【读点论文】CMTCo Contrastive Learning with Character Movement Task对比学习中的代理任务和数据增强用在手写字符体识别方向
CMT-Co: Contrastive Learning with Character Movement Task for Handwritten Text Recognition
Abstract
- 主流的手写文本识别(HTR)方法需要大规模的标记数据进行训练才能达到满意的效果。最近,对比学习被引入到对未标记数据进行自监督训练以提高表征能力。它使正电子对之间的距离最小化同时使它们与负电子对之间的距离最大化。以往的研究通常将序列特征映射中的每一帧或固定的帧窗口作为一个单独的实例进行对比学习。然而,由于笔迹的随意性和字长的多样性,这种建模可能包含多个连续字符的信息或一个过度分割的子字符,这可能会使模型无法感知语义线索信息。为了解决这一问题,本文设计了一个字符级ptrtext任务,称为字符M运动任务,以辅助单词级对比学习,即CMT-Co。它通过移动单词中的字符来产生伪影,并以移动的方向和距离作为监督来引导模型感知文本内容。此外,我们还为手写文本定制了一种数据增强策略,这对对比学习的训练对的构建有很大的帮助。实验表明,与以前的公共手写基准测试方法相比,所提出的CMT-Co实现了具有竞争力甚至更好的性能。
- 论文地址:ACCV 2022 Open Access Repository (thecvf.com)
Introduction
-
手写文本识别(HTR)是计算机视觉中的一个重要领域。目前大多数手写体文本识别方法都需要全程监督,这不仅耗费大量标注时间,而且成本昂贵。此外,随着大数据时代的到来和网络信息技术的发展,数据采集变得越来越容易,导致未标记数据的数量呈指数级增长。因此,有必要探索如何在不需要人工标注的情况下有效地利用它们。
-
自监督学习为这一问题提供了解决方案,并得到了广泛的研究。它旨在从数据本身学习表示,而无需手动标注。然后在特定的下游任务中对通过自监督过程学习到的特征进行微调,以加快收敛速度或获得更好的性能,同时大大减少了数据标注的数量。
-
早期的自我监督方法经常设计pretext任务。他们专注于发现可以从先验知识或手动修改数据中获得标签的任务。例如,Gidaris等将原始图像以特定角度旋转,然后让网络处理旋转预测任务。值得注意的是,几乎没有专门为手写文本识别设计的pretext任务。
-
近年来,基于对比学习的自监督方法受到了相当大的关注。对比学习的目的是使正对之间的距离最小,而使其与负对之间的距离最大,从而实现特征学习。一些相关研究将这一概念引入了手写文本识别领域。Aberdam等人提出了SeqCLR,它通过在序列特征映射上滑动窗口来创建正样本和负样本,然后对它们进行对比学习。该方法必须保证同一图像的不同增强视图之间的序列对齐,因此,SeqCLR的数据增强方法受到限制。Liu等提出了PerSec,它通过对浅层和深层特征映射的对比学习来学习低级和高级特征。它的目的是使顺序特征的每个元素能够从上下文中区分出来。这些手写文本识别方法通常将序列特征映射中的每个帧或固定的帧窗口作为单独的对比学习实例。然而,由于笔迹的随意性和字长的多样性,这种建模可能包含多个连续字符的信息或一个过度分割的子字符,这可能会使模型无法感知语义线索信息。
-
为了解决这个问题,本文设计了一个字符级的pretext任务,称为字符运动任务(CMT),它适用于手写文本。手写体文本具有独特的先验知识,例如其垂直和水平投影分布,这些先验知识被应用于传统的文档文本分线和分词方法中。对于手写文字图像,我们首先使用垂直投影分布(如下图(a)中的红线所示)来估计每个字符的大致位置。然后,选择一些字符来移动,并生成工件。请注意,工件不会改变单词的含义。最后,需要网络预测移动方向和距离。为了解决字符运动任务,网络需要识别移动的字符,达到字符级特征学习的目的。
-

-
CMT的说明和我们的方法CMT- co。CMT- co将CMT作为辅助任务来辅助对比学习,包括词级学习和字符级学习。表示空间中的红色箭头表示正对的距离最小化,而表示空间中的黑色虚线箭头表示负样本之间的距离最大化。
-
-
为了同时利用词级和字符级语义信息,我们采用CMT作为辅助任务来辅助整个词图像的对比学习,称为CMT- co。此外,为了提高对比学习的有效性,我们为手写文本定制了一种名为text - aug的数据增强策略。它包括四个方面:仿射变换、笔画抖动、笔画重叠和笔画厚度。Text-Aug可以为对比学习框架提供足够的多样性。实验结果表明,与之前的自监督文本识别方法相比,我们的方法在公共手写基准测试中取得了相当甚至更好的性能。本文的主要贡献如下:
- 我们提出了一种字符级的手写体pretext 任务,称为字符运动任务(CMT),它与单词级对比学习过程相结合。据我们所知,这是手写文本识别领域的第一个pretext 任务。
- 我们提出了一种名为Text-Aug的数据增强策略,包括仿射变换、笔画抖动、笔画重叠和笔画厚度,以进一步释放我们框架的力量。
- 整体框架CMT-Co在手写文本的表示质量和下游微调方面,与之前的自监督方法相比,具有竞争力甚至更好的性能。
Related works
Pretext Task
- 早期的自我监督方法通常设计自我监督任务,也称为pretext任务。自监督任务已被广泛研究。他们专注于发现任务,在这些任务中,标签可以从先前的知识或手动修改数据中获得。例如,在图像分类中,Gidaris等将原始图像以特定角度旋转,然后让网络处理旋转预测任务。Doersch等从每张图像中随机提取斑块对,并驱动网络预测第二个斑块相对于第一个斑块的位置。然而,据我们所知,目前在手写体文本识别领域,还没有一种基于手写体文本唯一先验知识来设计pretext任务的方法。
Contrastive Learning
- 除了设计特定的pretext任务外,最近基于对比学习的自我监督方法也显示出了巨大的潜力。SimCLR通过大批量生成负样本。此外,由于丰富的数据增强,它在对比学习后学习到足够的表征,并且在下游任务中表现出令人满意的性能。MoCo设计了对称结构,由一方通过动量更新生成负样本,既不需要提前存储所有数据,也不需要大量批量生成负样本。BYOL设计了不对称结构,无需负样本也能获得令人满意的性能。
- 在手写体文本识别领域,SeqCLR在SimCLR的基础上进行了改进,利用序列特征映射上的实例映射函数生成正样本和负样本。通过滑动窗口从单个图像生成多个实例。同一图像中具有不同数据增强的同一位置为正对。不同位置和其他图像为负样本。但是,这种方法必须保证序列对齐;否则,不同数据增强的同一图像的同一位置可能不包含相同的字符,这极大地限制了SeqCLR的数据增强方法。PerSec通过对比学习从一张图像内的浅特征图和深特征图中学习低级和高级特征。它的目的是使顺序特征的每个元素能够从上下文中区分出来。通常,上述对比学习用于手写体文本识别的实例可能包含多个连续字符或一个过度分割的子字符信息,从而使模型在感知语义信息时产生混淆。
- 因此,本文将利用手写文字文本的先验知识,设计一个字符级字符运动任务,然后在对比学习中辅助整个单词图像的单词级学习,从而在手写文本上取得更好的效果。
Method
Text-Aug
-
从最近关于对比学习的自监督研究中我们知道,数据增强在特征表示学习中起着重要作用。因此,我们设计了一种适合手写文本的数据增强策略。
-
众所周知,文字是由笔画组成的。对于手写文本,由于不同的写作者的风格,相同的单词或字符可能有不同的大小。同一字符的笔画也可能有不同程度的弯曲或扭曲。而且,人们在写字的时候,可能不擦掉写错的字,直接把正确的字覆盖在上面,这样会造成很多笔画重叠。由于书写设备和书写力度的不同,同一字的笔画可能粗细不一致,笔迹可能会分开或粘在一起。
-
因此,针对上述情况,我们为手写文本设计了text - aug。它包括四种类型的文本增强:仿射变换、笔画抖动、笔画重叠和笔画厚度。下图给出了text - aug中这四种类型的文本增强的一些示例。仿射变换包括缩放、平移、旋转、剪切变形和锐化。这种数据增强提供了不同尺度、位置和亮度的文本图像。行程抖动包括分段仿射变换和弹性变换。它们可以模拟文本中笔画的弯曲和抖动。笔画重叠的数据增强模拟了文本图像中笔画的重叠和模糊。它包括混合alpha,运动模糊和高斯模糊。描边厚度包括侵蚀、扩张、乙状体对比和正中模糊。这些增粗可以改变笔画的粗细,也可以改变字的粘接和分离。
-
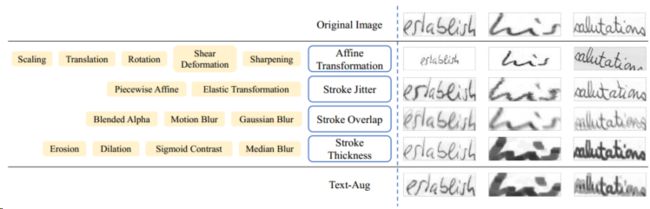
-
Composition of Text-Aug and examples of different parts.
-
缩放, ,旋转,裁剪,锐化,分段仿射,弹性变换,运动模糊,高斯模糊,腐蚀,膨胀,中值模糊
-
-
可以看出,text - aug极大地提高了文本的多样性,可以使网络分辨出更多的可变文本。伪代码和更多的text- aug示例显示在附录中。
Character Movement Task
-
它可以直观地从手写文字图像中知道一些先验知识,例如垂直投影分布,可以给出字符在图像中的大致位置。字符移动任务(CMT)首先通过垂直投影分布对字符进行粗略定位,然后对字符进行移动,最后驱动网络预测字符的移动方向和移动距离。为了解决字符运动任务,网络需要识别移动的字符,达到字符级特征学习的目的。CMT的过程如算法1所示,下面将详细说明。我们假设每个单词图像I都有字符。
-

-
Character Localization: 因为这个任务需要移动字符,我们首先需要定位每个字符在单词图像中的位置。对于手写灰度文字图像,将其大小调整为H × W,然后自适应二值化并归一化为[0,1]。注意,字符所在区域的值为1。最后进行行求和,得到文本图像的垂直投影分布Sta。如图(a)第一幅图所示,红线为垂直投影分布,表示字符像素在对应列位置的投影累计值。根据Sta,我们可以定位文字在文字图像中的大致位置。
-

-
角色移动任务(CMT)的过程说明。
-
-
然而,作家通常在单词的不同字符之间使用连续的笔画。因此,为了近似消除笔划粘附的干扰,我们将Sta中小于t的个数设为零,其中t取Sta中第二小的值。如图(a)第二幅图所示,蓝线表示t的值,将蓝线以下的位置设为零,得到图(a)第三幅图。我们定义一个投影值为非零的连续区域作为字符块区域u,以图(a)中的第三幅图像为例,有三个投影值为非零的连续区域,即有三个字符块区域,u = {u1, u2, u3}。从字符块区域生成的过程可以推断出,每个字符块区域都包含字符。
-
Character Selection: 定位字符在单词图像中的位置后,我们需要选择要移动的字符。我们将所选移动字符的中心位置定义为 l o c b loc_b locb,将移动目标位置定义为 l o c a loc_a loca。角色将从一个地点移动到另一个地点。位置 l o c b loc_b locb 和 l o c a loc_a loca 是从字符块区域集U中随机选择的。
-
如果|U| = 1,则表示只有一个字符块区域U = u1。如果移动过小(比如一两个像素的移动),对肉眼来说是没有区别的,所以强迫网络预测移动距离是不合理的。因此,角色在这里会移动一定的距离。如上图(b)所示,我们首先将u1的前40%表示为h1,将u1的后40%表示为h2。然后,我们从h1和h2中随机选择一个位置。最后,将这两个位置随机用作loca和locb。如果|U|≥2,则表示存在两个或多个字符块区域。在这种情况下,从U中随机选择两个字符块区域ub和ua作为移动前的字符块区域和移动后的字符块区域。然后,我们从ub中随机选择一个位置作为locb,从ua中随机选择一个位置作为loca。
-
在确定选定的移动字符的中心位置后,我们需要指定字符的宽度。首先,我们从 [ 0.15 2 W , 0.25 2 W ] [\frac {0.15}{2} W, \frac {0.25} 2 W] [20.15W,20.25W] 中随机抽取一个值,并将其作为初始移动字符区域宽度的一半,记为 w i n i w_{ini} wini,其中W为图像宽度。则lob与图像边界的最小距离为 b o r d e r b , border_b, borderb, l o c a loc_a loca与图像边界的最小距离为 b o r d e r a border_a bordera,如上图©所示。最终移动字符区域宽度wmove的一半是 w i n i w_{ini} wini, b o r d e r b border_b borderb和 b o r d e r a border_a bordera 之间的最小值。所选字符区域表示为
-
i m g b = I [ 0 : H , l o c b − w m o v e : l o c b + w m o v e ] img_b=I[0:H,loc_b-w_{move}:loc_b+w_{move}] imgb=I[0:H,locb−wmove:locb+wmove]
-
字符被移动到的区域的原始图像为
-
i m g a = I [ 0 : H , l o c a − w m o v e : l o c a + w m o v e ] img_a=I[0:H,loc_a-w_{move}:loc_a+w_{move}] imga=I[0:H,loca−wmove:loca+wmove]
-
最后,将选定的字符区域以1−λ的尺度叠加在图像上,即
-
i m g a = λ i m g a + ( 1 − λ ) i m g b img_a=\lambda img_a+(1-\lambda)img_b imga=λimga+(1−λ)imgb
-
-
I 的其余部分保持不变。我们将人物移动后的图像 I 设置为 MI,这并不改变初始单词图像I的含义。
-
Loss Function:字符移动任务被定义为分类任务。标签y由公式(4)给出。
-
y = p i x e l m + W y=pixel_m+W y=pixelm+W
-
其中W为图像宽度, p i x e l m = l o c a − l o c b pixel_m= loc_a−loc_b pixelm=loca−locb 。当 p i x e l m = 0 pixel_m = 0 pixelm=0 时,图像中没有移动, p i x e l m < 0 pixel_m < 0 pixelm<0 时,角色向左移动; p i x e l m > 0 pixel_m > 0 pixelm>0,表示角色向右移动。
-
-
由于在字符移动之前图像已经被调整过大小,所以像素的取值范围为[−W, W]。因此,分类的类别数为2W + 1。字符移动任务中的损失由式(5)给出。
-
L m o v e = − ∑ i = 1 N y i l o g p i , w h e r e p i = e F ( M I i ) ∑ j = 1 2 W + 1 e F ( M I j ) L_{move}=-\sum_{i=1}^Ny_ilogp_i,where~p_i=\frac{e^{F(MI_i)}}{\sum_{j=1}^{2W+1}e^{F(MI_j)}} Lmove=−i=1∑Nyilogpi,where pi=∑j=12W+1eF(MIj)eF(MIi)
-
其中F表示编码器和多层感知器,N表示小批量大小。
-
-
下图显示了由IAM训练集上的字符运动任务生成的像素分布。
-

-
由CMT生成的像素分布。
-
-
可以看出,左右移动的范围大致相等,分布大致平衡。下图显示了字符移动任务的一些示例。
-

-
Examples of character movement.
-
Overall Framework
-
我们的CMT- co方法在对比学习中使用CMT作为字符级辅助任务来辅助整个词级图像的学习。选择MoCo v2作为基本架构。CMT-Co的总体体系结构如下图所示。在CMT- co中,可以通过全词图像的对比学习来学习单词的高级语义信息,通过CMT学习低级的单字符信息。
-

-
我们的方法CMT-Co的总体框架。CMT- co在对比学习中将CMT作为字符级辅助任务来辅助整个词级图像的学习。请注意,用于计算损失 L m o v e L_{move} Lmove 的标签是由Character Movement模块生成的。
-
-
我们使用text - aug来增强文本图像。然而,由于字符移动任务的重叠现象,我们去除了产生重叠字符的数据增强方法,以防止歧义和干扰字符移动任务的学习。与MoCo类似,我们预先定义了一个大长度的队列,并随机初始化队列。在网络的训练过程中,当前的小批被加入队列,最old的小批被退出队列。对于编码器投影模块生成的每个特征向量,正样本为动量编码器投影模块对同一图像进行不同数据增强后生成的特征向量,负样本为队列中的特征向量。通过动量编码器投影模块提取队列中的特征向量;因此,它应该与编码器投影模块提取的特征相对一致。动量编码器投影模块受MoCo v2的启发,采用与编码器投影模块相同的结构,但不共享参数。形式上,我们将动量编码器投影模块的参数表示为 θ v θ_v θv,将编码器投影模块的参数表示为 θ q θ_q θq, θv由θq初始化,更新为
-
m θ v + ( 1 − m ) θ q → θ v m\theta_v+(1-m)\theta_q\rightarrow\theta_v mθv+(1−m)θq→θv
-
式中m∈[0,1]为动量系数。编码器和动量编码器都是基于cnn的网络。投影和动量投影头是带有隐藏层的多层感知器,它们用于将视觉表示映射到对比空间。用于字符移动任务的多层感知器(MLP)由两个完全连接的层组成,主要是将视觉特征映射转换为向量进行分类。CMT-Co的总损失可表示为:
-
L = L c o n t r a s t + α L m o v e , L c o n s t r a s t = − l o g e x p ( M I q ⋅ k + / τ ) ∑ i = 1 C e x p ( M I q ⋅ k i / τ ) L=L_{contrast}+\alpha L_{move},L_{constrast}=-log\frac{exp(MI_q·k_+/τ)}{\sum_{i=1}^Cexp(MI_q·k_i/τ)} L=Lcontrast+αLmove,Lconstrast=−log∑i=1Cexp(MIq⋅ki/τ)exp(MIq⋅k+/τ)
-
其中,C为队列大小, τ τ τ 为温度超参数, M I q MI_q MIq 为编码器投影模块输出的特征向量,k+为动量编码器投影模块输出的特征向量,ki为队列中的特征向量。α是加权损失项采用的超参数。
-
Experiments
Implementation Details
-
我们在公共手写基准上进行实验,这些基准是IAM , RIMES和CVL。我们使用词级精度作为所有实验的评价指标。我们按照SeqCLR的数据集设置进行预训练和下游微调,训练时只使用训练集。所有图像都被调整为32 × 100作为输入大小。
-
Pre-training and Downstream Fine-tuning Settings: 我们在一个A40 GPU上进行所有实验,小批量大小为256。对于预训练,我们采用与MoCo v2相同的设置。我们使用SGD作为优化器,初始学习率为0.03。对于CMT,式(3)中的叠加尺度λ为0.7。式(8)中的超参数α为0.2。式(7)中的动量系数m为0.999。动量编码器和编码器为ResNet29,与SeqCLR的主干相同。角色移动任务的MLP是两个完全连接的层。投影头和动量投影头是带有隐藏层的多层感知器。我们为每个数据集训练模型68K次迭代,这大约需要20个小时。
-
对于下游微调,我们遵循SeqCLR的设置进行公平比较。具体来说,我们在文本识别中使用“编码器-解码器”范式,其中有两种类型的解码器:基于ctc的解码器和基于注意力的解码器,如下图所示。我们使用Adadelta优化器,初始学习率为2。为了进一步证明Text-Aug的有效性,我们还展示了使用我们的数据增强方法进行下游微调的结果。
-

-
下游任务训练框架。我们遵循SeqCLR的框架。
-
Experimental Results
-
在本节中,我们定量地验证了所提出方法的有效性。我们将我们的方法与之前在手写数据集上基于对比学习的自监督方法(即SeqCLR , PerSec)进行了比较。我们首先对表征质量进行实验,以验证从预训练阶段学习到的编码器参数的表征能力。然后,我们对一定比例的标记训练数据进行实验,进一步验证我们的方法在数据较少的情况下进行微调的效果。
-
Representation Quality :为了检验通过预训练学习到的编码器表示的质量,我们遵循了SeqCLR和PerSec,它们冻结了编码器的参数,只训练了解码器。解码器都是随机初始化的。对于Baseline,我们随机初始化编码器,但对于其他方法,我们使用预训练的参数初始化编码器。
-
下表显示了与我们的方法SimCLR和SeqCLR在IAM、RIMES和CVL数据集上的表示质量比较。结合我们在预训练中的数据增强text - aug,“MoCo v2†”可以达到比SeqCLR更好的性能,SeqCLR是专门为大多数数据集的文本识别而设计的。与SeqCLR相比,基于ctc的解码器方法在IAM数据集上“MoCo v2†”提高了12%。然后,在CMT的辅助下,CMT- co在IAM和CVL数据集上取得了比“MoCo v2†”更好的性能。这证明了我们设计的基于手写文本先验知识的字符运动任务确实有利于自监督表示学习。最后,我们的方法CMT-Co在大多数数据集上优于SeqCLR,在IAM数据集上的改进最为显著,增益为13.4%。
-

-
我们冻结编码器,只训练解码器。粗体代表最好的结果,下划线代表第二好的结果。“Ft aug”表示下游微调时的增量。“Seq.Aug”表示SeqCLR中的增宽。“MoCo v2†”表示我们的数据增强方法Text-Aug用于预训练。
-
-
Downstream Task Fine-tuning,为了进一步证明预训练模型的表示能力,我们探索了模型在少量标记数据上的性能。在下表中,我们分别给出了标记训练数据的5%、10%和100%的结果。在微调中,我们训练整个模型,包括编码器和解码器。基线的编码器和解码器参数随机初始化。其他方法的编码器加载预训练参数,解码器参数随机初始化。
-

-
下游任务微调。我们训练整个模型,包括编码器和解码器。粗体代表最好的结果,下划线代表第二好的结果。“Aug”表示下游微调时的增量。“Seq.Aug”表示SeqCLR中的增宽。“MoCo v2†”表示我们的数据增强方法Text-Aug用于预训练。
-
-
上表显示了与我们的方法SimCLR、SeqCLR和PerSec的下游任务微调比较。可以看到,在大多数数据集中,结合我们在预训练中增强的数据text -aug,“MoCo v2†”的性能可以与专门为文本识别设计的SeqCLR和PerSec相媲美。在CMT的辅助下,CMT- co在大多数尺度的数据集上都有进一步的改进。最终,当在微调期间使用Text-Aug增加数据时,我们的方法再次改进,在所有数据集的尺度上获得最佳或次优结果。利用Text-Aug和CMT的双重功能,我们的方法在IAM数据集上取得了令人满意的性能。
-
下图显示了在IAM数据集上使用基于注意力的解码器进行下游微调期间,基线和CMT-Co之间的训练损失和词级精度。可以看出,CMT-Co预训练的编码器参数确实加快了收敛速度,取得了更好的效果。
-

-
在IAM数据集上使用基于注意力的解码器进行下游微调期间,基线和CMT-Co之间的训练损失和词级精度。
-
Ablation Study
-
在本节中,我们首先探讨了CMT- co中重要部分的作用,包括CMT和数据增强text- aug。然后,我们对CMT中的重要参数λ和损失函数进行消融,其中λ决定了叠加尺度。附录中显示了更多的消融来验证所提出方法的有效性。
-
我们在IAM数据集上进行了消融实验。在微调期间,我们将注意力用于解码器和SeqCLR中的数据增强。下表探讨了CMT-Co两部分的消融情况。
-
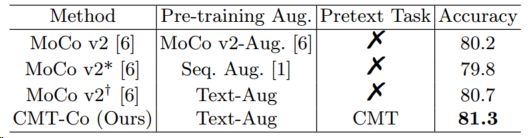
-
数据增强和CMT的消融。“Pre-training aug”表示预训练期间的增强量。“MoCov2-Aug。表示MoCo v2中的增强。“Seq.Aug”表示SeqCLR中的增宽。
-
-
可以看出,Text-Aug的性能优于“MoCo v2-Aug”。和“Seq.Aug”,验证我们的text-Aug策略的有效性。在pretext任务CMT的辅助下,进一步提高了CMT- co方法的性能,显示了CMT的有效性。决定叠加尺度的λ的影响见下表。当λ = 0.7时,CMT-Co的性能达到最佳。
-

-
The ablation of λ.
-
-
虽然在本文中,我们将字符移动任务定义为分类任务,但将CMT定义为回归任务也是合理的。因此,我们也将其作为回归任务来探讨其效果。下表研究了字符运动任务中不同损失函数的消融。
-

-
CMT中不同损失函数的消融。
-
-
“CE”表示交叉熵损失,即我们将CMT视为分类任务,其方程如式(5)所示。“MSE”表示均方损失,即我们将CMT视为回归任务,其方程如式(10)所示。
-
L m o v e = ∥ y p r e d − y ∥ 2 L_{move}=\|y_{pred}-y\|^2 Lmove=∥ypred−y∥2
-
其中 y p r e d y_{pred} ypred 为网络预测,y由CMT生成。可以看出,使用CMT作为分类任务时,性能更好。我们认为CMT不同于重建和生成任务,当预测距离差距变小时,CMT会减少惩罚。为了更好地学习字符的表示,应该准确地预测字符的位置。
-
Conclusion
- 在本文中,我们提出了一种基于手写文本先验知识的字符运动任务(CMT)来学习字符级特征。我们的CMT- co方法在对比学习中使用CMT作为字符级辅助任务来辅助整个词级图像的学习。此外,为了更好地提高对比学习的性能,我们还提出了一种适用于手写文本的数据增强策略text - aug。实验表明,我们的方法可以达到与现有的自监督文本识别方法相当甚至更好的性能。在未来,值得探索更有效的文本相关的pretext任务和多任务自监督学习方法。此外,我们希望这项工作可以激发更多关于文本识别的自监督学习的研究,这在文献中还没有得到很好的研究。