华清远见-重庆中心-数据库阶段技术总结/知识点梳理/个人总结
文章目录
- 前端、后端、数据库
- 数据和信息
- 数据库
- 数据库管理系统
- 总结
- 常见的数据库管理系统
-
- 关系型数据库
- 非关系型数据库
- MySQL8.x的安装和使用
-
- 1.下载
- 2.卸载
- 3.安装
- MySQL控制台常用命令
- 数据库管理系统图形化管理工具
-
- Navicat15优化学习版(呵呵)
- 使用
-
- 创建数据库
- 切换数据库
- 创建数据表
- 修改数据表
- SQL
-
- 操作数据库
-
- 1.创建数据库
- 2.切换数据库
- 3.删除数据库
- 操作数据表
-
- 1.创建数据表
- 2.删除数据表
- 3.修改数据表
- 添加约束
-
- 1.添加非空约束
- 2.添加主键约束
- 3.添加唯一约束
- 4.添加默认值约束
- 5.添加外键约束
- 建表的同时添加约束
- 数据完整性
-
- MySQL中常见的数据类型
- 约束
- 操作数据
- 数据添加insert
-
- 给所有字段赋值
- 给指定字段赋值
- 批量添加
- 数据修改update
-
- 修改单个字段的所有值
- 修改多个字段的所有值
- 根据条件修改(where子句)
-
- 指定值
- 指定范围
- 指定集合
- 空值
- 模糊查询
- 数据删除delete
-
- 删除所有
- 条件删除
- 数据查询select
-
- 查询所有字段
- 查询指定字段
- 字段重命名
- 查询指定条数
- 去重复
- 条件查询
- 排序
- 统计函数(聚合函数)
- 数学相关函数
- 字符串相关函数
- 时间相关函数
- 分组
-
- group_concat()函数
- 实际业务对应sql
-
- 登录
- 注册
- 充值
- 删除
-
- 逻辑删除
- 物理删除
- 连接查询
-
- 交叉连接、笛卡尔积
- 内连接
- 左连接
- 右连接
- 嵌套查询
- Jar
-
- 在Java项目中使用.jar文件
- JDBC
-
- 核心接口
- 数据查询
- 数据增删改
- SQL注入
- 使用数据库帮助类简化JDBC操作
-
- DBUtil类
- 实体类BookInfo
- 数据操作类BookInfoDao
- 实体关系模型
- 实体之间的关系
-
- 一对一
-
- ER图
- 在数据库中创建表的过程
- 一对多/多对一
-
- ER图
- 在数据库中创建表的过程
- 多对多
-
- ER图
- 在数据库中创建表的过程
- 总结
- 练习
- 数据库设计规范
-
- 第一范式1NF
- 第二范式2NF
- 第三范式3NF
- 最终根据实体关系模型进行优化,体现对应关系。
- 名词解释
-
- 主键/主码/主属性
- 联合主键
- 完全依赖
- 部分依赖
- 传递依赖
- 行列转换
- 视图View
-
- 创建视图
- 使用视图
- 删除视图
- 事务transaction
-
- 事务的特性ACID
-
- 原子性Atomicity
- 一致性Consistency
- 隔离性Isolation
- 持久性Durability
- 事务的使用
-
- 提交:commit
- 回滚:rollback
- 手动提交/回滚事务
- 事务并发可能出现的问题
- 事务隔离级别
- 查看事务隔离级别
- 设置事务隔离级别
- 触发器trigger
-
- 创建触发器
- 使用触发器
- 删除触发器
- 存储过程procedure
-
- 调用存储过程
- 定义存储过程
-
- 无参数
- 输入型参数
- 输出型参数
- 输入输出型参数
- 删除存储过程
- MySQL编程
-
- 定义变量
- 给变量赋值
- 读取变量的值
- 条件语句
-
- 单分支if语句
- 双分支if语句
- case语句
- 循环语句
-
- while循环
- repeat循环
- loop循环
- MySQL核心内容
-
- SQL语句
- 数据库设计
- JDBC
- 事务
- 存储引擎
- 循环语句
-
- while循环
- repeat循环
- loop循环
- MySQL核心内容
-
- SQL语句
- 数据库设计
- JDBC
- 事务
- 存储引擎
- 学习中的Sample
-
- 简单的控制台商品管理
- 学习中遇见的问题
- 错题
- 总结
前端、后端、数据库
前端 展示数据
后端 处理数据,得到有用的信息
数据库 保存数据
数据和信息
Data数据
任何描述事物的文字和符号的都可以称为数据。
软件开发就是为了收集数据,从中筛选出有用的信息。
Infomation信息
数据经过处理之后得到的内容称为信息。
数据需要保存,保存的介质有内存和硬盘等。
内存中的数据是临时的,随着系统的关闭,数据也会消失;
硬盘中的数据是永久的,就算系统关闭,数据依然保留。
excel等文件保存数据是一种保存到硬盘中的途径,
但是如果大量数据要保存,文件系统就不再方便。
使用一个系统化的数据仓库才能更高效地处理数据。
数据库
DataBase,简称为DB
运行在操作系统上,按一定的数据结构,保存数据的仓库。是一个电子化的文件柜。
数据永久保存在硬盘中。
数据库管理系统
DataBase Manager System,简称为DBMS
通常所说的数据库,是指数据库管理系统,如MySQL、Oracle等。
是一种操作和管理数据库的大型软件,用于建立、使用和维护数据库。
总结
- 数据Data需要永久保存到数据库中
- 数据库DB是运行在操作系统上的一个软件
- 数据库管理系统DBMS是管理数据库的一个软件
- 学习数据库就是学习如何使用DBMS创建、使用数据仓库来管理数据
常见的数据库管理系统
关系型数据库
关系型数据库是主流的数据库类型。
数据通过行row和列column的形式(表格)保存。
每行称为一条记录。
每列称为一个字段。
字段通常为Java中某个类的属性,通过这个类创建的对象,就是一条记录。
如class Employee,有员工编号、姓名、部门、工资等属性,
对应数据库中有一个Employee表,这个表中有员工编号、姓名、部门、工资等字段。
关系型数据库,数据表直接有关联,能快速地查询出想要的数据。

关系型数据库的特点
-
优点
- 易于维护:都是使用表结构存储数据,格式一致
- 使用方便:SQL语句通用,可用于不同关系型数据库
- 复杂查询:可以通过SQL语句在多个表之间查询出复杂数据
-
缺点
- 读写性能差,尤其是还是数据的高效读写
- 固定的表结构,灵活度少欠
- 高并发读写时,硬盘I/O决定了读写速度
非关系型数据库
数据通过对象的形式保存,对象可以是一个键值对、文档、图片等。

非关系型数据库的特点
- 保存数据的格式多样
- 对于海量数据的读写性能高
- 不支持复杂查询
MySQL8.x的安装和使用
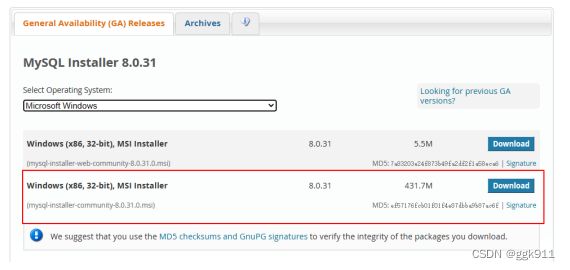
1.下载
mysql的安装包可以在官网或任意站点下载。
www.mysql

2.卸载
如果之前有安装过MySQL,必须要先卸载。
- 安装新版本时,会自动检测到旧版本,选择卸载
- 使用软件管理工具或系统自带卸载工具卸载
- 如果当初安装时没有指定路径,默认还要删除C:\Program Files下的MySQL文件夹
- 打开计算机的显示隐藏文件选项,删除C:\Program Data下的MySQL文件夹
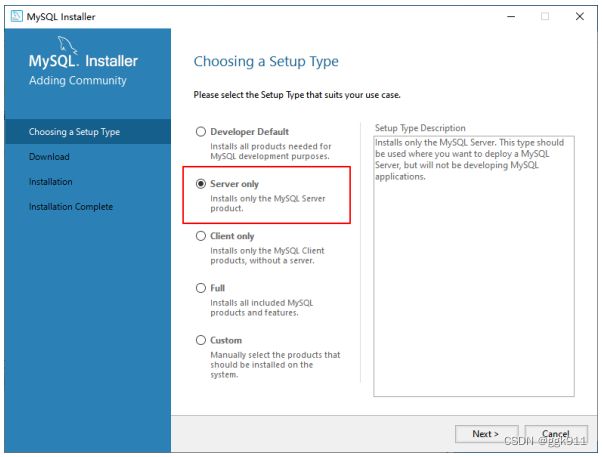
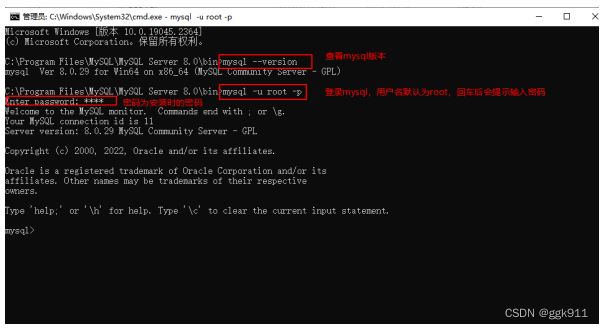
3.安装


MySQL控制台常用命令
-
查看所有数据库
show databases; -
切换数据库
use 数据库名; -
查看当前数据库下的所有表
show tables; -
创建一个数据库
create database 数据库名; -
删除数据库
drop database 数据库名;
数据库管理系统图形化管理工具
如果只是用控制台操作数据库系统不方便,所以有很多图形化的管理工具。
如navicat、datagrip、sqlyog等。
Navicat15优化学习版(呵呵)
这里自行查找吧
使用
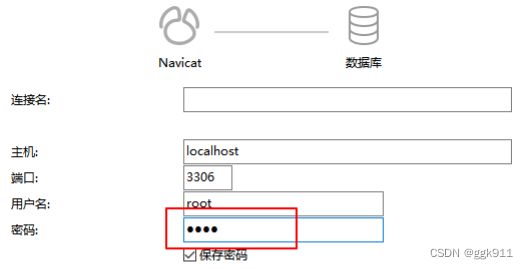
连接指定的MySQL
由于现在是自己的电脑链接自己,所以主机名是localhost,之后会连接真实的ip地址。
进入主界面后,点击左上角的连接,选择mysql,只需输入密码即可
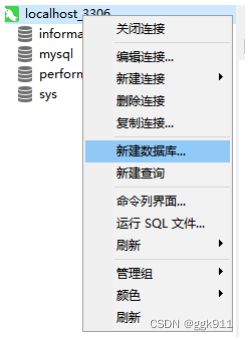
创建数据库
在连接上点击右键,新建数据库,只需写数据库名。
切换数据库
只需双击对应的数据库即可
创建数据表
在展开后的数据库中,在表的选项上右键新建表
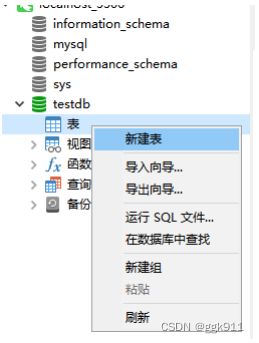

保存时会提示输入表名
创建表时的注意实现
-
每张表需要一个编号"id"列,通常设置为主键,目的是为了区分每条记录。整个主键列中的数据不能重复,通常还需要设置为自增
-
数据类型和所占长度根据实际情况选择
-
通过"不是null"设置能否允许该字段为空
-
如果某个字段有默认值,可以在设计表的时候设置,字符串用单引号引起来
-
最好写上注释
修改数据表
如果要对某张已存在的表进行修改,在对应的表上右键,设计表。
修改表时,要保存不影响现有数据。
SQL
Structrued Query Language 结构化查询语言
用于操作关系型数据库的一门语言。可以用来创建、维护数据库和数据。
-- mysql中的注释
操作数据库
1.创建数据库
create database 数据库名;
2.切换数据库
use 数据库名;
3.删除数据库
drop database 数据库名;
操作数据表
1.创建数据表
create table 表名(
字段名 数据类型 [字段特征],
字段名 数据类型 [字段特征],
...
字段名 数据类型 [字段特征]
)
2.删除数据表
drop table 表名;
3.修改数据表
-
对表重命名
alter table 旧表名 rename to 新表名; -
添加新字段
alter table 表名 add column 字段名 数据类型 字段特征; -
修改字段
alter table 表名 change 旧字段名 新字段名 数据类型 字段特征; -
删除字段
alter table 表名 drop 字段名;
添加约束
1.添加非空约束
alter table 表名 change 旧字段名 新字段名 数据类型 not null;
2.添加主键约束
alter table 表名 add primary key(字段名);
3.添加唯一约束
alter table 表名 add unique(字段名);
4.添加默认值约束
alter table 表名 alter 字段名 set default '默认值';
5.添加外键约束
alter table 从表表名 add foreign key(从表外键字段) references 主表(主表主键字段)
添加约束的操作通常是对已存在的表进行修改和维护时使用。如果是一张新表,最好在创建表的时候设计好约束。
建表的同时添加约束
-- 创建数据库gamedb
create database gamedb;
-- 切换数据库
use gamedb;
-- 创建游戏角色表hero
create table hero(
-- 编号 整型 非空 主键 自增
id int not null primary key auto_increment comment '编号',
-- 姓名 字符串 非空 唯一
name varchar(20) not null unique comment '姓名',
-- 定位 字符串 非空
position varchar(20) not null comment '定位',
-- 性别 字符串 非空 默认男
sex char(1) not null default '男' comment '性别',
-- 价格 整型 非空 默认4800
price int not null default '4800' comment '价格',
-- 上架日期
shelf_date date comment '上架日期'
)
-- 创建战斗表battle
create table battle(
hero_id int not null ,
position varchar(20),
-- 外键 hero_id参考hero表中的id字段
foreign key (hero_id) references hero(id)
)
数据完整性
数据完整性是指数据精确可靠。不能保存无意义或无效的数据。
如不合理的年龄、全为空的记录、重复记录等。
为了保证保存在数据库中的数据是完整数据,就要在设计数据表时添加一些约束或特征来保证数据完整性。
MySQL中常见的数据类型
| 整型 | ||
|---|---|---|
| tinyint | 短整型 | 对应java中的byte和short |
| int | 整型 | 对应java中的int |
| bigint | 长整型 | 对应java中的long |
| 浮点型 | ||
|---|---|---|
| float | 单精度浮点型 | 对应java中的float |
| double | 双精度浮点型 | 对应java中的double |
| decimal(宽度,精度) | 指定保留的小数位数和整体宽度 | 如decimal(4,2) 3.1415926–>3.14 |
| 字符串 | ||
|---|---|---|
| char(长度) | 定长字符串 | char(10)表示占10个字符,就算保存了3个字符,也占10个字符,对应java中的String |
| varchar(长度) | 可变字符串 | varchar(10)表示最多占10个字符,保存了3个字符,旧占3个字符,对应java中的String |
| text | 文本 |
| 日期 | ||
|---|---|---|
| date | 日期 | yyyy-MM-dd |
| time | 时间 | HH:mm:ss |
| datetime | 日期时间 | yyyy-MM-dd HH:mm:ss |
| timestamp(14或8) | 毫秒 | 保存日期的毫秒数.14表示yyyyMMddHHmmss,8表示yyyyMMdd |
约束
| 字段特征 | 概念 | 关键字 |
|---|---|---|
| 非空约束 | 是否允许该字段为null | null表示可以为空,not null表示不可以为空 |
| 主键约束 | 主键(primary key)。用于区分表中的每条记录的一个字段。如果有现成的字段可以区分每条记录时,将该字段设置为主键字段;如果没有现成的字段可以区分每条记录时,通常会额外添加一个id字段用于设置为主键字段。通常一张表只有一个主键字段。 | primary key |
| 唯一约束 | 保证该字段值不能重复 | unique |
| 默认值约束 | 如果在不给该字段添加数据的情况下,保证该字段有一个默认值。 | default |
| 外键约束 | 在主从关系的表中,给从表的某个字段添加外键约束后,该字段的值只能来自于主表中的某个主键字段 | foreign key references |
操作数据
数据的操作,是指数据的增加create,修改update,查询read和删除delete。
简称为CURD。
数据添加insert
数据添加时,都是整行(一条记录)添加。不能只给一个字段添加数据。
如果只给某个字段添加数据,实际是修改。
给所有字段赋值
insert into 表名 values('值1','值2'...)
- 表名后无需添加字段名,添加时保证值的顺序和字段的顺序一致
- 遇到自增字段,不能省略不写,要使用0、null或default让其自动填充
- 遇到有默认值的字段,不能省略不写,要使用default让其自动填充默认值
- 遇到允许为空的字段,不能省略不写,要使用null让其设置为空
给指定字段赋值
insert into 表名(字段1,字段2...) values('值1','值2'...)
- 没有默认值的非空字段必须要写出来
- 表名后的字段顺序要和值的顺序一致
批量添加
可以用一个insert into语句添加多条记录
insert into 表名[(字段1,字段2)] values
('值1','值2'...),
('值1','值2'...),
...
('值1','值2'...)
- 可以省略表名后的字段名
- 值的顺序和字段的顺序一致
- 如果一次添加多条记录时,优先使用批量添加,效率更高
数据修改update
修改单个字段的所有值
update 表名 set 字段 = 值;
修改多个字段的所有值
update 表名 set 字段1 = '值',字段2 = '值'...
根据条件修改(where子句)
update 表名 set 字段 = '值' where 条件
指定值
update 表名 set 字段 = '值' where 字段 = '值'
指定范围
-
使用>、<、>=、<=表示范围,使用and、or、&&、||将多个条件关联
update 表名 set 字段 = '值' where 字段 -
使用"字段 between 值1 and 值2"表示字段在闭区间[值1,值2]
update 表名 set 字段='值' where 字段 between 值1 and 值2 -
使用!=或<>表示不等于
update 表名 set 字段='值' where 字段<>值
指定集合
-
在某个集合中 in
update 表名 set 字段='值' where 字段 in ('值1','值2'...) -
不在某个集合中 not in
update 表名 set 字段='值' where 字段 not in ('值1','值2'...)
空值
-
使用is null表示空
update 表名 set 字段 = '值' where 字段 is null -
使用is not null表示非空
update 表名 set 字段 = '值' where 字段 is not null
模糊查询
-- 字段 like '%娜%'
-- 带有'娜'字
-- 字段 like '张%'
-- ‘张’字开头
-- 字段 like '%儿'
-- ‘儿’字结尾
-- 字段 like '%瑞_'
-- 倒数第二个字为‘瑞’
-- 字段 like '___'
-- 3个字
update 表名 set 字段 = '值' where 字段 like ‘%文字%’
数据删除delete
数据删除是删除一条或多条记录。
删除所有
delete from 表名;
-- 或
truncate table 表名;
- delete会保留自增列删除前的值,删除后再添加时,自动从删除前的值开始自增
- truncate会重置自增列的值。效率更高
- 如果要删除主从关系且设置了外键的表中的数据,如果从表中有数据,不能直接删除主表中相关数据,先删除从表中的数据后,才能删除主表中的数据
条件删除
delete from 表 where 条件
删除时的条件同修饰时的条件语句
数据查询select
查询所有字段
select * from 表名;
查询指定字段
select 字段名1,字段名2... from 表名;
字段重命名
select 字段1 as '重命名',字段2 '重命名'... from 表名;
查询指定条数
-- 查询前N条记录
select * from 表名 limit N;
-- 查询从索引N开始的M条记录
select * from 表名 limit N,M;
-- 每页显示size条,第page页
select * from 表名 limit (page-1)*size,size
去重复
select distinct 字段名 from 表名;
条件查询
where子句,语法同修改、删除时的where
select * from 表名 where 条件;
排序
select * from 表名 where 条件 order by 排序字段 [ASC/DESC],排序字段 [ASC/DESC]...
- 排序可以是升序或降序
- 默认不写是升序asc
- 降序需要写desc
- 排序时如果有条件,where条件写在表名之后,排序之前
- 多字段排序时,在order by之后写多个字段及排序规则,用逗号隔开
- 按字段顺序优先排序
统计函数(聚合函数)
select 统计函数(字段名) from 表名;
| 函数名 | |
|---|---|
| count(字段名) | 统计数量 |
| sum(字段名) | 求和 |
| avg(字段名) | 平均 |
| max(字段名) | 最大 |
| min(字段名) | 最小 |
数学相关函数
| 函数 | 作用 |
|---|---|
| abs(值或字段) | 绝对值 |
| pow(值或字段) | 次幂 |
| sqrt(值或字段) | 开平方 |
| round(值或字段) | 四舍五入 |
| ceil(值或字段) | 向上取整 |
| floor(值或字段) | 向下取整 |
字符串相关函数
| 函数 | |
|---|---|
| length(字符串或字段) | 得到字符串长度 |
| trim(字符串或字段)/ltrim(字符串或字段)/rtrim(字符串或字段) | 去除字符串首尾/首/尾空格 |
| left(字符串或字段,n)/right(字符串或字段,n) | 从字符串左/右开始截取n个字符 |
| substr(字段或字符串,start) | 从start开始截取至末尾 |
| substr(字段或字符串,start,length) | 从start开始截取length个字符 |
| lcase(字符串或字段)/ucase(字符串或字段) | 转换小写/大写 |
| instr(字符串1,字符串2)/locate(字符串2,字符串1) | 得到字符串2在字符串1中出现的顺序 |
| reverse(字符串或字段) | 翻转字符串 |
| concat(字符串1,字符串2…) | 拼接所有字符串 |
| replace(字符串或字段,旧字符串,新字符串) | 将字符串中的旧字符串替换为新字符串 |
时间相关函数
| 函数 | |
|---|---|
| now() | 当前日期时间 |
| current_date()/curdate() | 当前日期 |
| current_time()/curtime() | 当前时间 |
| year(日期)/month(日期)/day(日期) | 得到年/月/日部分 |
| datediff(时间1,时间2) | 计算时间1与时间2相隔的天数 |
| timediff(时间1,时间2) | 计算时间1与时间2相隔的时分秒 |
| TIMESTAMPDIFF(时间单位,时间1,时间2) | 计算时间1与时间2之间相隔的指定时间单位 |
分组
select 分组字段,统计函数 from 表名 group by 分组字段
按指定的字段进行分组,会将该字段值相同的记录归纳到同一组中。
分组通常配合统计函数使用。
如果统计函数作为条件,不能写在where之后,要写在having之后,
having子句放在分组之后。
-- 按图书作者分组,查询平均价格大于50的信息
select book_author,avg(book_price) from book_info
group by book_author
having avg(book_price)>50
group_concat()函数
将分组后的数据拼接成字符串。
group_concat(字段1或字符串,字段2或字符串...)
select group_concat(字段1,字段2...) from 表名 group by 分组字段
-- 根据图书类型分组,查看每组下的图书名和作者
select group_concat(book_name,'--',book_author) from book_info group by type_id
实际业务对应sql
登录
接收账号密码查询用户表中是否存在记录
select * from 表 where 账号=? and 密码=?
如果能查询到数据,说明存在该用户,可以登录;如果查询结果为Null,说明用户名或密码错误
注册
接收账号密码,判断是否存在该账号,不存在则添加到用户表中
select * from 表 where 账号=?
insert into 表 values(null,账号,密码)
充值
登录成功后,修改余额字段
update 表 set 余额=余额+充值金额 where 用户编号=?
删除
逻辑删除
不删除数据,只是不显示数据
可以给表中添加"是否删除"字段,用0表示未删除,用1表示已删除。
如果删除数据时,执行修改操作,将"是否删除"字段的值为1。
update 表 set deleted=1 where 用户编号=?;
最终在查询所有时,加上"是否删除"=0条件
select * from 表 where deleted=0;
物理删除
将数据真正删除
delete from 表 where 用户编号=?
连接查询
交叉连接、笛卡尔积
将两张表中的数据两两组合,得到的结果就是交叉连接的结果,也称为笛卡尔积
集合A:{a,b}
集合B:{1,2,3}
集合A x 集合B={a1,a2,a3,b1,b2,b3}
select * from 表1,表2;
select * from 表1 cross join 表2;
select * from 表1 inner join 表2;
将两张表中的数据互相组合成一张新表,其中有很多无效数据。
内连接
select * from 表1,表2 where 表1.字段=表2.字段;
select * from 表1 inner join 表2 on 表1.字段=表2.字段;
-- 如查询图书类型表(类型编号、类型名称)和图书详情表(图书编号、类型编号、图书名称)
select * from 图书类型表 t1 ,图书详情表 t2 where t1.类型编号=t2.类型编号;
select * from 图书类型表 t1 inner join 图书详情表 t2 on t1.类型编号=t2.类型编号;
- 通常是通过主表的主键字段关联从表的外键字段
- 如果两张表中关联的字段名一致,一定要通过"表名.字段名"进行区分,通常给表重命名
- 如果使用inner join,带条件时需要加入where子句;如果使用,隔开各个表,带条件时使用and拼接条件
- 内连接只会显示两张表中有关联的数据
左连接
-- 在保证左表数据显示完整的情况下,关联右表中的数据,没有关联的数据用null表示
select * from 表1 left join 表2 on 表1.字段=表2.字段;
-- 以上语句中表1称为左表,表2称为右表,会完整显示表1中的数据
右连接
-- 在保证右表数据显示完整的情况下,关联左表中的数据,没有关联的数据用null表示
select * from 表2 right join 表1 on 表1.字段=表2.字段;
-- 以上语句中表1称为左表,表2称为右表,会完整显示表2中的数据
嵌套查询
将查询出的结果继续嵌套使用在另一个查询语句中
-- 查询大于平均价格的图书
select * from 表
where price >(select avg(price) from 表)
-- 根据作者分组,查询每组大于平均价格的图书
select *
from 表 t1,(select author,avg(price) avg_price from 表)t2
where t1.author=t2.author and price>avg_price
Jar
以.jar为后缀的文件,称为Java归档文件,保存的是Java的字节码.class文件。
在Java程序中导入某个.jar文件,就能使用其中的.class文件。
在Java项目中使用.jar文件
1.创建一个Java项目,最好新建一个文件夹,将.jar文件保存在其中
2.在.jar文件上右键,点击“add as library”

JDBC
Java Database Connectivity Java数据库连接
用于Java程序连接不同的数据库。
实际在Java中定义的相关数据库连接时所需的接口,不同的数据库对其进行了实现。
核心接口
- Connection:用于设置连接的数据库的地址、账号、密码
- PreparedStatement:用于预处理、执行sql语句
- ResultSet:用于接收查询后的数据
以上接口都来自于java.sql包中
数据查询
import java.sql.*;
public class JDBCTest {
public static void main(String[] args) throws SQLException, ClassNotFoundException {
//连接mysql数据库,实现查询功能
//连接对象
//Connection conn;
//sql预处理对象
//PreparedStatement pst;
//结果集对象
//ResultSet rs;
//查询的流程
//1.加载mysql驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.连接指定的mysql
String url="jdbc:mysql://localhost:3306/gamedb?serverTimezone=Asia/Shanghai";
String username="root";
String pass1word="root";
Connection conn=DriverManager.getConnection(url,username,pass1word);
//3.构造sql语句
String sql="select * from hero";
//4.预处理sql语句
PreparedStatement pst=conn.prepareStatement(sql);
//5.执行查询的方法
ResultSet rs =pst.executeQuery();
//6.循环读取数据
while(rs.next()){//rs.next()方便表示读取且判断是否还有后续数据
//获取读取到的数据 rs.get数据类型(int columnIndex)根据字段索引获取值 rs.get数据类型(String columnName)根据字段名获取值
int id = rs.getInt(1);
String name = rs.getString("name");
String sex = rs.getString("sex");
String position = rs.getString("position");
int price = rs.getInt("price");
String shelf_date = rs.getString(6);
System.out.println(id+"--"+name+"--"+sex+"--"+position+"--"+price+"--"+shelf_date);
}
//7.释放与mysql的连接资源
rs.close();
pst.close();
conn.close();
}
}
数据增删改
public void addHero(Hero hero) throws SQLException, ClassNotFoundException {
//1.加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//2.获取连接对象
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/gamedb?serverTimezone=Asia/Shanghai", "root", "root");
//3.构造sql,参数使用?占位
String sql = "insert into hero values(null,?,?,?,?,curdate())";
//4.预处理sql
pst = conn.prepareStatement(sql);
//给?赋值
pst.setString(1,hero.getName());
pst.setString(2,hero.getPosition());
pst.setString(3,hero.getSex());
pst.setInt(4,hero.getPrice());
//5.调用更新的方法
int i = pst.executeUpdate();
//6.判断执行结果
if(i>0){
System.out.println("添加成功");
}else{
System.out.println("添加失败");
}
//7.释放资源
pst.close();
conn.close();
}
SQL注入
在构造sql语句时,如果使用字符串拼接的方式构造动态sql,可能会造成sql注入的风险,导致执行不是预期的sql语句
-- 如删除的sql:String sql = "delete from 表 where id="+参数;
-- 实际传值时,参数为 ''or 1=1 会导致sql变成
delete from battle where id= ''or 1=1
-- 这样就会删除所有数据
-- 查询时的sql: "select * from 表 where name="+参数+" and pwd= "+参数
-- 实际传值时,第一个参数为 'or 1=1 -- 会导致sql变成
select * from hero where id=''or 1=1 -- ' and name='亚索'
-- 这样会查询出所有数据
使用数据库帮助类简化JDBC操作
DBUtil类
package com.hqyj.util;
import java.sql.*;
/*
* 数据库工具类
* 连接方法
* 释放资源方法
* */
public class DBUtil {
//连接数据库所需字符串
private static String url = "jdbc:mysql://localhost:3306/bookdb?serverTimezone=Asia/Shanghai";
private static String username = "root";
private static String pass1word = "root";
/*
* 静态代码块
* 加载驱动
* */
static {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
System.out.println("加载驱动异常" + e);
}
}
/*
* 静态方法
* 获取连接
* */
public static Connection getConn() {
Connection connection = null;
try {
connection = DriverManager.getConnection(url, username, pass1word);
} catch (SQLException e) {
System.out.println("连接数据库异常" + e);
}
return connection;
}
/*
* 静态方法
* 释放资源
* */
public static void release(Connection conn, PreparedStatement pst, ResultSet rs) {
try {
if(conn!=null){
conn.close();
}
if(pst!=null){
pst.close();
}
if(rs!=null){
rs.close();
}
}catch (SQLException e){
System.out.println("释放资源异常"+e);
}
}
}
实体类BookInfo
package com.hqyj.entity;
/*
* book_info表对应的实体类
* */
public class BookInfo {
private int bookId;
private String bookName;
private String bookAuthor;
private int bookPrice;
private int bookNum;
private String publisherDate;
/*
* 全参数构造方法
* 用于查询时创建对象
* */
public BookInfo(int bookId, String bookName, String bookAuthor, int bookPrice, int bookNum, String publisherDate) {
this.bookId = bookId;
this.bookName = bookName;
this.bookAuthor = bookAuthor;
this.bookPrice = bookPrice;
this.bookNum = bookNum;
this.publisherDate = publisherDate;
}
/*
* 不含id和出版时间的构造方法
* 用于添加时创建对象
* */
public BookInfo(String bookName, String bookAuthor, int bookPrice, int bookNum) {
this.bookName = bookName;
this.bookAuthor = bookAuthor;
this.bookPrice = bookPrice;
this.bookNum = bookNum;
}
@Override
public String toString() {
return "BookInfo{" +
"bookId=" + bookId +
", bookName='" + bookName + '\'' +
", bookAuthor='" + bookAuthor + '\'' +
", bookPrice=" + bookPrice +
", bookNum=" + bookNum +
", publisherDate='" + publisherDate + '\'' +
'}';
}
public int getBookId() {
return bookId;
}
public void setBookId(int bookId) {
this.bookId = bookId;
}
public String getBookName() {
return bookName;
}
public void setBookName(String bookName) {
this.bookName = bookName;
}
public String getBookAuthor() {
return bookAuthor;
}
public void setBookAuthor(String bookAuthor) {
this.bookAuthor = bookAuthor;
}
public int getBookPrice() {
return bookPrice;
}
public void setBookPrice(int bookPrice) {
this.bookPrice = bookPrice;
}
public int getBookNum() {
return bookNum;
}
public void setBookNum(int bookNum) {
this.bookNum = bookNum;
}
public String getPublisherDate() {
return publisherDate;
}
public void setPublisherDate(String publisherDate) {
this.publisherDate = publisherDate;
}
}
数据操作类BookInfoDao
package com.hqyj.dao;
import com.hqyj.entity.BookInfo;
import com.hqyj.util.DBUtil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
/*
* book_info表的操作类
* */
public class BookInfoDao {
//定义成员变量,用于操作数据库的3个接口
Connection conn;
PreparedStatement pst;
ResultSet rs;
/*
* 查询所有
* */
public List<BookInfo> queryAll() {
//创建集合
ArrayList<BookInfo> list = new ArrayList<>();
try {
//通过数据库工具类获取连接
conn = DBUtil.getConn();
//预处理sql
pst = conn.prepareStatement("select * from book_info");
//调用查询
rs = pst.executeQuery();
//遍历结果集
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(3);
String author = rs.getString(4);
int price = rs.getInt(5);
int num = rs.getInt(6);
String time = rs.getString(7);
BookInfo bookInfo = new BookInfo(id, name, author, price, num, time);
list.add(bookInfo);
}
} catch (Exception e) {
System.out.println("查询所有异常" + e);
} finally {
DBUtil.release(conn, pst, rs);
}
return list;
}
/*
* 根据id查询
* */
public BookInfo queryById(int bookId) {
try {
//通过数据库工具类获取连接
conn = DBUtil.getConn();
//预处理sql
pst = conn.prepareStatement("select * from book_info where book_id=?");
//给?赋值
pst.setInt(1, bookId);
//调用查询
rs = pst.executeQuery();
//遍历结果集
if (rs.next()) {
String name = rs.getString(3);
String author = rs.getString(4);
int price = rs.getInt(5);
int num = rs.getInt(6);
String time = rs.getString(7);
BookInfo bookInfo = new BookInfo(bookId, name, author, price, num, time);
return bookInfo;
}
} catch (Exception e) {
System.out.println("根据id查询异常" + e);
} finally {
DBUtil.release(conn, pst, rs);
}
return null;
}
/*
* 添加
* */
public boolean insert(BookInfo bookInfo) {
conn = DBUtil.getConn();
try {
pst = conn.prepareStatement("insert into book_info values(null,1,?,?,?,?,curdate())");
pst.setString(1, bookInfo.getBookName());
pst.setString(2, bookInfo.getBookAuthor());
pst.setInt(3, bookInfo.getBookPrice());
pst.setInt(4, bookInfo.getBookNum());
return pst.executeUpdate() > 0;
} catch (SQLException e) {
System.out.println("添加异常" + e);
} finally {
DBUtil.release(conn, pst, rs);
}
return false;
}
/*
* 修改
* */
public boolean update(int bookId, int newPrice, int newNum) {
conn = DBUtil.getConn();
try {
pst = conn.prepareStatement("update book_info set book_price=? ,book_num=? where book_id=?");
pst.setInt(1, newPrice);
pst.setInt(2, newNum);
pst.setInt(3, bookId);
return pst.executeUpdate() > 0;
} catch (Exception e) {
System.out.println("修改异常" + e);
} finally {
DBUtil.release(conn, pst, rs);
}
return false;
}
/*
* 删除
* */
public boolean delete(int bookId) {
conn = DBUtil.getConn();
try {
pst = conn.prepareStatement("delete from book_info where book_id=?");
pst.setInt(1, bookId);
return pst.executeUpdate() > 0;
} catch (Exception e) {
System.out.println("删除异常" + e);
} finally {
DBUtil.release(conn, pst, rs);
}
return false;
}
}
实体关系模型
实体Entity:一个表就是一个实体。
关系Relationship:实体与实体之间的关系。
实体关系模型也称为ER模型。
用图形表示ER模型时,这个图就称为ER图。
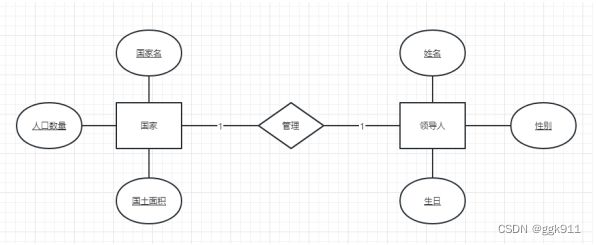
用矩形表示实体,用椭圆形表示实体的属性,用菱形表示实体之间的关系,用直线连接各个图形。
实体之间的关系
一对一
实体A与实体B之间唯一对应。
如一个国家有一个领导人,一个人对应一个配偶。
ER图
在数据库中创建表的过程
可以使用一张表实现,但如果使用一张表保存时,后期维护扩展时较为不便。
最好使用两张表实现。
-
创建国家表
create table country( country_id int not null primary key auto_increment, country_name varchar(20) not null, country_population bigint not null, country_area int not null ) -
创建领导人表
create table leader( leader_id int not null primary key auto_increment, leader_name varchar(20) not null, leader_birthday date not null )
这时两张表是独立的,并不能体现一对一的管理关系,可以通过以下方式体现一对一。
-
方式一:
创建一个管理表,保存两张表中的主键,添加唯一约束
create table relation( relation_no int not null primary key auto_increment, leader_id int not null unique, country_id int not null unique, foreign key (leader_id) references leader(leader_id), foreign key (country_id) references country(country_id), ) -
方式二(建议使用):
在以上的两个实体表中,选择任意一张表中添加一列,保存另一张表的主键,添加唯一约束
create table leader( leader_id int not null primary key auto_increment, leader_name varchar(20) not null, leader_birthday date not null, country_id int not null unique, foreign key (country_id) references country(country_id) )
一对多/多对一
一对多:一个实体A对应多个实体B,一个实体B不能对应多个实体A
多对一:多个实体B对应一个实体A,多个实体A不能对应一个实体B
如一个人有多辆车,一辆车不能对应多个人;
一个教官训练多个学员,一个学员不能对应多个教官;
ER图

在数据库中创建表的过程
-
创建主表(一)
create table coach( coach_id int not null primary key auto_increment, coach_name varchar(20) not null, coach_leave varchar(20) not null ) -
创建从表(多),在表中添加字段关联主表中的主键字段
create table student( stu_id int not null primary key auto_increment, stu_name varchar(20) not null, stu_phone varchar(20) not null, coach_id int not null, foriegn key (coach_id) references coach(coach_id) )
多对多
一个实体A可以对应多个实体B,一个实体B也可以对应多个实体A。
如一个学生可以学习多门课程,一门课程也可以对应多个学习它的学生。
一个医生可以有多个病人,一个病人也可以对应多个医生。
ER图

在数据库中创建表的过程
-
创建课程表
create table course( course_id int not null primary key auto_increment, course_name varchar(20) not null, course_score int not null ) -
创建学生表
create table student( stu_id int not null primary key auto_increment, stu_name varchar(20) not null, stu_phone varchar(20) not null ) -
体现多对多关系的表:成绩表
该表中必须要包含以上两个实体表中的主键字段
create table score( s_id int not null, course_id int not null, stu_id int not null, cj int not null, -- 可以选择添加外键约束 foreign key (course_id) references course(course_id), foreign key (stu_id) references student(stu_id) )
总结
一对一:创建各自的实体表,在任意一张表中添加另一张表的主键字段,并添加唯一约束
一对多/多对一:先创建主表(一),再创建从表(多),在从表中添加主表中的主键字段,外键可选
多对多:创建各自的实体表,再创建第三张表:“联系表”,在"联系表"中添加两个实体表中的主键字段,外键可选
练习
“医院信息管理系统”。
医生模块:医生的CURD
病人模块:病人的CURD
诊断模块:哪个医生在什么时间诊断了哪个病人,记录信息
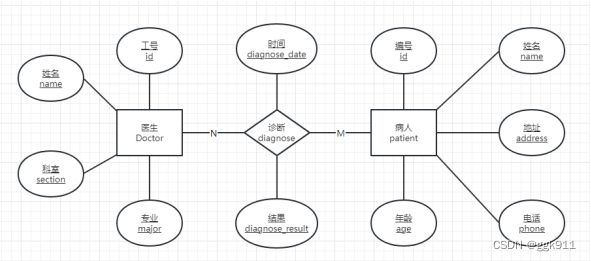
-- 医生表
create table doctor(
id int not null primary key auto_increment,
name varchar(20) not null,
section varchar(20) not null,
major varchar(50) not null
)
-- 病人表
create table patient(
id int not null primary key auto_increment,
name varchar(20) not null,
age int not null,
phone varchar(20),
address varchar(50)
)
-- 诊断记录表
create table diagnose(
diagnose_no int not null primary key auto_increment,
doctor_id int not null,
patient_id int not null,
diagnose_date datetime not null,
diagnose_result text
)
诊断病人流程:
-- 1.管理员登录系统,向医生表中添加一条记录
insert into doctor values(9001,'张海梅','内科','肺炎治疗')
-- 2.医生登录系统,添加病人信息
insert into patient values(null,'王海',20,null,null)
-- 3.记录添加诊断记录
insert into diagnose values(null,9001,1,now(),'没啥问题')
数据库设计规范
数据库设计的规范,简称为范式(NF)。
范式分为第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、BC范式(BCNF)、第四范式(4NF)和第五范式(5NF)共六种。
这六种范式的级别越高,表示数据库设计的结果越规范,每一个高级版的范式都包含了低级别的范式。
通常设计数据库时,只需满足3NF即可。
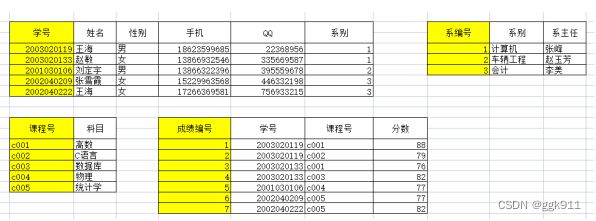
如有如下数据,黄色背景为联合主键,暂时不满足任何范式。

当前表如果要做增删改查的操作,会有如下问题:
- 如果要加入一个新的系别,就要添加学生,系主任等数据
- 如果要删除"刘定宇",他所在的系也会被删除
- 如果要将"王海"的系别改为会计,相应的系主任也要修改
- 当前表中有大量冗余数据
第一范式1NF
数据表中的每一列都是不可再分的原子项。
关系型数据库起码要满足1NF,才能创建表。
上表中的联系方式列,可以再分为手机和QQ两列,所以它不满足1NF。根据1NF的要求,修改后

第二范式2NF
在满足1NF的基础上,消除部分依赖。
对于联合主键而言,每一个非主属性字段都需要完全依赖于主属性,而不是依赖其中一部分。
在上图中,无法用学号做主键,需要将学号和科目组合为联合主键,通过联合主键才能得到分数。
出学号和科目外,其他字段都是非主键字段,分数完全依赖于联合主键,其他字段不满足,所以进行如下修改。

第三范式3NF
在满足2NF的基础上,消除传递依赖。
在上图中,系主任是通过学号->系别->系主任获取,系主任传递依赖于学号,消除这个传递依赖

最终根据实体关系模型进行优化,体现对应关系。
名词解释
主键/主码/主属性
用于唯一区分每条记录的一个字段,称为主键字段,如学号、身份证号。
通常选择能唯一且几乎不会改变的某个字段作为主键。如果没有,自定义一个id列作为主键。
联合主键
如果一个字段不能唯一区分每条记录,而是需要多个字段才能唯一区分时,这些字段一起组成了联合主键。
完全依赖
如果能通过A和B得到C,A和B都不能单独得到C时,称为C完全依赖于A和B。
如(学号+科目)联合主键->分数,分数完全依赖于联合主键。
其他字段完全依赖于学号。
部分依赖
通过A和B可以得到C,单独通过A或B也可以得到C,称为C部分依赖于A和B。
如(学号+科目)联合主键->姓名,其实只通过学号也可以得到姓名,称为姓名部分依赖于联合主键。
除了成绩外,其余字段都是部分依赖于(学号+科目)联合主键
2NF就是消除这种部分依赖,只保留完全依赖。
传递依赖
如果通过A可以得到B,通过B得到C,称为C传递依赖于A。
如学号->系->系主任,其实只通过系也能得到系主任,称为系主任传递依赖于学号。
3NF就是消除这种传递依赖。
行列转换
如现有表score

转换为
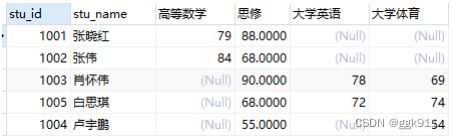
select stu_id,stu_name,
sum(if(c_name='高等数学',cj,null)) as '高等数学',
sum(if(c_name='思修',cj,null)) as '思修',
sum(if(c_name='大学英语',cj,null)) as '大学英语',
sum(if(c_name='大学体育',cj,null)) as '大学体育'
from score
group by stu_id
视图View
视图可以当做数据库中的一个临时表,保存一些较为复杂的查询后的结果,
之后可以直接通过该视图查询数据,不需要再次编写复杂的sql语句。
视图同时可以隐藏一些查询细节,定制查询数据。
创建视图
create view 视图名 as
查询的sql语句;
使用视图
select * from 视图名
修改视图中的数据,会直接修改原始表中的数据
删除视图
drop view 视图名;
-- 查询平均分最高的课程名及其授课教师
-- 创建视图
create view myview as
select s.c_id,avg(cj)avg_cj from score s,course c where s.c_id = c.c_id
group by s.c_id
-- 视图可以当做表使用
select c_name,t_name from teach t2,teacher t1,course c,
(select c_id from myview where avg_cj=(select max(avg_cj) from myview))t
where t1.t_id=t2.t_id and t.c_id=t2.c_id and c.c_id=t2.c_id
-- 删除视图
drop view myview;
事务transaction
事务是由一组sql语句组成的执行单元,这些sql之间一般都相互依赖。
这个执行单元要么全部执行,要么全部不执行。
转账
1.select * from 表 where id =1 and money>=1000
2.update 表 set money=money-1000 where id=1
3.update 表 set money=money+1000 where id=2
以上的所有sql组成了一个转账的事务。
事务的特性ACID
原子性Atomicity
事务是最小的执行单元
一致性Consistency
事务执行前后,必须让所有数据保持一致状态。(总体数据守恒)
隔离性Isolation
事务并发时相互隔离,互不影响
持久性Durability
事务一旦提交,对数据的改变是永久的
事务的使用
提交:commit
回滚:rollback
mysql中事务是默认自动提交的。
查看事务自动提交开启状态:select @@autocommit 1表示开启自动提交 0表示关闭自动提交
设置事务不自动提交:set @@autocommit=0
如果关闭了事务自动提交,在执行某个事务途中,如果出错,可以使用rollback进行回滚,让数据回到事务执行之前的状态。
如果不出错,通过commit提交事务,一旦提交事务,无法进行回滚。
手动提交/回滚事务
1.关闭事务自动提交:set @@autocommit=0
2.开启事务:start transaction;
3.事务要执行的sql;
4.没有提交之前,如果要回滚,使用rollback;
5.如果要提交,使用commit;一旦提交成功,无法rollback。
事务并发可能出现的问题
在同一时刻同时执行多个事务时,称为事务并发。
事务并发会有可能出现以下问题
| 问题 | 描述 |
|---|---|
| 脏读 | 事务A读取到了事务B未提交的数据 |
| 不可重复读 | 事务A中如果要读取两次数据,在这期间,事务B对数据进行了修改并提交,导致事务A读取两次的情况不一致 |
| 幻读 | 事务A读取id为1~10之间的数据,假如只有id为2和5的数据,在读取期间,事务B添加了一条id为3的数据,导致事务A多读到了事务B中的数据 |
事务隔离级别
为了防止事务并发时出现以上各种问题,数据库中设计了几种事务与事务之间的隔离级别。
| 隔离级别 | 能否出现脏读 | 能否出现不可重复读 | 能否出现幻读 |
|---|---|---|---|
| Read Uncommitted未提交读RU | 会 | 会 | 会 |
| Read Committed已提交读RC(Oracle默认) | 不会 | 会 | 会 |
| Repeatable Read可重复读RR(MySQL默认) | 不会 | 不会 | 会 |
| Serializable可序列化 | 不会 | 不会 | 不会 |
查看事务隔离级别
select @@transatcion_isolation
设置事务隔离级别
set [session|global] transaction isolation level [read uncommitted|read committed|repeatable read|serializable]
触发器trigger
如果要在更新某张表之前或之后,自动执行另一组sql时,可以使用触发器实现。
如表A是客户表,表B是操作日志表,对表A进行更新操作时,将操作的记录保存到表B中。
慎用触发器,因为如果有10000条记录,在修改所有记录时,触发器就会执行10000次,会花费很多时间。
创建触发器
create trigger 触发器名
触发时机 触发操作 on 表名 for each row
begin
触发时执行的sql;
end
-- 创建操作日志表
create table log(
log_id int not null primary key auto_increment,
log_opt varchar(20) not null,
log_time datetime not null
)
-- 创建触发器,在向客户表中添加记录后,自动向日志表中添加记录
create trigger mytrigger
after insert on customer for each row
begin
insert into log values(null,'添加了数据',now())
end
使用触发器
一旦创建成功触发器,无需刻意调用,在执行相应的操作时,自动执行触发器
-- 只对customer表做插入操作,会自动向log表中添加记录
insert into customer values(null,'测试插入','123123',0,null);
删除触发器
drop trigger 触发器名;
存储过程procedure
类似于java中的方法,定义一组用于完成特定功能的sql语句。
定义存储过程后,通过调用存储过程名,就可以执行定义时的内容。
存储过程可以有参数。
调用存储过程
-- 调用无参数的存储过程
call 存储过程名();
-- 调用输入型参数的存储过程
call 存储过程名('实参');
-- 调用输出型参数的存储过程
call 存储过程名(@变量);
-- 调用输入输出型参数的存储过程
set @变量
call 存储过程名(@变量)
定义存储过程
create procedure 存储过程名([参数类型 参数名 参数数据类型])-- 参数类型分为输入型/输出型/输入输出型
begin
sql语句;
end
无参数
create procedure 存储过程名()
begin
sql语句
end
-- 创建存储过程,查询每本图书的书名、作者、类型
CREATE PROCEDURE myproc1 () BEGIN
SELECT
book_name,
book_author,
type_name
FROM
book_info bi,
book_type bt
WHERE
bi.type_id = bt.type_id;
END
-- 调用存储过程
call myproc1();
输入型参数
create procedure 存储过程名(in 形参名 数据类型)
begin
sql语句;
end
-- 根据图书类型查询该类型下的所有图书
CREATE PROCEDURE myproc2 (IN lx VARCHAR ( 20 ))
BEGIN
SELECT
*
FROM
book_info bi,
book_type bt
WHERE
bi.type_id = bt.type_id
AND type_name = lx;
END
-- 调用
call myproc2('杂志')
输出型参数
类似于java中有返回值的方法
create procedure 存储过程名(out 形参名 数据类型)
begin
sql语句;
-- 通常需要将查询出的结果通过into赋值给形参
end
-- 根据作者查询图书数量
CREATE PROCEDURE myproc3 ( IN zz VARCHAR (20), OUT book_count INT )
BEGIN
-- 将查询的结果into到参数book_count中
SELECT
count( book_id ) INTO book_count
FROM
book_info
WHERE
book_author = zz;
END
-- 调用存储过程,@x表示将存储过程的输出型参数保存到变量x中
call myproc3('金庸',@x)
-- 查询参数中保存的数据
select @x
输入输出型参数
create procedure 存储过程名(inout 形参名 数据类型)
begin
sql语句;
end
-- 查询书名中带有指定文字的图书名、作者和类型
create procedure myproc4(inout keyword varchar(20))
begin
SELECT
book_name,
book_author,
type_name
FROM
book_info bi,
book_type bt
WHERE
bi.type_id = bt.type_id
AND book_name LIKE concat('%',keyword,'%');
end
-- 调用存储过程
set @keyword='龙';
call myproc4(@keyword);
select @keyword;
删除存储过程
drop procedure 存储过程名;
MySQL编程
在定义存储过程中,可以定义变量、使用流程控制语句等。
定义变量
create procedure 存储过程名()
begin
-- declare 变量名 数据类型;
declare num int;
declare name varchar(20);
end
给变量赋值
create procedure 存储过程名()
begin
declare num int;
declare name varchar(20);
-- 给num赋值
-- select 字段/值 into 变量 [from 表];
select 123 into num;
select book_name into name from book_info where book_id=1;
end
读取变量的值
create procedure 存储过程名()
begin
declare num int;
declare name varchar(20);
select 123 into num;
select book_name into name from book_info where book_id=1;
-- select 变量;
select num;
select name;
end
-- 创建存储过程,查询所有图书总数,保存到变量中
create procedure myproc5()
begin
-- 定义变量
declare sum_num int;
-- 给变量赋值
select sum(book_num) into sum_num from book_info ;
-- 打印变量的值
select sum_num;
end
-- 调用存储过程
call myproc5()
条件语句
单分支if语句
if 条件
then
满足条件时执行的sql;
end if;
-- 根据作者查询图书库存,如果不足1000,输出'库存不足1000'
create procedure myproc6(in zz varchar(20))
begin
-- 定义变量保存根据作者查询到的图书库存
declare num int;
-- 查询sql,将结果保存到变量中
select sum(book_num) into num from book_info where book_author = zz ;
-- 判断变量num
if num<1000
then
select '库存不足1000';
end if;
end
call myproc6('郭敬明')
双分支if语句
if 条件
then
满足条件时执行的sql;
else
不满足条件时执行的sql;
end if;
-- 根据图书类型查询图书数量,如果不足5,输出"不足5种图书",如果足够5,输出详情
create procedure myproc7(in lx varchar(20))
begin
-- 定义变量保存图书数量
declare num int;
-- 给变量赋值
select count(book_id) into num
from book_info bi inner join book_type bt on bi.type_id=bt.type_id
where type_name = lx;
-- 判断
if num>=5
then
select * from book_info bi inner join book_type bt on bi.type_id=bt.type_id where type_name=lx;
else
select '不足5种图书';
end if;
end
-- 调用存储过程
call myproc7('小说')
call myproc7('漫画')
case语句
CASE 变量
WHEN 值 THEN
满足该值时执行sql语句;
WHEN 值 THEN
满足该值时执行sql语句;
ELSE
没有任何值满足时sql语句;
END CASE;
-- case语句
create procedure myproc8(in num int)
begin
CASE num
WHEN 1 THEN
select '1';
WHEN 5 THEN
select '5';
ELSE
select '都不是';
END CASE;
end
-- 调用
call myproc8(6)
循环语句
while循环
while 条件 do
满足条件时执行的内容;
end while;
-- 添加10个客户
create procedure myproc9()
begin
-- 定义循环变量
declare i int;
-- 初始化循环变量
select 1 into i;
-- while循环
while i<=10 do
insert into customer values(null,concat('测试用户',i),'123123',0,null);
-- 更新循环变量
set i=i+1;
end while;
end
call myproc9()
repeat循环
repeat
循环体;
until 条件 end repeat;
-- repeat循环
create procedure myproc10()
begin
declare num int;
select 50 into num;
repeat
insert into customer values(null,concat('测试用户',num),'123123',0,null);
set num=num+1;
until num=60 end repeat;
end
-- 调用
call myproc10()
loop循环
循环名:loop
循环体;
if 条件 then leave 循环名;
end if;
end loop;
-- loop循环
create procedure myproc11()
begin
declare num int ;
select 100 into num;
test:loop
insert into customer values(null,concat('测试用户',num),'123123',0,null);
set num=num-1;
if num=90 then leave test;
end if;
end loop;
end
-- 调用
call myproc11()
MySQL核心内容
SQL语句
- 数据库和数据表的创建、修改、删除
- 数据完整性(约束)
- 单表增删改查CURD
- 函数
- 多表查询、嵌套查询
数据库设计
- 实体关系模型(ER)
- ER图
- 范式
JDBC
-
连接MySQL所需jar文件
- 普通java工程需要手动导入jar文件
- maven项目需要使用依赖自动导入jar文件
-
MySQL驱动名
//mysql5.5之前版本 Class.forName("com.mysql.jdbc.Driver"); //mysql8之后版本 Class.forName("com.mysql.cj.jdbc.Driver"); -
连接数据库的字符串
String url="jdbc:mysql://localhost:3306/数据库名?serverTimezone=Asia/Shanghai"; String username="root"; String pass1word="密码";
事务
-
事务的概念和特性
-
事务并发时出现的问题
- 脏读
- 不可重复读
- 幻读
-
事务的隔离级别
- read uncommitted 可能会出现脏读、不可重复读和幻读问题,效率最高
- read committed 解决了脏读问题,可能会出现不可重复读和幻读问题
- repeatable read MySQL默认 解决了脏读和不可重复读问题,可能会出现幻读问题
- serializable 解决了脏读、不可重复读和幻读问题,效率最低
存储引擎
- MySQL5.5版本之前,默认使用MyIsam存储引擎,不支持事务
- MySQL5.5版本之后,默认使用InnoDB存储引擎,支持事务
roc8(in num int)
begin
CASE num
WHEN 1 THEN
select '1';
WHEN 5 THEN
select '5';
ELSE
select '都不是';
END CASE;
end
-- 调用
call myproc8(6)
循环语句
while循环
while 条件 do
满足条件时执行的内容;
end while;
-- 添加10个客户
create procedure myproc9()
begin
-- 定义循环变量
declare i int;
-- 初始化循环变量
select 1 into i;
-- while循环
while i<=10 do
insert into customer values(null,concat('测试用户',i),'123123',0,null);
-- 更新循环变量
set i=i+1;
end while;
end
call myproc9()
repeat循环
repeat
循环体;
until 条件 end repeat;
-- repeat循环
create procedure myproc10()
begin
declare num int;
select 50 into num;
repeat
insert into customer values(null,concat('测试用户',num),'123123',0,null);
set num=num+1;
until num=60 end repeat;
end
-- 调用
call myproc10()
loop循环
循环名:loop
循环体;
if 条件 then leave 循环名;
end if;
end loop;
-- loop循环
create procedure myproc11()
begin
declare num int ;
select 100 into num;
test:loop
insert into customer values(null,concat('测试用户',num),'123123',0,null);
set num=num-1;
if num=90 then leave test;
end if;
end loop;
end
-- 调用
call myproc11()
MySQL核心内容
SQL语句
- 数据库和数据表的创建、修改、删除
- 数据完整性(约束)
- 单表增删改查CURD
- 函数
- 多表查询、嵌套查询
数据库设计
- 实体关系模型(ER)
- ER图
- 范式
JDBC
-
连接MySQL所需jar文件
- 普通java工程需要手动导入jar文件
- maven项目需要使用依赖自动导入jar文件
-
MySQL驱动名
//mysql5.5之前版本 Class.forName("com.mysql.jdbc.Driver"); //mysql8之后版本 Class.forName("com.mysql.cj.jdbc.Driver"); -
连接数据库的字符串
String url="jdbc:mysql://localhost:3306/数据库名?serverTimezone=Asia/Shanghai"; String username="root"; String pass1word="密码";
事务
-
事务的概念和特性
-
事务并发时出现的问题
- 脏读
- 不可重复读
- 幻读
-
事务的隔离级别
- read uncommitted 可能会出现脏读、不可重复读和幻读问题,效率最高
- read committed 解决了脏读问题,可能会出现不可重复读和幻读问题
- repeatable read MySQL默认 解决了脏读和不可重复读问题,可能会出现幻读问题
- serializable 解决了脏读、不可重复读和幻读问题,效率最低
存储引擎
- MySQL5.5版本之前,默认使用MyIsam存储引擎,不支持事务
- MySQL5.5版本之后,默认使用InnoDB存储引擎,支持事务
学习中的Sample
简单的控制台商品管理
截图太麻烦只展示部分功能

管理员:

普通用户:

查看商品:

搜索商品:

查看用户信息:

购买商品:
源码在这里:htt删ps://pa删n.b删aid除u.co中m/删s/删1YoK删nx文DyGITlZ8__Og删k删rp6g 提-取-码: iti7
学习中遇见的问题
Mysql异常No operations allowed after statement closed
Can not modify more than one base table through a join view
错题
数据库的错题没有,但是有些细节问题要注意
-- (5)假如产品信息表中有5条记录,购买信息表中有3条记录,查询所有的理财产品编号、理财产品名称、购买人数
SELECT
p2.productid AS '编号',
p2.productname AS '名称',
COUNT( p1.amount )
FROM
product p2
LEFT JOIN purchase p1 ON p1.productid = p2.productid
GROUP BY
p2.productid;
读题的时候没注意到是查询所有的理财产品,导致我没有左连接,只是简单的内连接,也就显示不全所有商品。
总结
因为是计科的原因学过数据库,整个学习的过程相当于复习了一遍,没太大的难度,主要是数据库jdbc的连接,跟学校里的不一样,学会了之后只要套用代码就行了,当自己要读懂连接字段的意义,不要只会使用。还简单接触了下,项目结构的分层,util工具类、entity实体类、service服务类、dao数据库连接类,之所以要分这些类就是要使整个代码具有更好的逻辑性,更好的阅读性。其实在工作中会频繁的接触数据库,使用把数据库学好非常重要,不仅是学习增删改查,平时还要拿具体的业务数据库查询来练习。以上