Amazon Bedrock 的微调和持续预训练功能允许用户使用私有数据定制模型
今天我很高兴地宣布,您现在可以在 Amazon Bedrock 中使用自己的数据,安全并私密地定制基础模型(FMs),按照您所在领域、企业和用例的特定要求构建应用程序。借助定制模型,您可以创建独特的用户体验,体现企业的风格、观点和服务。
通过微调,您可以通过私有的特定任务标注训练数据集来提高模型的准确性,进一步使基础模型(FM)专业化。借助持续预训练,您可以在安全的托管环境中使用私有未经标注的数据和客户管理密钥来训练模型。持续预训练有助于模型丰富知识,增强适应性,从而超越原始训练,提高面向特定领域的针对性。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
下面我们来快速浏览一下这两种模型定制选项。您可以使用 Amazon Bedrock 控制台 或 API 创建微调和持续预训练任务。在控制台中,导航至 Amazon Bedrock,然后选择“定制模型”。
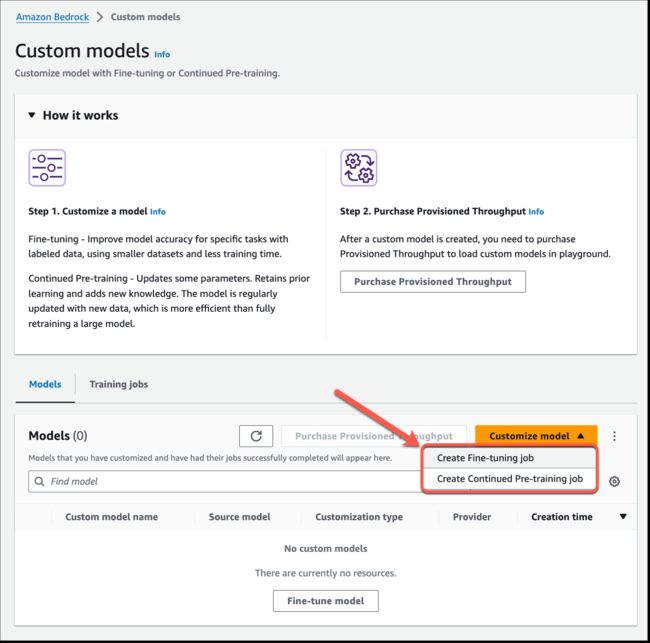
微调 Meta Llama 2、Cohere Command Light、以及 Amazon Titan FMs Amazon Bedrock 现在支持微调 Meta Llama 2、Cohere Command Light 以及 Amazon Titan 模型。要在控制台创建微调任务,选择 “自定义模型”,然后选择“创建微调任务”。
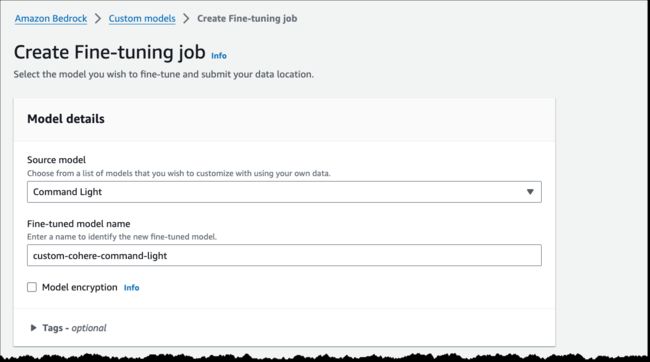
下面是关于使用 Amazon SDK for Python (Boto3) 的快速演示。我们对 Cohere Command Light 进行微调,以汇总对话。因为是演示,所以我使用了公开的 dialogsum 数据集,您也可以选择您所在企业的特定数据。
为了准备在 Amazon Bedrock 上进行微调,我将数据集转换为 JSON Lines 格式,并将其上传到 Amazon S3。每一行 JSON 都需要一个提示字段和一个完成字段。您最多可以指定 10,000 条训练数据记录,但只需几百个示例就能看到模型性能的提升。
{"completion": "Mr. Smith's getting a check-up, and Doctor Haw...", "prompt": Summarize the following conversation.\n\n#Pers..."}
{"completion": "Mrs Parker takes Ricky for his vaccines. Dr. P...", "prompt": "Summarize the following conversation.\n\n#Pers..."}
{"completion": "#Person1#'s looking for a set of keys and asks...", "prompt": "Summarize the following conversation.\n\n#Pers..."} 为方便起见,我编辑了提示和完成字段。
您可以使用以下命令列出支持微调的可用基础模型:
import boto3
bedrock = boto3.client(service_name="bedrock")
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
for model in bedrock.list_foundation_models(
byCustomizationType="FINE_TUNING")["modelSummaries"]:
for key, value in model.items():
print(key, ":", value)
print("-----\n")接下来,我创建了一个模型定制任务。我指定了支持微调的 Cohere Command Light 模型 ID,将定制类型设为 FINE_TUNING,并指向训练数据的 Amazon S3 位置。如有必要,您还可以调整微调超参数。
# Select the foundation model you want to customize
base_model_id = "cohere.command-light-text-v14:7:4k"
bedrock.create_model_customization_job(
customizationType="FINE_TUNING",
jobName=job_name,
customModelName=model_name,
roleArn=role,
baseModelIdentifier=base_model_id,
hyperParameters = {
"epochCount": "1",
"batchSize": "8",
"learningRate": "0.00001",
},
trainingDataConfig={"s3Uri": "s3://path/to/train-summarization.jsonl"},
outputDataConfig={"s3Uri": "s3://path/to/output"},
)
# Check for the job status
status = bedrock.get_model_customization_job(jobIdentifier=job_name)["status"]完成任务之后,您的自定义模型将收到一个唯一的模型 ID。Amazon Bedrock 将会安全地存储您的微调模型。要测试和部署您的模型,您需要购买 Provisioned Throughput。
我们来看看结果。我从数据集中选择一个示例,请求微调前的基本模型和微调后的自定义模型,总结出以下对话:
prompt = """Summarize the following conversation.\\n\\n
#Person1#: Hello. My name is John Sandals, and I've got a reservation.\\n
#Person2#: May I see some identification, sir, please?\\n
#Person1#: Sure. Here you are.\\n
#Person2#: Thank you so much. Have you got a credit card, Mr. Sandals?\\n
#Person1#: I sure do. How about American Express?\\n
#Person2#: Unfortunately, at the present time we take only MasterCard or VISA.\\n
#Person1#: No American Express? Okay, here's my VISA.\\n
#Person2#: Thank you, sir. You'll be in room 507, nonsmoking, with a queen-size bed. Do you approve, sir?\\n
#Person1#: Yeah, that'll be fine.\\n
#Person2#: That's great. This is your key, sir. If you need anything at all, anytime, just dial zero.\\n\\n
Summary: """下面是微调前的基本模型响应:
#Person2# 帮助 John Sandals 完成预订。John 提供了他的信用卡信息,而 #Person2# 确认他们只接受万事达和 VISA 卡。John 将入住 507 号房间,如果他有任何需要,将由 #Person2# 提供服务。
下面是微调后的响应,更简短、更切题:
John Sandals 预订了一家酒店并办理了入住手续。#Person2# 拿走了他的信用卡并给了他一把钥匙。
持续预训练支持 Amazon Titan Text (预览版)
Amazon Bedrock 的持续预训练可用于 Amazon Titan Text 模型的公开预览版,包括 Titan Text Express 和 Titan Text Lite。要在控制台创建持续预训练任务,选择“自定义模型”,然后选择“创建持续预训练任务”。
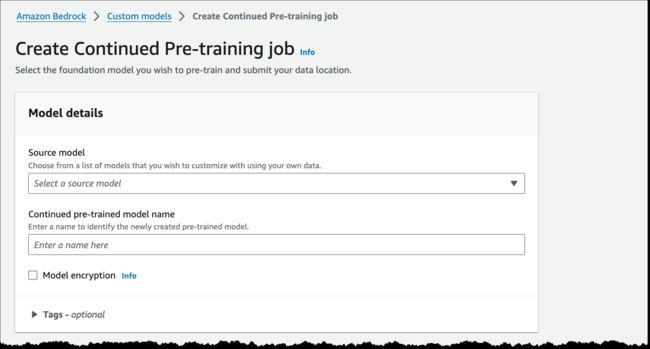
下面还是关于使用 boto3 的快速演示。假设您在一家投资公司工作,希望继续使用财务和分析师报告对模型进行预训练,使其更加了解金融行业术语。因为是演示,所以我选择了一组亚马逊股东信作为训练数据。
为了准备实施预训练,我将数据集转换为 JSON Lines 格式,并将其上传到 Amazon S3。我使用的是未加标注的数据,因此每一行 JSON 仅需提示字段。您最多可以指定 100,000 条训练数据记录,通常最少需要提供 10 亿个令牌才能看到积极效果。
{"input": "Dear shareholders: As I sit down to..."}
{"input": "Over the last several months, we to..."}
{"input": "work came from optimizing the conne..."}
{"input": "of the Amazon shopping experience f..."}为方便起见,我编辑了输入字段。
然后,创建一个模型自定义任务,将定制类型设为指向数据的 CONTINUED_PRE_TRAINING。如有必要,您还可以调整持续预训练超参数。
# Select the foundation model you want to customize
base_model_id = "amazon.titan-text-express-v1"
bedrock.create_model_customization_job(
customizationType="CONTINUED_PRE_TRAINING",
jobName=job_name,
customModelName=model_name,
roleArn=role,
baseModelIdentifier=base_model_id,
hyperParameters = {
"epochCount": "10",
"batchSize": "8",
"learningRate": "0.00001",
},
trainingDataConfig={"s3Uri": "s3://path/to/train-continued-pretraining.jsonl"},
outputDataConfig={"s3Uri": "s3://path/to/output"},
)完成任务之后,您将收到一个唯一的模型 ID。还是由 Amazon Bedrock 安全地存储您的自定义模型。和微调一样,要测试和部署您的模型,您需要购买 Provisioned Throughput。
注意事项
下面是一些重要注意事项:
数据隐私和网络安全 —— 借助 Amazon Bedrock,您可以控制自己的数据,并且您的所有输入和自定义内容都是亚马逊云科技账户私有的。您的数据(例如提示、完成情况和微调模型)不会用于改进服务,也绝不会用来和第三方模型提供商共享。您的数据将保留在处理 API 调用的区域。所有数据在传输和静止状态中均进行了加密。您可以使用Amazon PrivateLink 在您的 VPC 和 Amazon Bedrock 之间创建私密连接。
计费 —— Amazon Bedrock 对模型定制、存储和推理收费。模型定制按处理的令牌数量收费,即训练数据集中的令牌数量乘以训练周期数。训练周期是指在微调过程中,对训练数据集的一次完整遍历。您需要每月为每个模型支付模型存储费用。推理是按照每个模型单位使用的预配置吞吐量按小时收费。有关详细定价信息,请参阅 Amazon Bedrock 定价。
定制模型和预配置吞吐量 —— Amazon Bedrock 允许您通过购买预配置吞吐量在自定义模型上运行推理。这种模式可以保证稳定的吞吐量水平,作为交换,您需要承诺使用期限。您可以指定满足应用程序性能需求所需的模型单元数量。在最初评估自定义模型时,您可以按小时购买预配置吞吐量,无需长期承诺。如果没有承诺使用期限,则每个预配置吞吐量仅限使用 1 个模型单元。每个账户最多可创建两个预配置吞吐量。
可用性
支持 Meta Llama 2、Cohere Command Light 和 Amazon Titan Text FM 的微调功能现已在美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)这两个亚马逊云科技区域推出。持续预培训现已在美国东部(弗吉尼亚州北部)和美国西部(俄勒冈州)这两个亚马逊云科技区域以公开预览版提供。更多信息,请访问 Amazon Bedrock开发人员体验页面,查阅《用户指南》。
立即开始使用 Amazon Bedrock 自定义您的基础模型!
文章来源:Amazon Bedrock 的微调和持续预训练功能允许用户使用私有数据定制模型