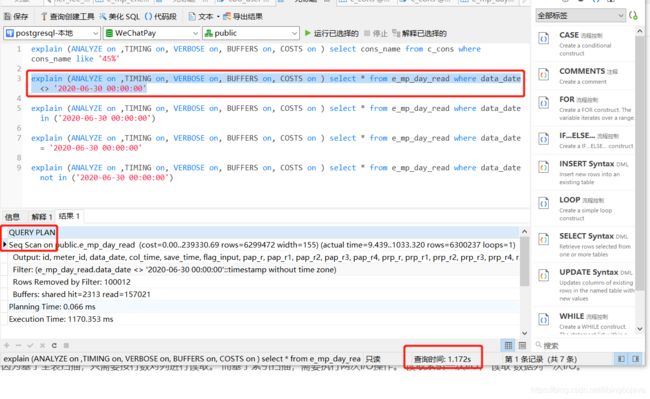
这条语句中, e_mp_day_read中的data_date建立了索引字段。但在实际执行的情况中,很明显sql执行规划中没有使用索引。 为什么呢? 很明显,是 where 的 <> 操作符是data_date列的索引失效了。
可以看到他是基于全表扫描, 查询时间是1.172秒, 注意, 此时数据库中有10000条数据。
第三条语句执行情况分析:
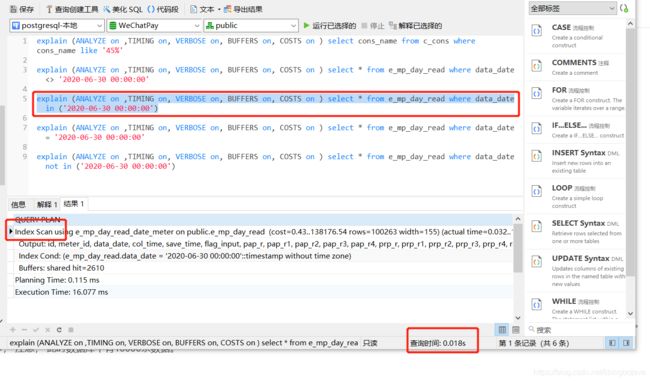
这里where对于data_date使用了in关键字, 可以看到,执行规划中使用了索引扫描。 查询时间达到了 0.018秒, 在同是10000条数据的情况下, 使用索引要比全表扫描快65倍左右!
我们在看看使用not in关键字的情况:
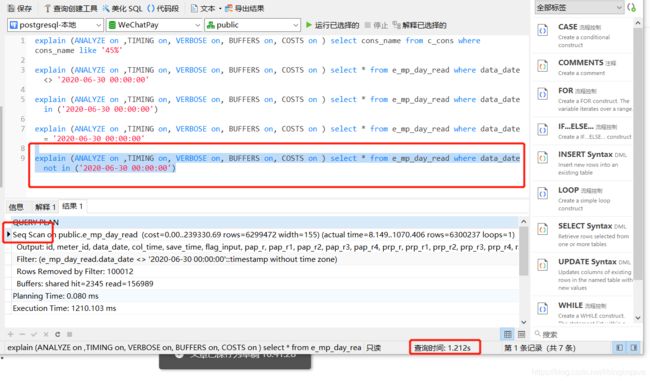
可以看到, not in关键字是列索引失效了。 查询时间高达1.212秒。
我们再来看看最后一条sql 。 当日期类型 和 字符串格式的日期 作为条件进行查询是,索引是否失效?
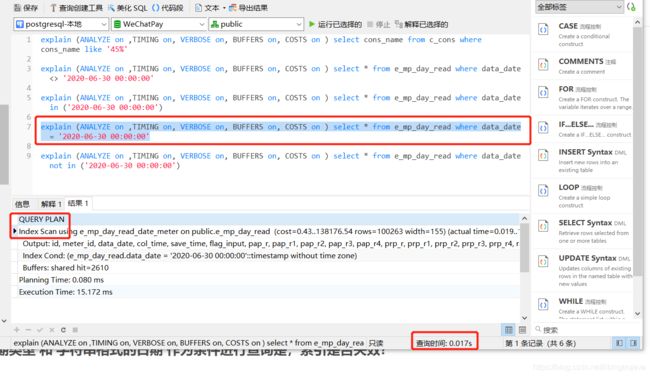
可以看到, 索引没有失效。 具体分析, 看 index Cond 展示的信息, 和data_date字段进行比较的参数类型是 timestamp 。 也就是所, pgsql在对字符串格式的日期进行比较前, 先将字符串格式转成 了日期格式然后进行的比较。 正式比较时, 是两个日期格式在比较。所以索引有效。用时0.017秒。
这里简单的记录一下。
一般来说。 使用 like '%a' , not in , <> , != , data_time(data_time) , num = a*b 这些情况下, 索引会失效。
最后一个注意点:
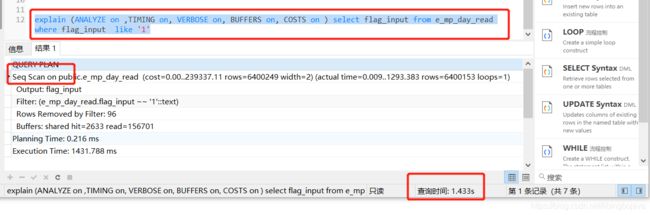
我们对flag_input (varchar类型)加了索引,但是flag_input整个列的值加了 check 约束(约束内容是1或2), 所以flag_input的值不是1 ,就是2。
可以看到,flag_input的索引失效了。
为什么? 因为 当索引列的值包含大量重复数据时, 实际执行不会走索引, 而是全表扫描。
那么这种情况怎么解决?
现在的问题是flag_input不走索引, 这个不走索引不是因为我们sql 写的有问题,而是列的值太多重复造成的情况。 我们可以重新定义一个列, 叫 flag_input_copy 。 flag_input_copy = flag_input + UUID。
这样flag_input_copy的值就不会大量重复了。 对flag_input的查询可以换为对flag_input_copy的查询。 只需要 like '(flag_input的值)%' 即可。