基于Python的微信聊天记录分析——数据处理与分析
本篇为《基于Python的微信聊天记录分析》系列的第二篇,主要讲解获取到聊天记录数据之后,在Python环境下对其进行数据处理、分析和可视化,涉及库的安装、相关操作的Python代码等内容。希望和大家多多交流,共同进步!
一. 数据处理
数据分析的基础是“数据”,俗话说基础不牢,地动山摇!对于聊天记录分析这件事儿来说,数据处理是十分有必要的,我们需要将茫茫多的记录中的无意义或意义不明数据过滤,这样才有助于后续的数据分析,那么就来到了本篇内容的第一部分——数据处理。
1. 相关库的安装
工欲善其事,必先利其器。完成这部分内容需要安装一些库,比如pandas、jieba、matplotlib等等(这部分不一定非得用我上面列的,有很多种方法可以达成目的,有一定基础的童鞋可以自由发挥),下面我对篇中数据处理用到的相关库进行简单介绍:
- Pandas(用于数据分析):据说pandas的名字来自于“python data analysis”,可以直观地看出它是专门用于python环境下的数据分析的扩展程序库,它的基础是numpy,在pandas中,有很多高性能、易于使用的数据结构和分析函数。有了它,从文件中导入结构化数据就不在话下了,它可以对各种数据进行运算,比如合并、选择、加工等等。
- jieba(用于中文分词):jieba的主要功能是做中文分词,可以进行简单分词、并行分词、命令行分词,当然它的功能不限于此,目前还支持关键词提取、词性标注、词位置查询等,目前来说,它是做中文分词比较好的库之一。
- matplotlib(用于可视化):matplotlib是python环境下的2D绘图库,利用它可以将数据可视化,只需几行代码即可生成直方图,条形图,饼图,散点图等,在数据处理中较为常用。
相关库在Anaconda Prompt中的安装命令如下:
pip install pandas jieba matplotlib安装完毕后,会显示如下信息,successfully就意味着成功啦:

也可以安装后import加载一下,不报错的话就ok ~
# 导入依赖库
import pandas as pd
import matplotlib.pyplot as plt
import jieba2. 数据清洗
数据清洗之前,可先通过pandas库中读取csv的相关函数加载聊天记录文件,该函数加载后是DataFrame格式,十分便于后续操作,大家可以将以下代码中的数据文件路径修改成自己的路径。
# 项目路径
project_path = 'D:\\Projects\\chatmsg-analysis\\chatmsg.csv' # 需要换成自己的路径
# pandas读取csv文件
msg = pd.read_csv(project_path)读取聊天记录中数据之后, 首先看一下格式(我这边使用PyCharm撰写和编辑代码,大家可以自由选择,Anaconda中自带的spyder之类的都可以),数据字段如下表所示,其中标红字段为重点使用字段,涉及是否发送者、文本内容、时间等内容:
| 字段名称 |
含义 |
| Localld |
数据ID(计数) |
| TalkerId |
聊天对象ID |
| Type |
数据类型(文本为1) |
| SubType |
子类型 |
| IsSender |
是否发送者(本人为1,对方为0) |
| CreateTime |
时间戳 |
| Status |
—— |
| StrContent |
文本内容 |
| StrTime |
时间(年月日时分秒标准格式) |
| Remark |
—— |
| NickName |
—— |
| Sender |
—— |
大概了解数据格式和数据内容之后,下面我们要做数据清洗,由于我们是基于文本内容分析的,需要将文本之外的数据滤除,以下代码滤除了聊天内容中的链接、撤回等信息,大家可以参考。
def datacleansing(data):
# 过滤分享的链接等数据
data_processed = data[data['StrContent'].str.contains('http') == False]
data_processed = data_processed[data_processed['StrContent'].str.contains('') == False]
# 过滤撤回数据
data_processed = data_processed[data_processed['StrContent'].str.contains('撤回了一条') == False]
return data_processed
# 运行
msg_processed = datacleansing(msg) 到此数据清洗就基本结束了,下面开始数据的统计分析~
二. 统计分析
本章主要涉及聊天数据的频次、描述性等方面统计:
1. 按日期统计聊天频次
首先是按日期统计两人的聊天频次,分别为总频次、主方频次和对方频次,这样可以对谁说的多、谁说的少一览无余~下面上代码:
# 首先划定需要分析的聊天记录时间范围,我这边选取了2023一整年的记录作为分析样本
msg_processed_time = msg_processed.loc[(msg_processed['StrTime'] >= '2023-01-01') & (msg_processed['StrTime'] <= '2024-01-01')]
# 下面利用IsSender字段将主对方分开
msg_total = msg_processed_time # 总
msg_i = msg_processed_time[msg_processed_time["IsSender"] == 1] # 我自己
msg_u = msg_processed_time[msg_processed_time["IsSender"] == 0] # 对方
# 加时间索引
msg_total['StrTime'] = pd.to_datetime(msg_total['StrTime'])
msg_total = msg_total.set_index('StrTime')
msg_i['StrTime'] = pd.to_datetime(msg_i['StrTime'])
msg_i = msg_i.set_index('StrTime')
msg_u['StrTime'] = pd.to_datetime(msg_u['StrTime'])
msg_u = msg_u.set_index('StrTime')
# 设计统计字段count
msg_total["count"] = 1
msg_i["count"] = 1
msg_u["count"] = 1
# 按天统计聊天频次
result_total_day = msg_total.resample('D').sum()
result_i_day = msg_i.resample('D').sum()
result_u_day = msg_u.resample('D').sum()到此,result中的count字段就是每天的聊天次数啦!
2. 按每日不同时段统计聊天频次
然后就是按每日不同时段来统计两人的聊天频次,我这里将一天分为0-23共24个时段,计算出一年内各时段的累计聊天次数,代码如下:
# copy一份数据
msg_phase_total = msg_processed_time
# 由于我们要根据StrTime字段划分时段,因此先将其转为字符串,便于后续操作
msg_phase_total['StrTime'] = msg_phase_total['StrTime'].apply(lambda x: x.strftime('%Y-%m-%d %H:%M:%S'))
# 取每日时段(小时部分):将StrTime字段重构成time_phase字段
time_phase = msg_phase_total.pop('StrTime')
time_phase = time_phase.str[11:13]
msg_phase_total.insert(1, 'time_phase', time_phase)
# 取主对方
msg_phase_i = msg_phase_total[msg_phase_total["IsSender"] == 1]
msg_phase_u = msg_phase_total[msg_phase_total["IsSender"] == 0]
# 算出各时段聊天次数
result_total_tp = msg_phase_total['time_phase'].value_counts()
result_i_tp = msg_phase_i['time_phase'].value_counts()
result_u_tp = msg_phase_u['time_phase'].value_counts()根据上述操作,一年内每日不同时段的聊天次数就统计在result中了。
3. 高频词汇统计
最后是高频词汇统计,这个环节就要用到一开始提到的jieba了,我们要利用jieba.cut函数对聊天记录中StrContent字段进行中文分词,代码如下:
# 分词函数
def obtain_word(data):
word = jieba.cut(data)
return list(word)
# copy一份数据
msg_word_total = msg_processed_time
# 将StrContent字段分词形成word字段
msg_word_total['word'] = msg_word_total['StrContent'].apply(obtain_word)
# 统计word字段中各词汇频次
result_word = pd.Series(msg_word_total['word'].sum()).value_counts()
# 需要将Series转换为DataFrame格式,便于画图
result_word_list = {'labels': result_word.index, 'counts': result_word.values}
result_word_new = pd.DataFrame(result_word_list)为了提高分词质量,jieba支持常用词列表,可在项目路径下生成文件,执行如下代码加载常用词配置:
import sys
sys.path.append("../")
# 加载常用词配置
jieba.load_userdict("userdict.txt")稍微讲讲常用词字典配置,一个常用词占一行,分为三部分:词语、词频、词性(空格分隔),示例如下:
词语 词频 词性
勒布朗 20 nr
詹姆斯 100 nr
打篮球 10 v
如果还不太会的童鞋可以在csdn搜一搜,资料贼多~
三. 结果可视化
通过第二章,实际已经把可视化所需要的数据统计出来了,这里我们通过matplotlib库来进行简单的可视化~
- 聊天频次类——折线图
下面是代码,两行就能搞定!
import matplotlib.pyplot as plt
# 聊天频次折线图
plt.plot(result_total_day.loc[:, ['count']])
plt.show()结果如下:

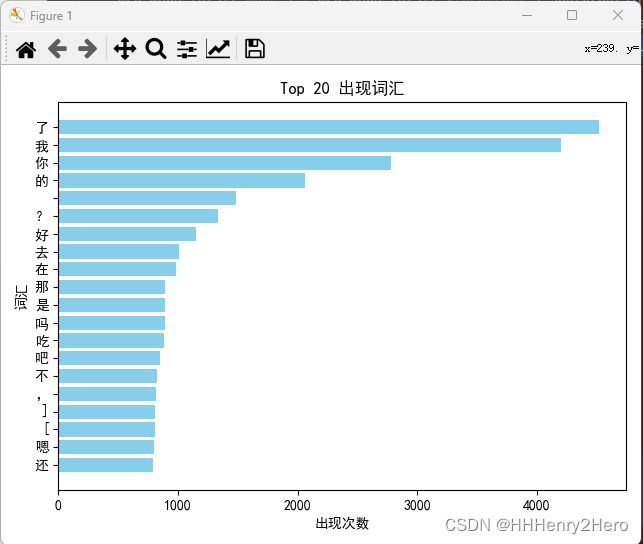
- 词汇出现次数——柱状图
这部分我输出了出现次数较多的Top20词汇,并且添加了标题、横纵坐标标注,大家可以参考:
# 要配置这些,否则会出现中文乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 从二-3的结果中提取数据和标签
top = result_word_new.head(20)
labels = top.iloc[:, 0]
counts = top.iloc[:, 1]
# 创建条形图
plt.barh(labels, counts, color='skyblue')
plt.xlabel('出现次数')
plt.ylabel('词汇')
plt.title('Top 20 出现词汇')
# 反转y轴,使得指标显示正确
plt.gca().invert_yaxis()
# 紧凑布局,确保y轴完全显示
plt.tight_layout()
plt.show()
结果如下(质量还有提升空间):
四. 学习后记
本篇我是在Python环境下,利用pandas、jieba、matplotlib等库对聊天记录csv数据进行数据处理、统计分析和结果可视化,大部分内容都是基础的数据分析,仅涉及了一点点文本分词内容;有的环节还可以优化,部分代码有些粗糙(有的地方甚至可以利用成熟软件来做,比如武汉大学的ROST等等),还望大家包容、见谅!希望多多进步,下一章打算进行一些情绪/情感分析。
与诸君共勉~
如何获取聊天记录数据可参考:
基于Python的微信聊天记录分析——数据获取