MySQL基础篇
MySQL数据库笔记
第一部分 MySQL基础篇
第01章 数据库概述
1. 为什么要使用数据库
- 持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用。大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以“固化”,而持久化的实现过程大多通过各种关系数据库来完成。
- 持久化的主要作用是将内存中的数据存储在关系型数据库中,当然也可以存储在磁盘文件、XML数据文件中。
2. 数据库与数据库管理系统
2.1 数据库的相关概念
-
DB:数据库(Database)
- 即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。
-
DBMS:数据库管理系统(Database Management System)
- 是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。
-
SQL:结构化查询语言(Structured Query Language)
- 专门用来与数据库通信的语言。
3. RDBMS与非RDBMS
3.1 关系型数据库(RDBMS)
3.1.1 实质
- 这种类型的数据库是最古老的数据库类型,关系型数据库模型是把复杂的数据结构归结为简单的二元关系 (即二维表格形式)。
- 关系型数据库以行(row)和列(column)的形式存储数据,以便于用户理解。这一系列的行和列被称为表(table),一组表组成了一个库(database)。
- SQL就是关系型数据库的查询语言。
3.1.2 优势
- 复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
- 事务支持使得对于安全性能很高的数据访问要求得以实现。
3.2 非关系型数据库(非RDBMS)
3.2.1 介绍
非关系型数据库,可看成传统关系型数据库的功能阉割版本,基于键值对存储数据,不需要经过SQL层的解析,性能非常高。同时,通过减少不常用的功能,进一步提高性能。
4. 关系型数据库设计规则
- 一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性。
- 表具有一些特性,这些特性定义了数据在表中如何存储,类似Java和Python中 “类”的设计。
4.1 表、记录、字段
- E-R(entity-relationship,实体-联系)模型中有三个主要概念是:实体集、属性、联系集。
- 一个实体集(class)对应于数据库中的一个表(table),一个实体(instance)则对应于数据库表中的一行(row),也称为一条记录(record)。一个属性(attribute)对应于数据库表中的一列(column),也称为一个字段(field)。
4.2 表的关联关系
- 表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。
- 四种:一对一关联、一对多关联、多对多关联、自我引用
第02章 MySQL环境搭建(略)
1. MySQL演示使用
1.1 MySQL的编码设置
MySQL5.7中
问题再现:命令行操作sql乱码问题
mysql> INSERT INTO t_stu VALUES(1,'张三','男');
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'sname' at row 1
问题解决
步骤1:查看编码命令
show variables like 'character_%';
show variables like 'collation_%';
步骤2:修改mysql的数据目录下的my.ini配置文件
default-character-set=utf8 #默认字符集 [mysqld]
# 大概在76行左右,在其下添加
...
character-set-server=utf8
collation-server=utf8_general_ci
步骤3:重启服务
步骤4:查看编码命令
show variables like 'character_%';
show variables like 'collation_%';
MySQL8.0中
在MySQL 8.0版本之前,默认字符集为latin1,utf8字符集指向的是utf8mb3。网站开发人员在数据库设计的时候往往会将编码修改为utf8字符集。如果遗忘修改默认的编码,就会出现乱码的问题。从MySQL 8.0开始,数据库的默认编码改为utf8mb4,从而避免了上述的乱码问题。
问题1:root用户密码忘记,重置的操作
1: 通过任务管理器或者服务管理,关掉mysqld(服务进程)
2: 通过命令行+特殊参数开启mysqld mysqld – defaults-file=“D:\ProgramFiles\mysql\MySQLServer5.7Data\my.ini” --skip-grant-tables
3: 此时,mysqld服务进程已经打开。并且不需要权限检查
4: mysql -uroot 无密码登陆服务器。另启动一个客户端进行
5: 修改权限表 (1) use mysql; (2)update user set authentication_string=password(‘新密码’) where user=‘root’ and Host=‘localhost’; (3)flush privileges;
6: 通过任务管理器,关掉mysqld服务进程。
7: 再次通过服务管理,打开mysql服务。
8: 即可用修改后的新密码登陆。
问题2:mysql命令报“不是内部或外部命令”
如果输入mysql命令报“不是内部或外部命令”,把mysql安装目录的bin目录配置到环境变量path中。
问题3: No database selected
解决方案一:就是使用“USE 数据库名;”语句,这样接下来的语句就默认针对这个数据库进行操作
解决方案二:就是所有的表对象前面都加上“数据库.”
问题4:命令行客户端的字符集问题
mysql> INSERT INTO t_stu VALUES(1,'张三','男');
ERROR 1366 (HY000): Incorrect string value: '\xD5\xC5\xC8\xFD' for column 'sname' at row 1
查看所有字符集:SHOW VARIABLES LIKE 'character_set_%';
解决方案,设置当前连接的客户端字符集 SET NAMES GBK;
问题5:修改数据库和表的字符编码
修改编码:
(1)先停止服务,(2)修改my.ini文件(3)重新启动服务
说明:
如果是在修改my.ini之前建的库和表,那么库和表的编码还是原来的Latin1,要么删了重建,要么使用alter语句修改编码。
mysql> create database 0728db charset Latin1;
Query OK, 1 row affected (0.00 sec)
mysql> use 0728db;
Database changed
mysql> show create table student\G
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
mysql> alter table student charset utf8; #修改表字符编码为UTF8
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table student\G
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` ( `id` int(11) NOT NULL, `name` varchar(20) CHARACTER SET latin1 DEFAULT NULL, #字段仍然是latin1编码 PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> alter table student modify name varchar(20) charset utf8; #修改字段字符编码为UTF8
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table student\G
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1 row in set (0.00 sec)
mysql> show create database 0728db;
+--------+-----------------------------------------------------------------+
|Database| Create Database |
+------+-------------------------------------------------------------------+
|0728db| CREATE DATABASE `0728db` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+------+-------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> alter database 0728db charset utf8; #修改数据库的字符编码为utf8
Query OK, 1 row affected (0.00 sec)
第03章 基本的SELECT语句
1. SQL概述
1.1 SQL分类
-
DDL:数据定义语言。
CREATE\ALTER\DROP\RENAME\TRUNCATE -
DML:数据操作语言。
INSERT\DELETE\UPDATE\SELECT(重中之重) -
DCL:数据控制语言。
COMMIT\ROLLBACK\SAVEPOINT\GRANT\REVOKE
2. SQL语言的规则与规范
2.1 基本规则
- SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进
- 每条命令以 ; 或 \g 或 \G 结束
- 关键字不能被缩写也不能分行
- 关于标点符号
- 必须保证所有的()、单引号、双引号是成对结束的
- 必须使用英文状态下的半角输入方式
- 字符串型和日期时间类型的数据可以使用单引号(’ ')表示
- 列的别名,尽量使用双引号(" "),而且不建议省略as
2.2 SQL大小写规范 (建议遵守)
- MySQL在Windows环境下是大小写不敏感的
- MySQL在Linux环境下是大小写敏感的
- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。
- 推荐采用统一的书写规范:
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
2.3 注 释
单行注释:#注释文字(MySQL特有的方式)
单行注释:-- 注释文字(--后面必须包含一个空格。)
多行注释:/* 注释文字 */
2.4 命名规则(暂时了解)
- 数据库、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名
- 必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用`(着重号)引起来
- 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
2.5 数据导入指令
在命令行客户端登录mysql,使用source指令导入
mysql> source d:\mysqldb.sql
3. 基本的SELECT语句
3.0 SELECT…
SELECT 1; #没有任何子句
SELECT 1 + 1,3 * 2
FROM DUAL; #dual:伪表
3.1 SELECT … FROM
- 语法:
SELECT 标识选择哪些列
FROM 标识从哪个表中选择
- 选择全部列:
SELECT *
FROM departments;
- 选择特定的列:
SELECT department_id, location_id
FROM departments;
3.2 列的别名
- 重命名一个列
- 便于计算
- 紧跟列名,也可以在列名和别名之间加入关键字AS,别名使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。
- AS 可以省略
- 建议别名简短,见名知意
SELECT last_name AS name, commission_pct comm
FROM employees;
SELECT last_name "Name", salary*12 "Annual Salary"
FROM employees;
3.3 去除重复行
在SELECT语句中使用关键字DISTINCT去除重复行
SELECT DISTINCT department_id,salary
FROM employees;
这里有两点需要注意:
-
DISTINCT需要放到所有列名的前面,如果写成SELECT salary, DISTINCT department_id FROM employees会报错。 -
DISTINCT其实是对后面所有列名的组合进行去重。如果你想要看都有哪些不同的部门(department_id),只需要写DISTINCT department_id即可,后面不需要再加其他的列名了。
3.4 空值参与运算
- 所有运算符或列值遇到null值,运算的结果都为null
SELECT employee_id,salary,commission_pct, 12 * salary * (1 + commission_pct) "annual_sal"
FROM employees;
在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
3.5 着重号
- 错误的
mysql> SELECT * FROM ORDER;
- 正确的
mysql> SELECT * FROM `ORDER`;
mysql> SELECT * FROM `order`;
- 结论
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在SQL语句中使用一对``(着重号)引起来。
3.6 查询常数
SELECT '尚硅谷' as corporation, last_name
FROM employees;
4. 显示表结构
使用DESCRIBE 或 DESC 命令,表示表结构。
DESCRIBE employees;
或
DESC employees;
5. 过滤数据
- 语法
- 使用WHERE 子句,将不满足条件的行过滤掉
- WHERE子句紧随FROM子句
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
- 举例
SELECT employee_id, last_name, job_id, department_id
FROM employees
WHERE department_id = 90;
第04章 运算符
1. 算术运算符
| 运算符 | 名称 | 作用 | 实例 |
|---|---|---|---|
| + | 加法运算符 | 计算两个值或表达式的和 | SELECT A + B |
| - | 减法运算符 | 计算两个值或表达式的差 | SELECT A - B |
| * | 乘法运算符 | 计算两个值或表达式的乘积 | SELECT A * B |
| / 或 DIV | 除法运算符 | 计算两个值或表达式的商 | SELECT A / B 或者 SELECT A DIV B |
| % 或 MOD | 求模(求余)运算符 | 计算两个值或表达式的余数 | SELECT A % B 或者 SELECT A MOD B |
加法与减法运算符结论:
- 一个整数类型的值对整数进行加法和减法操作,结果还是一个整数;
- 一个整数类型的值对浮点数进行加法和减法操作,结果是一个浮点数;
- 加法和减法的优先级相同,进行先加后减操作与进行先减后加操作的结果是一样的;
- 在Java中,+的左右两边如果有字符串,那么表示字符串的拼接。但是在MySQL中+只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算。(补充:MySQL中字符串拼接要使用字符串函数CONCAT()实现)
乘法与除法运算符结论:
- 一个数乘以整数1和除以整数1后仍得原数;
- 一个数乘以浮点数1和除以浮点数1后变成浮点数,数值与原数相等;
- 一个数除以整数后,不管是否能除尽,结果都为一个浮点数;
- 一个数除以另一个数,除不尽时,结果为一个浮点数,并保留到小数点后4位;
- 乘法和除法的优先级相同,进行先乘后除操作与先除后乘操作,得出的结果相同。
- 在数学运算中,0不能用作除数,在MySQL中,一个数除以0为NULL。
# 取模运算: % mod
SELECT 12 % 3,12 % 5, 12 MOD -5,-12 % 5,-12 % -5
FROM DUAL; # 结果的符号只与被模数有关
+--------+--------+-----------+---------+----------+
| 12 % 3 | 12 % 5 | 12 MOD -5 | -12 % 5 | -12 % -5 |
+--------+--------+-----------+---------+----------+
| 0 | 2 | 2 | -2 | -2 |
+--------+--------+-----------+---------+----------+
2. 比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。
| 运算符 | 名称 | 作用 | 示例 |
|---|---|---|---|
| = | 等于运算符 | 判断两个值、字符串或表达式是否相等 | SELECT C FROM TABLE WHERE A = B |
| <=> | 安全等于运算符 | 安全地判断两个值、字符串或表达式是否相等 | SELECT C FROM TABLE WHERE A <=> B |
| <> 或 != | 不等于运算符 | 判断两个值、字符串或表达式是否不相等 | SELECT C FROM TABLE WHERE A <> B |
| < | 小于运算符 | 判断前面的值、字符串或表达式是否小于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A < B |
| <= | 小于等于运算符 | 判断前面的值、字符串或表达式是否小于等于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A <= B |
| > | 大于运算符 | 判断前面的值、字符串或表达式是否大于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A > B |
| >= | 大于等于运算符 | 判断前面的值、字符串或表达式是否大于等于后面的值、字符串或表达式 | SELECT C FROM TABLE WHERE A >= B |
等号运算符
- 等号运算符(=)判断等号两边的值、字符串或表达式是否相等,如果相等则返回1,不相等则返回0。
- 在使用等号运算符时,遵循如下规则:
- 如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等。
- 如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小。
- 如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。
- 如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL。
安全等于运算符(为NULL而生)
安全等于运算符(<=>)与等于运算符(=)的作用是相似的, 唯一的区别是‘<=>’可以用来对NULL进行判断。在两个操作数均为NULL时,其返回值为1,而不为NULL;当一个操作数为NULL时,其返回值为0,而不为NULL。
不等于运算符
不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等,如果不相等则返回1,相等则返回0。不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL,或两边都为NULL,则结果为NULL。
| 运算符 | 名称 | 作用 | 示例 |
|---|---|---|---|
| IS NULL | 为空运算符 | 判断值、字符串或表达式是否为空 | SELECT B FROM TABLE WHERE A IS NULL |
| IS NOTNULL | 不为空运算符 | 判断值、字符串或表达式是否不为空 | SELECT B FROM TABLE WHERE A IS NOT NULL |
| LEAST | 最小值运算符 | 在多个值中返回最小值 | SELECT D FROM TABLE WHERE C LEAST(A, B) |
| GREATEST | 最大值运算符 | 在多个值中返回最大值 | SELECT D FROM TABLE WHERE C GREATEST(A, B) |
| BETWEEN … AND … | 两值之间的运算符 | 判断一个值是否在两个值之间 | SELECT D FROM TABLE WHERE C BETWEEN A AND B |
| ISNULL | 为空运算符 | 判断一个值、字符串或表达式是否为空 | SELECT B FROM TABLE WHERE A ISNULL |
| IN | 属于运算符 | 判断一个值是否为列表中的任意一个值 | SELECT D FROM TABLE WHERE C IN(A, B) |
| NOT IN | 不属于运算符 | 判断一个值是否不是一个列表中的任意一个值 | SELECT D FROM TABLE WHERE C NOT IN(A, B) |
| LIKE | 模糊匹配运算符 | 判断一个值是否符合模糊匹配规则 | SELECT C FROM TABLE WHERE A LIKE B |
| REGEXP | 正则表达式运算符 | 判断一个值是否符合正则表达式的规则 | SELECT C FROM TABLE WHERE A REGEXPB |
| RLIKE | 正则表达式运算符 | 判断一个值是否符合正则表达式的规则 | SELECT C FROM TABLE WHERE A RLIKEB |
空运算符
空运算符(IS NULL或者ISNULL)判断一个值是否为NULL,如果为NULL则返回1,否则返回0。
非空运算符
非空运算符(IS NOT NULL)判断一个值是否不为NULL,如果不为NULL则返回1,否则返回0。
最小值运算符
语法格式为:LEAST(值1,值2,…,值n)。其中,“值n”表示参数列表中有n个值。在有两个或多个参数的情况下,返回最小值。
当参数是整数或者浮点数时,LEAST将返回其中最小的值;当参数为字符串时,返回字母表中顺序最靠前的字符;当比较值列表中有NULL时,不能判断大小,返回值为NULL。
最大值运算符
语法格式为:GREATEST(值1,值2,…,值n)。其中,n表示参数列表中有n个值。当有两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值为NULL。
当参数中是整数或者浮点数时,GREATEST将返回其中最大的值;当参数为字符串时,返回字母表中顺序最靠后的字符;当比较值列表中有NULL时,不能判断大小,返回值为NULL。
BETWEEN AND运算符
BETWEEN运算符使用的格式通常为SELECT D FROM TABLE WHERE C BETWEEN A AND B,此时,当C大于或等于A,并且C小于或等于B时,结果为1,否则结果为0。
IN运算符
IN运算符用于判断给定的值是否是IN列表中的一个值,如果是则返回1,否则返回0。如果给定的值为NULL,或者IN列表中存在NULL,则结果为NULL。
NOT IN运算符
NOT IN运算符用于判断给定的值是否不是IN列表中的一个值,如果不是IN列表中的一个值,则返回1,否则返回0。列表中存在NULL,则结果为NULL。
LIKE运算符
LIKE运算符主要用来匹配字符串,通常用于模糊匹配,如果满足条件则返回1,否则返回0。如果给定的值或者匹配条件为NULL,则返回结果为NULL。
LIKE运算符通常使用如下通配符:
“%”:匹配0个或多个字符。
“_”:只能匹配一个字符。
#练习:查询last_name中包含字符'a'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%';
#练习:查询last_name中以字符'a'开头的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE 'a%';
#练习:查询第3个字符是'a'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';
ESCAPE
- 回避特殊符号的:使用转义符。
- 如果使用\表示转义,要省略ESCAPE。如果不是\,则要加上ESCAPE。
#练习:查询第2个字符是_且第3个字符是'a'的员工信息
#需要使用转义字符: \
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%';
#或者 (了解)
SELECT last_name
FROM employees
WHERE last_name LIKE '_$_a%' ESCAPE '$';
REGEXP运算符
REGEXP运算符用来匹配字符串,语法格式为:expr REGEXP 匹配条件。如果expr满足匹配条件,返回1;如果不满足,则返回0。若expr或匹配条件任意一个为NULL,则结果NULL。
(1)‘^’匹配以该字符后面的字符开头的字符串。
(2)‘$’匹配以该字符前面的字符结尾的字符串。
(3)‘.’匹配任何一个单字符。
(4)“[...]”匹配在方括号内的任何字符。例如,“[abc]”匹配“a”或“b”或“c”。为了命名字符的范围,使用一 个‘-’。“[a-z]”匹配任何字母,而“[0-9]”匹配任何数字。
(5)‘*’匹配零个或多个在它前面的字符。例如,“x*”匹配任何数量的‘x’字符,“[0-9]*”匹配任何数量的数字, 而“*”匹配任何数量的任何字符。
3. 逻辑运算符
| 运算符 | 作用 | 示例 |
|---|---|---|
| NOT 或 ! | 逻辑非 | SELECT NOT A |
| AND 或 && | 逻辑与 | SELECT A AND B |
| OR 或 || | 逻辑或 | SELECT A OR B |
| XOR | 逻辑异或 | SELECT A XOR B |
逻辑非运算符
逻辑非(NOT或!)运算符表示当给定的值为0时返回1;当给定的值为非0值时返回0;当给定的值为NULL时,返回NULL。
逻辑与运算符
逻辑与(AND或&&)运算符是当给定的所有值均为非0值,并且都不为NULL时,返回1;当给定的一个值或者多个值为0时则返回0;否则返回NULL。
逻辑或运算符
逻辑或(OR或||)运算符是当给定的值都不为NULL,并且任何一个值为非0值时,则返回1,否则返回0;当一个值为NULL,并且另一个值为非0值时,返回1,否则返回NULL;当两个值都为NULL时,返回NULL。
注意:OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
逻辑异或运算符
逻辑异或(XOR)运算符是当给定的值中任意一个值为NULL时,则返回NULL;如果两个非NULL的值都是0或者都不等于0时,则返回0;如果一个值为0,另一个值不为0时,则返回1。
4. 位运算符
| 运算符 | 作用 | 示例 |
|---|---|---|
| & | 按位与(位AND) | SELECT A & B |
| | | 按位或(位OR) | SELECT A | B |
| ^ | 按位异或(为XOR) | SELECT A ^ B |
| ~ | 按位取反 | SELECT ~A |
| >> | 按位右移 | SELECT A >> 2 |
| << | 按位左移 | SELECT B << 2 |
按位与运算符
按位与(&)运算符将给定值对应的二进制数逐位进行逻辑与运算。当给定值对应的二进制位的数值都为1时,则该位返回1,否则返回0。
按位或运算符
按位或(|)运算符将给定的值对应的二进制数逐位进行逻辑或运算。当给定值对应的二进制位的数值有一个或两个为1时,则该位返回1,否则返回0。
按位取反运算符
按位取反(~)运算符将给定的值的二进制数逐位进行取反操作,即将1变为0,将0变为1。
按位右移运算符
按位右移(>>)运算符将给定的值的二进制数的所有位右移指定的位数。右移指定的位数后,右边低位的数值被移出并丢弃,左边高位空出的位置用0补齐。
按位左移运算符
按位左移(<<)运算符将给定的值的二进制数的所有位左移指定的位数。左移指定的位数后,左边高位的数值被移出并丢弃,右边低位空出的位置用0补齐。
第05章 排序与分页
1. 排序数据
1.1 排序规则
- 使用 ORDER BY 子句排序
- ASC(ascend):升序
- DESC(descend):降序
- ORDER BY子句在SELECT语句的结尾。
# 单列排序
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary; # 如果在ORDER BY 后没有显式指名排序的方式的话,则默认按照升序排列。
# 我们可以使用列的别名,进行排序
SELECT employee_id,salary,salary * 12 annual_sal
FROM employees
ORDER BY annual_sal;
# 多列排序
SELECT employee_id,salary,department_id
FROM employees
ORDER BY department_id DESC,salary ASC;
- 可以使用不在SELECT列表中的列排序。
- 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
2. 分页
2.1 实现规则
- MySQL中使用LIMIT实现分页
- 格式:
LIMIT [位置偏移量,] 行数
- “偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1,以此类推);第二个参数“行数”指示返回的记录条数。
-- 前10条记录:
SELECT * FROM 表名 LIMIT 0,10;
或者
SELECT * FROM 表名 LIMIT 10;
-- 第11至20条记录:
SELECT * FROM 表名 LIMIT 10,10;
-- 第21至30条记录:
SELECT * FROM 表名 LIMIT 20,10;
MySQL 8.0中可以使用“LIMIT 3 OFFSET 4”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT 4,3;”返回的结果相同。
- 分页显式公式:*(当前页数-1)每页条数,每页条数
- 注意:LIMIT子句必须放在整个SELECT语句的最后!
第06章 多表查询
1. 一个案例引发的多表连接
1.1 笛卡尔积(或交叉连接)的理解
笛卡尔乘积是一个数学运算。假设我有两个集合 X 和 Y,那么 X 和 Y 的笛卡尔积就是 X 和 Y 的所有可能组合,也就是第一个对象来自于 X,第二个对象来自于 Y 的所有可能。组合的个数即为两个集合中元素个数的乘积数。
SQL92中,笛卡尔积也称为交叉连接,英文是CROSS JOIN。在 SQL99 中也是使用 CROSS JOIN表示交叉连接。它的作用就是可以把任意表进行连接,即使这两张表不相关。
#查询员工姓名和所在部门名称
SELECT last_name,department_name FROM employees,departments;
SELECT last_name,department_name FROM employees CROSS JOIN departments;
- 笛卡尔积的错误会在下面条件下产生:
- 省略多个表的连接条件(或关联条件)
- 连接条件(或关联条件)无效
- 所有表中的所有行互相连接
- 为了避免笛卡尔积, 可以在WHERE加入有效的连接条件。
2. 多表查询分类讲解
分类1:等值连接vs非等值连接
拓展1:区分重复的列名
- 多个表中有相同列时,必须在列名之前加上表名前缀。
拓展2:表的别名
- 使用别名可以简化查询。
- 列名前使用表名前缀可以提高查询效率。
需要注意的是,如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
拓展3:连接多个表
- 连接n个表,至少需要n-1个连接条件。
#非等值连接的例子
SELECT e.last_name,e.salary,j.grade_level
FROM employees e,job_grades j
#where e.`salary` between j.`lowest_sal` and j.`highest_sal`;
WHERE e.`salary` >= j.`lowest_sal` AND e.`salary` <= j.`highest_sal`;
分类2:自连接vs非自连接
#自连接的例子:
#练习:查询员工id,员工姓名及其管理者的id和姓名
SELECT emp.employee_id,emp.last_name,mgr.employee_id,mgr.last_name
FROM employees emp ,employees mgr
WHERE emp.`manager_id` = mgr.`employee_id`;
分类3:内连接 vs 外连接
-
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
-
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
- 如果是左外连接,则连接条件中左边的表也称为
主表,右边的表称为从表。 - 如果是右外连接,则连接条件中右边的表也称为
主表,左边的表称为从表。
- 如果是左外连接,则连接条件中左边的表也称为
3. SQL99语法实现多表查询
3.1 基本语法
- 使用JOIN…ON子句创建连接的语法结构:
SELECT table1.column, table2.column, table3.column
FROM table1 JOIN table2
ON table1 和 table2 的连接条件
JOIN table3
ON table2 和 table3 的连接条件
3.2 内连接(INNER JOIN)的实现
- 语法
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT last_name,department_name
FROM employees e INNER JOIN departments d
ON e.`department_id` = d.`department_id`;
3.3 外连接(OUTER JOIN)的实现
3.3.1 左外连接(LEFT OUTER JOIN)
- 语法:
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
3.3.2 右外连接(RIGHT OUTER JOIN)
- 语法:
SELECT 字段列表
FROM A表 RIGHT JOIN B表
ON 关联条件
WHERE 等其他子句;
SELECT last_name,department_name
FROM employees e RIGHT OUTER JOIN departments d
ON e.`department_id` = d.`department_id`;
4. UNION的使用
UNION操作符
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNION ALL操作符
UNION ALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询的效率。
5. 7种SQL JOINS的实现
5.1 举例
# 中图:内连接
SELECT employee_id,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
# 左上图:左外连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
# 右上图:右外连接
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
# 左中图:
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL;
# 右中图:
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
# 左下图:满外连接
# 方式1:左上图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
# 方式2:左中图 UNION ALL 右上图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
# 右下图:左中图 UNION ALL 右中图
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
5.2 语法格式小结
- 左中图
#实现A - A∩B
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
- 右中图
#实现B - A∩B
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句;
- 左下图
#实现查询结果是A∪B
#用左外的A,union 右外的B
select 字段列表
from A表 left join B表
on 关联条件
where 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 等其他子句;
- 右下图
#实现A∪B - A∩B 或 (A - A∩B) ∪ (B - A∩B)
#使用左外的 (A - A∩B) union 右外的(B - A∩B)
select 字段列表
from A表 left join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
union
select 字段列表
from A表 right join B表
on 关联条件
where 从表关联字段 is null and 等其他子句
6. SQL99语法新特性
6.1 自然连接
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
AND e.`manager_id` = d.`manager_id`;
# NATURAL JOIN : 它会帮你自动查询两张连接表中`所有相同的字段`,然后进行`等值连接`。
SELECT employee_id,last_name,department_name
FROM employees e NATURAL JOIN departments d;
6.2 USING连接
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
# 指定数据表里的同名字段进行等值连接,只能配合JOIN一起使用。
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
USING (department_id);
【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
第07章 单行函数
1. 数值函数
1.1 基本函数
| 函数 | 用法 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| SIGN(X) | 返回X的符号。正数返回1,负数返回-1,0返回0 |
| PI() | 返回圆周率的值 |
| CEIL(x),CEILING(x) | 返回大于或等于某个值的最小整数 |
| FLOOR(x) | 返回小于或等于某个值的最大整数 |
| LEAST(e1,e2,e3…) | 返回列表中的最小值 |
| GREATEST(e1,e2,e3…) | 返回列表中的最大值 |
| MOD(x,y) | 返回X除以Y后的余数 |
| RAND() | 返回0~1的随机值 |
| RAND(x) | 返回0~1的随机值,其中x的值用作种子值,相同的X值会产生相同的随机 |
| ROUND(x) | 返回一个对x的值进行四舍五入后,最接近于X的整数 |
| ROUND(x,y) | 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位 |
| TRUNCATE(x,y) | 返回数字x截断为y位小数的结果 |
| SQRT(x) | 返回x的平方根。当X的值为负数时,返回NULL |
1.2 角度与弧度
| 函数 | 用法 |
|---|---|
| RADIANS(x) | 将角度转化为弧度,其中,参数x为角度值 |
| DEGREES(x) | 将弧度转化为角度,其中,参数x为弧度值 |
1.3 三角函数
| 函数 | 用法 |
|---|---|
| SIN(x) | 返回x的正弦值,其中,参数x为弧度值 |
| ASIN(x) | 返回x的反正弦值,即获取正弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| COS(x) | 返回x的余弦值,其中,参数x为弧度值 |
| ACOS(x) | 返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| TAN(x) | 返回x的正切值,其中,参数x为弧度值 |
| ATAN(x) | 返回x的反正切值,即返回正切值为x的值 |
| ATAN2(m,n) | 返回两个参数的反正切值 |
| COT(x) | 返回x的余切值,其中,X为弧度值 |
1.4 指数与对数
| 函数 | 用法 |
|---|---|
| POW(x,y),POWER(X,Y) | 返回x的y次方 |
| EXP(X) | 返回e的X次方,其中e是一个常数,2.718281828459045 |
| LN(X),LOG(X) | 返回以e为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG10(X) | 返回以10为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG2(X) | 返回以2为底的X的对数,当X <= 0 时,返回NULL |
1.5 进制间的转换
| 函数 | 用法 |
|---|---|
| BIN(x) | 返回x的二进制编码 |
| HEX(x) | 返回x的十六进制编码 |
| OCT(x) | 返回x的八进制编码 |
| CONV(x,f1,f2) | 返回f1进制数变成f2进制数 |
2. 字符串函数
| 函数 | 用法 |
|---|---|
| ASCII(S) | 返回字符串S中的第一个字符的ASCII码值 |
| CHAR_LENGTH(s) | 返回字符串s的字符数。作用与CHARACTER_LENGTH(s)相同 |
| LENGTH(s) | 返回字符串s的字节数,和字符集有关 |
| CONCAT(s1,s2,…,sn) | 连接s1,s2,…,sn为一个字符串 |
| CONCAT_WS(x,s1,s2,…,sn) | 同CONCAT(s1,s2,…)函数,但是每个字符串之间要加上x |
| INSERT(str, idx, len,replacestr) | 将字符串str从第idx位置开始,len个字符长的子串替换为字符串replacestr |
| REPLACE(str, a, b) | 用字符串b替换字符串str中所有出现的字符串a |
| UPPER(s) 或 UCASE(s) | 将字符串s的所有字母转成大写字母 |
| LOWER(s) 或LCASE(s) | 将字符串s的所有字母转成小写字母 |
| LEFT(str,n) | 返回字符串str最左边的n个字符 |
| RIGHT(str,n) | 返回字符串str最右边的n个字符 |
| LPAD(str, len, pad) | 用字符串pad对str最左边进行填充,直到str的长度为len个字符,实现右对齐效果 |
| RPAD(str ,len, pad) | 用字符串pad对str最右边进行填充,直到str的长度为len个字符,实现左对齐效果 |
| LTRIM(s) | 去掉字符串s左侧的空格 |
| RTRIM(s) | 去掉字符串s右侧的空格 |
| TRIM(s) | 去掉字符串s开始与结尾的空格 |
| TRIM(s1 FROM s) | 去掉字符串s开始与结尾的s1 |
| TRIM(LEADING s1 FROM s) | 去掉字符串s开始处的s1 |
| TRIM(TRAILING s1 FROM s) | 去掉字符串s结尾处的s1 |
| REPEAT(str, n) | 返回str重复n次的结果 |
| SPACE(n) | 返回n个空格 |
| STRCMP(s1,s2) | 比较字符串s1,s2的ASCII码值的大小 |
| SUBSTR(s,index,len) | 返回从字符串s的index位置其len个字符,作用与SUBSTRING(s,n,len)、MID(s,n,len)相同 |
| LOCATE(substr,str) | 返回字符串substr在字符串str中首次出现的位置,作用于POSITION(substr IN str)、INSTR(str,substr)相同。未找到,返回0 |
| ELT(m,s1,s2,…,sn) | 返回指定位置的字符串,如果m=1,则返回s1,如果m=2,则返回s2,如果m=n,则返回sn |
| FIELD(s,s1,s2,…,sn) | 返回字符串s在字符串列表中第一次出现的位置 |
| FIND_IN_SET(s1,s2) | 返回字符串s1在字符串s2中出现的位置。其中,字符串s2是一个以逗号分隔的字符串 |
| REVERSE(s) | 返回s反转后的字符串 |
| NULLIF(value1,value2) | 比较两个字符串,如果value1与value2相等,则返回NULL,否则返回value1 |
注意:MySQL中,字符串的位置是从1开始的。
3. 日期和时间函数
3.1 获取日期、时间
| 函数 | 用法 |
|---|---|
| CURDATE() ,CURRENT_DATE() | 返回当前日期,只包含年、月、日 |
| CURTIME() , CURRENT_TIME() | 返回当前时间,只包含时、分、秒 |
| NOW() / SYSDATE() / CURRENT_TIMESTAMP() / LOCALTIME() / LOCALTIMESTAMP() | 返回当前系统日期和时间 |
| UTC_DATE() | 返回UTC(世界标准时间)日期 |
| UTC_TIME() | 返回UTC(世界标准时间)时间 |
3.2 日期与时间戳的转换
| 函数 | 用法 |
|---|---|
| UNIX_TIMESTAMP() | 以UNIX时间戳的形式返回当前时间。SELECT UNIX_TIMESTAMP() ->1634348884 |
| UNIX_TIMESTAMP(date) | 将时间date以UNIX时间戳的形式返回。 |
| FROM_UNIXTIME(timestamp) | 将UNIX时间戳的时间转换为普通格式的时间 |
3.3 获取月份、星期、星期数、天数等函数
| 函数 | 用法 |
|---|---|
| YEAR(date) / MONTH(date) / DAY(date) | 返回具体的日期值 |
| HOUR(time) / MINUTE(time) / SECOND(time) | 返回具体的时间值 |
| MONTHNAME(date) | 返回月份:January,… |
| DAYNAME(date) | 返回星期几:MONDAY,TUESDAY…SUNDAY |
| WEEKDAY(date) | 返回周几,注意,周1是0,周2是1,。。。周日是6 |
| QUARTER(date) | 返回日期对应的季度,范围为1~4 |
| WEEK(date) , WEEKOFYEAR(date) | 返回一年中的第几周 |
| DAYOFYEAR(date) | 返回日期是一年中的第几天 |
| DAYOFMONTH(date) | 返回日期位于所在月份的第几天 |
| DAYOFWEEK(date) | 返回周几,注意:周日是1,周一是2,。。。周六是7 |
3.4 日期的操作函数
| 函数 | 用法 |
|---|---|
| EXTRACT(type FROM date) | 返回指定日期中特定的部分,type指定返回的值 |
EXTRACT(type FROM date)函数中type的取值与含义:
| type取值 | 含义 |
|---|---|
| MICROSECOND | 返回毫秒数 |
| SECOND | 返回秒数 |
| MINUTE | 返回分钟数 |
| HOUR | 返回小时数 |
| DAY | 返回天数 |
| WEEK | 返回日期在一年中的第几个星期 |
| MONTH | 返回日期在一年中的第几个月 |
| QUARTER | 返回日期在一年中的第几个季度 |
| YEAR | 返回日期的年份 |
| SECOND_MICROSECOND | 返回秒和毫秒值 |
| MINUTE_MICROSECOND | 返回分钟和毫秒值 |
| MINUTE_SECOND | 返回分钟和秒值 |
| HOUR_MICROSECOND | 返回小时和毫秒值 |
| HOUR_SECOND | 返回小时和秒值 |
| HOUR_MINUTE | 返回小时和分钟值 |
| DAY_MICROSECOND | 返回天和毫秒值 |
| DAY_SECOND | 返回天和秒值 |
| DAY_MINUTE | 返回天和分钟值 |
| DAY_HOUR | 返回天和小时 |
| YEAR_MONTH | 返回年和月 |
3.5 时间和秒钟转换的函数
| 函数 | 用法 |
|---|---|
| TIME_TO_SEC(time) | 将 time 转化为秒并返回结果值。转化的公式为: 小时*3600+分钟*60+秒 |
| SEC_TO_TIME(seconds) | 将 seconds 描述转化为包含小时、分钟和秒的时间 |
3.6 计算日期和时间的函数
| 函数 | 用法 |
|---|---|
| DATE_ADD(datetime, INTERVAL expr type),ADDDATE(date,INTERVAL expr type) | 返回与给定日期时间相差INTERVAL时间段的日期时间 |
| DATE_SUB(date,INTERVAL expr type),SUBDATE(date,INTERVAL expr type) | 返回与date相差INTERVAL时间间隔的日期 |
上述函数中type的取值:
| 间隔类型 | 含义 |
|---|---|
| HOUR | 小时 |
| MINUTE | 分钟 |
| SECOND | 秒 |
| YEAR | 年 |
| MONTH | 月 |
| DAY | 日 |
| YEAR_MONTH | 年和月 |
| DAY_HOUR | 日和小时 |
| DAY_MINUTE | 日和分钟 |
| DAY_SECOND | 日和秒 |
| HOUR_MINUTE | 小时和分钟 |
| HOUR_SECOND | 小时和秒 |
| MINUTE_SECOND | 分钟和秒 |
| 函数 | 用法 |
|---|---|
| ADDTIME(time1,time2) | 返回time1加上time2的时间。当time2为一个数字时,代表的是秒 ,可以为负数 |
| SUBTIME(time1,time2) | 返回time1减去time2后的时间。当time2为一个数字时,代表的是秒,可以为负数 |
| DATEDIFF(date1,date2) | 返回date1 - date2的日期间隔天数 |
| TIMEDIFF(time1, time2) | 返回time1 - time2的时间间隔 |
| FROM_DAYS(N) | 返回从0000年1月1日起,N天以后的日期 |
| TO_DAYS(date) | 返回日期date距离0000年1月1日的天数 |
| LAST_DAY(date) | 返回date所在月份的最后一天的日期 |
| MAKEDATE(year,n) | 针对给定年份与所在年份中的天数返回一个日期 |
| MAKETIME(hour,minute,second) | 将给定的小时、分钟和秒组合成时间并返回 |
| PERIOD_ADD(time,n) | 返回time加上n后的时间 |
3.7 日期的格式化与解析
| 函数 | 用法 |
|---|---|
| DATE_FORMAT(date,fmt) | 按照字符串fmt格式化日期date值 |
| TIME_FORMAT(time,fmt) | 按照字符串fmt格式化时间time值 |
| GET_FORMAT(date_type,format_type) | 返回日期字符串的显示格式 |
| STR_TO_DATE(str, fmt) | 按照字符串fmt对str进行解析,解析为一个日期 |
上述非GET_FORMAT函数中fmt参数常用的格式符:
| 格式符 | 说明 | 格式符 | 说明 |
|---|---|---|---|
| %Y | 4位数字表示年份 | %y | 表示两位数字表示年份 |
| %M | 月名表示月份(January,…) | %m | 两位数字表示月份(01,02,03。。。) |
| %b | 缩写的月名(Jan.,Feb.,…) | %c | 数字表示月份(1,2,3,…) |
| %D | 英文后缀表示月中的天数(1st,2nd,3rd,…) | %d | 两位数字表示月中的天数(01,02…) |
| %e | 数字形式表示月中的天数(1,2,3,4,5…) | ||
| %H | 两位数字表示小数,24小时制(01,02…) | %h和%I | 两位数字表示小时,12小时制(01,02…) |
| %k | 数字形式的小时,24小时制(1,2,3) | %l | 数字形式表示小时,12小时制(1,2,3,4…) |
| %i | 两位数字表示分钟(00,01,02) | %S和%s | 两位数字表示秒(00,01,02…) |
| %W | 一周中的星期名称(Sunday…) | %a | 一周中的星期缩写(Sun.,Mon.,Tues.,…) |
| %w | 以数字表示周中的天数(0=Sunday,1=Monday…) | ||
| %j | 以3位数字表示年中的天数(001,002…) | %U | 以数字表示年中的第几周,(1,2,3。。)其中Sunday为周中第一天 |
| %u | 以数字表示年中的第几周,(1,2,3。。)其中Monday为周中第一天 | ||
| %T | 24小时制 | %r | 12小时制 |
| %p | AM或PM | %% | 表示% |
GET_FORMAT函数中date_type和format_type参数取值如下:
| 日期类型 | 格式化类型 | 返回的格式化字符串 |
|---|---|---|
| DATE | USA | %m.%d.%Y |
| DATE | JIS | %Y-%m-%d |
| DATE | ISO | %Y-%m-%d |
| DATE | EUR | %d.%m.%Y |
| DATE | INTERNAL | %Y%m%d |
| TIME | USA | %h:%i:%s %P |
| TIME | JIS | %H:%i:%s |
| TIME | ISO | %H:%i:%s |
| TIME | EUR | %H.%i.%s |
| TIME | INTERNAL | %H%i%s |
| DATETIME | USA | %Y-%m-%d %H.%i.%s |
| DATETIME | JIS | %Y-%m-%d %H:%i:%s |
| DATETIME | ISO | %Y-%m-%d %H:%i:%s |
| DATETIME | EUR | %Y-%m-%d %H.%i.%s |
| DATETIME | INTERNAL | %Y%m%d%H%i%s |
4. 流程控制函数
| 函数 | 用法 |
|---|---|
| IF(value,value1,value2) | 如果value的值为TRUE,返回value1,否则返回value2 |
| IFNULL(value1, value2) | 如果value1不为NULL,返回value1,否则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2… [ELSE resultn] END | 相当于Java的if…else if…else… |
| CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 … [ELSE 值n] END | 相当于Java的switch…case… |
5. 加密与解密函数
| 函数 | 用法 |
|---|---|
| PASSWORD(str) | 返回字符串str的加密版本,41位长的字符串。加密结果不可逆,常用于用户的密码加密。在mysql8.0中已弃用。 |
| MD5(str) | 返回字符串str的md5加密后的值,也是一种加密方式。若参数为NULL,则会返回NULL |
| SHA(str) | 从原明文密码str计算并返回加密后的密码字符串,当参数为NULL时,返回NULL。 SHA加密算法比MD5更加安全 。 |
| ENCODE(value,password_seed) | 返回使用password_seed作为加密密码加密value,在mysql8.0中已弃用。 |
| DECODE(value,password_seed) | 返回使用password_seed作为加密密码解密value,在mysql8.0中已弃用。 |
6. MySQL信息函数
| 函数 | 用法 |
|---|---|
| VERSION() | 返回当前MySQL的版本号 |
| CONNECTION_ID() | 返回当前MySQL服务器的连接数 |
| DATABASE(),SCHEMA() | 返回MySQL命令行当前所在的数据库 |
| USER(),CURRENT_USER()、SYSTEM_USER(),SESSION_USER() | 返回当前连接MySQL的用户名,返回结果格式为“主机名@用户名” |
| CHARSET(value) | 返回字符串value自变量的字符集 |
| COLLATION(value) | 返回字符串value的比较规则 |
7. 其他函数
| 函数 | 用法 |
|---|---|
| FORMAT(value,n) | 返回对数字value进行格式化后的结果数据。n表示四舍五入后保留到小数点后n位 |
| CONV(value,from,to) | 将value的值进行不同进制之间的转换 |
| INET_ATON(ipvalue) | 将以点分隔的IP地址转化为一个数字 |
| INET_NTOA(value) | 将数字形式的IP地址转化为以点分隔的IP地址 |
| BENCHMARK(n,expr) | 将表达式expr重复执行n次。用于测试MySQL处理expr表达式所耗费的时间 |
| CONVERT(value USING char_code) | 将value所使用的字符编码修改为char_code |
第08章 聚合函数
1. 聚合函数介绍
1.1 AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数。
mysql> SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
-> FROM employees
-> WHERE job_id LIKE '%REP%';
+-------------+-------------+-------------+-------------+
| AVG(salary) | MAX(salary) | MIN(salary) | SUM(salary) |
+-------------+-------------+-------------+-------------+
| 8272.727273 | 11500.00 | 6000.00 | 273000.00 |
+-------------+-------------+-------------+-------------+
1.2 MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
mysql> SELECT MIN(hire_date), MAX(hire_date)
-> FROM employees;
+----------------+----------------+
| MIN(hire_date) | MAX(hire_date) |
+----------------+----------------+
| 1987-06-17 | 2000-04-21 |
+----------------+----------------+
1.3 COUNT函数
- COUNT(*)返回表中记录总数,适用于任意数据类型。
mysql> SELECT COUNT(*)
-> FROM employees
-> WHERE department_id = 50;
+----------+
| COUNT(*) |
+----------+
| 45 |
+----------+
- COUNT(expr) 返回expr不为NULL的记录总数。
mysql> SELECT COUNT(commission_pct)
-> FROM employees
-> WHERE department_id = 50;
+-----------------------+
| COUNT(commission_pct) |
+-----------------------+
| 0 |
+-----------------------+
- 问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
- 问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代count(*),count(*) 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2. GROUP BY
2.1 基本使用
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
明确:WHERE一定放在FROM后面
在SELECT列表中所有未包含在组函数中的列都应该包含在GROUP BY子句中
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
SELECT AVG(salary)
FROM employees
GROUP BY department_id;
2.2 使用多个列分组
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id;
2.3 GROUP BY中使用WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
SELECT department_id,AVG(salary)
FROM employees
WHERE department_id > 80
GROUP BY department_id WITH ROLLUP;
注意:
当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
3. HAVING
3.1 基本使用
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000;
- 非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。
mysql> SELECT department_id, AVG(salary)
-> FROM employees
-> WHERE AVG(salary) > 8000
-> GROUP BY department_id;
ERROR 1111 (HY000): Invalid use of group function
结论:
当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。但是,建议大家声明在WHERE中。
3.2 WHERE和HAVING的对比
| 优点 | 缺点 | |
|---|---|---|
| WHERE | 先筛选数据再关联,执行效率高 | 不能使用分组中的计算函数进行筛选 |
| HAVING | 可以使用分组中的计算函数 | 在最后的结果集中进行筛选,执行效率较低 |
4. SELECT的执行过程
4.1 查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
4.2 SELECT执行顺序
你需要记住 SELECT 查询时的两个顺序:
1. 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
#FROM ...,...-> ON -> (LEFT/RIGNT JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
4.3 SQL 的执行原理
SELECT 是先执行 FROM 这一步的。在这个阶段,如果是多张表联查,还会经历下面的几个步骤:
-
首先先通过 CROSS JOIN 求笛卡尔积,相当于得到虚拟表 vt(virtual table)1-1;
-
通过 ON 进行筛选,在虚拟表 vt1-1 的基础上进行筛选,得到虚拟表 vt1-2;
-
添加外部行。如果我们使用的是左连接、右连接或者全连接,就会涉及到外部行,也就是在虚拟表 vt1-2 的基础上增加外部行,得到虚拟表 vt1-3。
当然如果我们操作的是两张以上的表,还会重复上面的步骤,直到所有表都被处理完为止。这个过程得到是我们的原始数据。
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表vt1,就可以在此基础上再进行WHERE阶段 。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表vt2。
然后进入第三步和第四步,也就是GROUP和HAVING阶段 。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4。
当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到SELECT和DISTINCT阶段 。
首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表vt5-1和vt5-2。
当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是ORDER BY阶段 ,得到虚拟表vt6。
最后在 vt6 的基础上,取出指定行的记录,也就是LIMIT阶段 ,得到最终的结果,对应的是虚拟表vt7。
当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
第09章 子查询
1. 需求分析与问题解决
1.1 实际问题
题目:谁的工资比Abel高?
#方式一:
SELECT salary
FROM employees
WHERE last_name = 'Abel';
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
#方式二:自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e1.`salary` < e2.`salary`
#方式三:子查询
SELECT last_name,salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
1.2 子查询的基本使用
- 子查询(内查询)在主查询之前一次执行完成。
- 子查询的结果被主查询(外查询)使用 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
1.3 子查询的分类
分类方式1:
我们按内查询的结果返回一条还是多条记录,将子查询分为单行子查询、多行子查询。
分类方式2:
我们按内查询是否被执行多次,将子查询划分为相关(或关联)子查询和不相关(或非关联)子查询。
2. 单行子查询
2.1 单行比较操作符
| 操作符 | 含义 |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
2.2 代码示例
题目:返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name, job_id, salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);
2.3 HAVING 中的子查询
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) > (
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
);
2.4 CASE中的子查询
题目:显示员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’。
SELECT employee_id, last_name, (
CASE department_id
WHEN (
SELECT department_id
FROM departments
WHERE location_id = 1800
) THEN 'Canada' ELSE 'USA' END
) location
FROM employees;
2.5 子查询中的空值问题
mysql> SELECT last_name, job_id
-> FROM employees
-> WHERE job_id = (
-> SELECT job_id
-> FROM employees
-> WHERE last_name = 'Haas'
-> );
Empty set (0.01 sec)
子查询不返回任何行
2.6 非法使用子查询
mysql> SELECT employee_id, last_name
-> FROM employees
-> WHERE salary = ( # 多行子查询使用单行比较符
-> SELECT MIN(salary)
-> FROM employees
-> GROUP BY department_id
-> );
ERROR 1242 (21000): Subquery returns more than 1 row
3. 多行子查询
3.1 多行比较操作符
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
3.2 代码示例
题目:查询平均工资最低的部门id
#方式1:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_sal)
FROM (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) dept_avg_sal
);
#方式2:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
);
MySQL中聚合函数是不能嵌套使用的。
3.3 空值问题
mysql> SELECT last_name
-> FROM employees
-> WHERE employee_id NOT IN (
-> SELECT manager_id
-> FROM employees
-> );
Empty set (0.01 sec)
4. 相关子查询
4.1 相关子查询执行流程
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询。
4.2 代码示例
题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
方式一:相关子查询
SELECT last_name, salary, department_id
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id
);
方式二:在 FROM 中使用子查询
SELECT last_name,salary,e1.department_id
FROM employees e1,(
SELECT department_id,AVG(salary) dept_avg_sal
FROM employees
GROUP BY department_id
) e2
WHERE e1.`department_id` = e2.department_id
AND e2.dept_avg_sal < e1.`salary`;
在ORDER BY 中使用子查询:
题目:查询员工的id,salary,按照department_name排序
SELECT employee_id,salary
FROM employees e
ORDER BY (
SELECT department_name
FROM departments d
WHERE e.`department_id` = d.`department_id`
);
结论:在SELECT中,除了GROUP BY 和 LIMIT之外,其他位置都可以声明子查询!
4.3 EXISTS与NOT EXISTS关键字
- 关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
- 如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
- 如果在子查询中存在满足条件的行:
- 不在子查询中继续查找
- 条件返回 TRUE
- NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
方式一:
SELECT employee_id, last_name, job_id, department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e2.manager_id = e1.employee_id
);
方式二:自连接
SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id
FROM employees e1 JOIN employees e2
WHERE e1.employee_id = e2.manager_id;
方式三:
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN (
SELECT DISTINCT manager_id
FROM employees
);
题目:查询departments表中,不存在于employees表中的部门的department_id和department_name
SELECT department_id,department_name
FROM departments d
WHERE NOT EXISTS (
SELECT *
FROM employees e
WHERE d.`department_id` = e.`department_id`
);
题目中可以使用子查询,也可以使用自连接。一般情况建议你使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
第10章 创建和管理表
1. 基础知识
1.1 标识符命名规则
- 数据库名、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名
- 必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用`(着重号)引起来
- 保持字段名和类型的一致性:在命名字段并为其指定数据类型的时候一定要保证一致性,假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
2. 创建和管理数据库
2.1 创建数据库
- 方式1:创建数据库
CREATE DATABASE 数据库名;
- 方式2:创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
- 方式3:判断数据库是否已经存在,不存在则创建数据库(
推荐)
CREATE DATABASE IF NOT EXISTS 数据库名;
注意:DATABASE 不能改名。一些可视化工具可以改名,它是建新库,把所有表复制到新库,再删旧库完成的
2.2 使用数据库
- 查看当前所有的数据库
SHOW DATABASES; #有一个S,代表多个数据库
- 查看当前正在使用的数据库
SELECT DATABASE(); #使用的一个 mysql 中的全局函数
- 查看指定库下所有的表
SHOW TABLES FROM 数据库名;
- 查看数据库的创建信息
SHOW CREATE DATABASE 数据库名;
或者:
SHOW CREATE DATABASE 数据库名\G
- 使用/切换数据库
USE 数据库名;
注意:要操作表格和数据之前必须先说明是对哪个数据库进行操作,否则就要对所有对象加上“数据库名.”。
2.3 修改数据库
- 更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
2.4 删除数据库
- 方式1:删除指定的数据库
DROP DATABASE 数据库名;
- 方式2:删除指定的数据库(
推荐)
DROP DATABASE IF EXISTS 数据库名;
3. 创建表
3.1 创建方式1
- 必须具备:
- CREATE TABLE权限
- 存储空间
- 语法格式:
CREATE TABLE [IF NOT EXISTS] 表名(
字段1 数据类型 [约束条件] [默认值],
字段2 数据类型 [约束条件] [默认值],
字段3 数据类型 [约束条件] [默认值],
……
[表约束条件]
);
加上了IF NOT EXISTS关键字,则表示:如果当前数据库中不存在要创建的数据表,则创建数据表;如果当前数据库中已经存在要创建的数据表,则忽略建表语句,不再创建数据表。
3.2 创建方式2
- 使用 AS subquery 选项,将创建表和插入数据结合起来
CREATE TABLE table [(column, column...)]
AS subquery;
- 指定的列和子查询中的列要一一对应
- 通过列名和默认值定义列
CREATE TABLE emp1 AS SELECT * FROM employees;
CREATE TABLE emp2 AS SELECT * FROM employees WHERE 1=2; -- 创建的emp2是空表
3.3 查看数据表结构
在MySQL中创建好数据表之后,可以查看数据表的结构。MySQL支持使用DESCRIBE/DESC 语句查看数据表结构,也支持使用SHOW CREATE TABLE语句查看数据表结构。
语法格式如下:
SHOW CREATE TABLE 表名\G
使用SHOW CREATE TABLE语句不仅可以查看表创建时的详细语句,还可以查看存储引擎和字符编码。
4. 修改表
4.1 追加一个列
语法格式如下:
ALTER TABLE 表名
ADD [COLUMN] 字段名 字段类型 [FIRST|AFTER 字段名];
4.2 修改一个列
- 修改字段数据类型、长度、默认值、位置的语法格式如下:
ALTER TABLE 表名
MODIFY [COLUMN] 字段名1 字段类型 [DEFAULT 默认值][FIRST|AFTER 字段名 2];
- 对默认值的修改只影响今后对表的修改
4.3 重命名一个列
- 语法格式如下:
ALTER TABLE 表名
CHANGE [column] 列名 新列名 新数据类型;
4.4 删除一个列
- 语法格式如下:
ALTER TABLE 表名
DROP [COLUMN] 字段名;
5. 重命名表
- 方式一:使用RENAME(
推荐)
RENAME TABLE emp TO myemp;
- 方式二:
ALTER table dept
RENAME [TO] detail_dept; -- [TO]可以省略
6. 删除表
- 在MySQL中,当一张数据表
没有与其他任何数据表形成关联关系时,可以将当前数据表直接删除。 - 数据和结构都被删除
- 所有正在运行的相关事务被提交
- 所有相关索引被删除
- 语法格式:
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
IF EXISTS的含义为:如果当前数据库中存在相应的数据表,则删除数据表;如果当前数据库中不存在相应的数据表,则忽略删除语句,不再执行删除数据表的操作。
- DROP TABLE 语句不能回滚
7. 清空表
- TRUNCATE TABLE语句:
- 删除表中所有的数据
- 释放表的存储空间
- 举例:
TRUNCATE TABLE detail_dept;
- TRUNCATE语句不能回滚,而使用 DELETE 语句删除数据,可以回滚
- COMMIT:提交数据。一旦执行COMMIT,则数据就被永久的保存在了数据库中,意味着数据不可以回滚。
- ROLLBACK:回滚数据。一旦执行ROLLBACK,则可以实现数据的回滚。回滚到最近的一次COMMIT之后。
SET autocommit = FALSE;
DELETE FROM emp2;
#TRUNCATE TABLE emp2;
SELECT * FROM emp2;
ROLLBACK;
SELECT * FROM emp2;
DDL 和 DML 的说明
-
DDL的操作一旦执行,就不可回滚。指令SET autocommit = FALSE对DDL操作失效。(因为在执行完DDL操作之后,一定会执行一次COMMIT。而此COMMIT操作不受SET autocommit = FALSE影响的。)
-
DML的操作默认情况,一旦执行,也是不可回滚的。但是,如果在执行DML之前,执行了 SET autocommit = FALSE,则执行的DML操作就可以实现回滚。
阿里开发规范:
【参考】TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无事务且不触发 TRIGGER,有可能造成事故,故不建议在开发代码中使用此语句。
说明:TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。
8. 内容拓展
拓展1:阿里巴巴《Java开发手册》之MySQL字段命名
-
【
强制】表名、字段名必须使用小写字母或数字,禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。- 正例:aliyun_admin,rdc_config,level3_name
- 反例:AliyunAdmin,rdcConfig,level_3_name
-
【
强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。 -
【
强制】表必备三字段:id, gmt_create, gmt_modified。- 说明:其中 id 必为主键,类型为BIGINT UNSIGNED、单表时自增、步长为 1。gmt_create, gmt_modified 的类型均为 DATETIME 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新
-
【
推荐】表的命名最好是遵循 “业务名称_表的作用”。- 正例:alipay_task 、 force_project、 trade_config
-
【
推荐】库名与应用名称尽量一致。 -
【参考】合适的字符存储长度,不但节约数据库表空间、节约索引存储,更重要的是提升检索速度。
拓展2:如何理解清空表、删除表等操作需谨慎?!
表删除操作将把表的定义和表中的数据一起删除,并且MySQL在执行删除操作时,不会有任何的确认信息提示,因此执行删除操作时应当慎重。在删除表前,最好对表中的数据进行备份,这样当操作失误时可以对数据进行恢复,以免造成无法挽回的后果。
同样的,在使用ALTER TABLE进行表的基本修改操作时,在执行操作过程之前,也应该确保对数据进行完整的备份,因为数据库的改变是无法撤销的,如果添加了一个不需要的字段,可以将其删除;相同的,如果删除了一个需要的列,该列下面的所有数据都将会丢失。
拓展3:MySQL8新特性—DDL的原子化
在MySQL 8.0版本中,InnoDB表的DDL支持事务完整性,即DDL操作要么成功要么回滚。DDL操作回滚日志写入到data dictionary数据字典表mysql.innodb_ddl_log(该表是隐藏的表,通过show tables无法看到)中,用于回滚操作。通过设置参数,可将DDL操作日志打印输出到MySQL错误日志中。
第11章 数据处理之增删改
1. 插入数据
1.1 方式1:VALUES的方式添加
使用这种语法一次只能向表中插入一条数据。
情况1:为表的所有字段按默认顺序插入数据
INSERT INTO 表名
VALUES (value1,value2,....);
值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
情况2:为表的指定字段插入数据(推荐)
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES (value1 [,value2, …, valuen]);
为表的指定字段插入数据,就是在INSERT语句中只向部分字段中插入值,而其他字段的值为表定义时的默认值。
情况3:同时插入多条记录(推荐)
INSERT语句可以同时向数据表中插入多条记录,插入时指定多个值列表,每个值列表之间用逗号分隔开,基本语法格式如下:
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
或者
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
一个同时插入多行记录的INSERT语句等同于多个单行插入的INSERT语句,但是多行的INSERT语句在处理过程中
效率更高。因为MySQL执行单条INSERT语句插入多行数据比使用多条INSERT语句快,所以在插入多条记录时最好选择使用单条INSERT语句的方式插入。VALUES 也可以写成 VALUE ,但是VALUES是标准写法。
1.2 方式2:将查询结果插入到表中
INSERT还可以将SELECT语句查询的结果插入到表中,此时不需要把每一条记录的值一个一个输入,只需要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速地从一个或多个表中向一个表中插入多行。
基本语法格式如下:
INSERT INTO 目标表名 (tar_column1 [, tar_column2, …, tar_columnn])
SELECT (src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
举例:
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
说明:emp2表中要添加数据的字段的长度不能低于employees表中查询的字段的长度。
如果emp2表中要添加数据的字段的长度低于employees表中查询的字段的长度的话,就有添加不成功的风险。
2. 更新数据
- 使用 UPDATE 语句更新数据。语法如下:
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
- 可以一次更新多条数据。
- 如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
- 使用 WHERE 子句指定需要更新的数据。
- 如果省略 WHERE 子句,则表中的所有数据都将被更新。
3. 删除数据
- 使用 DELETE 语句从表中删除数据
DELETE FROM table_name [WHERE <condition>];
- 使用 WHERE 子句删除指定的记录。
- 如果省略 WHERE 子句,则表中的全部数据将被删除
4. MySQL8新特性:计算列
什么叫计算列呢?简单来说就是某一列的值是通过别的列计算得来的。例如,a列值为1、b列值为2,c列不需要手动插入,定义a+b的结果为c的值,那么c就是计算列,是通过别的列计算得来的。
在MySQL 8.0中,CREATE TABLE 和 ALTER TABLE 中都支持增加计算列。下面以CREATE TABLE为例进行讲解。
举例:定义数据表tb1,然后定义字段id、字段a、字段b和字段c,其中字段c为计算列,用于计算a+b的值。 首先创建测试表tb1,语句如下:
CREATE TABLE tb1(
id INT,
a INT,
b INT,
c INT GENERATED ALWAYS AS (a + b) VIRTUAL
);
插入演示数据,语句如下:
INSERT INTO tb1(a,b) VALUES (100,200);
查询数据表tb1中的数据,结果如下:
mysql> SELECT * FROM tb1;
+------+------+------+------+
| id | a | b | c |
+------+------+------+------+
| NULL | 100 | 200 | 300 |
+------+------+------+------+
更新数据中的数据,语句如下:
mysql> UPDATE tb1 SET a = 500;
mysql> SELECT * FROM tb1;
+------+------+------+------+
| id | a | b | c |
+------+------+------+------+
| NULL | 500 | 200 | 700 |
+------+------+------+------+
第12章 MySQL数据类型精讲
1. MySQL中的数据类型
| 类型 | 类型举例 |
|---|---|
| 整数类型 | TINYINT、SMALLINT、MEDIUMINT、INT(或INTEGER)、BIGINT |
| 浮点类型 | FLOAT、DOUBLE |
| 定点数类型 | DECIMAL |
| 位类型 | BIT |
| 日期时间类型 | YEAR、TIME、DATE、DATETIME、TIMESTAMP |
| 文本字符串类型 | CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT |
| 枚举类型 | ENUM |
| 集合类型 | SET |
| 二进制字符串类 | BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB |
| JSON类型 | JSON对象、JSON数组 |
| 空间数据类型 | 单值:GEOMETRY、POINT、LINESTRING、POLYGON; 集合:MULTIPOINT、MULTILINESTRING、MULTIPOLYGON、GEOMETRYCOLLECTION |
常见数据类型的属性,如下:
| MySQL关键字 | 含义 |
|---|---|
| NULL | 数据列可包含NULL值 |
| NOT NULL | 数据列不允许包含NULL值 |
| DEFAULT | 默认值 |
| PRIMARY KEY | 主键 |
| AUTO_INCREMENT | 自动递增,适用于整数类型 |
| UNSIGNED | 无符号 |
| CHARACTER SET name | 指定一个字符集 |
2. 整数类型
2.1 类型介绍
整数类型一共有 5 种,包括 TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)和 BIGINT。
| 整数类型 | 字节 | 有符号数取值范围 | 无符号数取值范围 |
|---|---|---|---|
| TINYINT | 1 | -128~127 | 0~255 |
| SMALLINT | 2 | -32768~32767 | 0~65535 |
| MEDIUMINT | 3 | -8388608~8388607 | 0~16777215 |
| INT、INTEGER | 4 | -2147483648~2147483647 | 0~4294967295 |
| BIGINT | 8 | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
2.2 可选属性
整数类型的可选属性有三个:
2.2.1 M
M: 表示显示宽度,M的取值范围是(0, 255)。例如,int(5):当数据宽度小于5位的时候在数字前面需要用字符填满宽度。该项功能需要配合“ZEROFILL”使用,表示用“0”填满宽度,否则指定显示宽度无效。
如果设置了显示宽度,那么插入的数据宽度超过显示宽度限制,会不会截断或插入失败?
答案:不会对插入的数据有任何影响,还是按照类型的实际宽度进行保存,即显示宽度与类型可以存储的值范围无关。从MySQL 8.0.17开始,整数数据类型不推荐使用显示宽度属性。
2.2.2 UNSIGNED
UNSIGNED: 无符号类型(非负),所有的整数类型都有一个可选的属性UNSIGNED(无符号属性),无符号整数类型的最小取值为0。所以,如果需要在MySQL数据库中保存非负整数值时,可以将整数类型设置为无符号类型。
int类型默认显示宽度为int(11),无符号int类型默认显示宽度为int(10)。因为负号占了一个数字位。
2.2.3 ZEROFILL
ZEROFILL: 0填充,(如果某列是ZEROFILL,那么MySQL会自动为当前列添加UNSIGNED属性),如果指定了ZEROFILL只是表示不够M位时,用0在左边填充,如果超过M位,只要不超过数据存储范围即可。
2.3 适用场景
TINYINT:一般用于枚举数据,比如系统设定取值范围很小且固定的场景。
SMALLINT:可以用于较小范围的统计数据,比如统计工厂的固定资产库存数量等。
MEDIUMINT:用于较大整数的计算,比如车站每日的客流量等。
INT、INTEGER:取值范围足够大,一般情况下不用考虑超限问题,用得最多。比如商品编号。
BIGINT:只有当你处理特别巨大的整数时才会用到。比如双十一的交易量、大型门户网站点击量、证券公司衍生产品持仓等。
2.4 如何选择?
在评估用哪种整数类型的时候,你需要考虑存储空间和可靠性的平衡问题:一方 面,用占用字节数少的整数类型可以节省存储空间;另一方面,要是为了节省存储空间,使用的整数类型取值范围太小,一旦遇到超出取值范围的情况,就可能引起系统错误,影响可靠性。
举个例子,商品编号采用的数据类型是 INT。原因就在于,客户门店中流通的商品种类较多,而且,每天都有旧商品下架,新商品上架,这样不断迭代,日积月累。
如果使用 SMALLINT 类型,虽然占用字节数比 INT 类型的整数少,但是却不能保证数据不会超出范围65535。相反,使用 INT,就能确保有足够大的取值范围,不用担心数据超出范围影响可靠性的问题。
你要注意的是,在实际工作中,系统故障产生的成本远远超过增加几个字段存储空间所产生的成本。因此,我建议你首先确保数据不会超过取值范围,在这个前提之下,再去考虑如何节省存储空间。
3. 浮点类型
3.1 类型介绍
浮点数和定点数类型的特点是可以处理小数,你可以把整数看成小数的一个特例。
- FLOAT 表示单精度浮点数;
- DOUBLE 表示双精度浮点数;
| 类型 | 占用字节数 |
|---|---|
| FLOAT | 4 |
| DOUBLE | 8 |
- REAL默认就是 DOUBLE。如果你把 SQL 模式设定为启用“
REAL_AS_FLOAT”,那 么,MySQL 就认为REAL 是 FLOAT。如果要启用“REAL_AS_FLOAT”,可以通过以下 SQL 语句实现:
SET sql_mode = “REAL_AS_FLOAT”;
**问题1:**FLOAT 和 DOUBLE 这两种数据类型的区别是啥呢?
FLOAT 占用字节数少,取值范围小;DOUBLE 占用字节数多,取值范围也大。
问题2:为什么浮点数类型的无符号数取值范围,只相当于有符号数取值范围的一半,也就是只相当于有符号数取值范围大于等于零的部分呢?
MySQL 存储浮点数的格式为:符号(S) 、 尾数(M) 和 阶码(E)。因此,无论有没有符号,MySQL 的浮点数都会存储表示符号的部分。因此, 所谓的无符号数取值范围,其实就是有符号数取值范围大于等于零的部分。
3.2 数据精度说明
对于浮点类型,在MySQL中单精度值使用4个字节,双精度值使用8个字节。
-
MySQL允许使用
非标准语法(其他数据库未必支持,因此如果涉及到数据迁移,则最好不要这么用):FLOAT(M,D)或DOUBLE(M,D)。这里,M称为精度,D称为标度。(M,D)中 M=整数位+小数位,D=小数位。 D<=M<=255,0<=D<=30。例如,定义为FLOAT(5,2)的一个列可以显示为-999.99-999.99。如果超过这个范围会报错。
-
FLOAT和DOUBLE类型在不指定(M,D)时,默认会按照实际的精度(由实际的硬件和操作系统决定)来显示。
-
说明:浮点类型,也可以加
UNSIGNED,但是不会改变数据范围,例如:FLOAT(3,2) UNSIGNED仍然只能表示0-9.99的范围。 -
不管是否显式设置了精度(M,D),这里MySQL的处理方案如下:
- 如果存储时,整数部分超出了范围,MySQL就会报错,不允许存这样的值
- 如果存储时,小数点部分若超出范围,就分以下情况:
- 若四舍五入后,整数部分没有超出范围,则只警告,但能成功操作并四舍五入删除多余的小数位后保存。例如在FLOAT(5,2)列内插入999.009,近似结果是999.01。
- 若四舍五入后,整数部分超出范围,则MySQL报错,并拒绝处理。如FLOAT(5,2)列内插入999.995和-999.995都会报错。
-
从MySQL 8.0.17开始,FLOAT(M,D)和DOUBLE(M,D)用法在官方文档中已经明确不推荐使用,将来可能被移除。另外,关于浮点型FLOAT和DOUBLE的UNSIGNED也不推荐使用了,将来也可能被移除。
在编程中,如果用到浮点数,要特别注意误差问题,因为浮点数是不准确的,所以我们要避免使用“=”来判断两个数是否相等。
4. 定点数类型
4.1 类型介绍
- MySQL中的定点数类型只有 DECIMAL 一种类型。
| 数据类型 | 字节数 | 含义 |
|---|---|---|
| DECIMAL(M,D),DEC,NUMERIC | M+2字节 | 有效范围由M和D决定 |
使用 DECIMAL(M,D) 的方式表示高精度小数。其中,M被称为精度,D被称为标度。0<=M<=65, 0<=D<=30,D DECIMAL(M,D)的最大取值范围与DOUBLE类型一样,但是有效的数据范围是由M和D决定的。 定点数在MySQL内部是以 字符串 的形式进行存储,这就决定了它一定是精准的。 当DECIMAL类型不指定精度和标度时,其默认为DECIMAL(10,0)。当数据的精度超出了定点数类型的精度范围时,则MySQL同样会进行四舍五入处理。 浮点数 vs 定点数 “由于 DECIMAL 数据类型的精准性,在我们的项目中,除了极少数(比如商品编号)用到整数类型外,其他的数值都用的是 DECIMAL,原因就是这个项目所处的零售行业,要求精准,一分钱也不能差。 ” ——来自某项目经理 BIT类型中存储的是二进制值,类似010110。 BIT类型,如果没有指定(M),默认是1位。这个1位,表示只能存1位的二进制值。这里(M)是表示二进制的位数,位数最小值为1,最大值为64。 使用b+0查询数据时,可以直接查询出存储的十进制数据的值。 MySQL有多种表示日期和时间的数据类型,不同的版本可能有所差异,MySQL8.0版本支持的日期和时间类型主要有:YEAR类型、TIME类型、DATE类型、DATETIME类型和TIMESTAMP类型。 YEAR类型用来表示年份,在所有的日期时间类型中所占用的存储空间最小,只需要 在MySQL中,YEAR有以下几种存储格式: 从MySQL5.5.27开始,2位格式的YEAR已经不推荐使用。 DATE类型表示日期,没有时间部分,格式为 TIME类型用来表示时间,不包含日期部分。在MySQL中,需要 在MySQL中,向TIME类型的字段插入数据时,也可以使用几种不同的格式。 (1)可以使用带有冒号的字符串,比如’ 6.4 DATETIME类型 DATETIME类型在所有的日期时间类型中占用的存储空间最大,总共需要 在向DATETIME类型的字段插入数据时,同样需要满足一定的格式条件。 TIMESTAMP类型也可以表示日期时间,其显示格式与DATETIME类型相同,都是 TIMESTAMP和DATETIME的区别: 用得最多的日期时间类型,就是 此外,一般存注册时间、商品发布时间等,不建议使用DATETIME存储,而是使用 CHAR类型: VARCHAR类型: 哪些情况使用 CHAR 或 VARCHAR 更好 情况1:存储很短的信息。比如门牌号码101,201……这样很短的信息应该用char,因为varchar还要占个byte用于存储信息长度,本来打算节约存储的,结果得不偿失。 情况2:固定长度的。比如使用uuid作为主键,那用char应该更合适。因为他固定长度,varchar动态根据长度的特性就消失了,而且还要占个长度信息。 情况3:十分频繁改变的column。因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个非常频繁改变的,那就要有很多的精力用于计算,而这些对于char来说是不需要的。 情况4:具体存储引擎中的情况: 由于实际存储的长度不确定,MySQL不允许 TEXT 类型的字段做主键。遇到这种情况,你只能采用CHAR(M),或者 VARCHAR(M)。 开发中经验: TEXT文本类型,可以存比较大的文本段,搜索速度稍慢,因此如果不是特别大的内容,建议使用CHAR, VARCHAR来代替。还有TEXT类型不用加默认值,加了也没用。而且text和blob类型的数据删除后容易导致“空洞”,使得文件碎片比较多,所以频繁使用的表不建议包含TEXT类型字段,建议单独分出去,单独用一个表。 ENUM类型也叫作枚举类型,ENUM类型的取值范围需要在定义字段时进行指定。设置字段值时,ENUM类型只允许从成员中选取单个值,不能一次选取多个值。 SET表示一个字符串对象,可以包含0个或多个成员,但成员个数的上限为 64 。设置字段值时,可以取取值范围内的 0 个或多个值。 当SET类型包含的成员个数不同时,其所占用的存储空间也是不同的,具体如下: SET类型在存储数据时成员个数越多,其占用的存储空间越大。注意:SET类型在选取成员时,可以一次选择多个成员,这一点与ENUM类型不同。 MySQL中的二进制字符串类型主要存储一些二进制数据,比如可以存储图片、音频和视频等二进制数据。 BINARY与VARBINARY类型 BINARY和VARBINARY类似于CHAR和VARCHAR,只是它们存储的是二进制字符串。 BINARY (M)为固定长度的二进制字符串,M表示最多能存储的字节数,取值范围是0~255个字符。如果未指定(M),表示只能存储 VARBINARY (M)为可变长度的二进制字符串,M表示最多能存储的字节数,总字节数不能超过行的字节长度限制65535,另外还要考虑额外字节开销,VARBINARY类型的数据除了存储数据本身外,还需要1或2个字节来存储数据的字节数。VARBINARY类型 BLOB类型 BLOB是一个 需要注意的是,在实际工作中,往往不会在MySQL数据库中使用BLOB类型存储大对象数据,通常会将图片、音频和视频文件存储到 TEXT和BLOB的使用注意事项: 在使用text和blob字段类型时要注意以下几点,以便更好的发挥数据库的性能。 ① BLOB和TEXT值也会引起自己的一些问题,特别是执行了大量的删除或更新操作的时候。删除这种值会在数据表中留下很大的" ② 如果需要对大文本字段进行模糊查询,MySQL 提供了 ③ 把BLOB或TEXT列 JSON(JavaScript Object Notation)是一种轻量级的 数据交换格式 。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。它易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后就可以在网络或者程序之间轻松地传递这个字符串,并在需要的时候将它还原为各编程语言所支持的数据格式。 MySQL的空间数据类型(Spatial Data Type)对应于OpenGIS类,包括单值类型:GEOMETRY、POINT、 LINESTRING、POLYGON以及集合类型:MULTIPOINT、MULTILINESTRING、MULTIPOLYGON、 GEOMETRYCOLLECTION 。 在定义数据类型时,如果确定是 这样做的好处是,首先确保你的系统不会因为数据类型定义出错。不过,凡事都是有两面的,可靠性好,并不意味着高效。比如,TEXT 虽然使用方便,但是效率不如 CHAR(M) 和 VARCHAR(M)。 关于字符串的选择,建议参考如下阿里巴巴的《Java开发手册》规范: 阿里巴巴《Java开发手册》之MySQL数据库: 任何字段如果为非负数,必须是 UNSIGNED 【 【 【 数据完整性(Data Integrity)是指数据的精确性(Accuracy)和可靠性(Reliability)。它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息而提出的。 为了保证数据的完整性,SQL规范以约束的方式对表数据进行额外的条件限制。从以下四个方面考虑: 约束是表级的强制规定。 可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后通过 ALTER TABLE 语句规定约束。 **根据约束数据列的限制,**约束可分为: 根据约束的作用范围,约束可分为: 根据约束起的作用,约束可分为: 查看某个表已有的约束 限定某个字段/某列的值不允许为空 NOT NULL (1)建表时 (2)建表后 用来限制某个字段/某列的值不能重复。 UNIQUE (1)建表时 (2)建表后指定唯一键约束 可以向声明为unique的字段上添加null值。而且可以多次添加null 注意:可以通过 用来唯一标识表中的一行记录 primary key 主键约束相当于唯一约束+非空约束的组合,主键约束列不允许重复,也不允许出现空值 一个表最多只能有一个主键约束,建立主键约束可以在列级别创建,也可以在表级别上创建。 主键约束对应着表中的一列或者多列(复合主键) 如果是多列组合的复合主键约束,那么这些列都不允许为空值,并且组合的值不允许重复。 MySQL的主键名总是PRIMARY,就算自己命名了主键约束名也没用。 当创建主键约束时,系统默认会在所在的列或列组合上建立对应的主键索引(能够根据主键查询的,就根据主键查询,效率更高)。如果删除主键约束了,主键约束对应的索引就自动删除了。 需要注意的一点是,不要修改主键字段的值。因为主键是数据记录的唯一标识,如果修改了主键的值,就有可能会破坏数据的完整性。 (1)建表时指定主键约束 (2)建表后增加主键约束 说明:删除主键约束,不需要指定主键名,因为一个表只有一个主键,删除主键约束后,非空还存在。 在实际开发中,不会去删除表中的主键约束! 某个字段的值自增 auto_increment (1)一个表最多只能有一个自增长列 (2)当需要产生唯一标识符或顺序值时,可设置自增长 (3)自增长列约束的列必须是键列(主键列,唯一键列) (4)自增约束的列的数据类型必须是整数类型 (5)如果自增列指定了 0 和 null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接赋值为具体值。 (1)建表时 (2)建表后 在MySQL 8.0之前,自增主键AUTO_INCREMENT的值如果大于max(primary key)+1,在MySQL重启后,会重置AUTO_INCREMENT=max(primary key)+1,这种现象在某些情况下会导致业务主键冲突或者其他难以发现的问题。 在MySQL 5.7系统中,对于自增主键的分配规则,是由InnoDB数据字典内部一个 MySQL 8.0将自增主键的计数器持久化到 限定某个表的某个字段的引用完整性。 FOREIGN KEY 主表(父表):被引用的表,被参考的表 从表(子表):引用别人的表,参考别人的表 (1)从表的外键列,必须引用/参考主表的主键或唯一约束的列 为什么?因为被依赖/被参考的值必须是唯一的 (2)在创建外键约束时,如果不给外键约束命名,默认名不是列名,而是自动产生一个外键名(例如student_ibfk_1;),也可以指定外键约束名。 (3)创建(CREATE)表时就指定外键约束的话,先创建主表,再创建从表 (4)删表时,先删从表(或先删除外键约束),再删除主表 (5)当主表的记录被从表参照时,主表的记录将不允许删除,如果要删除数据,需要先删除从表中依赖该记录的数据,然后才可以删除主表的数据 (6)在“从表”中指定外键约束,并且一个表可以建立多个外键约束 (7)从表的外键列与主表被参照的列名字可以不相同,但是数据类型必须一样,逻辑意义一致。如果类型不一样,创建子表时,就会出现错误“ERROR 1005 (HY000): Can’t create table’database.tablename’(errno: 150)”。 (8)当创建外键约束时,系统默认会在所在的列上建立对应的普通索引。但是索引名是外键的约束名。(根据外键查询效率很高) (9)删除外键约束后,必须 (1)建表时 (2)建表后 总结:约束关系是针对双方的 如果没有指定等级,就相当于Restrict方式。 对于外键约束,最好是采用: 问题1:如果两个表之间有关系(一对一、一对多),比如:员工表和部门表(一对多),它们之间是否一定要建外键约束? 答:不是的 问题2:建和不建外键约束有什么区别? 答:建外键约束,你的操作(创建表、删除表、添加、修改、删除)会受到限制,从语法层面受到限制。例如:在员工表中不可能添加一个员工信息,它的部门的值在部门表中找不到。 不建外键约束,你的操作(创建表、删除表、添加、修改、删除)不受限制,要保证数据的 问题3:那么建和不建外键约束和查询有没有关系? 答:没有 在 MySQL 里,外键约束是有成本的,需要消耗系统资源。对于大并发的 SQL 操作,有可能会不适合。比如大型网站的中央数据库,可能会 【 说明:(概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于 检查某个字段的值是否符号xx要求,一般指的是值的范围 CHECK MySQL5.7 可以使用check约束,但check约束对数据验证没有任何作用。添加数据时,没有任何错误或警告 但是MySQL 8.0中可以使用check约束了。 给某个字段/某列指定默认值,一旦设置默认值,在插入数据时,如果此字段没有显式赋值,则赋值为默认值。 DEFAULT (1)建表时 (2)建表后 面试1、为什么建表时,加 not null default ‘’ 或 default 0 答:不想让表中出现null值。 面试2、为什么不想要 null 的值 答:(1)不好比较。null是一种特殊值,比较时只能用专门的is null 和 is not null来比较。碰到运算符,通常返回null。 (2)效率不高。影响提高索引效果。因此,我们往往在建表时 not null default ‘’ 或 default 0 面试3、带AUTO_INCREMENT约束的字段值是从1开始的吗? 在MySQL中,默认AUTO_INCREMENT的初始值是1,每新增一条记录,字段值自动加1。设置自增属性(AUTO_INCREMENT)的时候,还可以指定第一条插入记录的自增字段的值,这样新插入的记录的自增字段值从初始值开始递增,如在表中插入第一条记录,同时指定id值为5,则以后插入的记录的id值就会从6开始往上增加。添加主键约束时,往往需要设置字段自动增加属性。 面试4、并不是每个表都可以任意选择存储引擎? 外键约束(FOREIGN KEY)不能跨引擎使用。 MySQL支持多种存储引擎,每一个表都可以指定一个不同的存储引擎,需要注意的是:外键约束是用来保证数据的参照完整性的,如果表之间需要关联外键,却指定了不同的存储引擎,那么这些表之间是不能创建外键约束的。所以说,存储引擎的选择也不完全是随意的。 视图一方面可以帮我们使用表的一部分而不是所有的表,另一方面也可以针对不同的用户制定不同的查询视图。 语法1:查看数据库的表对象、视图对象 语法2:查看视图的结构 语法3:查看视图的属性信息 执行结果显示,注释Comment为VIEW,说明该表为视图,其他的信息为NULL,说明这是一个虚表。 语法4:查看视图的详细定义信息 MySQL支持使用INSERT、UPDATE和DELETE语句对视图中的数据进行插入、更新和删除操作。当视图中的数据发生变化时,数据表中的数据也会发生变化,反之亦然。 要使视图可更新,视图中的行和底层基本表中的行之间必须存在 虽然可以更新视图数据,但总的来说,视图作为 方式1:使用CREATE OR REPLACE VIEW 子句修改视图 方式2:ALTER VIEW 1. 操作简单 将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。 2. 减少数据冗余 视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。 3. 数据安全 MySQL将用户对数据的 同时,MySQL可以根据权限将用户对数据的访问限制在某些视图上,用户不需要查询数据表,可以直接通过视图获取数据表中的信息。这在一定程度上保障了数据表中数据的安全性。 4. 适应灵活多变的需求 当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。 5. 能够分解复杂的查询逻辑 数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。 如果我们在实际数据表的基础上创建了视图,那么,如果实际数据表的结构变更了,我们就需要及时对相关的视图进行相应的维护。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复杂, 可读性不好 ,容易变成系统的潜在隐患。因为创建视图的 SQL 查询可能会对字段重命名,也可能包含复杂的逻辑,这些都会增加维护的成本。 实际项目中,如果视图过多,会导致数据库维护成本的问题。 所以,在创建视图的时候,你要结合实际项目需求,综合考虑视图的优点和不足,这样才能正确使用视图,使系统整体达到最优。 含义:存储过程的英文是 执行过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。 语法: 说明: 1、参数前面的符号的意思 2、形参类型可以是 MySQL数据库中的任意类型。 3、 4、存储过程体中可以有多条 SQL 语句,如果仅仅一条SQL 语句,则可以省略 BEGIN 和 END 5、需要设置新的结束标记 举例1:创建存储过程select_all_data(),查看 emps 表的所有数据 举例2:创建存储过程avg_employee_salary(),返回所有员工的平均工资 举例3:创建存储过程show_max_salary(),用来查看“emps”表的最高薪资值。 举例4:创建存储过程show_someone_salary2(),查看“emps”表的某个员工的薪资,并用IN参数empname输入员工姓名,用OUT参数empsalary输出员工薪资。 举例5:创建存储过程show_mgr_name(),查询某个员工领导的姓名,并用INOUT参数“empname”输入员工姓名,输出领导的姓名。 格式: 1、调用in模式的参数: 2、调用out模式的参数: 3、调用inout模式的参数: 语法格式: 说明: 1、参数列表:指定参数为IN、OUT或INOUT只对PROCEDURE是合法的,FUNCTION中总是默认为IN参数。 2、RETURNS type 语句表示函数返回数据的类型; RETURNS子句只能对FUNCTION做指定,对函数而言这是 3、characteristic 创建函数时指定的对函数的约束。取值与创建存储过程时相同,这里不再赘述。 4、函数体也可以用BEGIN…END来表示SQL代码的开始和结束。如果函数体只有一条语句,也可以省略BEGIN…END。 创建存储函数count_by_id(),参数传入dept_id,该函数查询dept_id部门的员工人数,并返回,数据类型为整型。 调用: 注意: 若在创建存储函数中报错“ 此外,存储函数可以放在查询语句中使用,存储过程不行。反之,存储过程的功能更加强大,包括能够执行对表的操作(比如创建表,删除表等)和事务操作,这些功能是存储函数不具备的。 1. 使用SHOW CREATE语句查看存储过程和函数的创建信息 2. 使用SHOW STATUS语句查看存储过程和函数的状态信息 3. 从information_schema.Routines表中查看存储过程和函数的信息 修改存储过程或函数,不影响存储过程或函数功能,只是修改相关特性。使用ALTER语句实现。 其中,characteristic指定存储过程或函数的特性,其取值信息与创建存储过程、函数时的取值信息略有不同。 **1、存储过程可以一次编译多次使用。**存储过程只在创建时进行编译,之后的使用都不需要重新编译,这就提升了 SQL 的执行效率。 **2、可以减少开发工作量。**将代码 **3、存储过程的安全性强。**我们在设定存储过程的时候可以 **4、可以减少网络传输量。**因为代码封装到存储过程中,每次使用只需要调用存储过程即可,这样就减少了网络传输量。 **5、良好的封装性。**在进行相对复杂的数据库操作时,原本需要使用一条一条的 SQL 语句,可能要连接多次数据库才能完成的操作,现在变成了一次存储过程,只需要 阿里开发规范 【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。 **1、可移植性差。**存储过程不能跨数据库移植,比如在 MySQL、Oracle 和 SQL Server 里编写的存储过程,在换成其他数据库时都需要重新编写。 **2、调试困难。**只有少数 DBMS 支持存储过程的调试。对于复杂的存储过程来说,开发和维护都不容易。虽然也有一些第三方工具可以对存储过程进行调试,但要收费。 **3、存储过程的版本管理很困难。**比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。 **4、它不适合高并发的场景。**高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护, 增加数据库的压力 ,显然就不适用了。 小结: 存储过程既方便,又有局限性。尽管不同的公司对存储过程的态度不一,但是对于我们开发人员来说,不论怎样,掌握存储过程都是必备的技能之一。 系统变量分为全局系统变量(需要添加 全局系统变量针对于所有会话(连接)有效,但 会话系统变量仅针对于当前会话(连接)有效。会话期间,当前会话对某个会话系统变量值的修改,不会影响其他会话同一个会话系统变量的值。 会话1对某个全局系统变量值的修改会导致会话2中同一个全局系统变量值的修改。 作为 MySQL 编码规范,MySQL 中的系统变量以 方式1:修改MySQL 配置文件 ,继而修改MySQL系统变量的值(该方法需要重启MySQL服务) 方式2:在MySQL服务运行期间,使用“set”命令重新设置系统变量的值 用户变量是用户自己定义的,作为 MySQL 编码规范,MySQL 中的用户变量以 定义:可以使用 作用域:仅仅在定义它的 BEGIN … END 中有效 位置:只能放在 BEGIN … END 中,而且只能放在第一句 1.定义变量 2.变量赋值 方式1:一般用于赋简单的值 方式2:一般用于赋表中的字段值 3.使用变量(查看、比较、运算等) 说明:定义条件和处理程序在存储过程、存储函数中都是支持的。 在存储过程中未定义条件和处理程序,且当存储过程中执行的SQL语句报错时,MySQL数据库会抛出错误,并退出当前SQL逻辑,不再向下继续执行。 错误码的说明: 例如,在ERROR 1418 (HY000)中,1418是MySQL_error_code,'HY000’是sqlstate_value。 处理方式:处理方式有3个取值:CONTINUE、EXIT、UNDO。 错误类型(即条件)可以有如下取值: 处理语句:如果出现上述条件之一,则采用对应的处理方式,并执行指定的处理语句。语句可以是像“ 定义处理程序的几种方式,代码如下: CASE 语句的语法结构1: CASE 语句的语法结构2: LOOP循环语句用来重复执行某些语句。LOOP内的语句一直重复执行直到循环被退出(使用LEAVE子句),跳出循环过程。 对比三种循环结构: 1、这三种循环都可以省略名称,但如果循环中添加了循环控制语句(LEAVE或ITERATE)则必须添加名称。 2、 LOOP:一般用于实现简单的"死"循环;WHILE:先判断后执行;REPEAT:先执行后判断,无条件至少执行一次。 LEAVE语句:可以用在循环语句内,或者以 BEGIN 和 END 包裹起来的程序体内,表示跳出循环或者跳出程序体的操作。如果你有面向过程的编程语言的使用经验,你可以把 LEAVE 理解为 break。 ITERATE语句:只能用在循环语句(LOOP、REPEAT和WHILE语句)内,表示重新开始循环,将执行顺序转到语句段开头处。如果你有面向过程的编程语言的使用经验,你可以把 ITERATE 理解为 continue,意思为“再次循环”。 游标,提供了一种灵活的操作方式,让我们能够对结果集中的每一条记录进行定位,并对指向的记录中的数据进行操作的数据结构。游标让 SQL 这种面向集合的语言有了面向过程开发的能力。 游标必须在声明处理程序之前被声明,并且变量和条件还必须在声明游标或处理程序之前被声明。 第一步,声明游标 第二步,打开游标 第三步,使用游标(从游标中取得数据) 注意:游标的查询结果集中的字段数,必须跟 INTO 后面的变量数一致,否则,在存储过程执行的时候,MySQL 会提示错误。 第四步,关闭游标 当我们使用完游标后需要关闭掉该游标。因为游标会占用系统资源 ,如果不及时关闭,游标会一直保持到存储过程结束,影响系统运行的效率。 游标是 MySQL 的一个重要的功能,为 但同时也会带来一些性能问题,比如在使用游标的过程中,会对数据行进行 建议:养成用完之后就关闭的习惯,这样才能提高系统的整体效率。 使用SET GLOBAL语句设置的变量值只会 MySQL会将该命令的配置保存到数据目录下的 mysqld-auto.cnf 文件中,下次启动时会读取该文件,用其中的配置来覆盖默认的配置文件。 MySQL从 触发器是由 当对数据表中的数据执行插入、更新和删除操作,需要自动执行一些数据库逻辑时,可以使用触发器来实现。 说明: 方式1:查看当前数据库的所有触发器的定义 方式2:查看当前数据库中某个触发器的定义 方式3:从系统库information_schema的TRIGGERS表中查询“salary_check_trigger”触发器的信息。 1、触发器可以确保数据的完整性。 2、触发器可以帮助我们记录操作日志。 3、触发器还可以用在操作数据前,对数据进行合法性检查。 1、触发器最大的一个问题就是可读性差。 比如触发器中的数据插入操作多了一个字段,系统提示错误。可是,如果你不了解这个触发器,很可能会认为是更新语句本身的问题,或者是表的结构出了问题。 2、相关数据的变更,可能会导致触发器出错。 特别是数据表结构的变更,都可能会导致触发器出错,进而影响数据操作的正常运行。这些都会由于触发器本身的隐蔽性,影响到应用中错误原因排查的效率。 注意,如果在子表中定义了外键约束,并且外键指定了ON UPDATE/DELETE CASCADE/SET NULL子句,此时修改父表被引用的键值或删除父表被引用的记录行时,也会引起子表的修改和删除操作,此时基于子表的UPDATE和DELETE语句定义的触发器并不会被激活。 MySQL从8.0版本开始支持窗口函数。窗口函数的作用类似于在查询中对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录,而窗口函数是将结果置于每一条数据记录中。 窗口函数可以分为 静态窗口函数的窗口大小是固定的,不会因为记录的不同而不同; 动态窗口函数的窗口大小会随着记录的不同而变化。 窗口函数的语法结构是: 或者是: 窗口函数的特点是可以分组,而且可以在分组内排序。另外,窗口函数不会因为分组而减少原表中的行数,这对我们在原表数据的基础上进行统计和排序非常有用。 公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结果集,作用范围是当前语句。CTE可以理解成一个可以复用的子查询,当然跟子查询还是有点区别的,CTE可以引用其他CTE,但子查询不能引用其他子查询。所以,可以考虑代替子查询。 依据语法结构和执行方式的不同,公用表表达式分为 举例:查询员工所在的部门的详细信息。 **案例:**针对于我们常用的employees表,包含employee_id,last_name和manager_id三个字段。如果a是b的管理者,那么,我们可以把b叫做a的下属,如果同时b又是c的管理者,那么c就是b的下属,是a的下下属。 用递归公用表表达式中的种子查询,找出初代管理者。字段 n 表示代次,初始值为 1,表示是第一代管理者。 用递归公用表表达式中的递归查询,查出以这个递归公用表表达式中的人为管理者的人,并且代次的值加 1。直到没有人以这个递归公用表表达式中的人为管理者了,递归返回。 在最后的查询中,选出所有代次大于等于 3 的人,他们肯定是第三代及以上代次的下属了,也就是下下属了。这样就得到了我们需要的结果集。 代码实现: 公用表表达式的作用是可以替代子查询,而且可以被多次引用。递归公用表表达式对查询有一个共同根节点的树形结构数据非常高效,可以轻松搞定其他查询方式难以处理的查询。 1. 关闭 mysql 服务 2. 查看当前 mysql 安装状况 3. 卸载上述命令查询出的已安装程序 务必卸载干净,反复执行 4. 删除 mysql 相关文件 5.删除 my.cnf 1. 检查/tmp临时目录权限(必不可少) 由于mysql安装过程中,会通过mysql用户在/tmp目录下新建tmp_db文件,所以请给/tmp较大的权限。执行 : 2. 安装前,检查依赖 1. 将安装程序拷贝到/opt目录下 在mysql的安装文件目录下执行:(必须按照顺序执行) 若存在mariadb-libs问题,则执行yum remove mysql-libs即可 为了保证数据库目录与文件的所有者为 mysql 登录用户,如果你是以 root 身份运行 mysql 服务,需要执行下面的命令初始化: 说明: --initialize 选项默认以“安全”模式来初始化,则会为 root 用户生成一个密码并将 查看密码: root@localhost: 后面就是初始化的密码 通过 1. 确认网络 1.在远程机器上使用ping ip地址 2.在远程机器上使用telnet命令 2. 关闭防火墙或开放端口 方式一:关闭防火墙 方式二:开放端口 注意:在生产环境下不能为了省事将host设置为%,这样做会存在安全问题,具体的设置可以根据生产环境的IP进行设置。 配置新连接报错:错误号码 2058,分析是 mysql 密码加密方法变了。 **解决方法一:**升级远程连接工具版本 解决方法二: 小结 相关命令目录:/usr/bin 和/usr/sbin。 配置文件目录:/usr/share/mysql-8.0(命令及配置文件),/etc/mysql(如my.cnf) 1. 表结构 为了保存表结构, 2. 表中数据和索引 ① 系统表空间(system tablespace) 默认情况下,InnoDB会在数据目录下创建一个名为 ② 独立表空间(file-per-table tablespace) 在MySQL5.6.6以及之后的版本中,InnoDB并不会默认的把各个表的数据存储到系统表空间中,而是为 MySQL8.0中不再单独提供 ③ 系统表空间与独立表空间的设置 我们可以自己指定使用 ④ 其他类型的表空间 随着MySQL的发展,除了上述两种老牌表空间之外,现在还新提出了一些不同类型的表空间,比如通用表空间(general tablespace)、临时表空间(temporary tablespace)等。 1. 表结构 在存储表结构方面, MyISAM 和 InnoDB 一样,也是在 2. 表中数据和索引 在MyISAM中的索引全部都是 启动MySQL服务后,可以通过mysql命令来登录MySQL服务器,命令如下: 举例: 方式1:使用DROP方式删除(推荐) 举例: 方式2:使用DELETE方式删除(不推荐,有残留信息) 1. 使用ALTER USER命令来修改当前用户密码 2. 使用SET语句来修改当前用户密码 1. 使用ALTER语句来修改普通用户的密码 2. 使用SET命令来修改普通用户的密码 权限控制主要是出于安全因素,因此需要遵循以下几个 1、只授予能 2、创建用户的时候 3、为每个用户 4、 注意:在将用户账户从user表删除之前,应该收回相应用户的所有权限。 角色名称的命名规则和用户名类似。如果 上述语句中privileges代表权限的名称,多个权限以逗号隔开。可使用SHOW语句查询权限名称 只要你创建了一个角色,系统就会自动给你一个“ 注意, 角色创建并授权后,要赋给用户并处于 查询当前已激活的角色 方式1:使用set default role 命令激活角色 方式2:将activate_all_roles_on_login设置为ON 这条 SQL 语句的意思是,对 方式1:服务启动前设置 方式2:运行时设置 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-maDJ2OGO-1656668798777)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203291130782.png)] 系统(客户端)访问 经过三次握手建立连接成功后, SQL Interface: SQL接口 Parser: 解析器 Optimizer: 查询优化器 这个SELECT查询先根据WHERE语句进行 Caches & Buffers: 查询缓存组件 插件式存储引擎层( Storage Engines),真正的负责了MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,服务层通过API与存储引擎进行通信。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FSw9dYvh-1656668798778)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203291131321.png)] 简化为三层结构: 连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端; SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关; 存储引擎层:与数据库文件打交道,负责数据的存储和读取。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XOtJJBZF-1656668798778)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203291133116.png)] MySQL的查询流程: 1. 查询缓存:Server 如果在查询缓存中发现了这条 SQL 语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在 MySQL8.0 之后就抛弃了这个功能。 查询缓存是提前把查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。这就意味着查询匹配的 同时,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如 mysql、 information_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。 此外,既然是缓存,那就有它 2. 解析器:在解析器中对 SQL 语句进行语法分析、语义分析。 分析器先做“ 接着,要做“ 3. 优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据 4. 执行器:在执行之前需要判断该用户是否 SQL 语句在 MySQL 中的流程是: SQL语句→查询缓存→解析器→优化器→执行器 。 这样做的好处是可以让磁盘活动最小化,从而 1. 缓冲池(Buffer Pool) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GmSXuYrF-1656668798779)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203291155004.png)] 从图中,你能看到 InnoDB 缓冲池包括了数据页、索引页、插入缓冲、锁信息、自适应 Hash 和数据字典信息等。 缓存原则: “ 首先,位置决定效率,提供缓冲池就是为了在内存中可以直接访问数据。 其次,频次决定优先级顺序。因为缓冲池的大小是有限的,比如磁盘有 200G,但是内存只有 16G,缓冲池大小只有 1G,就无法将所有数据都加载到缓冲池里,这时就涉及到优先级顺序,会 2. 查询缓存 查询缓存是提前把 缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会判断该页面是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放到缓冲池中再进行读取。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hY0jTU4e-1656668798780)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203291159111.png)] 查看缓冲池的大小 设置缓冲池的大小 或者 何查看缓冲池的个数 每个 如果在创建表的语句中没有显式指定表的存储引擎的话,那就会默认使用 或者修改 存储引擎是负责对表中的数据进行提取和写入工作的,我们可以为 MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。 **索引的本质:**索引是数据结构。你可以简单理解为“排好序的快速查找数据结构”,满足特定查找算法。这些数据结构以某种方式指向数据, 这样就可以在这些数据结构的基础上实现 (1)类似大学图书馆建书目索引,提高数据检索的效率,降低 (2)通过创建唯一索引,可以保证数据库表中每一行 (3)在实现数据的参考完整性方面,可以 (4)在使用分组和排序子句进行数据查询时,可以显著 (1)创建索引和维护索引要 (2)索引需要占 (3)虽然索引大大提高了查询速度,同时却会 1.在一个页中的查找 假设目前表中的记录比较少,所有的记录都可以被存放在一个页中,在查找记录的时候可以根据搜索条件的不同分为两种情况: 2.在很多页中查找 大部分情况下我们表中存放的记录都是非常多的,需要好多的数据页来存储这些记录。在很多页中查找记录的话可以分为两个步骤: 在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们并不能快速的定位到记录所在的页,所以只能 这个新建的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ubdIxRxc-1656668798782)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203300956080.png)] 将记录格式示意图的其他信息项暂时去掉并把它竖起来的效果就是这样: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gTuyfJo5-1656668798782)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301000365.png)] 把一些记录放到页里的示意图就是: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hqg9bl67-1656668798783)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301001377.png)] 1. 一个简单的索引设计方案 我们在根据某个搜索条件查找一些记录时为什么要遍历所有的数据页呢?因为各个页中的记录并没有规律,我们并不知道我们的搜索条件匹配哪些页中的记录,所以不得不依次遍历所有的数据页。所以如果我们 以 先从目录项中根据 再根据前边说的在页中查找记录的方式去 至此,针对数据页做的简易目录就搞定了。这个目录有一个别名,称为 2. InnoDB中的索引方案 ① 迭代1次:目录项纪录的页 我们把前边使用到的目录项放到数据页中的样子就是这样: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bIWOBiJ6-1656668798789)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301028743.png)] 从图中可以看出来,我们新分配了一个编号为30的页来专门存储目录项记录。这里再次强调 **相同点:**两者用的是一样的数据页,都会为主键值生成 现在以查找主键为 先到存储 再到存储用户记录的页9中根据 ② 迭代2次:多个目录项纪录的页 从图中可以看出,我们插入了一条主键值为320的用户记录之后需要两个新的数据页: 现在因为存储目录项记录的页不止一个,所以如果我们想根据主键值查找一条用户记录大致需要3个步骤,以查找主键值为 确定 通过目录项记录页 在真实存储用户记录的页中定位到具体的记录。 ③ 迭代3次:目录项记录页的目录页 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7yqE9cIa-1656668798790)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301038376.png)] 如图,我们生成了一个存储更高级目录项的 我们可以用下边这个图来描述它: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M1EIBd99-1656668798790)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301040190.png)] 这个数据结构,它的名称是 ④ B+Tree 一个B+树的节点其实可以分成好多层,规定最下边的那层,也就是存放我们用户记录的那层为第 你的表里能存放 1. 聚簇索引 特点: 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义: 各个存放 存放 B+树的 所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。 优点: 缺点: 2. 二级索引(辅助索引、非聚簇索引) [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A1nsNxfg-1656668798791)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301050055.png)] 概念:回表 我们根据这个以c2列大小排序的B+树只能确定我们要查找记录的主键值,所以如果我们想根据c2列的值查找到完整的用户记录的话,仍然需要到 3. 联合索引 我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让B+树按照 先把各个记录和页按照c2列进行排序。 在记录的c2列相同的情况下,采用c3列进行排序 注意一点,以c2和c3列的大小为排序规则建立的B+树称为 建立 为c2和c3列分别建立索引会分别以c2和c3列的大小为排序规则建立2棵B+树。 1. 根页面位置万年不动 我们前边介绍B+索引的时候,为了大家理解上的方便,先把存储用户记录的叶子节点都画出来,然后接着画存储目录项记录的内节点,实际上B+树的形成过程是这样的: 这个过程特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是 2. 内节点中目录项记录的唯一性 我们知道B+树索引的内节点中目录项记录的内容是 如果二级索引中目录项的内容只是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FX1hyeI1-1656668798791)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301110222.png)] 如果我们想要新插入一行记录,其中 为了让新插入记录能找到自己在哪个页里,我们需要**保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的。**所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的: 也就是我们把主键值也添加到二级索引内节点中的目录项记录了,这样就能保证B+树每一层节点中各条目录项记录除页号这个字段外是唯一的,所以我们为c2列建立二级索引后的示意图实际上应该是这样子的: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A3b65NF4-1656668798792)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301120304.png)] 这样我们再插入记录 3. 一个页面最少可以存储2条记录 一个B+树只需要很少的层级就可以轻松存储数亿条记录,查询速度相当不错!这是因为B+树本质上就是一个大的多层级目录,每经过一个目录时都会过滤掉许多无效的子目录,直到最后访问的存储真实数据的目录。那如果一个大的目录中只存放一个子目录是个啥效果呢?那就是目录层级非常非常非常多,而且最后的那个存放真实数据的目录中存放一条记录。费了半天劲只能存放一条真实的用户记录?所以 B树索引适用存储引擎如表所示: 即使多个存储引擎支持同一种类型的索引,但是他们的实现原理也是不同的。Innodb和MyISAM默认的索引是Btree索引;而Memory默认的索引是Hash索引。 MyISAM引擎使用 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-utQOmU5c-1656668798792)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301133907.png)] MyISAM的索引方式都是“非聚簇”的,与InnoDB包含1个聚簇索引是不同的。 小结两种引擎中索引的区别: ① 在InnoDB存储引擎中,我们只需要根据主键值对 ② InnoDB的数据文件本身就是索引文件,而MyISAM索引文件和数据文件是 ③ InnoDB的非聚簇索引data域存储相应记录 ④ MyISAM的回表操作是十分 ⑤ InnoDB要求表 索引是个好东西,可不能乱建,它在空间和时间上都会有消耗: 每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用 每次对表中的数据进行 如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bz8lZkm3-1656668798793)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301636830.png)] 为了提高查询效率,就需要 如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。 针对同样的数据,如果我们把二叉树改成 B 树的结构如下图所示: 一个 M 阶的 B 树(M>2)有以下的特性: 根节点的儿子数的范围是 [2,M]。 每个中间节点包含 k-1 个关键字和 k 个孩子,孩子的数量 = 关键字的数量 +1,k 的取值范围为[ceil(M/2), M]。 叶子节点包括 k-1 个关键字(叶子节点没有孩子),k 的取值范围为 [ceil(M/2), M]。 假设中间节点节点的关键字为:Key[1], Key[2], …, Key[k-1],且关键字按照升序排序,即 Key[i] 所有叶子节点位于同一层。 上面那张图所表示的 B 树就是一棵 3 阶的 B 树。我们可以看下磁盘块 2,里面的关键字为(8,12),它有 3 个孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小于 8,(9,10) 在 8 和 12 之间,而 (13,15)大于 12,刚好符合刚才我们给出的特征。 然后我们来看下如何用 B 树进行查找。假设我们想要 我们与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1; 按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2; 按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。 你能看出来在 B 树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后在内存中进行比较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行 I/O 操作,消耗的时间比在内存中进行比较所需要的时间要多,是数据查找用时的重要因素。 再举例1: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3swXn1bc-1656668798805)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301644761.png)] B+ 树和 B 树的差异: 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数+1。 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。 B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树。 但B树和B+树各有自己的应用场景,不能说B+树完全比B树好,反之亦然。 思考题:为了减少IO,索引树会一次性加载吗? 1、数据库索引是存储在磁盘上的,如果数据量很大,必然导致索引的大小也会很大,超过几个G。 2、当我们利用索引查询时候,是不可能将全部几个G的索引都加载进内存的,我们能做的只能是:逐一加载每一个磁盘页,因为磁盘页对应着索引树的节点。 思考题:B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值,因为是估算,为了方便计算,这里的K取值为103。也就是说一个深度为3的B+Tree索引可以维护103 * 10^3 * 10^3 = 10亿条记录。(这里假定一个数据页也存储10^3条行记录数据了) 实际情况中每个节点可能不能填充满,因此在数据库中, 思考题:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引? 1.B+树的磁盘读写代价更低 B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对于B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。 2、B+树的查询效率更加稳定 由于非终结点并不是最终指向文件内容的节点,而只是叶子结点中关键字的索引。所有任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 思考题:Hash索引与B+树索引的区别 1、Hash索引 2、Hash索引 3、Hash索引 4、 索引结构给我们提供了高效的索引方式,不过索引信息以及数据记录都保存在文件上的,确切说是存储在页结构中。另一方面,索引是在存储引擎中实现的,MySQL服务器上的 由于 InnoDB将数据划分为若干个页,InnoDB中页的大小默认为 以 记录是按照行来存储的,但是数据库的读取并不以行为单位,否则一次读取(也就是一次I/O操作)只能处理一行数据,效率会非常低。 页a、页b、页c…页n这些页可以 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NhrR6jCg-1656668798806)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301838071.png)] 区(Extent)是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配 段(Segment)由一个或多个区组成,区在文件系统是一个连续分配的空间(在InnoDB中是连续的64个页),不过在段中不要求区与区之间是相邻的。 表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为 作用: 大小:38字节 作用: InnoDB存储引擎以页为单位把数据加载到内存中处理,如果该页中的数据在内存中被修改了,那么 为了检测一个页是否完整(也就是在同步的时候有没有发生只同步一半的尴尬情况),这时可以通过文件尾的校验和(checksum 值)与文件头的校验和做比对,如果两个值不相等则证明页的传输有问题,需要重新进行传输,否则认为页的传输已经完成。 我们自己存储的记录会按照指定的 User Records中的这些记录按照 记录可以比较大小吗? InnoDB规定的最小记录与最大记录这两条记录的构造十分简单,都是由5字节大小的记录头信息和8字节大小的一个固定的部分组成的。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G4o7cSDe-1656668798806)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301913664.png)] 这两条记录 为什么需要页目录? 页目录,二分法查找 举例: 现在的page_demo表中正常的记录共有6条,InnoDB会把它们分成两组,第一组中只有一个最小记录,第二组中是剩余的5条记录。如下图: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pmuinXwu-1656668798807)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301921631.png)] 从这个图中我们需要注意这么几点: 用箭头指向的方式替代数字,这样更易于我们理解,修改后如下 为什么最小记录的n_owned值为1,而最大记录的n_owned值为5呢? InnoDB规定:对于最小记录所在的分组只能有1条记录,最大记录所在的分组拥有的记录条数只能在1~8条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间。 分组是按照下边的步骤进行的: 为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫Page Header的部分,这个部分占用固定的56个字节,专门存储各种状态信息。 在MySQL 5.1版本中,默认设置为Compact行格式。一条完整的记录其实可以被分为记录的额外信息和记录的真实数据两大部分。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w3Gn99cj-1656668798808)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301939611.png)] MySQL支持一些变长的数据类型,比如VARCHAR(M)、VARBINARY(M)、TEXT类型,BLOB类型,这些数据类型修饰列称为 注意:这里面存储的变长长度和字段顺序是反过来的。比如两个varchar字段在表结构的顺序是a(10),b(15)。那么在变长字段长度列表中存储的长度顺序就是15,10,是反过来的。 Compact行格式会把可以为NULL的列统一管理起来,存在一个标记为NULL值列表中。如果表中没有允许存储 NULL 的列,则 NULL值列表也不存在了。 注意:同样顺序也是反过来存放的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WdCgqKIO-1656668798809)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202203301945235.png)] 被删除的记录为什么还在页中存储呢? 怎么不见heap_no值为0和1的记录呢? 一个表没有手动定义主键,则会选取一个Unique键作为主键,如果连Unique键都没有定义的话,则会为表默认添加一个名为row_id的隐藏列作为主键。所以row_id是在没有自定义主键以及Unique键的情况下才会存在的。 我们可以知道一个页的大小一般是16KB,也就是16384字节,而一个VARCHAR(M)类型的列就最多可以存储65533个字节,这样就可能出现一个页存放不了一条记录,这种现象称为 在Compact和Reduntant行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的一部分数据,把剩余的数据分散存储在几个其他的页中进行 在MySQL 8.0中,默认行格式就是Dynamic,Dynamic、Compressed行格式和Compact行格式挺像,只不过在处理行溢出数据时有分歧 引入 对于范围查询,其实是对B+树叶子节点中的记录进行顺序扫描,而如果不区分叶子节点和非叶子节点,统统把节点代表的页面放到申请到的区中的话,进行范围扫描的效果就大打折扣了。所以InnoDB对B+树的 除了索引的叶子节点段和非叶子节点段之外,InnoDB中还有为存储一些特殊的数据而定义的段,比如回滚段。所以,常见的段有 在InnoDB存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这从一定程度上简化了DBA对于段的管理。 段其实不对应表空间中的某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面以及一些完整的区组成。 默认情况下,一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引会生成2个段,而段是以区为单位申请存储空间的,一个区默认占用1M(64*16KB=1024KB)存储空间,所以**默认情况下一个只存在几条记录的小表也需要2M的存储空间么?**以后每次添加一个索引都要多申请2M的存储空间么?这对于存储记录比较少的表简直是天大的浪费。这个问题的症结在于到现在为止我们介绍的区都是非常 为了考虑以完整的区为单位分配给某个段对于 所以此后为某个段分配存储空间的策略是这样的: 所以现在段不能仅定义为是某些区的集合,更精确的应该是 区大体上可以分为4种类型: 处于 1. 创建普通索引 2. 创建唯一索引 3. 主键索引 4. 创建单列索引 5. 创建组合索引 6. 创建全文索引 7. 创建空间索引 2. 在已经存在的表上创建索引 1. 使用ALTER TABLE语句创建索引 2. 使用CREATE INDEX创建索引 1. 使用ALTER TABLE删除索引 2. 使用DROP INDEX语句删除索引 从MySQL 8.x开始支持 1. 创建表时直接创建 2. 在已经存在的表上创建 3. 通过ALTER TABLE语句创建 4. 切换索引可见状态 1. 字段的数值有唯一性的限制 索引本身可以起到约束的作用,比如唯一索引、主键索引都可以起到唯一性约束的,因此在我们的数据表中,如果 业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。(来源:Alibaba) 说明:不要以为唯一索引影响了insert速度,这个速度损耗可以忽略,但提高查找速度是明显的。 2. 频繁作为 WHERE 查询条件的字段 某个字段在SELECT语句的 WHERE 条件中经常被使用到,那么就需要给这个字段创建索引了。尤其是在数据量大的情况下,创建普通索引就可以大幅提升数据查询的效率。 3. 经常 GROUP BY 和 ORDER BY 的列 索引就是让数据按照某种顺序进行存储或检索,因此当我们使用 GROUP BY 对数据进行分组查询,或者使用 ORDER BY 对数据进行排序的时候,就需要 4. UPDATE、DELETE 的 WHERE 条件列 对数据按照某个条件进行查询后再进行 UPDATE 或 DELETE 的操作,如果对 WHERE 字段创建了索引,就能大幅提升效率。原理是因为我们需要先根据 WHERE 条件列检索出来这条记录,然后再对它进行更新或删除。如果进行更新的时候,更新的字段是非索引字段,提升的效率会更明显,这是因为非索引字段更新不需要对索引进行维护。 5.DISTINCT 字段需要创建索引 有时候我们需要对某个字段进行去重,使用 DISTINCT,那么对这个字段创建索引,也会提升查询效率。 6. 多表 JOIN 连接操作时,创建索引注意事项 首先, 其次, 最后, 7. 使用列的类型小的创建索引 我们这里所说的 这个建议对于表的 8. 使用字符串前缀创建索引 区分度计算公式: 拓展:Alibaba《Java开发手册》 【 说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会 9. 区分度高(散列性高)的列适合作为索引 可以使用公式 拓展:联合索引把区分度高(散列性高)的列放在前面。 10. 使用最频繁的列放到联合索引的左侧 11. 在多个字段都要创建索引的情况下,联合索引优于单值索引 在实际工作中,我们也需要注意平衡,索引的数目不是越多越好。我们需要限制每张表上的索引数量,建议单张表索引数量 1. 在where中使用不到的字段,不要设置索引 2. 数据量小的表最好不要使用索引 3. 有大量重复数据的列上不要建立索引 4. 避免对经常更新的表创建过多的索引 5. 不建议用无序的值作为索引 例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。 6. 删除不再使用或者很少使用的索引 7. 不要定义冗余或重复的索引 使用场景:它对于比较开销是非常有用的,特别是我们有好几种查询方式可选的时候。 SQL 查询是一个动态的过程,从页加载的角度来看,我们可以得到以下两点结论: 所以说,遇到I/O并不用担心,方法找对了,效率还是很高的。我们首先要考虑数据存放的位置,如果是经常使用的数据就要尽量放到 MySQL的慢查询日志,用来记录在MySQL中 默认情况下,MySQL数据库 1. 开启slow_query_log 查看下慢查询日志是否开启,以及慢查询日志文件的位置: 2. 修改long_query_time阈值 方式1:永久性方式 方式2:临时性方式 EXPLAIN 语句输出的各个列的作用如下: 1. table 不论我们的查询语句有多复杂,包含了多少个表 ,到最后也是需要对每个表进行 2. id 3. select_type 4. partitions 5. type(重点) 结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL SQL性能优化的目标:至少要达到 range级别,要求是ref级别,最好是consts级别。(阿里巴巴开发手册要求) 6. possible_keys和key 7. key_len(重点) key_len的长度计算公式: 8. ref 9. rows(重点) 预估的需要读取的记录条数 10. filtered 11. Extra 这里谈谈EXPLAIN的输出格式。EXPLAIN可以输出四种格式: 1. 传统格式 2. JSON格式 JSON格式:在EXPLAIN单词和真正的查询语句中间加上 3. TREE格式 TREE格式是8.0.16版本之后引入的新格式,主要根据查询的 4. 可视化输出 可视化输出,可以通过MySQL Workbench可视化查看MySQL的执行计划。 7.1 Sys schema视图使用场景 索引情况 表相关 语句相关 IO相关 Innodb 相关 MySQL中 大多数情况下都(默认)采用 其实,用不用索引,最终都是优化器说了算。优化器是基于什么的优化器?基于 在MySQL建立联合索引时会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。 结论:MySQL可以为多个字段创建索引,一个索引可以包括16个字段。对于多列索引,**过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。**如果查询条件中没有使用这些字段中第1个字段时,多列(或联合)索引不会被使用。 对于一个使用 应用开发中范围查询,例如:金额查询,日期查询往往都是范围查询。应将查询条件放置where语句最后。(创建的联合索引中,务必把范围涉及到的字段写在最后) 结论:最好在设计数据表的时候就将 拓展:同理,在查询中使用 拓展:Alibaba《Java开发手册》 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。 在WHERE子句中,如果在OR前的条件列进行了索引,而在OR后的条件列没有进行索引,那么索引会失效。也就是说,OR前后的两个条件中的列都是索引时,查询中才使用索引。 统一使用utf8mb4( 5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。不同的 结论1:对于内连接来说,查询优化器可以决定谁来作为驱动表,谁作为被驱动表出现 结论2:对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表 结论3:对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。 Index Nested-Loop Join其优化的思路主要是为了 如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录再加载到内存匹配,这样周而复始,大大增加了IO的次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。 不再是逐条获取驱动表的数据,而是一块一块的获取,引入了 从MySQL的8.0.20版本开始将废弃BNLJ,因为从MySQL8.0.18版本开始就加入了hash join默认都会使用hash join 子查询是 MySQL 的一项重要的功能,可以帮助我们通过一个 SQL **语句实现比较复杂的查询。但是,子查询的执行效率不高。**原因: ① 执行子查询时,MySQL需要为内层查询语句的查询结果 ② 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都 ③ 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。 **在MySQL中,可以使用连接(JOIN)查询来替代子查询。**连接查询 结论:尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代 SQL 中,可以在 WHERE 子句和 ORDER BY 子句中使用索引,目的是在 WHERE 子句中 尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引。 无法使用 Index 时,需要对 FileSort 方式进行调优。 优化思路一 在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。 优化思路二 该方案适用于主键自增的表,可以把Limit 查询转换成某个位置的查询。 理解方式一:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个行。毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了满足查询结果的数据就叫做覆盖索引。 理解方式二:非聚簇复合索引的一种形式,它包括在查询里的SELECT、JOIN和WHERE子句用到的所有列(即建索引的字段正好是覆盖查询条件中所涉及的字段)。 简单说就是, 好处: 1. 避免Innodb表进行索引的二次查询(回表) 2. 可以把随机IO变成顺序IO加快查询效率 弊端: 在不使用ICP索引扫描的过程: storage层:只将满足index key条件的索引记录对应的整行记录取出,返回给server层 server 层:对返回的数据,使用后面的where条件过滤,直至返回最后一行。 使用ICP扫描的过程: storage层:首先将index key条件满足的索引记录区间确定,然后在索引上使用index filter进行过滤。将满足的index filter条件的索引记录才去回表取出整行记录返回server层。不满足index filter条件的索引记录丢弃,不回表、也不会返回server层。 server 层:对返回的数据,使用table filter条件做最后的过滤。 索引是个前提,其实选择与否还会要看表的大小。你可以将选择的标准理解为 环节1: **环节2:**如果是MyISAM存储引擎,统计数据表的行数只需要 如果是InnoDB存储引擎,因为InnoDB支持事务,采用行级锁和MVCC机制,所以无法像MyISAM一样,维护一个row_count变量,因此需要采用 **环节3:**在InnoDB引擎中,如果采用 如果有多个二级索引,会使用key_len小的二级索引进行扫描。当没有二级索引的时候,才会采用主键索引来进行统计。 在表查询中,建议明确字段,不要使用 * 作为查询的字段列表,推荐使用SELECT <字段列表> 查询。原因: ① MySQL 在解析的过程中,会通过 ② 无法使用 针对的是会扫描全表的 SQL 语句,如果你可以确定结果集只有一条,那么加上 如果数据表已经对字段建立了唯一索引,那么可以通过索引进行查询,不会全表扫描的话,就不需要加上 只要有可能,在程序中尽量多使用 COMMIT,这样程序的性能得到提高,需求也会因为 COMMIT 所释放的资源而减少。 COMMIT 所释放的资源: 回滚段上用于恢复数据的信息 被程序语句获得的锁 redo / undo log buffer 中的空间 管理上述 3 种资源中的内部花费 **在关系型数据库中,关于数据表设计的基本原则、规则就称为范式。**可以理解为,一张数据表的设计结构需要满足的某种设计标准的 目前关系型数据库有六种常见范式,按照范式级别,从低到高分别是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。 这里有两个表: 第一范式主要是确保数据表中每个字段的值必须具有 第二范式要求,在满足第一范式的基础上,还要**满足数据表里的每一条数据记录,都是可唯一标识的。而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。**如果知道主键的所有属性的值,就可以检索到任何元组(行)的任何属性的任何值。 第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段。(即,不能存在非主属性A依赖于非主属性B,非主属性B依赖于主键C的情况,即存在"A–>B–>C"的决定关系)通俗地讲,该规则的意思是所有 关于数据表的设计,有三个范式要遵循。 (1)第一范式(1NF),确保每列保持 数据库的每一列都是不可分割的原子数据项,不可再分的最小数据单元,而不能是集合、数组、记录等非原子数据项。 (2)第二范式(2NF),确保每列都和主键 尤其在复合主键的情况向下,非主键部分不应该依赖于部分主键。 (3)第三范式(3NF),确保每列都和主键 **范式的优点:**数据的标准化有助于消除数据库中的 **范式的缺点:**范式的使用,可能 范式只是提出了设计的标准,实际上设计数据表时,未必一定要符合这些标准。开发中,我们会出现为了性能和读取效率违反范式化的原则,通过 规范化 vs 性能 为满足某种商业目标 , 数据库性能比规范化数据库更重要 在数据规范化的同时 , 要综合考虑数据库的性能 通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间 通过在给定的表中插入计算列,以方便查询 当冗余信息有价值或者能 1. 增加冗余字段的建议 1)这个冗余字段 2)这个冗余字段 2. 历史快照、历史数据的需要 在现实生活中,我们经常需要一些冗余信息,比如订单中的收货人信息,包括姓名、电话和地址等。每次发生的 反范式优化也常用在 主属性(仓库名)对于候选键(管理员,物品名)是部分依赖的关系,这样就有可能导致异常情况。因此引入BCNF,它在 3NF 的基础上消除了主属性对候选键的部分依赖或者传递依赖关系。 如果在关系R中,U为主键,A属性是主键的一个属性,若存在A->Y,Y为主属性,则该关系不属于BCNF。 ER模型也叫做 ER 模型中有三个要素,分别是实体、属性和关系。 注意:实体和属性不容易区分。这里提供一个原则:我们要从系统整体的角度出发去看,可以独立存在的是实体,不可再分的是属性。也就是说,属性不能包含其他属性。 在 ER 模型的 3 个要素中,关系又可以分为 3 种类型,分别是 一对一、一对多、多对多。 数据表设计的一般原则:“三少一多” 1. 数据表的个数越少越好 2. 数据表中的字段个数越少越好 3. 数据表中联合主键的字段个数越少越好 4. 使用主键和外键越多越好 注意:这个原则并不是绝对的,有时候我们需要牺牲数据的冗余度来换取数据处理的效率。 【强制】库的名称必须控制在32个字符以内,只能使用英文字母、数字和下划线,建议以英文字母开头。 【强制】库名中英文 【强制】库的名称格式:业务系统名称_子系统名。 【强制】库名禁止使用关键字(如type,order等)。 【强制】创建数据库时必须 【建议】对于程序连接数据库账号,遵循 【建议】临时库以 【强制】表和列的名称必须控制在32个字符以内,表名只能使用英文字母、数字和下划线,建议以 【强制】 【强制】表名要求有模块名强相关,同一模块的表名尽量使用 【强制】创建表时必须 【强制】表名、列名禁止使用关键字(如type,order等)。 【强制】创建表时必须 【强制】建表必须有comment。 【强制】字段命名应尽可能使用表达实际含义的英文单词或 【强制】布尔值类型的字段命名为 【强制】禁止在数据库中存储图片、文件等大的二进制数据。通常文件很大,短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随机IO操作,文件很大时,IO操作很耗时。通常存储于文件服务器,数据库只存储文件地址信息。 【建议】建表时关于主键: 【建议】核心表(如用户表)必须有行数据的 【建议】表中所有字段尽量都是 【建议】所有存储相同数据的 【建议】中间表(或临时表)用于保留中间结果集,名称以 【示范】一个较为规范的建表语句: 【强制】InnoDB表必须主键为id int/bigint auto_increment,且主键值 【强制】InnoDB和MyISAM存储引擎表,索引类型必须为 【建议】主键的名称以 【建议】多单词组成的columnname,取前几个单词首字母,加末单词组成column_name。如: sample 表 member_id 上的索引:idx_sample_mid。 【建议】单个表上的索引个数 【建议】在建立索引时,多考虑建立 【建议】在多表 JOIN 的SQL里,保证被驱动表的连接列上有索引,这样JOIN 执行效率最高。 【建议】建表或加索引时,保证表里互相不存在 【强制】程序端SELECT语句必须指定具体字段名称,禁止写成 *。 【建议】程序端insert语句指定具体字段名称,不要写成INSERT INTO t1 VALUES(…)。 【建议】除静态表或小表(100行以内),DML语句必须有WHERE条件,且使用索引查找。 【建议】INSERT INTO…VALUES(XX),(XX),(XX)… 这里XX的值不要超过5000个。 值过多虽然上线很快,但会引起主从同步延迟。 【建议】SELECT语句不要使用UNION,推荐使用UNION ALL,并且UNION子句个数限制在5个以内。 【建议】线上环境,多表 JOIN 不要超过5个表。 【建议】减少使用ORDER BY,和业务沟通能不排序就不排序,或将排序放到程序端去做。ORDER BY、GROUP BY、DISTINCT 这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。 【建议】包含了ORDER BY、GROUP BY、DISTINCT 这些查询的语句,WHERE 条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。 【建议】对单表的多次alter操作必须合并为一次。对于超过100W行的大表进行alter table,必须经过DBA审核,并在业务低峰期执行,多个alter需整合在一起。 因为alter table会产生 【建议】批量操作数据时,需要控制事务处理间隔时间,进行必要的sleep。 【建议】事务里包含SQL不超过5个。因为过长的事务会导致锁数据较久,MySQL内部缓存、连接消耗过多等问题。 【建议】事务里更新语句尽量基于主键或UNIQUE KEY,如UPDATE… WHERE id=XX;否则会产生间隙锁,内部扩大锁定范围,导致系统性能下降,产生死锁。 第1步:选择适合的 DBMS 第2步:优化表设计 第3步:优化逻辑查询 第4步:优化物理查询 物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等),通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。 第5步:使用 Redis 或 Memcached 作为缓存 第6步:库级优化 1、读写分离 2、数据分片 **服务器的硬件性能直接决定着MySQL数据库的性能。**硬件的性能瓶颈直接决定MySQL数据库的运行速度和效率。针对性能瓶颈提高硬件配置,可以提高MySQL数据库查询、更新的速度。 (1) (2) (3) (4) 情况1:对整数类型数据进行优化。 遇到整数类型的字段可以用 对于 情况2:既可以使用文本类型也可以使用整数类型的字段,要选择使用整数类型。 跟文本类型数据相比,大整数往往占用 情况3:避免使用TEXT、BLOB数据类型 情况4:避免使用ENUM类型 情况5:使用TIMESTAMP存储时间 情况6:用DECIMAL代替FLOAT和DOUBLE存储精确浮点数 总之,遇到数据量大的项目时,一定要在充分了解业务需求的前提下,合理优化数据类型,这样才能充分发挥资源的效率,使系统达到最优。 1. MyISAM引擎的表: ① 禁用索引 ② 禁用唯一性检查 ③ 使用批量插入 ④ 使用LOAD DATA INFILE 批量导入 2. InnoDB引擎的表: ① 禁用唯一性检查 ② 禁用外键检查 ③ 禁止自动提交 在设计字段的时候,如果业务允许,建议尽量使用非空约束 1. 分析表 默认的,MySQL服务会将 ANALYZE TABLE语句写到binlog中,以便在主从架构中,从服务能够同步数据。可以添加参数LOCAL 或者 NO_WRITE_TO_BINLOG取消将语句写到binlog中。 使用 ANALYZE TABLE分析后的统计结果会反应到 2. 检查表 MySQL中可以使用 3. 优化表 MySQL中使用 OPTIMIZE TABLE 语句对InnoDB和MyISAM类型的表都有效。该语句在执行过程中也会给表加上 **事务:**一组逻辑操作单元,使数据从一种状态变换到另一种状态。 **事务处理的原则:**保证所有事务都作为 原子性是指事务是一个不可分割的工作单位,要么全部提交,要么全部失败回滚。 一致性是指事务执行前后,数据从一个 事务的隔离性是指一个事务的执行 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是 持久性是通过 事务对应的数据库操作正在执行过程中时,我们就说该事务处在 当事务中的最后一个操作执行完成,但由于操作都在内存中执行,所造成的影响并 当事务处在 如果事务执行了一部分而变为 当一个处在 步骤1: ① ② ③ **步骤2:**一系列事务中的操作(主要是DML,不含DDL) **步骤3:**提交事务 或 中止事务(即回滚事务) 其中关于SAVEPOINT相关操作有: 数据定义语言(Data definition language,缩写为:DDL) 隐式使用或修改mysql数据库中的表 事务控制或关于锁定的语句 1. 脏写( 对于两个事务 Session A、Session B,如果事务Session A 2. 脏读( 对于两个事务 Session A、Session B,Session A 3. 不可重复读( 对于两个事务Session A、Session B,Session A [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ijnk75md-1656668798813)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204031124331.png)] 4. 幻读( 对于两个事务Session A、Session B, Session A 从一个表中 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-opjwXtMN-1656668798814)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204031125847.png)] 注意1: 有的同学会有疑问,那如果Session B中 注意2: 那对于先前已经读到的记录,之后又读取不到这种情况,算啥呢?这相当于对每一条记录都发生了 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-giZMUgUL-1656668798814)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204031127542.png)] 或者: 事务有4种特性:原子性、一致性、隔离性和持久性。那么事务的四种特性到底是基于什么机制实现呢? 一方面,缓冲池可以帮助我们消除CPU和磁盘之间的鸿沟,checkpoint机制可以保证数据的最终落盘,然而由于checkpoint 另一方面,事务包含 那么如何保证这个持久性呢? 1. 好处 2. 特点 Redo log可以简单分为以下两个部分: 参数设置:innodb_log_buffer_size: redo log buffer 大小,默认 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kP8phtU9-1656668798815)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204031147714.png)] 第1步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝 第2步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值 第3步:当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加写的方式 第4步:定期将内存中修改的数据刷新到磁盘中 Write-Ahead Log(预先日志持久化):在持久化一个数据页之前,先将内存中相应的日志页持久化。 redo log buffer刷盘到redo log file的过程并不是真正的刷到磁盘中去,只是刷入到 针对这种情况,InnoDB给出 1. 流程图 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pvv8JsZl-1656668798816)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204031153931.png)] 1. 补充概念:Mini-Transaction 一个事务可以包含若干条语句,每一条语句其实是由若干个 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5EC6otqb-1656668798816)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204040912119.png)] 2. redo 日志写入log buffer 不同的事务可能是 1. 相关参数设置 2. 日志文件组 3. checkpoint [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2TkssJcy-1656668798819)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204040921715.png)] 如果 write pos 追上 checkpoint ,表示日志文件组满了,这时候不能再写入新的 redo log记录,MySQL 得停下来,清空一些记录,把 checkpoint 推进一下。 redo log是事务持久性的保证,undo log是事务原子性的保证。在事务中 事务需要保证 以上情况出现,我们需要把数据改回原先的样子,这个过程称之为 1. 回滚段与undo页 InnoDB对undo log的管理采用段的方式,也就是 2. 回滚段与事务 每个事务只会使用一个回滚段,一个回滚段在同一时刻可能会服务于多个事务。 当一个事务开始的时候,会制定一个回滚段,在事务进行的过程中,当数据被修改时,原始的数据会被复制到回滚段。 在回滚段中,事务会不断填充盘区,直到事务结束或所有的空间被用完。如果当前的盘区不够用,事务会在段中请求扩展下一个盘区,如果所有已分配的盘区都被用完,事务会覆盖最初的盘区或者在回滚段允许的情况下扩展新的盘区来使用。 回滚段存在于undo表空间中,在数据库中可以存在多个undo表空间,但同一时刻只能使用一个undo表空间。 当事务提交时,InnoDB存储引擎会做以下两件事情: 3. 回滚段中的数据分类 未提交的回滚数据(uncommitted undo information) 已经提交但未过期的回滚数据(committed undo information) 事务已经提交并过期的数据(expired undo information) 在InnoDB存储引擎中,undo log分为: 1. 简要生成过程 只有Buffer Pool的流程: 有了Redo Log和Undo Log之后: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q9gY0wYG-1656668798820)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204040938657.png)] 2. 详细生成过程 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gT2FYQDB-1656668798821)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204040939231.png)] 当我们执行INSERT时: 当我们执行UPDATE时: 3. undo log是如何回滚的 以上面的例子来说,假设执行rollback,那么对应的流程应该是这样: 通过undo no=3的日志把id=2的数据删除 通过undo no=2的日志把id=1的数据的deletemark还原成0 通过undo no=1的日志把id=1的数据的name还原成Tom 通过undo no=0的日志把id=1的数据删除 4. undo log的删除 因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log可以在事务提交后直接删除,不需要进行purge操作。 该undo log可能需要提供MVCC机制,因此不能在事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qBewMNqi-1656668798822)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204040944948.png)] undo log是逻辑日志,对事务回滚时,只是将数据库逻辑地恢复到原来的样子。 redo log是物理日志,记录的是数据页的物理变化,undo log不是redo log的逆过程。 在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。为保证数据的一致性,需要对 在这种情况下会发生 怎么解决 所谓的 普通的SELECT语句在READ COMMITTED和REPEATABLE READ隔离级别下会使用到MVCC读取记录。 方案二:读、写操作都采用 小结对比发现: 一般情况下我们当然愿意采用 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3FMUDHTP-1656668798823)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204050933339.png)] 需要注意的是对于 InnoDB 引擎来说,读锁和写锁可以加在表上,也可以加在行上。 1. 锁定读 在采用 MySQL8.0新特性: 在5.7及之前的版本,SELECT … FOR UPDATE,如果获取不到锁,会一直等待,直到 2. 写操作 1. 表锁(Table Lock) 该锁会锁定整张表,它是MySQL中最基本的锁策略,并 ① 表级别的S锁、X锁 在对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,InnoDB存储引擎是不会为这个表添加表级别的 一般情况下,不会使用InnoDB存储引擎提供的表级别的 总结:MyISAM在执行查询语句(SELECT)前,会给涉及的所有表加读锁,在执行增删改操作前,会给涉及的表加写锁。 ② 意向锁 (intention lock) InnoDB 支持 1、意向锁的存在是为了协调行锁和表锁的关系,支持多粒度(表锁与行锁)的锁并存。 2、意向锁是一种 3、表明“某个事务正在某些行持有了锁或该事务准备去持有锁” 意向锁分为两种: 即:意向锁是由存储引擎 1. 意向锁要解决的问题 现在有两个事务,分别是T1和T2,其中T2试图在该表级别上应用共享或排它锁,如果没有意向锁存在,那么T2就需要去检查各个页或行是否存在锁;如果存在意向锁,那么此时就会受到由T1控制的 在数据表的场景中,如果我们给某一行数据加上了排它锁,数据库会自动给更大一级的空间,比如数据页或数据表加上意向锁,告诉其他人这个数据页或数据表已经有人上过排它锁了,这样当其他人想要获取数据表排它锁的时候,只需要了解是否有人已经获取了这个数据表的意向排它锁即可。 这时,意向锁会告诉其他事务已经有人锁定了表中的某些记录。 ③ 自增锁(AUTO-INC锁) 1. “Simple inserts” (简单插入) 可以 2. “Bulk inserts” (批量插入) 3. “Mixed-mode inserts” (混合模式插入) 这些是“Simple inserts”语句但是指定部分新行的自动递增值。例如 对于上面数据插入的案例,MySQL采用了 innodb_autoinc_lock_mode有三种取值,分别对应与不同锁定模式: 在此锁定模式下,所有类型的insert语句都会获得一个特殊的表级AUTO-INC锁,用于插入具有AUTO_INCREMENT列的表。这种模式其实就如我们上面的例子,即每当执行insert的时候,都会得到一个表级锁(AUTO-INC锁),使得语句中生成的auto_increment为顺序,且在binlog中重放的时候,可以保证master与slave中数据的auto_increment是相同的。因为是表级锁,当在同一时间多个事务中执行insert的时候,对于AUTO-INC锁的争夺会 在 MySQL 8.0 之前,连续锁定模式是 在这个模式下,“bulk inserts”仍然使用AUTO-INC表级锁,并保持到语句结束。这适用于所有INSERT … SELECT,REPLACE … SELECT和LOAD DATA语句。同一时刻只有一个语句可以持有AUTO-INC锁。 对于“Simple inserts”(要插入的行数事先已知),则通过在 从 MySQL 8.0 开始,交错锁模式是 在这种锁定模式下,所有类INSERT语句都不会使用表级AUTO-INC锁,并且可以同时执行多个语句。这是最快和最可拓展的锁定模式,但是当使用基于语句的复制或恢复方案时,从二进制日志重播SQL语句时,这是不安全的。 在此锁定模式下,自动递增值 ④ 元数据锁(MDL锁) MySQL5.5引入了meta data lock,简称MDL锁,属于表锁范畴。MDL 的作用是,保证读写的正确性。比如,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个 因此,当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。 2. InnoDB中的行锁 行锁(Row Lock)也称为记录锁,顾名思义,就是锁住某一行(某条记录row)。需要注意的是,MySQL服务器层并没有实现行锁机制,行级锁只在存储引擎层实现。 **优点:**锁定力度小,发生 **缺点:**对于 InnoDB与MyISAM的最大不同有两点:一是支持事务;二是采用了行级锁。 ① 记录锁(Record Locks) 记录锁也就是仅仅把一条记录锁上,官方的类型名称为: 记录锁是有S锁和X锁之分的,称之为 ② 间隙锁(Gap Locks) gap锁的提出仅仅是为了防止插入幻影记录而提出的。虽然有 ③ 临键锁(Next-Key Locks) 有时候我们既想 ④ 插入意向锁(Insert Intention Locks) 我们说一个事务在 插入意向锁是在插入一条记录行前,由 事实上插入意向锁并不会阻止别的事务继续获取该记录上任何类型的锁。 3. 页锁 页锁就是在 每个层级的锁数量是有限制的,因为锁会占用内存空间, 从对待锁的态度来看锁的话,可以将锁分成乐观锁和悲观锁,从名字中也可以看出这两种锁是两种看待 1. 悲观锁(Pessimistic Locking) 悲观锁总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 注意:select … for update 语句执行过程中所有扫描的行都会被锁上,因此在MySQL中用悲观锁必须确定使用了索引,而不是全表扫描,否则将会把整个表锁住。 2. 乐观锁(Optimistic Locking) 乐观锁认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,也就是不采用数据库自身的锁机制,而是通过程序来实现。在程序上,我们可以采用 1. 乐观锁的版本号机制 在表中设计一个 2. 乐观锁的时间戳机制 时间戳和版本号机制一样,也是在更新提交的时候,将当前数据的时间戳和更新之前取得的时间戳进行比较,如果两者一致则更新成功,否则就是版本冲突。 你能看到乐观锁就是程序员自己控制数据并发操作的权限,基本是通过给数据行增加一个戳(版本号或者时间戳),从而证明当前拿到的数据是否最新。 3. 两种锁的适用场景 从这两种锁的设计思想中,我们总结一下乐观锁和悲观锁的适用场景: 1. 隐式锁 **情景一:**对于聚簇索引记录来说,有一个 **情景二:**对于二级索引记录来说,本身并没有 即:一个事务对新插入的记录可以不显示的加锁(生成一个锁结构),但是由于 2. 显式锁 通过特定的语句进行加锁,我们一般称之为显示加锁。 全局锁就是对 全局锁的命令: 死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环。 1. 如何处理死锁 **方式1:**等待,直到超时(innodb_lock_wait_timeout=50s) 即当两个事务互相等待时,当一个事务等待时间超过设置的阈值时,就将其 **方式2:**使用死锁检测进行死锁处理 发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务(将持有最少行级排他锁的事务进行回滚),让其他事务得以继续执行。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dLE9ml2A-1656668798823)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051514736.png)] 结构解析: 不论是 此 对于 n_bits的值一般都比页面中记录条数多一些。主要是为了之后在页面中插入了新记录后也不至于重新分配锁结构 这是一个32位的数,被分成了 在InnoDB存储引擎中,LOCK_IS,LOCK_IX,LOCK_AUTO_INC都算是表级锁的模式,LOCK_S和 LOCK_X既可以算是表级锁的模式,也可以是行级锁的模式。 为了更好的管理系统运行过程中生成的各种锁结构而设计了各种哈希表和链表。 如果是 其他监控方法: MySQL把事务和锁的信息记录在了 MySQL8.0删除了information_schema.INNODB_LOCKS,添加了 同时,information_schema.INNODB_LOCK_WAITS也被 MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC 是通过数据行的多个版本管理来实现数据库的 MVCC在MySQL InnoDB中的实现主要是为了提高数据库并发性能,用更好的方式去处理 快照读又叫一致性读,读取的是快照数据。不加锁的简单的 SELECT 都属于快照读,即不加锁的非阻塞读。 之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于MVCC,它在很多情况下,避免了加锁操作,降低了开销。 既然是基于多版本,那么快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。 快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读。 当前读读取的是记录的最新版本(最新数据,而不是历史版本的数据),读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。加锁的 SELECT,或者对数据进行增删改都会进行当前读。 我们知道事务有 4 个隔离级别,可能存在三种并发问题: 另图: 回顾一下undo日志的版本链,对于使用 MVCC 的实现依赖于:隐藏字段、Undo Log、Read View。 ReadView就是事务在使用MVCC机制进行快照读操作时产生的读视图。当事务启动时,会生成数据库系统当前的一个快照,InnoDB为每个事务构造了一个数组,用来记录并维护系统当前 使用 使用 使用 这个ReadView中主要包含4个比较重要的内容,分别如下: 说明:只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。 注意:low_limit_id并不是trx_ids中的最大值,事务id是递增分配的。比如,现在有id为1, 2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,trx_ids就包括1和2,up_limit_id的值就是1,low_limit_id的值就是4。 有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见。 了解了这些概念之后,我们来看下当查询一条记录的时候,系统如何通过MVCC找到它: 首先获取事务自己的版本号,也就是事务 ID; 获取 ReadView; 查询得到的数据,然后与 ReadView 中的事务版本号进行比较; 如果不符合 ReadView 规则,就需要从 Undo Log 中获取历史快照; 最后返回符合规则的数据。 在隔离级别为读已提交(Read Committed)时,一个事务中的每一次 SELECT 查询都会重新获取一次Read View。 如表所示: 注意,此时同样的查询语句都会重新获取一次 Read View,这时如果 Read View 不同,就可能产生不可重复读或者幻读的情况。 当隔离级别为可重复读的时候,就避免了不可重复读,这是因为一个事务只在第一次 SELECT 的时候会获取一次 Read View,而后面所有的 SELECT 都会复用这个 Read View,如下表所示: READ COMMITTED :每次读取数据前都生成一个ReadView。 使用 假设现在表 student 中只有一条数据,数据内容中,主键 id=1,隐藏的 trx_id=10,它的 undo log 如下图所示。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pJm3gx7R-1656668798826)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051556631.png)] 假设现在有事务 A 和事务 B 并发执行, 步骤1:事务 A 开始第一次查询数据,查询的 SQL 语句如下。 在开始查询之前,MySQL 会为事务 A 产生一个 ReadView,此时 ReadView 的内容如下: 由于此时表 student 中只有一条数据,且符合 where id>=1 条件,因此会查询出来。然后根据 ReadView机制,发现该行数据的trx_id=10,小于事务 A 的 ReadView 里 up_limit_id,这表示这条数据是事务 A 开启之前,其他事务就已经提交了的数据,因此事务 A 可以读取到。 结论:事务 A 的第一次查询,能读取到一条数据,id=1。 步骤2:接着事务 B(trx_id=30),往表 student 中新插入两条数据,并提交事务。 此时表student 中就有三条数据了,对应的 undo 如下图所示: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X3D1dXqk-1656668798826)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051559345.png)] 步骤3:接着事务 A 开启第二次查询,根据可重复读隔离级别的规则,此时事务 A 并不会再重新生成ReadView。此时表 student 中的 3 条数据都满足 where id>=1 的条件,因此会先查出来。然后根据ReadView 机制,判断每条数据是不是都可以被事务 A 看到。 1)首先 id=1 的这条数据,前面已经说过了,可以被事务 A 看到。 2)然后是 id=2 的数据,它的 trx_id=30,此时事务 A 发现,这个值处于 up_limit_id 和 low_limit_id 之间,因此还需要再判断 30 是否处于 trx_ids 数组内。由于事务 A 的 trx_ids=[20,30],因此在数组内,这表示 id=2 的这条数据是与事务 A 在同一时刻启动的其他事务提交的,所以这条数据不能让事务 A 看到。 3)同理,id=3 的这条数据,trx_id 也为 30,因此也不能被事务 A 看见。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cpcHBfYg-1656668798827)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051559867.png)] 结论:最终事务 A 的第二次查询,只能查询出 id=1 的这条数据。这和事务 A 的第一次查询的结果是一样的,因此没有出现幻读现象,所以说在 MySQL 的可重复读隔离级别下,不存在幻读问题。 这里介绍了 核心点在于 ReadView 的原理, MySQL有不同类型的日志文件,用来存储不同类型的日志,分为 **慢查询日志:**记录所有执行时间超过long_query_time的所有查询,方便我们对查询进行优化。 **通用查询日志:**记录所有连接的起始时间和终止时间,以及连接发送给数据库服务器的所有指令,对我们复原操作的实际场景、发现问题,甚至是对数据库操作的审计都有很大的帮助。 **错误日志:**记录MySQL服务的启动、运行或停止MySQL服务时出现的问题,方便我们了解服务器的状态,从而对服务器进行维护。 **二进制日志:**记录所有更改数据的语句,可以用于主从服务器之间的数据同步,以及服务器遇到故障时数据的无损失恢复。 **中继日志:**用于主从服务器架构中,从服务器用来存放主服务器二进制日志内容的一个中间文件。从服务器通过读取中继日志的内容,来同步主服务器上的操作。 **数据定义语句日志:**记录数据定义语句执行的元数据操作。 除二进制日志外,其他日志都是 日志功能会 日志会 通用查询日志用来 方式1:永久性方式 方式2:临时性方式 方式1:永久性方式 方式2:临时性方式 在MySQL数据库中,错误日志功能是 方式1:永久性方式 设置带文件夹的bin-log日志存放目录 注意:新建的文件夹需要使用mysql用户,使用下面的命令即可。 方式2:临时性方式 上面这种办法读取出binlog日志的全文内容比较多,不容易分辨查看到pos点信息,下面介绍一种更为方便的查询命令: mysqlbinlog恢复数据的语法如下: 注意:使用mysqlbinlog命令进行恢复操作时,必须是编号小的先恢复,例如atguigu-bin.000001必须在atguigu-bin.000002之前恢复。 1. PURGE MASTER LOGS:删除指定日志文件 binlog的写入时机也非常简单,事务执行过程中,先把日志写到 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jj3eIgxE-1656668798828)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051630535.png)] write和fsync的时机,可以由参数 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sCeiZ4DU-1656668798828)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051631346.png)] 为了安全起见,可以设置为 在出现IO瓶颈的场景里,将sync_binlog设置成一个比较大的值,可以提升性能。同样的,如果机器宕机,会丢失最近N个事务的binlog日志。 在执行更新语句过程,会记录redo log与binlog两块日志,以基本的事务为单位,redo log在事务执行过程中可以不断写入,而binlog只有在提交事务时才写入,所以redo log与binlog的 为了解决两份日志之间的逻辑一致问题,InnoDB存储引擎使用两阶段提交方案。 使用两阶段提交后,写入binlog时发生异常也不会有影响 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cdJlzuh4-1656668798829)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051639192.png)] 另一个场景,redo log设置commit阶段发生异常,那会不会回滚事务呢? [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fd13nmzu-1656668798829)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051639403.png)] 并不会回滚事务,它会执行上图框住的逻辑,虽然redo log是处于prepare阶段,但是能通过事务id找到对应的binlog日志,所以MySQL认为是完整的,就会提交事务恢复数据。 中继日志只在主从服务器架构的从服务器上存在。从服务器为了与主服务器保持一致,要从主服务器读取二进制日志的内容,并且把读取到的信息写入 如果从服务器宕机,有的时候为了系统恢复,要重装操作系统,这样就可能会导致你的 解决的方法也很简单,把从服务器的名称改回之前的名称。 一般应用对数据库而言都是“ 如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何 第1个作用:读写分离。 第2个作用就是数据备份。 第3个作用是具有高可用性。 三个线程 实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 复制三步骤 步骤1: 步骤2: 步骤3: 复制的问题 复制的最大问题: 每个 每个 每个 主从同步的要求: 读库和写库的数据一致(最终一致); 写数据必须写到写库; 读数据必须到读库(不一定); 进行主从同步的内容是二进制日志,它是一个文件,在进行 在网络正常的时候,日志从主库传给从库所需的时间是很短的,即T2-T1的值是非常小的。即,网络正常情况下,主备延迟的主要来源是备库接收完binlog和执行完这个事务之间的时间差。 **主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。**造成原因: 1、从库的机器性能比主库要差 2、从库的压力大 3、大事务的执行 若想要减少主从延迟的时间,可以采取下面的办法: 降低多线程大事务并发的概率,优化业务逻辑 优化SQL,避免慢SQL, 尽量采用 实时性要求的业务读强制走主库,从库只做灾备,备份。 读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间 数据复制方式 的问题,如果按照数据一致性 从弱到强 来进行划分,有以下 3 种复制方式。 方法 1:异步复制 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ASnERnX-1656668798832)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051654133.png)] 方法 2:半同步复制 方法 3:组复制 首先我们将多个节点共同组成一个复制组,在 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UfUaygAm-1656668798833)(https://cdn.jsdelivr.net/gh/aoshihuankong/cloudimg@master/img/202204051656560.png)] 物理备份:备份数据文件,转储数据库物理文件到某一目录。物理备份恢复速度比较快,但占用空间比较大,MySQL中可以用 逻辑备份:对数据库对象利用工具进行导出工作,汇总入备份文件内。逻辑备份恢复速度慢,但占用空间小,更灵活。MySQL 中常用的逻辑备份工具为 1. 使用SELECT…INTO OUTFILE导出文本文件 2. 使用mysqldump命令导出文本文件 3. 使用mysql命令导出文本文件 1. 使用LOAD DATA INFILE方式导入文本文件 2. 使用mysqlimport方式导入文本文件
4.2 开发中经验
5. 位类型:BIT
二进制字符串类型
长度
长度范围
占用空间
BIT(M)
M
1 <= M <= 64
约为(M + 7)/8个字节
6. 日期与时间类型
YEAR类型通常用来表示年DATE类型通常用来表示年、月、日TIME类型通常用来表示时、分、秒DATETIME类型通常用来表示年、月、日、时、分、秒TIMESTAMP类型通常用来表示带时区的年、月、日、时、分、秒
类型
名称
字节
日期格式
最小值
最大值
YEAR
年
1
YYYY或YY
1901
2155
TIME
时间
3
HH:MM:SS
-838:59:59
838:59:59
DATE
日期
3
YYYY-MM-DD
1000-01-01
9999-12-03
DATETIME
日期时间
8
YYYY-MM-DD HH:MM:SS
1000-01-01 00:00:00
9999-12-31 23:59:59
TIMESTAMP
日期时间
4
YYYY-MM-DD HH:MM:SS
1970-01-01 00:00:00 UTC
2038-01-19 03:14:07UTC
6.1 YEAR类型
1个字节 的存储空间。
6.2 DATE类型
YYYY-MM-DD,其中,YYYY表示年份,MM表示月份,DD表示日期。需要3个字节的存储空间。在向DATE类型的字段插入数据时,同样需要满足一定的格式条件。
YYYY-MM-DD格式或者YYYYMMDD格式表示的字符串日期,其最小取值为1000-01-01,最大取值为9999-12-03。YYYYMMDD格式会被转化为YYYY-MM-DD格式。YY-MM-DD格式或者YYMMDD格式表示的字符串日期,此格式中,年份为两位数值或字符串满足YEAR类型的格式条件为:当年份取值为00到69时,会被转化为2000到2069;当年份取值为70到99时,会被转化为1970到1999。CURRENT_DATE()或者NOW()函数,会插入当前系统的日期。6.3 TIME类型
3个字节的存储空间来存储TIME类型的数据,可以使用“HH:MM:SS”格式来表示TIME类型,其中,HH表示小时,MM表示分钟,SS表示秒。D HH:MM:SS’、‘HH:MM:SS’、‘HH:MM’、‘D HH:MM’、'D HH’或’SS’格式,都能被正确地插入TIME类型的字段中。其中D表示天,其最小值为0,最大值为34。如果使用带有D格式的字符串插入TIME类型的字段时,D会被转化为小时,计算格式为D*24+HH。当使用带有冒号并且不带D的字符串表示时间时,表示当天的时间,比如12:10表示12:10:00,而不是00:12:10。 (2)可以使用不带有冒号的字符串或者数字,格式为’HHMMSS’或者HHMMSS。如果插入一个不合法的字符串或者数字,MySQL在存储数据时,会将其自动转化为00:00:00进行存储。比如1210,MySQL会将最右边的两位解析成秒,表示00:12:10,而不是12:10:00。 (3)使用CURRENT_TIME()或者NOW(),会插入当前系统的时间。8个字节的存储空间。在格式上为DATE类型和TIME类型的组合,可以表示为YYYY-MM-DD HH:MM:SS,其中YYYY表示年份,MM表示月份,DD表示日期,HH表示小时,MM表示分钟,SS表示秒。
YYYY-MM-DD HH:MM:SS格式或者YYYYMMDDHHMMSS格式的字符串插入DATETIME类型的字段时,最小值为1000-01-01 00:00:00,最大值为9999-12-03 23:59:59。
CURRENT_TIMESTAMP()和NOW(),可以向DATETIME类型的字段插入系统的当前日期和时间。6.5 TIMESTAMP类型
YYYY-MM-DD HH:MM:SS,需要4个字节的存储空间。但是TIMESTAMP存储的时间范围比DATETIME要小很多,只能存储“1970-01-01 00:00:01 UTC”到“2038-01-19 03:14:07 UTC”之间的时间。其中,UTC表示世界统一时间,也叫作世界标准时间。
6.6 开发中经验
DATETIME。虽然 MySQL 也支持 YEAR(年)、 TIME(时间)、DATE(日期),以及 TIMESTAMP 类型,但是在实际项目中,尽量用 DATETIME 类型。因为这个数据类型包括了完整的日期和时间信息,取值范围也最大,使用起来比较方便。毕竟,如果日期时间信息分散在好几个字段,很不容易记,而且查询的时候,SQL 语句也会更加复杂。时间戳,因为DATETIME虽然直观,但不便于计算。7. 文本字符串类型
7.1 CHAR与VARCHAR类型
字符串(文本)类型
特点
长度
长度范围
占用的存储空间
CHAR(M)
固定长度
M
0 <= M <= 255
M个字节
VARCHAR(M)
可变长度
M
0 <= M <= 65535
(实际长度 + 1) 个字节
右侧填充空格以达到指定的长度。当MySQL检索CHAR类型的数据时,CHAR类型的字段会去除尾部的空格。
必须指定长度M,否则报错。
类型
特点
空间上
时间上
适用场景
CHAR(M)
固定长度
浪费存储空间
效率高
存储不大,速度要求高
VARCHAR(M)
可变长度
节省存储空间
效率低
非CHAR的情况
MyISAM数据存储引擎和数据列:MyISAM数据表,最好使用固定长度(CHAR)的数据列代替可变长度(VARCHAR)的数据列。这样使得整个表静态化,从而使数据检索更快,用空间换时间。MEMORY存储引擎和数据列:MEMORY数据表目前都使用固定长度的数据行存储,因此无论使用CHAR或VARCHAR列都没有关系,两者都是作为CHAR类型处理的。7.2 TEXT类型
文本字符串类型
特点
长度
长度范围
占用的存储空间
TINYTEXT
小文本、可变长度
L
0 <= L <= 255
L + 2 个字节
TEXT
文本、可变长度
L
0 <= L <= 65535
L + 2 个字节
MEDIUMTEXT
中等文本、可变长度
L
0 <= L <= 16777215
L + 3 个字节
LONGTEXT
大文本、可变长度
L
0 <= L<= 4294967295(相当于4GB)
L + 4 个字节
8. ENUM类型
文本字符串类型
长度
长度范围
占用的存储空间
ENUM
L
1 <= L <= 65535
1或2个字节
CREATE TABLE test_enum(
season ENUM('春','夏','秋','冬','unknow')
);
INSERT INTO test_enum
VALUES('春'),('秋');
# 允许按照角标的方式获取指定索引位置的枚举值
INSERT INTO test_enum
VALUES('1'),(3);
# 当ENUM类型的字段没有声明为NOT NULL时,插入NULL也是有效的
INSERT INTO test_enum
VALUES(NULL);
9. SET类型
成员个数范围(L表示实际成员个数)
占用的存储空间
1 <= L <= 8
1个字节
9 <= L <= 16
2个字节
17 <= L <= 24
3个字节
25 <= L <= 32
4个字节
33 <= L <= 64
8个字节
CREATE TABLE test_set(
s SET ('A', 'B', 'C')
);
INSERT INTO test_set (s)
VALUES ('A'), ('A,B');
#插入重复的SET类型成员时,MySQL会自动删除重复的成员
INSERT INTO test_set (s)
VALUES ('A,B,C,A');
10. 二进制字符串类型
1个字节。例如BINARY (8),表示最多能存储8个字节,如果字段值不足(M)个字节,将在右边填充’\0’以补齐指定长度。必须指定(M),否则报错。
二进制字符串类型
特点
值的长度
占用空间
BINARY(M)
固定长度
M (0 <= M <= 255)
M个字节
VARBINARY(M)
可变长度
M(0 <= M <= 65535)
M+1个字节
二进制大对象,可以容纳可变数量的数据。服务器的磁盘上,并将图片、音频和视频的访问路径存储到MySQL中。
二进制字符串类型
值的长度
长度范围
占用空间
TINYBLOB
L
0 <= L <= 255
L + 1 个字节
BLOB
L
0 <= L <= 65535(相当于64KB)
L + 2 个字节
MEDIUMBLOB
L
0 <= L <= 16777215 (相当于16MB)
L + 3 个字节
LONGBLOB
L
0 <= L <= 4294967295(相当于4GB)
L + 4 个字节
空洞",以后填入这些"空洞"的记录可能长度不同。为了提高性能,建议定期使用 OPTIMIZE TABLE 功能对这类表进行碎片整理。前缀索引。但是仍然要在不必要的时候避免检索大型的BLOB或TEXT值。例如,SELECT * 查询就不是很好的想法,除非你能够确定作为约束条件的WHERE子句只会找到所需要的数据行。否则,你可能毫无目的地在网络上传输大量的值。分离到单独的表中。在某些环境中,如果把这些数据列移动到第二张数据表中,可以让你把原数据表中的数据列转换为固定长度的数据行格式,那么它就是有意义的。这会减少主表中的碎片,使你得到固定长度数据行的性能优势。它还使你在主数据表上运行 SELECT * 查询的时候不会通过网络传输大量的BLOB或TEXT值。11. JSON 类型
CREATE TABLE test_json(
js json
);
INSERT INTO test_json (js)
VALUES ('{"name":"songhk", "age":18, "address":{"province":"beijing", "city":"beijing"}}');
SELECT js -> '$.name' AS NAME,js -> '$.age' AS age ,js -> '$.address.province' AS province, js -> '$.address.city' AS city
FROM test_json;
12. 空间类型
13. 小结及选择建议
整数,就用INT; 如果是小数,一定用定点数类型DECIMAL(M,D); 如果是日期与时间,就用DATETIME。
强制】小数类型为 DECIMAL,禁止使用 FLOAT 和 DOUBLE。
强制】如果存储的字符串长度几乎相等,使用 CHAR 定长字符串类型。强制】VARCHAR 是可变长字符串,不预先分配存储空间,长度不要超过 5000。如果存储长度大于此值,定义字段类型为 TEXT,独立出来一张表,用主键来对应,避免影响其它字段索引效率。第13章 约束
1. 约束(constraint)概述
1.1 为什么需要约束
实体完整性(Entity Integrity):例如,同一个表中,不能存在两条完全相同无法区分的记录域完整性(Domain Integrity):例如:年龄范围0-120,性别范围“男/女”引用完整性(Referential Integrity):例如:员工所在部门,在部门表中要能找到这个部门用户自定义完整性(User-defined Integrity):例如:用户名唯一、密码不能为空等,本部门经理的工资不得高于本部门职工的平均工资的5倍。1.2 什么是约束
1.3 约束的分类
#information_schema数据库名(系统库)
#table_constraints表名称(专门存储各个表的约束)
SELECT * FROM information_schema.table_constraints
WHERE table_name = '表名称';
2. 非空约束
2.1 作用
2.2 关键字
2.3 特点
2.4 添加非空约束
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);
ALTER TABLE 表名称
MODIFY 字段名 数据类型 NOT NULL;
2.5 删除非空约束
# 方式一:
ALTER TABLE 表名称
MODIFY 字段名 数据类型 NULL;
# 方式二:
ALTER TABLE 表名称
MODIFY 字段名 数据类型;
3. 唯一性约束
3.1 作用
3.2 关键字
3.3 特点
3.4 添加(复合)唯一约束
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 UNIQUE [KEY],
字段名 数据类型
);
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[CONSTRAINT 约束名] UNIQUE [KEY](字段列表) #多个字段之间用逗号隔开
);
#字段列表中如果是一个字段,表示该列的值唯一。如果是两个或更多个字段,那么复合唯一,即多个字段的组合是唯一的
#方式1:
ALTER TABLE 表名称
ADD [CONSTRAINT 约束名] UNIQUE [KEY](字段列表); #多个字段之间用逗号隔开
#方式2:
ALTER TABLE 表名称
MODIFY 字段名 字段类型 UNIQUE [KEY];
3.5 删除唯一约束
ALTER TABLE 表名称
DROP INDEX 索引名;
show index from 表名称;查看表的索引4. PRIMARY KEY 约束
4.1 作用
4.2 关键字
4.3 特点
4.4 添加(复合)主键约束
create table 表名称(
字段名 数据类型 primary key, #列级模式
字段名 数据类型,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] primary key(字段列表) #表级模式,多个字段之间用逗号隔开
);
# 列级约束
CREATE TABLE emp4(
id INT PRIMARY KEY AUTO_INCREMENT, # AUTO_INCREMENT 表示自增
NAME VARCHAR(20)
);
# 表级约束
CREATE TABLE emp5(
id INT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20), pwd VARCHAR(15),
CONSTRAINT emp5_id_pk PRIMARY KEY(id) #没有必要起名字
);
ALTER TABLE 表名称
ADD PRIMARY KEY(字段列表); #字段列表可以是一个字段,也可以是多个字段,如果是多个字段的话,是复合主键
4.5 删除主键约束
alter table 表名称
drop primary key;
5. 自增列:AUTO_INCREMENT
5.1 作用
5.2 关键字
5.3 特点和要求
5.4 如何指定自增约束
create table 表名称(
字段名 数据类型 primary key auto_increment,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值
);
create table 表名称(
字段名 数据类型 default 默认值,
字段名 数据类型 unique key auto_increment,
字段名 数据类型 not null default 默认值,
primary key(字段名)
);
alter table 表名称 modify 字段名 数据类型 auto_increment;
5.5 如何删除自增约束
#alter table 表名称 modify 字段名 数据类型 auto_increment;#给这个字段增加自增约束
alter table 表名称 modify 字段名 数据类型; #去掉auto_increment相当于删除
5.6 MySQL 8.0新特性—自增变量的持久化
计数器来决定的,而该计数器只在内存中维护,并不会持久化到磁盘中。当数据库重启时,该计数器会被初始化。重做日志中。每次计数器发生改变,都会将其写入重做日志中。如果数据库重启,InnoDB会根据重做日志中的信息来初始化计数器的内存值。6. FOREIGN KEY 约束
6.1 作用
6.2 关键字
6.3 主表和从表/父表和子表
6.4 特点
手动删除对应的索引6.5 添加外键约束
create table 主表名称(
字段1 数据类型 primary key,
字段2 数据类型
);
create table 从表名称(
字段1 数据类型 primary key,
字段2 数据类型,
[CONSTRAINT <外键约束名称>] FOREIGN KEY(从表的某个字段) references 主表名(被参考字段)
);
#(从表的某个字段)的数据类型必须与主表名(被参考字段)的数据类型一致,逻辑意义也一样
#(从表的某个字段)的字段名可以与主表名(被参考字段)的字段名一样,也可以不一样
-- FOREIGN KEY: 在表级指定子表中的列
-- REFERENCES: 标示在父表中的列
ALTER TABLE 从表名
ADD [CONSTRAINT 约束名] FOREIGN KEY (从表的字段) REFERENCES 主表名(被引用 字段) [on update xx][on delete xx];
6.6 约束等级
Cascade方式:在父表上update/delete记录时,同步update/delete掉子表的匹配记录Set null方式:在父表上update/delete记录时,将子表上匹配记录的列设为null,但是要注意子表的外键列不能为not nullNo action方式:如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作Restrict方式:同no action, 都是立即检查外键约束Set default方式(在可视化工具SQLyog中可能显示空白):父表有变更时,子表将外键列设置成一个默认的值,但Innodb不能识别ON UPDATE CASCADE ON DELETE RESTRICT的方式。create table emp(
eid int primary key, #员工编号
ename varchar(5), #员工姓名
deptid int, #员工所在的部门
foreign key (deptid) references dept(did) ON UPDATE CASCADE ON DELETE RESTRICT #把修改操作设置为级联修改等级,把删除操作设置为Restrict等级
);
6.7 删除外键约束
# (1)第一步先查看约束名和删除外键约束
SELECT * FROM information_schema.table_constraints WHERE table_name = '表名称';#查看某个表的约束名
ALTER TABLE 从表名 DROP FOREIGN KEY 外键约束名;
#(2)第二步查看索引名和删除索引。(注意,只能手动删除)
SHOW INDEX FROM 表名称; #查看某个表的索引名
ALTER TABLE 从表名 DROP INDEX 索引名;
6.8 开发场景
引用完整性,只能依靠程序员的自觉,或者是在Java程序中进行限定。例如:在员工表中,可以添加一个员工的信息,它的部门指定为一个完全不存在的部门。
因为外键约束的系统开销而变得非常慢。所以, MySQL 允许你不使用系统自带的外键约束,在应用层面完成检查数据一致性的逻辑。也就是说,即使你不用外键约束,也要想办法通过应用层面的附加逻辑,来实现外键约束的功能,确保数据的一致性。6.9 阿里开发规范
强制】不得使用外键与级联,一切外键概念必须在应用层解决。单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。7. CHECK 约束
7.1 作用
7.2 关键字
7.3 说明:MySQL 5.7 不支持
CREATE TABLE temp(
id INT AUTO_INCREMENT,
NAME VARCHAR(20),
age INT CHECK(age > 20),
gender char CHECK ('男' OR '女'),
PRIMARY KEY(id)
);
8. DEFAULT约束
8.1 作用
8.2 关键字
8.3 如何给字段加默认值
create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 not null default 默认值,
字段名 数据类型 not null default 默认值,
primary key(字段名),
unique key(字段名)
);
# 说明:默认值约束一般不在唯一键和主键列上加
alter table 表名称
modify 字段名 数据类型 default 默认值;
#如果这个字段原来有非空约束,你还保留非空约束,那么在加默认值约束时,还得保留非空约束,否则非空约束就被删除了
#同理,在给某个字段加非空约束也一样,如果这个字段原来有默认值约束,你想保留,也要在modify语句中保留默认值约束,否则就删除了
alter table 表名称 modify 字段名 数据类型 default 默认值 not null;
8.4 如何删除默认值约束
alter table 表名称 modify 字段名 数据类型 ;#删除默认值约束,也不保留非空约束
alter table 表名称 modify 字段名 数据类型 not null; #删除默认值约束,保留非空约束
9. 面试
第14章 视图
1. 常见的数据库对象
对象
描述
表(TABLE)
表是存储数据的逻辑单元,以行和列的形式存在,列就是字段,行就是记录
数据字典
就是系统表,存放数据库相关信息的表。系统表的数据通常由数据库系统维护,程序员通常不应该修改,只可查看
约束(CONSTRAINT)
执行数据校验的规则,用于保证数据完整性的规则
视图(VIEW)
一个或者多个数据表里的数据的逻辑显示,视图并不存储数据
索引(INDEX)
用于提高查询性能,相当于书的目录
存储过程(PROCEDURE)
用于完成一次完整的业务处理,没有返回值,但可通过传出参数将多个值传给调用环境
存储函数(FUNCTION)
用于完成一次特定的计算,具有一个返回值
触发器(TRIGGER)
相当于一个事件监听器,当数据库发生特定事件后,触发器被触发,完成相应的处理
2. 视图概述
2.1 为什么使用视图?
2.2 视图的理解
虚拟表,本身是不具有数据的,占用很少的内存空间,它是 SQL 中的一个重要概念。
3. 创建视图
CREATE [OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW 视图名称 [(字段列表)]
AS 查询语句
[WITH [CASCADED|LOCAL] CHECK OPTION]
CREATE VIEW 视图名称
AS 查询语句
4. 查看视图
SHOW TABLES;
DESC / DESCRIBE 视图名称;
# 查看视图信息(显示数据表的存储引擎、版本、数据行数和数据大小等)
SHOW TABLE STATUS LIKE '视图名称'\G
SHOW CREATE VIEW 视图名称;
5. 更新视图的数据
5.1 一般情况
5.2 不可更新的视图
一对一的关系。另外当视图定义出现如下情况时,视图不支持更新操作:
JOIN联合查询,视图将不支持INSERT和DELETE操作;数学表达式或子查询,视图将不支持INSERT,也不支持UPDATE使用了数学表达式、子查询的字段值;DISTINCT、聚合函数、GROUP BY、HAVING、UNION等,视图将不支持INSERT、UPDATE、DELETE;不可更新视图;
虚拟表,主要用于方便查询,不建议更新视图的数据。对视图数据的更改,都是通过对实际数据表里数据的操作来完成的。6. 修改、删除视图
6.1 修改视图
ALTER VIEW 视图名称
AS
查询语句
6.2 删除视图
DROP VIEW IF EXISTS 视图名称;
7. 总结
7.1 视图优点
访问限制在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用户不必直接查询或操作数据表。这也可以理解为视图具有隔离性。视图相当于在用户和实际的数据表之间加了一层虚拟表。7.2 视图不足
第15章 存储过程与函数
1. 存储过程概述
1.1 理解
Stored Procedure。它的思想很简单,就是一组经过预先编译的 SQL 语句的封装。2. 创建存储过程
2.1 语法分析
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGIN
存储过程体
END
IN:当前参数为输入参数,也就是表示入参;
默认就是 IN,表示输入参数。OUT:当前参数为输出参数,也就是表示出参;
INOUT:当前参数既可以为输入参数,也可以为输出参数。characteristics表示创建存储过程时指定的对存储过程的约束条件,其取值信息如下:LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
LANGUAGE SQL:说明存储过程执行体是由SQL语句组成的,当前系统支持的语言为SQL。[NOT] DETERMINISTIC:指明存储过程执行的结果是否确定。DETERMINISTIC表示结果是确定的。每次执行存储过程时,相同的输入会得到相同的输出。NOT DETERMINISTIC表示结果是不确定的,相同的输入可能得到不同的输出。如果没有指定任意一个值,默认为NOT DETERMINISTIC。{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }:指明子程序使用SQL语句的限制。
SQL SECURITY { DEFINER | INVOKER }:执行当前存储过程的权限,即指明哪些用户能够执行当前存储过程。
DEFINER表示只有当前存储过程的创建者或者定义者才能执行当前存储过程;INVOKER表示拥有当前存储过程的访问权限的用户能够执行当前存储过程。COMMENT 'string':注释信息,可以用来描述存储过程。DELIMITER 新的结束标记
2.2 代码举例
DELIMITER $
CREATE PROCEDURE select_all_data()
BEGIN
SELECT * FROM emps;
END $
DELIMITER ;
DELIMITER //
CREATE PROCEDURE avg_employee_salary ()
BEGIN
SELECT AVG(salary) AS avg_salary FROM emps;
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE show_max_salary()
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT '查看最高薪资'
BEGIN
SELECT MAX(salary) FROM emps;
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE show_someone_salary2(IN empname VARCHAR(20),OUT empsalary DOUBLE)
BEGIN
SELECT salary INTO empsalary FROM emps WHERE ename = empname;
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(20))
BEGIN
SELECT ename INTO empname FROM emps WHERE eid = (SELECT MID FROM emps WHERE ename=empname);
END //
DELIMITER ;
3. 调用存储过程
3.1 调用格式
CALL 存储过程名(实参列表)
CALL sp1('值');
SET @name;
CALL sp1(@name);
SELECT @name;
SET @name=值;
CALL sp1(@name);
SELECT @name;
4. 存储函数的使用
4.1 语法分析
CREATE FUNCTION 函数名(参数名 参数类型,...)
RETURNS 返回值类型
[characteristics ...]
BEGIN
函数体 #函数体中肯定有 RETURN 语句
END
强制的。它用来指定函数的返回类型,而且函数体必须包含一个RETURN value语句。4.2 调用存储函数
SELECT 函数名(实参列表)
4.3 代码举例
DELIMITER //
CREATE FUNCTION count_by_id(dept_id INT)
RETURNS INT
LANGUAGE SQL
NOT DETERMINISTIC
READS SQL DATA
SQL SECURITY DEFINER
COMMENT '查询部门平均工资'
BEGIN
RETURN (SELECT COUNT(*) FROM employees WHERE department_id = dept_id);
END //
DELIMITER ;
SET @dept_id = 50;
SELECT count_by_id(@dept_id);
you might want to use the less safe log_bin_trust_function_creators variable”,有两种处理方法:
mysql> SET GLOBAL log_bin_trust_function_creators = 1;
4.4 对比存储函数和存储过程
关键字
调用语法
返回值
应用场景
存储过程
PROCEDURE
CALL 存储过程()
理解为有0个或多个
一般用于更新
存储函数
FUNCTION
SELECT 函数()
只能是一个
一般用于查询结果为一个值并返回时
5. 存储过程和函数的查看、修改、删除
5.1 查看
SHOW CREATE {PROCEDURE | FUNCTION} 存储过程名或函数名
SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern']
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='存储过程或函数的名' [AND ROUTINE_TYPE = {'PROCEDURE|FUNCTION'}];
5.2 修改
ALTER {PROCEDURE | FUNCTION} 存储过程或函数的名 [characteristic ...];
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
5.3 删除
DROP {PROCEDURE | FUNCTION} [IF EXISTS] 存储过程或函数的名;
6. 关于存储过程使用的争议
6.1 优点
封装成模块,实际上是编程的核心思想之一,这样可以把复杂的问题拆解成不同的模块,然后模块之间可以重复使用,在减少开发工作量的同时,还能保证代码的结构清晰。设置对用户的使用权限,这样就和视图一样具有较强的安全性。连接一次即可。6.2 缺点
第16章 变量、流程控制与游标
1. 变量
1.1 系统变量
1.1.1 系统变量分类
global关键字)以及会话系统变量(需要添加session关键字),有时也把全局系统变量简称为全局变量,有时也把会话系统变量称为local变量。**如果不写,默认会话级别。**静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
不能跨重启1.1.2 查看系统变量
#查看所有全局变量
SHOW GLOBAL VARIABLES;
#查看所有会话变量
SHOW SESSION VARIABLES;
#或
SHOW VARIABLES;
#查看满足条件的部分系统变量。
SHOW GLOBAL VARIABLES LIKE '%标识符%';
#查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%标识符%';
两个“@”开头,其中“@@global”仅用于标记全局系统变量,“@@session”仅用于标记会话系统变量。“@@”首先标记会话系统变量,如果会话系统变量不存在,则标记全局系统变量。#查看指定的系统变量的值
SELECT @@global.变量名;
#查看指定的会话变量的值
SELECT @@session.变量名;
#或者
SELECT @@变量名;
#为某个系统变量赋值
#方式1:
SET @@global.变量名=变量值;
#方式2:
SET GLOBAL 变量名=变量值;
#为某个会话变量赋值
#方式1:
SET @@session.变量名=变量值;
#方式2:
SET SESSION 变量名=变量值;
1.2 用户变量
1.2.1 用户变量分类
一个“@”开头。根据作用范围不同,又分为会话用户变量和局部变量。
当前连接会话有效。存储过程和函数中使用。1.2.2 会话用户变量
#方式1:“=”或“:=”
SET @用户变量 = 值;
SET @用户变量 := 值;
#方式2:“:=” 或 INTO关键字
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];
SELECT @用户变量
1.2.3 局部变量
DECLARE语句定义一个局部变量BEGIN
#声明局部变量
DECLARE 变量名1 变量数据类型 [DEFAULT 变量默认值];
DECLARE 变量名2,变量名3,... 变量数据类型 [DEFAULT 变量默认值];
#为局部变量赋值
SET 变量名1 = 值;
SELECT 值 INTO 变量名2 [FROM 子句];
#查看局部变量的值
SELECT 变量1,变量2,变量3;
END
DECLARE 变量名 类型 [default 值]; # 如果没有DEFAULT子句,初始值为NULL
SET 变量名=值;
SET 变量名:=值;
SELECT 字段名或表达式 INTO 变量名 FROM 表;
SELECT 局部变量名;
1.2.4 对比会话用户变量与局部变量
作用域
定义位置
语法
会话用户变量
当前会话
会话的任何地方
加@符号,不用指定类型
局部变量
定义它的BEGIN END中
BEGIN END的第一句话
一般不用加@,需要指定类型
2. 定义条件与处理程序
定义条件是事先定义程序执行过程中可能遇到的问题,处理程序定义了在遇到问题时应当采取的处理方式,并且保证存储过程或函数在遇到警告或错误时能继续执行。这样可以增强存储程序处理问题的能力,避免程序异常停止运行。2.1 定义条件
DECLARE 错误名称 CONDITION FOR 错误码(或错误条件)
MySQL_error_code和sqlstate_value都可以表示MySQL的错误。
#使用MySQL_error_code
DECLARE Field_Not_Be_NULL CONDITION FOR 1048;
#使用sqlstate_value
DECLARE Field_Not_Be_NULL CONDITION FOR SQLSTATE '23000';
2.2 定义处理程序
DECLARE 处理方式 HANDLER FOR 错误类型 处理语句
CONTINUE:表示遇到错误不处理,继续执行。EXIT:表示遇到错误马上退出。UNDO:表示遇到错误后撤回之前的操作。MySQL中暂时不支持这样的操作。
SQLSTATE '字符串错误码':表示长度为5的sqlstate_value类型的错误代码;MySQL_error_code:匹配数值类型错误代码;错误名称:表示DECLARE … CONDITION定义的错误条件名称。SQLWARNING:匹配所有以01开头的SQLSTATE错误代码;NOT FOUND:匹配所有以02开头的SQLSTATE错误代码;SQLEXCEPTION:匹配所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码;SET 变量 = 值”这样的简单语句,也可以是使用BEGIN ... END编写的复合语句。#方法1:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
#方法2:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
#方法3:先定义条件,再调用
DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR NO_SUCH_TABLE SET @info = 'NO_SUCH_TABLE';
#方法4:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
#方法5:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
#方法6:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';
3. 流程控制
3.1 分支结构之 IF
IF 表达式1 THEN 操作1
[ELSEIF 表达式2 THEN 操作2]……
[ELSE 操作N]
END IF
3.2 分支结构之 CASE
#情况一:类似于switch
CASE 表达式
WHEN 值1 THEN 结果1或语句1(如果是语句,需要加分号)
WHEN 值2 THEN 结果2或语句2(如果是语句,需要加分号)
...
ELSE 结果n或语句n(如果是语句,需要加分号)
END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
#情况二:类似于多重if
CASE
WHEN 条件1 THEN 结果1或语句1(如果是语句,需要加分号)
WHEN 条件2 THEN 结果2或语句2(如果是语句,需要加分号)
...
ELSE 结果n或语句n(如果是语句,需要加分号)
END [case](如果是放在begin end中需要加上case,如果放在select后面不需要)
3.3 循环结构之LOOP
[loop_label:] LOOP
循环执行的语句
END LOOP [loop_label]
3.4 循环结构之WHILE
[while_label:] WHILE 循环条件 DO
循环体
END WHILE [while_label];
3.5 循环结构之REPEAT
[repeat_label:] REPEAT
循环体的语句
UNTIL 结束循环的条件表达式
END REPEAT [repeat_label]
3.6 跳转语句之LEAVE语句
LEAVE 标记名
3.7 跳转语句之ITERATE语句
ITERATE label
4. 游标
4.1 什么是游标(或光标)
4.2 使用游标步骤
DECLARE cursor_name CURSOR FOR select_statement;
OPEN cursor_name
FETCH cursor_name INTO var_name [, var_name] ...
CLOSE cursor_name
4.3 小结
逐条读取结果集中的数据,提供了完美的解决方案。跟在应用层面实现相同的功能相比,游标可以在存储程序中使用,效率高,程序也更加简洁。加锁,这样在业务并发量大的时候,不仅会影响业务之间的效率,还会消耗系统资源,造成内存不足,这是因为游标是在内存中进行的处理。补充:MySQL 8.0的新特性—全局变量的持久化
临时生效。数据库重启后,服务器又会从MySQL配置文件中读取变量的默认值。 MySQL 8.0版本新增了SET PERSIST命令。SET PERSIST global max_connections = 1000;
第17章 触发器
1. 触发器概述
5.0.2版本开始支持触发器。MySQL的触发器和存储过程一样,都是嵌入到MySQL服务器的一段程序。事件来触发某个操作,这些事件包括INSERT、UPDATE、DELETE事件。所谓事件就是指用户的动作或者触发某项行为。如果定义了触发程序,当数据库执行这些语句时候,就相当于事件发生了,就会自动激发触发器执行相应的操作。2. 触发器的创建
2.1 创建触发器语法
CREATE TRIGGER 触发器名称
{BEFORE|AFTER} {INSERT|UPDATE|DELETE} ON 表名
FOR EACH ROW
触发器执行的语句块;
表名:表示触发器监控的对象。BEFORE|AFTER:表示触发的时间。BEFORE 表示在事件之前触发;AFTER 表示在事件之后触发。INSERT|UPDATE|DELETE:表示触发的事件。
DELIMITER //
CREATE TRIGGER before_insert
BEFORE INSERT ON test_trigger
FOR EACH ROW
BEGIN
INSERT INTO test_trigger_log (t_log)
VALUES('before_insert');
END //
DELIMITER ;
3. 查看、删除触发器
3.1 查看触发器
SHOW TRIGGERS\G
SHOW CREATE TRIGGER 触发器名
SELECT * FROM information_schema.TRIGGERS;
3.2 删除触发器
DROP TRIGGER IF EXISTS 触发器名称;
4. 触发器的优缺点
4.1 优点
4.2 缺点
4.3 注意点
第18章 MySQL8其它新特性
1. 新特性1:窗口函数
1.1 窗口函数分类
静态窗口函数和动态窗口函数。
函数分类
函数
函数说明
序号函数
ROW_NUMBER()
顺序排序
RANK()
并列排序,会跳过重复的序号,比如序号为1、1、3
DENSE_RANK()
并列排序,不会跳过重复的序号,比如序号为1、1、2
分布函数
PERCENT_RANK()
等级值百分比
CUME_DIST()
累积分布值
前后函数
LAG(expr, n)
返回当前行的前n行的expr的值
LEAD(expr, n)
返回当前行的后n行的expr的值
首尾函数
FIRST_VALUE(expr)
返回第一个expr的值
LAST_VALUE(expr)
返回最后一个expr的值
其他函数
NTH_VALUE(expr, n)
返回第n个expr的值
NTILE(n)
将分区中的有序数据分为n个桶,记录桶编号
1.2 语法结构
函数 OVER([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
函数 OVER 窗口名 … WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num, id, category_id, category, NAME, price, stock
FROM goods;
1.3 小 结
2. 新特性2:公用表表达式
普通公用表表达式和递归公用表表达式2 种。2.1 普通公用表表达式
WITH CTE名称
AS (子查询)
SELECT|DELETE|UPDATE 语句;
WITH emp_dept_id
AS (SELECT DISTINCT department_id FROM employees)
SELECT *
FROM departments d JOIN emp_dept_id e
ON d.department_id = e.department_id;
2.2 递归公用表表达式
WITH RECURSIVE
CTE名称 AS (子查询)
SELECT|DELETE|UPDATE 语句;
WITH RECURSIVE cte
AS(SELECT employee_id,last_name,manager_id,1 AS n FROM employees WHERE employee_id = 100
-- 种子查询,找到第一代领导
UNION ALL
SELECT a.employee_id,a.last_name,a.manager_id,n+1 FROM employees AS a JOIN cte
ON (a.manager_id = cte.employee_id) -- 递归查询,找出以递归公用表表达式的人为领导的人
)
SELECT employee_id,last_name FROM cte WHERE n >= 3;
2.3 小 结
第二部分 MySQL高级特性篇
第01章 Linux下MySQL的安装与使用
1. 安装前说明
1.1 查看是否安装过MySQL
rpm -qa | grep -i mysql # -i 忽略大小写
systemctl status mysqld.service
1.2 MySQL的卸载
systemctl stop mysqld.service
rpm -qa | grep -i mysql
# 或
yum list installed | grep mysql
yum remove mysql-xxx mysql-xxx mysql-xxx mysqk-xxxx
rpm -qa | grep -i mysql确认是否有卸载残留
find / -name mysql
rm -rf xxx
rm -rf /etc/my.cnf
2. MySQL的Linux版安装
2.1 CentOS7下检查MySQL依赖
chmod -R 777 /tmp
rpm -qa|grep libaio
rpm -qa|grep net-tools
2.2 CentOS7下MySQL安装过程
rpm -ivh mysql-community-common-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-plugins-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-8.0.25-1.el7.x86_64.rpm
rpm是Redhat Package Manage缩写,通过RPM的管理,用户可以把源代码包装成以rpm为扩展名的文件形式,易于安装。-i, --install 安装软件包-v, --verbose 提供更多的详细信息输出-h, --hash 软件包安装的时候列出哈希标记 (和 -v 一起使用效果更好),展示进度条
2.3 查看MySQL版本
mysql --version
#或
mysqladmin --version
2.4 服务的初始化
mysqld --initialize --user=mysql
该密码标记为过期,登录后你需要设置一个新的密码。生成的临时密码会往日志中记录一份。cat /var/log/mysqld.log
2.5 启动MySQL,查看状态
#加不加.service后缀都可以
启动:systemctl start mysqld.service
关闭:systemctl stop mysqld.service
重启:systemctl restart mysqld.service
查看状态:systemctl status mysqld.service
2.6 查看MySQL服务是否自启动
systemctl list-unit-files|grep mysqld.service
systemctl enable mysqld.service
systemctl disable mysqld.service
3. MySQL登录
3.1 首次登录
mysql -hlocalhost -P3306 -uroot -p进行登录,在Enter password:录入初始化密码3.2 修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'new_password';
3.3 设置远程登录
保证网络畅通保证端口号开放访问
service iptables stop
#开启防火墙
systemctl start firewalld.service
#查看防火墙状态
systemctl status firewalld.service
#关闭防火墙
systemctl stop firewalld.service
#设置开机启用防火墙
systemctl enable firewalld.service
#设置开机禁用防火墙
systemctl disable firewalld.service
firewall-cmd --list-all
firewall-cmd --add-service=http --permanent
firewall-cmd --add-port=3306/tcp --permanent
firewall-cmd --reload
4. Linux下修改配置
use mysql;
select Host,User from user;
update user set host = '%' where user ='root';
flush privileges;
%是个 通配符 ,如果Host=192.168.1.%,那么就表示只要是IP地址前缀为“192.168.1.”的客户端都可以连接。如果Host=%,表示所有IP都有连接权限。ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'abc123';
5. 字符集的相关操作
5.1 各级别的字符集
show variables like 'character%';
创建或修改列时没有显式的指定字符集和比较规则,则该列默认用表的字符集和比较规则创建表时没有显式的指定字符集和比较规则,则该表默认用数据库的字符集和比较规则创建数据库时没有显式的指定字符集和比较规则,则该数据库默认用服务器的字符集和比较规则5.2 请求到响应过程中字符集的变化
第02章 MySQL的数据目录
1. MySQL8的主要目录结构
find / -name mysql
1.1 数据库文件的存放路径
show variables like 'datadir'; # /var/lib/mysql/
1.2 相关命令目录
1.3 配置文件目录
2. 数据库和文件系统的关系
2.1 表在文件系统中的表示
2.3.1 InnoDB存储引擎模式
InnoDB在数据目录下对应的数据库子目录下创建了一个专门用于描述表结构的文件表名.frm
ibdata1、大小为12M的自拓展文件,这个文件就是对应的系统表空间在文件系统上的表示。每一个表建立一个独立表空间,也就是说我们创建了多少个表,就有多少个独立表空间。使用独立表空间来存储表数据的话,会在该表所属数据库对应的子目录下创建一个表示该独立表空间的文件,文件名和表名相同。表名.ibd
表名.frm,而是合并在表名.ibd文件中。系统表空间还是独立表空间来存储数据,这个功能由启动参数innodb_file_per_table控制[server]
innodb_file_per_table=0 # 0:代表使用系统表空间; 1:代表使用独立表空间
2.3.2 MyISAM存储引擎模式
数据目录下对应的数据库子目录下创建了一个专门用于描述表结构的文件表名.frm
二级索引,该存储引擎的数据和索引是分开存放的。所以在文件系统中也是使用不同的文件来存储数据文件和索引文件,同时表数据都存放在对应的数据库子目录下。test.frm 存储表结构 #MySQL8.0 改为了 b.xxx.sdi
test.MYD 存储数据 (MYData)
test.MYI 存储索引 (MYIndex
第03章 用户与权限管理
1. 用户管理
1.1 登录MySQL服务器
mysql –h hostname|hostIP –P port –u username –p DatabaseName –e "SQL语句"
-h参数后面接主机名或者主机IP,hostname为主机,hostIP为主机IP。-P参数后面接MySQL服务的端口,通过该参数连接到指定的端口。MySQL服务的默认端口是3306,不使用该参数时自动连接到3306端口,port为连接的端口号。-u参数后面接用户名,username为用户名。-p参数会提示输入密码。DatabaseName参数指明登录到哪一个数据库中。如果没有该参数,就会直接登录到MySQL数据库中,然后可以使用USE命令来选择数据库。-e参数后面可以直接加SQL语句。登录MySQL服务器以后即可执行这个SQL语句,然后退出MySQL服务器。mysql -uroot -p -hlocalhost -P3306 mysql -e "select host,user from user"
1.2 创建用户
CREATE USER 用户名 [IDENTIFIED BY '密码'][,用户名 [IDENTIFIED BY '密码']];
CREATE USER zhang3 IDENTIFIED BY '123123'; # 默认host是 %
CREATE USER 'kangshifu'@'localhost' IDENTIFIED BY '123456';
1.3 修改用户
UPDATE mysql.user SET USER='li4' WHERE USER='wang5';
FLUSH PRIVILEGES;
1.4 删除用户
DROP USER user[,user]…;
DROP USER li4 ; # 默认删除host为%的用户
DROP USER 'kangshifu'@'localhost';
DELETE FROM mysql.user WHERE Host=’hostname’ AND User=’username’;
FLUSH PRIVILEGES;
1.5 设置当前用户密码
ALTER USER USER() IDENTIFIED BY 'new_password';
SET PASSWORD='new_password';
1.6 修改其它用户密码
ALTER USER user [IDENTIFIED BY '新密码']
[,user[IDENTIFIED BY '新密码']]…;
SET PASSWORD FOR 'username'@'hostname'='new_password';
2. 权限管理
2.1 权限列表
show privileges;
CREATE和DROP权限,可以创建新的数据库和表,或删除(移掉)已有的数据库和表。如果将MySQL数据库中的DROP权限授予某用户,用户就可以删除MySQL访问权限保存的数据库。SELECT、INSERT、UPDATE和DELETE权限允许在一个数据库现有的表上实施操作。SELECT权限只有在它们真正从一个表中检索行时才被用到。INDEX权限允许创建或删除索引,INDEX适用于已有的表。如果具有某个表的CREATE权限,就可以在CREATE TABLE语句中包括索引定义。ALTER权限可以使用ALTER TABLE来更改表的结构和重新命名表。CREATE ROUTINE权限用来创建保存的程序(函数和程序),ALTER ROUTINE权限用来更改和删除保存的程序,EXECUTE权限用来执行保存的程序。GRANT权限允许授权给其他用户,可用于数据库、表和保存的程序。FILE权限使用户可以使用LOAD DATA INFILE和SELECT … INTO OUTFILE语句读或写服务器上的文件,任何被授予FILE权限的用户都能读或写MySQL服务器上的任何文件(说明用户可以读任何数据库目录下的文件,因为服务器可以访问这些文件)。2.2 授予权限的原则
经验原则:满足需要的最小权限,防止用户干坏事。比如用户只是需要查询,那就只给select权限就可以了,不要给用户赋予update、insert或者delete权限。限制用户的登录主机,一般是限制成指定IP或者内网IP段。设置满足密码复杂度的密码。定期清理不需要的用户,回收权限或者删除用户。2.3 授予权限
GRANT 权限1,权限2,…权限n ON 数据库名称.表名称 TO 用户名@用户地址 [IDENTIFIED BY ‘密码口令’];
GRANT SELECT,INSERT,DELETE,UPDATE ON atguigudb.* TO li4@localhost;
GRANT ALL PRIVILEGES ON *.* TO joe@'%' IDENTIFIED BY '123';
2.4 查看权限
SHOW GRANTS;
# 或
SHOW GRANTS FOR CURRENT_USER;
# 或
SHOW GRANTS FOR CURRENT_USER();
SHOW GRANTS FOR 'user'@'主机地址';
2.5 收回权限
REVOKE 权限1,权限2,…权限n ON 数据库名称.表名称 FROM 用户名@用户地址;
#收回全库全表的所有权限
REVOKE ALL PRIVILEGES ON *.* FROM joe@'%';
#收回mysql库下的所有表的插删改查权限
REVOKE SELECT,INSERT,UPDATE,DELETE ON mysql.* FROM joe@localhost;
须用户重新登录后才能生效3. 角色管理
3.1 创建角色
CREATE ROLE 'role_name'[@'host_name'] [,'role_name'[@'host_name']]...
host_name省略,默认为%,role_name不可省略,不可为空。3.2 给角色赋予权限
GRANT privileges ON table_name TO 'role_name'[@'host_name'];
SHOW PRIVILEGES\G
3.3 查看角色的权限
SHOW GRANTS FOR 'role_name';
USAGE”权限,意思是连接登录数据库的权限。3.4 回收角色的权限
REVOKE privileges ON tablename FROM 'rolename';
3.5 删除角色
DROP ROLE role [,role2]...
如果你删除了角色,那么用户也就失去了通过这个角色所获得的所有权限。3.6 给用户赋予角色
激活状态才能发挥作用。GRANT role [,role2,...] TO user [,user2,...];
SELECT CURRENT_ROLE();
3.7 激活角色
SET DEFAULT ROLE ALL TO 'kangshifu'@'localhost';
SET GLOBAL activate_all_roles_on_login=ON;
所有角色永久激活。3.8 撤销用户的角色
REVOKE role FROM user;
3.9 设置强制角色(mandatory role)
[mysqld]
mandatory_roles='role1,role2@localhost,r3@%.atguigu.com'
SET PERSIST mandatory_roles = 'role1,role2@localhost,r3@%.example.com'; #系统重启后仍然有效
SET GLOBAL mandatory_roles = 'role1,role2@localhost,r3@%.example.com'; #系统重启后失效
第04章 逻辑架构
1. 逻辑架构剖析
1.1 第1层:连接层
MySQL服务器前,做的第一件事就是建立TCP连接。MySQL服务器对TCP传输过来的账号密码做身份认证、权限获取。
TCP连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后面的流程。每一个连接从线程池中获取线程,省去了创建和销毁线程的开销。1.2 第2层:服务层
语法树,并根据数据字典丰富查询语法树,会验证该客户端是否具有执行该查询的权限。创建好语法树后,MySQL还会对SQL查询进行语法上的优化,进行查询重写。
执行计划。使用哪些索引进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。选取-投影-连接”策略进行查询。例如:SELECT id,name FROM student WHERE gender = '女';
选取,而不是将表全部查询出来以后再进行gender过滤。 这个SELECT查询先根据id和name进行属性投影,而不是将属性全部取出以后再进行过滤,将这两个查询条件连接起来生成最终查询结果。
不同客户端之间共享。MySQL 8.0中删除。1.3 第3层:引擎层
1.4 小结
2. SQL执行流程
2.1 MySQL 中的 SQL执行流程
鲁棒性大大降低,只有相同的查询操作才会命中查询缓存。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。因此 MySQL 的 查询缓存命中率不高 。缓存失效的时候。MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除!对于更新压力大的数据库来说,查询缓存的命中率会非常低。词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。 MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。语法分析”。根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。如果SQL语句正确,则会生成一个语法树。全表检索,还是根据索引检索等。在查询优化器中,可以分为逻辑查询优化阶段和物理查询优化阶段。具备权限。如果没有,就会返回权限错误。如果具备权限,就执行 SQL查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
3. 数据库缓冲池(buffer pool)
InnoDB存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页面(包括读页面、写页面、创建新页面等操作)。而磁盘 I/O 需要消耗的时间很多,而在内存中进行操作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请占用内存来作为数据缓冲池,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的Buffer Pool之后才可以访问。减少与磁盘直接进行 I/O 的时间。要知道,这种策略对提升 SQL 语句的查询性能来说至关重要。如果索引的数据在缓冲池里,那么访问的成本就会降低很多。3.1 缓冲池 vs 查询缓存
位置 * 频次”这个原则,可以帮我们对 I/O 访问效率进行优化。优先对使用频次高的热数据进行加载。查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。因为命中条件苛刻,而且只要数据表发生变化,查询缓存就会失效,因此命中率低。3.2 缓冲池如何读取数据
3.3 查看/设置缓冲池的大小
show variables like 'innodb_buffer_pool_size';
set global innodb_buffer_pool_size = 268435456;
[server]
innodb_buffer_pool_size = 268435456
3.4 多个Buffer Pool实例
[server]
innodb_buffer_pool_instances = 2
show variables like 'innodb_buffer_pool_instances';
Buffer Pool实例实际占内存空间innodb_buffer_pool_size/innodb_buffer_pool_instances
第05章 存储引擎
1. 查看存储引擎
show engines;
# 或
show engines\G
2. 设置系统默认的存储引擎
show variables like '%storage_engine%';
#或
SELECT @@default_storage_engine;
InnoDB作为表的存储引擎。SET DEFAULT_STORAGE_ENGINE=MyISAM;
my.cnf文件:default-storage-engine=MyISAM
# 重启服务
systemctl restart mysqld.service
3. 设置表的存储引擎
不同的表设置不同的存储引擎,也就是说不同的表可以有不同的物理存储结构,不同的提取和写入方式。3.1 创建表时指定存储引擎
CREATE TABLE 表名(
建表语句;
) ENGINE = 存储引擎名称;
3.2 修改表的存储引擎
ALTER TABLE 表名 ENGINE = 存储引擎名称;
4. 引擎介绍
4.1 InnoDB 引擎:具备外键支持功能的事务存储引擎
大于等于5.5之后,默认采用InnoDB引擎。默认事务型引擎,它被设计用来处理大量的短期(short-lived)事务。可以确保事务的完整提交(Commit)和回滚(Rollback)。
为处理巨大数据量的最大性能设计。
.frm,.par,.trn,.isl,.db.opt等都在MySQL8.0中不存在了。InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保存数据和索引。对内存要求较高,而且内存大小对性能有决定性的影响。4.2 MyISAM 引擎:主要的非事务处理存储引擎
不支持事务、行级锁、外键,有一个毫无疑问的缺陷就是崩溃后无法安全恢复。5.5之前默认的存储引擎速度快,对事务完整性没有要求或者以SELECT、INSERT为主的应用
4.3 Archive 引擎:用于数据存档
4.4 Blackhole 引擎:丢弃写操作,读操作会返回空内容
4.5 CSV 引擎:存储数据时,以逗号分隔各个数据项
4.6 Memory 引擎:置于内存的表
4.7 Federated 引擎:访问远程表
4.8 Merge引擎:管理多个MyISAM表构成的表集合
4.9 NDB引擎:MySQL集群专用存储引擎
5. MyISAM和InnoDB
对比项
MyISAM
InnoDB
外键
不支持
支持
事务
不支持
支持
行表锁
表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作
行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作
缓存
只缓存索引,不缓存真实数据
不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响
自带系统表使用
Y
N
关注点
性能:节省资源、消耗少、简单业务
事务:并发写、事务、更大资源
默认安装
Y
Y
默认使用
N
Y
第06章 索引的数据结构
1. 索引及其优缺点
1.1 索引概述
高级查找算法。1.2 优点
数据库的IO成本,这也是创建索引最主要的原因。数据的唯一性。加速表和表之间的连接。换句话说,对于有依赖关系的子表和父表联合查询时,可以提高查询速度。减少查询中分组和排序的时间,降低了CPU的消耗。1.3 缺点
耗费时间,并且随着数据量的增加,所耗费的时间也会增加。磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间存储在磁盘上,如果有大量的索引,索引文件就可能比数据文件更快达到最大文件尺寸。降低更新表的速度。当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。2. InnoDB中索引的推演
2.1 索引之前的查找
SELECT [列名列表] FROM 表名 WHERE 列名 = xxx;
二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
从第一个页沿着双向链表一直往下找,在每一个页中根据我们上面的查找方式去查找指定的记录。因为要遍历所有的数据页,所以这种方式显然是超级耗时的。2.2 设计索引
mysql> CREATE TABLE index_demo(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;
index_demo表中有2个INT类型的列,1个CHAR(1)类型的列,而且我们规定了c1列为主键,这个表使用Compact行格式来实际存储记录的。这里我们简化了index_demo表的行格式示意图:
record_type:记录头信息的一项属性,表示记录的类型,0表示普通记录、1表示目录项记录、2表示最小记录、3表示最大记录。next_record:记录头信息的一项属性,表示下一条地址相对于本条记录的地址偏移量,我们用箭头来表明下一条记录是谁。各个列的值:这里只记录在index_demo表中的三个列,分别是c1、c2和c3。其他信息:除了上述3种信息以外的所有信息,包括其他隐藏列的值以及记录的额外信息。想快速的定位到需要查找的记录在哪些数据页中该咋办?我们可以为快速定位记录所在的数据页而建立一个目录,建这个目录必须完成下边这些事:

页28为例,它对应目录项2,这个目录项中包含着该页的页号28以及该页中用户记录的最小主键值5。我们只需要把几个目录项在物理存储器上连续存储(比如:数组),就可以实现根据主键值快速查找某条记录的功能了。比如:查找主键值为20的记录,具体查找过程分两步:
二分法快速确定出主键值为20的记录在目录项3中(因为 12 < 20 < 209 ),它对应的页是页9。页9中定位具体的记录。索引。目录项记录和普通的用户记录的不同点:
目录项记录的record_type值是1,而普通用户记录的record_type值是0。主键值和页的编号两个列,而普通的用户记录的列是用户自己定义的,可能包含很多列,另外还有InnoDB自己添加的隐藏列。min_rec_mask的属性,只有在存储目录项记录的页中的主键值最小的目录项记录的min_rec_mask值为1,其他别的记录的min_rec_mask值都是0。Page Directory(页目录),从而在按照主键值进行查找时可以使用二分法来加快查询速度。20的记录为例,根据某个主键值去查找记录的步骤就可以大致拆分成下边两步:
目录项记录的页,也就是页30中通过二分法快速定位到对应目录项,因为 12 < 20 < 209 ,所以定位到对应的记录所在的页就是页9。二分法快速定位到主键值为20的用户记录。
页31。页30的容量已满(我们前边假设只能存储4条目录项记录),所以不得不需要一个新的页32来存放页31对应的目录项。20的记录为例:
目录项记录页我们现在的存储目录项记录的页有两个,即页30和页32,又因为页30表示的目录项的主键值的范围是 [1, 320) ,页32表示的目录项的主键值不小于 320 ,所以主键值为20的记录对应的目录项记录在页30中。确定用户记录真实所在的页。在一个存储目录项记录的页中通过主键值定位一条目录项记录的方式说过了。页33,这个页中的两条记录分别代表页30和页32,如果用户记录的主键值在[1, 320)之间,则到页30中查找更详细的目录项记录,如果主键值不小于320的话,就到页32中查找更详细的目录项记录。B+树。0层,之后依次往上加。之前我们做了一个非常极端的假设:存放用户记录的页最多存放3条记录,存放目录项记录的页最多存放4条记录。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录的叶子节点代表的数据页可以存放100条用户记录,所有存放目录项记录的内节点代表的数据页可以存放1000条目录项记录,那么:
100条记录。1000×100=10,0000条记录。1000×1000×100=1,0000,0000条记录。1000×1000×1000×100=1000,0000,0000条记录。相当多的记录!!!100000000000条记录吗?所以一般情况下,我们用到的B+树都不会超过4层,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的Page Directory(页目录),所以在页面内也可以通过二分法实现快速定位记录。2.3 常见索引概念
页内的记录是按照主键的大小顺序排成一个单向链表。用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。叶子节点存储的是完整的用户记录。
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快排序查找和范围查找速度非常快节省了大量的io操作。
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增ID列为主键更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据聚簇索引中再查一遍,这个过程称为回表。也就是根据c2列的值查询一条完整的用户记录需要使用到2棵B+树!c2和c3列的大小进行排序,这个包含两层含义:
联合索引,本质上也是一个二级索引。它的意思与分别为c2和c3列分别建立索引的表述是不同的,不同点如下:
联合索引只会建立如上图一样的1棵B+树。2.4 InnoDB的B+树索引的注意事项
根节点页面。最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录。根节点中。空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值(也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页。InnoDB存储引擎需要用到这个索引的时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引。索引列+页号的搭配,但是这个搭配对于二级索引来说有点不严谨。还拿index_demo表为例,假设这个表中的数据是这样的:
c1
c2
c3
1
1
‘u’
3
1
‘d’
5
1
‘y’
7
1
‘a’
索引号+页号的搭配的话,那么为c2列建立索引后的B+树应该长这样:c1、c2、c3的值分别是:9、1、c,那么在修改这个为c2列建立的二级索引对应的B+树时便碰到了个大问题:由于页3中存储的目录项记录是由c2列+页号的值构成的,页3中的两条目录项记录对应的c2列的值都是1,那么我们这条新插入的记录到底应该放在页4中,还是应该放在页5中啊?答案是:对不起,懵了。
(9, 1, 'c')时,由于页3中存储的目录项记录是由c2列+主键+页号的值构成的,可以先把新记录的c2列的值和页3中各目录项记录的c2列的值作比较,如果c2列的值相同的话,可以接着比较主键值,因为B+树同一层中不同目录项记录的c2列+主键的值肯定是不一样的,所以最后肯定能定位唯一的一条目录项记录,在本例中最后确定新记录应该被插入到页5中。InnoDB的一个数据页至少可以存放两条记录3. MyISAM中的索引方案
索引/存储引擎
MyISAM
InnoDB
Memory
B-Tree索引
支持
支持
支持
B+Tree作为索引结构,叶子节点的data域存放的是数据记录的地址。3.1 MyISAM索引的原理
3.2 MyISAM 与 InnoDB对比
聚簇索引进行一次查找就能找到对应的记录,而在MyISAM中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全部都是二级索引。分离的,索引文件仅保存数据记录的地址。主键的值,而MyISAM索引记录的是地址。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域。快速的,因为是拿着地址偏移量直接到文件中取数据的,反观InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然说也不慢,但还是比不上直接用地址去访问。必须有主键(MyISAM可以没有)。如果没有显式指定,则MySQL系统会自动选择一个可以非空且唯一标识数据记录的列作为主键。如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。4. 索引的代价
16KB的存储空间,一棵很大的B+树由许多数据页组成,那就是很大的一片存储空间。
增、删、改操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每层节点都是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是内节点中的记录(也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收等操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,会给性能拖后腿。5. MySQL数据结构选择的合理性
5.1 二叉搜索树
减少磁盘IO数。为了减少磁盘IO的次数,就需要尽量降低树的高度,需要把原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。5.2 AVL树

M 叉树(M>2)呢?当 M=3 时,同样的 31 个节点可以由下面的三叉树来进行存储:
5.3 B-Tree

查找的关键字是 9,那么步骤可以分为以下几步:
B 树相比于平衡二叉树来说磁盘 I/O 操作要少,在数据查询中比平衡二叉树效率要高。所以只要树的高度足够低,IO次数足够少,就可以提高查询性能。5.4 B+Tree
非叶子节点既保存索引,也保存数据记录。
B+Tree的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作
不能进行范围查询,而B+树可以。这是因为Hash索引指向的数据是无序的,而B+树的叶子节点是个有序的链表。不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),而B+树可以。对于联合索引来说,Hash索引在计算Hash值的时候是将索引键合并后再一起计算Hash值,所以不会针对每个索引单独计算Hash值。因此如果用到联合索引的一个或者几个索引时,联合索引无法被利用。不支持 ORDER BY 排序,因为Hash索引指向的数据是无序的,因此无法起到排序优化的作用,而B+树索引数据是有序的,可以起到对该字段ORDER BY 排序优化的作用。同理,我们也无法用Hash索引进行模糊查询,而B+树使用LIKE进行模糊查询的时候,LIKE后面后模糊查询(比如%结尾)的话就可以起到优化作用。InnoDB不支持哈希索引第07章 InnoDB数据存储结构
1. 数据库的存储结构:页
存储引擎负责对表中数据的读取和写入工作。不同存储引擎中存放的格式一般不同的,甚至有的存储引擎比如Memory都不用磁盘来存储数据。InnoDB是MySQL的默认存储引擎,所以本章剖析InooDB存储引擎的数据存储结构。1.1 磁盘与内存交互基本单位:页
16KB。页作为磁盘和内存之间交互的基本单位,也就是一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。也就是说,**在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页(Page),数据库I/O操作的最小单位是页。**一个页中可以存储多个行记录。
1.2 页结构概述
不在物理结构上相连,只要通过双向链表相关联即可。每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里边的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应的分组中的记录即可快速找到指定的记录。1.3 页的上层结构
64个连续的页。因为InnoDB中的页大小默认是16KB,所以一个区的大小是64*16KB=1MB。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。系统表空间、用户表空间、撤销表空间、临时表空间等。2. 页的内部结构
2.1 第1部分:文件头部和文件尾部
2.1.1 File Header(文件头部)(38字节)
描述各种页的通用信息。(比如页的编号、其上一页、下一页是谁等)
名称
占用空间大小
描述
FIL_PAGE_SPACE_OR_CHKSUM4字节页的校验和(checksum值)
FIL_PAGE_OFFSET4字节页号
FIL_PAGE_PREV4字节上一个页的页号
FIL_PAGE_NEXT4字节下一个页的页号
FIL_PAGE_LSN
8字节页面被最后修改时对应的日志序列位置
FIL_PAGE_TYPE2字节该页的类型
FIL_PAGE_FILE_FLUSH_LSN
8字节仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID4字节页属于哪个表空间
FIL_PAGE_OFFSET(4字节):每一个页都有一个单独的页号,就跟你的身份证号码一样,InnoDB通过页号可以唯一定位一个页。FIL_PAGE_TYPE(2字节):这个代表当前页的类型。
类型名称
十六进制
描述
FIL_PAGE_TYPE_ALLOCATED
0x0000
最新分配,还没有使用
FIL_PAGE_UNDO_LOG0x0002
Undo日志页
FIL_PAGE_INODE
0x0003
段信息节点
FIL_PAGE_IBUF_FREE_LIST
0x0004
Insert Buffer空闲列表
FIL_PAGE_IBUF_BITMAP
0x0005
Insert Buffer位图
FIL_PAGE_TYPE_SYS0x0006
系统页
FIL_PAGE_TYPE_TRX_SYS
0x0007
事务系统数据
FIL_PAGE_TYPE_FSP_HDR
0x0008
表空间头部信息
FIL_PAGE_TYPE_XDES
0x0009
扩展描述页
FIL_PAGE_TYPE_BLOB
0x000A
溢出页
FIL_PAGE_INDEX0x45BF
索引页,也就是我们所说的
数据页
FIL_PAGE_PREV(4字节)和FIL_PAGE_NEXT(4字节):InnoDB都是以页为单位存放数据的,如果数据分散到多个不连续的页中存储的话需要把这些页关联起来,FIL_PAGE_PREV和FIL_PAGE_NEXT就分别代表本页的上一个和下一个页的页号。这样通过建立一个双向链表把许许多多的页就都串联起来了,保证这些页之间不需要是物理上的连续,而是逻辑上的连续。FIL_PAGE_SPACE_OR_CHKSUM(4字节):代表当前页面的校验和(checksum)。文件头部和文件尾部都有属性:FIL_PAGE_SPACE_OR_CHKSUM在修改后的某个时间需要把数据同步到磁盘中。但是在同步了一半的时候断电了,造成了该页传输的不完整。
FIL_PAGE_LSN(8字节):页面被最后修改时对应的日志序列位置(英文名是:Log Sequence Number)2.1.2 File Trailer(文件尾部)(8字节)
2.2 第2部分:空闲空间、用户记录和最小最大记录
2.2.1 Free Space (空闲空间)
行格式存储到User Records部分。但是在一开始生成页的时候,其实并没有User Records这个部分,每当我们插入一条记录,都会从Free Space部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到User Records部分,当Free Space部分的空间全部被User Records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。2.2.2 User Records (用户记录)
指定的行格式一条一条摆在User Records部分,相互之间形成单链表。2.2.3 Infimum + Supremum(最小最大记录)
是的,记录可以比大小,对于一条完整的记录来说,比较记录的大小就是比较主键的大小。比方说我们插入的4行记录的主键值分别是:1、2、3、4,这也就意味着这4条记录是从小到大依次递增。不是我们自己定义的记录,所以它们并不存放在页的User Records部分,他们被单独放在一个称为Infimum + Supremum的部分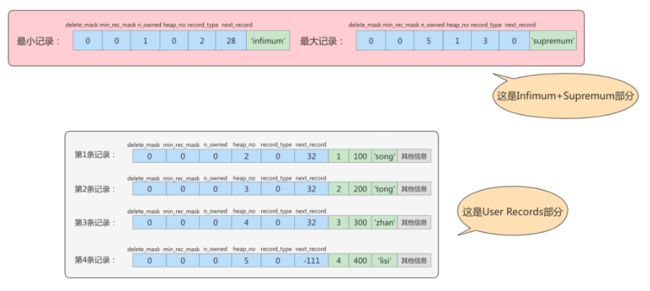
2.3 第3部分:页目录和页面头部
2.3.1 Page Directory(页目录)
在页中,记录是以单向链表的形式进行存储的。单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。因此在页结构中专门设计了页目录这个模块,专门给记录做一个目录,通过二分查找法的方式进行检索,提升效率。
分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录。
最后一组,就是最大记录所在的分组,会有 1-8 条记录;
其余的组记录数量在 4-8 条之间。
这样做的好处是,除了第 1 组(最小记录所在组)以外,其余组的记录数会尽量平分。页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
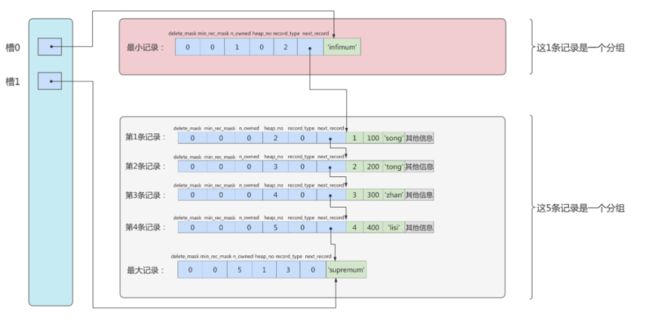
2.3.2 Page Header(页面头部)
名称
占用空间大小
描述
PAGE_N_DIR_SLOTS
2字节
在页目录中的槽数量
PAGE_HEAP_TOP
2字节
还未使用的空间最小地址,也就是说从该地址之后就是
Free Space
PAGE_N_HEAP
2字节
本页中的记录的数量(包括最小和最大记录以及标记为删除的记录)
PAGE_FREE
2字节
第一个已经标记为删除的记录的记录地址(各个已删除的记录通过
next_record也会组成一个单链表,这个单链表中的记录可以被重新利用)
PAGE_GARBAGE
2字节
已删除记录占用的字节数
PAGE_LAST_INSERT
2字节
最后插入记录的位置
PAGE_DIRECTION
2字节
记录插入的方向
PAGE_N_DIRECTION
2字节
一个方向连续插入的记录数量
PAGE_N_RECS
2字节
该页中记录的数量(不包括最小和最大记录以及被标记为删除的记录)
PAGE_MAX_TRX_ID
8字节
修改当前页的最大事务ID,该值仅在二级索引中定义
PAGE_LEVEL
2字节
当前页在B+树中所处的层级
PAGE_INDEX_ID
8字节
索引ID,表示当前页属于哪个索引
PAGE_BTR_SEG_LEAF
10字节
B+树叶子段的头部信息,仅在B+树的Root页定义
PAGE_BTR_SEG_TOP
10字节
B+树非叶子段的头部信息,仅在B+树的Root页定义
3. InnoDB行格式(或记录格式)
3.1 指定行格式的语法
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称
ALTER TABLE 表名 ROW_FORMAT=行格式名称
3.2 COMPACT行格式
3.2.1 变长字段长度列表
变长字段,变长字段中存储多少字节的数据不是固定的,所以我们在存储真实数据的时候需要顺便把这些数据占用的字节数也存起来。在Compact行格式中,把所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表。
3.2.2 NULL值列表
为什么定义NULL值列表?
之所以要存储NULL是因为数据都是需要对齐的,如果没有标注出来NULL值的位置,就有可能在查询数据的时候出现混乱。如果使用一个特定的符号放到相应的数据位表示空置的话,虽然能达到效果,但是这样很浪费空间,所以直接就在行数据得头部开辟出一块空间专门用来记录该行数据哪些是非空数据,哪些是空数据,格式如下:
3.2.3 记录头信息(5字节)
名称
大小(单位:bit)
描述
预留位11
没有使用
预留位21
没有使用
delete_mask1
标记该记录是否被删除
mini_rec_mask1
B+树的每层非叶子节点中的最小记录都会添加该标记
n_owned4
表示当前记录拥有的记录数
heap_no13
表示当前记录在记录堆的位置信息
record_type3
表示当前记录的类型,
0表示普通记录,1表示B+树非叶子节点记录,2表示最小记录,3表示最大记录
next_record16
表示下一条记录的相对位置
delete_mask:这个属性标记着当前记录是否被删除,占用1个二进制位。
你以为它删除了,可它还在真实的磁盘上。这些被删除的记录之所以不立即从磁盘上移除,是因为移除它们之后其他的记录在磁盘上需要重新排列,导致性能消耗。所以只是打一个删除标记而已,所有被删除掉的记录都会组成一个所谓的垃圾链表,在这个链表中的记录占用的空间称之为可重用空间,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉。
min_rec_mask:B+树的每层非叶子节点中的最小记录都会添加该标记,min_rec_mask值为1。我们自己插入的四条记录的min_rec_mask值都是0,意味着它们都不是B+树的非叶子节点中的最小记录。record_type:这个属性表示当前记录的类型,一共有4种类型的记录:
heap_no:这个属性表示当前记录在本页中的位置。
MySQL会自动给每个页里加了两个记录,由于这两个记录并不是我们自己插入的,所以有时候也称为伪记录或者虚拟记录。这两个伪记录一个代表最小记录,一个代表最大记录。最小记录和最大记录的heap_no值分别是0和1,也就是说它们的位置最靠前
n_owned:页目录中每个组中最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段next_record:记录头信息里该属性非常重要,它表示从当前记录的真实数据到下一条记录的真实数据的地址偏移量。3.2.4 记录的真实数据
列名
是否必须
占用空间
描述
row_id
否
6字节
行ID,唯一标识一条记录
transaction_id
是
6字节
事务ID
roll_pointer
是
7字节
回滚指针
3.3 Dynamic和Compressed行格式
行溢出分页存储,然后记录的真实数据处用20个字节存储指向这些页的地址(当然这20个字节中还包括这些分散在其他页面中的数据的占用的字节数),从而可以找到剩余数据所在的页。这称为页的扩展。
4. 区、段和碎片区
4.1 为什么要有区?
B+树的每一层中的页都会形成一个双向链表,如果是以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物理位置可能离得非常远。我们介绍B+树索引的使用场景的时候特别提到范围查询只需要定位到最左边的记录和最右边的记录,然后沿着双向链表一直扫描就可以了,而如果链表中相邻的两个页物理位置离得非常远,就是所谓的随机I/O。再一次强调,磁盘的速度和内存的速度差了好几个数量级,随机I/O是非常慢的,所以我们应该尽量让链表中相邻的页的物理位置也相邻,这样进行范围查询的时候才可以使用所谓的顺序I/O。区的概念,一个区就是物理位置上连续的64个页。因为InnoDB中的页的大小默认是16KB,所以一个区的大小是64*16KB=1MB。在表中数据量大的时候,为某个索引分配空间的时候就不再按照页的单位分配了,而是按照区为单位分配,甚至在表中的数据特别多的时候,可以一次性分配多个连续的区。虽然可能造成一点点空间的浪费(数据不足以填充满整个区),但是从性能角度看,可以消除很多的随机I/O,功大于过!4.2 为什么要有段?
叶子节点和非叶子节点进行了区别对待,也就是说叶子节点有自己独有的区,非叶子节点也有自己独有的区。存放叶子节点的区的集合就算是一个段(segment),存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。数据段、索引段、回滚段。数据段即为B+树的叶子节点,索引段即为B+树的非叶子节点。4.3 为什么要有碎片区?
纯粹的,也就是一个区被整个分配给某一个段,或者说区中的所有页面都是为了存储同一个段的数据而存在的,即使段的数据填不满区中所有的页面,那余下的页面也不能挪作他用。数据量较小的表太浪费存储空间的这种情况,InnoDB提出了一个碎片(fragment)区的概念。在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在的,而是碎片区中的页可以用于不同的目的,比如有些页面用于段A,有些页面用于段B,有些页甚至哪个段都不属于。碎片区直属于表空间,并不属于任何一个段。
32个碎片区页面之后,就会申请以完整的区为单位来分配存储空间。某些零散的页面已经一些完整的区的集合。4.4 区的分类
空闲的区(FREE):现在还没有用到这个区中的任何页面。有剩余空间的碎片区(FREE_FRAG):表示碎片区中还有可用的页面。没有剩余空间的碎片区(FULL_FRAG):表示碎片区中的所有页面都被使用,没有空闲页面。附属于某个段的区(FSEG):每一索引都可以分为叶子节点段和非叶子节点段FREE、FREE_FRAG以及FULL_FRAG这三种状态的区都是独立的,直属于表空间。而处于FSEG状态的区是附属于某个段的。第08章 索引的创建与设计原则
1. 索引的声明与使用
1.1 索引的分类
功能逻辑上说,索引主要有 4 种,分别是普通索引、唯一索引、主键索引、全文索引。物理实现方式,索引可以分为 2 种:聚簇索引和非聚簇索引。作用字段个数进行划分,分成单列索引和联合索引。1.2 创建索引
CREATE TABLE table_name [col_name data_type]
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC | DESC]
UNIQUE、FULLTEXT和SPATIAL为可选参数,分别表示唯一索引、全文索引和空间索引;INDEX与KEY为同义词,两者的作用相同,用来指定创建索引;index_name指定索引的名称,为可选参数,如果不指定,那么MySQL默认col_name为索引名;col_name为需要创建索引的字段列,该列必须从数据表中定义的多个列中选择;length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;ASC或DESC指定升序或者降序的索引值存储。CREATE TABLE book(
book_id INT ,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100) ,
comment VARCHAR(100),
year_publication YEAR,
INDEX(year_publication)
);
CREATE TABLE test1(
id INT NOT NULL,
name varchar(30) NOT NULL,
UNIQUE INDEX uk_idx_id(id)
);
CREATE TABLE student (
id INT(10) UNSIGNED AUTO_INCREMENT,
student_no VARCHAR(200),
student_name VARCHAR(200),
PRIMARY KEY(id)
);
# 删除主键索引
ALTER TABLE student drop PRIMARY KEY ;
CREATE TABLE test2(
id INT NOT NULL,
name CHAR(50) NULL,
INDEX single_idx_name(name(20))
);
CREATE TABLE test3(
id INT(11) NOT NULL,
name CHAR(30) NOT NULL,
age INT(11) NOT NULL,
info VARCHAR(255),
INDEX multi_idx(id,name,age)
);
CREATE TABLE `papers` (
id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`content` text, PRIMARY KEY (`id`),
FULLTEXT KEY `title` (`title`,`content`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
SELECT * FROM papers WHERE MATCH(title,content) AGAINST (‘查询字符串’);
CREATE TABLE test5(
geo GEOMETRY NOT NULL,
SPATIAL INDEX spa_idx_geo(geo)
) ENGINE=MyISAM;
ALTER TABLE table_name
ADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name[length],...) [ASC | DESC]
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
ON table_name (col_name[length],...) [ASC | DESC]
1.3 删除索引
ALTER TABLE table_name DROP INDEX index_name;
DROP INDEX index_name ON table_name;
2. MySQL8.0索引新特性
2.1 支持降序索引
CREATE TABLE ts1(a int,b int,index idx_a_b(a,b desc));
2.2 隐藏索引
隐藏索引(invisible indexes),只需要将待删除的索引设置为隐藏索引,使查询优化器不再使用这个索引(即使使用force index(强制使用索引),优化器也不会使用该索引),确认将索引设置为隐藏索引后系统不受任何响应,就可以彻底删除索引。这种通过先将索引设置为隐藏索引,再删除索引的方式就是软删除。CREATE TABLE tablename(
propname1 type1[CONSTRAINT1],
propname2 type2[CONSTRAINT2],
……
propnamen typen,
INDEX [indexname](propname1 [(length)]) INVISIBLE
);
CREATE INDEX indexname
ON tablename(propname[(length)]) INVISIBLE;
ALTER TABLE tablename
ADD INDEX indexname (propname [(length)]) INVISIBLE;
ALTER TABLE tablename ALTER INDEX index_name INVISIBLE; #切换成隐藏索引
ALTER TABLE tablename ALTER INDEX index_name VISIBLE; #切换成非隐藏索引
3. 索引的设计原则
3.1 哪些情况适合创建索引
某个字段是唯一的,就可以直接创建唯一性索引,或者主键索引。这样可以更快速地通过该索引来确定某条记录。
对分组或者排序的字段进行索引。如果待排序的列有多个,那么可以在这些列上建立组合索引。连接表的数量尽量不要超过 3 张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长会非常快,严重影响查询的效率。对 WHERE 条件创建索引,因为 WHERE 才是对数据条件的过滤。如果在数据量非常大的情况下,没有 WHERE 条件过滤是非常可怕的。对用于连接的字段创建索引,并且该字段在多张表中的类型必须一致。类型大小指的就是该类型表示的数据范围的大小。
放下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。主键来说更加适用,因为不仅是聚簇索引中会存储主键值,其他所有的二级索引的节点处都会存储一份记录的主键值,如果主键使用更小的数据类型,也就意味着节省更多的存储空间和更高效的I/O。count(distinct left(列名, 索引长度))/count(*)
强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。高达 90% 以上。列的基数指的是某一列中不重复数据的个数,比方说某个列包含值2,5,8,2,5,8,2,5,8,虽然有9条记录,但该列的基数却是3。也就是说,**在记录行数一定的情况下,列的基数越大,该列中的值越分散;列的基数越小,该列中的值越集中。**这个列的基数指标非常重要,直接影响我们是否能有效的利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果可能不好。select count(distinct a)/count(*) from t1计算区分度,越接近1越好,一般超过33%就算是比较高效的索引了。3.2 限制索引的数目
不超过6个。原因:
磁盘空间,索引越多,需要的磁盘空间就越大。INSERT、DELETE、UPDATE等语句的性能,因为表中的数据更改的同时,索引也会进行调整和更新,会造成负担。索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,会增加MySQL优化器生成执行计划时间,降低查询性能。3.3 哪些情况不适合创建索引
第09章 性能分析工具的使用
1. 统计SQL的查询成本:last_query_cost
SHOW STATUS LIKE 'last_query_cost';
位置决定效率。如果页就在数据库缓冲池中,那么效率是最高的,否则还需要从内存或者磁盘中进行读取,当然针对单个页的读取来说,如果页存在于内存中,会比在磁盘中读取效率高很多。批量决定效率。如果我们从磁盘中对单一页进行随机读,那么效率是很低的(差不多10ms),而采用顺序读取的方式,批量对页进行读取,平均一页的读取效率就会提升很多,甚至要快于单个页面在内存中的随机读取。缓冲池中,其次我们可以充分利用磁盘的吞吐能力,一次性批量读取数据,这样单个页的读取效率也就得到了提升。2. 定位执行慢的SQL:慢查询日志
响应时间超过阈值的语句,具体指运行时间超过long_query_time的值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上(不含10秒)的语句,认为是超出了我们的最大忍耐时间值。没有开启慢查询日志,需要我们手动来设置这个参数。如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。2.1 开启慢查询日志参数
set global slow_query_log='ON';
show variables like `%slow_query_log%`;
show variables like '%long_query_time%';
#测试发现:设置global的方式对当前session的long_query_time失效。对新连接的客户端有效。所以可以一并 执行下述语句
mysql > set global long_query_time = 1;
mysql> show global variables like '%long_query_time%';
mysql> set long_query_time=1;
mysql> show variables like '%long_query_time%';
2.2 查看慢查询数目
SHOW GLOBAL STATUS LIKE '%Slow_queries%';
2.3 慢查询日志分析工具:mysqldumpslow
#得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log
#得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log
#得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log
#另外建议在使用这些命令时结合 | 和more 使用 ,否则有可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more
2.4 关闭慢查询日志
[mysqld]
slow_query_log=OFF
#或
[mysqld]
#slow_query_log =OFF
SET GLOBAL slow_query_log=off;
3. 查看 SQL 执行成本:SHOW PROFILE
show variables like 'profiling';
#开启
set profiling = 'ON';
#查看
show profiles;
show profile cpu,block io for query 2;
4. 分析查询语句:EXPLAIN
4.1 基本语法
EXPLAIN SELECT select_options
#或者
DESCRIBE SELECT select_options
列名
描述
id
在一个大的查询语句中每个SELECT关键字都对应一个
唯一的id
select_type
SELECT关键字对应的那个查询的类型
table
表名
partitions
匹配的分区信息
type
针对单表的访问方法
possible_keys
可能用到的索引
key
实际上使用的索引
key_len
实际使用到的索引长度
ref
当使用索引列等值查询时,与索引列进行等值匹配的对象信息
rows
预估的需要读取的记录条数
filtered
某个表经过搜索条件过滤后剩余记录条数的百分比
Extra
一些额外的信息
4.2 EXPLAIN各列作用
单表访问的,所以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
varchar(10)变长字段且允许NULL = 10 * ( character set: utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段)
varchar(10)变长字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+2(变长字段)
char(10)固定字段且允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)+1(NULL)
char(10)固定字段且不允许NULL = 10 * ( character set:utf8=3,gbk=2,latin1=1)
5. EXPLAIN的进一步使用
5.1 EXPLAIN四种输出格式
传统格式,JSON格式,TREE格式以及可视化输出。用户可以根据需要选择适用于自己的格式。FORMAT=JSON。用于查看执行成本cost_info各个部分之间的关系和各部分的执行顺序来描述如何查询。5.2 SHOW WARNINGS的使用
mysql> EXPLAIN SELECT s1.key1, s2.key1 FROM s1 LEFT JOIN s2 ON s1.key1 = s2.key1 WHERE s2.common_field IS NOT NULL;
# 查看优化后的执行语句
mysql> SHOW WARNINGS\G
6. 分析优化器执行计划:trace
# 开启
SET optimizer_trace="enabled=on",end_markers_in_json=on;
# 设置大小
set optimizer_trace_max_mem_size=1000000;
# 使用
select * from student where id < 10;
select * from information_schema.optimizer_trace\G
7. MySQL监控分析视图-sys schema
#1. 查询冗余索引
select * from sys.schema_redundant_indexes;
#2. 查询未使用过的索引
select * from sys.schema_unused_indexes;
#3. 查询索引的使用情况
select index_name,rows_selected,rows_inserted,rows_updated,rows_deleted from sys.schema_index_statistics where table_schema='dbname' ;
# 1. 查询表的访问量
select table_schema,table_name,sum(io_read_requests+io_write_requests) as io from sys.schema_table_statistics group by table_schema,table_name order by io desc;
# 2. 查询占用bufferpool较多的表
select object_schema,object_name,allocated,data
from sys.innodb_buffer_stats_by_table order by allocated limit 10;
# 3. 查看表的全表扫描情况
select * from sys.statements_with_full_table_scans where db='dbname';
#1. 监控SQL执行的频率
select db,exec_count,query from sys.statement_analysis order by exec_count desc;
#2. 监控使用了排序的SQL
select db,exec_count,first_seen,last_seen,query
from sys.statements_with_sorting limit 1;
#3. 监控使用了临时表或者磁盘临时表的SQL
select db,exec_count,tmp_tables,tmp_disk_tables,query
from sys.statement_analysis where tmp_tables>0 or tmp_disk_tables >0 order by (tmp_tables+tmp_disk_tables) desc;
#1. 查看消耗磁盘IO的文件
select file,avg_read,avg_write,avg_read+avg_write as avg_io
from sys.io_global_by_file_by_bytes order by avg_read limit 10;
#1. 行锁阻塞情况
select * from sys.innodb_lock_waits;
第10章 索引优化与查询优化
1. 索引失效案例
提高性能的一个最有效的方式是对数据表设计合理的索引。索引提供了访问高效数据的方法,并且加快查询的速度,因此索引对查询的速度有着至关重要的影响。
快速地定位表中的某条记录,从而提高数据库查询的速度,提高数据库的性能。扫描表中的所有记录。在数据量大的情况下,这样查询的速度会很慢。B+树来构建索引。只是空间列类型的索引使用R-树,并且MEMORY表还支持hash索引。cost开销(CostBaseOptimizer),它不是基于规则(Rule-BasedOptimizer),也不是基于语义。怎么样开销小就怎么来。另外,SQL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。1.1 全值匹配我最爱
1.2 最佳左前缀法则
1.3 主键插入顺序
InnoDB存储引擎的表来说,在我们没有显示的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点的。而记录又存储在数据页中的,数据页和记录又是按照记录主键值从小到大的顺序进行排序,所以如果我们插入的记录的主键值是依次增大的话,那我们每插满一个数据页就换到下一个数据页继续插,而如果我们插入的主键值忽小忽大的话,则可能会造成页面分裂和记录移位。1.4 计算、函数、类型转换(自动或手动)导致索引失效
1.5 类型转换导致索引失效
1.6 范围条件右边的列索引失效
1.7 不等于(!= 或者<>)索引失效
1.8 is null可以使用索引,is not null无法使用索引
字段设置为 NOT NULL 约束,比如你可以将INT类型的字段,默认值设置为0。将字符类型的默认值设置为空字符串(‘’)not like也无法使用索引,导致全表扫描1.9 like以通配符%开头索引失效
1.10 OR 前后存在非索引的列,索引失效
1.11 数据库和表的字符集统一使用utf8mb4
字符集进行比较前需要进行转换会造成索引失效。2. 关联查询优化
小表驱动大表2.1 Index Nested-Loop Join(索引嵌套循环连接)
减少内层表数据的匹配次数,所以要求被驱动表上必须有索引才行。
2.2 Block Nested-Loop Join(块嵌套循环连接)
join buffer缓冲区,将驱动表join相关的部分数据列(大小受join buffer的限制)缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
2.3 Hash Join
大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用Join Key在内存中建立散列值,然后扫描较大的表并探测散列值,找出与Hash表匹配的行。
若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要求有较大的临时段从而尽量提高I/O的性能。3. 子查询优化
建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。不会存在索引,所以查询性能会受到一定的影响。不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
4. 排序优化
避免全表扫描,在 ORDER BY 子句避免使用 FileSort 排序。当然,某些情况下全表扫描,或者 FileSort 排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。5. GROUP BY优化
max_length_for_sort_data和sort_buffer_size参数的设置6. 优化分页查询
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 2000000,10) a
WHERE t.id = a.id;
EXPLAIN SELECT * FROM student WHERE id > 2000000 LIMIT 10;
7. 优先考虑覆盖索引
7.1 什么是覆盖索引?
索引列+主键包含SELECT 到 FROM之间查询的列。7.2 覆盖索引的利弊
索引字段的维护总是有代价的。因此,在建立冗余索引来支持覆盖索引时就需要权衡考虑了。这是业务DBA,或者称为业务数据架构师的工作。8. 索引条件下推
8.1 使用前后的扫描过程
9. 其它查询优化策略
9.1 EXISTS 和 IN 的区分
小表驱动大表。9.2 COUNT(*)与COUNT(具体字段)效率
COUNT(*)和COUNT(1)都是对所有结果进行COUNT,COUNT(*)和COUNT(1)本质上并没有区别(二者执行时间可能略有差别,不过你还是可以把它俩的执行效率看成是相等的)。如果有WHERE子句,则是对所有符合筛选条件的数据行进行统计;如果没有WHERE子句,则是对数据表的数据行数进行统计。O(1)的复杂度,这是因为每张MyISAM的数据表都有一个meta信息存储了row_count值,而一致性则是由表级锁来保证的。扫描全表,是O(n)的复杂度,进行循环+计数的方式来完成统计。COUNT(具体字段)来统计数据行数,要尽量采用二级索引。因为主键采用的索引是聚簇索引,聚簇索引包含的信息多,明显会大于二级索引(非聚簇索引)。对于COUNT(*)和COUNT(1)来说,它们不需要查找具体的行,只是统计行数,系统会自动采用占用空间更小的二级索引来进行统计。9.3 关于SELECT(*)
查询数据字典将"*"按序转换成所有列名,这会大大的耗费资源和时间。覆盖索引9.4 LIMIT 1 对优化的影响
LIMIT 1的时候,当找到一条结果的时候就不会继续扫描了,这样会加快查询速度。LIMIT 1了。9.5 多使用COMMIT
第11章 数据库的设计规范
1. 范 式
1.1 范式简介
级别。要想设计一个结构合理的关系型数据库,必须满足一定的范式。1.2 范式都包括哪些

1.3 键和相关属性的概念
球员表(player):球员编号 | 姓名 | 身份证号 | 年龄 | 球队编号球队表(team):球队编号 | 主教练 | 球队所在地
超键:对于球员表来说,超键就是包括球员编号或者身份证号的任意组合,比如(球员编号)(球员编号,姓名)(身份证号,年龄)等。候选键:就是最小的超键,对于球员表来说,候选键就是(球员编号)或者(身份证号)。主键:我们自己选定,也就是从候选键中选择一个,比如(球员编号)。外键:球员表中的球队编号。主属性、非主属性:在球员表中,主属性是(球员编号)(身份证号),其他的属性(姓名)(年龄)(球队编号)都是非主属性。1.4 第一范式(1st NF)
原子性,也就是说数据表中每个字段的值为不可再次拆分的最小数据单位。1.5 第二范式(2nd NF)
1.6 第三范式(3rd NF)
非主键属性之间不能有依赖关系,必须相互独立。1.7 小结
原子性完全依赖直接相关,而不是间接相关数据冗余,第三范式(3NF)通常被认为在性能、拓展性和数据完整性方面达到了最好的平衡。降低查询的效率。因为范式等级越高,设计出来的数据表就越多、越精细,数据的冗余度就越低,进行数据查询的时候就可能需要关联多张表,这不但代价昂贵,也可能使一些索引策略无效。增加少量的冗余或重复的数据来提高数据库的读性能,减少关联查询,join表的次数,实现空间换取时间的目的。因此在实际的设计过程中要理论结合实际,灵活运用。2. 反范式化
2.1 概述
2.2 反范式的新问题
空间变大了数据不一致消耗系统资源数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加复杂2.3 反范式的适用场景
大幅度提高查询效率的时候,我们才会采取反范式的优化。不需要经常进行修改查询的时候不可或缺订单收货信息都属于历史快照,需要进行保存,但用户可以随时修改自己的信息,这时保存这些冗余信息是非常有必要的。数据仓库的设计中,因为数据仓库通常存储历史数据,对增删改的实时性要求不强,对历史数据的分析需求强。这时适当允许数据的冗余度,更方便进行数据分析。3. BCNF(巴斯范式)
4. ER模型
实体关系模型,是用来描述现实生活中客观存在的事物、事物的属性,以及事物之间关系的一种数据模型。在开发基于数据库的信息系统的设计阶段,通常使用ER模型来描述信息需要和信息特性,帮助我们理清业务逻辑,从而设计出优秀的数据库。4.1 ER 模型包括那些要素?
实体,可以看做是数据对象,往往对应于现实生活中的真实存在的个体。在 ER 模型中,用矩形来表示。实体分为两类,分别是强实体和弱实体。强实体是指不依赖于其他实体的实体;弱实体是指对另一个实体有很强的依赖关系的实体。属性,则是指实体的特性。比如超市的地址、联系电话、员工数等。在 ER 模型中用椭圆形来表示。关系,则是指实体之间的联系。比如超市把商品卖给顾客,就是一种超市与顾客之间的联系。在 ER 模型中用菱形来表示。4.2 关系的类型
一对一:指实体之间的关系是一一对应的一对多:指一边的实体通过关系,可以对应多个另外一边的实体。相反,另外一边的实体通过这个关系,则只能对应唯一的一边的实体多对多:指关系两边的实体都可以通过关系对应多个对方的实体5. 数据表的设计原则
6. 数据库对象编写建议
6.1 关于库
一律小写,不同单词采用下划线分割。须见名知意。显式指定字符集,并且字符集只能是utf8或者utf8mb4。创建数据库SQL举例:CREATE DATABASE crm_fund DEFAULT CHARACTER SET 'utf8';权限最小原则。使用数据库账号只能在一个DB下使用,不准跨库。程序使用的账号原则上不准有drop权限。tmp_为前缀,并以日期为后缀;备份库以bak_为前缀,并以日期为后缀。6.2 关于表、列
英文字母开头。表名、列名一律小写,不同单词采用下划线分割。须见名知意。统一前缀。比如:crm_fund_item显式指定字符集为utf8或utf8mb4。显式指定表存储引擎类型。如无特殊需求,一律为InnoDB。缩写。如:公司 ID,不要使用 corporation_id, 而用corp_id 即可。is_描述。如member表上表示是否为enabled的会员的字段命名为 is_enabled。表必须有主键 (1)强制要求主键为id,类型为int或bigint,且为auto_increment 建议使用unsigned无符号型。 (2)标识表里每一行主体的字段不要设为主键,建议设为其他字段如user_id,order_id等,并建立unique key索引。因为如果设为主键且主键值为随机插入,则会导致innodb内部页分裂和大量随机I/O,性能下降。创建时间字段(create_time)和最后更新时间字段(update_time),便于查问题。NOT NULL属性,业务可以根据需要定义DEFAULT值。 因为使用NULL值会存在每一行都会占用额外存储空间、数据迁移容易出错、聚合函数计算结果偏差等问题。列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。tmp_开头。备份表用于备份或抓取源表快照,名称以bak_开头。中间表和备份表定期清理。CREATE TABLE user_info (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`user_id` bigint(11) NOT NULL COMMENT '用户id',
`username` varchar(45) NOT NULL COMMENT '真实姓名',
`email` varchar(30) NOT NULL COMMENT '用户邮箱',
`nickname` varchar(45) NOT NULL COMMENT '昵称',
`birthday` date NOT NULL COMMENT '生日',
`sex` tinyint(4) DEFAULT '0' COMMENT '性别',
`short_introduce` varchar(150) DEFAULT NULL COMMENT '一句话介绍自己,最多50个汉字',
`user_resume` varchar(300) NOT NULL COMMENT '用户提交的简历存放地址',
`user_register_ip` int NOT NULL COMMENT '用户注册时的源ip',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`user_review_status` tinyint NOT NULL COMMENT '用户资料审核状态,1为通过,2为审核中,3为未 通过,4为还未提交审核',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_user_id` (`user_id`),
KEY `idx_username`(`username`),
KEY `idx_create_time_status`(`create_time`,`user_review_status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='网站用户基本信息'
6.3 关于索引
禁止被更新。BTREE。pk_开头,唯一键以uni_或uk_开头,普通索引以idx_开头,一律使用小写格式,以字段的名称或缩写作为后缀。不能超过6个。联合索引,并把区分度最高的字段放在最前面。冗余索引。 比如:如果表里已经存在key(a,b), 则key(a)为冗余索引,需要删除。6.4 SQL编写
表锁,期间阻塞对于该表的所有写入,对于业务可能会产生极大影响。第12章 数据库其它调优策略
1. 数据库调优的措施
1.1 调优的目标
节省系统资源,以便系统可以提供更大负荷的服务。(吞吐量更大) 响应的速度。(响应速度更快)1.2 如何定位调优问题
1.3 调优的维度和步骤
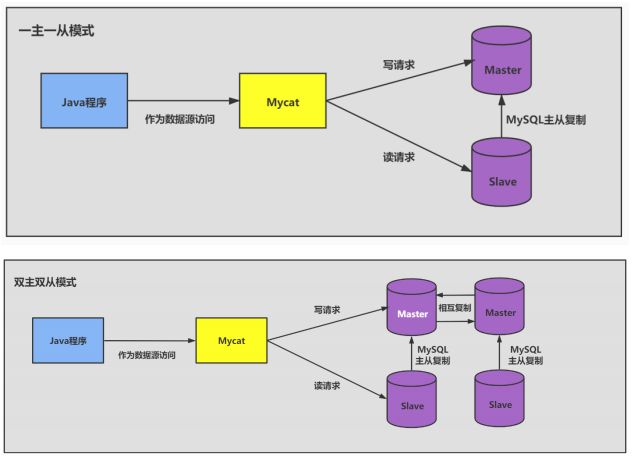

2. 优化MySQL服务器
2.1 优化服务器硬件
配置较大的内存配置高速磁盘系统合理分布磁盘I/O配置多处理器2.2 优化MySQL的参数
innodb_buffer_pool_size:这个参数是Mysql数据库最重要的参数之一,表示InnoDB类型的表和索引的最大缓存。它不仅仅缓存索引数据,还会缓存表的数据。这个值越大,查询的速度就会越快。但是这个值太大会影响操作系统的性能。key_buffer_size:表示索引缓冲区的大小。索引缓冲区是所有的线程共享。增加索引缓冲区可以得到更好处理的索引(对所有读和多重写)。当然,这个值不是越大越好,它的大小取决于内存的大小。如果这个值太大,就会导致操作系统频繁换页,也会降低系统性能。对于内存在4GB左右的服务器该参数可设置为256M或384M。table_cache:表示同时打开的表的个数。这个值越大,能够同时打开的表的个数越多。物理内存越大,设置就越大。默认为2402,调到512-1024最佳。这个值不是越大越好,因为同时打开的表太多会影响操作系统的性能。query_cache_size:表示查询缓冲区的大小。可以通过在MySQL控制台观察,如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,就要增加Query_cache_size的值;如果Qcache_hits的值非常大,则表明查询缓冲使用非常频繁,如果该值较小反而会影响效率,那么可以考虑不用查询缓存;Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。MySQL8.0之后失效。该参数需要和query_cache_type配合使用。query_cache_type的值是0时,所有的查询都不使用查询缓存区。但是query_cache_type=0并不会导致MySQL释放query_cache_size所配置的缓存区内存。
SQL_NO_CACHE,如SELECT SQL_NO_CACHE * FROM tbl_name。SQL_CACHE关键字,查询才会使用查询缓存区。使用查询缓存区可以提高查询的速度,这种方式只适用于修改操作少且经常执行相同的查询操作的情况。sort_buffer_size:表示每个需要进行排序的线程分配的缓冲区的大小。增加这个参数的值可以提高ORDER BY或GROUP BY操作的速度。默认数值是2 097 144字节(约2MB)。对于内存在4GB左右的服务器推荐设置为6-8M,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 6 = 600MB。join_buffer_size = 8M:表示联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。read_buffer_size:表示每个线程连续扫描时为扫描的每个表分配的缓冲区的大小(字节)。当线程从表中连续读取记录时需要用到这个缓冲区。SET SESSION read_buffer_size=n可以临时设置该参数的值。默认为64K,可以设置为4M。innodb_flush_log_at_trx_commit:表示何时将缓冲区的数据写入日志文件,并且将日志文件写入磁盘中。该参数对于innoDB引擎非常重要。该参数有3个值,分别为0、1和2。该参数的默认值为1。
0时,表示每秒1次的频率将数据写入日志文件并将日志文件写入磁盘。每个事务的commit并不会触发前面的任何操作。该模式速度最快,但不太安全,mysqld进程的崩溃会导致上一秒钟所有事务数据的丢失。1时,表示每次提交事务时将数据写入日志文件并将日志文件写入磁盘进行同步。该模式是最安全的,但也是最慢的一种方式。因为每次事务提交或事务外的指令都需要把日志写入(flush)硬盘。2时,表示每次提交事务时将数据写入日志文件,每隔1秒将日志文件写入磁盘。该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失。innodb_log_buffer_size:这是 InnoDB 存储引擎的事务日志所使用的缓冲区。为了提高性能,也是先将信息写入 Innodb Log Buffer 中,当满足 innodb_flush_log_trx_commit 参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件(或者同步到磁盘)中。max_connections:表示 允许连接到MySQL数据库的最大数量 ,默认值是 151 。如果状态变量connection_errors_max_connections 不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections 的值。在Linux 平台下,性能好的服务器,支持 500-1000 个连接不是难事,需要根据服务器性能进行评估设定。这个连接数 不是越大 越好 ,因为这些连接会浪费内存的资源。过多的连接可能会导致MySQL服务器僵死。back_log:用于控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。5.6.6 版本之前默认值为 50 , 之后的版本默认为 50 + (max_connections / 5), 对于Linux系统推荐设置为小于512的整数,但最大不超过900。如果需要数据库在较短的时间内处理大量连接请求, 可以考虑适当增大back_log 的值。thread_cache_size:线程池缓存线程数量的大小,当客户端断开连接后将当前线程缓存起来,当在接到新的连接请求时快速响应无需创建新的线程 。这尤其对那些使用短连接的应用程序来说可以极大的提高创建连接的效率。那么为了提高性能可以增大该参数的值。默认为60,可以设置为120。wait_timeout:指定一个请求的最大连接时间,对于4GB左右内存的服务器可以设置为5-10。interactive_timeout:表示服务器在关闭连接前等待行动的秒数。3. 优化数据库结构
3.1 拆分表:冷热数据分离
3.2 增加中间表
3.3 增加冗余字段
3.4 优化数据类型
INT 型。这样做的理由是,INT 型数据有足够大的取值范围,不用担心数据超出取值范围的问题。刚开始做项目的时候,首先要保证系统的稳定性,这样设计字段类型是可以的。但在数据量很大的时候,数据类型的定义,在很大程度上会影响到系统整体的执行效率。非负型的数据(如自增ID、整型IP)来说,要优先使用无符号整型UNSIGNED来存储。因为无符号相对于有符号,同样的字节数,存储的数值范围更大。如tinyint有符号为-128-127,无符号为0-255,多出一倍的存储空间。更少的存储空间,因此,在存取和比对的时候,可以占用更少的内存空间。所以,在二者皆可用的情况下,尽量使用整数类型,这样可以提高查询的效率。如:将IP地址转换成整型数据。3.5 优化插入记录的速度
3.6 使用非空约束
3.7 分析表、检查表与优化表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name[,tbl_name]…
ANALYZE TABLE分析表的过程中,数据库系统会自动对表加一个只读锁。在分析期间,只能读取表中的记录,不能更新和插入记录。ANALYZE TABLE语句能够分析InnoDB和MyISAM类型的表,但是不能作用于视图。cardinality的值,该值统计了表中某一键所在的列不重复的值的个数。该值越接近表中的总行数,则在表连接查询或者索引查询时,就越优先被优化器选择使用。CHECK TABLE tbl_name [, tbl_name] ... [option] ... option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
CHECK TABLE语句来检查表。CHECK TABLE语句能够检查InnoDB和MyISAM类型的表是否存在错误。CHECK TABLE语句在执行过程中也会给表加上只读锁。OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
OPTIMIZE TABLE语句来优化表。但是,OPTILMIZE TABLE语句只能优化表中的VARCHAR、BLOB或TEXT类型的字段。一个表使用了这些字段的数据类型,若已经删除了表的一大部分数据,或者已经对含有可变长度行的表(含有VARCHAR、BLOB或TEXT列的表)进行了很多更新,则应使用OPTIMIZE TABLE来重新利用未使用的空间,并整理数据文件的碎片。只读锁。第13章 事务基础知识
1. 数据库事务概述
1.1 基本概念
一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交(commit),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务回滚(rollback)到最初状态。1.2 事务的ACID特性
合法性状态变换到另外一个合法性状态。这种状态是语义上的而不是语法上的,跟具体的业务有关。
不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。事务日志来保证的。日志包括了重做日志和回滚日志。当我们通过事务对数据进行修改的时候,首先会将数据库的变化信息记录到重做日志中,然后再对数据库中对应的行进行修改。这样做的好处是,即使数据库系统崩溃,数据库重启后也能找到没有更新到数据库系统中的重做日志,重新执行,从而使事务具有持久性。1.3 事务的状态
活动的状态。
没有刷新到磁盘时,我们就说该事务处在部分提交的状态。
活动的或者部分提交的状态时,可能遇到了某些错误(数据库自身的错误、操作系统错误或者直接断电等)而无法继续执行,或者人为的停止当前事务的执行,我们就说该事务处在失败的状态。
失败的状态,那么就需要把已经修改的事务中的操作还原到事务执行前的状态。换句话说,就是要撤销失败事务对当前数据库造成的影响。我们把这个撤销的过程称之为回滚。当回滚操作执行完毕时,也就是数据库恢复到了执行事务之前的状态,我们就说该事务处在了中止的状态。
部分提交的状态的事务将修改过的数据都同步到磁盘上之后,我们就可以说该事务处在了提交的状态。2. 如何使用事务
2.1 显式事务
START TRANSACTION或者BEGIN,作用是显式开启一个事务。mysql> BEGIN;
#或者
mysql> START TRANSACTION;
START TRANSACTION语句相较于BEGIN特别之处在于,后边能跟随几个修饰符:READ ONLY:标识当前事务是一个只读事务,也就是属于该事务的数据库操作只能读取数据,而不能修改数据。READ WRITE:标识当前事务是一个读写事务,也就是属于该事务的数据库操作既可以读取数据,也可以修改数据。WITH CONSISTENT SNAPSHOT:启动一致性读。# 提交事务。当提交事务后,对数据库的修改是永久性的。
mysql> COMMIT;
# 回滚事务。即撤销正在进行的所有没有提交的修改
mysql> ROLLBACK;
# 将事务回滚到某个保存点。
mysql> ROLLBACK TO [SAVEPOINT]
# 在事务中创建保存点,方便后续针对保存点进行回滚。一个事物中可以存在多个保存点。
SAVEPOINT 保存点名称;
# 删除某个保存点
RELEASE SAVEPOINT 保存点名称;
2.2 隐式事务
START TRANSACTION或者BEGIN语句开启一个事务。这样在本次事务提交或者回滚前会暂时关闭掉自动提交的功能。autocommit的值设置为OFF2.3 隐式提交数据的情况
START TRANSACTION或者BEGIN语句开启了另一个事务时,会隐式的提交上一个事务。autocommit系统变量的值为OFF,我们手动把它调为ON时,也会隐式的提交前边语句所属的事务。LOCK TABLES、UNLOCK TABLES等关于锁定的语句也会隐式的提交前边语句所属的事务。3. 事务隔离级别
3.1 数据并发问题
Dirty Write)修改了另一个未提交事务Session B修改过的数据,那就意味着发生了脏写
Dirty Read)读取了已经被 Session B更新但还没有被提交的字段。之后若 Session B回滚,Session A读取的内容就是临时且无效的。
Non-Repeatable Read)读取了一个字段,然后 Session B更新了该字段。 之后Session A再次读取同一个字段,值就不同了。那就意味着发生了不可重复读。Phantom)读取了一个字段, 然后 Session B 在该表中插入了一些新的行。 之后, 如果 Session A再次读取同一个表, 就会多出几行。那就意味着发生了幻读。剔除了一些符合studentno > 0的记录而不是插入新记录,那么Session A之后再根据studentno > 0的条件读取的记录变少了,这种现象算不算幻读呢?这种现象不属于幻读,幻读强调的是一个事物按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录。不可重复读的现象。幻读只是重点强调了读取到之前读取没有获取到的记录。3.2 SQL中的四种隔离级别
SQL标准中设立了4个隔离级别:
READ UNCOMMITTED:读未提交,在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。不能避免脏读、不可重复读、幻读。READ COMMITTED:读已提交,它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。可以避免脏读,但不可重复读、幻读问题仍然存在。REPEATABLE READ:可重复读,事务A在读到一条数据之后,此时事务B对该数据进行了修改并提交,那么事务A再读该数据,读到的还是原来的内容。可以避免脏读、不可重复读,但幻读问题仍然存在。这是MySQL的默认隔离级别。SERIALIZABLE:可串行化,确保事务可以从一个表中读取相同的行。在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作。所有的并发问题都可以避免,但性能十分低下。能避免脏读、不可重复读和幻读。3.3 如何设置事务的隔离级别
SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL 隔离级别;
#其中,隔离级别格式:
> READ UNCOMMITTED
> READ COMMITTED
> REPEATABLE READ
> SERIALIZABLE
SET [GLOBAL|SESSION] TRANSACTION_ISOLATION = '隔离级别'
#其中,隔离级别格式:
> READ-UNCOMMITTED
> READ-COMMITTED
> REPEATABLE-READ
> SERIALIZABLE
第14章 MySQL事务日志
锁机制实现。
重做日志,提供再写入操作,恢复提交事务修改的页操作,用来保证事务的持久性。回滚日志,回滚行记录到某个特定版本,用来保证事务的原子性、一致性。1. redo日志
1.1 为什么需要REDO日志
并不是每次变更的时候就触发的,而是master线程隔一段时间去处理的。所以最坏的情况就是事务提交后,刚写完缓冲池,数据库宕机了,那么这段数据就是丢失的,无法恢复。持久性的特性,就是说对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失。一个简单的做法:在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘,但是这个简单粗暴的做法有些问题另一个解决的思路:我们只是想让已经提交了的事务对数据库中数据所做的修改永久生效,即使后来系统崩溃,在重启后也能把这种修改恢复出来。所以我们其实没有必要在每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好。比如,某个事务将系统表空间中第10号页面中偏移量为100处的那个字节的值1改成2。我们只需要记录一下:将第0号表空间的10号页面的偏移量为100处的值更新为 2 。1.2 REDO日志的好处、特点
1.3 redo的组成
重做日志的缓冲 (redo log buffer) ,保存在内存中,是易失的。16M,最大值是4096M,最小值为1M。
重做日志文件 (redo log file),保存在硬盘中,是持久的。1.4 redo的整体流程
1.5 redo log的刷盘策略
文件系统缓存(page cache)中去(这是现代操作系统为了提高文件写入效率做的一个优化),真正的写入会交给系统自己来决定(比如page cache足够大了)。那么对于InnoDB来说就存在一个问题,如果交给系统来同步,同样如果系统宕机,那么数据也丢失了(虽然整个系统宕机的概率还是比较小的)。innodb_flush_log_at_trx_commit参数,该参数控制 commit提交事务时,如何将 redo log buffer 中的日志刷新到 redo log file 中。它支持三种策略:
设置为0:表示每次事务提交时不进行刷盘操作。(系统默认master thread每隔1s进行一次重做日志的同步)设置为1:表示每次事务提交时都将进行同步,刷盘操作(默认值)设置为2:表示每次事务提交时都只把 redo log buffer 内容写入 page cache,不进行同步。由os自己决定什么时候同步到磁盘文件。1.6 不同刷盘策略演示
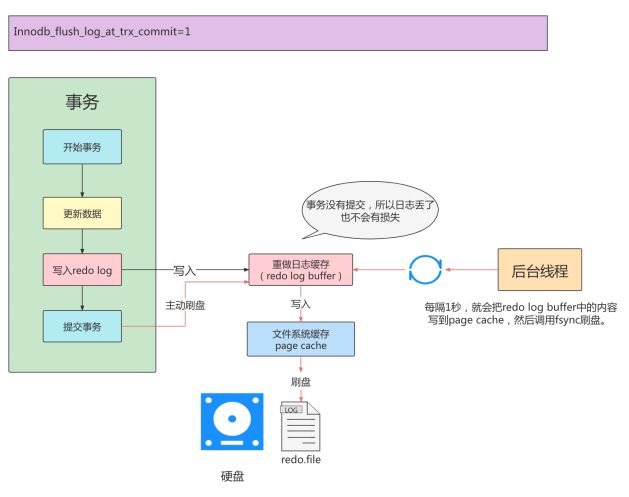
1.7 写入redo log buffer过程
mtr组成,每一个mtr又可以包含若干条redo日志并发执行的,所以事务T1、事务T2之间的mtr可能是交替执行的。1.8 redo log file
innodb_log_group_home_dir:指定 redo log 文件组所在的路径,默认值为./,表示在数据库的数据目录下。MySQL的默认数据目录(var/lib/mysql)下默认有两个名为ib_logfile0和ib_logfile1的文件,log buffer中的日志默认情况下就是刷新到这两个磁盘文件中。此redo日志文件位置还可以修改。innodb_log_files_in_group:指明redo log file的个数,命名方式如:ib_logfile0,ib_logfile1… ib_logfilen。默认2个,最大100个。innodb_flush_log_at_trx_commit:控制 redo log 刷新到磁盘的策略,默认为1。innodb_log_file_size:单个 redo log 文件设置大小,默认值为 48M 。最大值为512G,注意最大值指的是整个 redo log 系列文件之和,即(innodb_log_files_in_group * innodb_log_file_size )不能大于最大值512G。
2. Undo日志
更新数据的前置操作其实是要先写入一个 undo log 。2.1 如何理解Undo日志
原子性,也就是事务中的操作要么全部完成,要么什么也不做。但有时候事务执行到一半会出现一些情况,比如:
服务器本身的错误,操作系统错误,甚至是突然断电导致的错误。ROLLBACK语句结束当前事务的执行。回滚,这样就可以造成一个假象:这个事务看起来什么都没做,所以符合原子性要求。2.2 Undo日志的作用
2.3 undo的存储结构
回滚段(rollback segment)。每个回滚段记录了1024个undo log segment,而在每个undo log segment段中进行undo页的申请。
2.4 undo的类型
2.5 undo log的生命周期
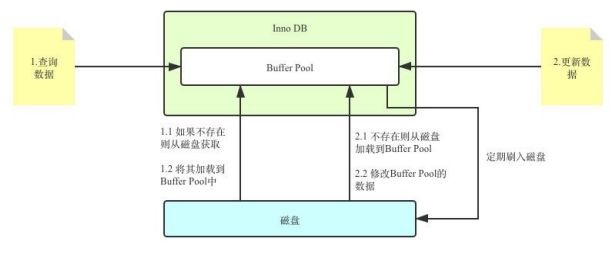
begin;
INSERT INTO user (name) VALUES ("tom");
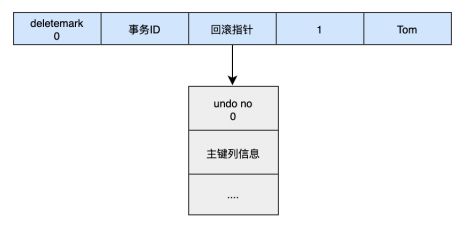

UPDATE user SET id=2 WHERE id=1;

2.6 小结
第15章 锁
1. 概述
并发操作进行控制,因此产生了锁。同时锁机制也为实现MySQL的各个隔离级别提供了保证。 锁冲突 也是影响数据库并发访问性能的一个重要因素。所以锁对数据库而言显得尤其重要,也更加复杂。2. MySQL并发事务访问相同记录
2.1 读-读情况
读-读情况,即并发事务相继读取相同的记录。读取操作本身不会对记录有任何影响,并不会引起什么问题,所以允许这种情况的发生。2.2 写-写情况
写-写情况,即并发事务相继对相同的记录做出改动。脏写的问题,任何一种隔离级别都不允许这种问题的发生。所以在多个未提交事务相继对一条记录做改动时,需要让它们排队执行,这个排队的过程其实是通过锁来实现的。2.3 读-写或写-读情况
读-写或写-读,即一个事务进行读取操作,另一个进行改动操作。这种情况下可能发生脏读、不可重复读、幻读的问题。2.4 并发问题的解决方案
脏读、不可重复读、幻读这些问题呢?其实有两种可选的解决方案:
MVCC,下章讲解),写操作进行加锁。MVCC,就是生成一个ReadView,通过ReadView找到符合条件的记录版本(历史版本由undo日志构建)。查询语句只能读到在生成ReadView之前已提交事务所做的更改,在生成ReadView之前未提交的事务或者之后才开启的事务所做的更改是看不到的。而写操作肯定针对的是最新版本的记录,读记录的历史版本和改动记录的最新版本本身并不冲突,也就是采用MVCC时,读-写操作并不冲突。
READ COMMITTED隔离级别下,一个事务在执行过程中每次执行SELECT操作时都会生成一个ReadView,ReadView的存在本身就保证了事务不可以读取到未提交的事务所做的更改,也就是避免了脏读现象;REPEATABLE READ隔离级别下,一个事务在执行过程中只有第一次执行SELECT操作 才会生成一个ReadView,之后的SELECT操作都复用这ReadView,这样也就避免了不可重复读和幻读的问题。
加锁的方式。
MVCC方式的话,读-写操作彼此并不冲突,性能更高。加锁方式的话,读-写操作彼此需要排队执行,影响性能。MVCC来解决读-写操作并发执行的问题,但是业务在某些特殊情况下,要求必须采用加锁的方式执行。3. 锁的不同角度分类
3.1 从数据操作的类型划分:读锁、写锁
读锁:也称为共享锁、英文用S表示。针对同一份数据,多个事务的读操作可以同时进行而不会互相影响,相互不阻塞的。写锁:也称为排他锁、英文用X表示。当前写操作没有完成前,它会阻断其他写锁和读锁。这样就能确保在给定的时间里,只有一个事务能执行写入,并防止其他用户读取正在写入的同一资源。加锁方式解决脏读、不可重复读、幻读这些问题时,读取一条记录时需要获取该记录的S锁,其实是不严谨的,有时候需要在读取记录时就获取记录的X锁,来禁止别的事务读写该记录,为此MySQL提出了两种比较特殊的SELECT语句格式:
S锁:SELECT ... LOCK IN SHARE MODE;
# 或
SELECT ... FOR SHARE; #(8.0新增语法)
X锁:SELECT ... FOR UPDATE;
innodb_lock_wait_timeout超时。在8.0版本中,SELECT … FOR UPDATE, SELECT … FOR SHARE 添加NOWAIT、SKIP LOCKED语法,跳过锁等待,或者跳过锁定。
DELETE:对一条记录做DELETE操作的过程其实是先在B+树中定位到这条记录的位置,然后获取这条记录的X锁,再执行delete mark操作。UPDATE:在对一条记录做UPDATE操作时分为三种情况:
B+树中定位到这条记录的位置,然后再获取一下记录的X锁,最后在原纪录的位置进行修改操作。B+树中定位到这条记录的位置,然后获取一下记录的X锁,将该记录彻底删除掉(就是把记录彻底移入垃圾链表),最后再插入一条新记录。新插入的记录由INSERT操作提供的隐式锁进行保护。DELECT操作之后再来一次INSERT操作。INSERT:一般情况下,新插入一条记录的操作并不加锁,通过一种称之为隐式锁的结构来保护这条新插入的记录在本事务提交前不被别的事务访问。3.2 从数据操作的粒度划分:表级锁、页级锁、行锁
不依赖于存储引擎,并且表锁是开销最少的策略。由于表级锁一次会将整个表锁定,所以可以很好的避免死锁的问题。当然,锁的粒度大所带来最大的负面影响就是出现锁资源争用的概率也会最高,导致并发率大打折扣。S锁或者X锁的。在对某个表执行一些诸如ALTER TABLE、DROP TABLE这类的DDL语句时,其他事务对这个表并发执行诸如SELECT、INSERT、DELETE、UPDATE的语句会发生阻塞。同理,某个事务中对某个表执行SELECT、INSERT、DELETE、UPDATE语句时,在其他会话中对这个表执行DDL语句也会发生阻塞。这个过程其实是通过在server层使用一种称之为元数据锁(英文名:Metadata Locks,简称MDL)结构来实现的。S锁和X锁。只会在一些特殊情况下,比方说崩溃恢复过程中用到。比如,在系统变量autocommit=0,innodb_table_locks = 1时,手动获取InnoDB存储引擎提供的表t 的S锁或者X锁可以这么写:
LOCK TABLES t READ:InnoDB存储引擎会对表t加表级别的S锁。LOCK TABLES t WRITE:InnoDB存储引擎会对表t加表级别的X锁。InnoDB存储引擎是不会为这个表添加表级别的读锁或者写锁的。多粒度锁(multiple granularity locking),它允许行级锁与表级锁共存,而意向锁就是其中的一种表锁。不与行级锁冲突的表级锁,这一点非常重要。
-- 事务要获取某些行的 S 锁,必须先获得表的 IS 锁。
SELECT column FROM table ... LOCK IN SHARE MODE;
-- 事务要获取某些行的 X 锁,必须先获得表的 IX 锁。
SELECT column FROM table ... FOR UPDATE;
自己维护的,用户无法手动操作意向锁,在为数据行加共享 / 排他锁之前,InooDB 会先获取该数据行所在数据表的对应意向锁。表级别意向锁的阻塞。T2在锁定该表前不必检查各个页或行锁,而只需检查表上的意向锁。简单来说就是给更大一级级别的空间示意里面是否已经上过锁。
添加意向共享锁添加意向排他锁预先确定要插入的行数(当语句被初始处理时)的语句。包括没有嵌套子查询的单行和多行INSERT...VALUES()和REPLACE语句。事先不知道要插入的行数(和所需自动递增值的数量)的语句。比如INSERT ... SELECT,REPLACE ... SELECT和LOAD DATA语句,但不包括纯INSERT。 InnoDB在每处理一行,为AUTO_INCREMENT列分配一个新值。INSERT INTO teacher (id,name) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');只是指定了部分id的值。另一种类型的“混合模式插入”是INSERT ... ON DUPLICATE KEY UPDATE。自增锁的方式来实现,AUTO-INT锁是当向使用含有AUTO_INCREMENT列的表中插入数据时需要获取的一种特殊的表级锁,在执行插入语句时就在表级别加一个AUTO-INT锁,然后为每条待插入记录的AUTO_INCREMENT修饰的列分配递增的值,在该语句执行结束后,再把AUTO-INT锁释放掉。一个事务在持有AUTO-INC锁的过程中,其他事务的插入语句都要被阻塞,可以保证一个语句中分配的递增值是连续的。也正因为此,其并发性显然并不高,当我们向一个有AUTO_INCREMENT关键字的主键插入值的时候,每条语句都要对这个表锁进行竞争,这样的并发潜力其实是很低下的,所以innodb通过innodb_autoinc_lock_mode的不同取值来提供不同的锁定机制,来显著提高SQL语句的可伸缩性和性能。(1)innodb_autoinc_lock_mode = 0(“传统”锁定模式)限制并发能力。(2)innodb_autoinc_lock_mode = 1(“连续”锁定模式)默认的。mutex(轻量锁)的控制下获得所需数量的自动递增值来避免表级AUTO-INC锁, 它只在分配过程的持续时间内保持,而不是直到语句完成。不使用表级AUTO-INC锁,除非AUTO-INC锁由另一个事务保持。如果另一个事务保持AUTO-INC锁,则“Simple inserts”等待AUTO-INC锁,如同它是一个“bulk inserts”。(3)innodb_autoinc_lock_mode = 2(“交错”锁定模式)默认设置。保证在所有并发执行的所有类型的insert语句中是唯一且单调递增的。但是,由于多个语句可以同时生成数字(即,跨语句交叉编号),为任何给定语句插入的行生成的值可能不是连续的。表结构做变更,增加了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。锁冲突概率低,可以实现的并发度高锁的开销比较大,加锁会比较慢,容易出现死锁情况LOCK_REC_NOT_GAP。S型记录锁和X型记录锁。
MySQL在REPEATABLE READ隔离级别下是可以解决幻读问题的,解决方案有两种,可以使用MVCC方案解决,也可以采用加锁方案解决。但是在使用加锁方案解决时有个大问题,就是事务在第一次执行读取操作时,那些幻影记录尚不存在,我们无法给这些幻影记录加上记录锁。InnoDB提出了一种称之为Gap Locks的锁,官方的类型名称为:LOCK_GAP,我们可以简称为gap锁。共享gap锁和独占gap锁这样的说法,但是它们起到的作用是相同的。而且如果对一条记录加了gap锁(不论是共享gap锁还是独占gap锁),并不会限制其他事务对这条记录加记录锁或者继续加gap锁。锁住某条记录,又想阻止其他事务在该记录前边的间隙插入新记录,所以InnoDB就提出了一种称之为Next-Key Locks的锁,官方的类型名称为:LOCK_ORDINARY,我们也可以简称为next-key锁。Next-Key Locks是在存储引擎innodb、事务级别在可重复读的情况下使用的数据库锁,innodb默认的锁就是Next-Key locks。begin;
select * from student where id <=8 and id > 3 for update;
插入一条记录时需要判断一下插入位置是不是被别的事务加了gap锁(next-key锁也包含gap锁),如果有的话,插入操作需要等待,直到拥有gap锁的那个事务提交。但是InnoDB规定事务在等待的时候也需要在内存中生成一个锁结构,表明有事务想在某个间隙中插入新记录,但是现在在等待。InnoDB就把这种类型的锁命名为Insert Intention Locks,官方的类型名称为:LOCK_INSERT_INTENTION,我们称为插入意向锁。插入意向锁是一种Gap锁,不是意向锁,在insert操作时产生。INSERT 操作产生的一种间隙锁。页的粒度上进行锁定,锁定的数据资源比行锁要多,因为一个页中可以有多个行记录。当我们使用页锁的时候,会出现数据浪费的现象,但这样的浪费最多也就是一个页上的数据行。页锁的开销介于表锁和行锁之间,会出现死锁。锁定粒度介于表锁和行锁之间,并发度一般。锁空间的大小是有限的。当某个层级的锁数量超过了这个层级的阈值时,就会进行锁升级。锁升级就是用更大粒度的锁替代多个更小粒度的锁,比如InnoDB 中行锁升级为表锁,这样做的好处是占用的锁空间降低了,但同时数据的并发度也下降了。3.3 从对待锁的态度划分:乐观锁、悲观锁
数据并发的思维方式。需要注意的是,乐观锁和悲观锁并不是锁,而是锁的设计思想。阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁,当其他线程想要访问数据时,都需要阻塞挂起。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。版本号机制或者CAS机制实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量。在Java中java.util.concurrent.atomic包下的原子变量类就是使用了乐观锁的一种实现方式:CAS实现的。版本字段 version,第一次读的时候,会获取 version 字段的取值。然后对数据进行更新或删除操作时,会执行UPDATE ... SET version=version+1 WHERE version=version。此时如果已经有事务对这条数据进行了更改,修改就不会成功。
乐观锁适合读操作多的场景,相对来说写的操作比较少。它的优点在于程序实现,不存在死锁问题,不过适用场景也会相对乐观,因为它阻止不了除了程序以外的数据库操作。悲观锁适合写操作多的场景,因为写的操作具有排它性。采用悲观锁的方式,可以在数据库层面阻止其他事务对该数据的操作权限,防止读 - 写和写 - 写的冲突。3.4 按加锁的方式划分:显式锁、隐式锁
trx_id隐藏列,该隐藏列记录着最后改动该记录的事务id。那么如果在当前事务中新插入一条聚簇索引记录后,该记录的trx_id隐藏列代表的的就是当前事务的事务id,如果其他事务此时想对该记录添加S锁或者X锁时,首先会看一下该记录的trx_id隐藏列代表的事务是否是当前的活跃事务,如果是的话,那么就帮助当前事务创建一个X锁(也就是为当前事务创建一个锁结构,is_waiting属性是false),然后自己进入等待状态(也就是为自己也创建一个锁结构,is_waiting属性是true)。trx_id隐藏列,但是在二级索引页面的Page Header部分有一个PAGE_MAX_TRX_ID属性,该属性代表对该页面做改动的最大的事务id,如果PAGE_MAX_TRX_ID属性值小于当前最小的活跃事务id,那么说明对该页面做修改的事务都已经提交了,否则就需要在页面中定位到对应的二级索引记录,然后回表找到它对应的聚簇索引记录,然后再重复情景一的做法。事务id的存在,相当于加了一个隐式锁。别的事务在对这条记录加S锁或者X锁时,由于隐式锁的存在,会先帮助当前事务生成一个锁结构,然后自己再生成一个锁结构后进入等待状态。隐式锁是一种延迟加锁的机制,从而来减少加锁的数量。3.5 其它锁之:全局锁
整个数据库实例加锁。当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。全局锁的典型使用场景是:做全库逻辑备份。Flush tables with read lock
3.6 其它锁之:死锁
回滚,另外事务继续进行。4. 锁的内存结构
1. 锁所在的事务信息:表锁还是行锁,都是在事务执行过程中生成的,哪个事务生成了这个 锁结构 ,这里就记录这个事务的信息。锁所在的事务信息在内存结构中只是一个指针,通过指针可以找到内存中关于该事务的更多信息,比方说事务id等。2. 索引信息:行锁来说,需要记录一下加锁的记录是属于哪个索引的。这里也是一个指针。3. 表锁/行锁信息:表锁结构和行锁结构在这个位置的内容是不同的:
4. type_mode:lock_mode、lock_type和rec_lock_type三个部分,如图所示:
lock_mode),占用低4位,可选的值如下:
LOCK_IS(十进制的0):表示共享意向锁,也就是IS锁。LOCK_IX(十进制的1):表示独占意向锁,也就是IX锁。LOCK_S(十进制的2):表示共享锁,也就是S锁。LOCK_X(十进制的3):表示独占锁,也就是X锁。LOCK_AUTO_INC(十进制的4):表示AUTO-INC锁。
lock_type),占用第5~8位,不过现阶段只有第5位和第6位被使用:
LOCK_TABLE(十进制的16),也就是当第5个比特位置为1时,表示表级锁。LOCK_REC(十进制的32),也就是当第6个比特位置为1时,表示行级锁。rec_lock_type),使用其余的位来表示。只有在 lock_type的值为LOCK_REC时,也就是只有在该锁为行级锁时,才会被细分为更多的类型:
LOCK_ORDINARY(十进制的0):表示next-key锁。LOCK_GAP(十进制的512):也就是当第10个比特位置为1时,表示gap锁。LOCK_REC_NOT_GAP(十进制的1024):也就是当第11个比特位置为1时,表示正经记录锁。LOCK_INSERT_INTENTION(十进制的2048):也就是当第12个比特位置为1时,表示插入意向锁。其他的类型:还有一些不常用的类型我们就不多说了。is_waiting属性呢?基于内存空间的节省,所以把 is_waiting 属性放到了 type_mode 这个32位的数字中:
LOCK_WAIT(十进制的256) :当第9个比特位置为1时,表示is_waiting为true,也就是当前事务尚未获取到锁,处在等待状态;当这个比特位为0时,表示is_waiting为false,也就是当前事务获取锁成功。5. 其他信息:6. 一堆比特位:行锁结构的话,在该结构末尾还放置了一堆比特位,比特位的数量是由上边提到的n_bits属性表示的。InnoDB数据页中的每条记录在记录头信息中都包含一个 heap_no 属性,伪记录Infimum的heap_no值为0,Supremum的heap_no值为1,之后每插入一条记录,heap_no值就增1。锁结构最后的一堆比特位就对应着一个页面中的记录,一个比特位映射一个heap_no,即一个比特位映射到页内的一条记录。5. 锁监控
mysql> show status like 'innodb_row_lock%';
Innodb_row_lock_time:从系统启动到现在锁定总时间长度;(等待总时长)Innodb_row_lock_time_avg:每次等待所花平均时间;(等待平均时长)Innodb_row_lock_waits:系统启动后到现在总共等待的次数;(等待总次数)information_schema库中,涉及到的三张表分别是INNODB_TRX、INNODB_LOCKS和INNODB_LOCK_WAITS。MySQL5.7及之前,可以通过information_schema.INNODB_LOCKS查看事务的锁情况,但只能看到阻塞事务的锁;如果事务并未被阻塞,则在该表中看不到该事务的锁情况。performance_schema.data_locks,可以通过performance_schema.data_locks查看事务的锁情况,和MySQL5.7及之前不同,performance_schema.data_locks不但可以看到阻塞该事务的锁,还可以看到该事务所持有的锁。performance_schema.data_lock_waits所代替。第16章 多版本并发控制
1. 什么是MVCC
并发控制。这项技术使得在InnoDB的事务隔离级别下执行一致性读操作有了保证。换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。2. 快照读与当前读
读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读,而这个读指的就是快照读, 而非当前读。当前读实际上是一种加锁的操作,是悲观锁的实现。而MVCC本质是采用乐观锁思想的一种方式。2.1 快照读
2.2 当前读
3. 复习
3.1 再谈隔离级别


3.2 隐藏字段、Undo Log版本链
InnoDB存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列。
trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id 隐藏列。roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到 undo日志 中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。4. MVCC实现原理之ReadView
4.1 什么是ReadView
活跃事务的ID(“活跃”指的就是,启动了但还没提交)。4.2 设计思路
READ UNCOMMITTED隔离级别的事务,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。SERIALIZABLE隔离级别的事务,InnoDB规定使用加锁的方式来访问记录。READ COMMITTED和REPEATABLE READ隔离级别的事务,都必须保证读到已经提交了的事务修改过的记录。假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是需要判断一下版本链中的哪个版本是当前事务可见的,这是ReadView要解决的主要问题。
creator_trx_id,创建这个 Read View 的事务 ID。
trx_ids,表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。up_limit_id,活跃的事务中最小的事务 ID。low_limit_id,表示生成ReadView时系统中应该分配给下一个事务的id值。low_limit_id 是系统最大的事务id值,这里要注意是系统中的事务id,需要区别于正在活跃的事务ID。
4.3 ReadView的规则
creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。up_limit_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。low_limit_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。up_limit_id和low_limit_id之间,那就需要判断一下trx_id属性值是不是在 trx_ids 列表中。
4.4 MVCC整体操作流程
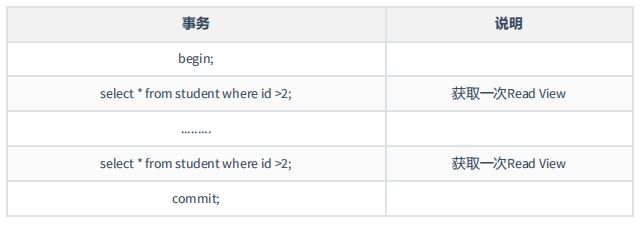

5. 举例说明
5.1 READ COMMITTED隔离级别下
5.2 REPEATABLE READ隔离级别下
REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个 ReadView ,之后的查询就不会重复生成了。5.3 如何解决幻读
事务 A的事务 id 为20,事务 B的事务 id 为30。select * from student where id >= 1;
trx_ids= [20,30],up_limit_id=20,low_limit_id=31,creator_trx_id=20。insert into student(id,name) values(2,'李四');
insert into student(id,name) values(3,'王五');
6. 总结
MVCC在READ COMMITTD、REPEATABLE READ这两种隔离级别的事务在执行快照读操作时访问记录的版本链的过程。这样使不同事务的读-写、写-读操作并发执行,从而提升系统性能。READ COMMITTD、REPEATABLE READ这两个隔离级别的一个很大不同就是生成ReadView的时机不同:
READ COMMITTD在每一次进行普通SELECT操作前都会生成一个ReadViewREPEATABLE READ只在第一次进行普通SELECT操作前生成一个ReadView,之后的查询操作都重复使用这个ReadView就好了。第17章 其它数据库日志
1. MySQL支持的日志
1.1 日志类型
二进制日志、错误日志、通用查询日志和慢查询日志,这也是常用的4种。MySQL 8又新增两种支持的日志:中继日志和数据定义语句日志。使用这些日志文件,可以查看MySQL内部发生的事情。
文本文件。默认情况下,所有日志创建于MySQL数据目录中。1.2 日志的弊端
降低MySQL数据库的性能。占用大量的磁盘空间。2. 通用查询日志(general query log)
记录用户的所有操作,包括启动和关闭MySQL服务、所有用户的连接开始时间和截止时间、发给 MySQL 数据库服务器的所有 SQL 指令等。当我们的数据发生异常时,查看通用查询日志,还原操作时的具体场景,可以帮助我们准确定位问题。2.1 查看当前状态
mysql> SHOW VARIABLES LIKE '%general%';
2.2 启动日志
[mysqld]
general_log=ON
general_log_file=[path[filename]] #日志文件所在目录路径,filename为日志文件名
SET GLOBAL general_log=on; # 开启通用查询日志
SET GLOBAL general_log_file=’path/filename’; # 设置日志文件保存位置
SET GLOBAL general_log=off; # 关闭通用查询日志
SHOW VARIABLES LIKE 'general_log%'; # 查看设置后情况
2.3 停止日志
[mysqld]
general_log=OFF
SET GLOBAL general_log=off;
SHOW VARIABLES LIKE 'general_log%';
3.错误日志(error log)
3.1 启动日志
默认开启的。而且,错误日志无法被禁止。[mysqld]
log-error=[path/[filename]] #path为日志文件所在的目录路径,filename为日志文件名
3.2 查看日志
mysql> SHOW VARIABLES LIKE 'log_err%';
3.3 删除\刷新日志
install -omysql -gmysql -m0644 /dev/null /var/log/mysqld.log
mysqladmin -uroot -p flush-logs
4. 二进制日志(bin log)
4.1 查看默认情况
mysql> show variables like '%log_bin%';
4.2 日志参数设置
[mysqld]
#启用二进制日志
log-bin=atguigu-bin
binlog_expire_logs_seconds=600 max_binlog_size=100M
[mysqld]
log-bin="/var/lib/mysql/binlog/atguigu-bin"
chown -R -v mysql:mysql binlog
# global 级别
mysql> set global sql_log_bin=0;
ERROR 1228 (HY000): Variable 'sql_log_bin' is a SESSION variable and can`t be used with SET GLOBAL
# session级别
mysql> SET sql_log_bin=0;
Query OK, 0 rows affected (0.01 秒)
4.3 查看日志
mysqlbinlog -v "/var/lib/mysql/binlog/atguigu-bin.000002"
# 不显示binlog格式的语句
mysqlbinlog -v --base64-output=DECODE-ROWS "/var/lib/mysql/binlog/atguigu-bin.000002"
# 可查看参数帮助
mysqlbinlog --no-defaults --help
# 查看最后100行
mysqlbinlog --no-defaults --base64-output=decode-rows -vv atguigu-bin.000002 |tail -100
# 根据position查找
mysqlbinlog --no-defaults --base64-output=decode-rows -vv atguigu-bin.000002 |grep -A20 '4939002'
mysql> show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
IN 'log_name':指定要查询的binlog文件名(不指定就是第一个binlog文件)FROM pos:指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)LIMIT [offset]:偏移量(不指定就是0)row_count:查询总条数(不指定就是所有行)mysql> show binlog events in 'atguigu-bin.000002';
4.4 使用日志恢复数据
mysqlbinlog [option] filename|mysql –uuser -ppass;
filename:是日志文件名。option:可选项,比较重要的两对option参数是–start-date、–stop-date 和 --start-position、-- stop-position。
--start-date 和 --stop-date:可以指定恢复数据库的起始时间点和结束时间点。--start-position和--stop-position:可以指定恢复数据的开始位置和结束位置。
4.5 删除二进制日志
PURGE {MASTER | BINARY} LOGS TO ‘指定日志文件名’
PURGE {MASTER | BINARY} LOGS BEFORE ‘指定日期’
5. 再谈二进制日志(binlog)
5.1 写入机制
binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。因为一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为binlog cache。sync_binlog控制,默认是 0。为0的时候,表示每次提交事务都只write,由系统自行判断什么时候执行fsync。虽然性能得到提升,但是机器宕机,page cache里面的binglog 会丢失。如下图:1,表示每次提交事务都会执行fsync,就如同redo log 刷盘流程一样。最后还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write,但累积N个事务后才fsync。5.2 binlog与redolog对比
物理日志,记录内容是“在某个数据页上做了什么修改”,属于 InnoDB 存储引擎层产生的。逻辑日志,记录内容是语句的原始逻辑,类似于“给 ID=2 这一行的 c 字段加 1”,属于MySQL Server 层。
5.3 两阶段提交
写入时机不一样。
6. 中继日志(relay log)
6.1 介绍
本地的日志文件中,这个从服务器本地的日志文件就叫中继日志。然后,从服务器读取中继日志,并根据中继日志的内容对从服务器的数据进行更新,完成主从服务器的数据同步。6.2 恢复的典型错误
服务器名称与之前不同。而中继日志里是包含从服务器名的。在这种情况下,就可能导致你恢复从服务器的时候,无法从宕机前的中继日志里读取数据,以为是日志文件损坏了,其实是名称不对了。第18章 主从复制
1. 主从复制概述
1.1 如何提升数据库并发能力
读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做主从架构、进行读写分离,这样同样可以提升数据库的并发处理能力。但并不是所有的应用都需要对数据库进行主从架构的设置,毕竟设置架构本身是有成本的。优化SQL和索引,这种方式简单有效;其次才是采用缓存的策略,比如使用 Redis将热点数据保存在内存数据库中,提升读取的效率;最后才是对数据库采用主从架构,进行读写分离。1.2 主从复制的作用
2. 主从复制的原理
2.1 原理剖析
3 个线程来操作,一个主库线程,两个从库线程。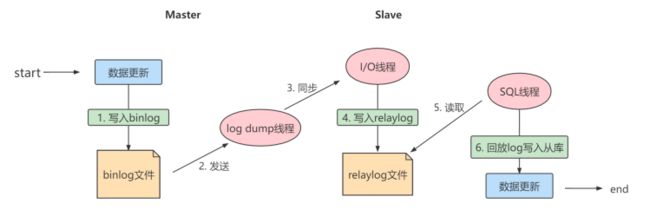
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上加锁,读取完成之后,再将锁释放掉。从库 I/O 线程会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。从库 SQL 线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
Master将写操作记录到二进制日志(binlog)。Slave将Master的binary log events拷贝到它的中继日志(relay log);Slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的,而且重启后从接入点开始复制。延时2.2 复制的基本原则
Slave只有一个MasterSlave只能有一个唯一的服务器IDMaster可以有多个Slave3. 同步数据一致性问题
3.1 理解主从延迟问题
网络传输的过程中就一定会存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。3.2 主从延迟问题原因
3.3 如何减少主从延迟
减少批量操作,建议写脚本以update-sleep这样的形式完成。提高从库机器的配置,减少主库写binlog和从库读binlog的效率差。短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。3.4 如何解决一致性问题

执行读写(RW)事务的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接 COMMIT 即可。第19章 数据库备份与恢复
1. 物理备份与逻辑备份
xtrabackup工具来进行物理备份。mysqldump。逻辑备份就是备份sql语句,在恢复的时候执行备份的sql语句实现数据库数据的重现。2. mysqldump实现逻辑备份
2.1 备份一个数据库
mysqldump –u 用户名称 –h 主机名称 –p密码 待备份的数据库名称[tbname, [tbname...]]> 备份文件名 称.sql
mysqldump -uroot -p atguigu>atguigu.sql #备份文件存储在当前目录下
mysqldump -uroot -p atguigudb1 > /var/lib/mysql/atguigu.sql
2.2 备份全部数据库
mysqldump -uroot -pxxxxxx --all-databases > all_database.sql
mysqldump -uroot -pxxxxxx -A > all_database.sql
2.3 备份部分数据库
mysqldump –u user –h host –p --databases [数据库的名称1 [数据库的名称2...]] > 备份文件名 称.sql
mysqldump -uroot -p --databases atguigu atguigu12 >two_database.sql
mysqldump -uroot -p -B atguigu atguigu12 > two_database.sql
2.4 备份部分表
mysqldump –u user –h host –p 数据库的名称 [表名1 [表名2...]] > 备份文件名称.sql
mysqldump -uroot -p atguigu book> book.sql
#备份多张表
mysqldump -uroot -p atguigu book account > 2_tables_bak.sql
2.5 备份单表的部分数据
mysqldump -uroot -p atguigu student --where="id < 10 " > student_part_id10_low_bak.sql
2.6 排除某些表的备份
mysqldump -uroot -p atguigu --ignore-table=atguigu.student > no_stu_bak.sql
2.7 只备份结构或只备份数据
mysqldump -uroot -p atguigu --no-data > atguigu_no_data_bak.sql
mysqldump -uroot -p atguigu --no-create-info > atguigu_no_create_info_bak.sql
2.8 备份中包含存储过程、函数、事件
mysqldump -uroot -p -R -E --databases atguigu > fun_atguigu_bak.sql
3. mysql命令恢复数据
mysql –u root –p [dbname] < backup.sql
3.1 单库备份中恢复单库
#备份文件中包含了创建数据库的语句
mysql -uroot -p < atguigu.sql
#备份文件中不包含了创建数据库的语句
mysql -uroot -p atguigu4< atguigu.sql
3.2 全量备份恢复
mysql –u root –p < all.sql
3.3 从全量备份中恢复单库
sed -n '/^-- Current Database: `atguigu`/,/^-- Current Database: `/p' all_database.sql > atguigu.sql
#分离完成后我们再导入atguigu.sql即可恢复单个库
3.4 从单库备份中恢复单表
cat atguigu.sql | sed -e '/./{H;$!d;}' -e 'x;/CREATE TABLE `class`/!d;q' > class_structure.sql
cat atguigu.sql | grep --ignore-case 'insert into `class`' > class_data.sql
#用shell语法分离出创建表的语句及插入数据的语句后 再依次导出即可完成恢复
use atguigu;
mysql> source class_structure.sql;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> source class_data.sql;
Query OK, 1 row affected (0.01 sec)
4. 表的导出与导入
4.1 表的导出
SHOW GLOBAL VARIABLES LIKE '%secure%';
SELECT * FROM account INTO OUTFILE "/var/lib/mysql-files/account.txt";
mysqldump -uroot -p -T "/var/lib/mysql-files/" atguigu account
# 或
mysqldump -uroot -p -T "/var/lib/mysql-files/" atguigu account --fields-terminated- by=',' --fields-optionally-enclosed-by='\"'
mysql -uroot -p --execute="SELECT * FROM account;" atguigu> "/var/lib/mysql-files/account.txt"
4.2 表的导入
LOAD DATA INFILE '/var/lib/mysql-files/account_0.txt' INTO TABLE atguigu.account;
# 或
LOAD DATA INFILE '/var/lib/mysql-files/account_1.txt' INTO TABLE atguigu.account FIELDS TERMINATED BY ',' ENCLOSED BY '\"';
mysqlimport -uroot -p atguigu '/var/lib/mysql-files/account.txt' --fields-terminated- by=',' --fields-optionally-enclosed-by='\"'