算法day3
算法day3
- 链表理论基础
- 203.移除链表元素
- 707.设计链表
- 206 反转链表
链表理论基础
链表类型
单链表,双链表,循环单链表,循环双链表。
快速掌握细节:1.熟悉结点的结构,2.熟悉链表的特点,和指针域。
链表的存储方式
数组在内存中是连续分布的,链表在内存中不是连续分布的,链表是通过指针域来链接在内存中的各个结点。链表的这种分布也可以叫离散分布。结点分布在内存的不同地址空间上。
链表的定义
type ListNode struct{
val int
Next *ListNode
}
这个在面试的时候如果要用到链表就要会自己写。因为leetcode默认给你写好了
链表的操作:带头结点版
删除结点:
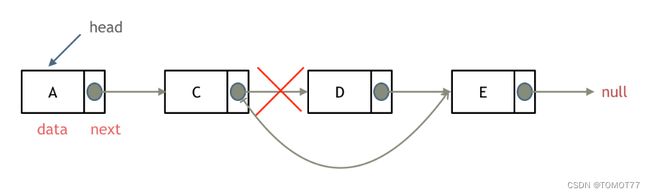
比如我举个例子:删除p结点后的元素,那就是p.next=p.next.next。
这里再进行一个补充:
之前我写c++的时候,比如我要删除p结点后面的这个q结点。
我会习惯有这样的写法:
q=p->next
p->next = q->next
free(q)
那在go语言中,这个free(q)就没必要了,因为go语言的垃圾回收机制是自动完成的,这代表无需也无法进行这个像c++一样的free结点。
还有一点注意就是别用->,go语言里面结构体没有->,只用.就可以了
添加结点
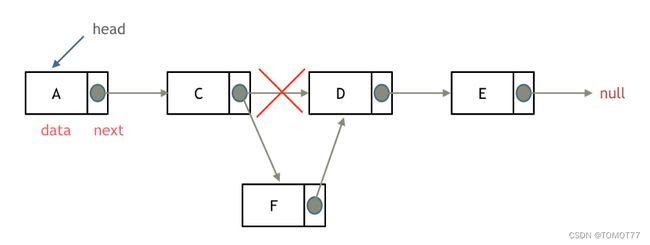
基本上了解这些性质,剩下都去题中练习。
一个技巧:我看leetcode上的题目,基本上都是不给头结点的,所以自己写一个虚拟头结点dummyhead是一个必会的技巧。还有带头结点有什么好处,好处就在于对每一个结点的操作都是统一的处理方式,因为不带头结点的链表,删除第一个元素和删除中间的元素,这操作显然就不一样。这在你写代码的时候显然就要搞一个特判,判断是否是头结点。这样就显得麻烦了。
203.移除链表元素
不带头结点写法
type struct ListNode{
Val int
Next *ListNode
}
func removeElements(head *ListNode, val int) *ListNode {
for head!=nil && head.Val==val{
head=head.Next
}
cur:=head
for cur!=nil && cur.Next!=nil{
if cur.Next.Val==val{
cur.Next=cur.Next.Next
}else{
cur=cur.Next
}
}
return head
}
解决以下问题就等于会写这个题
1.没用虚拟头结点,如果要删头结点,该怎么删。
2.删除非头结点,为什么这里cur要等于head,既然已经判断是非头结点,为什么不直接指向head.next更方便?
3.删头结点时为什么要用for循环,用if行不行
解答:
1.写个特判,因为删第一个结点的操作就是和删非第一个结点的操作不一样,删除第一个结点时head=head.next,删除非头结点就是p.next = p.next.next
2.因为删除非头结点,你要找到指定删除的结点的前一个结点,才能实现删除操作
3.不行,看这个案例,target = 1 ,某链表:1->1->1->1 如果用if你就只删了一个1,后面的就没实现删除。
带头结点的写法
type struct ListNode{
Val int
Next *ListNode
}
func removeElements(head *ListNode, val int) *ListNode {
dummyhead := &ListNode{}
dummyhead.Next=head
cur:=dummyhead
for cur.Next!=nil{
if cur.Next.Val==val{
cur.Next=cur.Next.Next
}else{
cur=cur.Next
}
}
return dummyhead.Next
}
掌握以下几个点就等于会写这个题:
1.为什么要用虚拟头结点。
2.dummyhead怎么创建,我之所以这么问是,在go语言中怎么创建。
3.为什么要用临时指针cur,而不用head。
4.为什么cur要等于dummyhead而不直接等于dummyhead->next,毕竟dummyhead只是个虚拟结点
5.为什么要返回dummyhead.Next,而不是返回head
解答:
1.用虚拟头结点的好处就是对所有结点的处理都得到了统一化。
2.创建dummyhead就是实例化一个结构体变量,而且头结点的数据域并不需要赋值。创建完之后直接dummyhead.Next=head。
3.在虚拟头结点的写法中,最好都不要去动head结点。这个在没用虚拟头结点的写法中也是。
4.这个就是删除操作不是要找指定元素,而是要找要删除的元素的前一个元素。因为删除操作就是找要删的前一个元素才能够实现删除
5.就是因为所有结点进行操作统一化处理,head结点可能被删除了,此时返回head就空指针了.所以要用dummyhead.Next
707设计链表
type MyLinkedList struct {
dummyhead *ListNode
size int
}
func Constructor() MyLinkedList {
return MyLinkedList{
dummyhead:&ListNode{},
size:0,
}
}
func (this *MyLinkedList) Get(index int) int {
if index<0 || index>=this.size{
return -1
}
cur:= this.dummyhead.Next
for i:=0;i<index;i++{
cur=cur.Next
}
return cur.Val
}
func (this *MyLinkedList) AddAtHead(val int) {
newnode :=&ListNode{
Val:val,
}
cur:=this.dummyhead
newnode.Next=cur.Next
this.dummyhead.Next=newnode
this.size++
}
func (this *MyLinkedList) AddAtTail(val int) {
newnode :=&ListNode{Val:val}
cur:=this.dummyhead
for cur.Next!=nil{
cur=cur.Next
}
cur.Next=newnode
this.size++
}
func (this *MyLinkedList) AddAtIndex(index int, val int) {
if index<0{
index=0
}else if index > this.size{
return
}
newnode :=&ListNode{Val: val}
cur:=this.dummyhead
for i:=0;i<index;i++{
cur=cur.Next
}
newnode.Next=cur.Next
cur.Next=newnode
this.size++
}
func (this *MyLinkedList) DeleteAtIndex(index int) {
if index<0 || index >= this.size{
return
}
cur := this.dummyhead
for i:=0;i<index;i++{
cur=cur.Next
}
if cur.Next!=nil{
cur.Next=cur.Next.Next
}
this.size--
}
这个题我写了挺久的,主要就是这个题我调了半天发现,插入[-1,0]竟然可以。这就把我恶心坏了,因为这题目我怎么也没读出当下标<0时要进行头插,在这里卡了半天。
![]()
1.这里总结一个最大的问题就是在写addAtIndex()这个函数的特判,要注意index<0要进行头插。别的我认为题目都是给全了。
2.这个题目也是默认给了结点的结构体,我第一次写的时候没注意,于是自己写了一个点的定义。这里以后都别写什么花里胡哨的名字,就按这个题的标准来写。
type ListNode struct {
Val int
Next *ListNode
}
3.这个题我写的时候对边界处理还是有问题,首先这个题他要求下标从0开始,也就是说第一个结点是题目要求的第0个结点。这会对写index的边界判断有影响,此时的index特判就应该是index <0 || index>=this.size(),这里我一开始写的是>,因为忘了没注意是从0开始。如果从1开始,那么>就是没毛病的,如果从0开始,这个=this.size()是肯定取不到的,所以就要加入特判。
4.这个链表初始化刚开始写我也挺纠结的,虽然知道要创建虚拟头结点,但是不知道怎么起手写。
之后我就想通了,我初始化这个虚拟头结点,但是size=0不就完事了。虚拟头结点不计入我的链表就可以了。因此创建的链表,两个熟悉,一个就是虚拟头结点,一个是记录size长度。链表初始化函数就是实例化这个虚拟头结点和长度赋初值。
5.细节总结:下标,还有边界条件,极端的例子是否能够统一的进行处理,处理不了就特判。
6.删除操作这里一个细节:这里我自己写的时候就漏判断了。
if cur.Next!=nil{
cur.Next=cur.Next.Next
}
this.size--
我写的时候我清楚我的cur其实是遍历我要删除的元素的前一个元素,因为删除操作就是要找前一个元素,这样才能对后面的元素进行删除。这样虽然方便但就有个问题,我要删除链表的最后一个元素,我这里直接cur.Next=cur.Next.Next,后面这里显然就会有空指针异常。所以这里要加特判。那么最后一个元素的删除操作这里直接this.size–就巧妙化解了。直接不计入链表的有效范围。
206反转链表
我拿到这个题时后的想法:
法一:遍历链表,搞个数组把值存下来,然后倒着遍历这个数据键链表
法二:直接头插法建表。
然后我就写了法二的版本:这种也就是双指针的写法
双指针写法
时间O(N),空间O(1)
func reverseList(head *ListNode) *ListNode {
var pre *ListNode = nil
cur := head
for cur != nil{
temp:=cur.Next
cur.Next=pre
pre = cur
cur=temp
}
return pre
}
灵魂拷问:
1.为什么pre初始化为null?
2.for循环什么时候停下来,为什么?
3.return返回什么,为什么?
4.怎么实现cur后移
回答:
1.因为此时头结点要作为尾结点了,那这个头结点的next就要指向null。
2.当cur==nil时,这个关系到这个构造的过程。所以说这个过程要理解清楚
3.这个也是构造的过程。
4.每次用个temp记录cur后面的位置
递归写法:
思路是和双指针我感觉是非常的像的,就是写法不一样。
这个题要想掌握递归写法,关键就在于双指针写法用递归的方式来写
func reverse(pre *ListNode,cur *ListNode)*ListNode{
if cur == nil{
return pre
}
temp := cur.Next
cur.Next=pre
pre=cur
return reverse(cur,temp)
}
func reverseList(head *ListNode) *ListNode {
return reverse(nil,head)
}
这代码的逻辑可以说是和双指针写法一模一样。
因为递归体做的事情和上面双指针for循环做的事情一模一样。
我写递归很快就写出来了,因为我总结递归的写法就像填空,就思考两个空怎么填,一个是递归出口,一个是递归函数体。
由上面图遍历的逻辑,就是cur==nil时就是递归的出口,此时返回pre就是结果。
递归函数体:不停的做双指针后移操作。
时间复杂度:o(n),空间o(n)。
总结:关键掌握双指针写法,因为递归写法有递归调用栈,费空间。
今日总结:
今天的题目我认为难点主要就是在边界和极端例子的处理:比如链表为空时删除操作,写代码时对第一个元素,最后一个元素的特判等等。这是在做的时候往往关注的问题。