ElasticSearch基本使用
官网:Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用lava开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用
一、ES安装
提前说明:Elaticsearch基于java1.8以上使用 我们需要安装客户端与界面工具 Elaticsearch的版本要与java的jar包依赖对应
解压即可使用

启动elasticsearch.bat 访问 127.0.0.1:9200
安装可视化插件
- 安装elasticsearch-head插件(需要Node.js环境)
- 解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"
另外,也可以之间安装对应的elasticsearch-head 谷歌插件 不会有跨域问题

了解 ELK
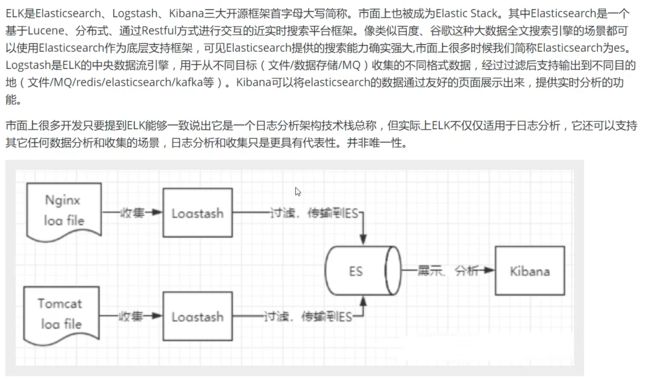
Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard ) 实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
官网:Kibana:数据的探索、可视化和分析 | Elastic 下载的版本要一致、需要依赖Node环境
解压完成之后 启动kibana.bat 访问 http://localhost:5601

网站默认是英文,更改配置文件
i18n.locale: "zh-CN"
相关工具下载地址
下载慢的小伙伴们可以到 华为云的镜像去下载
速度很快,自己找对应版本就可以
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
至此 工具安装完毕
二、相关概念
elasticsearch是面向文档
关系行数据库和elasticsearch客观的对比!

物理设计∶
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
默认的集群名称就是elasticsearch
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的一各顺序找到它:索引》类型文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串。
文档

索引
就是数据库! 索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
如何分片

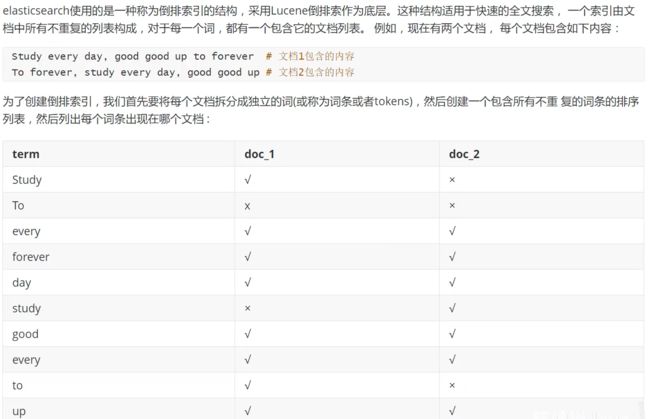
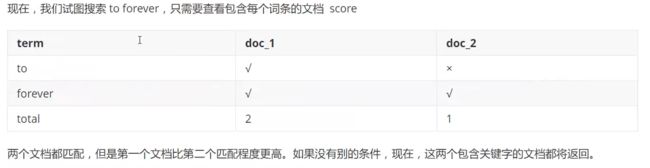
倒排索引
三、IK分词器
什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,不符合要求
IK提供了两个分词算法:ik_ smart和ik_max_word,其中ik smart为最少切分,ik_max_word为最细粒度划分!
- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 下载完毕后放入elasticsearch插件中即可 注意版本对应
- 启动elasticsearch

- 使用kibana测试
ik smart为最少切分:

ik_max_word为最细粒度划分:
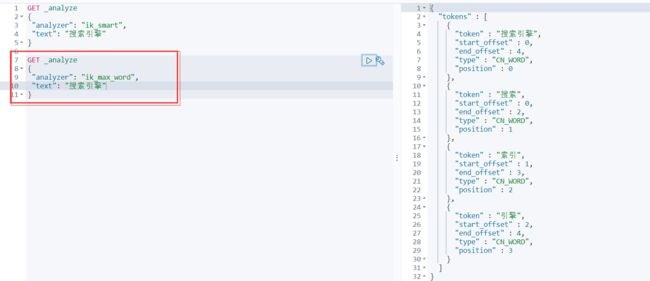
- 有时候分词器不能得出我们想要的,所以需要配置字典

我们需要自己配置分词就在自己定义的dic文件中进行配置即可!
四、基本操作
**Rest风格说明:**一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。

创建索引
- 创建一个索引
PUT /索引名/类型名()可省略/文档id
{ 请求体 }

2. 指定的类型

3. 指定字段的类型
# 创建规则
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
查看信息
- 查看规则
GET test2
- 查看默认的信息
PUT /test3/_doc/1
{
"name": "前度",
"age": 10
}
GET test3
如果自己的文档字段没有指定,那么es就会给我们默认配置字段类型 另外通过命令elasticsearch索引情况!通过 get _cat/ 可以获得es的当前的很多信息!
修改索引
方法1:提交还是使用PUT即可!然后覆盖!最新办法!
方法2:
POST /test1/type1/1/_update
{
"doc":{
"name": "张三"
}
}
删除索引
通过DELETE命令实现删除、根据你的请求来判断是删除索引还是删除文档记录!
DELETE test2
- 简单搜索
GET test1/_search?q=name:前度
_search:代表搜素
?q=xxxx: 搜素条件
-
复杂搜索
我们之后使用Java操作es ,所有的方法和对象就是这里面的key !

情景2:限制显示的字段信息

情景3:排序

情景4:分页查询

情景5:多条件都满足查询
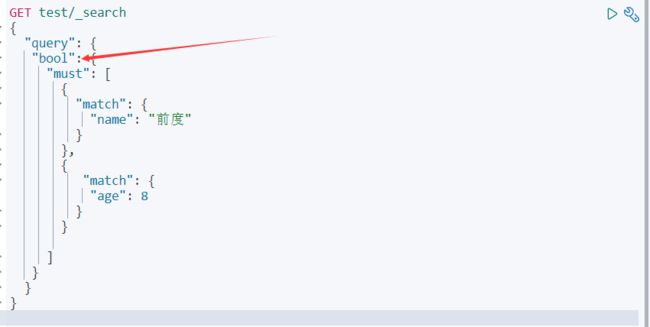
情景6:或(OR)查询

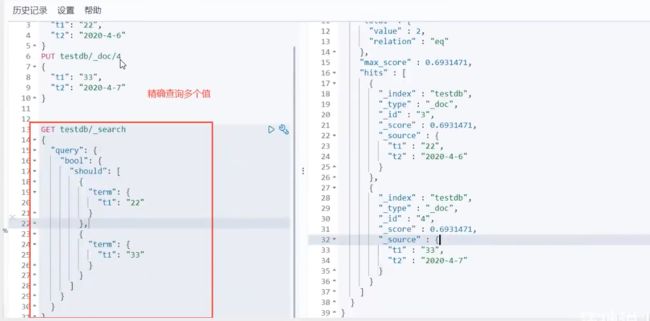
情景7:精确查询

情景8:高亮显示
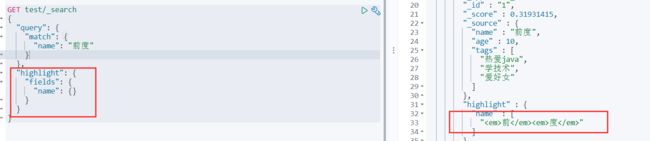
我们也能自定义高亮显示样式

五、集成SpringBoot
- 导入依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>7.6.2version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.2version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
<version>7.6.2version>
dependency>
自定义版本:

2. 构建与关闭

3. 源码


4. 配置
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
));
return client;
}
}
索引API操作
- 创建索引
@Autowired
private RestHighLevelClient client;
//索引的创建 Request
@Test
public void creatIndex() throws IOException {
//1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("qiandu_index");
//2、执行请求->请求后获得响应
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
- 判断索引是否存在
//获取索引
public void existsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("qiandu_index");
//判断索引是否存在
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
}
- 删除索引
//删除索引
public void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("qiandu_index");
//判断索引是否存在
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//返回true代表删除
System.out.println(delete.isAcknowledged());
}
文档API操作
首先需要创建实体类
- 添加文档
//添加文档
public void addDocument() throws IOException {
// 创建对象
User user = new User(1, "qiandu");
//创建请求
IndexRequest request = new IndexRequest("qinadu_index");
//设置规则 PUT /qiandu_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
//将数据放入请求 JSON
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writeValueAsString(user);
request.source(s, XContentType.JSON);
//发送请求,获取响应结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
//返回的状态:create/update
System.out.println(indexResponse.status());
}
- 获取文档,判断是否存在
//获取文档,判断是否存在 GET qiandu_index/1
public void existsDocument() throws IOException {
GetRequest request = new GetRequest("qiandu_index", "1");
//不获取返回的_source的上下文
request.fetchSourceContext(FetchSourceContext.DO_NOT_FETCH_SOURCE);
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
- 获取文档的信息
//获取文档的信息
public void getDocument() throws IOException {
GetRequest request = new GetRequest("qiandu_index", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//打印内容 或者用map
System.out.println(response.getSourceAsString());
//返回全部内容
System.out.println(response);
}
- 更新文档信息
//更新文档信息
public void updateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("qindau_index", "1");
request.timeout("1s");
User user = new User(2, "前度");
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writeValueAsString(user);
request.doc(s, XContentType.JSON);
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println(response.status());
}
- 删除文档
//删除文档
public void deleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("qinadu_index", "2");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response.status());
}
- 批量插入数据
//批量插入/删除/更新数据
public void insert() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User(1, "前度1"));
userList.add(new User(2, "前度2"));
ObjectMapper objectMapper = new ObjectMapper();
for (int i = 0; i < userList.size(); i++) {
//批量更新/删除也是如此
bulkRequest.add(
new IndexRequest("qiandu_index")
.id("" + (i + 1))
.source(objectMapper.writeValueAsString(userList.get(i)), XContentType.JSON)
);
}
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//判断是否执行成功 返回false表示成功
System.out.println(response.hasFailures());
}
- 查询
//查询
public void query() throws IOException {
SearchRequest request = new SearchRequest("qiandu_index");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//设置高亮显示
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags(");
highlightBuilder.postTags("
");
highlightBuilder.field("name");
highlightBuilder.requireFieldMatch()
TermQueryBuilder termQuery = QueryBuilders.termQuery("name", "前度");
sourceBuilder.query(termQuery).highlighter(highlightBuilder);
//设置超时
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(sourceBuilder);
//执行请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//返回的所有数据都在hits中
System.out.println(response.getHits());
//打印
for (SearchHit document : response.getHits().getHits()) {
//原结果
System.out.println(document.getSourceAsMap());
Map<String, HighlightField> highlightFields = document.getHighlightFields();
//得到高亮的字段
HighlightField field = highlightFields.get("name");
//原来的结果
Map<String, Object> sourceAsMap = document.getSourceAsMap();
//解析高亮的字段,替换原来的字段
if (field != null) {
Text[] fragments = field.fragments();
String n_field = "";
for (Text text : fragments) {
n_field += text;
}
sourceAsMap.put("name", n_field);
}
//sourceAsMap放入list中
}
}

简单使用
1、
2、

The End~~