【编者的话】本文系SDN实战团微信群(团主张宇峰@brocade)组织的首次线上技术分享整理而成,由IBM云网络服务团队资深架构师唐刚将其团队内部对于如何在openstack环境下实现高性能的网络服务而做的研究进行分享。
分享嘉宾
--------------------------------------------------------------------------------------------------

唐刚,IBM云网络服务团队资深架构师。曾参与IBM 5000V虚拟交换机和SDNVE(基于IBM DOVE - distributed overlay virtual Ethernet技术)产品的架构设计和实现。目前主要研究方向为通过使用DPDK架构在OpenStack中实现高性能的网络服务和网关。
-----------------------------------------------------------------------------------------------------
大家晚上好。那我们开始吧。主要还是抛装引玉,互相学习交流。今天和大家分享下面一些内容:
1.关于openstack中VNF网络性能的一些思考和思路
2.相关的开源项目
3.OVS 2.4 DPDK with IVSHMEM/vHost-user(w/DPDK) 和vHost (w/oDPDK)性能测试数据
4.后续可以一起来做的一些工作
第一部分 关于openstack中VNF网络性能的一些思考和思路
先来介绍一下背景,目前openstack社区版本的一些网络服务如routing,fip,snat,fw,,lb,数据平面都是linux network stack来实现的,linux network stack的性能其实不是很好,尤其是对小包的处理。
如果我们看pps的话,通常一个core可以支持0.2M~0.5M packet per second,而如果需要在10g网卡上实现64byte小包的线速转发,需要14.88Mpps的处理能力,所以这里还是有很大的提升空间。
像brocade的vrouter和其它的一些商业方案,据说已经可以支持10Mpps以上的处理能力。从vswitch的角度,OVS2.4已经增加了对DPDK tunnel和DPDK vhost的支持。虽然ovs在它的文档上有说明,这些还只是实验性质的,但我们认为这块的支持最终会走向成熟,我们再测试ovs dpdk的性能时,在两块物理网卡之间已经可以支持10Mpps的转发能力。如果ovs dpdk最终被采纳的话,那么openstack网络中的一些vnf将成为瓶颈。
所以我们研究的方向是如何在openstack环境下实现高性能的网络服务OpenStackOpenStack L3-agent, LBaaS, FWaaS, VPNaaS, etc。为了实现这个目标,有两部分主要的工作需要考虑:
- 其一,需要高性能的userspace network stack,并且可以使用dpdk来做完网络i/o接口;
- 其二,需要在openstack环境下实现相应的driver,包括创建userspace ovs,创建vnf实例,创建vnf到ovs的特殊的通道(vHost-user or IVSHMEM)。
第二部分 相关开源项目openstack和opnfv
openstack那个项目我们有尝试去使用,不过还没有成功。下面我们来看一下实现高性能网络服务需要考虑的一些因素(这几个图片其实是取自intel的一些文档):
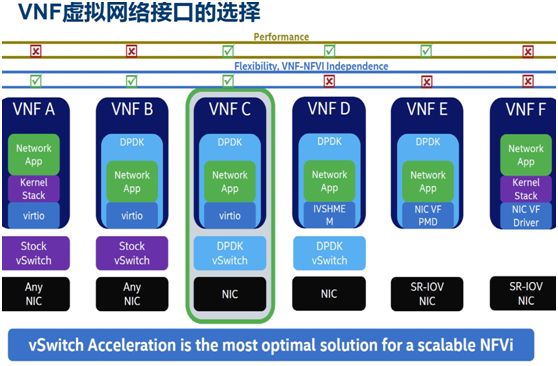

这里ovs-switchd是运行在用户态的进程,通过dpdk pmd直接从物理网卡抓取和发送报文,要实现高性能的vnf,需要:
- 高性能的ovs
- 高性能的vnf到ovs的通道
- 高性能的vnf 网络堆栈
关于高性能的网络堆栈,其实有一些选择,intel也给了一些推荐

当然这些项目在实际去用的时候还有许多坑,文档也不够,需要投入人力去尝试,intel这个链接有更详细的介绍:
https://software.intel.com/en-us/blogs/2015/06/12/user-space-networking-fuels-nfv-performance
我们尝试过rumpkernel,花了好些时间终于跑通了,但是性能还是没有达到预期,大概能到1Mpps,比linux好一点点,有可能是没有配置好的原因,后面会进行更多的尝试。关于用户态网络堆栈的介绍就到这。
第三部分 OVS 2.4 DPDK withIVSHMEM/vHost-user(w/DPDK)和vHost (w/oDPDK)性能测试
下面介绍一下ovs2.4的测试,后面我会把这个测试报告和大家分享,这个报告主要测试的是ovs连接虚拟网卡的性能。
连接物理网卡的性能比虚拟网卡来说还是好很多,使用10G物理网卡时,单向流量,128byte以上基本上可以达到线速,刚才的介绍有提到,vnf是通过虚拟网卡连接到ovs的,所以我们更关心虚拟网卡的性能。
1. Toolsused
•Packet Generators
a) Dpdk-Pktgenfor max pps measurements.
b) Netperfto measure bandwidth and latency.
•Test servers
a) CPU:2 sockets Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz, 10 cores per scoket.
b) RAM:64 Gbytes.
• NIC cards are Intel10-Gigabit X540-AT2.
• Kernel used is Linux3.13.0-53-generic .
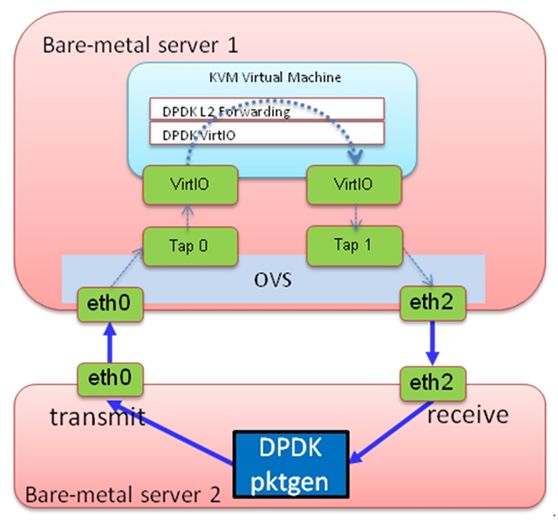
第一个实验是测试IVSHMEM的pps,我们使用dpdk-pktgen来产生报文,基本上可以打出线速的报文。虚拟机转发的程序使用ring client,在ovs的安装目录下有。
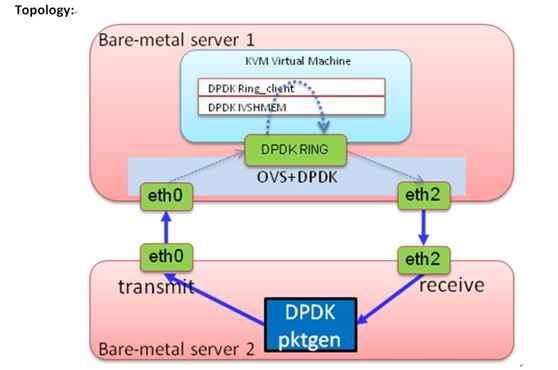
类似的拓扑用来测vhost user和vhost
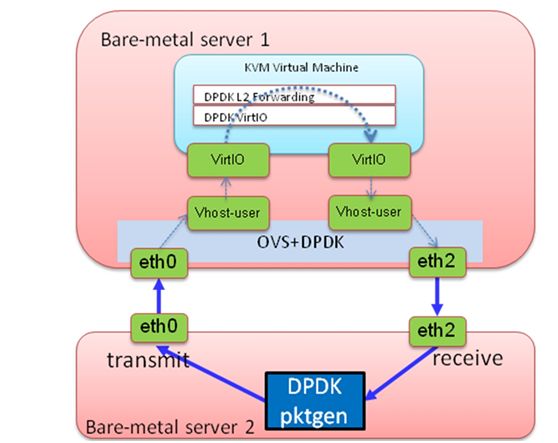
测vhost的时候用的是ovs 的kernel datapath
下面是用netperf测试性能的拓扑
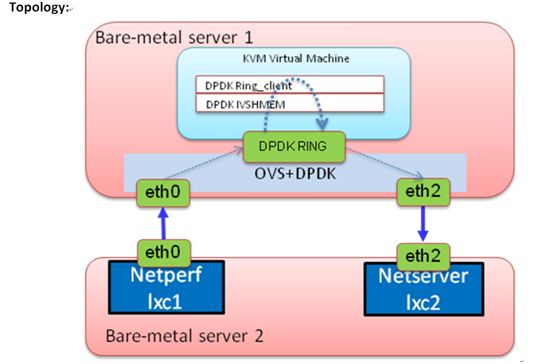
用netperf测试vhost-user和vhost的拓扑与上图类似,我就不在贴了,下面看一下最后的数据:
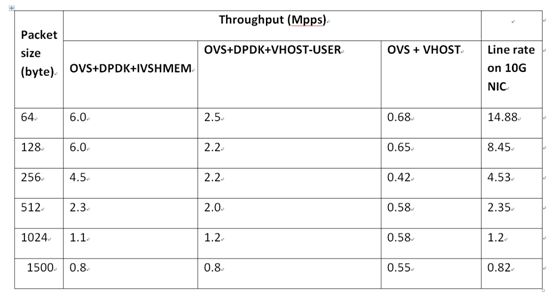
可以看到ovs+dpdk比ovs kernel datapath在小包的处理上优势还是很明显的。ivshmem性能更是强上一大截,如图:
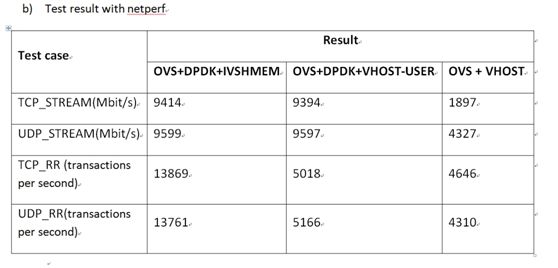
这个是netperf的,大家看到ovs+vhost只有不到2G,可能会认为和平时使用的感觉不一致,这主要是因为我们测试的vnf没有使用gro的原因。
第四部分 后续可以一起来做的一些工作
最后再介绍一下后续可以做的一些工作,有兴趣的同学可以私聊,一起来做一些研究:
1.测试ovs 2.4 dpdk vxlan的性能和ovs 2.4 user space patch interface的性能
2.研究用户态网络堆栈与dpdk的集成,比如Libuinet, mTCP, libusnet
3.在openstack环境下用新的neutron L2 driver来使用ovs+dpdk
其中第3个主要是去试用刚才说的两个开源项目,可参考如下链接:
https://github.com/stackforge/networking-ovs-dpdk
https://wiki.opnfv.org/open_vswitch_for_nfv
好,时间有点超过了,我的介绍就到这。大家有什么问题?
Q&A环节
-----------------------------------------------------------------------------------------------------
郭瑞景
Q1:Ovs 2.4快要release
A:ovs 2.4应该是8月24日就release了
HongLiang
Q2:正常大包的开销低。你这个测试小包性能高,有问题。
A:前面那个单位是pps,是报文的个数,大包到后面就已经到线速了,没法再高了
Q3:1500是0.8,64是6。那个大那个小?你这结果有问题,再好好测测
A1:64byte虽然是6mpps,但是只只是达到线速的6/14.88=43%,1500是0.8,但是已经是线速的0.8/0.82=97%。
A2:测试数据是pps 你换算成bps就直观了
A3:1500的包,在0.8pps的速率时已经接近线速了
wl
Q3:对于DPDK门外汉,问个问题如何可以降低学习成本或者比较好的学习路线
A:dpdk有一些example,可以去跑这些example;dpdk的包中包含example的source code;dpdk的文档也有介绍这些example如何使用,及example的代码介绍
郭瑞景
Q4:你的测试都在Openstack里做的么?其实我真正的问题是openstack 多少特性用了dpdk?
A1:测试没有在openstack的环境,目前社区版本的openstack还没有使用dpdk
猫叔
Q5:目前这些实现, 能挂仪表测性能吗? Smartbits or STC
A1:可以挂物理测试仪从物理网卡打包,但是因为我们测试的是虚拟网卡的性能所以用物理仪器打包并不是关键
风雨兼程-Kevin
Q6:你们的研究是用在nfv项目吗?对于neutron项目也适用吗?
A1:最终是做到集成到neutron中使用
Q7:userspace network stack 后续你们会重点做吗?
A1:yes
张宇峰@Brocade
Q8:听说Intel之前有 Neutreon OVS DPDK 优化的 open stack 版本,后来砍掉了往主线trunk版本里merge,你们会利用吗?
A1:我想你说的那个就是我刚才介绍的openstack当中那个项目。
zhang xin
Q9:你们做的事情能不能独立出来,所有stack都能用?网络归网络,理论上没必要跟openstack紧耦合啊
A1:是的,但目前在OpenStack的应用更迫切一些。
-----------------------------------------------------------------------------------------------------
SDN实战团微信群由Brocade中国区CTO张宇峰领衔组织创立,携手SDN Lab及海内外SDN/NFV/云计算产学研生态系统相关领域实战技术牛,每周都会组织定向的技术及业界动态分享,欢迎感兴趣的同学加微信:eigenswing,进群参与,您有想听的话题可以给我们留言。