MySQL 聚集与非聚集索引
文章目录
- 1.聚集索引
-
- 1.1 介绍
- 1.2 优点
- 1.3 缺点
- 2.非聚集索引
- 3.区别
- 参考文献
MySQL 中,根据索引树叶结点存放数据行还是数据行的地址,可以将索引分为两类:
- 存放数据行:聚集索引
- 存放数据行地址:非聚集索引
InnoDB 使用聚集索引,MyISAM 使用非聚集索引。
1.聚集索引
1.1 介绍
聚集索引(Clustered Index)也叫聚簇索引,一般以主键建立索引。
在 InnoDB 中如果没有定义主键,会选择第一个非空唯一索引来代替。如果没有这样的索引,InnoDB 会自动生成一个不可见的列名为 ROW_ID,索引名为 GEN_CLUST_INDEX 的聚簇索引,该列是一个 6 字节的自增数值,随着插入而自增。
聚集索引(Clustered Index)的索引和表数据放在一个文件,行数据存储存在索引树叶子结点上,通过索引可直接获得行数据。
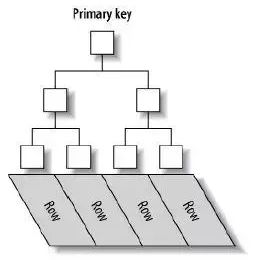
与聚集索引配套使用的是二级索引(Secondary Indexes),也叫辅助索引。
一个表可以有多个二级索引。
二级索引树叶子结点存储的是主键。
若对非主键字段建立的索引就是二级索引,根据二级索引搜索,则需要两步:
- 第一步在二级索引(辅助索引)B+ 树中检索,到达其叶子结点获取对应的主键。
- 第二步使用主键在主键索引 B+ 树中再执行一次 B+ 树检索操作,最终到达叶子节点即可获取行数据。

1.2 优点
- 主键查询效率更高
通过主键使用聚集索引查找数据比非聚集索引要快,因为非聚集索引定位到对应主键时还要多一次目标记录磁盘 IO,即回表查询。
- 范围查询效率更高
聚集索引存储记录,记录物理存储按照索引排序,物理上有序。因此范围查询(例如,使用 BETWEEN、>、< 等条件)可以更有效地利用磁盘上的顺序数据。而非聚集索引是逻辑上有序,物理存储并不有序。
- 辅助索引易维护
当出现行移动或者数据页分裂(Page Split)时,InnoDB 无须更新辅助索引。
数据页是存储数据行的物理存储单元,它通常包含一定数量的数据行,以及用于管理数据页的页头信息。
页分裂指的是当一个数据页已经满了,需要插入一条新的记录但无法容纳时,数据库引擎将尝试重新组织页上的数据,将一部分数据移动到新的页上,从而为新记录腾出空间。
1.3 缺点
- 二级索引访问需要两次索引查找。
第一次找到主键值,第二次根据主键值找到行数据。
- 更新主键的代价高。
因为将会导致被更新的行发生移动,所以 InnoDB 表主键一般定义为不可更新。
- 插入速度严重依赖于插入顺序。
按照主键顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于 InnoDB 表,我们一般都会定义一个自增的 ID 列为主键。
2.非聚集索引
按照语义,除了聚集索引,其他索引都是非聚集索引。
但在这里非聚集索引特指索引树叶结点存储的是「索引+数据地址」的索引。
非聚集索引(Nonclustered Index)的索引文件和表数据是分开的,主键索引和二级索引存储上没有任何区别。使用 B+ 树存储索引,所有节点都是索引,叶子结点存储的是「索引+数据地址」。

3.区别
- 数量不同。
一个表中只能有一个聚集索引,而非聚集索引可以有多个。
- 磁盘 IO 次数不同。
聚集索引通过一次索引查询可以直接找到数据,而非聚集索引需要一次索引查询到数据地址,外加一次数据磁盘 IO。
- 数据组织方式不同。
聚集索引的数据行在物理存储上是有序的,对于范围查询和排序操作,有序的物理存储结构也有助于减少磁盘 I/O 操作,提高查询性能。非聚集索引和数据行是分开两个文件存放,数据行在物理存储上是乱序的。
- 读写性能不同。
聚集索引查询效率高,但插入效率低,因为需要移动数据的物理位置保证物理存储上有序。非聚集索引则反过来,插入效率高,查询效率低。
参考文献
15.6.2.1 Clustered and Secondary Indexes
索引常见面试题 - 小林coding