Spring面试的几大问题
一、Bean的循环依赖
1.循环依赖是什么?
循环依赖指的就是依赖闭环的问题,如下面代码所示:
package com.csc.pojo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class A {
@Autowired
private B b;
}
package com.csc.pojo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class B {
@Autowired
private A a;
}
启动程序,会发现报错,可以看见控制台输出的错误提示信息,就是自定义的A和B相互依赖。那么我们应该怎么解决呢?
spring给我们提供了简单的配置,如下图所示,这样就解决了循环依赖的问题了。
2.spring是如何解决的呢?
(1)图片化方式解释
1.借用黑马程序员的图片来理解一下是如何解决循环依赖的问题。Spring使用三级缓存机制来解决循环依赖:
- 第一级缓存(singletonObjects)存放完全初始化好的单例对象。
- 第二级缓存(earlySingletonObjects)存放提前曝光但尚未完成初始化的单例对象。
- 第三级缓存(singletonFactories)存放可以用来创建单例对象的对象工厂。

2.要想创建一个完整的A实例,先要创建一个半成品的A实例,因为还没有依赖注入B,所以先把A的半成品实例放入第三级缓存中。
3.然后需要处理向A中注入B,但是实例B并没有创建,所以先需要创建B的实例,但是也是半成品的B,因为还没有处理A的依赖注入。
4.现在就是需要向B中加入A,那么在这三级缓存中,先从哪开始找A呢?当然是先从一级缓存开始依次向后寻找,所以这里就是在第三级缓存找到了半成品A的对象工厂,可以从半成品A的对象工厂中获取到半成品A,这样完整的B就创建好了。然后把完整的B放入一级缓存,方便别人注入。把半成品A放入二级缓存,因为可能还有其他对象依赖A,所以并不会删除半成品A。然后把半成品A的对象工厂从三级缓存中删除。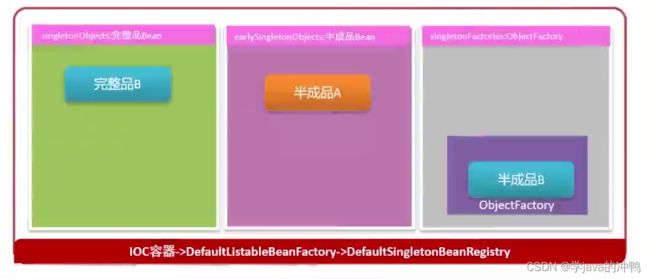
5.因为完整的实例化好了B,所以可以直接把B依赖注入到半成品A,这样完整品A就创建完成了。因为这里只是最简单的循环依赖,所以最后把二级和三级缓存的内容清除了。
(2)debug看源码的方式
1.根据上一篇文章Bean的生命周期中的Bean的实例化中,这个断点处就是真正创建Bean实例的方法,可以看见只是创建了一个半成品的A,并没有注入B。
2.怎么放入第三级缓存呢?找到相关代码,可以看出这个就是把半成品A加入到第三级缓存的一个方法。
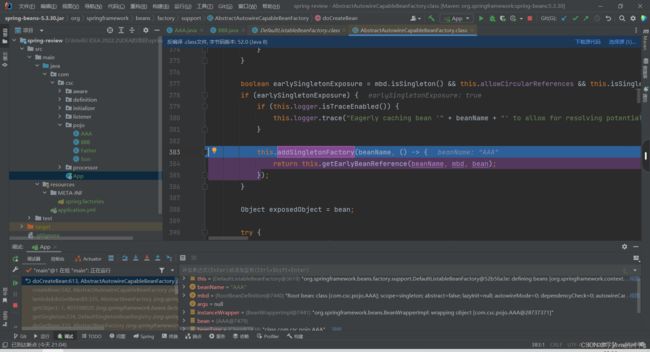
3.我们步入进去,发现这些singletonFactories等等都是Map集合。
- this.singletonFactories.put(beanName, singletonFactory);这个就是把半成品A加入到了工厂里面,并放入到三级缓存中了。
- this.earlySingletonObjects.remove(beanName);这个就是防止二级缓存有了半成品A,先删除以防保险。
- this.registeredSingletons.add(beanName);记录一下添加的bean。

4.现在需要依赖注入B,上篇文章也说过该方法就是用来实现依赖注入。我们打上断点后,需要放行,然后看B实例是如何创建的,因为要先创建B实例才能向A中注入B。
5.可以看见B实例其实也是一个半成品,并没有注入A。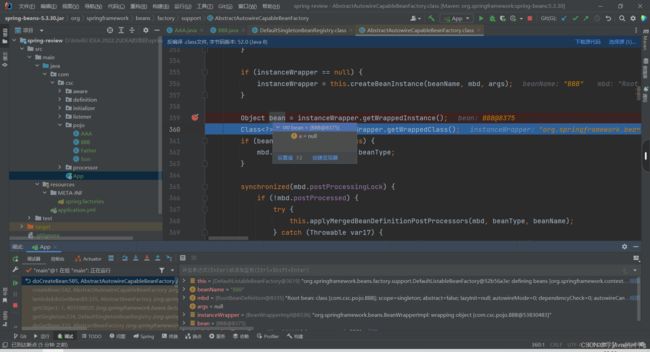
6.和A一样的步骤debug,可以看见singletonFactories里面就有了A和B的对象工厂。
7.放行进入到了下面这个方法,这个返回的其实是个动态代理对象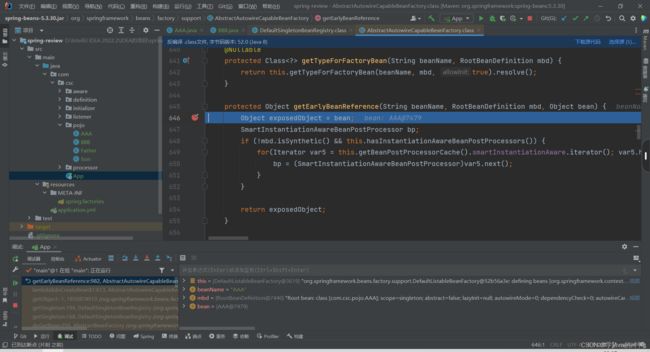
8.步过,返回上一个方法调用的地方,这个就是核心的依赖注入了。这个整段代码的大概意思就是,先从第一个缓存区获取实例没有再从第二个缓存区去获取,为什么还要再重复上面操作呢?因为有同步锁,第一次获取到的话其实就是为了提高性能。
9.通过singletonFactories集合获取到的singletonFactory对象,再调用该工厂对象的getObject()方法获取半成品A,可以看见singletonObject就是半成品的A。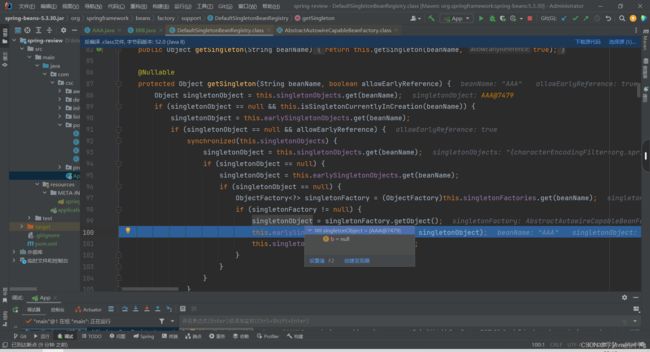
10.获取到半成品A后,然后先把半成品A放入第二级缓存,并删除第三级缓存的A的对象工厂。
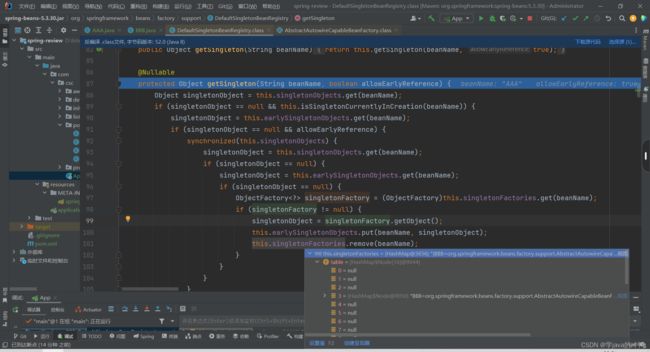
11.放行,可以看见现在的B就是一个完全品,因为注入了A。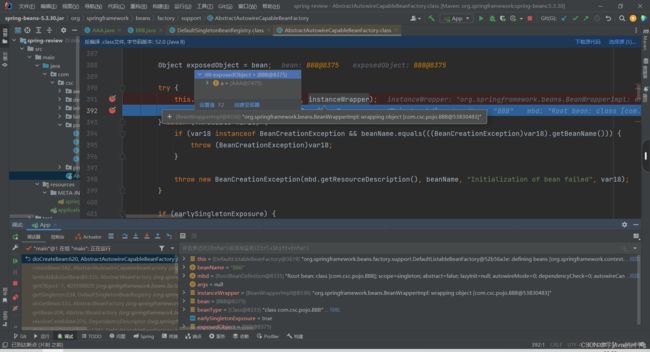
12.现在已经有了半成品的A,以及完全品的B,但是B现在在哪里呢?我们依然步过跳转到核心的DefaultSingletonBeanRegistry这个类里面去找相关的代码。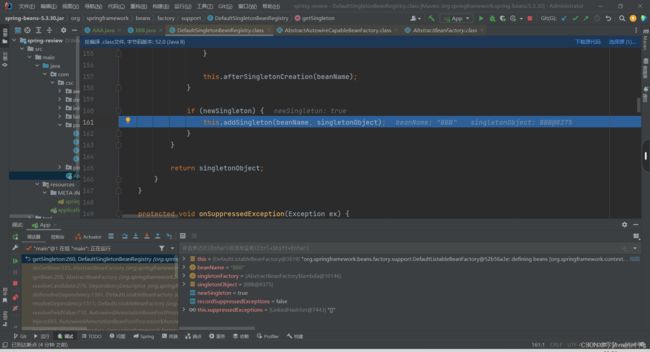
13.可以看见该方法就是把完全品B加入到一级缓存,删除二级和三级相关的B实例对象。
14.现在B的所有工作已经完成了,我们放行就会回到最开始的创建A实例,而且是依赖注入的那个方法那里,然后依赖注入完全品B,这样完全品A就创建好了。
15.和把完全品B放入一级缓存等步骤一样。
16.至此,循环依赖就这样通过3个缓存解决了,其实两个缓存就够了,为什么还要三级缓存呢?其实就是动态代理,动态代理在此过程中的作用在于,对于那些实现了接口的Bean,在发生循环依赖时,Spring可以通过JDK动态代理或CGLIB代理生成一个代理对象,该代理对象可以在不完成目标Bean全部初始化的情况下提供基本的功能,从而打破循环依赖的僵局。
3.面试的时候应该怎么说呢?
参考了黑马程序员的图片,如下图所示:
