Python数据清洗-——(1)选择子集,列名重命名;(2)缺失值处理;(3)数据转换(重复值等);(4)异常值的处理
注:我在这里用的工具是jupyter notebook,代码里面的注释有些挺重要的,大家要仔细看
1、选择子集,列名重命名
在数据分析的过程中,有可能数据量会非常大,但并不是每一列都有分析的 价值,这时候就要从这些数据中选择有用的子集进行分析,或重命名列,这样才能提高分析的价值和效率。此时,我们应该用到列索引
In [1]:import numpy as np
In [2]:import pandas as pd
In [3]: frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
# 创建一矩阵,“index”是行索引, “column”是列索引
In [4]: frame2
Out[5]:
year state pop debt
one 2000 Ohio 1.5 NaN
two 2001 Ohio 1.7 NaN
three 2002 Ohio 3.6 NaN
four 2001 Nevada 2.4 NaN
five 2002 Nevada 2.9 NaN
six 003 Nevada 3.2 NaN
# 通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series
# 方式一:
In [6]: frame2['state']
Out[7]:
one Ohio
two Ohio
three Ohio
four Nevada
five Nevada
six Nevada
Name: state, dtype: object
# 方式二:
In [8]: frame2.year
Out[9]:
one 2000
two 2001
three 2002
four 2001
five 2002
six 2003
Name: year, dtype: int64
# 索引多条列
In [131]: frame2[['year', 'state']]
Out[131]:
year state
one 2000 Ohio
two 2001 Ohio
three 2002 Ohio
four 2001 Nevada
five 2002 Nevada
six 2003 Nevada
# 也可以通过切片获取列或行,重点注意:列(iloc)的切片索引是前闭后开区间(即包括),行(loc)前闭后闭区间
In [1]: data = pd.DataFrame(np.arange(16).reshape((4, 4)),index=['Ohio', 'Colorado',
'Utah','New York'], columns=['one', 'two', 'three','four'])
# 新建一个随机矩阵,这里涉及到np.arange().reshape()的用法,不了解可以看一下其他博客
In [2]: data
Out[2]:
one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
# 通过切片获取行
In [3]: data[:2]
Out[3]:
Ohio 0 1 2 3
Colorado 4 5 6 7
# 用loc和iloc进行选取,对于DataFrame的行的标签索引,我引入了特殊的标签运算符loc和iloc。它们可以
让你用类似NumPy的标记,使用轴标签(loc)或整数索引(iloc),从DataFrame选择行和列的子集。(这
里重点使用iloc)
# 们通过标签选择一行和多列:
In [4]: data.loc['Colorado', ['two', 'three']]
Out[4]:
two 5
three 6
Name: Colorado, dtype: int64
# 然后用iloc和整数进行选取:
In [5]: data.iloc[2, [3, 0, 1]]
Out[5]:
four 11
one 8
two 9
Name: Utah, dtype: int64
In [6]: data.iloc[2]
Out[6]:
one 8
two 9
three 10
four 11
Name: Utah, dtype: int64
In [7]: data.iloc[[1, 2], [3, 0, 1]]
Out[7]:
four one two
Colorado 7 0 5
# 这两个索引函数也适用于一个标签或多个标签的切片:
In [8]: data.loc[:'Utah', 'two']
Out[8]:
Ohio 0
Colorado 5
Utah 9
Name: two, dtype: int64
In [9]: data.iloc[:, :3][data.three > 5]
Out[9]:
one two three
Colorado 0 5 6
Utah 8 9 10
New York 12 13 14
# 列的重命名
data.rename(columns={‘old_name’:‘new_name’}, inplace = True) #inplace=True是在原df上直接修改2、缺失值处理
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正 常。对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。我 们称其为哨兵值,可以方便的检测出来,pandas项目中还在不断优化内部细节以更好处理缺失数据,像用户API功能,例如 pandas.isnull,去除了许多恼人的细节。表7-1列出了一些关于缺失数据处理的函 数。

In [1]: data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado']) # 创建一个series数组
In [2]: data
Out[2]:
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
In [3]: string_data.isnull() # isnull()查看缺失值,是缺失值返回True,否则返回False
Out[3]:
0 False
1 False
2 True
3 False
dtype: bool
# 处理缺失值常用的两种方法:1、滤除法; 2、替换法(一般使用平均值,众数等替换)
# 方法一:滤除法:
# 对于DataFrame对象,事情就有点复杂了。你可能希望丢弃全NA或含有NA的行或列。dropna默认丢弃任何 含有缺失值的行:
In [1]: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],[NA, NA, NA], [NA, 6.5, 3.]])
In [2]: cleaned = data.dropna()
In [3]: data
Out[3]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
In [4]: cleaned
Out[4]:
0 1 2
0 1.0 6.5 3.0
# 传入how='all'将只丢弃全为NA的那些行:
In [5]: data.dropna(how='all')
Out[5]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
# 用这种方式丢弃列,只需传入axis=1即可:
In [6]: data[4] = NA # 添加一列
In [7]: data
Out[7]:
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
In [8]: data.dropna(axis=1, how='all')
Out[8]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
# 如果一列的缺失值大于80%,那就删除此列(缺失值大于百分之几删除此列可根据自己的需求所选)
In [9]: data[cl] = NA # 添加一列
In [10]: data
Out[10]:
0 1 2 cl
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
In [11]:data1 = data.drop(["cl"], axis=1) # 也可以使用 data.drop(columns=["列名"])
In [11]:data1
Out[12]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
# 删除多列
In [13]:data2 = data.drop(["cl", "2"], axis=1) # 也可以使用 data.drop(columns=["列名1","列名2"])
In [14]:data2
Out[14]:
0 1
0 1.0 6.5
1 1.0 NaN
2 NaN NaN
3 NaN 6.5
# 另一个滤除DataFrame行的问题涉及时间序列数据。假设你只想留下一部分观测数据,可以用thresh参数实 现此目的:
In [9]: df = pd.DataFrame(np.random.randn(7, 3))
In [10]: df.iloc[:4, 1] = NA
In [11]: df.iloc[:2, 2] = NA
In [12]: df
Out[12]:
0 1 2
0 -0.204708 NaN NaN
1 -0.555730 NaN NaN
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
In [13]: df.dropna()
Out[13]:
0 1 2
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
In [14]: df.dropna(thresh=2)
Out[14]:
0 1 2
2 0.092908 NaN 0.769023
3 1.246435 NaN -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
# 方法二:填充缺失数据:
# 你可能不想滤除缺失数据(有可能会丢弃跟它有关的其他数据),而是希望通过其他方式填补那些“洞对于大多数情况而言,fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为那个常数值:
In [1]: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],[NA, NA, NA], [NA, 6.5, 3.]])
In [2]: data
Out[2]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
# 比如,我们把列名为“1”的列的缺失值(空值)填充,填充值为此列的平均值(最常见的方法)
In [3]:mean = np.mean(data["1"])
In [4]:mean
Out[4]:6.5
In [5]:x["1"].fillna(mean, inplace=True)
In [6]:data
Out[6]:
0 1 2
0 1.0 6.5 3.0
1 1.0 6.5 NaN
2 NaN 6.5 NaN
3 NaN 6.5 3.0
3、数据转换(重复值处理)
(1)重复值: 以下代码表示检测重复值,重复值的处理和之前的缺失值处理差不多,也是采用删除的方法。
# DataFrame中出现重复行有多种原因。下面就是一个例子:
In [45]: data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'], 'k2': [1, 1, 2, 3, 3, 4, 4]})
In [46]: data
Out[46]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
# DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行(前面出现过的行):
In [47]: data.duplicated()
Out[47]:
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
# 还有一个与此相关的drop_duplicates方法,默认情况下,它会根据所有列删除重复的行:
In [48]: data1 = data.drop_duplicates()
In [49]:data1
Out[49]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
# 要删除特定列上的重复项,请使用subset
In [50]:data2 = data.drop_duplicates(subest=["k1"])
in [51]:data2
Out[51]:
k1 k2
0 one 1
1 two 1(2)数据转换:对于许多数据集,可能希望根据数组、Series或DataFrame列中的值来实现转换工作,因此可以利用函数或映射进行数据转换
In [52]: data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon','Pastrami',
'corned beef', 'Bacon', 'pastrami', 'honey ham',
'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]}) # 建立一组关肉类的数据
In [53]: data
Out[53]:
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
# 假设我们想要添加一列表示该肉类食物来源的动物类型。我们先编写一个不同肉类到动物的映射:
In [54]:meat_to_animal = {'bacon': 'pig', 'pulled pork': 'pig', 'pastrami': 'cow',
'corned beef': 'cow', 'honey ham': 'pig', 'nova lox': 'salmon'}
# Series的map方法可以接受一个函数或含有映射关系的字典型对象,但是这里有一
个小问题,即有些肉类的首字母大写了,而另一些则没有。因此,我们还需要使用
Series的str.lower方法,将各个值转换为小写:
In [55]: lowercased = data['food'].str.lower()
In [56]: lowercased
Out[56]:
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastrami
7 honey ham
8 nova lox
Name: food, dtype: object
In [57]: data['animal'] = lowercased.map(meat_to_animal)
In [58]: data
Out[58]:
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
# 我们也可以传入一个能够完成全部这些工作的函数:
In [59]: data['food'].map(lambda x: meat_to_animal[x.lower()])
Out[59]:
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object4、异常值的处理:这里介绍两种方法(1)3-sigma原则异常值检测;(2)分箱法(四分点检测法),我比较推荐第二种方法
(1)3-sigma原则异常值检测:3-Sigma原则又称为拉依达准则,该准则定义如下:假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。如果数据服从正态分布,异常值被定义为一组测定值中与平均值的偏差超过3倍的值 → p(|x - μ| > 3σ) ≤ 0.003。
特别注意:数据需要服从正态分布,如果数据不服从正态分布,可以用分箱法做异常值处理
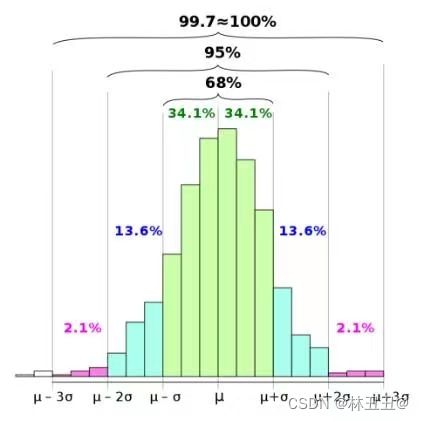
代码如下:数据是我随意捏造的,不服从正态分布,有些离谱,但原理不变
In [1]:import numpy as np
import pandas as pd
# 创建一组DataFream,在实际应用中一般是提取列(根据自己的需求提取)
In [2]:data=pd.DataFrame({'column2'[50,55,60,59,58,69,68,67,798,987,1,2,3,10000,53,63]})
Out[2]:
column2
0 50
1 55
2 60
3 59
4 58
5 69
6 68
7 67
8 798
9 987
10 1
11 2
12 3
13 10000
14 53
15 63
# 计算平均值
In [3]:data_mean = np.mean(data["column2"])
In [4]:data_mean
Out[4]:
774.5625
# 计算方差
In [5]:data_std = np.std(data["column2"])
In [6]:data_std
Out[6]:
2398.547163616707
# 计算正常值的上限
In [7]:data_max = data_mean + 3*data_std
In [8]:data_max
Out[8]:
7970.203990850121
# 计算正常值的下限
In [9]:data_min = data_mean - 3*data_std
In [10]:data_min
Out[10]:
-6421.078990850121
# 根据loc()函数找出异常值的行索引
In [11]:data_new = data.loc[(data['column2']>data_max) | (data['column2'](2)分箱法(四分点检测法):箱形图可以用来观察数据整体的分布情况,利用中位数,25/%分位数,75/%分位数,上边界,下边界等统计量来来描述数据的整体分布情况。通过计算这些统计量,生成一个箱体图,箱体包含了大部分的正常数据,而在箱体上边界和下边界之外的,就是异常数据。
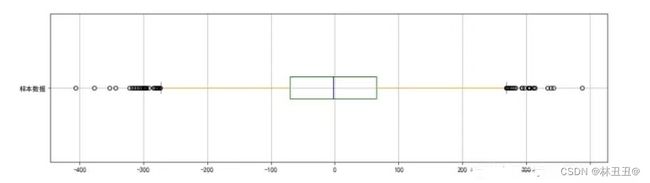
下面这张图是我对四分点检测法的理解:

代码如下:
In [1]:import numpy as np
import pandas as pd
# 创建一组DataFream,在实际应用中一般是提取列(根据自己的需求提取)
In [2]:data=pd.DataFrame({'column2'[50,55,60,59,58,69,68,67,798,987,1,2,3,10000,53,63]})
Out[2]:
column2
0 50
1 55
2 60
3 59
4 58
5 69
6 68
7 67
8 798
9 987
10 1
11 2
12 3
13 10000
14 53
15 63
# 计算Q1 计算1/4分位数
In [3]:Q1 = np.percentile(data['column2'], 25)
In [4]:Q1
Out[4]:
52.25
# 计算Q3 计算3/4分位数
In [5]:Q3 = np.percentile(data['column2'], 75)
In [6]:Q3
Out[6]:
68.25
# 计算IQR距离
In [7]:IQR = Q3 - Q1
In [8]:IQR
Out[8]:
16.0
# 计算异常值步距
In [9]:outlier_step = 1.5 * IQR
In [10]:outlier_step
Out[10]:
24.0
# 计算上限异常值
In [11]:max_limit_box = Q3 + outlier_step
In [12]:max_limit_box
Out[12]:
92.25
# 计算下限异常值
In [13]:min_limit_box = Q1 - outlier_step
In [14]:min_limit_bo
Out[14]:
28.25
In[15]:print('正常值范围是:'+str(min_limit_box)+'---'+str(max_limit_box))
"正常值范围是:28.25---92.25"
# 根据loc()函数找出异常值的行索引
In [16]:data_new = data.loc[(data['column2'] > max_limit_box) | (data['column2']