【具身智能】论文系列解读-RL-ViGen & ArrayBot & USEEK
1. RL-ViGen:视觉泛化的强化学习基准
RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization
0 摘要与总结
视觉强化学习(Visual RL)与高维观察相结合,一直面临着分布外泛化的长期挑战。尽管重点关注旨在解决视觉泛化问题的算法,但我们认为现有的基准测试存在问题,因为它们仅限于孤立的任务和泛化类别,从而破坏了对智能体视觉泛化能力的综合评估。为了弥补这一差距,我们引入了 RL-ViGen:一种新颖的视觉泛化强化学习基准,它包含不同的任务和广泛的泛化类型,从而有助于得出更可靠的结论。此外,RL-ViGen 将最新的泛化视觉 RL 算法纳入统一的框架中,实验结果表明,没有任何一种现有算法能够跨任务通用。我们的愿望是 RL-ViGen 将成为该领域的催化剂,并为未来创建适合现实场景的通用视觉泛化 RL 代理奠定基础。 https://gemcollector.github.io/RL-ViGen/ 提供对我们的代码和实现算法的访问。
在4.2节中,如图 7 所示,所有算法的性能均未达到预期,这表明当前的视觉 RL 算法和泛化方法对场景结构变化的鲁棒性不够。必须进行更深入的研究,以增强经过训练的智能体感知不断变化的场景结构的泛化能力。
1 引言
视觉强化学习 (RL) 在众多领域取得了显着的成功 [33,36,14]。人们采用了多种技术,不仅可以解决试错学习过程,还可以解决高维输入数据带来的复杂性。
尽管取得了这些成功,视觉强化学习智能体面临的一个根本挑战仍然存在——实现泛化。
为了克服这个障碍,出现了几个视觉 RL 泛化基准,包括 Procgen [6]、Distracting Control Suite [40] 和 DMC-GB [18]。虽然这些基准对于视觉 RL 泛化进展是不可或缺的,但它们并不能免除对进一步发展构成挑战的固有限制。 Procgen 提供多样化的环境配置和视觉外观分布。然而,它仅限于具有非真实图像和低维离散动作空间的视频游戏,导致其环境与现实世界场景之间存在显着差距。另一个例子,DMC-GB,有时被视为许多最先进的视觉泛化算法的黄金标准。
**图 1:**用于视觉泛化的新颖 RL 基准。我们证明 RL-ViGen 支持具有不同泛化类别的广泛任务。可以更全面地评估算法并获得更有说服力的实验结果
然而,现有设置中任务类别和泛化类别范围狭窄,无法彻底、全面地评估智能体的泛化能力。此外,虽然Distracting Control Suite包含两种泛化类型,但它在多样性和复杂性方面存在不足。该领域的普遍趋势是展示所提出的算法在这些基准上的优越性,这不利地带来了促进对这些基准的过度拟合的一定风险,而不是发现可能有益于解决现实世界问题的算法。
在本文中,我们介绍了一种新颖的视觉泛化强化学习基准(RLViGen),与现有同行相比具有许多优点。我们的基准测试将一系列任务类别与真实图像输入相结合,包括桌面操纵、运动、自动驾驶、室内导航和灵巧的手部操纵,从而可以更全面地评估智能体的功效。此外,通过整合视觉 RL 泛化中的各个关键方面,例如视觉外观、光照变化、摄像机视图、场景结构和交叉实施例,RL-ViGen 能够全面检查智能体针对不同视觉条件的泛化能力。
值得注意的是,我们提供了一个统一的框架,其中包含各种最先进的视觉强化学习和泛化算法,每种方法都具有相同的优化方案。该框架不仅促进公平的基准比较,而且还降低了设计新颖方法的准入门槛。
总之,我们的贡献如下:
- 1)我们提出了一种新颖的视觉 RL 泛化基准 RL-ViGen,具有多样化、真实的渲染任务和众多泛化类型;
- 2)我们在统一的框架内实现和评估各种算法,从而能够全面分析其泛化性能;
- 3)我们进行了全面而广泛的实验,以证明现有方法在处理不同任务和泛化类型时的独特性能,并强调当前可泛化视觉强化学习算法的优点和局限性。综合所有贡献,RL-ViGen 可能为视觉 RL 泛化的进一步进步铺平道路,最终为现实世界的应用带来更强大、适应性更强的算法。
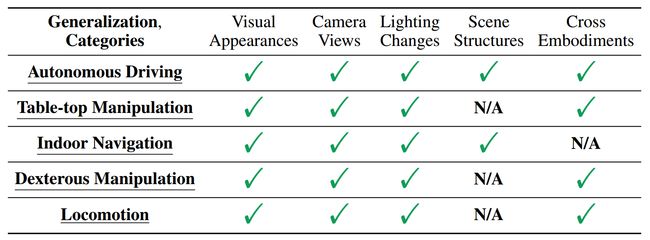
表 1:概括类别。
下表概述了每个任务中包含的泛化类型。除了被认为不适用 (N/A) 的类别(例如,对于运动,不需要场景结构的变化)之外,所有潜在类型都包括在内。
2 RL-ViGen 框架
RL-ViGen 包含 5 个不同的任务类别,涵盖运动、桌面操纵、自动驾驶、室内导航和灵巧手操纵领域。与之前的基准相比,RL-ViGen 采用多种任务类别来评估智能体的泛化性能。我们相信,只有通过多角度综合检验,才能得出令人信服的结果。此外,如表1所示,我们的基准测试提供了广泛的泛化类别,包括视觉外观、摄像机视图、照明条件的变化、场景结构和跨实施例设置,从而提供了对算法的鲁棒性和泛化能力的全面评估。
2.1 实验环境
**灵巧的操作:**Adroit [37] 是一个复杂的环境,专门为灵巧的手操作任务而定制。由于环境的稀疏奖励性质和高维动作空间的复杂性,它需要大量的探索和细粒度的特征捕获。在 RL-ViGen 中,我们通过集成不同的视觉外观、相机视角、手型、光照变化和物体形状来丰富 Adroit 环境。
**自动驾驶:**CARLA [9]作为自动驾驶的真实高保真模拟器,研究动态条件下智能体的控制能力。在之前的研究中,它已成功部署在视觉强化学习设置上。与之前的工作[21]相反,RLViGen 在不同的场景结构中提供了更广泛的动态天气和更复杂的路况。此外,RL-ViGen 中还包含灵活的相机角度调整功能。
**室内导航:**作为一种高效且逼真的 3D 模拟器,Habitat [39] 结合了众多视觉导航任务。成功完成这些任务需要智能体拥有场景理解的能力。 RL-ViGen 以 skokloster 城堡场景为基础,并提出了具有不同视觉和照明设置的附加场景。此外,摄像机视图和场景结构被设计为可调节的。
**桌面操控:**Robosuite [57] 是一个旨在支持机器人学习的模块化仿真平台。它本质上包含旨在调整各种场景参数的界面。最近的工作[12]利用这个平台来测试智能体对视觉背景变化的泛化能力。 RL-ViGen 进一步结合了动态背景、自适应照明条件和实施例变化选项,改进了模拟,使其更接近现实世界。
Locomotion:DeepMind Control 是一种流行的连续视觉 RL 基准测试。 DMC-GB[19]是在其上开发的,并已成为广泛使用的评估泛化算法的基准。RL-ViGen 以 DMC-GB 为基础,引入了来自复杂的现实世界运动和操纵应用程序的对象和相应任务,例如 Unitree、Anymal 四足机器人和 Franka Arm。更重要的是,RL-ViGen 还提供了各种泛化类别来进一步丰富这个环境。
更详细的实现和修改可以在附录 B 和我们的代码库中找到。

**图 2:**泛化过程。智能体首先在第一阶段使用特定的固定场景进行训练。随后,在第二阶段,以零样本的方式在各种视觉泛化场景中测试代理。智能体在第 2 阶段的各个场景中表现越好,其表现出的泛化能力就越强。
2.2 类别概括
在这里,我们强调 RL-ViGen 中使用的主要泛化类别: 视觉外观:在物体、场景或环境的视觉特征发生变化的情况下保持有效的性能至关重要,特别是对于视觉强化学习而言。
在我们的基准测试中,环境中的不同组件可以使用多种颜色进行修改。同时,还引入了动态视频背景作为具有挑战性的设置。
**摄像机视图:**在现实世界中,智能体必须应对可能与训练期间所经历的不一致的摄像机配置、角度或位置。我们提供将摄像机设置为不同角度、距离和视场的权限。此外,摄像机的数量也可以相应调整。
**照明条件:**现实世界中不可避免地会发生照明条件的变化。为了使代理能够适应这种变化,我们的基准测试提供了与照明相关的接口,例如不同的光强度、颜色和动态阴影变化。
**场景结构:**掌握理解和适应不同场景中不同空间安排和组织模式的能力对于真正可泛化的智能体至关重要。为此,我们的基准测试可以通过调整地图、图案或引入额外的对象来修改场景结构。
**跨实施例:**使学习到的技能和知识适应不同的物理形态或实施例对于代理在具有不同运动结构和传感器配置的各种平台或机器人上表现良好至关重要。因此,我们的基准还提供了在模型类型、大小和其他物理属性方面修改经过训练的代理的体现的途径。
3. 视觉强化学习中泛化的算法基线
3.1 统一框架
我们工作的另一个重要贡献是实现了统一的代码库来支持各种视觉 RL 算法之间的比较。在之前的研究中,不同的算法采用不同的优化方案、RL 基线和超参数。例如,SRM [22] 和 SVEA [20] 依赖于基于 SAC 的 RL 算法,而 PIE-G [54] 采用基于 DDPG 的方法。此外,微小的不同实现都可能会对最终性能产生重大影响。因此,提供一个统一的框架在这个领域非常重要,可以通过一致的框架和不同的任务评估算法得出更有说服力的结论。
3.2 视觉强化学习算法
在我们的基准测试中,我们组装了八种领先的视觉强化学习算法,并应用相同的统一训练和评估框架。 DrQ-v2 [50] 就样本效率而言是现有最先进的基于 DDPG 的无模型视觉 RL 算法。 DrQ [27] 是另一种基于 SAC 的样本高效视觉 RL 算法,它是 DrQ-v2 的基础。 CURL [28] 利用 SimCLR 式 [5] 对比损失来获得更好的视觉表示。 VRL3 [43] 是具有人类演示的 Adroit 任务中最先进的算法。其他四种算法专注于实现稳健的表示。
SVEA[20]采用未增强图像的Q值作为目标,同时利用数据增强来减少Q方差; SRM[22]采用频域增强来选择性消除部分观测频率; PIE-G[54]结合ImageNet[8]预训练模型进一步提升泛化能力; SGQN [3] 通过与显着图集成来识别决策的关键像素。
4. 实验
在本节中,我们尝试研究所提出的 RL-ViGen 基准中不同方法的泛化能力。如图 2 所示,所有智能体都在相同的固定训练环境中进行训练,并以零样本的方式在各种未见过的场景中进行评估。训练样本效率和渐近性能如附录E.4所示。对于每项任务,我们评估超过 5 个随机种子并报告平均分数和 95% 置信区间。对于每个训练环境,我们给出了多个子任务的汇总分数。详细而广泛的实验结果可以在附录 B 和 E 中找到。每个环境和泛化类型的可视化如附录 D.1 所示。
4.1 视觉外观和灯光变化
4.1.1 室内导航
在 Habitat 平台中,我们选择 ImageNav 任务并修改 3D 扫描模型,以引入具有各种视觉外观和照明条件的新颖场景。我们对 10 个选定场景中的每一个进行 10 次评估(总共 100 次试验)。与大多数现有基准相比,Habitat 渲染的图像是由高性能 3D 模拟器从第一人称视角捕获的。因此,它可以提供更类似于现实世界场景的可视化效果。如图3所示,PIE-G的优越性能归功于与ImageNet预训练模型的集成,为PIE-G配备了丰富的真实图像,使其能够更有效地处理这些场景。相反,与第 4.1.2 节得出的结论一致,SGQN 旨在通过消除冗余背景来分割中心代理,但在这些对象丰富和第一人称视图任务中被证明是无效的。
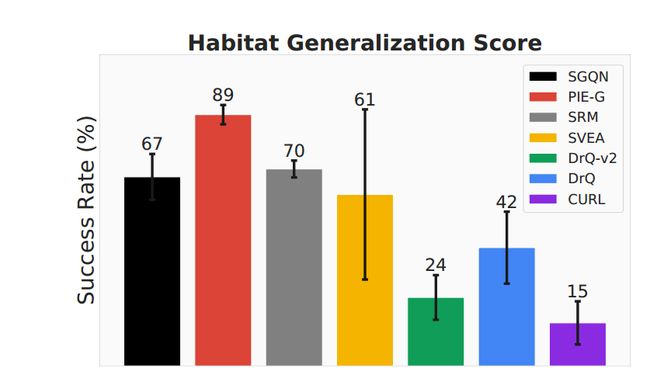
**图 3:室内导航的泛化得分。**我们展示了每种方法的成功率。结果表明PIE-G在Habitat上取得了更好的泛化性能。
4.1.2 自动驾驶
关于CARLA,我们采用Zhang等人[55]中的奖励函数设置,并应用第一人称视角来更好地模拟真实世界的驾驶条件。如附录D.1中的图11所示,该环境分为三个级别:简单、中等和困难。主要修改涉及不同因素,例如降雨强度、道路湿度和照明。训练场景的差异越大,难度就越大。在这项任务中,其独特之处之一是特点是输入图像频率发生相当大的变化。因此,在频域中应用数据增强的 SRM 方法表现出最佳性能,因为它可以适应不同频率的输入图像。虽然PIE-G采用了ImageNet预训练模型,但其源训练图像主要具有高频特征,因此在面对低频场景(例如黑夜)时泛化效果不佳。此外,提取显着信息的 SGQN 在面对视觉丰富的场景(其中受控代理不存在于观察帧中)时表现出性能下降。还应该指出的是,DrQ 在这种环境中获得了一定程度的泛化能力。我们的观察表明,由于 DrQ 是一种基于 SAC 的算法,因此它往往容易发生熵崩溃 [50]。这意味着经过训练的智能体仅针对不同的图像输入产生单一的动作分布。
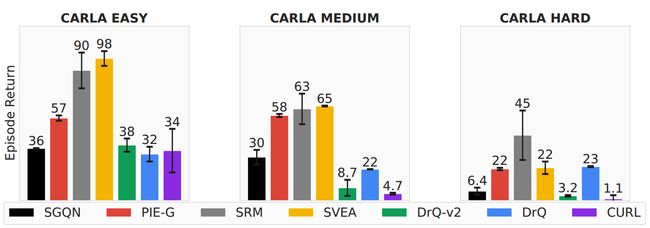
**图 4:**自动驾驶的综合泛化得分。我们展示了每种方法的汇总回报。 SRM表现出更好的性能,可以适应图像频率变化较大的场景。
4.1.3 灵巧的手部操作
在 Adroit 环境中,我们评估了每种方法在三个单视图任务中的性能:门、锤子和笔。由于 DrQ-v2 和 DrQ 在这些具有挑战性的环境中几乎没有表现良好,因此我们利用 VRL3 [43],这是该领域最先进的方法,因为 RL-ViGen 中的基本算法和视觉 RL 方法是重新设计的。并以此为基础实施。
关于样本效率,人们普遍认为应用强增强会对样本效率产生负面影响。然而,如附录 E.4 中的图 5 所示,值得注意的是,由于 VRL3 专门设计了一种安全 Q 机制来防止该环境中潜在的 Q 发散,因此应用强增强的泛化算法可以实现与仅使用随机的泛化算法相当的性能转移。
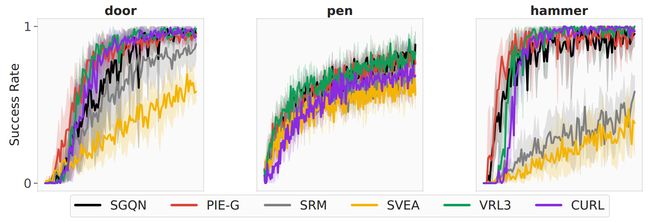
**图 5:**Adroit 的样本效率。每种算法的成功率。我们将训练步骤标准化为 (0, 1)。具有强增强能力的方法也可以获得可比的性能。

**图 6:**灵巧操作的综合泛化得分。我们展示了每种方法的总体成功率。配备 ImageNet 预训练模型的 PIE-G 对需要细粒度信息捕获的 Adroit 任务表现出更好的适应性。
至于泛化,Adroit 任务要求智能体识别细粒度的特征,以进行灵巧而复杂的操作。因此,PIE-G 利用 ImageNet 预训练模型来捕获详细信息,展示了协助学习代理执行下游任务的有效性,特别是在困难环境中。此外,如图 6 所示,由于缺乏减轻视觉变化影响的额外目标,导致 VRL3 和 CURL 在这些要求较高的任务中难以适应新的视觉情况。
4.2 场景结构
能够在不同场景结构中提供强大性能的通用代理对于潜在的广泛现实应用至关重要。我们选择 CARLA 作为评估场景结构泛化能力的测试平台。这些代理在标准训练场景(高速公路)中进行训练,并在更复杂的结构设置中进行测试,包括狭窄的道路、隧道和 HardRainSunset 天气条件下的环形交叉口。如图 7 所示,所有算法的性能均未达到预期,这表明当前的视觉 RL 算法和泛化方法对场景结构变化的鲁棒性不够。必须进行更深入的研究,以增强经过训练的智能体感知不断变化的场景结构的泛化能力。

图 7:场景结构的泛化得分。在这一类泛化中,所有算法的性能都不尽如人意。
4.3 相机视图
我们继续评估 Adroit 环境中相机视图的泛化能力。如图 8 所示,在 Easy 设置下,PIEG 和 SGQN 在摄像机视图方面表现出领先的泛化能力,而其他算法由于使用随机移位增强也表现出一定程度的泛化能力。然而,在硬设置中,相机位置、方向和视场 (FOV) 发生了重大变化,除了 SGQN 之外,几乎所有算法都失去了泛化能力。 SGQN 的卓越性能主要是由于其严重依赖于生成显着图,从而增强了智能体的对物体几何形状和相对位置的自我意识。因此,即使面对相机视图发生重大变化,该属性也能增强其泛化性能。
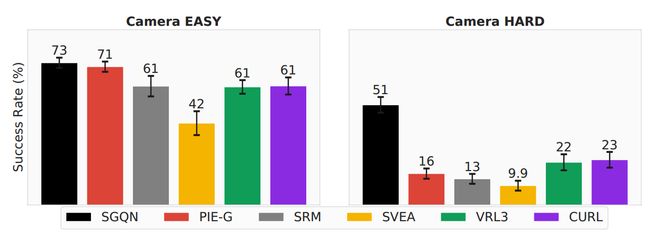
**图 8:**相机视图的泛化得分。 SGQN 表明相机视图泛化中不同级别的优势泛化能力。
4.4 交叉实施例
解决视觉输入中的实施例不匹配问题至关重要,因为实施例构成了图像的很大一部分,并显着影响机器人与世界交互的行为。为了研究这种类型的泛化,采用 Robosuite 作为评估平台。我们在训练期间利用 OSC_POSE 控制器 [35] 来促进动作空间维度及其各自含义的维护。然后,训练有素的智能体从 Panda Arm 转移到两种不同的形态:KUKA IIWA 和 Kinova3。如图 9 所示,所有算法的整体性能都不是最优的;然而,基于泛化的方法在训练期间包含更多样化的信息,与主要关注跨实施例设置中的样本效率的方法相比,表现出轻微的优势。
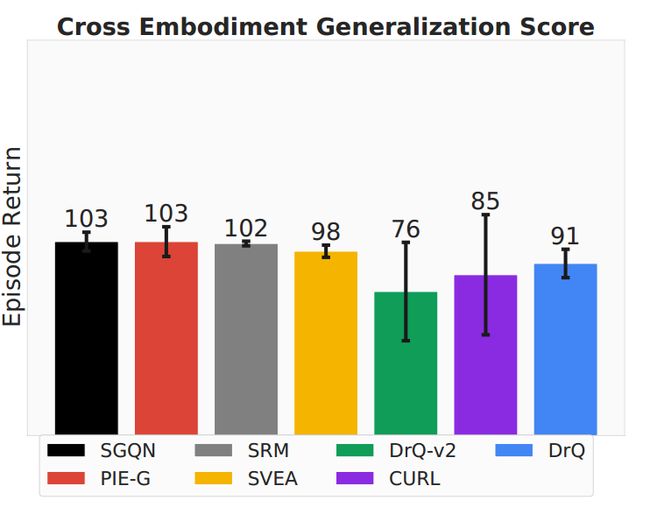
**图 9:**交叉实施例的聚合泛化得分。目前还没有算法展示出管理跨实施例泛化的能力。
5 讨论
综上所述,我们的实验表明,基于先前基准的研究结果可能无法准确反映实际进展,从而导致对情况的认知扭曲;这些先进的视觉 RL 算法以前被认为是最前沿的,但在 RL-ViGen 中显示出较低的效率。
我们将主要内容总结如下:
要点 1: 实验结果揭示了不同视觉 RL 算法在不同任务和泛化类别中的不同泛化性能,没有单一算法表现出普遍强大的泛化能力。
结论 2:仅仅提高训练性能并不能保证泛化能力的提高。尽管DrQ(v2)和CURL在训练过程中表现出较高的样本效率,甚至实现了更好的渐近性能(附录E.4),但它们在各种泛化场景中的表现尚未达到令人满意的水平。因此,当试图提高智能体的泛化能力时,引入额外的归纳偏差来帮助训练过程至关重要。
要点 3:有效的可泛化视觉 RL 代理必须在多个泛化类别中表现出卓越的性能。之前的工作主要集中在视觉外观的泛化上,而我们的实验揭示了现有算法在交叉实施例和场景结构设置中的相当大的缺点。这些表现不佳的泛化类别不仅仅改变了马尔可夫决策过程(MDP)中的观察空间;它们还对动作空间和转换概率进行修改,从而给智能体带来额外的挑战。
要点 4: 每种泛化算法都有其独特的优势。值得注意的是,PIE-G 在视觉外观和照明条件变化方面表现出卓越的性能,而 SRM 在显着的图像频率变化下表现出卓越的鲁棒性。当面临相当大的摄像机视图变化时,SGQN 保留其泛化能力。此外,SVEA不需要额外的参数,只需要很少的修改,就可以达到一定水平的泛化能力。我们假设通过融合不同的算法可能会获得更强的性能,例如利用带有基于频率的增强的预训练模型来进一步改进。
结合要点,我们希望算法在 RL-ViGen 中的成功能够表明其在更复杂和不可预测的现实场景中的潜在适用性。未来,涵盖场景结构、摄像机视图和交叉实施例等方面的整体和多维方法对于培养能够在各种动态现实环境中导航的真正通用代理至关重要。同样,设计更复杂、更现实的训练环境,能够反映现实世界条件的复杂性,也可以作为未来探索的关键领域。
2. ArrayBot:通过触摸进行泛化分布式操作的强化学习
0. 摘要与总结
我们提出了 ArrayBot,这是一种分布式操纵系统,由集成了触觉传感器的 16×16 垂直滑动柱阵列组成,可以同时支撑、感知和操纵桌面物体。为了实现可推广的分布式操作,我们利用强化学习(RL)算法来自动发现控制策略。面对大量冗余动作,我们建议通过考虑空间局部动作块和频域中的低频动作来重塑动作空间。通过这个重塑的动作空间,我们训练强化学习智能体,使其仅通过触觉观察即可重新定位不同的物体。令人惊讶的是,我们发现所发现的策略不仅可以推广到模拟器中看不见的物体形状,而且可以在没有任何域随机化的情况下转移到物理机器人。利用已部署的策略,我们展示了丰富的现实世界操作任务,展示了 ArrayBot 上的强化学习在分布式操作方面的巨大潜力。
**关键词:**分布式操纵、强化学习、触觉感知
**图1:**我们设计和制造分布式操作系统ArrayBot的硬件。为了实现可推广的分布式操作,我们在模拟 ArrayBot 上训练强化学习 (RL) 代理,其中唯一可访问的观察是触觉信息。我们将控制策略部署到物理机器人上,并展示现实世界操纵任务的轨迹鸟瞰图:重新定位新颖形状的物体、并行操纵、轨迹跟踪以及在严重视觉干扰下操纵透明物体。
1. 引言
机器人操纵的概念 [1, 2] 很容易调用仿生机器人手臂或手的图像,试图抓住桌面物体,然后将它们重新排列成由 RGBD 相机等外部感受传感器推断出的所需配置。为了促进这种操作流程,机器人学习社区在如何在要求较高的场景中确定更稳定的抓取姿势[3,4,5,6,7]或如何以更稳健和更通用的方式理解外感受输入方面做出了巨大的努力[8、9、10、11、12、13]。认识到这些进展,本文试图通过倡导 ArrayBot 来绕过当前管道中的挑战,ArrayBot 是一种用于分布式操纵的强化学习驱动系统 [14],其中对象通过大量仅具有本体触觉感知的执行器进行操纵 [15, 16、17、18]。
从概念上讲,ArrayBot 的硬件是一个 16×16 的垂直滑动柱子阵列,每个柱子都可以独立驱动,从而形成 16×16 的动作空间。从功能上讲,桌面物体下方的执行器可以支撑其重量,同时通过适当的**运动策略配合提升、倾斜甚至平移它。**为了给 ArrayBot 配备本体感觉传感功能,我们将每个执行器与纤薄且低成本的力敏电阻 (FSR) 传感器集成,使机器人能够在缺乏外部视觉输入时“感觉”物体。由于其分布式特性,ArrayBot 的尺寸非常灵活,本质上支持并行操作,并且有可能操作比其末端执行器尺寸大几倍的对象。
以前的分布式操纵作品以执行器阵列[19,20,21,22]、智能表面[23,24]或有形用户界面的辅助功能[25,26,27]的名称出现。尽管它们承诺操纵桌面对象,但它们严重依赖于预定义的运动基元来适应执行器的特定设计,并且只能以预编程的方式操纵固定类型的对象,这阻碍了它们在实际应用中的实用性。为了使分布式操作具有更好的通用性和多功能性,我们探索了将无模型强化学习(RL)[28,29,30]应用于控制策略自动发现的可行性。然而,与手臂或手等流行的操纵器相比,在 2D 阵列动作空间中控制 ArrayBot 可能极具挑战性,因为动作的大量冗余使得试错过程的效率极其低下。
意识到其冗余性,我们建议重塑动作空间,目的是加强其归纳偏差,以实现对分布式操纵更有利的动作。首先,我们明确地将有效动作空间的扩展限制为以对象为中心的局部动作块,因为远处的执行器几乎无法施加任何物理效果。同时,我们提出了通过二维离散余弦变换(DCT)考虑频域动作的想法[31]。其基本原理是,对于分布式操纵,集体行为的影响比个体碰撞更稳定和可预测[32, 33]。由于频域中的每个通道处理空间全局视野,因此频域中的动作空间可能隐含着对协作的偏向。在频率变换之上,我们进一步对动作通道执行高频截断,这受到图像压缩方法(例如 JPEG [34])丢弃高频模式的启发。同样,我们认为同样的偏好也适用于 2D 阵列动作空间,因为较低频率的动作可能会产生具有语义的紧急运动基元,例如,DC 通道意味着提升,基频意味着倾斜。相比之下,由高频通道确定的详细纹理信息对操作任务影响很小。
通过重塑动作空间,我们首先通过在 Isaac Gym 模拟器 [35] 中设置 ArrayBot 环境,然后训练 RL 代理 [30],证明 ArrayBot 上的无模型 RL 发现的策略与预定义原语一样强大。分别举起和翻转一个立方体。除了运动基元的范围之外,我们还展示了 RL 学习到的 ArrayBot 的一项单一策略,该策略与对象形状和视觉观察无关,但可以仅通过触摸感应将数百个以前未见过的各种形状的对象从任意位置重新定位到任意位置。令人惊讶的是,我们发现可以将模拟器中训练的策略直接部署到现实世界的机器上,而无需任何模拟到真实的传输技术,包括域随机化[36]。
利用部署到现实世界的一般通过触摸重新定位策略,我们展示了 ArrayBot 的一些更具体的应用,展示了它操纵不同形状的对象并根据指定轨迹驱动对象的能力,以及它对急剧变化的环境外观和透明对象的鲁棒性,最后是并行操纵的潜力。我们还针对非常静态但更复杂的任务提出了一些硬编码策略,以展示我们硬件的巨大潜力。视觉效果请参考项目网站。
我们的贡献概括为:
(i)我们设计和制造了可以同时支持、感知和操纵物体的ArrayBot硬件;
(ii)我们提出了 ArrayBot 的动作空间重塑方法,通过分布式操纵系统上的无模型强化学习来验证自动策略发现;
(iii)我们在模拟器中训练一种适合各种形状的触摸重定位策略,该策略可以立即部署到现实世界中;
(iv)我们提供了由 RL 衍生策略支持的具体应用程序,以更好地说明 ArrayBot 的优势。
2. 分布式操作的动作空间重塑
使用强化学习进行分布式操作的主要挑战来自其具有大量冗余的非常规动作空间。在本节中,我们提出了一系列技术来重塑 ArrayBot 的动作空间,使其更适合分布式操作。
本地操作补丁。 ArrayBot的动作空间是16×16数组的形状。考虑到远离物体的执行器不会对操纵产生任何影响,我们只考虑以物体为中心的 5 × 5 局部动作补丁(LAP)。到目前为止,一个未触及的细节是如何确定局部补丁的中心。如果假设物体的真实位置在模拟器中是可访问的,我们只需选择最接近物体中心的执行器作为 LAP 的中心。然而,现实场景中的观察空间不包括这种特权状态信息。在ArrayBot中,我们通过触摸来估计物体位置。更具体地说,我们对 16×16 FSR 传感器阵列的噪声读数进行后处理,给出指示接触条件的二进制触觉图。然后,计算接触点的平均值作为被操纵物体的估计中心位置。
频域中的动作。我们没有考虑在接触丰富的环境中每个个体接触的影响,这实际上是无法解决的[32, 33],而是考虑集体行为对分布式操纵的影响[26, 21, 22]。我们建议学习频域中的动作,其中每个组件可能在空间域中产生全局影响。因此,策略网络不是直接预测平坦的 25 维位置方差,而是输出 25 维频率方差。随后,25 维输出被展平为 5×5 的形状,然后通过 2D 逆离散余弦变换(iDCT)[31] 算子进行后处理,以在空间域中产生最终的 5×5 动作。
高频截断。除了对协作的潜在归纳偏见之外,频域还提供了重新检查操作冗余的宝贵观点。直观上,低频通道会产生光滑的平面,其语义可能与新出现的运动基元相对应。基于这些观察,我们建议截断动作的高频通道。策略网络现在被设计为输出 6 维预测,该预测用于填充频域中整个预测动作的 6 个最低频率通道。为了获得准备好进行逆频率变换的完整 25 维动作,我们只需对其余 19 个较高频率的通道进行零填充。
**图 2:**我们考虑 5 × 5 2D DCT 图上以绿色标记的 6 个最低频率通道。
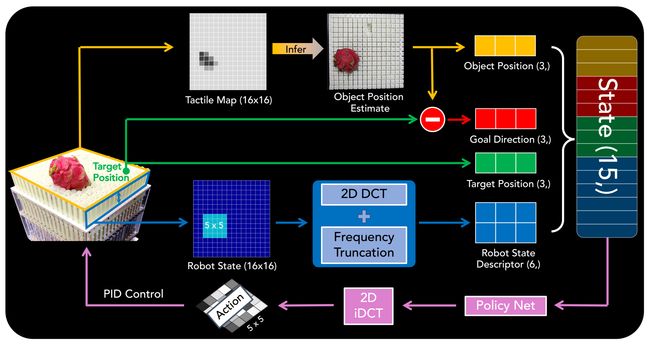
**图 3:**ArrayBot 上用于一般重定位的 RL 框架概述。状态是估计的物体位置、指定的目标位置、剩余目标方向和频域中的机器人状态的组合。无需任何视觉输入,状态是通过对机器人关节配置和触觉传感器阵列的纯粹本体感觉观察来推断的。
3 重塑行动空间中的学习控制策略
3.1 系统设置
**硬件。**我们设计并制造了 ArrayBot 的硬件,它可以被视为一个 16 × 16 的垂直滑动单元阵列。每个单元从下到上由驱动单元垂直方向移动的电机、每个尺寸长度分别为 16 × 16 × 200 mm 的矩形柱、纤薄且低成本的力敏电阻 (FSR) 组成。测量垂直压力的传感器,以及保护触觉传感器并增加摩擦力的硅胶半球末端执行器。每个垂直棱柱关节的有效范围为55毫米,最大运动速度为53毫米/秒。 ArrayBot 通过位置 PID 控制执行操作。
**模拟器。**接触丰富的交互的物理模拟可能非常耗时。为了以有效的方式产生足够的样本,以便为需要数据的强化学习算法提供数据,我们在 Isaac Gym [35] 模拟器中构建了 ArrayBot 的模拟环境。物理模拟步骤的频率为 50 Hz。由于机械速度限制,我们将RL控制的频率设置为5 Hz。由于强化学习算法考虑了触觉传感器的二值化结果,因此我们从模拟器的接触缓冲区中检索信息作为触觉传感器的模拟。
3.2 环境
我们考虑三种操作任务:提升、翻转和一般重新定位。在举起过程中,我们要求 ArrayBot 将立方体举起尽可能高。在翻转中,我们要求 ArrayBot 将同一个块沿某个轴翻转 90 度。在一般的重新定位中,我们要求 ArrayBot 仅通过触觉感知将各种形状的物体重新定位到其范围内的任意位置。
**状态。**提升和翻转的任务直接利用模拟器提供的特权位置和方向信息。在一般的搬迁中,我们考虑一个更现实的场景,其中唯一的观察是二值化的触觉信息。一般搬迁的估计状态如图 3 所示。更多详细信息请参阅附录 B 中的表 1。
**奖励。**提升和翻转的任务分别简单地考虑物体高度和方向的密集奖励。在一般的迁移中,除了对象位置的密集奖励之外,我们在达到目标时再添加一项稀疏奖励,以鼓励机器人及时将物体停在目标位置。更多详细信息请参见附录 B 中的表 2。
**行动。**在每一步,策略都会在频域中输出一个 6 维动作,该动作经过后处理以在 5 × 5 LAP 上生成相对联合配置。
**重置。**如果桌面对象移出边界或剧集长度达到 100 步,我们会重置剧集。由于 5 × 5 LAP 的存在,我们要求对象的中心应位于中央 11 × 11 块上。
**被操纵的物体。**在提升和翻转过程中,我们操纵一个 8×8×8 cm 的立方体块,它可以由 4 × 4 的执行器阵列大致支撑。在一般的重定位中,我们通过从 EGAD [37] 训练集中采样 128 个不同的形状,然后重新缩放它们来训练可推广到形状方差的 RL 代理。在测试时,我们评估了可泛化代理在 EGAD 测试集上总共 49 个未见过的物体形状的性能。为了在模拟器中快速准确地进行碰撞检测,我们对所有对象形状执行 V-HACD [38] 凸分解。
3.3 训练 RL 代理
对于所有任务,我们在 128 个并行 Isaac Gym 环境上训练近端策略优化(PPO)[30]代理,以自动发现控制策略。强化学习训练的更多细节可以在附录 B 中找到。值得注意的是,所有 128 个用于一般重定位的并行环境都涉及相互不同的对象形状。由于状态空间与对象形状完全无关,代理会接收混合类型的动态。这迫使代理发现对数据集中的所有形状尽可能通用的策略,从而增强其对形状方差的泛化能力。
3.4 提升和翻转指标的实验
指标。在提升和翻转中,我们比较每集的平均累积收益和生存步骤。生存步数是指物体能够留在机器人上而不掉落的步数。生存步数最多为 100。
**比较方法。**为了研究重塑动作空间的必要性,我们在以下动作空间中训练相同的 PPO 算法:
(i)仅在空间域中进行 LAP;
(ii)LAP+DCT-25,保留频域中的所有 25 个通道;
(iii)LAP+DCT-6,仅考虑 6 个最低频率信道。
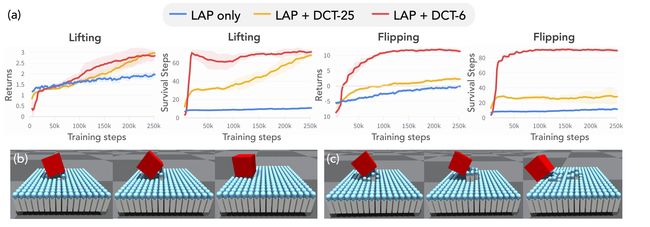
图 4:(a) 情节回报和生存步骤的训练曲线。结果取 5 颗种子的平均值。阴影区域代表标准差。 (b)© (b) LAP+DCT-6 和 © 仅用于翻转的 LAP 学习的策略示例轨迹。
**结果。**两个任务的学习曲线如图 4(a)所示。在这两项任务中,基于 DCT 的方法在总回报和生存步骤方面都比在空间动作空间中训练的方法具有显着优势。此外,DCT-6 方法比 DCT-25 存活时间更长且表现更好,尤其是在更具挑战性的翻转任务中,这与低频模式导致更稳定动作的直觉相呼应。通过可视化图 4(b)© 中的翻转轨迹,我们发现 LAP 只会侵入环境,并学会通过以滚动的方式将障碍物从机器人上扔下来来获得奖励。相比之下,LAP+DCT-6的动作更加温和合理,这也解释了其更好的性能和更长的生存时间。
3.5 一般重定位指标的实验。
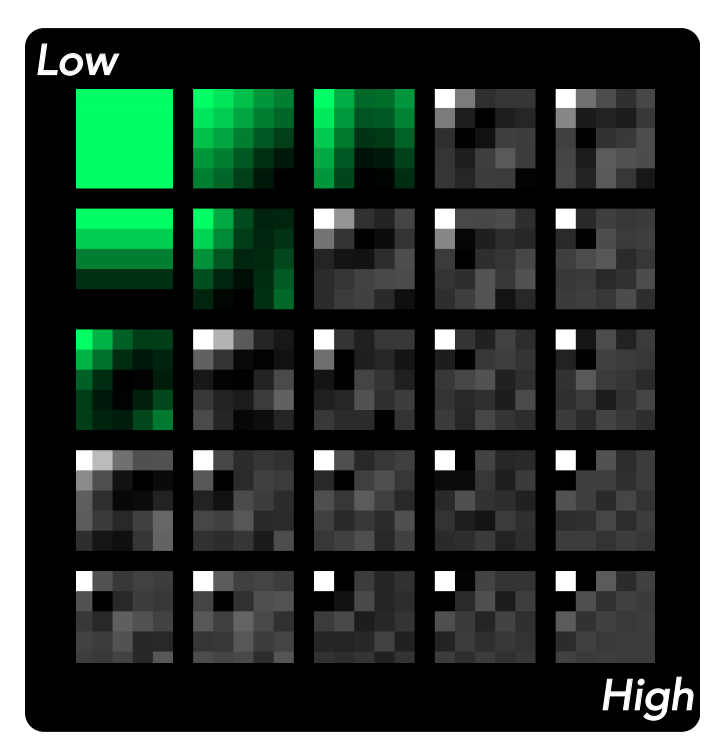
指标。我们报告了包含 49 个看不见的物体的 EGAD [37] 测试集上的重定位成功率。如果物体到达目标位置并坚持至少 1 秒,则判定一次情节成功。结果是 200 条具有随机初始位置和目标位置的轨迹的平均值。
**结果。**右图所示的成功率遵循 EGAD 中的相同分类法,其中物体的抓取难度和形状复杂性按字母和数字顺序排序。我们观察到,即使形状复杂度很高,ArrayBot 也能在大多数低难度物体上取得相对较高的成功率。考虑到在训练时没有向 RL 代理显示任何对象,这表明了显着的通用性。同时,我们发现被认为难以掌握的特定对象(例如 F3 和 F4)对于 ArrayBot 来说相对容易。这意味着ArrayBot可能对现有的通用机械臂具有补充能力。在评估过程中,我们发现强化学习在ArrayBot上发现的控制策略是滑动和滚动的混合。这就解释了为什么细长的平面物体(例如,G6是一片雪的形状)给传统的抓取方法带来了很大的困难,但由于其进行滚动运动的能力有限,也给分布式操纵技术带来了挑战。
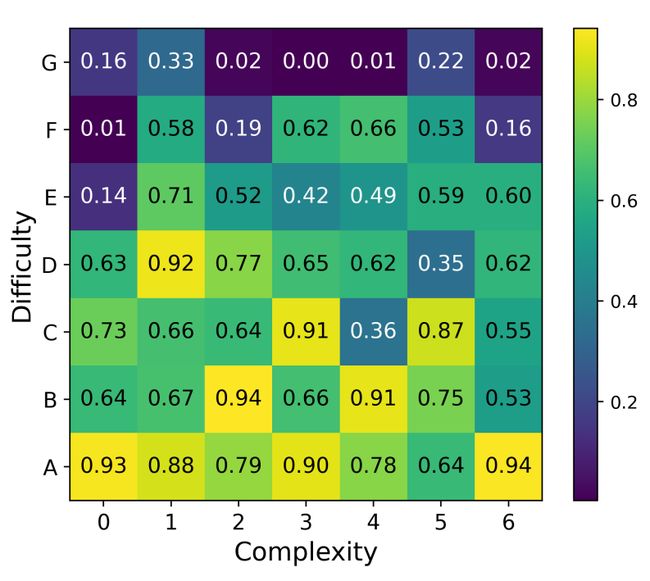
**图 5:**一般重定位策略在之前未见过的 EGAD [37] 测试集上的成功率。
4 将控制策略部署到物理机器人
零样本模拟到真实的转换。令我们惊讶的是,我们发现在模拟器中 EGAD 数据集上训练的一般重定位策略可以毫不费力地部署到物理机器人上,以执行多个基于重定位的任务。请注意,即时模拟到真实的传输甚至可以免除流行的模拟到真实技术的参与,例如域随机化[36]。直观上,模拟与真实差距有两个来源:感知和动态。我们选择本体感觉观察和二值化触觉测量将感知差异保持在较低水平。同时,训练时引入的不同形状和动作空间中的大量冗余都有助于提高动态变化的弹性。这些因素结合在一起解释了 ArrayBot 在模拟到现实过程中带来的非凡便利。
**现实世界的操纵任务。**利用成功部署到现实世界的一般搬迁策略,我们通过在物理机器人上呈现以下操作任务来进一步展示 ArrayBot 的优点:Y
- 操纵不同形状的物体。 ArrayBot 特别擅长处理瓜类和火龙果等自然物体。它还可以操纵人造物体,例如橡皮鸭和橄榄球形状的艺术品。请注意,这些物体比末端执行器的尺寸大几倍,由于它们太大而无法抓住或握住,因此超出了手臂或手的范围。

**图 6:**操作任务的真实轨迹显示了我们的系统对 (a) 意外外力 (b) 严重视觉退化影响的鲁棒性。
- **轨迹跟随。**通过迭代调用一般重定位策略可以轻松实现轨迹跟踪。请注意,ArrayBot 对增量操作很友好,因为它的工作量与行驶距离成正比。相比之下,轻微的操作对于手臂或手来说同样麻烦,因为无论操作规模如何,“拾取”和“放置”的成本都是恒定的。
- 并行操纵。 ArrayBot 由大量执行器组成,本质上支持并行操作。由于机械结构的空间自相似性,相同的控制策略自动适应所有局部补丁。假设没有发生碰撞,并行操作两个对象就像初始化两个独立的操作进程一样简单。我们将更复杂的涉及碰撞的并行操作留给未来的工作。
- 视觉退化下的操纵。 ArrayBot 完全不依赖任何视觉观察,毫无疑问对视觉退化具有鲁棒性。我们展示了 ArrayBot 在投影仪严重视觉干扰下自信地操纵透明物体的能力。
除了强化学习派生的控制策略的强大功能之外,我们还展示了一些用于静态但更复杂的操纵设置的硬编码策略。有关上述任务的直观说明,请参阅附录 C 中的图 1 和 6、图 10 和 11 以及项目网站。
5 硬件设计草图
ArrayBot由机器人框架和密集排列的可控支柱组成。机器人框架由支撑铝合金立柱、亚克力板、不锈钢底座组成。框架内部有256根矩形棱柱,在滑轨支架的约束下,由电机驱动实现垂直移动。每个支柱的横截面积为 16 × 16 mm2,需要紧密排列,间隙为 4 mm,以便顺利操作。支柱运动由 STM32 微控制器控制。在本节中,我们提供 ArrayBot 的重要硬件设计选择。我们将完整的设计细节留给附录 A。
**末端执行器。**图7(a)的右侧是末端执行器,它有一个硅胶半球形帽和一个FSR触觉传感器。当物体放置在末端执行器上时,支撑力通过硅胶帽传递到板状FSR传感器。为了在有限的物理空间内成功传输信号,我们设计了一种导电滑轨,可以避免使用电线。

图7:(a)单个支柱的分解图。 (b) 1 × 2 阵列的组装模块化单元。
**执行器。**图7(a)左侧是执行器,它是直流(DC)齿轮电机。它通过螺杆结构将电机的旋转运动转换为平移运动。电机的旋转轴上安装了磁性编码器,用于计算角度和角速度,最终将其映射到支柱的位置和速度。
支柱模块。如图7(b)所示,为了方便组装并最大限度地利用微控制器的性能,我们将每两个支柱组合成一个由STM32板控制的模块。因此,整个机器人包含 128 个模块,由 4 个控制器局域网 (CAN) 信号控制。在运行过程中,STM32板接收来自桌面的CAN命令,对其进行处理,并分别输出两个脉宽调制(PWM)信号来控制两个电机。
6 相关工作
分布式操纵:分布式操纵通过众多接触点控制目标物体的运动[14]。分布式操纵系统由一系列固定单位单元组成,能够缩放尺寸并固有地支持并行操纵。回顾文献,大多数分布式操纵系统由一系列专用执行器组成,例如振动板 [19]、空气喷射器 [39]、滚轮 [20]、电磁体 [25] 和 Delta 机器人 [21, 22] ]。虽然它们被设计为擅长特定类型的操作任务,但它们通常不够通用,并且需要精心预定义的运动基元。与机器人研究中的原型相比,ArrayBot 的硬件更多地与人机界面领域中被称为**“变形有形用户界面”**[26,27,40]的工作分支相关,其中执行器是垂直棱柱。设计的简单性不仅使其更易于制造,而且更易于制造。其有组织的动作空间还有助于打开通过无模型强化学习学习运动策略的大门。
频域学习:频域学习是机器学习社区各个领域广泛讨论的概念。在计算机视觉研究中,采用频率变换来弥合高质量图像和下采样图像之间的差距[41],并有助于在二进制CNN中实现更准确的梯度近似[42]。在强化学习的主题中,频率的概念被用来提高基于模型的架构中搜索控制的效率[43],并表示分布式强化学习的回报特征函数[44]。与我们发现的所有现有工作相比,ArrayBot 利用频率变换来重塑动作空间,旨在提高无模型强化学习中的样本效率。
7 结论和局限性
我们提出了 ArrayBot,一种具有触觉感知功能的 RL 驱动的分布式操纵系统。我们在提议的重塑动作空间中训练了一种可推广的通过触摸重新定位策略,该策略可以立即转移到物理机器人上。利用已部署的策略,我们通过各种现实世界的操作任务展示了 ArrayBot 的独特优点。
鉴于我们所有的发现,我们想呼吁机器人学习社区关注分布式操作。我们认为其非常规行动空间的冗余是一把双刃剑。只要我们找到方法来缓解其样本效率低下的恶魔面,其容错的天使面可能会为解决社区中众所周知的挑战(例如对象形状的泛化性和弥合模拟与真实的差距)提供捷径。
不可否认,ArrayBot 的原型还并不完美。例如,它的 16 × 16 尺寸对于大规模的多对象并行操作来说仍然不够大。关节的速度限制可能会阻碍强化学习智能体探索更高动态的控制策略。我们还发现,由于物体施加的压力由多个传感器共享,因此触觉传感器有时不够灵敏。未来,我们将不断升级ArrayBot的硬件和软件,以挖掘强化学习在分布式操纵方面的更大潜力。
3. USEEK:用于可推广操作的无监督 SE(3)-等变 3D 关键点
0. 摘要与总结
机器人是否可以仅通过单个物体实例上的抓取姿势演示来以任意姿势操纵类别内看不见的物体?在本文中,我们尝试使用 USEEK 来解决这一有趣的挑战,USEEK 是一种无监督的 SE(3) 等变关键点方法,可以跨类别中的实例进行对齐,以执行可泛化的操作。 USEEK遵循师生结构来解耦无监督关键点发现和SE(3)等变关键点检测。有了 USEEK,机器人可以以高效且可解释的方式推断类别级任务相关的对象框架,从而能够操纵任何类别内对象的任何姿势。通过大量的实验,我们证明了 USEEK 产生的关键点具有丰富的语义,从而成功地将功能知识从演示对象转移到新颖的知识。与其他用于操作的对象表示相比,USEEK 在面对大的类别内形状方差时更具适应性,在有限的演示下更稳健,并且在推理时更高效。项目网站:https://sites.google.com/view/usek/。
1. 引言
当三岁的孩子想到一个物体时,他们不仅将其识别为物体本身,而且将其识别为类别的符号[8]。根据发展心理学,人类天生的概括能力被称为符号功能[21]。在机器人技术的背景下,同样的泛化愿望引发了研究问题:是否存在一种控制方法可以实现跨对象姿势和实例的泛化操纵?
随着对物体完整 3D 几何结构的访问,机器人操作的流程早已成熟:用于感知的模板匹配 [10]、[1]、[26],同时轨迹优化 [2]、[25] 和逆运动学[5] 执行。然而,这些操作技能通常会受到类别内形状差异的影响,因为用于模板匹配的常见手工技术可能无法泛化。
为了实现类别内的任意姿势操作,实现类别级泛化的对象表示至关重要。现有的表示可以大致分为三类:6-DOF姿态估计器[39],[38],[37],[40],[18],3D关键点[33],[29],[19],[ 20]、[4]和密集对应模型[28]、[12]、[32]、[31]。尽管形式上存在差异,但他们的最终目标是一致的——确定物体的局部坐标系。因此,我们倾向于将这些表示视为对象的不同抽象级别。其中,6-DOF 位姿估计器通过直接预测对象框架提供最高级别的抽象。然而,它们通常被认为对于机器人操作任务中的大形状变化来说不够通用[19],[31]。最近,密集对应模型通过近似将 2D 像素或 3D 点映射到空间描述符的连续函数来隐式定义对象。虽然这些空间描述符保留了丰富的几何细节,但无法从密集的对应表示中免费获取直接指导操作的对象框架。
与上述表示相比,3D 关键点具有实用性和简单性的优点:其语义对应比 6-DOF 位姿提供更多信息;其简洁的表达比密集的对应模型更有效。尽管关键点有这些优点,但对于类别内任意姿态机器人操作的任务,我们可能进一步要求关键点具有以下属性:
-
(i) 抗闭塞。面对自遮挡时,关键点应该是可重复的。因此,我们更喜欢原始 3D 输入(即点云)而不是多视图图像。
-
(ii) 无人监督。关键点应该以无监督或自监督的方式获得,以避免人工注释的成本和偏差。
-
(iii) 跨实例对齐。某个类别内跨实例的关键点的语义对应对于类别级可概括的操作至关重要。
-
(iv) SE(3)-等变体。进一步希望关键点是等变的。 3D 空间中对象的平移和旋转,因为野外的对象可以以任何姿势出现。
在本文中,我们提出了一个利用 3D 关键点进行类别内任意姿势机器人操作的框架。该框架的核心是发现的 3D 关键点,它们拥有所有四个所需的属性。具体来说,我们提出了一种新颖的师生架构,用于无监督 SE(3) 等变关键点 (USEEK) 发现。然后,我们首先通过视觉指标根据最先进的关键点发现基线评估 USEEK。接下来,我们利用 USEEK 使机器人能够从随机初始化的姿势中拾取类别内的物体,然后通过一次性模仿学习将其放置在指定的姿势中。尽管有困难,USEEK 给出的关键点的丰富语义使机器人能够通过将功能知识从有限的演示转移到任何姿势中看不见的实例来执行拾取和放置。模拟器以及真实机器人上的定量和定性结果表明 USEEK 能够作为通用操作任务的对象表示。
2. 相关工作
2.1 用于操作的对象表示
**显式 6-DOF 位姿估计:**姿态估计技术始于 RANSAC [10] 或迭代最近点 (ICP) [26] 等早期工作。尽管非常有效,但这些工作通常会与未知物体的形状变化作斗争。基于学习的六自由度姿态估计器[27]、[39]、[37]、[18]设法在类别级别上表示对象。但当应用于机器人操作时,它们通常被视为要么在较大的类别内形状方差下模棱两可[19],要么无法提供足够的几何信息用于控制[31]。
**密集通信:**与显式姿态预测相反,密集对应方法[28]、[12]、[11]、[32]、[31]以连续且隐式的方式定义对象。一个例子是最近提出的神经描述符场(NDF)[31],它编码外部刚体和演示对象的空间关系。尽管 NDF 对于少样本模仿学习很有效,但效率很低,因为它必须通过迭代优化来回归数百个查询点的描述符字段[14]。
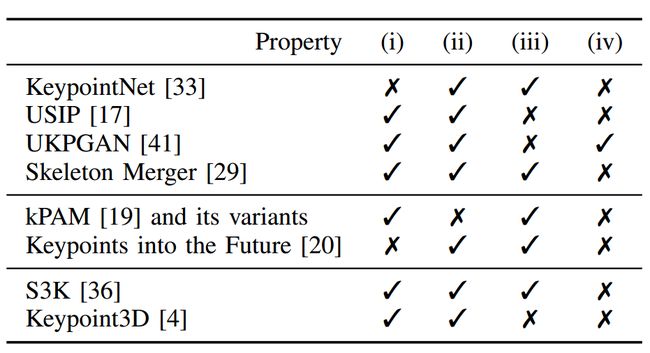
**3D 关键点:**使用 3D 关键点进行控制在计算机视觉 [33]、[17]、[41]、[29]、机器人技术 [20]、[19]、[13] 和强化学习 [36]、[ 4]。然而,我们发现表一中所示的现有方法都不满足我们列出的有利于通用机器人操作任务的所有要求。
**表 I:**我们比较了计算机视觉、机器人技术和强化学习领域最近提出的 3D 关键点检测器的功能。
2.2 SE(3)-不变/等变神经网络
SE(3) 不变和 SE(3) 等变的概念有时是相互交织的。对于关键点检测函数,如果函数选择点云中点的索引,我们要求它是SE(3)不变的;否则,如果函数返回关键点的坐标,我们要求它是 SE(3) 等变的。在本文中,我们采用第二种解释,要求 3D 关键点是 SE(3) 等变的。注意到我们可以通过将点云的质心归一化到指定的原始点来轻松处理平移,挑战主要与旋转有关,即 SO(3)-不变性/等变性。
PRIN/SPRIN [43]、[44] 和矢量神经元 [9] 是最近提出的 SO(3) 不变网络,直接将点云作为输入。 PRIN 通过吸收 Spherical CNN [6] 和 PointNet [23] 类网络的优点来提取旋转不变特征。 SPRIN 改进了 PRIN 的稀疏性并实现了最先进的性能。同时,矢量神经元通过将神经元从 1D 标量扩展到 3D 向量并提供相应的 SO(3) 等变神经操作来享受 SO(3) 等变。
3. 方法
我们提出了一个框架,该框架利用无监督的 SE(3) 等变关键点 (USEEK) 进行类别内任意姿势对象操作。 USEEK 中的关键点首先用于指定演示对象的与任务相关的局部坐标系。然后,它们在训练时将同一类别内未见过的形状和未观察到的姿势的物体推广到相应的点。利用这些关键点,我们设法传输与任务相关的帧,并最终执行运动规划算法来操纵对象
3.1 关键点的预备知识
我们首先将关键点检测器定义为 f(·),它将对象点云 P 映射到关键点 p 的有序集合:
f ( P ) : R N × 3 → R K × 3 f(\mathbf{P}): \mathbb{R}^{N \times 3} \rightarrow \mathbb{R}^{K \times 3} f(P):RN×3→RK×3
其中 N 是点的数量,K 是关键点的数量。如果对于任何点云 P 和任何刚体变换 ( R , t ) ∈ SE ( 3 ) (\mathbf{R}, \mathbf{t}) \in \operatorname{SE}(3) (R,t)∈SE(3) ,以下方程成立,则该函数是 SE(3) 等变的:
f ( R P + t ) ≡ R f ( P ) + t f(\mathbf{R P}+\mathbf{t}) \equiv \mathbf{R} f(\mathbf{P})+\mathbf{t} f(RP+t)≡Rf(P)+t
此外,如果检测到的关键点能够最好地表示一类对象的共享几何特征,则将其视为类别级别。

图 2:USEEK 的流程,遵循师生架构。所有“标签”都是由教师网络生成的伪真实标签,没有任何额外的人工注释。 PointNet++ [24] 模块具有固定参数,从预训练的 Skeleton Merger [29] 中提取。 SPRIN[44]网络将在训练过程中进行优化。二元交叉熵(BCE)损失用于损失计算。
3.2 USEEK:教师-学生框架
为了开发一个类别级别和 SE(3) 等变的关键点检测器,我们提出了具有教师-学生结构的 USEEK。教师网络是一个类别级关键点检测器,可以以自监督的方式进行预训练。学生网络由 SE(3) 不变主干网络组成。
从概念上讲,师生网络的主要优点是解耦学习过程,每个网络只负责它最擅长的属性。此外,SE(3) 不变网络通常更难训练。因此,师生结构可能会减轻学生网络在关键点发现过程中的负担。这些是师生结构至关重要以及简单方法(如第 IV-A 节所示)无法取得有竞争力的结果的核心原因。接下来,建立了 USEEK 的蓝图,我们用具体细节实例化它
教师网络:在教师网络中,每个关键点被视为云中所有点坐标的加权和。为了产生所需的权重矩阵 W ∈ R K × N \mathbf{W} \in \mathbb{R}^{K \times N} W∈RK×N ,我们从 Skeleton Merger [29](一种最先进的类别级关键点检测器)中提取 PointNet++ [24] 编码器。权重矩阵与输入云的乘法直接给出预测的关键点
p = W P \mathbf{p}=\mathbf{W P} p=WP
我们遵循[29]中所示的相同自监督训练过程来预训练 PointNet++ 模块。
教师网络预测的关键点用于为学生网络生成伪标签。由于附近的点具有相同的语义,因此某个关键点距离内的所有点都被视为相应关键点的候选点,因此被标记为正标签;其余的是负面的。在N点云中总共检测到K个关键点,最终的伪标签可以被视为K通道二进制分割掩模 M ∈ R K × N \mathbf{M} \in \mathbb{R}^{K \times N} M∈RK×N 。
学生网: USEEK 的学生网络利用 SPRIN [44](一种最先进的 SE(3) 不变主干网)来生成 SE(3) 等变关键点。 SPRIN 模块将规范对象点云作为输入,并预测教师网络生成的标签。
对于训练,学生网络优化每点 K 通道二进制预测和相应伪标签之间的二进制交叉熵 (BCE) 损失。为了处理负标签相对于正标签不平衡的问题,我们执行重要性采样[35]。此外,我们强调整个训练过程不需要任何 SE(3) 数据增强,因为 SE(3) 不变主干可以自动泛化到看不见的姿势。
测试时,对预测进行后处理以产生最终的关键点。我们采用argmax操作,这意味着具有最高置信值的点被选择作为K个分割类别中的每个类别的检测到的关键点。此外,我们采用非极大值抑制[22]来鼓励关键点的稀疏局部性。
3.3 从关键点到任务相关的对象框架
可概括操作的本质可以说是将功能知识从已知对象转移到未知对象。在本节中,我们展示了一个易于执行但有效的过程,该过程利用检测到的关键点来确定与任务相关的对象框架。
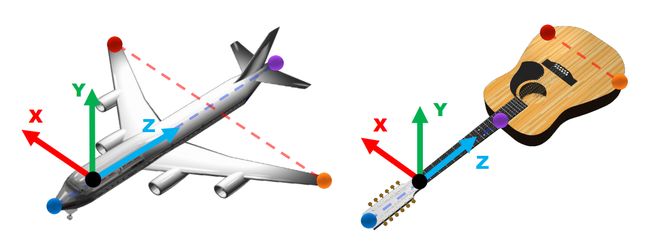
**图 3:**用于操作的类别级任务相关坐标系可以从 USEEK 检测到的关键点以及仅在一个对象上确定的少量先验信息中获取。
以图3(左)中的飞机为例,检测到的四个关键点分别位于机头、机尾、左翼尖和右翼尖。有了清晰的语义,我们就可以很容易地设定简单的规则来建立框架:x轴平行于两个翼尖的连线; z 轴平行于连接的鼻子和尾巴的线条; y轴垂直于x轴和z轴;原点是演示的抓取位置在 z 轴上的投影。由于 USEEK 的类别内对齐属性,一旦在一个特定对象上设置了规则,它们就会立即适应所有其他实例。从这个意义上说,每个实例花费的平均劳动力可以忽略不计。在图 3(右)中,我们提供了吉他的类别作为附加示例。
值得注意的是,与之前的工作[19]、[31]不同,USEEK在推断目标框架时避免了任何搜索或优化过程,从而大大降低了计算成本。
3.4 使用 USEEK 进行一次性模仿学习
配备了关键点和与任务相关的对象框架,我们现在已准备好进行类别级操作。任务是从随机初始化的 SE(3) 姿势中拾取一个看不见的物体并将其放置到另一个指定的姿势中。为了展示 USEEK 的全部潜力,我们采用了更具挑战性的一次性模仿学习设置,而不是之前作品中常见的几次设置[31],因为演示数量的减少要求提高模型的鲁棒性和一致性。提议的对象表示。
具体来说,演示 D = ( P d e m o , X d e m o G ) \mathscr{D}=\left(\mathbf{P}_{\mathrm{demo}}, \mathbf{X}_{\mathrm{demo}}^{G}\right) D=(Pdemo,XdemoG) 仅仅是坐标系形式的对象 P d e m o \mathbf{P}_{\mathrm{demo}} Pdemo 的点云和 X demo G \mathbf{X}_{\text {demo }}^{G} Xdemo G 的功能抓取姿势。给定演示 D \mathscr{D} D ,USEEK 推断演示对象 X demo O \mathbf{X}_{\text {demo }}^{O} Xdemo O 的任务相关坐标系。然后,我们计算从对象到 O T demo G , s.t. { }^{O} \mathbf{T}_{\text {demo }}^{G} \text {, s.t. } OTdemo G, s.t. 演示的刚体变换,
X d e m o G = X d e m o O O T d e m o G \mathbf{X}_{\mathrm{demo}}^{G}=\mathbf{X}_{\mathrm{demo}}^{O}{ }^{O} \mathbf{T}_{\mathrm{demo}}^{G} XdemoG=XdemoOOTdemoG
其中所有的姿势和变换都在齐次坐标中。假设物体是刚性的并且抓握很紧, O T demo G , s.t. { }^{O} \mathbf{T}_{\text {demo }}^{G} \text {, s.t. } OTdemo G, s.t. 对于该类别来说是通用的。因此,为了简单起见,我们将其重写为 O T G , s.t. { }^{O} \mathbf{T}_{\text { }}^{G} \text {, s.t. } OT G, s.t.
在测试时,观测值 O = ( P init , P targ ) \mathscr{O}=\left(\mathbf{P}_{\text {init }}, \mathbf{P}_{\text {targ }}\right) O=(Pinit ,Ptarg ) 由处于任意初始姿态 P init \mathbf{P}_{\text {init }} Pinit 的看不见物体的点云和指示目标姿态 P target \mathbf{P}_{\text {target}} Ptarget 的另一个点云组成。请注意,目标姿势中的物体不需要与初始姿势中的物体相同。 USEEK 推断初始姿态 X init O \mathbf{X}_{\text {init }}^{O} Xinit O 中的对象框架和目标姿态 X t a r g O \mathbf{X}_{\mathrm{targ}}^{O} XtargO 中的框架。然后,准备好 O T G { }^{O} \mathbf{T}^{G} OTG ,我们可以轻松计算用于拾取和放置的夹具的位姿:
X pick G = X init O O T G \begin{aligned} \mathbf{X}_{\text {pick }}^{G} & =\mathbf{X}_{\text {init }}^{O}{ }^{O} \mathbf{T}^{G} \end{aligned} Xpick G=Xinit OOTG
X place G = X targ O T G . \begin{aligned} \mathbf{X}_{\text {place }}^{G} & =\mathbf{X}_{\text {targ }}^{O}{ }_{\mathbf{T}^{G}} . \end{aligned} Xplace G=Xtarg OTG.
最后,我们利用现成的运动规划 [15] 和逆运动学 [30] 工具来执行预测的姿势。

表 II:USEEK 检测到的关键点的 mIoU 分数以及 SE(3) KeypointNet [42] 数据集上的基线。最佳结果以粗体显示。此外,还包括在规范数据集上测试的教师网络,但以灰色标记以区别。
4. 实验:关键点的语义
在本节中,我们评估当输入点云经过 SE(3) 变换时,USEEK 检测到的关键点是否具有正确且准确的语义。
4.1 设置和基线
实验在 KeypointNet [42] 数据集上进行,其中具有类别级语义标签的关键点由专家注释。我们使用平均交集 (mIoU) [34] 分数来衡量预测和人工注释之间的对齐情况。为了评估 SE(3) 等方差的属性,输入及其注释处于相同的随机 SE(3) 变换下。我们将USEEK与以下方法进行比较:
-
固有形状特征(ISS)。 ISS [45] 是一个经典的手工制作的 3D 关键点检测器。
-
骨架合并。骨架合并在 ShapeNet [3] 上使用规范点云进行训练。
-
骨架合并与数据增强。我们将 SE(3) 数据增强应用于训练数据集。
-
骨干合并与ICP。在测试期间,我们随机选取训练数据集上的一个规范姿态实例作为模板,并采用用 RANSAC [10] 初始化的 ICP [26] 进行点云配准。
-
带有SPRIN 编码器的骨架合并。 Skeleton Merger 的编码器被替换为 SE(3) 不变的 SPRIN 编码器。
-
USEEK 带KL 散度。 USEEK 中的 SE(3) 不变主干经过轻微修改以预测权重矩阵。它通过预测权重和伪权重标签之间的 Kullback-Leibler (KL) 散度 [16] 进行优化
此外,我们在没有 SE(3) 转换的规范 KeypointNet 数据集上评估了 USEEK 的教师网络。这个辅助配置反映了 USEEK 可以学习的语义的质量。
4.2 结果与讨论
USEEK 检测到的关键点的定性结果如图 4 所示。在 SE(3) 变换和较大的形状方差下,关键点在整个类别中很好地对齐,并识别出类似于人类直觉的语义部分。表 II 中给出的定量结果表明,USEEK 的性能大大优于所有其他基线。令人惊讶的是,USEEK 在飞机和吉他类别上的表现接近 Teacher Network,甚至在刀具方面超过了 Teacher Network。事实上,考虑到精心设计的标签生成机制,预测关键点的周围点都被视为候选关键点,USEEK 中的学生可能胜过其老师,这是合理的。
对于其他基线,正如预期的那样,带有数据增强的 Skeleton Merger 之类的基线无法产生语义上有意义的关键点,因为对于朴素的 PointNet++ 编码器来说,从任意 SE(3 ) 变换。此外,我们还注意到更强的基线方法(例如带有 SPRIN 编码器的 Skeleton Merger)不如 USEEK 功能强大。我们将其失败归因于编码器的 SE(3) 不变保证通常会导致网络中的参数更多以及训练难度更大。与基线相比,USEEK 通过遵循师生结构来实现训练过程,将潜在关键点的无监督因果发现转变为更简单的监督学习任务。

**图4:**USEEK检测到的关键点的定性结果。输入点云处于随机 SE(3) 变换下。关键点的颜色代表预测的类别级语义对应(即类别的关键点是颜色对齐的)。
5. 实验:操控要点
在本节中,我们评估 USEEK 作为可泛化操作的对象表示的能力。我们在模拟和现实环境中进行实验,其中利用 USEEK 通过一次性模仿学习执行类别级拾取和放置。
5.1 设置
我们构建模拟环境来模仿 PyBullet [7] 中的物理设置。对于现实环境,我们使用 Franka Panda 机器人手臂进行操作,并在桌子的每个角落使用四个英特尔实感 D435i 深度摄像头来捕获点云。我们使用木楔子、金属支架或橡皮泥捏制的支架来支撑物体,以便它们可以放置成任意姿势。真实世界的实验设置如图 5 所示。
**图 5:**在现实世界的实验中,操纵类别内形状方差较大的对象。对齐和 SE(3) 等变属性使 USEEK 能够将功能知识从一个演示对象转移到任意姿势的各种看不见的对象。
机器人需要以随机初始化的 SE(3) 姿势拾取看不见的物体,并将它们放置在指定的目标姿势中。为了实现这一任务,为每个类别仅提供一个对单个物体的功能性抓取姿势的演示。为了实现更大的多样性,我们将任务设计为三类:1)对于飞机,我们演示两种不同的功能姿势(即前面和后面),以检查机器人是否能够根据演示做出相应的动作; 2)对于吉他,机器人被要求通过握住吉他的颈部将吉他从一个金属支架转移到另一个金属支架上。这项任务更具挑战性,因为吉他的琴颈很脆弱,因此需要非常精确的控制; 3)对于刀,机器人需要拿起桌子上的刀,用它来切豆腐。斩波方向是根据给定的目标姿态推断出来的。
5.2 基线和评估指标
为了显示 USEEK 操作的有效性,我们在模拟环境中与使用 RANSAC [10] 粗配准和神经描述符域 (NDF) [31] 初始化的 ICP [26] 进行比较。 ICP 通过尝试将看不见的对象与给定的演示对象对齐来估计其框架。 NDF 是最近提出的用于类别级别操作的最先进的密集对应表示。 NDF 通过一组查询点对外部刚体的每个 SE(3) 位姿与演示对象的关系进行编码。看不见的对象的任务相关坐标系是通过将其描述符字段回归到演示的字段来确定的。
我们测量抓取本身和整个拾放过程的成功率。具体来说,如果夹具能够稳定地将物体从桌子上取下,且垂直间隙至少为10厘米,则抓取成功。对于拾放,每个自由度的最终位姿的跨国和旋转公差分别为 5 厘米和 0.2 弧度。实验在从 ShapeNet [3] 中随机抽取的 100 个不同对象实例上进行,无需对每个类别进行挑选。此外,我们还给出了每种方法执行一次所需的平均推理时间。
5.3 训练细节
我们在 ShapeNet [3] 数据集上训练 USEEK 和 NDF 基线,并将模型直接部署到操作任务中。我们使用 Adam [14] 进行优化,默认学习率为 0.001。虽然 NDF 可以使用一个统一模型处理多个类别,但我们发现由于所选类别中的形状方差较大,给定预训练模型的性能显着下降。因此,我们为 USEEK 和 NDF 训练每个类别的独立模型,以进行公平比较。
5.3 模拟实验
ICP[26]、NDF[31]和USEEK的成功率如表III所示。 USEEK 在具有挑战性的一次性模仿学习环境中显着优于两个基线,展示了其作为可泛化操作的对象表示的优势。相比之下,ICP作为模板匹配方法实际上无法处理较大的类别内形状方差,并且无法为操作提供准确的信息。与此同时,NDF 在刀具类别上取得了相对不错的成绩。但整体竞争力远不如USEEK。我们观察到 NDF 无法找到正确的抓取方向的故障模式。我们将此归因于在只有一个可用演示的情况下对大量(默认情况下约为 500 个)查询点的神经描述符进行回归的困难。此外,对于 NDF,在 NVIDIA RTX 3070 GPU 上推断一次执行平均需要 3.65 秒,而对于 USEEK,只需要 0.11 秒,效率提升了 30 倍以上。

**表三:**一次性模仿学习设置下的抓取成功率和拾放的整个过程。
5.4 真实世界执行
最后,我们验证 USEEK 可以成功部署在真实机器人上进行通用操作,而无需进行 simto-real 微调。我们应用 RRT-Connect [15] 算法进行运动规划,并使用 Panda Robot 库 [30] 中的默认方法来执行逆运动学。
从数量上看,总共有 50 次处决是在一系列具有各种外观和材料、并且具有任意初始姿势的新颖飞机上进行的。其中,成功37次,成功率74%。我们发现 USEEK 对于从深度相机获取的原始点云的质量下降具有鲁棒性。结果还表明,USEEK 可以很好地适应现实场景中的颜色变化和形状变化。一种常见的故障模式是 USEEK 无法处理点云中的严重伪影(例如,缺少一半机翼),这主要是由于某些飞机表面油漆的高反射率。我们相信,通过使用更先进的深度相机,这一问题在未来可以得到缓解。定性地,我们在图 6 中展示了飞机、吉他和刀具的示例执行轨迹。更多结果可以在补充视频中找到。
6. 结论
我们提出了 USEEK,一种无监督的 SE(3) 等变关键点检测器,可通过一次性模仿学习实现通用的拾取和放置。 USEEK 使用师生结构,以便可以以无监督的方式获取具有所需属性的关键点。大量实验表明,USEEK 检测到的关键点具有丰富的语义,这使得功能知识能够从一个演示对象迁移到任意姿势下具有较大类别内形状方差的未见过的对象。此外,USEEK 在有限的演示中表现出鲁棒性,并且在推理时非常高效。考虑到所有这些优点,我们相信 USEEK 是一种强大的对象表示,并且有潜力支持许多操作任务。