SQL注入:宽字节注入
SQL注入系列文章:
初识SQL注入-CSDN博客
SQL注入:联合查询的三个绕过技巧-CSDN博客
SQL注入:报错注入-CSDN博客
SQL注入:盲注-CSDN博客
SQL注入:二次注入-CSDN博客
SQL注入:order by注入-CSDN博客
目录
什么是宽字节注入?
宽字节注入
绕过addslashes的限制
方法1:吃掉\
GB2312与GBK
mysql_real_escape_string防御绕过?
防御
宽字符注入的修复
防御
iconv导致的致命后果
方法2:二次转义
前面和大家分享了很多SQL注入的类型,联合查询,报错注入,盲注,二次注入,和order by 注入转眼间SQL注入已经来到了宽字节,这个注入也是一个比较特别的注入形式,可以说是“中国限定”的一个注入方式了,那么现在我们开始ヾ(◍°∇°◍)ノ゙
什么是宽字节注入?
SQL宽字节注入(SQL wide-character injection)是指利用数据库中的特定编码格式来进行非法操作或者获取未经授权的信息。这种注入通常发生在使用了不安全的输入验证机制、错误地处理用户提供的参数等情况下。
宽字节注入
想要搞清楚宽字节注入,这里我们首先要知道gbk编码是什么
GBK编码是一种汉字字符编码标准,它是在GB2312-80标准的基础上建立的内部码扩展规范。GBK编码采用了双字节编码方案,其编码范围是从8140至FEFE(剔除xx7F),共计23940个码位。GBK编码能够容纳21003个汉字,这些包括了GB2312中的全部汉字以及其他一些生僻汉字和少数民族文字。此外,GBK编码还包括了BIG5编码中的所有汉字。
GBK编码的一个特点是,它在8140至FEFE之间的首字节中,第一个字节的范围是0x81至0xFE,而第二个字节的范围是0x40至0xFE(不包括0x7F)。这样的设计使得总共可以组合出190 * 94 = 17860个不同的汉字和符号。
GBK编码与Unicode编码不同,因为它是专门为中国大陆地区设计的,并不适用于全球通用的情况。GBK编码在早期的Windows操作系统如Windows 95、Windows 98、Windows NT以及Windows 2000、Windows XP、Windows 7中都有支持。然而,随着GB18030-2000标准的推出,GBK被视为该标准的子集,并且在某些方面有所扩展。
总结来说,GBK编码是一个兼容GB2312的双字节编码标准,主要用于中文文本的处理和存储,但它不是国际通用的编码方式。
gbk编码与utf编码的不同之处有很多,其中我们必须要知道的是:
一个gbk编码汉字,占用2个字节。
一个utf-8编码的汉字,占用3个字节。
我们可以使用php来测试一下:

这里是utf-8的编码的输出结果,然后我们可以在设置中修改一下编码为bgk,然后再试试: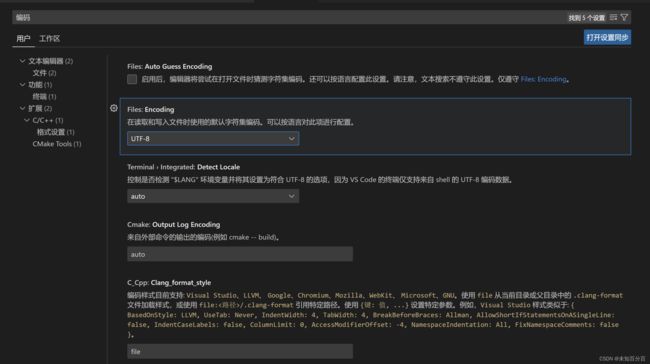
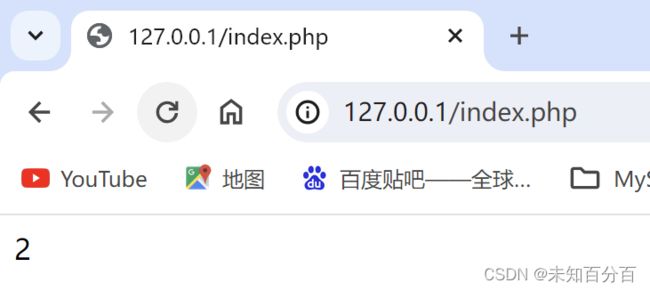
可以看到修改为bgk后,字节数就变成了2
那么下面就可以一起探讨一下Mysql中的宽字节注入
绕过addslashes的限制
首先我们先写一个存在宽字节注入的前后端代码:
宽字节注入
{$row['title']}{$row['content']}
\n";
mysql_free_result($result);
?>
可以看到SQL语句是SELECT * FROM news WHERE tid='{$id}',就是根据文章的id把文章从news表中取出来。
在这个sql语句前面,我们使用了一个addslashes函数,将$id的值转义。
这是通常cms中对sql注入进行的操作,只要我们的输入参数在单引号中,就逃逸不出单引号的限制,无法注入:
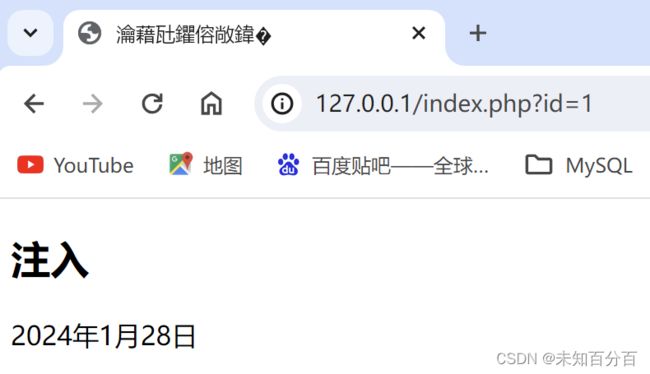

可以看到我们确实无法使用'来闭合单引号,导致提示报错了
那么怎么逃过addslashes的限制?
addslashes函数的作用就是让'变成\',让引号变得不再是原本的“单引号”,没有了之前的语义,而是变成了一个字符。那么我们现在要做的就是想办法将'前面的\给它去除掉:
方法1:吃掉\
既然这函数给'前面加了一个\那么是不是想办法给\前面再加一个\(或单数个即可),然后变成了\\',这样\就又被转义了,这样就成功的逃出了addslashes的限制
但是现在理论知识已经有了,下面就要开始尝试了,这里又该怎么来个给\前面增加一个\呢?
这时宽字节注入就出现了,mysql有一个特性就是在使用GBK编码的时候,会认为两个字符是一个汉字(前一个ascii码要大于128,才到汉字的范围)。如果我们在刚才的代码中传入一个%df'看会怎样:

可以看到这里成功的报错了,既然报错了那说明我们的闭合已经起作用了,说明成功的绕过了addslashes函数的限制了
那么导致我们可以闭合成功的原因是什么呢?
从报错的内容中可以看到,好像是在一个奇怪的字符附近。
这就是因为前面提到的mysql的特性,因为gbk是多字节编码,他认为两个字节代表一个汉字,所以%df和addslashes为我们加的后面的\也就是%5c和成了一起变成了一个汉字“運”,而%df后面的'逃逸了出来。
我们可以再看%df%df%27,看看它是否可以绕过:

可以看到,这样却无法闭合,这时因为我们输入的%df和%df组成了一个汉字,%5c和%27不是汉字,仍然是\',所以无法报错
那么这里就值得思考一下mysql怎么判断一个字符是不是汉字,根据gbk编码,第一个字节ascii码大于128,基本上就可以了。
比如我们不用%df,用%a1也可以:

可以看到%1a和%5c构成了一个?,然后后面的'由逃逸出来了
那么既然现在已经使用宽字节绕过了限制,那么就可以直接来注入出信息了,比如说注入出数据库的名称:
可以看到第2,3列是可以显示出来的,那么就可以直接在这里注入出数据库名了:
可以看到,成功的注入出了数据库名
我们这里的宽字节注入是利用mysql的一个特性,mysql在使用GBK编码的时候,会认为两个字符是一个汉字(前一个ascii码要大于128,才到汉字的范围)。
如果我们输入%df'看会怎样:
GB2312与GBK
还有一个GB2312,众所周知GBK是GB2312的扩展版本,GBK包含了GB2312的所有字符,同时还包含了更多的汉字和符号。
那么既然GB2312既然也有宽字节的特性,那么这个编码是否可以向BGK那样注入呢?
来试试看,这里把上面的代码的编码修改为GB2312来看看
宽字节注入
{$row['title']}{$row['content']}
\n";
mysql_free_result($result);
?>
现在再来试试使用%1a和'来闭合一下:
可以看到这里病灭有报错,说明这种方法不能绕过
那么到底是为什么呢?,这归结于gb2312编码的取值范围。它的高位范围是0xA1~0xF7,低位范围是0xA1~0xFE,而\是0x5c,是不在低位范围中的。所以,0x5c根本不是gb2312中的编码,所以自然也是不会与%1a组成一个宽字节字符。
所以,把这个思路扩展到世界上所有多字节编码,我们可以这样认为:只要低位的范围中含有0x5c的编码,就可以进行宽字符注入。
mysql_real_escape_string防御绕过?
防御1
php中有这样一个函数,官网上是这样介绍的

可以看到这个函数对特殊字符进行转义,那么是否可以使用该函数来防御宽字节注入绕过呢?
还是实践一下:
将代码修改为下列形式,主要就是将addslashes函数修改为mysql_real_escape_string
宽字节注入
{$row['title']}{$row['content']}
\n";
mysql_free_result($result);
?>
修改后我们再来试试绕过:
还是绕过了,说明这个函数并不能防御我们的绕过
没有绕过的原因就是,没有指定php连接mysql的字符集。我们需要在执行sql语句之前调用一下mysql_set_charset函数,设置当前连接的字符集为gbk。就可以完美的防御了:
宽字节注入
{$row['title']}{$row['content']}
\n";
mysql_free_result($result);
?>
再来试试: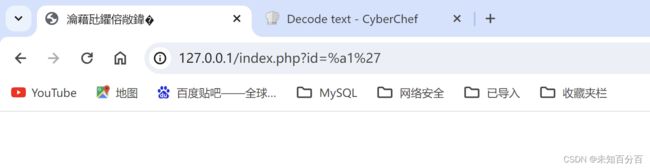
现在就无法绕过了
宽字符注入的修复
防御2
上面已经演示了一种防御宽字节注入的方法,下面再来介绍一种
但是因为有一些老的cms,在多处使用addslashes来过滤字符串,我们不可能去把addslashes都修改成mysql_real_escape_string。
因此这里就需要用到第二个解决方案:将character_set_client设置为binary(二进制)。
只需在所有sql语句前指定一下连接的形式是二进制:
SET character_set_connection=gbk, character_set_results=gbk,character_set_client=binary这几个变量是什么意思?
当我们的mysql接受到客户端的数据后,会认为他的编码是character_set_client,然后会将之将换成character_set_connection的编码,然后进入具体表和字段后,再转换成字段对应的编码。
然后,当查询结果产生后,会从表和字段的编码,转换成character_set_results编码,返回给客户端。
所以,我们将character_set_client设置成binary,就不存在宽字节或多字节的问题了,所有数据以二进制的形式传递,就能有效避免宽字符注入。
那么就可以再次使用上面的代码来演示一下:
宽字节注入
{$row['title']}{$row['content']}
\n";
mysql_free_result($result);
?>
尝试注入:
可以看到,防御成功了
iconv导致的致命后果
本来上面两种防御方法已经可以非常完美的防御宽字节注入了,但是有一些人会在网站的后端配置iconc,来对utf-8进行一个编码目的一般是为了避免乱码,特别是在搜索框的位置。 :
iconv('utf-8', 'gbk', $_GET['word']);
//将utf8编码转换为gbk那我还是使用上面的代码测试一下,上面的代码修改后:
宽字节注入
{$row['title']}{$row['content']}
\n";
mysql_free_result($result);
?>
根据龙哥的提示,我们可以输入一个锦'来导致报错

可以看到居然报错了。说明可以注入。而我只是输入了一个錦'。这是什么原因?
方法2:二次转义
我们来分析一下。“錦“这个字,它的utf-8编码是0xe98ca6,它的gbk编码是0xe55c。
那么就非常的清楚了,\的ascii码正是5c。当我们的錦被iconv从utf-8转换成gbk后,变成了%e5%5c,而后面的'被addslashes变成了%5c%27,这样组合起来就是%e5%5c%5c%27,两个%5c就是\,正好把反斜杠转义了,导致’逃逸出单引号,产生注入。
这正利用了我之前说的,绕过addslashes的两种方式的第二种:将\转义掉。
那么,如果我是用iconv将gbk转换成utf-8呢?
$id = iconv('gbk', 'utf-8', $id);尝试注入:
又成功了。这次直接用宽字符注入的,但实际上问题出在php而不是mysql。
我们知道一个gbk汉字2字节,utf-8汉字3字节,如果我们把gbk转换成utf-8,则php会每两个字节一转换。所以,如果\'前面的字符是奇数的话,势必会吞掉\,'逃出限制。
那么为什么之前utf-8转换成gbk的时候,没有使用这个方法呢?
这跟utf-8的规则有关,UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
从2我们可以看到,对于多字节的符号,其第2、3、4字节的前两位都是10,也就是说,\(0x0000005c)不会出现在utf-8编码中,所以utf-8转换成gbk时,如果有\则php会报错:
但因为gbk编码中包含了\,所以仍然可以利用,只是利用方式不同罢了。
总而言之,调用iconv时千万要小心,避免出现不必要的麻烦。
到次,SQL注入中的盲注就全部复习和演示完毕了,但是SQL注入的学习并没有结束,后面我会和大家分享更多的SQL注入的技巧和实验,我们后面再见(^▽^)