Transformer 自然语言处理(二)
原文:Natural Language Processing with Transformers
译者:飞龙
协议:CC BY-NC-SA 4.0
第五章:文本生成
基于 Transformer 的语言模型最令人不安的特点之一是它们生成的文本几乎无法与人类写的文本区分开。一个著名的例子是 OpenAI 的 GPT-2,当给出以下提示时:¹
在一个令人震惊的发现中,科学家们发现了一群生活在安第斯山脉偏远、以前未被探索过的山谷中的独角兽。更令研究人员感到惊讶的是,这些独角兽竟然讲着一口流利的英语。
能够生成一篇关于说话的独角兽的引人入胜的新闻文章:
科学家们根据它们独特的角,将这一种群命名为奥维德独角兽。这种四角、银白色的独角兽以前对科学界来说是未知的。现在,经过将近两个世纪的时间,这一奇怪现象的起因终于得到了解决。拉巴斯大学的进化生物学家豪尔赫·佩雷斯博士和几个同伴在探索安第斯山脉时发现了一个没有其他动物或人类的小山谷。佩雷斯注意到山谷中有一个看起来像是天然喷泉的地方,周围有两座岩石和银色的雪峰。佩雷斯和其他人随后进一步探索了山谷。“当我们到达一个山峰的顶部时,水看起来是蓝色的,上面有一些水晶,”佩雷斯说。佩雷斯和他的朋友们惊讶地看到了独角兽群。这些生物可以从空中看到,而不需要移动太多就能看到它们——它们离得很近,可以触摸到它们的角。在检查这些奇怪的生物时,科学家们发现这些生物还能说一些相当规范的英语……
这个例子之所以如此引人注目,是因为它是在没有任何明确监督的情况下生成的!通过简单地学习预测数百万网页文本中的下一个单词,GPT-2 及其更强大的后代如 GPT-3 能够获得广泛的技能和模式识别能力,可以通过不同类型的输入提示来激活。图 5-1 显示了语言模型有时在预训练期间会接触到需要仅基于上下文预测下一个标记的任务序列,比如加法、单词重组和翻译。这使它们能够在微调期间或(如果模型足够大)在推断期间有效地转移这些知识。这些任务并不是提前选择的,而是在用于训练百亿参数语言模型的庞大语料库中自然发生的。

图 5-1。在预训练期间,语言模型会接触到可以在推断期间进行调整的任务序列(由汤姆·布朗提供)
Transformer 生成逼真文本的能力已经导致了各种各样的应用,比如InferKit、Write With Transformer、AI Dungeon,以及像Google 的 Meena这样的对话代理,甚至可以讲一些陈腐的笑话,就像图 5-2 中所示的那样!²
图 5-2。左边是米娜,右边是一个人,米娜正在讲一个陈腐的笑话(由丹尼尔·阿迪瓦达纳和 Thang Luong 提供)
在本章中,我们将使用 GPT-2 来说明语言模型的文本生成工作原理,并探讨不同的解码策略如何影响生成的文本。
生成连贯文本的挑战
到目前为止,在本书中,我们已经专注于通过预训练和监督微调的组合来解决 NLP 任务。正如我们所看到的,对于诸如序列或标记分类的任务特定头部,生成预测是相当简单的;模型产生一些 logits,我们要么取最大值得到预测类,要么应用 softmax 函数以获得每个类的预测概率。相比之下,将模型的概率输出转换为文本需要解码方法,这引入了一些对文本生成独特的挑战:
-
解码是迭代进行的,因此涉及的计算量比简单地通过模型的前向传递一次传递输入要多得多。
-
生成的文本的质量和多样性取决于解码方法和相关超参数的选择。
为了理解这个解码过程是如何工作的,让我们从检查 GPT-2 是如何预训练和随后应用于生成文本开始。
与其他自回归或因果语言模型一样,GPT-2 被预训练来估计在给定一些初始提示或上下文序列 = x 1 , x 2 , … x k的情况下,估计文本中出现的一系列标记 = y 1 , y 2 , … y t的概率P ( | )。由于直接获取足够的训练数据来估计P ( | )是不切实际的,因此通常使用概率的链式法则将其分解为条件概率的乘积:
P ( y 1 , … , y t | ) = ∏ t=1 N P ( y t | y 其中y 到目前为止,您可能已经猜到了我们如何将下一个标记预测任务调整为生成任意长度的文本序列。如图 5-3 所示,我们从一个提示开始,比如“Transformer 是”,然后使用模型预测下一个标记。一旦确定了下一个标记,我们将其附加到提示上,然后使用新的输入序列生成另一个标记。我们一直这样做,直到达到特殊的序列结束标记或预定义的最大长度。 由于输出序列取决于输入提示的选择,这种类型的文本生成通常被称为条件文本生成。 这个过程的核心是一个解码方法,它确定在每个时间步骤选择哪个标记。由于语言模型头在每个步骤的词汇表中为每个标记生成一个 logit z t,i,我们可以通过使用 softmax 得到下一个可能标记w i的概率分布: P ( y t = w i | y 大多数解码方法的目标是通过选择 ^来搜索最可能的整体序列,使得: ^ = argmax P ( | ) 直接找到 ^将涉及评估语言模型的每个可能序列。由于不存在可以在合理时间内执行此操作的算法,因此我们依赖于近似。在本章中,我们将探讨其中一些近似,并逐渐构建更聪明和更复杂的算法,这些算法可以用于生成高质量的文本。 从模型的连续输出中获得离散标记的最简单解码方法是在每个时间步骤贪婪地选择具有最高概率的标记: y ^ t = argmax y t P ( y t | y 为了看看贪婪搜索是如何工作的,让我们从加载带有语言建模头的 GPT-2 的 15 亿参数版本开始:³ 现在让我们生成一些文本!虽然 通过这种简单的方法,我们能够生成句子“Transformers are the most popular toy line in the world”。有趣的是,这表明 GPT-2 已经内化了一些关于变形金刚媒体特许经营的知识,这是由两家玩具公司(孩之宝和 Takara Tomy)创造的。我们还可以看到每一步的其他可能的延续,这显示了文本生成的迭代性质。与其他任务(如序列分类)不同,在那些任务中,单次前向传递就足以生成预测,而在文本生成中,我们需要逐个解码输出标记。 实现贪婪搜索并不太难,但我们希望使用来自 现在让我们尝试一些更有趣的东西:我们能否重现 OpenAI 的独角兽故事?与之前一样,我们将使用分词器对提示进行编码,并为 ```py` The researchers, from the University of California, Davis, and the University of The researchers were surprised to find that the unicorns were able to The researchers were surprised to find that the unicorns were able 这导致了数值不稳定,因为我们遇到了下溢。我们可以通过计算一个相关的术语,即对数概率来避免这种情况。如果我们对联合和条件概率应用对数,然后借助对数的乘法规则,我们得到: log P ( y 1 , … y t | ) = ∑ t=1 N log P ( y t | y 换句话说,我们之前看到的概率乘积变成了对数概率的总和,这样就不太可能遇到数值不稳定性的问题。例如,计算与之前相同示例的对数概率为: 这是一个我们可以轻松处理的数字,这种方法对于更小的数字仍然有效。因为我们只想比较相对概率,所以我们可以直接使用对数概率进行比较。 让我们计算并比较贪婪搜索和束搜索生成的文本的对数概率,看看束搜索是否可以提高整体概率。由于 这给我们了单个标记的对数概率,所以要得到序列的总对数概率,我们只需要对每个标记的对数概率求和: 请注意,我们忽略输入序列的对数概率,因为它们不是模型生成的。我们还可以看到对齐 logits 和标签的重要性;因为模型预测下一个标记,我们不会得到第一个标签的 logit,并且我们不需要最后一个 logit,因为我们没有它的真实标记。 让我们首先使用这些函数来计算 OpenAI 提示中贪婪解码器的序列对数概率: 现在让我们将其与使用束搜索生成的序列进行比较。要使用 我们可以看到,使用束搜索得到的对数概率(越高越好)比简单的贪婪解码要好。然而,我们也可以看到束搜索也存在重复的文本问题。解决这个问题的一种方法是使用 这并不太糟糕!我们成功地停止了重复,并且可以看到,尽管产生了较低的分数,文本仍然连贯。带有n-gram 惩罚的波束搜索是一种很好的方法,可以在关注高概率标记(使用波束搜索)的同时减少重复(使用n-gram 惩罚),在摘要或机器翻译等需要事实正确性的应用中通常使用。当事实正确性不如生成输出的多样性重要时,例如在开放域闲聊或故事生成中,另一种减少重复并提高多样性的替代方法是使用抽样。让我们通过检查一些最常见的抽样方法来完成我们对文本生成的探索。 最简单的抽样方法是在每个时间步从模型输出的概率分布中随机抽样整个词汇表: P ( y t = w i | y 其中| V |表示词汇表的基数。我们可以通过添加一个温度参数T来控制输出的多样性,该参数在进行 softmax 之前重新调整 logits: P ( y t = w i | y 通过调整T,我们可以控制概率分布的形状。⁵ 当T ≪ 1时,分布在原点附近呈峰值,罕见的标记被抑制。另一方面,当T ≫ 1时,分布变得平坦,每个标记变得同样可能。温度对标记概率的影响在图 5-5 中显示。 为了看看我们如何使用温度来影响生成的文本,让我们通过在 我们可以清楚地看到,高温大多产生了胡言乱语;通过突出罕见的标记,我们导致模型创建了奇怪的语法和相当多的虚构词!让我们看看如果我们降低温度会发生什么: 这显然更加连贯,甚至包括了另一所大学被认为是发现的引用!我们可以从温度中得出的主要教训是,它允许我们控制样本的质量,但在连贯性(低温)和多样性(高温)之间总是存在一个权衡,需要根据手头的使用情况进行调整。 调整连贯性和多样性之间的权衡的另一种方法是截断词汇的分布。这使我们能够通过温度自由调整多样性,但在一个更有限的范围内,排除了在上下文中太奇怪的单词(即低概率单词)。有两种主要方法可以做到这一点:top-k和核(或 top-p)抽样。让我们来看看。 Top-k和核(top-p)抽样是使用温度的两种流行的替代方法或扩展。在这两种情况下,基本思想是限制我们可以在每个时间步骤从中抽样的可能标记的数量。为了了解这是如何工作的,让我们首先可视化模型在T = 1时的累积概率分布,如图 5-6 中所示。 让我们分解这些图表,因为它们包含了大量信息。在上图中,我们可以看到标记概率的直方图。它在10 -8左右有一个峰值,然后在10 -4左右有第二个较小的峰值,接着急剧下降,只有少数标记的概率在10 -2和10 -1之间。从这个图表中,我们可以看到选择具有最高概率的标记(在10 -1处的孤立条)的概率是 10 中的 1。 在下图中,我们按概率降序排列了标记,并计算了前 10,000 个标记的累积和(GPT-2 的词汇表中总共有 50,257 个标记)。曲线代表选择任何前面标记的概率。例如,选择具有最高概率的 1,000 个标记的概率大约为 96%。我们看到概率在 90%以上迅速上升,但只有在几千个标记后才接近 100%。图表显示,有 100 分之一的机会不选择任何不在前 2,000 位的标记。 尽管这些数字乍一看可能很小,但它们变得重要,因为在生成文本时,我们每个标记只采样一次。因此,即使只有 100 分之一或 1000 分之一的几率,如果我们采样数百次,就有很大的机会在某个时候选择到一个不太可能的标记,并且在采样时选择这些标记可能会严重影响生成文本的质量。因此,我们通常希望避免这些非常不太可能的标记。这就是 top-k和 top-p采样发挥作用的地方。 top-k采样的理念是通过仅从具有最高概率的k个标记中进行采样来避免低概率的选择。这对分布的长尾部分进行了固定的截断,并确保我们只从可能的选择中进行采样。回到图 5-6,top-k采样相当于定义一条垂直线,并从左侧的标记中进行采样。同样, 这可能是我们迄今为止生成的最接近人类的文本。但是我们如何选择k?k的值是手动选择的,并且对于序列中的每个选择都是相同的,独立于实际的输出分布。我们可以通过查看一些文本质量指标来找到k的合适值,我们将在下一章中探讨这些指标,但是这种固定的截断可能并不令人满意。 另一种选择是使用动态截断。使用核或 top-p采样时,我们不是选择固定的截断值,而是设置一个截断条件。这个条件是在选择中达到一定的概率质量时截断。假设我们将该值设置为 95%。然后,我们按概率降序排列所有标记,并从列表顶部逐个添加标记,直到所选标记的概率总和达到 95%。回到图 5-6,p的值定义了累积概率图上的水平线,并且我们只从线下的标记中进行采样。根据输出分布,这可能只是一个(非常可能的)标记,也可能是一百个(同等可能的)标记。在这一点上,您可能不会感到惊讶, Top-p采样也产生了一个连贯的故事,这次是关于从澳大利亚迁移到南美洲的新情节。您甚至可以结合这两种采样方法,以获得两全其美。设置 当我们使用采样时,我们还可以应用束搜索。我们可以对下一批候选标记进行采样并以相同的方式构建束,而不是贪婪地选择它们。 不幸的是,没有普遍“最佳”的解码方法。哪种方法最好将取决于你为生成文本的任务的性质。如果你希望你的模型执行精确的任务,比如算术或提供对特定问题的答案,那么你应该降低温度或使用贪婪搜索与波束搜索的确定性方法来保证得到最可能的答案。如果你希望模型生成更长的文本,甚至有点创造性,那么你应该切换到采样方法,增加温度或使用 top-k和核采样的混合。 在本章中,我们研究了文本生成,这与我们之前遇到的 NLU 任务非常不同。生成文本至少需要每个生成的标记进行一次前向传递,如果使用波束搜索,甚至需要更多。这使得文本生成在计算上要求很高,需要适当的基础设施来规模化运行文本生成模型。此外,一个良好的解码策略,将模型的输出概率转换为离散标记,可以提高文本质量。找到最佳的解码策略需要一些实验和对生成的文本进行主观评价。 然而,在实践中,我们不希望仅凭直觉做出这些决定!与其他 NLP 任务一样,我们应该选择一个反映我们想要解决的问题的模型性能指标。毫不奇怪,有很多选择,我们将在下一章中遇到最常见的选择,在那里我们将看看如何训练和评估文本摘要模型。或者,如果你迫不及待地想学习如何从头开始训练 GPT 类型的模型,你可以直接跳到第十章,在那里我们收集了大量的代码数据集,然后对其进行自回归语言模型的训练。 ¹ 这个例子来自 OpenAI 的GPT-2 博客文章。 ² 然而,正如Delip Rao 指出的,Meena 是否打算讲冷笑话是一个微妙的问题。 ³ 如果你的机器内存不足,你可以通过将 ⁴ N.S. Keskar 等人,“CTRL: A Conditional Transformer Language Model for Controllable Generation”,(2019)。 ⁵ 如果你懂一些物理学,你可能会发现与玻尔兹曼分布有惊人的相似之处。 你可能在某个时候需要总结一篇文档,无论是研究文章、财务收益报告还是一系列电子邮件。如果你仔细想想,这需要一系列能力,比如理解长篇文章、推理内容,并产生流畅的文本,其中包含原始文档的主要主题。此外,准确总结新闻文章与总结法律合同大不相同,因此能够做到这一点需要一定程度的领域泛化。出于这些原因,文本摘要对于神经语言模型,包括 Transformer 来说,是一项困难的任务。尽管存在这些挑战,文本摘要为领域专家提供了显著加快工作流程的可能性,并被企业用于压缩内部知识、总结合同、自动生成社交媒体发布的内容等。 为了帮助您了解涉及的挑战,本章将探讨如何利用预训练的 Transformer 来总结文档。摘要是一个经典的序列到序列(seq2seq)任务,有一个输入文本和一个目标文本。正如我们在第一章中看到的,这正是编码器-解码器 Transformer 擅长的地方。 在本章中,我们将构建自己的编码器-解码器模型,将几个人之间的对话压缩成简洁的摘要。但在开始之前,让我们先来看看摘要的经典数据集之一:CNN/DailyMail 语料库。 CNN/DailyMail 数据集包括约 30 万对新闻文章及其相应摘要,由 CNN 和 DailyMail 附加到其文章的要点组成。数据集的一个重要方面是摘要是抽象的,而不是提取的,这意味着它们由新句子组成,而不是简单的摘录。数据集可在Hub上找到;我们将使用 3.0.0 版本,这是为摘要设置的非匿名版本。我们可以像在第四章中看到的那样,使用 数据集有三列: 我们看到,与目标摘要相比,文章可能非常长;在这种特殊情况下,差异是 17 倍。长篇文章对大多数 Transformer 模型构成挑战,因为上下文大小通常限制在 1,000 个标记左右,相当于几段文字。对于摘要,处理这个问题的标准但粗糙的方法是简单地截断超出模型上下文大小的文本。显然,文本末尾可能有重要信息供摘要使用,但目前我们需要接受模型架构的这种限制。 让我们首先定性地查看前面示例的输出,看看一些最受欢迎的摘要 Transformer 模型的表现如何。尽管我们将要探索的模型架构具有不同的最大输入大小,但让我们将输入文本限制为 2,000 个字符,以便所有模型都具有相同的输入,从而使输出更具可比性: 摘要中的一个惯例是用换行符分隔摘要句子。我们可以在每个句号后添加一个换行符,但这种简单的启发式方法对于像“U.S.”或“U.N.”这样的字符串将失败。自然语言工具包(NLTK)包括一个更复杂的算法,可以区分句子的结束和缩写中出现的标点符号: 在接下来的几节中,我们将加载几个大型模型。如果内存不足,可以用较小的检查点(例如“gpt”,“t5-small”)替换大型模型,或者跳过本节,转到“在 CNN/DailyMail 数据集上评估 PEGASUS”。 摘要新闻文章的一个常见基线是简单地取文章的前三句。使用 NLTK 的句子分词器,我们可以很容易地实现这样一个基线: 我们已经在第五章中看到了 GPT-2 如何根据一些提示生成文本。该模型令人惊讶的一个特点是,我们还可以使用它来生成摘要,只需在输入文本末尾添加“TL;DR”。表达“TL;DR”(太长了;没看)经常在 Reddit 等平台上使用,表示长篇帖子的简短版本。我们将通过使用来自 Transformers 的 在这里,我们只需存储通过切割输入查询生成的摘要,并将结果保存在 Python 字典中以供以后比较。 接下来让我们尝试 T5 Transformer。正如我们在第三章中看到的,该模型的开发人员对 NLP 中的迁移学习进行了全面研究,并发现他们可以通过将所有任务制定为文本-文本任务来创建通用 Transformer 架构。T5 检查点经过混合无监督数据(用于重建掩码单词)和监督数据的训练,包括摘要等多个任务。因此,这些检查点可以直接用于执行摘要,而无需使用预训练期间使用的相同提示进行微调。在该框架中,模型摘要文档的输入格式为 我们可以直接使用 BART 还使用了编码器-解码器架构,并且经过训练以重建损坏的输入。它结合了 BERT 和 GPT-2 的预训练方案。我们将使用 像 BART 一样,PEGASUS 是一种编码器-解码器 Transformer。如图 6-2 所示,它的预训练目标是预测多句文本中的掩码句子。作者认为,预训练目标与下游任务越接近,效果就越好。为了找到一个比通用语言建模更接近摘要的预训练目标,他们在一个非常大的语料库中自动识别了包含其周围段落大部分内容的句子(使用摘要评估指标作为内容重叠的启发式),并预训练 PEGASUS 模型以重建这些句子,从而获得了用于文本摘要的最先进模型。 该模型具有用于换行的特殊标记,这就是为什么我们不需要 现在我们已经用四种不同的模型生成了摘要,让我们比较一下结果。请记住,其中一个模型根本没有在数据集上进行训练(GPT-2),一个模型在这项任务以及其他任务上进行了微调(T5),而另外两个模型则专门在这项任务上进行了微调(BART 和 PEGASUS)。让我们看看这些模型生成的摘要: 通过查看模型输出,我们首先注意到 GPT-2 生成的摘要与其他模型有很大不同。它不是给出文本的摘要,而是总结了字符。由于它并没有明确训练生成真实摘要,因此 GPT-2 模型经常“产生幻觉”或虚构事实。例如,在撰写时,内斯塔并不是世界上最快的人,而是排名第九。将其他三个模型的摘要与真实情况进行比较,我们发现 PEGASUS 的输出与之最为相似。 现在我们已经检查了一些模型,让我们试着决定在生产环境中使用哪个模型。所有四个模型似乎都提供了合理的结果,我们可以生成更多的例子来帮助我们决定。然而,这并不是一个系统确定最佳模型的方法!理想情况下,我们会定义一个指标,在一些基准数据集上对所有模型进行测量,并选择性能最佳的模型。但是如何定义文本生成的指标呢?我们看到的标准指标,如准确率、召回率和精度,不容易应用于这个任务。对于人类撰写的“黄金标准”摘要,可能有数十种其他具有同义词、释义或稍微不同表达事实方式的摘要同样可以接受。 在接下来的部分,我们将看一些用于衡量生成文本质量的常见指标。 好的评估指标很重要,因为我们用它们来衡量模型的性能,不仅在训练时使用,而且在生产中也会用到。如果我们的指标不好,我们可能会对模型的退化视而不见,如果它们与业务目标不一致,我们可能无法创造任何价值。 在文本生成任务上衡量性能并不像标准分类任务(如情感分析或命名实体识别)那样容易。以翻译为例;给定一个句子“我爱狗!”的英文翻译成西班牙语可能有多种有效的可能性,比如“¡Me encantan los perros!”或“¡Me gustan los perros!”简单地检查是否与参考翻译完全匹配并不是最佳选择;即使是人类在这样的指标上表现也不佳,因为我们每个人写的文本都略有不同(甚至在一天或一年的不同时间也不同!)。幸运的是,还有其他选择。 用于评估生成文本的最常见的两个指标是 BLEU 和 ROUGE。让我们看看它们是如何定义的。 BLEU 的思想很简单:⁴,我们不是看生成文本中有多少标记与参考文本标记完全对齐,而是看单词或n-grams。BLEU 是一种基于精度的指标,这意味着当我们比较两个文本时,我们计算生成文本中与参考文本中出现的单词数,并将其除以参考文本的长度。 然而,这种基础精度存在一个问题。假设生成的文本只是一遍又一遍地重复相同的单词,并且这个单词也出现在参考文本中。如果它重复的次数正好等于参考文本的长度,那么我们就得到了完美的精度!因此,BLEU 论文的作者引入了一个轻微的修改:一个单词只计算它在参考文本中出现的次数。为了说明这一点,假设我们有参考文本“猫在垫子上”,生成文本“猫猫猫猫猫猫”。 从这个简单的例子中,我们可以计算出精度值如下: 我们可以看到,简单的修正产生了一个更合理的值。现在让我们通过不仅查看单词,而且还查看n-克拉姆来扩展这一点。假设我们有一个生成的句子, s n t ,我们想将其与一个参考句子 s n t ’ 进行比较。我们提取所有可能的n-克拉姆,并进行计算,得到精度 p n : 数学标记=“p 下标 n 基线等于开始分数 sigma-总和下标 n-克拉姆元素属于 snt 上标计数下标 clip 基线左括号 n-克拉姆右括号除以 sigma-总和下标 n-克拉姆元素属于 snt 上标计数左括号 n-克拉姆右括号结束分数” 显示=“块”> p n = ∑ n - g r a m ∈ s n t C o u n t c l i p ( n - g r a m ) ∑ n - g r a m ∈ s n t ’ C o u n t ( n - g r a m ) 为了避免奖励重复生成,分子中的计数被剪切。这意味着n-克拉姆的出现次数被限制为它在参考句子中出现的次数。还要注意,这个方程中对句子的定义并不是非常严格的,如果你有一个生成的跨越多个句子的文本,你会将它视为一个句子。 通常情况下,我们在测试集中有多个样本要评估,因此我们需要稍微扩展方程,对语料库C中的所有样本进行求和: 数学标记=“p 下标 n 基线等于开始分数 sigma-求和下标 snt 属于上 C 结束 sigma-求和下标 n-hyphen-gram 属于 snt 上 C 计数 clip 下标基线左括号 n-hyphen-gram 右括号除以 sigma-求和下标 snt prime 属于上 C 结束 sigma-求和下标 n-hyphen-gram 属于 snt prime 计数左括号 n-hyphen-gram 右括号结束分数” 显示=“块”> p n = ∑ s n t ∈ C ∑ n - g r a m ∈ s n t C o u n t c l i p ( n - g r a m ) ∑ s n t ’ ∈ C ∑ n - g r a m ∈ s n t ’ C o u n t ( n - g r a m ) 我们快要到了。由于我们不关注召回率,所有生成的序列如果短而准确,都比长句子有益。因此,精确度得分偏爱短生成物。为了补偿这一点,BLEU 的作者引入了一个额外的术语,简洁惩罚: 通过取最小值,我们确保这个惩罚永远不会超过 1,当生成文本的长度l gen小于参考文本l ref时,指数项变得指数级小。此时,你可能会问,为什么我们不使用类似F[1]-分数来考虑召回率呢?答案是,通常在翻译数据集中,有多个参考句子而不只是一个,因此,如果我们也测量召回率,我们会鼓励使用所有参考句子中的所有单词的翻译。因此,最好是寻求翻译中的高精度,并确保翻译和参考具有类似的长度。 最后,我们可以把所有东西放在一起,得到 BLEU 分数的方程: 最后一个术语是修改后的精度直到n-gram N的几何平均值。在实践中,通常报告 BLEU-4 分数。然而,您可能已经看到这个指标有许多局限性;例如,它不考虑同义词,并且推导过程中的许多步骤似乎是临时的和相当脆弱的启发式。您可以在 Rachel Tatman 的博客文章“Evaluating Text Output in NLP: BLEU at Your Own Risk”中找到对 BLEU 缺陷的精彩阐述。 总的来说,文本生成领域仍在寻找更好的评估指标,克服 BLEU 等指标的局限性是一个活跃的研究领域。BLEU 指标的另一个弱点是它期望文本已经被标记化。如果没有使用完全相同的文本标记化方法,这可能会导致不同的结果。SacreBLEU 指标通过内部化标记化步骤来解决这个问题;因此,它是用于基准测试的首选指标。 我们现在已经通过了一些理论,但我们真正想做的是计算一些生成文本的分数。这是否意味着我们需要在 Python 中实现所有这些逻辑?不用担心, 如果有多个参考翻译,BLEU 分数也适用。这就是为什么 我们可以看到 1-gram 的精度确实是 2/6,而 2/3/4-gram 的精度都是 0。 (有关个别指标的更多信息,如计数和 bp,请参阅SacreBLEU 存储库。)这意味着几何平均值为零,因此 BLEU 分数也为零。让我们看另一个几乎正确的预测示例: 我们观察到精度分数要好得多。预测中的 1-gram 都匹配,只有在精度分数中我们才看到有些不对劲。对于 4-gram,只有两个候选项, BLEU 分数被广泛用于评估文本,特别是在机器翻译中,因为通常更青睐精确的翻译,而不是包含所有可能和适当单词的翻译。 还有其他应用,比如摘要,情况就不同了。在那里,我们希望生成的文本中包含所有重要信息,因此我们更青睐高召回率。这就是 ROUGE 分数通常被使用的地方。 ROUGE 分数专门为像摘要这样的应用程序开发,其中高召回率比精确度更重要。这种方法与 BLEU 分数非常相似,我们观察不同的n-gram,并比较它们在生成文本和参考文本中的出现次数。不同之处在于,对于 ROUGE,我们检查参考文本中有多少n-gram 也出现在生成文本中。对于 BLEU,我们看生成文本中有多少n-gram 出现在参考文本中,因此我们可以重新使用精确度公式,只是在分子中计算生成文本中参考n-gram 的(未修剪的)出现次数。 ROUGE-N = ∑ snt’€™∈C ∑ n-gram∈snt ‘ Count match (n-gram) ∑ snt’€™∈C ∑ n-gram∈snt ’ Count(n-gram) 这是 ROUGE 的原始提案。随后,研究人员发现完全移除精确度可能会产生强烈的负面影响。回到没有修剪计数的 BLEU 公式,我们可以衡量精确度,并且可以将精确度和召回的 ROUGE 分数结合起来,得到F[1]-score。这个分数是现在常用于 ROUGE 报告的度量标准。 ROUGE 中有一个单独的分数用于衡量最长公共子串(LCS),称为 ROUGE-L。LCS 可以计算任意一对字符串。例如,“abab”和“abc”的 LCS 将是“ab”,其长度为 2。如果我们想比较两个样本之间的这个值,我们需要以某种方式对其进行归一化,否则较长的文本将处于优势地位。为了实现这一点,ROUGE 的发明者提出了一种类似于F -score 的方案,其中 LCS 与参考文本和生成文本的长度进行了归一化,然后将两个归一化分数混合在一起: R LCS = LCS(X,Y) mP LCS = LCS(X,Y) nF LCS = (1+β 2 )R LCS P LCS R LCS +βP LCS , where β = P LCS / R LCS 这样,LCS 分数就可以得到适当的归一化,并可以在样本之间进行比较。在 我们可以按以下方式加载度量标准: 我们已经使用 GPT-2 和其他模型生成了一组摘要,现在我们有了一个系统比较摘要的度量标准。让我们将 ROUGE 分数应用于模型生成的所有摘要: 在 显然,这些结果并不是非常可靠,因为我们只看了一个样本,但我们可以比较一下这一个例子的摘要质量。表格证实了我们的观察,即我们考虑的模型中,GPT-2 的表现最差。这并不奇怪,因为它是这个组中唯一没有明确训练用于摘要的模型。然而,令人惊讶的是,简单的前三句基线与拥有大约十亿参数的 Transformer 模型相比,表现并不太差!PEGASUS 和 BART 是整体上最好的模型(ROUGE 分数越高越好),但 T5 在 ROUGE-1 和 LCS 分数上略微更好。这些结果将 T5 和 PEGASUS 列为最佳模型,但再次需要谨慎对待这些结果,因为我们只在一个例子上评估了模型。从 PEGASUS 论文中的结果来看,我们预期 PEGASUS 在 CNN/DailyMail 数据集上的表现将优于 T5。 让我们看看我们是否可以用 PEGASUS 复现这些结果。 我们现在已经准备好适当地评估模型了:我们有一个来自 CNN/DailyMail 的测试集的数据集,我们有一个 ROUGE 指标,我们有一个摘要模型。我们只需要把这些部分组合起来。让我们首先评估三句基线的性能: 现在我们将把这个函数应用到数据的一个子集上。由于 CNN/DailyMail 数据集的测试部分大约有 10,000 个样本,为所有这些文章生成摘要需要很长时间。回想一下第五章中提到的,每个生成的标记都需要通过模型进行前向传递;为每个样本生成 100 个标记将需要 100 万次前向传递,如果我们使用波束搜索,这个数字将乘以波束的数量。为了保持计算相对快速,我们将对测试集进行子采样,然后在 1,000 个样本上运行评估。这应该给我们一个更加稳定的分数估计,同时在单个 GPU 上不到一小时内完成 PEGASUS 模型的评估: 大多数分数比上一个例子差,但仍然比 GPT-2 取得的分数要好!现在让我们实现相同的评估函数来评估 PEGASUS 模型: 让我们稍微解开一下这个评估代码。首先,我们将数据集分成较小的批次,然后对每个批次进行同时处理。然后,对于每个批次,我们对输入文章进行标记化,并将它们馈送到 这些数字非常接近已发布的结果。这里需要注意的一点是,损失和每个标记的准确性在某种程度上与 ROUGE 分数是分离的。损失与解码策略无关,而 ROUGE 分数与之强相关。 由于 ROUGE 和 BLEU 与人类判断更相关,比损失或准确性,我们应该专注于它们,并在构建文本生成模型时仔细探索和选择解码策略。然而,这些指标远非完美,人们始终应该考虑人类判断。 现在我们有了一个评估函数,是时候为我们自己的摘要模型进行训练了。 我们已经详细讨论了文本摘要和评估的许多细节,现在让我们利用这些来训练一个自定义的文本摘要模型!对于我们的应用,我们将使用三星开发的SAMSum 数据集,其中包含一系列对话以及简要摘要。在企业环境中,这些对话可能代表客户与支持中心之间的互动,因此生成准确的摘要可以帮助改善客户服务并检测客户请求中的常见模式。让我们加载它并查看一个示例: 对话看起来就像你通过短信或 WhatsApp 进行聊天时所期望的那样,包括表情符号和 GIF 的占位符。 首先,我们将使用 PEGASUS 运行相同的摘要流程,看看输出是什么样的。我们可以重用用于 CNN/DailyMail 摘要生成的代码: 我们可以看到,该模型主要通过提取对话中的关键句子来进行摘要。这在 CNN/DailyMail 数据集上可能效果相对较好,但在 SAMSum 中的摘要更加抽象。让我们通过在测试集上运行完整的 ROUGE 评估来确认这一点: 结果并不理想,但这并不意外,因为我们已经远离了 CNN/DailyMail 数据分布。尽管如此,在训练之前设置评估流程有两个优点:我们可以直接用指标来衡量训练的成功与否,同时也有了一个很好的基准。在我们的数据集上微调模型应该会立即提高 ROUGE 指标,如果不是这样,我们就会知道我们的训练循环出了问题。 在处理训练数据之前,让我们快速查看输入和输出的长度分布: 我们看到大多数对话比 CNN/DailyMail 文章要短得多,每个对话大约有 100-200 个标记。同样,摘要也要短得多,大约有 20-40 个标记(平均推文长度)。 在构建 在标记化步骤中使用的新功能是 现在,我们需要创建数据收集器。这个函数在 我们将其向右移动一个,以便解码器只看到先前的地面真实标签,而不是当前或未来的标签。仅仅移位就足够了,因为解码器具有掩码自注意力,可以屏蔽当前和未来的所有输入。 因此,当我们准备批处理时,我们通过将标签向右移动一个来设置解码器输入。之后,我们确保通过将它们设置为-100 来忽略标签中的填充标记,以便损失函数忽略它们。实际上,我们不必手动执行此操作,因为 然后,像往常一样,我们为训练设置了 与以前的设置不同的一件事是新的参数 现在让我们确保我们已经登录到 Hugging Face,这样我们就可以在训练后将模型推送到 Hub 了: 现在,我们已经准备好使用模型、分词器、训练参数和数据整理器以及训练和评估集来初始化训练器了: 我们已经准备好进行训练。训练后,我们可以直接在测试集上运行评估函数,以查看模型的表现如何: 我们看到 ROUGE 分数比没有微调的模型有了显著的改进,因此即使先前的模型也是用于摘要,但它并没有很好地适应新的领域。让我们将模型推送到 Hub: 在下一节中,我们将使用模型为我们生成一些摘要。 您还可以在训练循环中评估生成的内容:使用名为 通过查看损失和 ROUGE 分数,似乎模型在 CNN/DailyMail 上训练的原始模型相比显示了显著的改进。让我们看看从测试集中的样本生成的摘要是什么样子的: 这看起来更像参考摘要。似乎模型已经学会将对话合成为摘要,而不仅仅是提取段落。现在,最终测试:模型在自定义输入上的表现如何? 定制对话的生成摘要是有意义的。它很好地总结了讨论中所有人都想一起写书,而不仅仅是提取单个句子。例如,它将第三和第四行合成了一个逻辑组合。 与可以作为分类任务框架的其他任务相比,文本摘要提出了一些独特的挑战,比如情感分析、命名实体识别或问答。传统的度量标准如准确性并不能反映生成文本的质量。正如我们所看到的,BLEU 和 ROUGE 指标可以更好地评估生成的文本;然而,人类判断仍然是最好的衡量标准。 在使用总结模型时一个常见问题是如何总结文档,其中文本长度超过模型的上下文长度。不幸的是,目前还没有解决这个问题的单一策略,迄今为止,这仍然是一个开放和活跃的研究问题。例如,OpenAI 的最新工作显示了如何通过将其递归应用于长文档并在循环中使用人类反馈来扩展总结。⁶ 在下一章中,我们将讨论问答,这是根据文本段落提供问题答案的任务。与总结相比,对于这个任务,存在处理长篇或多篇文档的良好策略,我们将向您展示如何将问答扩展到数千篇文档。 ¹ A. Radford 等人,“语言模型是无监督多任务学习者”,OpenAI (2019)。 ² M. Lewis 等人,“BART:去噪序列到序列的预训练用于自然语言生成、翻译和理解”,(2019)。 ³ J. Zhang 等人,“PEGASUS:使用抽取的间隙句子进行抽象总结的预训练”,(2019)。 ⁴ K. Papineni 等人,“BLEU:机器翻译自动评估的方法”,计算语言学协会第 40 届年会论文集 (2002 年 7 月): 311–318,http://dx.doi.org/10.3115/1073083.1073135。 ⁵ C-Y. Lin,“ROUGE:自动摘要评估包”,文本摘要分支扩展 (2004 年 7 月),https://aclanthology.org/W04-1013.pdf。 ⁶ J. Wu 等人,“使用人类反馈递归总结书籍”,(2021)。 无论您是研究人员、分析师还是数据科学家,都有可能在某个时候需要浏览大量文档以找到您正在寻找的信息。更糟糕的是,您不断地被谷歌和必应提醒,存在更好的搜索方式!例如,如果我们在谷歌上搜索“玛丽·居里何时获得她的第一个诺贝尔奖?”我们立即得到了“1903”这个正确答案,如图 7-1 所示。 在这个例子中,谷歌首先检索了大约 319,000 个与查询相关的文档,然后进行了额外的处理步骤,提取了带有相应段落和网页的答案片段。很容易看出这些答案片段是有用的。例如,如果我们搜索一个更棘手的问题,比如“哪种吉他调音是最好的?”谷歌没有提供答案,而是我们必须点击搜索引擎返回的网页之一来找到答案。¹ 这项技术背后的一般方法被称为问答(QA)。有许多种类的 QA,但最常见的是抽取式 QA,它涉及到问题的答案可以在文档中识别为文本段落的一部分,文档可能是网页、法律合同或新闻文章。首先检索相关文档,然后从中提取答案的两阶段过程也是许多现代 QA 系统的基础,包括语义搜索引擎、智能助手和自动信息提取器。在本章中,我们将应用这一过程来解决电子商务网站面临的一个常见问题:帮助消费者回答特定的查询以评估产品。我们将看到客户评论可以作为 QA 的丰富而具有挑战性的信息来源,并且在这个过程中,我们将学习 transformers 如何作为强大的阅读理解模型,可以从文本中提取含义。让我们从详细说明用例开始。 本章重点介绍抽取式 QA,但其他形式的 QA 可能更适合您的用例。例如,社区 QA涉及收集用户在论坛上生成的问题-答案对,然后使用语义相似性搜索找到与新问题最接近的答案。还有长篇 QA,旨在对开放性问题生成复杂的段落长度答案,比如“天空为什么是蓝色?”值得注意的是,还可以对表格进行 QA,transformer 模型如TAPAS甚至可以执行聚合以生成最终答案! 如果您曾经在网上购买过产品,您可能会依赖客户评论来帮助您做出决定。这些评论通常可以帮助回答特定问题,比如“这把吉他带吗?”或者“我可以在晚上使用这个相机吗?”这些问题可能很难仅通过产品描述就能回答。然而,热门产品可能会有数百甚至数千条评论,因此找到相关的评论可能会很麻烦。一个替代方法是在像亚马逊这样的网站提供的社区问答平台上发布您的问题,但通常需要几天时间才能得到答案(如果有的话)。如果我们能像图 7-1 中的谷歌示例那样立即得到答案,那不是挺好的吗?让我们看看是否可以使用 transformers 来实现这一点! 为了构建我们的 QA 系统,我们将使用 SubjQA 数据集²,该数据集包括英语中关于六个领域的产品和服务的 10,000 多条客户评论:TripAdvisor、餐馆、电影、书籍、电子产品和杂货。如图 7-2 所示,每条评论都与一个问题相关联,可以使用评论中的一句或多句来回答。³ 该数据集的有趣之处在于,大多数问题和答案都是主观的;也就是说,它们取决于用户的个人经验。图 7-2 中的示例显示了为什么这一特点使得这个任务可能比寻找对像“英国的货币是什么?”这样的事实问题的答案更困难。首先,查询是关于“质量差”,这是主观的,取决于用户对质量的定义。其次,查询的重要部分根本不出现在评论中,这意味着不能用关键词搜索或释义输入问题来回答。这些特点使得 SubjQA 成为一个真实的数据集,可以用来对我们基于评论的 QA 模型进行基准测试,因为像图 7-2 中显示的用户生成内容类似于我们可能在野外遇到的内容。 QA 系统通常根据其在响应查询时可以访问的数据的领域进行分类。封闭领域QA 处理关于狭窄主题的问题(例如单个产品类别),而开放领域QA 处理几乎任何问题(例如亚马逊的整个产品目录)。一般来说,封闭领域 QA 涉及搜索的文档比开放领域情况少。 为了开始,让我们从Hugging Face Hub下载数据集。就像我们在第四章中所做的那样,我们可以使用 对于我们的用例,我们将专注于构建电子产品领域的 QA 系统。要下载 与 Hub 上的其他问答数据集一样,SubjQA 将每个问题的答案存储为嵌套字典。例如,如果我们检查 我们可以看到答案存储在 请注意,数据集相对较小,总共只有 1,908 个示例。这模拟了真实世界的情况,因为让领域专家标记抽取式 QA 数据集是费时费力的。例如,用于法律合同抽取式 QA 的 CUAD 数据集估计价值为 200 万美元,以应对标注其 13,000 个示例所需的法律专业知识!⁴ SubjQA 数据集中有相当多的列,但对于构建我们的 QA 系统来说,最有趣的是表 7-1 中显示的那些。 表 7-1. SubjQA 数据集的列名及其描述 让我们专注于这些列,并查看一些训练示例。我们可以使用 从这些例子中,我们可以做出一些观察。首先,问题在语法上不正确,这在电子商务网站的常见 FAQ 部分中是很常见的。其次,空的 接下来,让我们通过计算以一些常见起始词开头的问题来了解训练集中有哪些类型的问题: 我们可以看到以“How”、“What”和“Is”开头的问题是最常见的,所以让我们看一些例子: 现在我们已经对数据集有了一些了解,让我们深入了解 transformers 如何从文本中提取答案。 我们的问答系统首先需要找到一种方法来识别客户评论中的潜在答案作为文本跨度。例如,如果我们有一个问题“它防水吗?”和评论段落是“这个手表在 30 米深处防水”,那么模型应该输出“在 30 米处防水”。为了做到这一点,我们需要了解如何: 构建监督学习问题。 为问答任务对文本进行标记和编码。 处理超出模型最大上下文大小的长段落。 让我们从如何构建问题开始。 从文本中提取答案的最常见方法是将问题构建为跨度分类任务,其中答案跨度的起始和结束标记作为模型需要预测的标签。这个过程在图 7-4 中有所说明。 由于我们的训练集相对较小,只有 1295 个例子,一个好的策略是从已经在大规模 QA 数据集(如 SQuAD)上进行了微调的语言模型开始。一般来说,这些模型具有很强的阅读理解能力,并且可以作为构建更准确系统的良好基线。这与之前章节中的方法有些不同,在之前的章节中,我们通常是从预训练模型开始,然后自己微调特定任务的头部。例如,在第二章中,我们不得不微调分类头部,因为类别数量与手头的数据集相关联。对于抽取式问答,我们实际上可以从一个经过微调的模型开始,因为标签的结构在不同数据集之间保持不变。 您可以通过导航到Hugging Face Hub并在 Models 选项卡上搜索“squad”来找到一系列抽取式 QA 模型(图 7-5)。 正如您所看到的,在撰写本文时,有超过 350 个 QA 模型可供选择,那么您应该选择哪一个呢?一般来说,答案取决于各种因素,比如您的语料库是单语还是多语,以及在生产环境中运行模型的约束。表 7-2 列出了一些提供了良好基础的模型。 表 7-2。在 SQuAD 2.0 上进行微调的基线 Transformer 模型 在本章的目的是,我们将使用经过微调的 MiniLM 模型,因为它训练速度快,可以让我们快速迭代我们将要探索的技术。⁸ 像往常一样,我们需要的第一件事是一个标记器来对我们的文本进行编码,所以让我们看看这对于 QA 任务是如何工作的。 为了对我们的文本进行编码,我们将像往常一样从Hugging Face Hub加载 MiniLM 模型检查点: 要看到模型的实际效果,让我们首先尝试从文本的简短段落中提取答案。在抽取式 QA 任务中,输入以(问题,上下文)对的形式提供,因此我们将它们都传递给标记器,如下所示: 在这里,我们返回了 PyTorch 我们可以看到熟悉的 为了了解标记器如何为 QA 任务格式化输入,让我们解码 我们看到,对于每个 QA 示例,输入采用以下格式: 其中第一个 在这里,我们可以看到我们得到了一个 如果我们比较这些 logits 的形状和输入 ID: 我们看到每个输入标记都有两个 logits(一个起始和一个结束)。如图 7-6 所示,较大的正 logits 对应于更有可能成为起始和结束标记的候选标记。在这个例子中,我们可以看到模型将最高的起始标记 logits 分配给数字“1”和“6000”,这是有道理的,因为我们的问题是关于数量的。同样,我们看到最高 logits 的结束标记是“minute”和“hours”。 为了得到最终答案,我们可以计算起始和结束标记 logits 的 argmax,然后从输入中切片出这个范围。以下代码执行这些步骤并解码结果,以便我们可以打印出结果文本: 太好了,成功了!在 除了答案,管道还在 在我们的简单示例中,我们通过获取相应 logits 的 argmax 来获得起始和结束索引。然而,这种启发式方法可能会产生超出范围的答案,因为它选择属于问题而不是上下文的标记。在实践中,管道计算最佳的起始和结束索引组合,受到各种约束的限制,比如在范围内,要求起始索引在结束索引之前等等。 阅读理解模型面临的一个微妙之处是,上下文通常包含的标记比模型的最大序列长度(通常最多几百个标记)多。如图 7-7 所示,SubjQA 训练集中相当一部分包含的问题-上下文对无法适应 MiniLM 的 512 个标记的上下文大小。 对于其他任务,比如文本分类,我们简单地截断长文本,假设 在 在这种情况下,我们现在得到了一个 最后,我们可以通过解码输入来看到两个窗口重叠的位置: 现在我们对 QA 模型如何从文本中提取答案有了一些直觉,让我们看看构建端到端 QA 管道所需的其他组件。 在我们简单的答案提取示例中,我们向模型提供了问题和上下文。然而,在现实中,我们系统的用户只会提供有关产品的问题,因此我们需要一种方法从我们语料库中的所有评论中选择相关的段落。做到这一点的一种方法是将给定产品的所有评论连接在一起,并将它们作为单个长上下文输入模型。虽然简单,但这种方法的缺点是上下文可能变得非常长,从而为我们用户的查询引入不可接受的延迟。例如,假设平均每个产品有 30 条评论,每条评论需要 100 毫秒处理。如果我们需要处理所有评论来得到答案,这将导致每个用户查询的平均延迟为 3 秒,对于电子商务网站来说太长了! 为了处理这一点,现代 QA 系统通常基于检索器-阅读器架构,它有两个主要组件: 检索器 负责为给定查询检索相关文档。检索器通常被分类为稀疏或密集。稀疏检索器使用词频来表示每个文档和查询,形成稀疏向量。¹¹然后通过计算向量的内积来确定查询和文档的相关性。另一方面,密集检索器使用编码器(如 transformers)将查询和文档表示为上下文化的嵌入(密集向量)。这些嵌入编码语义含义,并允许密集检索器通过理解查询的内容来提高搜索准确性。 阅读器 负责从检索器提供的文档中提取答案。阅读器通常是一个阅读理解模型,尽管在本章末尾我们将看到可以生成自由形式答案的模型示例。 如图 7-9 所示,还可以有其他组件对检索器获取的文档或阅读器提取的答案进行后处理。例如,检索到的文档可能需要重新排名,以消除可能混淆阅读器的嘈杂或无关的文档。类似地,当正确答案来自长文档中的各个段落时,通常需要对阅读器的答案进行后处理。 为了构建我们的 QA 系统,我们将使用由deepset开发的Haystack库,deepset 是一家专注于 NLP 的德国公司。Haystack 基于检索器-阅读器架构,抽象了构建这些系统所涉及的大部分复杂性,并与 除了检索器和阅读器之外,在构建 Haystack 的 QA 管道时还涉及另外两个组件: 文档存储 存储文档和元数据的面向文档的数据库,这些文档和元数据在查询时提供给检索器 管道 将 QA 系统的所有组件结合在一起,以实现自定义查询流程,合并来自多个检索器的文档等 在本节中,我们将看看如何使用这些组件快速构建原型 QA 管道。稍后,我们将探讨如何提高其性能。 本章是使用 Haystack 库的 0.9.0 版本编写的。在版本 0.10.0中,重新设计了管道和评估 API,以便更容易检查检索器或阅读器是否影响性能。要查看使用新 API 的本章代码是什么样子,请查看GitHub 存储库。 在 Haystack 中,有各种可供选择的文档存储,并且每个文档存储都可以与一组专用的检索器配对。这在表 7-3 中有所说明,其中显示了每个可用文档存储的稀疏(TF-IDF、BM25)和密集(嵌入、DPR)检索器的兼容性。我们将在本章后面解释所有这些首字母缩略词的含义。 表 7-3。Haystack 检索器和文档存储的兼容性 由于本章将探讨稀疏和密集检索器,我们将使用与两种检索器类型兼容的 要初始化文档存储,我们首先需要下载并安装 Elasticsearch。通过按照 Elasticsearch 的指南¹² ,我们可以使用 接下来,我们需要启动 Elasticsearch 服务器。由于我们在 Jupyter 笔记本中运行本书中的所有代码,我们需要使用 Python 的 在 现在我们的 Elasticsearch 服务器已经启动运行,接下来要做的事情是实例化文档存储: 默认情况下, 太好了,我们已经将所有的评论加载到了一个索引中!要搜索索引,我们需要一个检索器,因此让我们看看如何为 Elasticsearch 初始化一个检索器。 Elasticsearch 文档存储可以与 Haystack 检索器中的任何一种配对,因此让我们首先使用基于 BM25 的稀疏检索器(简称“Best Match 25”)。BM25 是经典的词项频率-逆文档频率(TF-IDF)算法的改进版本,它将问题和上下文表示为可以在 Elasticsearch 上高效搜索的稀疏向量。BM25 分数衡量了匹配文本与搜索查询的相关程度,并通过迅速饱和 TF 值和规范化文档长度来改进 TF-IDF,以便短文档优于长文档。¹³ 在 Haystack 中,默认情况下使用 BM25 检索器在 接下来,让我们看一下训练集中单个电子产品的简单查询。对于像我们这样基于评论的问答系统,将查询限制在单个项目是很重要的,否则检索器会返回与用户查询无关的产品评论。例如,询问“相机质量如何?”如果没有产品过滤器,可能会返回关于手机的评论,而用户可能是在询问特定笔记本电脑相机的情况。我们的数据集中的 ASIN 值本身有点神秘,但我们可以使用在线工具如amazon ASIN或者简单地将 在这里,我们已经指定了 除了文档的文本,我们还可以看到 Elasticsearch 为其与查询的相关性计算的 现在我们有了检索相关文档的方法,接下来我们需要的是从中提取答案的方法。这就是读取器的作用,让我们看看如何在 Haystack 中加载我们的 MiniLM 模型。 在 Haystack 中,有两种类型的读取器可以用来从给定的上下文中提取答案: 基于 deepset 的FARM框架进行 transformers 的微调和部署。与使用 基于 尽管两种读取器都以相同的方式处理模型的权重,但在转换预测以生成答案方面存在一些差异: 在 由于我们将在本章后面对读取器进行微调,我们将使用 也可以直接在 在 太好了,读取器似乎正在按预期工作——接下来,让我们使用 Haystack 的一个管道将所有组件联系在一起。 Haystack 提供了一个 每个 太好了,现在我们有了一个端到端的 Amazon 产品评论 QA 系统!这是一个很好的开始,但请注意第二和第三个答案更接近实际问题。为了做得更好,我们需要一些指标来量化检索器和读取器的性能。我们接下来将看一下这一点。 尽管最近关于 QA 的研究大部分集中在改进阅读理解模型上,但实际上,如果检索器一开始就找不到相关文档,你的读取器有多好并不重要!特别是,检索器为整个 QA 系统的性能设定了一个上限,因此确保它做得好很重要。考虑到这一点,让我们首先介绍一些常见的指标来评估检索器,以便我们可以比较稀疏和密集表示的性能。 评估检索器的常见指标是召回率,它衡量了检索到的所有相关文档的比例。在这种情况下,“相关”只是指答案是否出现在文本段落中,因此给定一组问题,我们可以通过计算答案出现在检索器返回的前k个文档中的次数来计算召回率。 在 Haystack 中,有两种评估检索器的方法: 使用检索器内置的 构建一个自定义的 与召回率相辅相成的指标是平均精度(mAP),它奖励能够将正确答案排在文档排名中较高位置的检索器。 由于我们需要对每个产品进行召回率评估,然后在所有产品中进行聚合,我们将选择第二种方法。流水线图中的每个节点都代表一个通过 这里的 在我们的情况下,我们需要一个节点来评估检索器,因此我们将使用 注意每个节点都有一个 现在我们有了评估流水线,我们需要传递一些查询及其相应的答案。为此,我们将答案添加到我们文档存储中的专用 如果我们查看其中一个标签: 我们可以看到问题-答案对,以及一个包含唯一问题 ID 的 接下来,我们需要建立一个映射,将我们的问题 ID 和相应的答案传递给流水线。为了获取所有标签,我们可以使用文档存储中的 通过查看其中一个标签,我们可以看到与给定问题相关联的所有答案都聚合在一个 现在我们有了评估检索器的所有要素,让我们定义一个函数,将与每个产品相关联的每个问题-答案对传递到评估流水线中,并在我们的 太好了,它起作用了!请注意,我们选择了一个特定的值作为 如果我们绘制结果,我们可以看到随着k的增加,召回率如何提高: 从图中可以看出,在k = 5附近有一个拐点,从k = 10开始我们几乎可以完美地召回。现在让我们来看看使用密集向量技术检索文档。 我们已经看到,当我们的稀疏检索器返回k = 10个文档时,我们几乎可以完美地召回,但在较小的k值上我们能做得更好吗?这样做的优势在于我们可以向读者传递更少的文档,从而减少我们问答流程的总体延迟。像 BM25 这样的稀疏检索器的一个众所周知的局限性是,如果用户查询包含与评论完全不匹配的术语,它们可能无法捕获相关文档。一个有前途的替代方案是使用密集嵌入来表示问题和文档,当前的技术水平是一种被称为密集通道检索(DPR)的架构。¹⁴ DPR 背后的主要思想是使用两个 BERT 模型作为问题和段落的编码器。如图 7-10 所示,这些编码器将输入文本映射到 在 Haystack 中,我们可以像为 BM25 那样初始化 DPR 的检索器。除了指定文档存储外,我们还需要选择用于问题和段落的 BERT 编码器。通过给它们提供具有相关(正面)段落和不相关(负面)段落的问题进行训练,这些编码器被训练,目标是学习相关的问题-段落对具有更高的相似性。对于我们的用例,我们将使用已经以这种方式在 NQ 语料库上进行了微调的编码器: 在这里我们还设置了 我们现在准备好了!我们可以像为 BM25 那样评估密集检索器,并比较前k个召回率: 在这里我们可以看到,DPR 在召回率上并没有比 BM25 提供提升,并且在k = 3左右饱和。 通过使用 Facebook 的FAISS 库作为文档存储,可以加速嵌入的相似性搜索。同样,通过在目标领域进行微调,可以提高 DPR 检索器的性能。如果您想了解如何微调 DPR,请查看 Haystack 的教程。 现在我们已经探讨了检索器的评估,让我们转而评估读者。 在抽取式问答中,有两个主要的指标用于评估读者: 精确匹配(EM) 一个二进制度量,如果预测答案中的字符与真实答案完全匹配,则 EM = 1,否则 EM = 0。如果不期望有答案,那么如果模型预测任何文本,EM = 0。 F[1]-score 度量精确度和召回率的调和平均值。 让我们通过从 FARM 导入一些辅助函数并将它们应用于一个简单的例子来看看这些度量是如何工作的: 在底层,这些函数首先通过去除标点,修复空白和转换为小写来对预测和标签进行规范化。然后对规范化的字符串进行词袋式标记化,最后在标记级别计算度量。从这个简单的例子中,我们可以看到 EM 比F[1]-score 严格得多:向预测中添加一个标记会使 EM 为零。另一方面,F[1]-score 可能无法捕捉真正不正确的答案。例如,如果我们的预测答案范围是“大约 6000 美元”,那么我们得到: 因此,仅依赖F[1]-score 是误导性的,跟踪这两个度量是在权衡低估(EM)和高估(F[1]-score)模型性能之间的一个好策略。 一般来说,每个问题可能有多个有效答案,因此这些度量是针对评估集中的每个问题-答案对计算的,并且从所有可能的答案中选择最佳分数。然后通过对每个问题-答案对的单独分数进行平均来获得模型的整体 EM 和F[1]分数。 为了评估阅读器,我们将创建一个包含两个节点的新管道:一个阅读器节点和一个用于评估阅读器的节点。我们将使用 请注意,我们指定了 好吧,看起来经过精细调整的模型在 SubjQA 上的表现明显比在 SQuAD 2.0 上差,MiniLM 在 SQuAD 2.0 上的 EM 和F[1]分别为 76.1 和 79.5。性能下降的一个原因是客户评论与 SQuAD 2.0 数据集生成的维基百科文章非常不同,它们使用的语言通常是非正式的。另一个因素可能是我们数据集固有的主观性,其中问题和答案都与维基百科中包含的事实信息不同。让我们看看如何在数据集上进行精细调整以获得更好的领域自适应结果。 尽管在 SQuAD 上进行了精细调整的模型通常会很好地推广到其他领域,但我们发现对于 SubjQA,我们的模型的 EM 和F[1]分数要比 SQuAD 差得多。这种泛化失败也在其他抽取式 QA 数据集中观察到,并且被认为是证明了 Transformer 模型特别擅长过度拟合 SQuAD 的证据。(15)改进阅读器的最直接方法是在 SubjQA 训练集上进一步对我们的 MiniLM 模型进行精细调整。 这是一个非常复杂的数据格式,因此我们需要一些函数和一些 Pandas 魔术来帮助我们进行转换。我们需要做的第一件事是实现一个可以创建与每个产品 ID 相关联的 现在,当我们将与单个产品 ID 相关联的 最后一步是将此函数应用于每个拆分的 现在我们已经将拆分格式正确,让我们通过指定训练和开发拆分的位置以及保存微调模型的位置来微调我们的阅读器: 阅读器微调后,让我们现在将其在测试集上的性能与我们的基线模型进行比较: 哇,领域适应将我们的 EM 分数提高了六倍以上,并且F[1]-score 增加了一倍多!此时,您可能会想知道为什么我们不直接在 SubjQA 训练集上对预训练的语言模型进行微调。一个原因是 SubjQA 中只有 1,295 个训练示例,而 SQuAD 有超过 100,000 个,因此我们可能会遇到过拟合的挑战。尽管如此,让我们看看天真的微调会产生什么结果。为了公平比较,我们将使用与在 SQuAD 上微调基线时使用的相同语言模型。与以前一样,我们将使用 接下来,我们进行一轮微调: 并在测试集上进行评估: 我们可以看到,直接在 SubjQA 上对语言模型进行微调的结果比在 SQuAD 和 SubjQA 上进行微调的性能要差得多。 处理小数据集时,最佳做法是在评估 Transformer 时使用交叉验证,因为它们可能容易过拟合。您可以在FARM 存储库中找到如何使用 SQuAD 格式的数据集执行交叉验证的示例。 现在我们已经了解了如何分别评估阅读器和检索器组件,让我们将它们联系在一起,以衡量我们管道的整体性能。为此,我们需要为我们的检索器管道增加阅读器及其评估的节点。我们已经看到,在k = 10时,我们几乎可以完美地召回,因此我们可以固定这个值,并评估这对阅读器性能的影响(因为现在它将收到每个查询的多个上下文,而不是 SQuAD 风格的评估): 然后,我们可以将模型预测文档中检索器返回的答案的前 1 个 EM 和F[1]分数与图 7-12 中的进行比较。 从这个图中,我们可以看到检索器对整体性能的影响。特别是,与匹配问题-上下文对相比,整体性能有所下降,这是在 SQuAD 风格的评估中所做的。这可以通过增加阅读器被允许预测的可能答案数量来避免。 到目前为止,我们只从上下文中提取了答案范围,但一般情况下,答案的各个部分可能分散在整个文档中,我们希望我们的模型能够将这些片段综合成一个连贯的答案。让我们看看如何使用生成式 QA 来成功完成这项任务。 在文档中提取答案作为文本段的一个有趣的替代方法是使用预训练语言模型生成它们。这种方法通常被称为抽象或生成型 QA,它有潜力产生更好措辞的答案,综合了多个段落中的证据。虽然这种方法比抽取式 QA 不够成熟,但这是一个快速发展的研究领域,所以很可能在您阅读本文时,这些方法已经被广泛应用于工业中!在本节中,我们将简要介绍当前的技术水平:检索增强生成(RAG)。 RAG 通过将读者替换为生成器并使用 DPR 作为检索器来扩展了我们在本章中看到的经典检索器-阅读器架构。生成器是一个预训练的序列到序列变换器,如 T5 或 BART,它接收来自 DPR 的文档的潜在向量,然后根据查询和这些文档迭代生成答案。由于 DPR 和生成器是可微分的,整个过程可以端到端地进行微调,如图 7-13 所示。 为了展示 RAG 的工作原理,我们将使用之前的 RAG-Sequence 使用相同的检索文档来生成完整的答案。特别是,从检索器中获取的前k个文档被馈送到生成器,生成器为每个文档产生一个输出序列,然后对结果进行边际化以获得最佳答案。 RAG-Token 可以使用不同的文档来生成答案中的每个标记。这允许生成器从多个文档中综合证据。 由于 RAG-Token 模型往往比 RAG-Sequence 模型表现更好,我们将使用在 NQ 上进行微调的标记模型作为我们的生成器。在 Haystack 中实例化生成器类似于实例化阅读器,但是我们不是为上下文中的滑动窗口指定 这里的 接下来要做的事情是使用 Haystack 的 在 RAG 中,查询编码器和生成器都是端到端训练的,而上下文编码器是冻结的。在 Haystack 中, 现在让我们通过输入一些关于之前的亚马逊 Fire 平板电脑的查询来尝试一下 RAG。为了简化查询,我们将编写一个简单的函数,该函数接受查询并打印出前几个答案: 好的,现在我们准备好测试一下: 这个答案并不算太糟糕,但它确实表明问题的主观性使生成器感到困惑。让我们尝试一些更加客观的问题: 这更有意义!为了获得更好的结果,我们可以在 SubjQA 上对 RAG 进行端到端的微调;我们将把这留作练习,但如果您有兴趣探索,可以在 好吧,这是 QA 的一个风风火火的介绍,你可能还有很多问题想要得到答案(双关语!)。在本章中,我们讨论了 QA 的两种方法(提取式和生成式),并检查了两种不同的检索算法(BM25 和 DPR)。在这个过程中,我们看到领域适应可以是一个简单的技术,可以显著提高我们的 QA 系统的性能,并且我们看了一些用于评估这种系统的最常见的指标。尽管我们专注于封闭领域的 QA(即电子产品的单一领域),但本章中的技术可以很容易地推广到开放领域的情况;我们建议阅读 Cloudera 出色的 Fast Forward QA 系列来了解其中的内容。 在野外部署 QA 系统可能是一个棘手的问题,我们的经验是,其中相当大一部分价值来自首先为最终用户提供有用的搜索功能,然后是一个提取组件。在这方面,读者可以以新颖的方式使用,超出了按需回答用户查询的范围。例如,Grid Dynamics的研究人员能够使用他们的读者自动提取客户目录中每种产品的优缺点。他们还表明,可以通过创建查询,如“什么样的相机?”以零-shot 方式使用读者来提取命名实体。鉴于其幼稚和微妙的失败模式,我们建议只有在其他两种方法耗尽后才探索生成式 QA。解决 QA 问题的这种“需求层次结构”在图 7-14 中有所说明。 展望未来,一个令人兴奋的研究领域是多模态 QA,它涉及对文本、表格和图像等多种模态进行 QA。正如 MultiModalQA 基准所描述的那样,¹⁷这样的系统可以使用户回答跨越不同模态的信息的复杂问题,比如“著名的两根手指的画是什么时候完成的?”另一个具有实际业务应用的领域是在知识图谱上进行 QA,其中图的节点对应于现实世界的实体,它们的关系由边定义。通过将事实编码为(主语,谓语,宾语)三元组,可以使用图来回答关于缺失元素的问题。有一个将 Transformer 与知识图谱相结合的例子,请参见Haystack 教程。另一个有前途的方向是自动生成问题,作为一种使用未标记数据或数据增强进行无监督/弱监督训练的方式。最近的两个例子包括 Probably Answered Questions(PAQ)基准和跨语言设置的合成数据增强的论文。¹⁸ 在本章中,我们已经看到,为了成功地将 QA 模型应用于实际用例,我们需要应用一些技巧,比如实现一个快速检索管道,以便在几乎实时进行预测。尽管这听起来可能不像什么,但想象一下,如果您必须等待几秒钟才能获得谷歌搜索结果,您的体验会有多不同——几秒钟的等待时间可能决定了您的 Transformer 应用程序的命运。在下一章中,我们将看一些加速模型预测的方法。 ¹尽管在这种特殊情况下,每个人都同意 Drop C 是最好的吉他调音。 ²J. Bjerva 等人,“SubjQA: A Dataset for Subjectivity and Review Comprehension”,(2020)。 ³ 正如我们将很快看到的,还有一些无法回答的问题,旨在产生更健壮的模型。 ⁴ D. Hendrycks 等人,“CUAD: 专家注释的法律合同审查 NLP 数据集”,(2021)。 ⁵ P. Rajpurkar 等人,“SQuAD:超过 10 万个文本理解问题”,(2016)。 ⁶ P. Rajpurkar, R. Jia, and P. Liang,“知道你不知道的:SQuAD 的无法回答的问题”,(2018)。 ⁷ T. Kwiatkowski 等人,“自然问题:问答研究的基准”,计算语言学协会交易 7(2019 年 3 月):452-466,http://dx.doi.org/10.1162/tacl_a_00276。 ⁸ W. Wang 等人,“MINILM: 用于任务不可知的预训练 Transformer 的深度自注意压缩”,(2020)。 ⁹ 请注意, ¹⁰ 有关如何提取这些隐藏状态的详细信息,请参阅第二章。 ¹¹ 如果一个向量的大部分元素都是零,那么它就是稀疏的。 ¹² 该指南还提供了 macOS 和 Windows 的安装说明。 ¹³ 有关使用 TF-IDF 和 BM25 进行文档评分的深入解释,请参阅 D. Jurafsky 和 J.H. Martin(Prentice Hall)的《语音和语言处理》第 3 版第二十三章。 ¹⁴ V. Karpukhin 等人,“用于开放领域问答的密集通道检索”,(2020)。 ¹⁵ D. Yogatama 等人,“学习和评估通用语言智能”,(2019)。 ¹⁶ P. Lewis 等人,“用于知识密集型 NLP 任务的检索增强生成”,(2020)。 ¹⁷ A. Talmor 等人,“MultiModalQA:文本、表格和图像的复杂问答”,(2021)。 ¹⁸ P. Lewis 等人,“PAQ: 6500 万个可能被问到的问题及其用途”,(2021);A. Riabi 等人,“用于零样本跨语言问答的合成数据增强”,(2020)。
图 5-3。通过在每个步骤向输入添加一个新单词来从输入序列生成文本
注意
贪婪搜索解码
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "gpt2-xl"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
 Transformers 为 GPT-2 这样的自回归模型提供了
Transformers 为 GPT-2 这样的自回归模型提供了 generate() 函数,但我们将自己实现这种解码方法,以了解底层发生了什么。为了热身,我们将采用图 5-3 中显示的相同的迭代方法:我们将使用“Transformers are the”作为输入提示,并运行八个时间步的解码。在每个时间步,我们挑选出模型对提示中最后一个标记的 logits,并用 softmax 包装它们以获得概率分布。然后我们选择具有最高概率的下一个标记,将其添加到输入序列中,然后再次运行该过程。以下代码完成了这项工作,并且还存储了每个时间步的五个最有可能的标记,以便我们可以可视化替代方案:import pandas as pd
input_txt = "Transformers are the"
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
iterations = []
n_steps = 8
choices_per_step = 5
with torch.no_grad():
for _ in range(n_steps):
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0])
output = model(input_ids=input_ids)
# Select logits of the first batch and the last token and apply softmax
next_token_logits = output.logits[0, -1, :]
next_token_probs = torch.softmax(next_token_logits, dim=-1)
sorted_ids = torch.argsort(next_token_probs, dim=-1, descending=True)
# Store tokens with highest probabilities
for choice_idx in range(choices_per_step):
token_id = sorted_ids[choice_idx]
token_prob = next_token_probs[token_id].cpu().numpy()
token_choice = (
f"{tokenizer.decode(token_id)} ({100 * token_prob:.2f}%)"
)
iteration[f"Choice {choice_idx+1}"] = token_choice
# Append predicted next token to input
input_ids = torch.cat([input_ids, sorted_ids[None, 0, None]], dim=-1)
iterations.append(iteration)
pd.DataFrame(iterations)
输入
选择 1
选择 2
选择 3
选择 4
选择 5
0
Transformers are the
most (8.53%)
only (4.96%)
best (4.65%)
Transformers (4.37%)
ultimate (2.16%)
1
Transformers are the most
popular (16.78%)
powerful (5.37%)
common (4.96%)
famous (3.72%)
successful (3.20%)
2
Transformers are the most popular
toy (10.63%)
toys (7.23%)
Transformers (6.60%)
of (5.46%)
and (3.76%)
3
Transformers are the most popular toy
line (34.38%)
in (18.20%)
of (11.71%)
brand (6.10%)
line (2.69%)
4
Transformers are the most popular toy line
in (46.28%)
of (15.09%)
, (4.94%)
on (4.40%)
ever (2.72%)
5
Transformers are the most popular toy line in
the (65.99%)
history (12.42%)
America (6.91%)
Japan (2.44%)
North (1.40%)
6
Transformers are the most popular toy line in the
world (69.26%)
United (4.55%)
history (4.29%)
US (4.23%)
U (2.30%)
7
Transformers are the most popular toy line in the world
, (39.73%)
. (30.64%)
and (9.87%)
with (2.32%)
today (1.74%)
 Transformers 的内置
Transformers 的内置 generate() 函数来探索更复杂的解码方法。为了重现我们的简单示例,让我们确保抽样被关闭(默认情况下关闭,除非您从加载检查点的特定模型配置中另有说明),并指定 max_new_tokens 为新生成标记的数量:input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output = model.generate(input_ids, max_new_tokens=n_steps, do_sample=False)
print(tokenizer.decode(output[0]))
Transformers are the most popular toy line in the world,
max_length 指定一个较大的值,以生成更长的文本序列。max_length = 128
input_txt = """In a shocking finding, scientist discovered \
a herd of unicorns living in a remote, previously unexplored \
valley, in the Andes Mountains. Even more surprising to the \
researchers was the fact that the unicorns spoke perfect English.\n\n `"""`
`input_ids` `=` `tokenizer``(``input_txt``,` `return_tensors``=``"pt"``)[``"input_ids"``]``.``to``(``device``)`
`output_greedy` `=` `model``.``generate``(``input_ids``,` `max_length``=``max_length``,`
`do_sample``=``False``)`
`print``(``tokenizer``.``decode``(``output_greedy``[``0``]))`
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
Colorado, Boulder, were conducting a study on the Andean cloud forest, which is
home to the rare species of cloud forest trees.
communicate with each other, and even with humans.
嗯,前几句与 OpenAI 的示例有很大不同,有趣的是涉及到不同的大学被认为是发现者!我们还可以看到贪婪搜索解码的一个主要缺点:它倾向于产生重复的输出序列,在新闻文章中显然是不可取的。这是贪婪搜索算法的一个常见问题,它可能无法给出最佳解决方案;在解码的上下文中,它可能会错过整体概率更高的词序列,只是因为高概率的词恰好是由低概率的词前导的。
幸运的是,我们可以做得更好——让我们来看一种被称为*束搜索解码*的流行方法。
###### 注意
尽管贪婪搜索解码在需要多样性的文本生成任务中很少使用,但它对于生成像算术这样需要确定性和事实正确的输出的短序列是有用的。⁴ 对于这些任务,您可以通过提供格式为`"5 + 8 => 13 \n 7 + 2 => 9 \n 1 + 0 =>"`的几个以换行符分隔的示例来对 GPT-2 进行条件设置。` `#束搜索解码
束搜索不是在每一步解码时选择具有最高概率的标记,而是跟踪前*b*个最有可能的下一个标记,其中*b*被称为*束*或*部分假设*的数量。下一组束是通过考虑现有集合的所有可能的下一个标记扩展,并选择*b*个最有可能的扩展来选择的。这个过程重复进行,直到达到最大长度或 EOS 标记,并且通过根据它们的对数概率对*b*束进行排名来选择最有可能的序列。束搜索的一个示例显示在图 5-4 中。

###### 图 5-4。具有两个束的束搜索
为什么我们要使用对数概率而不是概率本身来对序列进行评分?计算序列的总体概率涉及计算条件概率的*乘积*是一个原因。由于每个条件概率通常是在[ ]范围内的一个小数,取它们的乘积可能导致总体概率很容易下溢。这意味着计算机不能准确地表示计算结果。例如,假设我们有一个包含个标记的序列,并慷慨地假设每个标记的概率为 0.5。这个序列的总体概率是一个极小的数:
```py
0.5 ** 1024
5.562684646268003e-309
import numpy as np
sum([np.log(0.5)] * 1024)
-709.7827128933695
 Transformers 模型返回给定输入标记的下一个标记的非归一化 logits,我们首先需要对 logits 进行归一化,以创建整个词汇表上每个标记的概率分布。然后我们需要选择仅出现在序列中的标记概率。以下函数实现了这些步骤:
Transformers 模型返回给定输入标记的下一个标记的非归一化 logits,我们首先需要对 logits 进行归一化,以创建整个词汇表上每个标记的概率分布。然后我们需要选择仅出现在序列中的标记概率。以下函数实现了这些步骤:import torch.nn.functional as F
def log_probs_from_logits(logits, labels):
logp = F.log_softmax(logits, dim=-1)
logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)
return logp_label
def sequence_logprob(model, labels, input_len=0):
with torch.no_grad():
output = model(labels)
log_probs = log_probs_from_logits(
output.logits[:, :-1, :], labels[:, 1:])
seq_log_prob = torch.sum(log_probs[:, input_len:])
return seq_log_prob.cpu().numpy()
logp = sequence_logprob(model, output_greedy, input_len=len(input_ids[0]))
print(tokenizer.decode(output_greedy[0]))
print(f"\nlog-prob: {logp:.2f}")
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
The researchers, from the University of California, Davis, and the University of
Colorado, Boulder, were conducting a study on the Andean cloud forest, which is
home to the rare species of cloud forest trees.
The researchers were surprised to find that the unicorns were able to
communicate with each other, and even with humans.
The researchers were surprised to find that the unicorns were able
log-prob: -87.43
generate()函数激活束搜索,我们只需要使用num_beams参数指定束的数量。我们选择的束数越多,结果可能就越好;然而,生成过程变得更慢,因为我们为每个束生成并行序列:output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,
do_sample=False)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\nlog-prob: {logp:.2f}")
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
The discovery of the unicorns was made by a team of scientists from the
University of California, Santa Cruz, and the National Geographic Society.
The scientists were conducting a study of the Andes Mountains when they
discovered a herd of unicorns living in a remote, previously unexplored valley,
in the Andes Mountains. Even more surprising to the researchers was the fact
that the unicorns spoke perfect English
log-prob: -55.23
no_repeat_ngram_size参数来施加n-gram 惩罚,该参数跟踪已经看到的n-gram,并且如果生成的下一个标记会产生先前看到的n-gram,则将其概率设置为零:output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,
do_sample=False, no_repeat_ngram_size=2)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\nlog-prob: {logp:.2f}")
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
The discovery was made by a team of scientists from the University of
California, Santa Cruz, and the National Geographic Society.
According to a press release, the scientists were conducting a survey of the
area when they came across the herd. They were surprised to find that they were
able to converse with the animals in English, even though they had never seen a
unicorn in person before. The researchers were
log-prob: -93.12
抽样方法
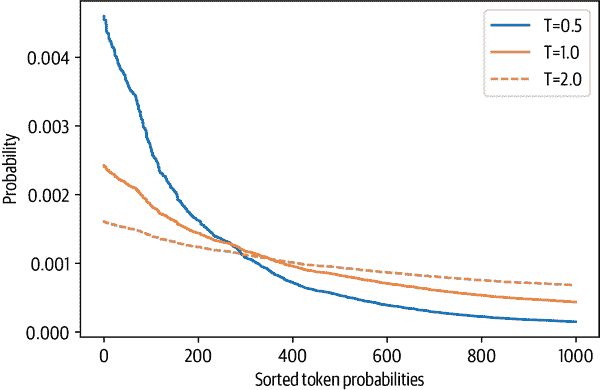
图 5-5. 三个选定温度下随机生成的标记概率分布
generate()函数中设置temperature参数来使用T = 2进行抽样(我们将在下一节解释top_k参数的含义):output_temp = model.generate(input_ids, max_length=max_length, do_sample=True,
temperature=2.0, top_k=0)
print(tokenizer.decode(output_temp[0]))
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
While the station aren protagonist receive Pengala nostalgiates tidbitRegarding
Jenny loclonju AgreementCON irrational �rite Continent seaf A jer Turner
Dorbecue WILL Pumpkin mere Thatvernuildagain YoAniamond disse *
Runewitingkusstemprop});b zo coachinginventorymodules deflation press
Vaticanpres Wrestling chargesThingsctureddong Ty physician PET KimBi66 graz Oz
at aff da temporou MD6 radi iter
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True,
temperature=0.5, top_k=0)
print(tokenizer.decode(output_temp[0]))
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
The scientists were searching for the source of the mysterious sound, which was
making the animals laugh and cry.
The unicorns were living in a remote valley in the Andes mountains
'When we first heard the noise of the animals, we thought it was a lion or a
tiger,' said Luis Guzman, a researcher from the University of Buenos Aires,
Argentina.
'But when
Top-k 和核抽样
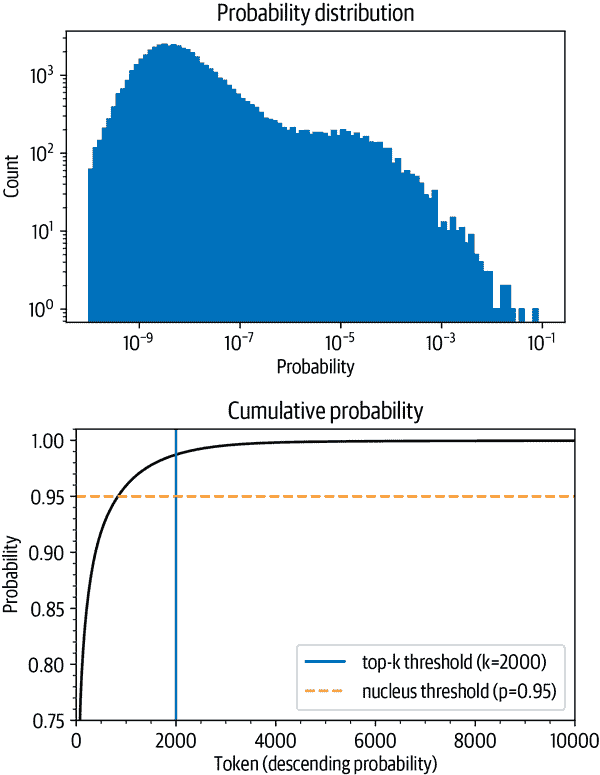
图 5-6. 下一个标记预测的概率分布(上)和下降标记概率的累积分布(下)
generate()函数提供了一个使用top_k参数轻松实现这一点的方法:output_topk = model.generate(input_ids, max_length=max_length, do_sample=True,
top_k=50)
print(tokenizer.decode(output_topk[0]))
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
The wild unicorns roam the Andes Mountains in the region of Cajamarca, on the
border with Argentina (Picture: Alamy/Ecole Nationale Supérieure d'Histoire
Naturelle)
The researchers came across about 50 of the animals in the valley. They had
lived in such a remote and isolated area at that location for nearly a thousand
years that
generate()函数还提供了一个参数来激活 top-p采样。让我们试一试:output_topp = model.generate(input_ids, max_length=max_length, do_sample=True,
top_p=0.90)
print(tokenizer.decode(output_topp[0]))
In a shocking finding, scientist discovered a herd of unicorns living in a
remote, previously unexplored valley, in the Andes Mountains. Even more
surprising to the researchers was the fact that the unicorns spoke perfect
English.
The scientists studied the DNA of the animals and came to the conclusion that
the herd are descendants of a prehistoric herd that lived in Argentina about
50,000 years ago.
According to the scientific analysis, the first humans who migrated to South
America migrated into the Andes Mountains from South Africa and Australia, after
the last ice age had ended.
Since their migration, the animals have been adapting to
top_k=50和top_p=0.9相当于选择具有 90%概率质量的标记,最多从 50 个标记中进行选择的规则。注意
哪种解码方法最好?
结论
model_name = "gpt-xl"替换为model_name = "gpt"来加载一个较小的 GPT-2 版本。第六章:摘要
CNN/DailyMail 数据集
version关键字选择版本。所以让我们深入研究一下:from datasets import load_dataset
dataset = load_dataset("cnn_dailymail", version="3.0.0")
print(f"Features: {dataset['train'].column_names}")
Features: ['article', 'highlights', 'id']
文章,其中包含新闻文章,摘要,其中包含摘要,以及id,用于唯一标识每篇文章。让我们来看一段文章摘录:sample = dataset["train"][1]
print(f"""
Article (excerpt of 500 characters, total length: {len(sample["article"])}):
""")
print(sample["article"][:500])
print(f'\nSummary (length: {len(sample["highlights"])}):')
print(sample["highlights"])
Article (excerpt of 500 characters, total length: 3192):
(CNN) -- Usain Bolt rounded off the world championships Sunday by claiming his
third gold in Moscow as he anchored Jamaica to victory in the men's 4x100m
relay. The fastest man in the world charged clear of United States rival Justin
Gatlin as the Jamaican quartet of Nesta Carter, Kemar Bailey-Cole, Nickel
Ashmeade and Bolt won in 37.36 seconds. The U.S finished second in 37.56 seconds
with Canada taking the bronze after Britain were disqualified for a faulty
handover. The 26-year-old Bolt has n
Summary (length: 180):
Usain Bolt wins third gold of world championship .
Anchors Jamaica to 4x100m relay victory .
Eighth gold at the championships for Bolt .
Jamaica double up in women's 4x100m relay .
文本摘要管道
sample_text = dataset["train"][1]["article"][:2000]
# We'll collect the generated summaries of each model in a dictionary
summaries = {}
import nltk
from nltk.tokenize import sent_tokenize
nltk.download("punkt")
string = "The U.S. are a country. The U.N. is an organization."
sent_tokenize(string)
['The U.S. are a country.', 'The U.N. is an organization.']
警告
摘要基线
def three_sentence_summary(text):
return "\n".join(sent_tokenize(text)[:3])
summaries["baseline"] = three_sentence_summary(sample_text)
GPT-2
pipeline()函数重新创建原始论文的程序开始我们的摘要实验。我们创建一个文本生成管道并加载大型 GPT-2 模型:from transformers import pipeline, set_seed
set_seed(42)
pipe = pipeline("text-generation", model="gpt2-xl")
gpt2_query = sample_text + "\nTL;DR:\n"
pipe_out = pipe(gpt2_query, max_length=512, clean_up_tokenization_spaces=True)
summaries["gpt2"] = "\n".join(
sent_tokenize(pipe_out[0]["generated_text"][len(gpt2_query) :]))
T5
"summarize: ,翻译的格式看起来像"translate English to German: 。如图 6-1 所示,这使得 T5 非常灵活,可以使用单个模型解决许多任务。pipeline()函数加载 T5 进行摘要,该函数还负责以文本-文本格式格式化输入,因此我们不需要在其前面加上"summarize":pipe = pipeline("summarization", model="t5-large")
pipe_out = pipe(sample_text)
summaries["t5"] = "\n".join(sent_tokenize(pipe_out[0]["summary_text"]))

图 6-1。T5 的文本-文本框架图(由 Colin Raffel 提供);除了翻译和摘要之外,还显示了 CoLA(语言可接受性)和 STSB(语义相似性)任务
巴特
facebook/bart-large-ccn检查点,该检查点已经在 CNN/DailyMail 数据集上进行了特定的微调:pipe = pipeline("summarization", model="facebook/bart-large-cnn")
pipe_out = pipe(sample_text)
summaries["bart"] = "\n".join(sent_tokenize(pipe_out[0]["summary_text"]))
飞马座
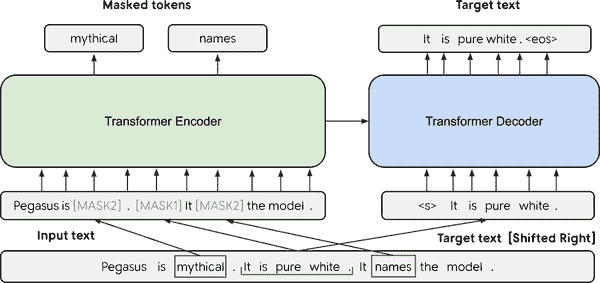
图 6-2。PEGASUS 架构图(由 Jingqing Zhang 等人提供)
sent_tokenize()函数的原因:pipe = pipeline("summarization", model="google/pegasus-cnn_dailymail")
pipe_out = pipe(sample_text)
summaries["pegasus"] = pipe_out[0]["summary_text"].replace(" .比较不同的摘要
print("GROUND TRUTH")
print(dataset["train"][1]["highlights"])
print("")
for model_name in summaries:
print(model_name.upper())
print(summaries[model_name])
print("")
GROUND TRUTH
Usain Bolt wins third gold of world championship .
Anchors Jamaica to 4x100m relay victory .
Eighth gold at the championships for Bolt .
Jamaica double up in women's 4x100m relay .
BASELINE
(CNN) -- Usain Bolt rounded off the world championships Sunday by claiming his
third gold in Moscow as he anchored Jamaica to victory in the men's 4x100m
relay.
The fastest man in the world charged clear of United States rival Justin Gatlin
as the Jamaican quartet of Nesta Carter, Kemar Bailey-Cole, Nickel Ashmeade and
Bolt won in 37.36 seconds.
The U.S finished second in 37.56 seconds with Canada taking the bronze after
Britain were disqualified for a faulty handover.
GPT2
Nesta, the fastest man in the world.
Gatlin, the most successful Olympian ever.
Kemar, a Jamaican legend.
Shelly-Ann, the fastest woman ever.
Bolt, the world's greatest athlete.
The team sport of pole vaulting
T5
usain bolt wins his third gold medal of the world championships in the men's
4x100m relay .
the 26-year-old anchored Jamaica to victory in the event in the Russian capital
.
he has now collected eight gold medals at the championships, equaling the record
.
BART
Usain Bolt wins his third gold of the world championships in Moscow.
Bolt anchors Jamaica to victory in the men's 4x100m relay.
The 26-year-old has now won eight gold medals at world championships.
Jamaica's women also win gold in the relay, beating France in the process.
PEGASUS
Usain Bolt wins third gold of world championships.
Anchors Jamaica to victory in men's 4x100m relay.
Eighth gold at the championships for Bolt.
Jamaica also win women's 4x100m relay .
衡量生成文本的质量
BLEU
 Datasets 还提供了指标!加载指标的方式与加载数据集的方式相同:
Datasets 还提供了指标!加载指标的方式与加载数据集的方式相同:from datasets import load_metric
bleu_metric = load_metric("sacrebleu")
bleu_metric对象是Metric类的一个实例,它像聚合器一样工作:您可以使用add()添加单个实例,也可以通过add_batch()添加整个批次。一旦添加了需要评估的所有样本,然后调用compute(),指标就会被计算。这将返回一个包含多个值的字典,例如每个n-gram 的精度,长度惩罚,以及最终的 BLEU 分数。让我们看一下之前的例子:import pandas as pd
import numpy as np
bleu_metric.add(
prediction="the the the the the the", reference=["the cat is on the mat"])
results = bleu_metric.compute(smooth_method="floor", smooth_value=0)
results["precisions"] = [np.round(p, 2) for p in results["precisions"]]
pd.DataFrame.from_dict(results, orient="index", columns=["Value"])
值
分数
0.0
计数
[2, 0, 0, 0]
总数
[6, 5, 4, 3]
精度
[33.33, 0.0, 0.0, 0.0]
bp
1.0
系统长度
6
参考长度
6
注
reference作为列表传递的原因。为了使n-gram 中的零计数的指标更加平滑,BLEU 集成了修改精度计算的方法。一种方法是向分子添加一个常数。这样,缺少的n-gram 不会导致分数自动变为零。为了解释这些值,我们通过设置smooth_value=0将其关闭。bleu_metric.add(
prediction="the cat is on mat", reference=["the cat is on the mat"])
results = bleu_metric.compute(smooth_method="floor", smooth_value=0)
results["precisions"] = [np.round(p, 2) for p in results["precisions"]]
pd.DataFrame.from_dict(results, orient="index", columns=["Value"])
值
分数
57.893007
计数
[5, 3, 2, 1]
总数
[5, 4, 3, 2]
精度
[100.0, 75.0, 66.67, 50.0]
bp
0.818731
系统长度
5
参考长度
6
["the", "cat", "is", "on"]和["cat", "is", "on", "mat"],后者不匹配,因此精度为 0.5。ROUGE
 数据集实现中,计算了两种 ROUGE 的变体:一种计算每个句子的得分并对摘要进行平均(ROUGE-L),另一种直接在整个摘要上计算(ROUGE-Lsum)。
数据集实现中,计算了两种 ROUGE 的变体:一种计算每个句子的得分并对摘要进行平均(ROUGE-L),另一种直接在整个摘要上计算(ROUGE-Lsum)。rouge_metric = load_metric("rouge")
reference = dataset["train"][1]["highlights"]
records = []
rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
for model_name in summaries:
rouge_metric.add(prediction=summaries[model_name], reference=reference)
score = rouge_metric.compute()
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
records.append(rouge_dict)
pd.DataFrame.from_records(records, index=summaries.keys())
rouge1
rouge2
rougeL
rougeLsum
—
—
—
—
—
基线
0.303571
0.090909
0.214286
0.232143
gpt2
0.187500
0.000000
0.125000
0.187500
t5
0.486486
0.222222
0.378378
0.486486
bart
0.582278
0.207792
0.455696
0.506329
pegasus
0.866667
0.655172
0.800000
0.833333
注意
 数据集库中,ROUGE 度量标准还计算置信区间(默认情况下为第 5 和第 95 百分位数)。平均值存储在属性
数据集库中,ROUGE 度量标准还计算置信区间(默认情况下为第 5 和第 95 百分位数)。平均值存储在属性mid中,区间可以通过low和high检索。评估 PEGASUS 在 CNN/DailyMail 数据集上
def evaluate_summaries_baseline(dataset, metric,
column_text="article",
column_summary="highlights"):
summaries = [three_sentence_summary(text) for text in dataset[column_text]]
metric.add_batch(predictions=summaries,
references=dataset[column_summary])
score = metric.compute()
return score
test_sampled = dataset["test"].shuffle(seed=42).select(range(1000))
score = evaluate_summaries_baseline(test_sampled, rouge_metric)
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame.from_dict(rouge_dict, orient="index", columns=["baseline"]).T
rouge1
rouge2
rougeL
rougeLsum
基线
0.396061
0.173995
0.245815
0.361158
from tqdm import tqdm
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
def chunks(list_of_elements, batch_size):
"""Yield successive batch-sized chunks from list_of_elements."""
for i in range(0, len(list_of_elements), batch_size):
yield list_of_elements[i : i + batch_size]
def evaluate_summaries_pegasus(dataset, metric, model, tokenizer,
batch_size=16, device=device,
column_text="article",
column_summary="highlights"):
article_batches = list(chunks(dataset[column_text], batch_size))
target_batches = list(chunks(dataset[column_summary], batch_size))
for article_batch, target_batch in tqdm(
zip(article_batches, target_batches), total=len(article_batches)):
inputs = tokenizer(article_batch, max_length=1024, truncation=True,
padding="max_length", return_tensors="pt")
summaries = model.generate(input_ids=inputs["input_ids"].to(device),
attention_mask=inputs["attention_mask"].to(device),
length_penalty=0.8, num_beams=8, max_length=128)
decoded_summaries = [tokenizer.decode(s, skip_special_tokens=True,
clean_up_tokenization_spaces=True)
for s in summaries]
decoded_summaries = [d.replace("generate()函数中,使用波束搜索生成摘要。我们使用与论文中提出的相同的生成参数。长度惩罚的新参数确保模型不会生成太长的序列。最后,我们解码生成的文本,替换AutoModelForSeq2SeqLM类加载模型,用于 seq2seq 生成任务,并对其进行评估:from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model_ckpt = "google/pegasus-cnn_dailymail"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModelForSeq2SeqLM.from_pretrained(model_ckpt).to(device)
score = evaluate_summaries_pegasus(test_sampled, rouge_metric,
model, tokenizer, batch_size=8)
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame(rouge_dict, index=["pegasus"])
rouge1
rouge2
rougeL
rougeLsum
pegasus
0.434381
0.210883
0.307195
0.373231
训练摘要模型
dataset_samsum = load_dataset("samsum")
split_lengths = [len(dataset_samsum[split])for split in dataset_samsum]
print(f"Split lengths: {split_lengths}")
print(f"Features: {dataset_samsum['train'].column_names}")
print("\nDialogue:")
print(dataset_samsum["test"][0]["dialogue"])
print("\nSummary:")
print(dataset_samsum["test"][0]["summary"])
Split lengths: [14732, 819, 818]
Features: ['id', 'dialogue', 'summary']
Dialogue:
Hannah: Hey, do you have Betty's number?
Amanda: Lemme check
Hannah: <file_gif>
Amanda: Sorry, can't find it.
Amanda: Ask Larry
Amanda: He called her last time we were at the park together
Hannah: I don't know him well
Hannah: <file_gif>
Amanda: Don't be shy, he's very nice
Hannah: If you say so..
Hannah: I'd rather you texted him
Amanda: Just text him
Hannah: Urgh.. Alright
Hannah: Bye
Amanda: Bye bye
Summary:
Hannah needs Betty's number but Amanda doesn't have it. She needs to contact
Larry.
dialogue字段包含完整文本,summary包含总结的对话。CNN/DailyMail 数据集上进行了微调的模型能够处理吗?让我们找出来!在 SAMSum 上评估 PEGASUS
pipe_out = pipe(dataset_samsum["test"][0]["dialogue"])
print("Summary:")
print(pipe_out[0]["summary_text"].replace(" .Summary:
Amanda: Ask Larry Amanda: He called her last time we were at the park together.
Hannah: I'd rather you texted him.
Amanda: Just text him .
score = evaluate_summaries_pegasus(dataset_samsum["test"], rouge_metric, model,
tokenizer, column_text="dialogue",
column_summary="summary", batch_size=8)
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame(rouge_dict, index=["pegasus"])
rouge1
rouge2
rougeL
rougeLsum
pegasus
0.296168
0.087803
0.229604
0.229514
PEGASUS 微调
d_len = [len(tokenizer.encode(s)) for s in dataset_samsum["train"]["dialogue"]]
s_len = [len(tokenizer.encode(s)) for s in dataset_samsum["train"]["summary"]]
fig, axes = plt.subplots(1, 2, figsize=(10, 3.5), sharey=True)
axes[0].hist(d_len, bins=20, color="C0", edgecolor="C0")
axes[0].set_title("Dialogue Token Length")
axes[0].set_xlabel("Length")
axes[0].set_ylabel("Count")
axes[1].hist(s_len, bins=20, color="C0", edgecolor="C0")
axes[1].set_title("Summary Token Length")
axes[1].set_xlabel("Length")
plt.tight_layout()
plt.show()

Trainer的数据收集器时,让我们记住这些观察结果。首先,我们需要对数据集进行标记化。目前,我们将对话和摘要的最大长度分别设置为 1024 和 128:def convert_examples_to_features(example_batch):
input_encodings = tokenizer(example_batch["dialogue"], max_length=1024,
truncation=True)
with tokenizer.as_target_tokenizer():
target_encodings = tokenizer(example_batch["summary"], max_length=128,
truncation=True)
return {"input_ids": input_encodings["input_ids"],
"attention_mask": input_encodings["attention_mask"],
"labels": target_encodings["input_ids"]}
dataset_samsum_pt = dataset_samsum.map(convert_examples_to_features,
batched=True)
columns = ["input_ids", "labels", "attention_mask"]
dataset_samsum_pt.set_format(type="torch", columns=columns)
tokenizer.as_target_tokenizer()上下文。一些模型需要在解码器输入中使用特殊标记,因此区分编码器和解码器输入的标记化非常重要。在with语句(称为上下文管理器)中,标记器知道它正在为解码器进行标记化,并可以相应地处理序列。Trainer中在批处理通过模型之前调用。在大多数情况下,我们可以使用默认的收集器,它会从批处理中收集所有张量并简单地堆叠它们。对于摘要任务,我们不仅需要堆叠输入,还需要在解码器端准备目标。PEGASUS 是一个编码器-解码器变换器,因此具有经典的 seq2seq 架构。在 seq2seq 设置中,一个常见的方法是在解码器中应用“教师强制”。使用这种策略,解码器接收输入标记(就像在仅解码器模型(如 GPT-2)中一样),其中包括标签向后移动一个位置的内容,以及编码器输出;因此,在进行下一个标记的预测时,解码器会得到向后移动一个位置的地面真相作为输入,如下表所示:
解码器输入
标签
步骤
—
—
—
1
[PAD]
Transformers
2
[PAD, Transformers]
are
3
[PAD, Transformers, are]
awesome
4
[PAD, Transformers, are, awesome]
for
5
[PAD, Transformers, are, awesome, for]
text
6
[PAD, Transformers, are, awesome, for, text]
summarization
DataCollatorForSeq2Seq会帮助我们处理所有这些步骤:from transformers import DataCollatorForSeq2Seq
seq2seq_data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
TrainingArguments:from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir='pegasus-samsum', num_train_epochs=1, warmup_steps=500,
per_device_train_batch_size=1, per_device_eval_batch_size=1,
weight_decay=0.01, logging_steps=10, push_to_hub=True,
evaluation_strategy='steps', eval_steps=500, save_steps=1e6,
gradient_accumulation_steps=16)
gradient_accumulation_steps。由于模型非常庞大,我们不得不将批处理大小设置为 1。然而,太小的批处理大小可能会影响收敛。为了解决这个问题,我们可以使用一种称为梯度累积的巧妙技术。顾名思义,我们不是一次计算整个批次的梯度,而是制作更小的批次并聚合梯度。当我们聚合了足够的梯度时,我们运行优化步骤。当然,这比一次性完成要慢一些,但它节省了大量的 GPU 内存。from huggingface_hub import notebook_login
notebook_login()
trainer = Trainer(model=model, args=training_args,
tokenizer=tokenizer, data_collator=seq2seq_data_collator,
train_dataset=dataset_samsum_pt["train"],
eval_dataset=dataset_samsum_pt["validation"])
trainer.train()
score = evaluate_summaries_pegasus(
dataset_samsum["test"], rouge_metric, trainer.model, tokenizer,
batch_size=2, column_text="dialogue", column_summary="summary")
rouge_dict = dict((rn, score[rn].mid.fmeasure) for rn in rouge_names)
pd.DataFrame(rouge_dict, index=[f"pegasus"])
rouge1
rouge2
rougeL
rougeLsum
pegasus
0.427614
0.200571
0.340648
0.340738
trainer.push_to_hub("Training complete!")
提示
Seq2SeqTrainingArguments的TrainingArguments的扩展,并指定predict_with_generate=True。将其传递给专用的Trainer称为Seq2SeqTrainer,然后使用generate()函数而不是模型的前向传递来创建评估预测。试试看!生成对话摘要
gen_kwargs = {"length_penalty": 0.8, "num_beams":8, "max_length": 128}
sample_text = dataset_samsum["test"][0]["dialogue"]
reference = dataset_samsum["test"][0]["summary"]
pipe = pipeline("summarization", model="transformersbook/pegasus-samsum")
print("Dialogue:")
print(sample_text)
print("\nReference Summary:")
print(reference)
print("\nModel Summary:")
print(pipe(sample_text, **gen_kwargs)[0]["summary_text"])
Dialogue:
Hannah: Hey, do you have Betty's number?
Amanda: Lemme check
Hannah: <file_gif>
Amanda: Sorry, can't find it.
Amanda: Ask Larry
Amanda: He called her last time we were at the park together
Hannah: I don't know him well
Hannah: <file_gif>
Amanda: Don't be shy, he's very nice
Hannah: If you say so..
Hannah: I'd rather you texted him
Amanda: Just text him
Hannah: Urgh.. Alright
Hannah: Bye
Amanda: Bye bye
Reference Summary:
Hannah needs Betty's number but Amanda doesn't have it. She needs to contact
Larry.
Model Summary:
Amanda can't find Betty's number. Larry called Betty last time they were at the
park together. Hannah wants Amanda to text Larry instead of calling Betty.
custom_dialogue = """\
Thom: Hi guys, have you heard of transformers?
Lewis: Yes, I used them recently!
Leandro: Indeed, there is a great library by Hugging Face.
Thom: I know, I helped build it ;)
Lewis: Cool, maybe we should write a book about it. What do you think?
Leandro: Great idea, how hard can it be?!
Thom: I am in!
Lewis: Awesome, let's do it together!
"""
print(pipe(custom_dialogue, **gen_kwargs)[0]["summary_text"])
Thom, Lewis and Leandro are going to write a book about transformers. Thom
helped build a library by Hugging Face. They are going to do it together.
结论
第七章:问答
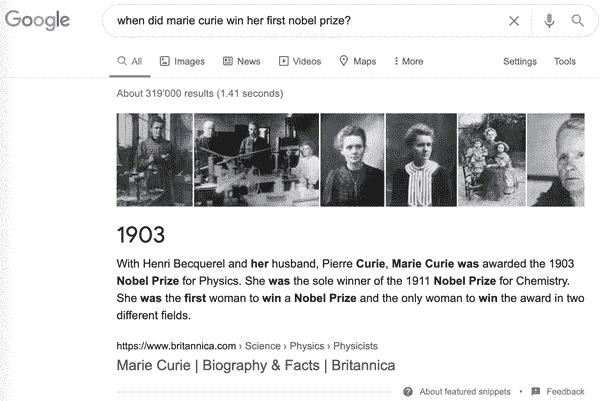
图 7-1 谷歌搜索查询和相应的答案片段
注
构建基于评论的问答系统
数据集

图 7-2. 有关产品的问题和相应的评论(答案范围已划线)
注意
get_dataset_config_names()函数来找出哪些子集是可用的:from datasets import get_dataset_config_names
domains = get_dataset_config_names("subjqa")
domains
['books', 'electronics', 'grocery', 'movies', 'restaurants', 'tripadvisor']
electronics子集,我们只需要将该值传递给load_dataset()函数的name参数:from datasets import load_dataset
subjqa = load_dataset("subjqa", name="electronics")
answers列中的一行:print(subjqa["train"]["answers"][1])
{'text': ['Bass is weak as expected', 'Bass is weak as expected, even with EQ
adjusted up'], 'answer_start': [1302, 1302], 'answer_subj_level': [1, 1],
'ans_subj_score': [0.5083333253860474, 0.5083333253860474], 'is_ans_subjective':
[True, True]}
text字段中,而起始字符索引则在answer_start中提供。为了更轻松地探索数据集,我们将使用flatten()方法展平这些嵌套列,并将每个拆分转换为 Pandas 的DataFrame,如下所示:import pandas as pd
dfs = {split: dset.to_pandas() for split, dset in subjqa.flatten().items()}
for split, df in dfs.items():
print(f"Number of questions in {split}: {df['id'].nunique()}")
Number of questions in train: 1295
Number of questions in test: 358
Number of questions in validation: 255
列名
描述
title与每个产品相关联的亚马逊标准识别号(ASIN)
question问题
answers.answer_text标注者标记的评论文本范围
answers.answer_start答案范围的起始字符索引
context客户评论
sample()方法选择一个随机样本:qa_cols = ["title", "question", "answers.text",
"answers.answer_start", "context"]
sample_df = dfs["train"][qa_cols].sample(2, random_state=7)
sample_df
标题
问题
答案文本
答案起始
上下文
B005DKZTMG
键盘轻便吗?
[这个键盘很紧凑]
[215]
我真的很喜欢这个键盘。我给它 4 颗星,因为它没有大写锁定键,所以我永远不知道我的大写是否打开。但是就价格而言,它确实足够作为一个无线键盘。我手很大,这个键盘很紧凑,但我没有抱怨。
B00AAIPT76
电池如何?
[]
[]
我在购买了第一个备用 gopro 电池后发现它无法保持充电。我对这种产品有非常现实的期望,对于充电时间和电池寿命的惊人故事我持怀疑态度,但我确实希望电池至少能保持几周的充电,并且充电器能像充电器一样工作。在这方面我并不失望。我是一名漂流者,发现 gopro 电池很快就用完了,所以这次购买解决了这个问题。电池保持了充电,在短途旅行上,额外的两块电池足够使用,在长途旅行上,我可以使用我的朋友的 JOOS Orange 来给它们充电。我刚刚购买了一个 newtrent xtreme powerpak,期望能用它给这些电池充电,所以我不会再用完电了。
answers.text条目表示“无法回答”的问题,其答案无法在评论中找到。最后,我们可以使用答案跨度的起始索引和长度来切出对应于答案的评论文本跨度:start_idx = sample_df["answers.answer_start"].iloc[0][0]
end_idx = start_idx + len(sample_df["answers.text"].iloc[0][0])
sample_df["context"].iloc[0][start_idx:end_idx]
'this keyboard is compact'
counts = {}
question_types = ["What", "How", "Is", "Does", "Do", "Was", "Where", "Why"]
for q in question_types:
counts[q] = dfs["train"]["question"].str.startswith(q).value_counts()[True]
pd.Series(counts).sort_values().plot.barh()
plt.title("Frequency of Question Types")
plt.show()

for question_type in ["How", "What", "Is"]:
for question in (
dfs["train"][dfs["train"].question.str.startswith(question_type)]
.sample(n=3, random_state=42)['question']):
print(question)
How is the camera?
How do you like the control?
How fast is the charger?
What is direction?
What is the quality of the construction of the bag?
What is your impression of the product?
Is this how zoom works?
Is sound clear?
Is it a wireless keyboard?
从文本中提取答案
跨度分类

图 7-4。QA 任务的跨度分类头部

图 7-5。Hugging Face Hub 上一些抽取式 QA 模型的选择
Transformer
描述
参数数量
SQuAD 2.0 上的F分数
MiniLM
保留了 99%的性能,同时运行速度是 BERT-base 的两倍
66M
79.5
RoBERTa-base
RoBERTa 模型的性能比 BERT 模型更好,并且可以在大多数 QA 数据集上使用单个 GPU 进行微调
125M
83.0
ALBERT-XXL
在 SQuAD 2.0 上表现出色,但计算密集且难以部署
235M
88.1
XLM-RoBERTa-large
用于 100 种语言的多语言模型,具有强大的零热门性能
570M
83.8
QA 的文本标记化
from transformers import AutoTokenizer
model_ckpt = "deepset/minilm-uncased-squad2"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
question = "How much music can this hold?"
context = """An MP3 is about 1 MB/minute, so about 6000 hours depending on \
file size."""
inputs = tokenizer(question, context, return_tensors="pt")
Tensor对象,因为我们需要它们来运行模型的前向传递。如果我们将标记化的输入视为表格:
input_ids
101
2129
2172
2189
2064
2023
…
5834
2006
5371
2946
1012
102
token_type_ids
0
0
0
0
0
0
…
1
1
1
1
1
1
attention_mask
1
1
1
1
1
1
…
1
1
1
1
1
1
input_ids和attention_mask张量,而token_type_ids张量指示了输入的哪个部分对应于问题和上下文(0 表示问题标记,1 表示上下文标记)。⁹input_ids张量:print(tokenizer.decode(inputs["input_ids"][0]))
[CLS] how much music can this hold? [SEP] an mp3 is about 1 mb / minute, so
about 6000 hours depending on file size. [SEP]
[CLS] question tokens [SEP] context tokens [SEP]
[SEP]标记的位置由token_type_ids确定。现在我们的文本已经被标记化,我们只需要用 QA 头实例化模型并通过前向传递运行输入:import torch
from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained(model_ckpt)
with torch.no_grad():
outputs = model(**inputs)
print(outputs)
QuestionAnsweringModelOutput(loss=None, start_logits=tensor([[-0.9862, -4.7750,
-5.4025, -5.2378, -5.2863, -5.5117, -4.9819, -6.1880,
-0.9862, 0.2596, -0.2144, -1.7136, 3.7806, 4.8561, -1.0546, -3.9097,
-1.7374, -4.5944, -1.4278, 3.9949, 5.0390, -0.2018, -3.0193, -4.8549,
-2.3107, -3.5110, -3.5713, -0.9862]]), end_logits=tensor([[-0.9623,
-5.4733, -5.0326, -5.1639, -5.4278, -5.5151, -5.1749, -4.6233,
-0.9623, -3.7855, -0.8715, -3.7745, -3.0161, -1.1780, 0.1758, -2.7365,
4.8934, 0.3046, -3.1761, -3.2762, 0.8937, 5.6606, -0.3623, -4.9554,
-3.2531, -0.0914, 1.6211, -0.9623]]), hidden_states=None,
attentions=None)
QuestionAnsweringModelOutput对象作为 QA 头的输出。正如图 7-4 中所示,QA 头对应于一个线性层,它获取来自编码器的隐藏状态并计算开始和结束跨度的 logits。¹⁰ 这意味着我们将 QA 视为一种令牌分类,类似于我们在第四章中遇到的命名实体识别。要将输出转换为答案跨度,我们首先需要获取开始和结束令牌的 logits:start_logits = outputs.start_logits
end_logits = outputs.end_logits
print(f"Input IDs shape: {inputs.input_ids.size()}")
print(f"Start logits shape: {start_logits.size()}")
print(f"End logits shape: {end_logits.size()}")
Input IDs shape: torch.Size([1, 28])
Start logits shape: torch.Size([1, 28])
End logits shape: torch.Size([1, 28])

图 7-6。预测的起始和结束标记的 logits;得分最高的标记以橙色标出
import torch
start_idx = torch.argmax(start_logits)
end_idx = torch.argmax(end_logits) + 1
answer_span = inputs["input_ids"][0][start_idx:end_idx]
answer = tokenizer.decode(answer_span)
print(f"Question: {question}")
print(f"Answer: {answer}")
Question: How much music can this hold?
Answer: 6000 hours
 Transformers 中,所有这些预处理和后处理步骤都方便地包装在一个专用的管道中。我们可以通过传递我们的分词器和微调模型来实例化管道,如下所示:
Transformers 中,所有这些预处理和后处理步骤都方便地包装在一个专用的管道中。我们可以通过传递我们的分词器和微调模型来实例化管道,如下所示:from transformers import pipeline
pipe = pipeline("question-answering", model=model, tokenizer=tokenizer)
pipe(question=question, context=context, topk=3)
[{'score': 0.26516005396842957,
'start': 38,
'end': 48,
'answer': '6000 hours'},
{'score': 0.2208300083875656,
'start': 16,
'end': 48,
'answer': '1 MB/minute, so about 6000 hours'},
{'score': 0.10253632068634033,
'start': 16,
'end': 27,
'answer': '1 MB/minute'}]
score字段中返回模型的概率估计(通过对 logits 进行 softmax 获得)。当我们想要在单个上下文中比较多个答案时,这是很方便的。我们还表明,通过指定topk参数,我们可以让模型预测多个答案。有时,可能会有问题没有答案的情况,比如 SubjQA 中空的answers.answer_start示例。在这些情况下,模型将为[CLS]标记分配高的起始和结束分数,管道将这个输出映射为空字符串:pipe(question="Why is there no data?", context=context,
handle_impossible_answer=True)
{'score': 0.9068416357040405, 'start': 0, 'end': 0, 'answer': ''}
注意
处理长段落

图 7-7。SubjQA 训练集中每个问题-上下文对的标记分布
[CLS]标记的嵌入中包含足够的信息来生成准确的预测。然而,对于 QA 来说,这种策略是有问题的,因为问题的答案可能位于上下文的末尾,因此会被截断。如图 7-8 所示,处理这个问题的标准方法是在输入上应用滑动窗口,其中每个窗口包含适合模型上下文的标记段。
图 7-8。滑动窗口如何为长文档创建多个问题-上下文对——第一个条形图对应问题,而第二个条形图是每个窗口中捕获的上下文
 Transformers 中,我们可以在分词器中设置
Transformers 中,我们可以在分词器中设置return_overflowing_tokens=True来启用滑动窗口。滑动窗口的大小由max_seq_length参数控制,步幅的大小由doc_stride控制。让我们从训练集中抓取第一个例子,并定义一个小窗口来说明这是如何工作的:example = dfs["train"].iloc[0][["question", "context"]]
tokenized_example = tokenizer(example["question"], example["context"],
return_overflowing_tokens=True, max_length=100,
stride=25)
input_ids列表,每个窗口一个。让我们检查每个窗口中的标记数:for idx, window in enumerate(tokenized_example["input_ids"]):
print(f"Window #{idx} has {len(window)} tokens")
Window #0 has 100 tokens
Window #1 has 88 tokens
for window in tokenized_example["input_ids"]:
print(f"{tokenizer.decode(window)} \n")
[CLS] how is the bass? [SEP] i have had koss headphones in the past, pro 4aa and
qz - 99\. the koss portapro is portable and has great bass response. the work
great with my android phone and can be " rolled up " to be carried in my
motorcycle jacket or computer bag without getting crunched. they are very light
and don't feel heavy or bear down on your ears even after listening to music
with them on all day. the sound is [SEP]
[CLS] how is the bass? [SEP] and don't feel heavy or bear down on your ears even
after listening to music with them on all day. the sound is night and day better
than any ear - bud could be and are almost as good as the pro 4aa. they are "
open air " headphones so you cannot match the bass to the sealed types, but it
comes close. for $ 32, you cannot go wrong. [SEP]
使用 Haystack 构建 QA 管道

图 7-9。现代 QA 系统的检索器-阅读器架构
 Transformers 紧密集成。
Transformers 紧密集成。警告
初始化文档存储
内存
Elasticsearch
FAISS
Milvus
TF-IDF
是
是
否
否
BM25
否
是
否
否
嵌入
是
是
是
是
DPR
是
是
是
是
ElasticsearchDocumentStore。Elasticsearch 是一种能够处理各种数据类型的搜索引擎,包括文本、数字、地理空间、结构化和非结构化数据。它存储大量数据并能够快速进行全文搜索过滤,因此特别适用于开发问答系统。它还具有成为基础设施分析行业标准的优势,因此您的公司很有可能已经有一个集群可以使用。wget获取 Linux 的最新版本,并使用tar shell 命令解压缩它:url = """https://artifacts.elastic.co/downloads/elasticsearch/\
elasticsearch-7.9.2-linux-x86_64.tar.gz"""
!wget -nc -q {url}
!tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
Popen()函数来生成一个新的进程。在此过程中,让我们还使用chown shell 命令在后台运行子进程:import os
from subprocess import Popen, PIPE, STDOUT
# Run Elasticsearch as a background process
!chown -R daemon:daemon elasticsearch-7.9.2
es_server = Popen(args=['elasticsearch-7.9.2/bin/elasticsearch'],
stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1))
# Wait until Elasticsearch has started
!sleep 30
Popen()函数中,args指定我们希望执行的程序,而stdout=PIPE创建一个新的管道用于标准输出,stderr=STDOUT收集相同管道中的错误。preexec_fn参数指定我们希望使用的子进程的 ID。默认情况下,Elasticsearch 在本地端口 9200 上运行,因此我们可以通过向localhost发送 HTTP 请求来测试连接:!curl -X GET "localhost:9200/?pretty"
{
"name" : "96938eee37cd",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "ABGDdvbbRWmMb9Umz79HbA",
"version" : {
"number" : "7.9.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "d34da0ea4a966c4e49417f2da2f244e3e97b4e6e",
"build_date" : "2020-09-23T00:45:33.626720Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
from haystack.document_store.elasticsearch import ElasticsearchDocumentStore
# Return the document embedding for later use with dense retriever
document_store = ElasticsearchDocumentStore(return_embedding=True)
ElasticsearchDocumentStore在 Elasticsearch 上创建两个索引:一个称为document用于(你猜对了)存储文档,另一个称为label用于存储注释的答案跨度。现在,我们将使用 SubjQA 评论填充document索引,Haystack 的文档存储期望一个带有text和meta键的字典列表,如下所示:{
"text": "meta中的字段可用于在检索期间应用过滤器。为了我们的目的,我们将包括 SubjQA 的item_id和q_review_id列,以便我们可以按产品和问题 ID 进行过滤,以及相应的训练拆分。然后,我们可以循环遍历每个DataFrame中的示例,并使用write_documents()方法将它们添加到索引中,如下所示:for split, df in dfs.items():
# Exclude duplicate reviews
docs = [{"text": row["context"],
"meta":{"item_id": row["title"], "question_id": row["id"],
"split": split}}
for _,row in df.drop_duplicates(subset="context").iterrows()]
document_store.write_documents(docs, index="document")
print(f"Loaded {document_store.get_document_count()} documents")
Loaded 1615 documents
初始化检索器
ElasticsearchRetriever中,因此让我们通过指定我们希望搜索的文档存储来初始化这个类:from haystack.retriever.sparse import ElasticsearchRetriever
es_retriever = ElasticsearchRetriever(document_store=document_store)
item_id的值附加到www.amazon.com/dp/ URL 来解密它们。以下项目 ID 对应于亚马逊的 Fire 平板电脑之一,所以让我们使用检索器的retrieve()方法来询问它是否适合阅读:item_id = "B0074BW614"
query = "Is it good for reading?"
retrieved_docs = es_retriever.retrieve(
query=query, top_k=3, filters={"item_id":[item_id], "split":["train"]})
top_k参数返回多少个文档,并在我们的文档的meta字段中包含的item_id和split键上应用了过滤器。retrieved_docs的每个元素都是一个 Haystack Document对象,用于表示文档并包括检索器的查询分数以及其他元数据。让我们看一下其中一个检索到的文档:print(retrieved_docs[0])
{'text': 'This is a gift to myself. I have been a kindle user for 4 years and
this is my third one. I never thought I would want a fire for I mainly use it
for book reading. I decided to try the fire for when I travel I take my laptop,
my phone and my iPod classic. I love my iPod but watching movies on the plane
with it can be challenging because it is so small. Laptops battery life is not
as good as the Kindle. So the Fire combines for me what I needed all three to
do. So far so good.', 'score': 6.243799, 'probability': 0.6857824513476455,
'question': None, 'meta': {'item_id': 'B0074BW614', 'question_id':
'868e311275e26dbafe5af70774a300f3', 'split': 'train'}, 'embedding': None, 'id':
'252e83e25d52df7311d597dc89eef9f6'}
score(较大的分数意味着更好的匹配)。在幕后,Elasticsearch 依赖于Lucene进行索引和搜索,因此默认情况下它使用 Lucene 的practical scoring function。您可以在Elasticsearch 文档中找到得分函数背后的细节,但简而言之,它首先通过应用布尔测试(文档是否与查询匹配)来过滤候选文档,然后应用基于将文档和查询表示为向量的相似度度量。初始化读取器
FARMReader Transformers 训练的模型兼容,并且可以直接从 Hugging Face Hub 加载模型。
Transformers 训练的模型兼容,并且可以直接从 Hugging Face Hub 加载模型。TransformersReader Transformers 的 QA 流水线。适用于仅运行推理。
Transformers 的 QA 流水线。适用于仅运行推理。
 Transformers 中,QA 管道使用 softmax 在每个段落中对开始和结束的 logits 进行归一化。这意味着只有在从同一段落中提取的答案之间才有意义比较得分,其中概率总和为 1。例如,来自一个段落的答案得分为 0.9 并不一定比另一个段落中的得分为 0.8 好。在 FARM 中,logits 没有被归一化,因此可以更容易地比较跨段落的答案。
Transformers 中,QA 管道使用 softmax 在每个段落中对开始和结束的 logits 进行归一化。这意味着只有在从同一段落中提取的答案之间才有意义比较得分,其中概率总和为 1。例如,来自一个段落的答案得分为 0.9 并不一定比另一个段落中的得分为 0.8 好。在 FARM 中,logits 没有被归一化,因此可以更容易地比较跨段落的答案。TransformersReader有时会预测相同的答案两次,但得分不同。如果答案跨越两个重叠的窗口,这可能会发生。在 FARM 中,这些重复项会被删除。FARMReader。与 Transformers 一样,要加载模型,我们只需要在 Hugging Face Hub 上指定 MiniLM 检查点以及一些特定于 QA 的参数:
Transformers 一样,要加载模型,我们只需要在 Hugging Face Hub 上指定 MiniLM 检查点以及一些特定于 QA 的参数:from haystack.reader.farm import FARMReader
model_ckpt = "deepset/minilm-uncased-squad2"
max_seq_length, doc_stride = 384, 128
reader = FARMReader(model_name_or_path=model_ckpt, progress_bar=False,
max_seq_len=max_seq_length, doc_stride=doc_stride,
return_no_answer=True)
注意
 Transformers 中微调阅读理解模型,然后加载到
Transformers 中微调阅读理解模型,然后加载到TransformersReader中进行推理。有关如何进行微调的详细信息,请参阅库的文档中的问答教程。FARMReader中,滑动窗口的行为由我们在标记器中看到的max_seq_length和doc_stride参数控制。这里我们使用了 MiniLM 论文中的值。现在让我们在之前的简单示例上测试一下读取器:print(reader.predict_on_texts(question=question, texts=[context], top_k=1))
{'query': 'How much music can this hold?', 'no_ans_gap': 12.648084878921509,
'answers': [{'answer': '6000 hours', 'score': 10.69961929321289, 'probability':
0.3988136053085327, 'context': 'An MP3 is about 1 MB/minute, so about 6000 hours
depending on file size.', 'offset_start': 38, 'offset_end': 48,
'offset_start_in_doc': 38, 'offset_end_in_doc': 48, 'document_id':
'e344757014e804eff50faa3ecf1c9c75'}]}
将所有内容放在一起
Pipeline抽象,允许我们将检索器、读取器和其他组件组合成一个图,可以根据每个用例轻松定制。还有预定义的管道类似于 Transformers 中的管道,但专门为 QA 系统设计。在我们的案例中,我们对提取答案感兴趣,所以我们将使用
Transformers 中的管道,但专门为 QA 系统设计。在我们的案例中,我们对提取答案感兴趣,所以我们将使用ExtractiveQAPipeline,它以单个检索器-读取器对作为其参数:from haystack.pipeline import ExtractiveQAPipeline
pipe = ExtractiveQAPipeline(reader, es_retriever)
Pipeline都有一个run()方法,指定查询流程应如何执行。对于ExtractiveQAPipeline,我们只需要传递query,用top_k_retriever指定要检索的文档数量,用top_k_reader指定要从这些文档中提取的答案数量。在我们的案例中,我们还需要使用filters参数指定对项目 ID 的过滤器,就像我们之前对检索器所做的那样。让我们再次运行一个关于亚马逊 Fire 平板电脑的简单示例,但这次返回提取的答案:n_answers = 3
preds = pipe.run(query=query, top_k_retriever=3, top_k_reader=n_answers,
filters={"item_id": [item_id], "split":["train"]})
print(f"Question: {preds['query']} \n")
for idx in range(n_answers):
print(f"Answer {idx+1}: {preds['answers'][idx]['answer']}")
print(f"Review snippet: ...{preds['answers'][idx]['context']}...")
print("\n\n")
Question: Is it good for reading?
Answer 1: I mainly use it for book reading
Review snippet: ... is my third one. I never thought I would want a fire for I
mainly use it for book reading. I decided to try the fire for when I travel I
take my la...
Answer 2: the larger screen compared to the Kindle makes for easier reading
Review snippet: ...ght enough that I can hold it to read, but the larger screen
compared to the Kindle makes for easier reading. I love the color, something I
never thou...
Answer 3: it is great for reading books when no light is available
Review snippet: ...ecoming addicted to hers! Our son LOVES it and it is great
for reading books when no light is available. Amazing sound but I suggest good
headphones t...
改进我们的 QA 管道
评估检索器
eval()方法。这可以用于开放域和封闭域的问答,但不能用于像 SubjQA 这样的数据集,其中每个文档都与一个产品配对,我们需要为每个查询按产品 ID 进行过滤。Pipeline,将检索器与EvalRetriever类结合在一起。这样可以实现自定义指标和查询流程。注意
run()方法获取一些输入并产生一些输出的类:class PipelineNode:
def __init__(self):
self.outgoing_edges = 1
def run(self, **kwargs):
...
return (outputs, "outgoing_edge_name")
kwargs对应于图中前一个节点的输出,在run()方法中进行操作,以返回下一个节点的输出的元组,以及出边的名称。唯一的其他要求是包括一个outgoing_edges属性,指示节点的输出数量(在大多数情况下outgoing_edges=1,除非流水线中有根据某些标准路由输入的分支)。EvalRetriever类,其run()方法跟踪哪些文档具有与地面真相匹配的答案。有了这个类,我们可以通过在代表检索器本身的节点之后添加评估节点来构建Pipeline图:from haystack.pipeline import Pipeline
from haystack.eval import EvalDocuments
class EvalRetrieverPipeline:
def __init__(self, retriever):
self.retriever = retriever
self.eval_retriever = EvalDocuments()
pipe = Pipeline()
pipe.add_node(component=self.retriever, name="ESRetriever",
inputs=["Query"])
pipe.add_node(component=self.eval_retriever, name="EvalRetriever",
inputs=["ESRetriever"])
self.pipeline = pipe
pipe = EvalRetrieverPipeline(es_retriever)
name和一个inputs列表。在大多数情况下,每个节点都有一个单独的出边,因此我们只需要在inputs中包含前一个节点的名称。label索引。Haystack 提供了一个Label对象,以标准化的方式表示答案跨度及其元数据。为了填充label索引,我们将首先通过循环遍历测试集中的每个问题,并提取匹配的答案和附加的元数据来创建Label对象的列表:from haystack import Label
labels = []
for i, row in dfs["test"].iterrows():
# Metadata used for filtering in the Retriever
meta = {"item_id": row["title"], "question_id": row["id"]}
# Populate labels for questions with answers
if len(row["answers.text"]):
for answer in row["answers.text"]:
label = Label(
question=row["question"], answer=answer, id=i, origin=row["id"],
meta=meta, is_correct_answer=True, is_correct_document=True,
no_answer=False)
labels.append(label)
# Populate labels for questions without answers
else:
label = Label(
question=row["question"], answer="", id=i, origin=row["id"],
meta=meta, is_correct_answer=True, is_correct_document=True,
no_answer=True)
labels.append(label)
print(labels[0])
{'id': 'e28f5e62-85e8-41b2-8a34-fbff63b7a466', 'created_at': None, 'updated_at':
None, 'question': 'What is the tonal balance of these headphones?', 'answer': 'I
have been a headphone fanatic for thirty years', 'is_correct_answer': True,
'is_correct_document': True, 'origin': 'd0781d13200014aa25860e44da9d5ea7',
'document_id': None, 'offset_start_in_doc': None, 'no_answer': False,
'model_id': None, 'meta': {'item_id': 'B00001WRSJ', 'question_id':
'd0781d13200014aa25860e44da9d5ea7'}}
origin字段,以便我们可以根据问题过滤文档存储。我们还将产品 ID 添加到meta字段中,以便我们可以按产品筛选标签。现在我们有了标签,我们可以按以下方式将它们写入 Elasticsearch 上的label索引:document_store.write_labels(labels, index="label")
print(f"""Loaded {document_store.get_label_count(index="label")} \
question-answer pairs""")
Loaded 358 question-answer pairs
get_all_labels_aggregated()方法,该方法将聚合与唯一 ID 相关联的所有问题-答案对。该方法返回一个MultiLabel对象的列表,但在我们的情况下,由于我们按问题 ID 进行过滤,所以只会得到一个元素。我们可以按以下方式建立一个聚合标签列表:labels_agg = document_store.get_all_labels_aggregated(
index="label",
open_domain=True,
aggregate_by_meta=["item_id"]
)
print(len(labels_agg))
330
multiple_answers字段中:print(labels_agg[109])
{'question': 'How does the fan work?', 'multiple_answers': ['the fan is really
really good', "the fan itself isn't super loud. There is an adjustable dial to
change fan speed"], 'is_correct_answer': True, 'is_correct_document': True,
'origin': '5a9b7616541f700f103d21f8ad41bc4b', 'multiple_document_ids': [None,
None], 'multiple_offset_start_in_docs': [None, None], 'no_answer': False,
'model_id': None, 'meta': {'item_id': 'B002MU1ZRS'}}
pipe对象中跟踪正确的检索:def run_pipeline(pipeline, top_k_retriever=10, top_k_reader=4):
for l in labels_agg:
_ = pipeline.pipeline.run(
query=l.question,
top_k_retriever=top_k_retriever,
top_k_reader=top_k_reader,
top_k_eval_documents=top_k_retriever,
labels=l,
filters={"item_id": [l.meta["item_id"]], "split": ["test"]})
run_pipeline(pipe, top_k_retriever=3)
print(f"Recall@3: {pipe.eval_retriever.recall:.2f}")
Recall@3: 0.95
top_k_retriever,以指定要检索的文档数。一般来说,增加这个参数将提高召回率,但会增加向读者提供更多文档并减慢端到端流程的速度。为了指导我们选择哪个值,我们将创建一个循环遍历几个k值并计算每个k在整个测试集上的召回率的函数:def evaluate_retriever(retriever, topk_values = [1,3,5,10,20]):
topk_results = {}
for topk in topk_values:
# Create Pipeline
p = EvalRetrieverPipeline(retriever)
# Loop over each question-answers pair in test set
run_pipeline(p, top_k_retriever=topk)
# Get metrics
topk_results[topk] = {"recall": p.eval_retriever.recall}
return pd.DataFrame.from_dict(topk_results, orient="index")
es_topk_df = evaluate_retriever(es_retriever)
def plot_retriever_eval(dfs, retriever_names):
fig, ax = plt.subplots()
for df, retriever_name in zip(dfs, retriever_names):
df.plot(y="recall", ax=ax, label=retriever_name)
plt.xticks(df.index)
plt.ylabel("Top-k Recall")
plt.xlabel("k")
plt.show()
plot_retriever_eval([es_topk_df], ["BM25"])

密集通道检索
[CLS]标记的d维向量表示。
图 7-10。DPR 的双编码器架构用于计算文档和查询的相关性
from haystack.retriever.dense import DensePassageRetriever
dpr_retriever = DensePassageRetriever(document_store=document_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
embed_title=False)
embed_title=False,因为连接文档的标题(即item_id)不会提供任何额外信息,因为我们按产品进行过滤。一旦我们初始化了密集检索器,下一步是迭代我们 Elasticsearch 索引中的所有索引文档,并应用编码器来更新嵌入表示。这可以通过以下方式完成:document_store.update_embeddings(retriever=dpr_retriever)
dpr_topk_df = evaluate_retriever(dpr_retriever)
plot_retriever_eval([es_topk_df, dpr_topk_df], ["BM25", "DPR"])

提示
评估读者
from farm.evaluation.squad_evaluation import compute_f1, compute_exact
pred = "about 6000 hours"
label = "6000 hours"
print(f"EM: {compute_exact(label, pred)}")
print(f"F1: {compute_f1(label, pred)}")
EM: 0
F1: 0.8
pred = "about 6000 dollars"
print(f"EM: {compute_exact(label, pred)}")
print(f"F1: {compute_f1(label, pred)}")
EM: 0
F1: 0.4
EvalReader类,该类获取阅读器的预测并计算相应的 EM 和F[1]分数。为了与 SQuAD 评估进行比较,我们将使用EvalAnswers中存储的top_1_em和top_1_f1度量来获取每个查询的最佳答案:from haystack.eval import EvalAnswers
def evaluate_reader(reader):
score_keys = ['top_1_em', 'top_1_f1']
eval_reader = EvalAnswers(skip_incorrect_retrieval=False)
pipe = Pipeline()
pipe.add_node(component=reader, name="QAReader", inputs=["Query"])
pipe.add_node(component=eval_reader, name="EvalReader", inputs=["QAReader"])
for l in labels_agg:
doc = document_store.query(l.question,
filters={"question_id":[l.origin]})
_ = pipe.run(query=l.question, documents=doc, labels=l)
return {k:v for k,v in eval_reader.__dict__.items() if k in score_keys}
reader_eval = {}
reader_eval["Fine-tune on SQuAD"] = evaluate_reader(reader)
skip_incorrect_retrieval=False。这是为了确保检索器始终将上下文传递给阅读器(就像在 SQuAD 评估中一样)。现在我们已经通过阅读器运行了每个问题,让我们打印分数:def plot_reader_eval(reader_eval):
fig, ax = plt.subplots()
df = pd.DataFrame.from_dict(reader_eval)
df.plot(kind="bar", ylabel="Score", rot=0, ax=ax)
ax.set_xticklabels(["EM", "F1"])
plt.legend(loc='upper left')
plt.show()
plot_reader_eval(reader_eval)

领域自适应
FARMReader有一个train()方法,专门用于此目的,并且期望数据以 SQuAD JSON 格式提供,其中所有问题-答案对都被分组在一起,如图 7-11 所示。
图 7-11. SQuAD JSON 格式的可视化
paragraphs数组的函数。该数组中的每个元素包含单个上下文(即评论)和问题-答案对的qas数组。以下是一个构建paragraphs数组的函数:def create_paragraphs(df):
paragraphs = []
id2context = dict(zip(df["review_id"], df["context"]))
for review_id, review in id2context.items():
qas = []
# Filter for all question-answer pairs about a specific context
review_df = df.query(f"review_id == '{review_id}'")
id2question = dict(zip(review_df["id"], review_df["question"]))
# Build up the qas array
for qid, question in id2question.items():
# Filter for a single question ID
question_df = df.query(f"id == '{qid}'").to_dict(orient="list")
ans_start_idxs = question_df["answers.answer_start"][0].tolist()
ans_text = question_df["answers.text"][0].tolist()
# Fill answerable questions
if len(ans_start_idxs):
answers = [
{"text": text, "answer_start": answer_start}
for text, answer_start in zip(ans_text, ans_start_idxs)]
is_impossible = False
else:
answers = []
is_impossible = True
# Add question-answer pairs to qas
qas.append({"question": question, "id": qid,
"is_impossible": is_impossible, "answers": answers})
# Add context and question-answer pairs to paragraphs
paragraphs.append({"qas": qas, "context": review})
return paragraphs
DataFrame的行应用于 SQuAD 格式时:product = dfs["train"].query("title == 'B00001P4ZH'")
create_paragraphs(product)
[{'qas': [{'question': 'How is the bass?',
'id': '2543d296da9766d8d17d040ecc781699',
'is_impossible': True,
'answers': []}],
'context': 'I have had Koss headphones ...',
'id': 'd476830bf9282e2b9033e2bb44bbb995',
'is_impossible': False,
'answers': [{'text': 'Bass is weak as expected', 'answer_start': 1302},
{'text': 'Bass is weak as expected, even with EQ adjusted up',
'answer_start': 1302}]}],
'context': 'To anyone who hasn\'t tried all ...'},
{'qas': [{'question': 'How is the bass?',
'id': '455575557886d6dfeea5aa19577e5de4',
'is_impossible': False,
'answers': [{'text': 'The only fault in the sound is the bass',
'answer_start': 650}]}],
'context': "I have had many sub-$100 headphones ..."}]
DataFrame中的每个产品 ID。以下convert_to_squad()函数可以做到这一点,并将结果存储在electronics-{split}.json文件中:import json
def convert_to_squad(dfs):
for split, df in dfs.items():
subjqa_data = {}
# Create `paragraphs` for each product ID
groups = (df.groupby("title").apply(create_paragraphs)
.to_frame(name="paragraphs").reset_index())
subjqa_data["data"] = groups.to_dict(orient="records")
# Save the result to disk
with open(f"electronics-{split}.json", "w+", encoding="utf-8") as f:
json.dump(subjqa_data, f)
convert_to_squad(dfs)
train_filename = "electronics-train.json"
dev_filename = "electronics-validation.json"
reader.train(data_dir=".", use_gpu=True, n_epochs=1, batch_size=16,
train_filename=train_filename, dev_filename=dev_filename)
reader_eval["Fine-tune on SQuAD + SubjQA"] = evaluate_reader(reader)
plot_reader_eval(reader_eval)

FARMReader加载模型:minilm_ckpt = "microsoft/MiniLM-L12-H384-uncased"
minilm_reader = FARMReader(model_name_or_path=minilm_ckpt, progress_bar=False,
max_seq_len=max_seq_length, doc_stride=doc_stride,
return_no_answer=True)
minilm_reader.train(data_dir=".", use_gpu=True, n_epochs=1, batch_size=16,
train_filename=train_filename, dev_filename=dev_filename)
reader_eval["Fine-tune on SubjQA"] = evaluate_reader(minilm_reader)
plot_reader_eval(reader_eval)

警告
评估整个 QA 管道
# Initialize retriever pipeline
pipe = EvalRetrieverPipeline(es_retriever)
# Add nodes for reader
eval_reader = EvalAnswers()
pipe.pipeline.add_node(component=reader, name="QAReader",
inputs=["EvalRetriever"])
pipe.pipeline.add_node(component=eval_reader, name="EvalReader",
inputs=["QAReader"])
# Evaluate!
run_pipeline(pipe)
# Extract metrics from reader
reader_eval["QA Pipeline (top-1)"] = {
k:v for k,v in eval_reader.__dict__.items()
if k in ["top_1_em", "top_1_f1"]}
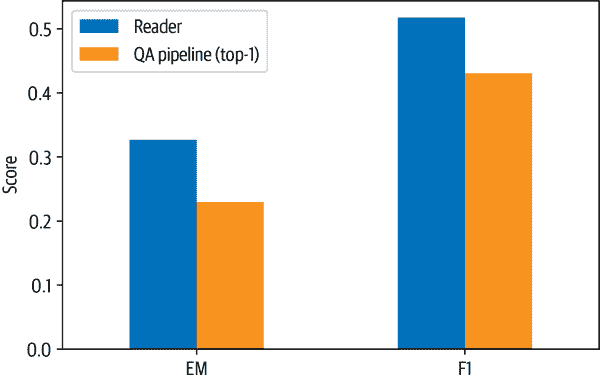
图 7-12。EM 和F[1]分数的阅读器与整个 QA 管道的比较
超越抽取式 QA

图 7-13。RAG 架构用于对检索器和生成器进行端到端微调(由 Ethan Perez 提供)
DPRetriever,因此我们只需要实例化一个生成器。有两种类型的 RAG 模型可供选择:max_seq_length和doc_stride参数,而是指定控制文本生成的超参数:from haystack.generator.transformers import RAGenerator
generator = RAGenerator(model_name_or_path="facebook/rag-token-nq",
embed_title=False, num_beams=5)
num_beams指定了在波束搜索中使用的波束数量(文本生成在第五章中有详细介绍)。与 DPR 检索器一样,我们不嵌入文档标题,因为我们的语料库始终根据产品 ID 进行过滤。GenerativeQAPipeline将检索器和生成器联系起来:from haystack.pipeline import GenerativeQAPipeline
pipe = GenerativeQAPipeline(generator=generator, retriever=dpr_retriever)
注意
GenerativeQAPipeline使用RAGenerator的查询编码器和DensePassageRetriever的上下文编码器。def generate_answers(query, top_k_generator=3):
preds = pipe.run(query=query, top_k_generator=top_k_generator,
top_k_retriever=5, filters={"item_id":["B0074BW614"]})
print(f"Question: {preds['query']} \n")
for idx in range(top_k_generator):
print(f"Answer {idx+1}: {preds['answers'][idx]['answer']}")
generate_answers(query)
Question: Is it good for reading?
Answer 1: the screen is absolutely beautiful
Answer 2: the Screen is absolutely beautiful
Answer 3: Kindle fire
generate_answers("What is the main drawback?")
Question: What is the main drawback?
Answer 1: the price
Answer 2: no flash support
Answer 3: the cost
 Transformers repository中找到一些脚本来帮助您入门。
Transformers repository中找到一些脚本来帮助您入门。结论

图 7-14. QA 需求层次结构
token_type_ids并不是所有 Transformer 模型都具有的。对于 MiniLM 等类似 BERT 的模型,token_type_ids在预训练期间也用于整合下一个句子预测任务。