高级SQL优化 | 如何优化Order by Random
本篇属于PawSQL的高级SQL优化系列专题中的一篇,该专题介绍PawSQL引擎优化算法原理及优化案例,欢迎大家微信搜索PawSQL订阅专题。
问题定义
我们有时候会使用以下查询语句获取数据集的随机样本。
select * from orders order by random() limit 10;
MySQL的函数
rand或PostgreSQL的函数random会返回一个在范围0到1.0之间的随机浮点数。
它的执行计划如下,
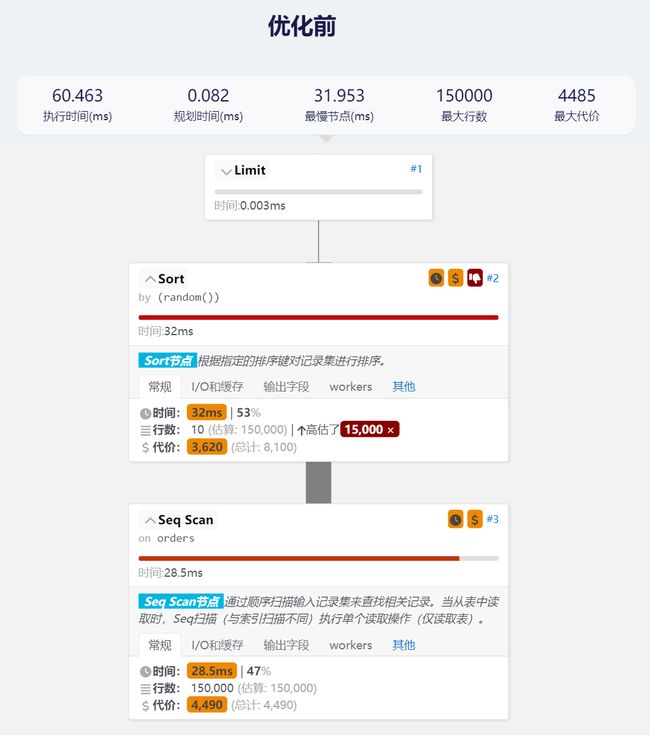
如果orders表少于10,000行,则此方法效果很好。但是当您有1,000,000行时,排序的开销变得不可接受。原因很明显:我们将所有行排序,但只保留其中的一行。其实有更高效的方法来实现此需求,本文所用的测试表为150000行。
解决方案
1.如果在一个数值列上有一个唯一索引,且该列的值均匀分布,那么查询可以被重写为一个更高效的查询,以避免全表扫描和包含所有行的排序操作。
如果在orders的o_orderkey列存在一个唯一性索引。
create unique index ord_idx_key on orders(o_orderkey)
那么上面的SQL就可以重写为下面这个SQL,
select
*
from
orders
where
o_orderkey >= (
select
floor( RANDOM() * ((select MAX(o_orderkey) from orders)-(select MIN(o_orderkey) from orders)) + (select MIN(o_orderkey) from orders)))
order by
o_orderkey
limit 10;
它的执行计划为
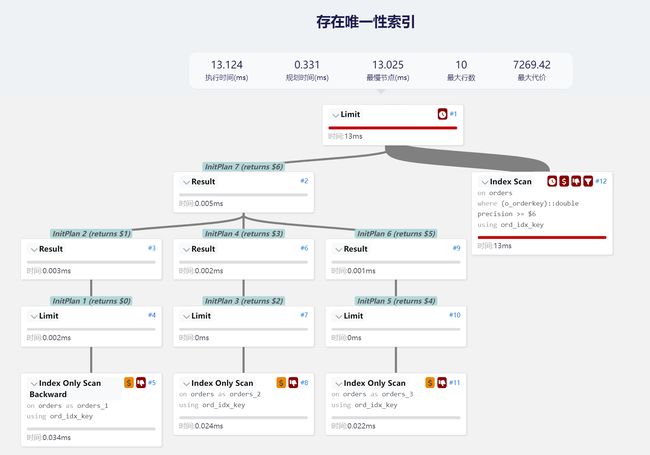
可以看到它执行时间为13.124ms,相比较原始SQL提升了450%左右。
2.否则, 我们可以创建一个map表来创建一个连续且唯一的列,并基于这个列来获取一个随机的行.
create table orders_key_map ( row_id integer GENERATED ALWAYS AS IDENTITY PRIMARY KEY, o_orderkey int not null);
INSERT INTO orders_key_map(o_orderkey) SELECT o_orderkey FROM orders;
> select * from orders_key_map;
+--------+-----------+
| row_id | o_orderkey |
+--------+-----------+
| 1 | 100 |
| 2 | 102 |
| 3 | 300 |
| 4 | 833 |
| 5 | 1116 |
+--------+-----------+
获取这个随机行的SQL如下:
select
*
from
orders o, orders_key_map m
where
o.o_orderkey = m.o_orderkey
m.row_id >= (
select
floor( RAND() * ((select MAX(row_id) from orders_key_map)-(select MIN(row_id) from orders_key_map)) + (select MIN(row_id) from orders_key_map)))
order by
row_id
limit 10;
其执行计划如下

可以看到其执行时间为3ms左右,性能相比较原SQL提升了20倍。虽然它比第一种方案的性能更佳,但是需要引入一张临时表,逻辑上更加复杂。具体采用哪一种方式,读者可以根据自己的实际情况进行选择。
关于PawSQL
PawSQL专注数据库性能优化的自动化和智能化,支持MySQL,PostgreSQL,openGauss,Oracle等,提供的SQL优化产品包括
- PawSQL Cloud,在线自动化SQL优化工具,支持SQL审查,智能查询重写、基于代价的索引推荐,适用于数据库管理员及数据应用开发人员,
- PawSQL Advisor,IntelliJ 插件, 适用于数据应用开发人员,可以IDEA/DataGrip应用市场通过名称搜索“PawSQL Advisor”安装。
- PawSQL Engine, 是PawSQL系列产品的后端优化引擎,可以独立安装部署,并通过http/json的接口提供SQL优化服务。PawSQL Engine以docker镜像的方式提供部署安装。
联系我们
- 网址:https://www.pawsql.com
- 邮件:[email protected]
- Twitter: https://twitter.com/pawsql
- 微信搜索并关注PawSQL公众号