【深入浅出SpringCloud原理及实战】「Netflix系列之Hystrix」针对于限流熔断组件Hystrix的回退降级实现方案和机制
针对于限流熔断组件Hystrix的回退降级实现方案和机制
-
-
- 依赖隔离
-
- 依赖隔离之线程&线程池
- 高延迟请求的例子
- 线程池的优势
- 线程池的弊端
-
- 线程池的开销
- 线程池开销
- 信号量
-
依赖隔离
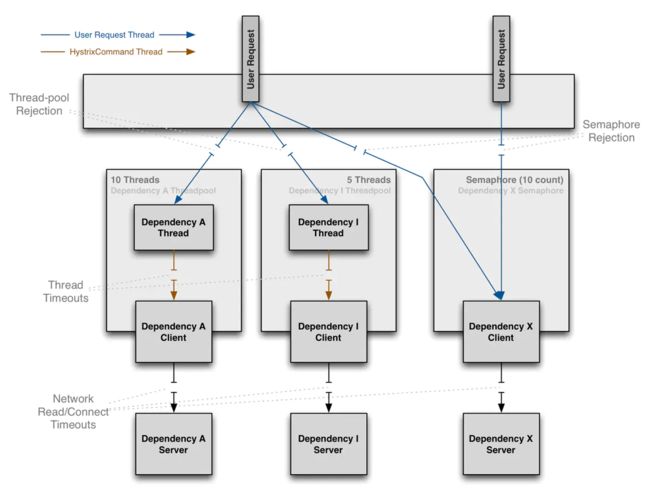
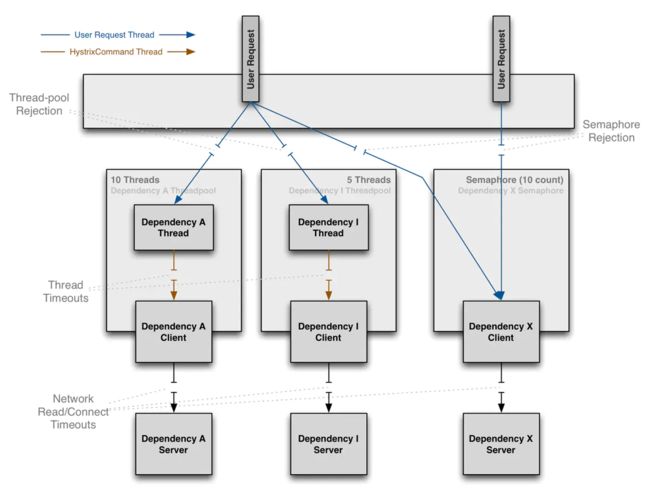
Hystrix通过使用『舱壁模式』(注:将船的底部划分成一个个的舱室,这样一个舱室进水不会导致整艘船沉没。将系统所有依赖服务隔离起来,一个依赖延迟升高或者失败,不会导致整个系统失败)来隔离依赖服务,并限制访问这些依赖服务的并发度。

依赖隔离之线程&线程池
通过将对依赖服务的访问执行放到单独的线程,将其与调用线程(例如 Tomcat 线程池中的线程)隔离开来,调用线程能空出来去做其他的工作而不至于被依赖服务的访问阻塞过长时间。
Hystrix使用独立的,每个依赖服务对应一个线程池的方式,来隔离这些依赖服务,这样,某个依赖服务的高延迟只会拖慢这个依赖服务对应的线程池。

高延迟请求的例子
当然,也可以不使用线程池来使你的系统免受依赖服务失效的影响,这需要你小心的设置网络连接/读取超时时间和重试配置,并保证这些配置能正确正常的运作,以使这些依赖服务在失效时,能快速返回错误。
Netflix在设计Hystrix时,使用线程/线程池来实现隔离,原因如下:
-
多数系统同时运行了(有时甚至多达数百个)不同的后端服务,这些服务由不同开发组开发。
-
每个服务都提供了自己的客户端库
-
客户端库经常会发生变动
-
客户端库可能会改变逻辑,加入新的网络请求
-
客户端库可能会包含重试逻辑,数据解析,缓存(本地缓存或分布式缓存),或者其他类似逻辑。
-
客户端库对于使用者来说,相当于『黑盒』,其实现细节,网络访问方式,默认配置等等均对使用者透明。
In several real-world production outages the determination was “oh,something changed and properties should be adjusted” or “the client library changed its behavior.”
-
即使客户端库本身未发生变化,服务自身发生变化,也可能会影响其性能,从而导致客户端配置不再可靠。
-
中间依赖服务可能包含一些其依赖服务提供的客户端库,而这些库可能不受控且配置不合理
-
绝大多数网络访问都采用同步的方式进行
-
客户端代码可能也会有失效或者高延迟,而不仅仅是在网络访问时
面对失效时 Hystrix 包装的请求拓扑图
线程池的优势
将依赖服务请求通过使用不同的线程池隔离,其优势如下:
-
(拒绝请求)系统完全与依赖服务请求隔离开来,即使依赖服务对应线程池耗尽,也不会影响系统其它请求
-
(资源隔离)降低了系统接入新的依赖服务的风险,若新的依赖服务存在问题,也不会影响系统其它请求
-
当依赖服务失效后又恢复正常,其对应的线程池会被清理干净,相对于整个 Tomcat容器的线程池被占满需要耗费更长时间以恢复可用来说,此时系统可以快速恢复。
-
若依赖服务的配置有问题,线程池能迅速反映出来(通过失败次数的增加,高延迟,超时,拒绝访问等等),同时,你可以在不影响系统现有功能的情况下,处理这些问题(通常通过热配置等方式)。
-
若依赖服务的实现发生变更,性能有了很大的变化(这种情况时常发生),需要进行配置调整(例如增加/减小超时阈值,调整重试策略等)时,也可以从线程池的监控信息上迅速反映出来(失败次数增加,高延迟,超时,拒绝访问等等),同时,你可以在不影响其他依赖服务,系统请求和用户的情况下,处理这些问题
线程池处理能起到隔离的作用以外,还能通过这种内置的并发特性,在客户端库同步网络IO上,建立一个异步的Facade(类似 Netflix API建立在 Hystrix 命令上的 Reactive、全异步化的那一套 Java API)
简而言之,通过线程池提供的依赖服务隔离,可以使得我们能在不停止服务的情况下,更加优雅地应对客户端库和子系统性能上的变化。
注:尽管线程池能提供隔离性,但你仍然需要对你的依赖服务客户端代码增加超时逻辑,并且/或者处理线程中断异常,以使这些代码不会无故地阻塞或者拖慢 Hystrix 线程池。
线程池的弊端
使用线程池的主要弊端是会增加系统 CPU 的负载,每个命令的执行,都包含了 CPU 任务的排队,调度,上下文切换。
Netflix在设计Hystrix 时,认为相对于其带来的好处,其带来的负载的一点点升高对系统的影响是微乎其微的。
线程池的开销
Hystrix的开发人员测试了在子线程中执行construct()或run()方法带来的额外时延,以及在父线程中整个请求的耗时,通过这个测试,你能直观了解 Hystrix 使用线程池带来的一点点系统负载的升高影响(线程,监控,日志,熔断器等)。
Netflix API 使用线程池来隔离依赖服务,每天可以处理超过 100 亿的 Hystrix 命令,每个 API 实例有超过 40 个线程池,每个线程池有 5 到 20 个工作线程(绝大部分设置为 10 个线程)。
下图展示了一个HystrixCommand以 60QPS 的速度,在一个 API 实例(每台服务器每秒运行的线程数峰值为 350)上被执行的耗时监控:

线程池开销
(注:有 User 的表示使用线程池来隔离依赖服务后的耗时)
中位数显示二者(未使用线程池和使用线程池)没有差别。
-
90%的情况下,使用线程池有3ms的延迟
-
99% 的情况下,使用线程池有9ms的延迟,尽管如此,相对于请求的总时间(2ms28ms),延迟(0ms9ms)基本可以忽略不计
90%的情况下,这些延迟和在使用了熔断器之后更高的延迟,在绝大多数 Netflix 的需求来看,是微不足道的,更何况其能带来系统稳定性和鲁棒性上的巨大提升。
对于那些本来延迟就比较小的请求(例如访问本地缓存成功率很高的请求)来说,线程池带来的开销是非常高的,这时,你可以考虑采用其他方法,例如非阻塞信号量(不支持超时),来实现依赖服务的隔离,使用信号量的开销很小。
但绝大多数情况下,Netflix 更偏向于使用线程池来隔离依赖服务,因为其带来的额外开销可以接受,并且能支持包括超时在内的所有功能。
信号量
除了线程池,队列之外,你可以使用信号量(或者叫计数器)来限制单个依赖服务的并发度。Hystrix 可以利用信号量,而不是线程池,来控制系统负载,但信号量不允许我们设置超时和异步化,如果你对客户端库有足够的信任(延迟不会过高),并且你只需要控制系统负载,那么你可以使用信号量。
HystrixCommand和HystrixObservableCommand在两个地方支持使用信号量:
- 失败回退逻辑:当 Hystrix 需要执行失败回退逻辑时,其在调用线程(Tomcat 线程)中使用信号量
执行命令时:如果设置了 Hystrix 命令的execution.isolation.strategy属性为SEMAPHORE,则 Hystrix 会使用信号量而不是线程池来控制调用线程调用依赖服务的并发度
你可以通过动态配置(即热部署)来决定信号量的大小,以控制并发线程的数量,信号量大小的估计和使用线程池进行并发度估计一样(仅访问内存数据的请求,一般能达到耗时在 1ms 以内,且能达到 5000rps,这样的请求对应的信号量可以设置为 1 或者 2。默认值为 10)。
注意:如果依赖服务使用信号量来进行隔离,当依赖服务出现高延迟,其调用线程也会被阻塞,直到依赖服务的网络请求超时。
信号量在达到上限时,会拒绝后续请求的访问,同时,设置信号量的线程也无法异步化(即像线程池那样,实现『提交-做其他工作-得到结果』模式)