【低照度图像增强系列(5)】Zero-DCE算法详解与代码实现(CVPR 2020)

前言
☀️ 在低照度场景下进行目标检测任务,常存在图像RGB特征信息少、提取特征困难、目标识别和定位精度低等问题,给检测带来一定的难度。
使用图像增强模块对原始图像进行画质提升,恢复各类图像信息,再使用目标检测网络对增强图像进行特定目标检测,有效提高检测的精确度。
⭐本专栏会介绍传统方法、Retinex、EnlightenGAN、SCI、Zero-DCE、IceNet、RRDNet、URetinex-Net等低照度图像增强算法。
完整代码已打包上传至资源→低照度图像增强代码汇总
目录
前言
一、Zero-DCE介绍
☀️1.1 Zero-DCE简介
二、Zero-DCE网络结构及核心代码
☀️2.1 网络结构
☀️2.2 核心代码
三、Zero-DCE损失函数及核心代码
☀️3.1 Lspa—Spatial Consistency Loss(空间一致性损失)
☀️3.2 Lexp—Exposure Control Loss(曝光控制损失)
☀️3.3 Lcol—Color Constancy Loss(颜色恒定损失)
☀️3.4 LtvA—Illumination Smoothness Loss(照明平滑度损失)
四、Zero-DCE代码复现
☀️4.1 环境配置
☀️4.2 运行过程
☀️4.3 运行效果

一、Zero-DCE介绍
相关资料:
- 论文题目:《Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement》(用于低光图像增强的零参考深度曲线估计)
- 原文地址:https://arxiv.org/abs/2001.06826
- 论文精读:CVPR2020|ZeroDCE《Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement》论文超详细解读(翻译+精读)
- 源码地址:项目概览 - Zero-DCE - GitCode
☀️1.1 Zero-DCE简介
本文发表在CVPR2020,主要提出了一个零参考深度曲线估计Zero-Reference Deep Curve Estimation(Zero-DCE),将光线增强转换为了一个image-specific曲线估计问题(图像作为输入,曲线作为输出),通过非参考损失函数实现,从而获得增强图像。
另外,通过训练一个轻量级的网络(DCE-NET),来预测一个像素级的,高阶的曲线,并通过该曲线来调整图像。
 主要贡献:
主要贡献:
- 是第一个不依赖于成对和非成对训练数据的弱光增强网络,从而避免了过拟合的风险。
- 设计一种特定的曲线,能够迭代运用于自身来近似像素和高阶曲线。这种曲线能够在动态范围内有效的进行映射
- 提出了一种无参的损失函数,来直接估计增强图像的质量。
取得成效:
- 整个方法在多个数据集上都取得了SOTA
-
在黑暗中的人脸检测取得成效

二、Zero-DCE网络结构及核心代码
☀️2.1 网络结构

- (1)backbone: DCE-Net包含七个具有对称跳跃连接的卷积层:conv-ReLU 重复 6 次 + conv-Than。(注意:它具有对称的级联,即第 1/2/3 层输出和第 6/5/4 层输出进行通道级联)
- (2)conv层: 由32个3x3的卷积核组成,stride=1
- (3)参数: 整个网络的参数量为79,416
- (4)Flops: Flops为5.21G(input 为256x256x3)
☀️2.2 核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
#import pytorch_colors as colors
import numpy as np
class enhance_net_nopool(nn.Module):
def __init__(self):
super(enhance_net_nopool, self).__init__()
self.relu = nn.ReLU(inplace=True)
# 一共有32个模块
number_f = 32
# 7个3*3,padding=1,stride=1的卷积核
self.e_conv1 = nn.Conv2d(3,number_f,3,1,1,bias=True)
self.e_conv2 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv3 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv4 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv5 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv6 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv7 = nn.Conv2d(number_f*2,24,3,1,1,bias=True)
# 最大池化层
self.maxpool = nn.MaxPool2d(2, stride=2, return_indices=False, ceil_mode=False)
# 双线性插值上采样层
self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x):
x1 = self.relu(self.e_conv1(x))
# p1 = self.maxpool(x1)
x2 = self.relu(self.e_conv2(x1))
# p2 = self.maxpool(x2)
x3 = self.relu(self.e_conv3(x2))
# p3 = self.maxpool(x3)
x4 = self.relu(self.e_conv4(x3))
x5 = self.relu(self.e_conv5(torch.cat([x3,x4],1)))
# x5 = self.upsample(x5)
x6 = self.relu(self.e_conv6(torch.cat([x2,x5],1)))
# 通过tanh激活函数处理得到增强后的图像enhance_image
x_r = F.tanh(self.e_conv7(torch.cat([x1,x6],1)))
# 通过torch.split将enhance_image分割成8个通道,分别表示不同的增强效果
r1,r2,r3,r4,r5,r6,r7,r8 = torch.split(x_r, 3, dim=1)
x = x + r1*(torch.pow(x,2)-x)
x = x + r2*(torch.pow(x,2)-x)
x = x + r3*(torch.pow(x,2)-x)
enhance_image_1 = x + r4*(torch.pow(x,2)-x)
x = enhance_image_1 + r5*(torch.pow(enhance_image_1,2)-enhance_image_1)
x = x + r6*(torch.pow(x,2)-x)
x = x + r7*(torch.pow(x,2)-x)
enhance_image = x + r8*(torch.pow(x,2)-x)
r = torch.cat([r1,r2,r3,r4,r5,r6,r7,r8],1)
return enhance_image_1,enhance_image,r这段代码平平无奇,就是实现图像增强操作。具体来说,主要通过多层卷积和连接操作,以及一些激活函数,学习图像的增强信息。
首先,初始化定义了32个模块,每个模块由7个3*3,padding=1,stride=1的卷积核组成。
然后,前6个卷积层使用ReLU激活函数,第7层使用tanh激活函数,得到增强后的图像enhance_image。
接着, 通过torch.split将enhance_image分割成8个通道,分别表示不同的增强效果。
最后,将这些效果叠加到原始输入图像上,得到最终的增强图像。
三、Zero-DCE损失函数及核心代码
其实这四个损失函数,才是本文最大的亮点。
☀️3.1 Lspa—Spatial Consistency Loss(空间一致性损失)
目的
通过保持输入图像与增强图像相邻区域的梯度促进图像的空间一致性。
方法
-
首先计算输入图像和增强图像在通道维度的平均值(将R、G、B三通道加起来求平均),得到两个灰度图像
-
然后分解为若干个4×4patches(不重复,覆盖全图)
-
最后计算patch内中心i与相邻j像素差值,求平均
公式

-
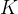 :局部区域的数量
:局部区域的数量 -
 :是以区域 i为中心的四个相邻区域(顶部、下、左、右)
:是以区域 i为中心的四个相邻区域(顶部、下、左、右) -
 :增强版本的局部区域的平均强度值
:增强版本的局部区域的平均强度值 -
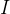 :输入版本的局部区域的平均强度值
:输入版本的局部区域的平均强度值
代码
class L_spa(nn.Module):
def __init__(self):
super(L_spa, self).__init__()
# print(1)kernel = torch.FloatTensor(kernel).unsqueeze(0).unsqueeze(0)
kernel_left = torch.FloatTensor( [[0,0,0],[-1,1,0],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)
kernel_right = torch.FloatTensor( [[0,0,0],[0,1,-1],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)
kernel_up = torch.FloatTensor( [[0,-1,0],[0,1, 0 ],[0,0,0]]).cuda().unsqueeze(0).unsqueeze(0)
kernel_down = torch.FloatTensor( [[0,0,0],[0,1, 0],[0,-1,0]]).cuda().unsqueeze(0).unsqueeze(0)
self.weight_left = nn.Parameter(data=kernel_left, requires_grad=False)
self.weight_right = nn.Parameter(data=kernel_right, requires_grad=False)
self.weight_up = nn.Parameter(data=kernel_up, requires_grad=False)
self.weight_down = nn.Parameter(data=kernel_down, requires_grad=False)
self.pool = nn.AvgPool2d(4)
def forward(self, org , enhance ):
b,c,h,w = org.shape
org_mean = torch.mean(org,1,keepdim=True)
enhance_mean = torch.mean(enhance,1,keepdim=True)
org_pool = self.pool(org_mean)
enhance_pool = self.pool(enhance_mean)
weight_diff =torch.max(torch.FloatTensor([1]).cuda() + 10000*torch.min(org_pool - torch.FloatTensor([0.3]).cuda(),torch.FloatTensor([0]).cuda()),torch.FloatTensor([0.5]).cuda())
E_1 = torch.mul(torch.sign(enhance_pool - torch.FloatTensor([0.5]).cuda()) ,enhance_pool-org_pool)
D_org_letf = F.conv2d(org_pool , self.weight_left, padding=1)
D_org_right = F.conv2d(org_pool , self.weight_right, padding=1)
D_org_up = F.conv2d(org_pool , self.weight_up, padding=1)
D_org_down = F.conv2d(org_pool , self.weight_down, padding=1)
D_enhance_letf = F.conv2d(enhance_pool , self.weight_left, padding=1)
D_enhance_right = F.conv2d(enhance_pool , self.weight_right, padding=1)
D_enhance_up = F.conv2d(enhance_pool , self.weight_up, padding=1)
D_enhance_down = F.conv2d(enhance_pool , self.weight_down, padding=1)
D_left = torch.pow(D_org_letf - D_enhance_letf,2)
D_right = torch.pow(D_org_right - D_enhance_right,2)
D_up = torch.pow(D_org_up - D_enhance_up,2)
D_down = torch.pow(D_org_down - D_enhance_down,2)
E = (D_left + D_right + D_up +D_down)
# E = 25*(D_left + D_right + D_up +D_down)
return E首先,定义了四个卷积核分别用于计算图像在左、右、上和下方向上的差异。
然后,在向前传播过程中进行如下计算:
- 计算权重差异
weight_diff。 - 计算增强图像的差异
E_1,该差异受到阈值0.5的控制。 - 利用卷积运算分别计算原始图像和增强图像在四个方向上的梯度差异。
- 计算每个方向上的梯度差异的平方,并将它们相加,得到
E。
最后,返回计算得到的空间损失 E。
☀️3.2 Lexp—Exposure Control Loss(曝光控制损失)
目的
抑制曝光不足/过度区域,控制曝光水平。
方法
测量的是局部区域的平均强度值与良好曝光水平(E=0.6 ,经验设置)之间的距离。
-
首先将增强图像转为灰度图
-
然后分解为若干 16×16 patches(不重复,覆盖全图)
-
最后计算 patch 内的平均值
公式

-
 :大小为16×16的不重叠局部区域个数
:大小为16×16的不重叠局部区域个数 - :增强图像中某个局部区域的平均强度值
代码
class L_exp(nn.Module):
def __init__(self,patch_size,mean_val):
super(L_exp, self).__init__()
# print(1)
self.pool = nn.AvgPool2d(patch_size)
self.mean_val = mean_val
def forward(self, x ):
b,c,h,w = x.shape
x = torch.mean(x,1,keepdim=True)
mean = self.pool(x)
d = torch.mean(torch.pow(mean- torch.FloatTensor([self.mean_val] ).cuda(),2))
return d这段代码比较简单,就是通过初始化平均池化层和均值函数,比较输入图像的全局均值与指定均值之间的差异。
最后,返回计算得到的亮度损失 d。
☀️3.3 Lcol—Color Constancy Loss(颜色恒定损失)
目的
用于纠正增强图像中的潜在色偏,同时也建立了三个调整通道之间的关系。
方法
-
首先将提亮图像分成RGB三通道,计算每个通道的平均亮度
-
然后将不同通道的平均亮度两两相减,求平均和
Color Constancy Loss值越小,说明提亮图像颜色越平衡,损失越大则说明提亮图像可能有色偏的问题
公式

-
 :增强后图像中p通道的平均强度值
:增强后图像中p通道的平均强度值 -
 :一对颜色通道
:一对颜色通道
代码
class L_color(nn.Module):
def __init__(self):
super(L_color, self).__init__()
def forward(self, x ):
b,c,h,w = x.shape
mean_rgb = torch.mean(x,[2,3],keepdim=True)
mr,mg, mb = torch.split(mean_rgb, 1, dim=1)
Drg = torch.pow(mr-mg,2)
Drb = torch.pow(mr-mb,2)
Dgb = torch.pow(mb-mg,2)
k = torch.pow(torch.pow(Drg,2) + torch.pow(Drb,2) + torch.pow(Dgb,2),0.5)
return k这段代码也比较简单,主要进行以下的计算:
- 计算图像在每个像素位置的RGB均值,这是通过对每个通道在高度和宽度上进行平均计算得到的。
- 将RGB均值分割成单独的通道(mr、mg、mb)。
- 计算颜色差异,分别为红绿差异
Drg、红蓝差异Drb和绿蓝差异Dgb。
最后,返回计算得到的最终的颜色损失 k。
☀️3.4 LtvA—Illumination Smoothness Loss(照明平滑度损失)
目的
保持相邻像素之间的单调关系。
启发
将所有通道、所有迭代次数的 A (也就是网络的输出),其横竖的梯度平均值应该很小。
公式

-
 :迭代次数
:迭代次数 -
 :水平梯度
:水平梯度 -
 :垂直梯度
:垂直梯度
代码
class L_TV(nn.Module):
def __init__(self,TVLoss_weight=1):
super(L_TV,self).__init__()
self.TVLoss_weight = TVLoss_weight
def forward(self,x):
batch_size = x.size()[0]
h_x = x.size()[2]
w_x = x.size()[3]
count_h = (x.size()[2]-1) * x.size()[3]
count_w = x.size()[2] * (x.size()[3] - 1)
h_tv = torch.pow((x[:,:,1:,:]-x[:,:,:h_x-1,:]),2).sum()
w_tv = torch.pow((x[:,:,:,1:]-x[:,:,:,:w_x-1]),2).sum()
return self.TVLoss_weight*2*(h_tv/count_h+w_tv/count_w)/batch_size首先,定义了一个 TVLoss_weight 属性,表示总变差损失的权重,默认为1。
然后,在向前传播过程中进行如下计算:
- 计算图像在水平方向上的总变差
h_tv和在垂直方向上的总变差w_tv。 - 计算总变差损失(包括水平和垂直方向上的总变差),以及权重调整。
最后,返回计算得到的总变差损失。
四、Zero-DCE代码复现
☀️4.1 环境配置
- Python 3.7
- Pytorch 1.0.0
- opencv
- torchvision 0.2.1
- cuda 10.0
☀️4.2 运行过程
这个运行比较简单,配好环境就行。如果有报错可以参考以下博文:
【代码复现Zero-DCE详解:Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement】_zerodce代码解读-CSDN博客 跑微光图像增强程序遇到的问题汇总_userwarning: nn.functional.tanh is deprecated. use-CSDN博客
暗光增强——Zero-DCE网络推理测试(详细图文教程)-CSDN博客
☀️4.3 运行效果


