Linux文本处理三剑客
grep awk sed是Linux下文本处理常用的命令,这篇笔记就是详细阐述文本三剑客的用法。
功能概述:
概述
grep:文本过滤器,仅仅是过滤文本,没有编辑功能
sed:Stream EDitor,流编辑器,可以按照特定规则按行编辑数据(sed是不处理原数据的,编辑完的行默认是打印到屏幕,所以sed运行完原文件内容是不变的)
awk:报告生成器,可以根据特定字符分割行(如空格、冒号、顿号等),然后按照你设定的格式显示。(如果对处理的数据需要生成报告之类的信息,或者你处理的数据是按列进行处理的,最好使用 awk)
适合场景:
grep 更适合单纯的查找或匹配文本
sed 更适合编辑匹配到的文本(尤其擅长替换)
awk 更适合格式化文本,对文本进行较复杂格式处理(擅长取列)
功能详细教程:
一、grep
grep (global search regular expression(RE) and print out the line,全面搜索正则表达式并把匹配到的行打印出来)
是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。
格式:
grep [options] [regex] [file]
- options是带-的选项
- regex是正则表达式
- file是需要grep的文件名
options选项:
-i : 忽略大小写。不会区分大小写字符。也可用–ignore-case 来指定。
-v : 不匹配。通常,grep 程序会打印包含匹配项的文本行。这个选项导致 grep 程序只会打印不包含匹配项的文本行。也可用–invert-match 来指定。
-c : 打印匹配的数量(或者是不匹配的数目,若指定了-v 选项),而不是文本行本身。 也可用–count 选项来指定。
-l : 打印包含匹配项的文件名,而不是文本行本身,也可用–files-with-matches 选项来指定。
-L : 相似于-l 选项,但是只是打印不包含匹配项的文件名。也可用–files-without-match 来指定。
-n : 在每个匹配行之前打印出其位于文件中的相应行号。也可用–line-number 选项来指定。
-h : 应用于多文件搜索,不输出文件名。也可用–no-filename 选项来指定。
Tips:
1、regex为正则表达式,如果想用扩展正则表达式必须用egrep 或者grep -E
2、grep可以接收管道符传过来的文本,这种情况下[file]不需要写了
eg: cat test.txt | grep "#tzq"
二、sed
sed 是一种流编辑器,它是文本处理中非常重要的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。
格式:
sed [options] [commands] [file(s)]
options选项:
| 选项 | 功能 |
|---|---|
| -n | 抑制输出源文件内容,则只有经过sed匹配的那一行才会被打印出来 |
| -i | 修改源文件,sed默认是不会修改原文件的,加上-i选项会直接修改源文件 |
| -e | 该选项允许在同一行里执行多条命令。 |
#-e的例子:
#如例子所示,第一条命令删除 1 至 5 行,第二条命令用check替换test。命令的执行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
sed -e '1,5d' -e 's/test/check/'
commands选项(重点):
常用命令大致的作用:
| 序号 | 命令 | 作用 |
|---|---|---|
| 1 | p | 打印 |
| 2 | s | 替换匹配到的关键字 |
| 3 | c | 替换行 |
| 4 | i | 在行前插入一行内容 |
| 5 | a | 在行后插入一行内容 |
| 6 | d | 删除行 |
1、打印命令:p
-
打印第1行到最后一行:
sed -n "1,$"p test.txt引号为单双引号都行,这里的p必须放在引号外面
-
打印匹配到关键字【吴彦祖】的行
sed -n "/吴彦祖/p" test.txt这里的p放引号里面和外面都可以
-
从第1行打印, 直到匹配含有关键字【吴彦祖】的行(不常用)
sed -n "1,/吴彦祖/"p test.txt这里的p放引号里面和外面都可以
-
打印开始匹配到关键字【吴彦祖】的行, 到匹配到关键字【蔡徐坤】的行:
sed -n "/吴彦祖/,/蔡徐坤/"p taoge.txt
2、替换命令:s
-
常规替换
echo "i love you, you love me" | sed "s/love/like/"默认只替换第一个love
使用s命令,不用-n,替换的那一行也不会重复输出
-
全部替换
echo "i love you, you love me" | sed "s/love/like/g"加上g表示替换出现的所有关键字
-
针对某一行进行替换
sed "2s/so/very/g" test.txt把test.txt文件中第2行中出现的所有【so】都替换为【very】
-
针对多行进行替换
sed "1,2,5s/so/very/g" test.txt
把test.txt文件中第1、2、5行中出现的所有【so】都替换为【very】
-
替换指定序号的关键字
#只替换test.txt文件中出现的第1个【love】 sed "s/love/like/1" test.txt #只替换test.txt文件中出现的第2个【love】 sed "s/love/like/2" test.txt #替换test.txt文件中出现的第2个到最后一个【love】 sed "s/love/like/2g" test.txt -
多模式匹配
#同时替换两种关键字,命令中间用分号,可以一次替换多种关键字 sed "1,4s/I/i/g; 5,6s/I/you/g" taoge.txt -
利用&表示匹配到的关键字
sed "s/so/{&}/g" taoge.txt该命令是给所有关键字【so】加上大括号,里面的&表示匹配到的内容
3、行替换命令:c
-
替换第二行
sed "2 c hahaha" test.txt把第二行内容替换为hahaha了
-
仅仅替换含有关键字【It】的行
sed "/It/ c tzq" test.text把含有关键字【It】的行内容替换为【tzq】
4、行前插入命令:i
-
在第2行前插入新的一行:【oh, my god】
- sed "2 i oh, my god" test.txt -
在1至3行,每一行前都插入一行:【oh, my god】
- sed "1,3 i oh, my god" test.txt
5、行后插入命令:a
-
在最后一行后面插入新的一行:【oh, my god】
sed "$ a oh, my god" test.text
6、删除命令:d
-
删除第一行
sed "1d" test.txt -
删除2到4行
sed "2,4d" test.txt -
删除2到最后一行
sed "2,$"d test.txt这里的d必须放在引号外面,不能跟$写一起
-
删除含有关键字【love】的行
sed "/love/"d taoge.txtd可以放在引号里面,也可以放在外面
sed语法Tips
1、所有引号可以是单引号,也可以是双引号
2、$代表最后一行,^代表第一行,有点类似正则表达式
3、命令可以放在引号内,也可以放在引号外面(除了第4点tips)
4、$不能跟命令连着写,如有需要,应该把命令放在引号外面,比如:
#打印第1行到最后一行 sed -n "1,$"p test.txt #删除2到最后一行 sed "2,$"d test.txt5、-n是抑制自动输出,sed默认执行完自动输出缓冲区的文本,加上-n就抑制自动输出了
三、awk
awk, 它也是一个文本处理器, 是linux下的一个命令, 比sed更强大。 搞linux开发, 尤其是后台开发, 这个命令几乎必须要用到。 awk这三个字母分别代表其三位作者的名字, 而不是某个/某些有意义单词的缩写。
awk的原理:读入有’\n’换行符分割的一条记录,将记录按指定的域分隔符划分域,$0表示所有域, $1表示第一个域, $n表示第n个域。 默认域分隔符是空格键或tab键。
awk支持c、c++语法,功能很强大,所以内容也很多,本笔记这里只记录了简单入门的用法
格式:
awk [option] 'pattern {action}' [file(s)]
Tips:
1、pattern {action}外面必须用单引号
2、[option]主要是-F来指定分隔符,如果不写,则默认分隔符为空白符(空格或制表符),如:
#以冒号为分割符 awk -F “:” '{print $2}' test.txt3、pattern一般为正则表达式(也可以是条件语句,如NR>2),匹配条件符合的行进行awk处理
4、awk可以指定同时读取多个文件,按照指定的先后顺序,逐个读取。
内置变量:
| 内置变量 | 含义 |
|---|---|
| NR | 读取到所有记录(包括多个文件)的行数 |
| NF | 当前行中的字段个数(列数) |
| FS | 输入字段分隔符(默认值为空格) |
| OFS | 输出字段分隔符(默认值为空格) |
其中FS和OFS一般在BEGIN{ }里面设置
参考链接:
关于awk这篇博客写的比较好
附、正则表达式
0、测试文本内容
正则表达式的示例,都是以该文件内容来测试的:
test.text
Hello! / Hi!
Good-bye, "Mike".
See you tomorrow.
It’s time for class.
Open your books and turn to page 20.
Could you say it again?
Where’s the company?
Which is the right size?
Do you know where I’ve put my glasses?
Is this your pen? I found it under the desk.
Which is your bag?
The one on your right.
Are these books all yours?
She must be a model, isn’t she?
I really don’t known.
#I have no idea about it.
What’s your family name?
Rose, let me introduce my friend to you.
Nice to meet you, too.
toooooot
What day is it today?
It’s January the 15th, 1999.
It’s the year of 1999.
However, this dress is about $ 3183 dollars.
1、特殊符号
| 序号 | RE字符 | 代表的含义 |
|---|---|---|
| 1 | [:alnum:] | 代表所有的大小写英文字符和数字,即0-9 A - Z a-z |
| 2 | [:alpha:] | 代表任意英文大小写字符,即A-Z a-z |
| 3 | [:lower:] | 代表小写英文字符,即a-z |
| 4 | [:upper:] | 代表大写英文字符 ,即A-Z |
| 5 | [:digit:] | 代表数字,即0-9 |
示例:
[root@localhost tmp]# grep "[:alnum:]" test.text #运行这句话报错提示
grep: 字符类的语法是 [[:space:]],而非 [:space:]
[root@localhost tmp]# grep "[[:alnum:]]" test.text #我们不能直接使用这些特殊符号,特殊符号全都需要用[]将其括起来

2、正则表达式的RE字符
| 序号 | RE字符 | 含义 |
|---|---|---|
| 1 | ^ | 匹配行首字符 |
| 2 | $ | 匹配行尾字符 |
| 3 | . | 一个任意字符(必须为1个,包括空字符串) |
| 4 | \ | 转义符,去除特殊符号的特殊意义 |
| 5 | * | 前面的一个字符重复0次到无数次 |
| 6 | [] | 表示匹配到里面其中一个字符([123]表示匹配1、2、3中任意一个) |
| 7 | [^] | 表示匹配到除了里面字符之外的其它所有字符 |
| 8 | {n,m} | 一个字符重复n到m次(m和n均含) |
示例(图片序号与上面表格序号一致):
1、
![]()
2、
![]()
3、

4、
![]()
5、
6、

7、

8、
3、grep的扩展正则表达式
用扩展正则必须用egrep 或者grep -E
| 序号 | 扩展RE字符 | 含义 |
|---|---|---|
| 1 | + | 前一个字符重复1+次 |
| 2 | ? | 前一个字符重复0次或1次 |
| 3 | | | 表示或者 |
| 4 | () | 群组字串 |
| 5 | ()+ | 前一个群组字串重复1+次 |
#示例
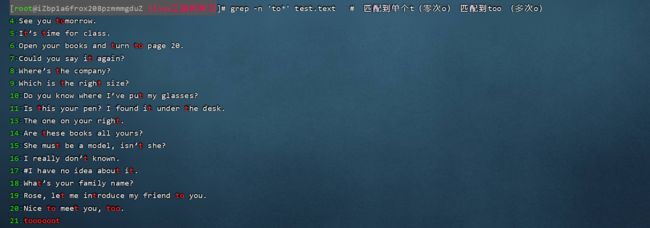
[root@localhost tmp]# echo "tooooabsdsadooo" | grep -E 'too|ab' #表示匹配too或者ab
tooooabsdsadooo #too 和 ab 将被标红
[root@localhost tmp]# echo "goodaaaglad" | grep -E 'g(oo|la)d' #表示匹配到good或者glad
goodaaaglad #good和glad将被标红
[root@localhost tmp]# echo "goodgabcabcabcglad" | grep -E 'g(abc)+g' #是匹配到gabcabcabcg
goodgabcabcabcglad #找的是以g开头g结尾,中间是一个以上的abc