Redis -- 开篇热身,常用的全局命令
目录
Redis重要文件
启动停止脚本
配置文件
持久化文件存储目录
核心命令
set
get
全局命令
keys
exists
del
expire
ttl
过期策略是如何实现的
定时器
type
小结

Redis重要文件
启动停止脚本
- /usr/bin/redis-benchmark : 用于对Redis做性能基准测试的工具
- /usr/bin/redis-check-aof -> /usr/bin/redis-server :redis-server的软链接 ,是修复AOD的工具
- /usr/bin/redis-check-rdb -> /usr/bin/redis-server :redis-server的软连接,是修复RDB文件的工具
- /usr/bin/redis-cli :命令行客户端程序
- /usr/bin/redis-sentinel -> /usr/bin/redis-server : redis-server的软链接,是Redis的哨兵程序
- /usr/bin/redis-server : 是Redis的服务器程序
- /usr/libexec/redis-shutdown :停止Redis的专用脚本
演示:
在bin目录下输入redis-cli启动redis命令行客户端(按下ctrl + c 结束当前客户端状态):

配置文件
- /etc/redis-sentinel.conf
- /etc/redis.conf
redis-sentinel.conf是Redis-sentinel的配置文件,redis.conf是redis服务器的配置文件
持久化文件存储目录
- /var/log/redis/
/var/log/redis/ 目录下会保存 Redis 运行期间生产的日志文件,默认按照天进行分割,并且会将一定日期的日子文件使用 gzip 格式压缩保存。可以使用任意文本编辑器打开,后边章节我们会通过日志来观察一些现象。
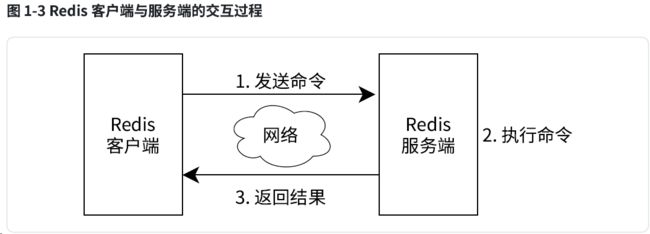
下面这些命令都是需要进入到redis的客户端程序。使用redis客户端,通过网络的形式来操作redis服务器。
核心命令
redis最核心的两个命令就是get和set, get就是根据key来取value,set就是吧key和value存储进去。
redis 的命令是不区分大小写的。
set
格式:set key value
其中key和value都是字符串,在set的时候,输入的key和value是不需要加上引号的,就是表示的字符串类型
演示
输入key之后:![]()
象征性的输入两个数据:例如key1 value1, key2 value2>>
如果给key加上引号也是可以的,此时无论是加上单引号还是双引号都是可以的:
设置好键值对之后,就可以使用get来进行查操作
get
格式:get key
输入key之后就可以得到value,如果不存在就会返回nil(和null是一个意思)。
nil和null有什么区别?下面是官方解释:

也就是说,他们在值上都是零,这两个词的区别主要在于在哪个领域使用他们,null主要使用在数学,变成,商业和法律方面,而nil主要使用在运动和游戏中。
演示
输入key之后:
不带引号默认识别为字符串
当然你可以使用 引号也是没问题的:
输入一个不存在的key,输出nil :

全局命令
redis支持多种数据结构,整体来说redis是键值对结构,key是固定的字符串,但是value的种类却有很多种,例如:
- 字符串
- 哈希表
- 列表
- 集合
- 有序集合
这里的全局命令就是能够搭配任意一个数据结构来使用的命令,接下来我们介绍一些全局命令
keys
格式:keys pattern
用来查询当前服务器上匹配的key,通过一些特殊的通配符来描述key的模样,匹配上述模样的key来查询想要的key值。
注意:keys命令的时间复杂度是O(N),所以生产环境一般会禁止使用keys,尤其是keys*这种匹配模式,查询redis中所有的key,是非常危险的,因为生产环境的key可能是非常多的,redis是一个单线程的服务器,会导致执行keys *的时间非常长,是redis服务器被阻塞,导致无法给其他客户端提供服务。Redis经常当作缓存使用,挡在了mysql的前面,万一redis被一个keys*给阻塞了,此时其他的redis查询操作就超时了,此时就会直接请求查询数据库,mysql也同样负重而行了,就容易挂了。
他的匹配规则如下:

涉及到的通配符:
- ?:匹配任意一个字符
- *:匹配0个或任意多个字符
- [abcde]:匹配一个字符,且只能匹配到abcde中的一个,相当于给出固定格式
- [^ae]:匹配一个字符,但是排除a和e,只有a和e不能匹配,其他的都能匹配
- [a-c]:匹配一个字符,且这个字符的范围在a和c之间,包含a和c
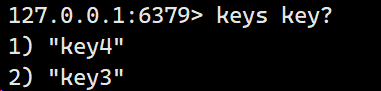
例如,keys key?, 输出key1,key2,key3,key4......
你甚至可以理解为筛选 出符合要求的key值。
演示
现在我们有下面几个键值对:
?:
[]:
*:
不一一举例,此处理解不是很复杂。
exists
判断某个key是否存在,返回一个integer类型,表名存在的个数。
格式:exists key [key ... ]
可以有多个key,多个key之间使用空格分开,例如:exists key1 key2, 时间复杂度为O(1),redis组织这些数据是根据 哈希表的形式来组织的
演示
有下面两个key-value.
使用 exist key1和 exists key1 key2
分别返回1和2, 代表着存在着几个结果

如果key1存在, key100不存在, 那么返回1
提问:既然可以一次就写一个, 为什么还会存在一次性写两个的写法?
别忘记了, Redis也是一种客户端服务器的程序,无论客户端服务器是否在一个主机,客户端和服务器之间都是通过网络进行请求和响应的。exists多个key的好处就在于只需要请求一次,服务器也只需要做出一次响应即可。而将多个key分别exists会消耗额外的网络资源。进行网络通信的时候,发送一个数据需要经过应用层,物理层等等的层层封装,接收方每接到一个数据也要通过应用层等层层分用。网络比起直接操作内存相比的话速度慢成本更高。
del
删除指定的key
格式:del key [key ... ]
后面可以指定多个key,多个key之间使用空格隔开。时间复杂度为O(1),返回一个integer值,表明删除掉的key的个数。
时间复杂度为O(1)
演示
有下面几个key:
选择删除key1,key2和key100:

返回2,说明删除了两个,查看是否删除成功:
删除成功,因为key100不存在所以删除失败,返回值为2而不是3。
对于删除操作,有几个注意点:redis主要的应用场景就是作为缓存,此时redis存储的是热点数据,全量数据还是存储在mysql中,此时把redis中几个key删除了,问题倒是不大,但是如果把所有的数据或者一大半的数据给删除了,因为redis数据没了,大部分数据就要直接访问mysql了就很容易把MySQL弄挂掉了。
相比之下,如果是mysql这样的数据,哪怕删除一个数据都可能造成不可估量的影响。
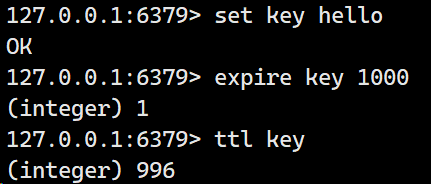
expire
为指定的key添加 单位为秒的过期时间,超过指定存活时间就会自动删除。
格式:expire key seconds
返回值为一个integer类型的0或者1,0表示设置失败,1表示设置成功。
注意,这里的key必须是已经存在的key,如果不存在就会返回0。
时间复杂度为O(1)
演示

这里有两个key
首先设置一个不存在的key1,如下:

解释:key1表示我要给key1设置存活时间,设置的存活时间为3秒。返回值为0表示设置失败,因为当前key1不存在。
设置一个存在的key3:

返回值为1表示成功,三秒后查询key3 发现被删除:

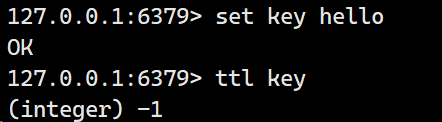
ttl
time to live,获取指定key的过期时间
格式:ttil key
时间复杂度O(1),返回值为剩余的过期时间,-1表示没有过期时间,-2表示key不存在。
演示
如果没有设置存活时间:
如果key不存在:

上述的expire和ttil的单位都是秒,如果你不习惯于使用秒作为单位,那么redis还提供了使用毫秒作为单位的命令,他们分别是pexpire和pttl,其用法和上述操作差不多。
过期策略是如何实现的
一个redis中会同时存在很多个key,这些key中可能大部分都存在过期时间,此时redis服务器如何知道哪些key已经过期要被删除了,哪些key又没有过期呢?
如果直接遍历是不可行的,原因是效率非常低。 redis整体的策略是定期删除,一方面是惰性删除。
- 惰性删除:假设这个key已经到过期时间了,但是暂时没有删除它,但是后面有一次请求访问到这个key,这次访问就会触发让redis删除key的操作,同时再返回一个nil(null)。
- 定期删除:每次抽取一部分进行过期验证,保证抽取检查的过程够快。
为啥这里对于定期删除的时间有要求?因为redis是单线程程序,主要任务是处理每个命令,如果扫描时间过长,就可能导致正常的命令被阻塞,就产生了类似于keys * 的效果。
虽然上述两种方法结合的策略,但是效果确实很很一般。仍然有很多的过期的key没能及时的清理掉。
redis为了对上述策略进行补充,还提供了一系列内存淘汰系列的方法(后面会详细讨论,这里不展开讨论)。
定时器
在某个时间到达之后,执行指定的任务。下面是两种比较高效的定时器实现方案。
注意:下面两个定时器并未在redis中实现。
- 基于优先级队列、堆:过期时间越早,优先级别越高(队首元素是最早要过期的元素),此时只需要分配一个线程去检测队首元素,如果队首元素没有过期,那么后面的元素肯定也没有过期。此时扫描线程 不需要遍历所有的key,同时也不必要检测的太频繁,可以根据队首元素的过期时间去设置一个等待时间,等待时间到了就唤醒这个县城去检测队首元素是否过期,把cpu的开销也省下来了。
- 基于时间轮:把时间分为很多小段,每一小段都挂着一个链表,每一个链表都代表要执行的任务,假设添加一个key到3里面,并且这个key是在300ms之后过期,此时这个轮盘上面有一个指针,这个指针就会根据固定的间隔时间进行移动,假设是100ms,每走到一个格子,就尝试将这个格子的任务进行执行。
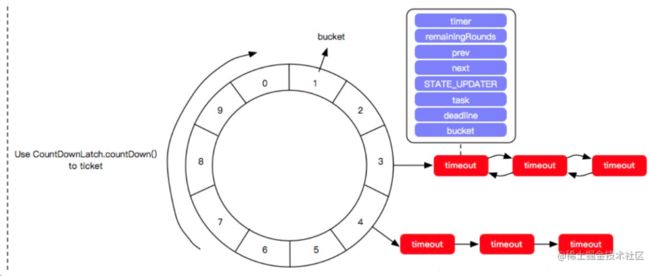 时间轮
时间轮
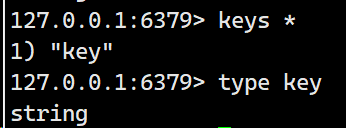
type
查看key对应的value的数据类型
格式:type key
返回值为:none,string,list,set,zset,hash,stream(redis作为消息队列的时候的数据类型)。
时间复杂度O(1)
演示
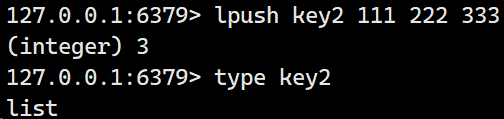
创建一个list:
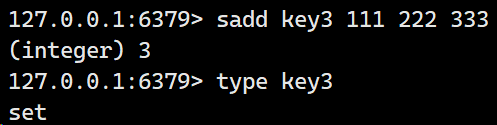
创建一个set:
创建一个hash:
上面这些hset,sadd等命令后面讲解。
小结
- set和get方法来设置和获取key value。
- exists:用来判断指定的key是否存在,可以输入多个key
- keys:查看指定pattern格式的key,使用keys * 存在非常大的风险,不建议使用。
- del:删除key,可以一次性输入多个要删除的key, del 的风险
- expire:设置过期时间,前提是key存在
- ttl:查看过期时间,秒级,-1表示不存在过期时间,-2表示不存在key,其他integer表示秒级的时间
- type:返回对应可以的value的数据类型。
- key的过期策略是如何实现。
- 两种比较高效的定时器:时间轮,基于优先级队列,堆的实现。
- 本篇只是作为一个热身,后面我们将围绕数据结构来介绍相关命令。
- 当前的redis5支持10中数据类型,还有其他的数据类型是针对其他的特殊场景的特殊数据机构
本篇完:敬请查看下一篇章。