【Flink】Flink 自定义 redis sink
1.概述
内部要做 Flink SQL 平台,本文以自定义 Redis Sink 为例来说明 Flink SQL 如何自定义 Sink 以及自定义完了之后如何使用
基于 Flink 1.11
2.步骤
- implements DynamicTableSinkFactory
- implements DynamicTableSink
- 创建 Redis Sink
3.自定义 sink 代码
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.streaming.api.functions.sink.PrintSinkFunction;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.flink.table.connector.ChangelogMode;
import org.apache.flink.table.connector.sink.DynamicTableSink;
import org.apache.flink.table.connector.sink.DynamicTableSink.DataStructureConverter;
import org.apache.flink.table.connector.sink.SinkFunctionProvider;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.DynamicTableSinkFactory;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import org.apache.flink.table.types.logical.RowType;
import org.apache.flink.types.Row;
import org.apache.flink.types.RowKind;
import redis.clients.jedis.JedisCluster;
import java.util.*;
import static org.apache.flink.configuration.ConfigOptions.key;
/**
* @author shengjk1
* @date 2020/10/16
*/
public class RedisTableSinkFactory implements DynamicTableSinkFactory {
public static final String IDENTIFIER = "redis";
public static final ConfigOption<String> HOST_PORT = key("hostPort")
.stringType()
.noDefaultValue()
.withDescription("redis host and port,");
public static final ConfigOption<String> PASSWORD = key("password")
.stringType()
.noDefaultValue()
.withDescription("redis password");
public static final ConfigOption<Integer> EXPIRE_TIME = key("expireTime")
.intType()
.noDefaultValue()
.withDescription("redis key expire time");
public static final ConfigOption<String> KEY_TYPE = key("keyType")
.stringType()
.noDefaultValue()
.withDescription("redis key type,such as hash,string and so on ");
public static final ConfigOption<String> KEY_TEMPLATE = key("keyTemplate")
.stringType()
.noDefaultValue()
.withDescription("redis key template ");
public static final ConfigOption<String> FIELD_TEMPLATE = key("fieldTemplate")
.stringType()
.noDefaultValue()
.withDescription("redis field template ");
public static final ConfigOption<String> VALUE_NAMES = key("valueNames")
.stringType()
.noDefaultValue()
.withDescription("redis value name ");
@Override
// 当 connector 与 IDENTIFIER 一直才会找到 RedisTableSinkFactory 通过
public String factoryIdentifier() {
return IDENTIFIER;
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
return new HashSet<>();
}
@Override
//我们自己定义的所有选项 (with 后面的 ) 都会在这里获取
public Set<ConfigOption<?>> optionalOptions() {
Set<ConfigOption<?>> options = new HashSet<>();
options.add(HOST_PORT);
options.add(PASSWORD);
options.add(EXPIRE_TIME);
options.add(KEY_TYPE);
options.add(KEY_TEMPLATE);
options.add(FIELD_TEMPLATE);
options.add(VALUE_NAMES);
return options;
}
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
helper.validate();
ReadableConfig options = helper.getOptions();
return new RedisSink(
context.getCatalogTable().getSchema().toPhysicalRowDataType(),
options);
}
private static class RedisSink implements DynamicTableSink {
private final DataType type;
private final ReadableConfig options;
private RedisSink(DataType type, ReadableConfig options) {
this.type = type;
this.options = options;
}
@Override
//ChangelogMode
public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
return requestedMode;
}
@Override
//具体运行的地方,真正开始调用用户自己定义的 streaming sink ,建立 sql 与 streaming 的联系
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
DataStructureConverter converter = context.createDataStructureConverter(type);
return SinkFunctionProvider.of(new RowDataPrintFunction(converter, options, type));
}
@Override
// sink 可以不用实现,主要用来 source 的谓词下推
public DynamicTableSink copy() {
return new RedisSink(type, options);
}
@Override
public String asSummaryString() {
return "redis";
}
}
/**
同 flink streaming 自定义 sink ,只不过我们这次处理的是 RowData,不细说
*/
private static class RowDataPrintFunction extends RichSinkFunction<RowData> {
private static final long serialVersionUID = 1L;
private final DataStructureConverter converter;
private final ReadableConfig options;
private final DataType type;
private RowType logicalType;
private HashMap<String, Integer> fields;
private JedisCluster jedisCluster;
private RowDataPrintFunction(
DataStructureConverter converter, ReadableConfig options, DataType type) {
this.converter = converter;
this.options = options;
this.type = type;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
logicalType = (RowType) type.getLogicalType();
fields = new HashMap<>();
List<RowType.RowField> rowFields = logicalType.getFields();
int size = rowFields.size();
for (int i = 0; i < size; i++) {
fields.put(rowFields.get(i).getName(), i);
}
jedisCluster = RedisUtil.getJedisCluster(options.get(HOST_PORT));
}
@Override
public void close() throws Exception {
RedisUtil.closeConn(jedisCluster);
}
@Override
/*
2> +I(1,30017323,1101)
2> -U(1,30017323,1101)
2> +U(2,30017323,1101)
2> -U(2,30017323,1101)
2> +U(3,30017323,1101)
2> -U(3,30017323,1101)
2> +U(4,30017323,1101)
3> -U(3,980897,3208)
3> +U(4,980897,3208)
*/
public void invoke(RowData rowData, Context context) {
RowKind rowKind = rowData.getRowKind();
Row data = (Row) converter.toExternal(rowData);
if (rowKind.equals(RowKind.UPDATE_AFTER) || rowKind.equals(RowKind.INSERT)) {
String keyTemplate = options.get(KEY_TEMPLATE);
if (Objects.isNull(keyTemplate) || keyTemplate.trim().length() == 0) {
throw new NullPointerException(" keyTemplate is null or keyTemplate is empty");
}
if (keyTemplate.contains("${")) {
String[] split = keyTemplate.split("\\$\\{");
keyTemplate = "";
for (String s : split) {
if (s.contains("}")) {
String filedName = s.substring(0, s.length() - 1);
int index = fields.get(filedName);
keyTemplate = keyTemplate + data.getField(index).toString();
} else {
keyTemplate = keyTemplate + s;
}
}
}
String keyType = options.get(KEY_TYPE);
String valueNames = options.get(VALUE_NAMES);
// type=hash must need fieldTemplate
if ("hash".equalsIgnoreCase(keyType)) {
String fieldTemplate = options.get(FIELD_TEMPLATE);
if (fieldTemplate.contains("${")) {
String[] split = fieldTemplate.split("\\$\\{");
fieldTemplate = "";
for (String s : split) {
if (s.contains("}")) {
String fieldName = s.substring(0, s.length() - 1);
int index = fields.get(fieldName);
fieldTemplate = fieldTemplate + data.getField(index).toString();
} else {
fieldTemplate = fieldTemplate + s;
}
}
}
//fieldName = fieldTemplate-valueName
if (valueNames.contains(",")) {
HashMap<String, String> map = new HashMap<>();
String[] fieldNames = valueNames.split(",");
for (String fieldName : fieldNames) {
String value = data.getField(fields.get(fieldName)).toString();
map.put(fieldTemplate + "_" + fieldName, value);
}
jedisCluster.hset(keyTemplate, map);
} else {
jedisCluster.hset(keyTemplate, fieldTemplate + "_" + valueNames, data.getField(fields.get(valueNames)).toString());
}
} else if ("set".equalsIgnoreCase(keyType)) {
jedisCluster.set(keyTemplate, data.getField(fields.get(valueNames)).toString());
} else if ("sadd".equalsIgnoreCase(keyType)) {
jedisCluster.sadd(keyTemplate, data.getField(fields.get(valueNames)).toString());
} else if ("zadd".equalsIgnoreCase(keyType)) {
jedisCluster.sadd(keyTemplate, data.getField(fields.get(valueNames)).toString());
} else {
throw new IllegalArgumentException(" not find this keyType:" + keyType);
}
if (Objects.nonNull(options.get(EXPIRE_TIME))) {
jedisCluster.expire(keyTemplate, options.get(EXPIRE_TIME));
}
}
}
}
}
4.使用 Redis Sink
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.typeutils.TupleTypeInfo;
import org.apache.flink.api.scala.typeutils.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.time.Duration;
/**
* @author shengjk1
* @date 2020/9/25
*/
public class SqlKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings environmentSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, environmentSettings);
// enable checkpointing
Configuration configuration = tableEnv.getConfig().getConfiguration();
configuration.set(
ExecutionCheckpointingOptions.CHECKPOINTING_MODE, CheckpointingMode.EXACTLY_ONCE);
configuration.set(
ExecutionCheckpointingOptions.CHECKPOINTING_INTERVAL, Duration.ofSeconds(10));
String sql = "CREATE TABLE sourcedata (`id` bigint,`status` int,`city_id` bigint,`courier_id` bigint,info_index int,order_id bigint,tableName String" +
") WITH (" +
"'connector' = 'kafka','topic' = 'xxx'," +
"'properties.bootstrap.servers' = 'xxx','properties.group.id' = 'testGroup'," +
"'format' = 'json','scan.startup.mode' = 'earliest-offset')";
tableEnv.executeSql(sql);
//15017284 distinct
Table bigtable = tableEnv.sqlQuery("select distinct a.id,a.courier_id,a.status,a.city_id,b.info_index from (select id,status,city_id,courier_id from sourcedata where tableName = 'orders' and status=60)a join (select " +
" order_id,max(info_index)info_index from sourcedata where tableName = 'infos' group by order_id )b on a.id=b.order_id");
sql = "CREATE TABLE redis (info_index BIGINT,courier_id BIGINT,city_id BIGINT" +
") WITH (" +
"'connector' = 'redis'," +
"'hostPort'='xxx'," +
"'keyType'='hash'," +
"'keyTemplate'='test2_${city_id}'," +
"'fieldTemplate'='test2_${courier_id}'," +
"'valueNames'='info_index,city_id'," +
"'expireTime'='1000')";
tableEnv.executeSql(sql);
Table resultTable = tableEnv.sqlQuery("select sum(info_index)info_index,courier_id,city_id from " + bigtable + " group by city_id,courier_id");
TupleTypeInfo<Tuple3<Long, Long, Long>> tupleType = new TupleTypeInfo<>(
Types.LONG(),
Types.LONG(),
Types.LONG());
tableEnv.toRetractStream(resultTable, tupleType).print("===== ");
tableEnv.executeSql("INSERT INTO redis SELECT info_index,courier_id,city_id FROM " + resultTable);
env.execute("");
}
}
5.详细解释
create table test(
`id` bigint,
`url` string,
`day` string,
`pv` long,
`uv` long
) with {
'connector'='redis',
'hostPort'='xxx',
'password'='',
'expireTime'='100',
'keyType'='hash',
'keyTemplate'='test_${id}',
'fieldTemplate'='${day}',
'valueNames'='pv,uv',
}
redis result: 假设 id=1 day=20201016 pv=20,uv=20
hash
test_1 20201016-pv 20,20201016-uv 20
参数解释:
connector 固定写法
hostPort redis 的地址
password redis 的密码
expireTime redis key 过期时间,单位为 s
keyType redis key 的类型,目前有 hash、set、sadd、zadd
keyTemplate redis key 的表达式,如 test_${id} 注意 id 为表的字段名
fieldTemplate redis keyType==hash 时,此选项为必选,表达式规则同 keyTemplate
valueNames redis value only 可以有多个
6.原理
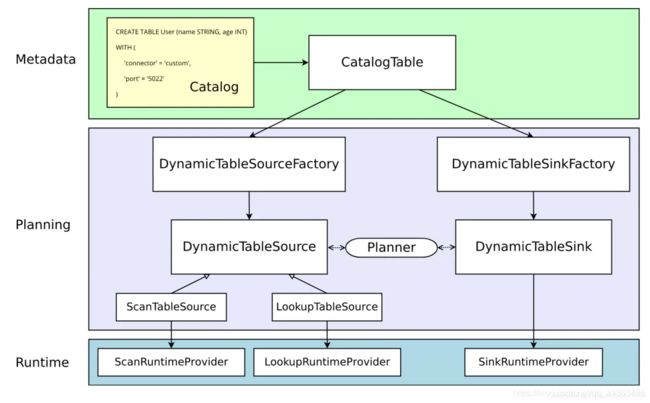
整个流程如图,CatalogTable —> DynamicTableSource and DynamicTableSink 这个过程中,其实是通过 DynamicTableSourceFactory and DynamicTableSinkFactory 起到了一个桥梁的作用
(Source/Sink)Factory 通过 connector=‘xxx’ 找到,理论上会做三种操作
- validate options
- configure encoding/decoding formats( if required )
- create a parameterized instance of the table connector
其中 formats 是通过 format=‘xxx’ 找到
DynamicTableSource DynamicTableSink
官网虽说可以看做是有状态的,但是否真的有状态取决于具体实现的 source 和 sink
生成 Runtime logic,Runtime logic 被 Flink core connector interfaces( 如 InputFormat or SourceFunction),如果是 kafka 的话 则 是 FlinkKafkaConsumer 实现,而这些实现又被抽象为 *Provider,然后开始执行 *Provider
*Provider 是连接 SQL 与 Streaming 代码级别的桥梁
7.参考
https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/sourceSinks.html
作者:学木
链接:https://www.jianshu.com/p/09ed7e71aa1f
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。