广告行业中那些趣事系列68:五花八门的训练范式,你真的了解了吗
导读:本文是“数据拾光者”专栏的第六十八篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要介绍有监督、无监督、半监督、弱监督、蒸馏等五花八门的训练范式。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
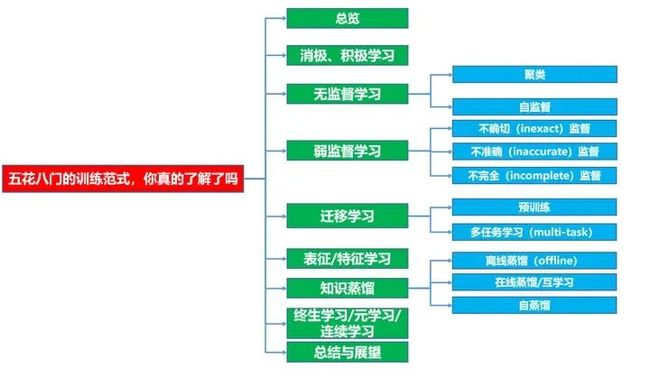
下面主要按照如下思维导图进行学习分享:
本文开始前,咱们先来做个测试:请在10分钟内解释一下以下术语含义以及他们之间的联系——有监督、半监督、弱监督、无监督、自监督、在线蒸馏,离线蒸馏、自蒸馏、预训练、自训练、互训练、联合训练、多标签、多任务、多视角、对抗学习、对比学习、表征学习、表示学习、特征学习、直推学习、归纳学习、迁移学习、主动学习、消极学习、积极学习。通过了测试的大佬,我们下次有缘再见,剩下的各位,我们还是一起来捋一捋吧,捋顺了,无论别人聊啥模型,我们都能掺和几句,既增加沟通效率又能避免尴尬,整个人老精神了!
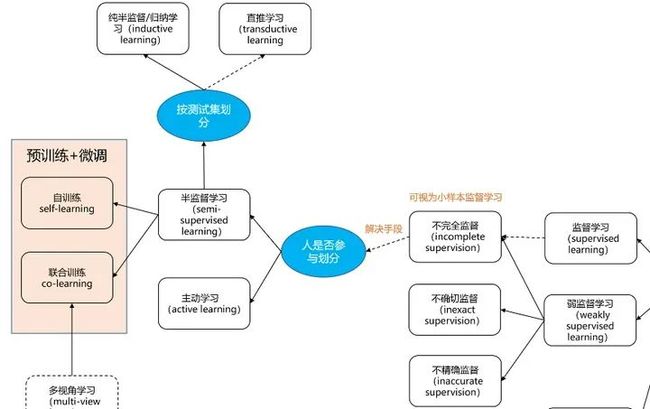
1 总览
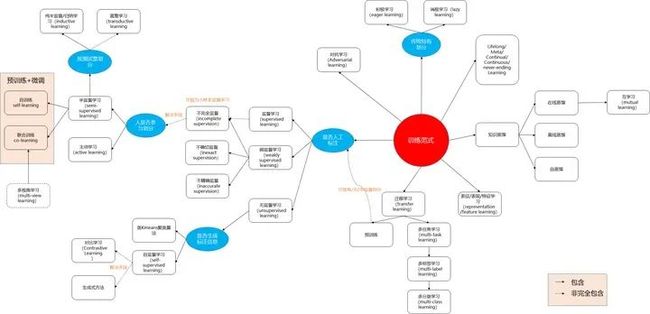
上图是作者通过一些文献总结出来的关系,其中蓝圈是细分的依据。需要说明的是,上图给出的关系并不完全,这是因为很难在现有的训练范式分类(taxonomy)下,完全表示出他们之间的关系,一种训练范式下,可能会涉及到其他范式,导致界限比较模糊。
比如预训练是一种训练范式,半/自/监督也是一种训练范式,但预训练中也可细分分为半/自/监督;又比如对抗学习可单独分为生成式学习,但实际上很多训练范式中的算法,也在尝试对抗学习;又比如表征学习在图中为单独一块儿,表面上“无依无靠”,但其实几乎图中所有的范式都跟它有很大交集。所以这些交叉的关系,都避免在图中被展现(因为图难画,而且就算画出来,估计也很难看,不清晰)
不过没关系,只要我们把每种训练范式的定义搞清楚,上图也就够用了。
2 消极、积极学习
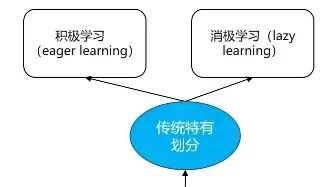
“传统特有划分”指的是,在传统机器学习领域,会有消极、积极的说法,而在深度学习领域,几乎看不到这种说法——因为神经网络本身就属于积极学习。关于他们定义,直接截取网上优质回答(下图),这里不再复述了。

3 无监督学习
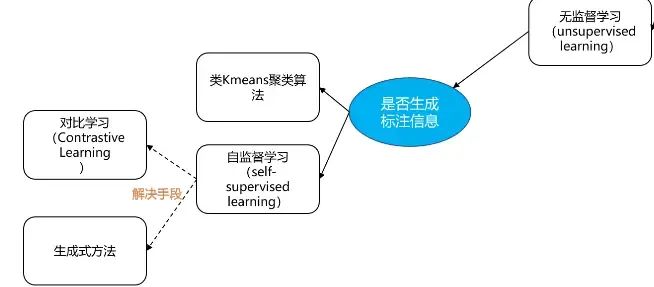
全部使用无标注数据训练
3.1 聚类
聚类算法各位应该都很熟悉了,比如kmeans,它们是传统的无监督算法——对标注信息一点兴趣都没有
3.2 自监督
通常从数据结构本身挖掘出标注信息(监督信息),再进行训练。自监督学习通常出现在pre-text task(辅助任务),如下图所示:

pre-text task算法详情参阅:
CV—— Self-supervised Visual Feature Learning Deep Neural Networks: A Survey
NLP——Self Supervised Representation Learning in NLP
此处仅列出NLP领域的一些做法:
预测中心词
预测邻居词
相邻句子的预测
自回归语言建模
掩码语言建模
下一个句子预测
句子顺序的预测
句子重排
文档旋转
表情符号预测
3.2.1 生成式/对比学习:
推荐文章——对比学习(Contrastive Learning),截图摘要:

4 弱监督学习
推荐文献:
知乎——浅谈弱监督学习(Weakly Supervised Learning)
论文——A brief introduction to weakly supervised learning

4.1 不确切(inexact)监督
标注信息比较粗粒度,如在CV领域,只有图片级别的label,缺乏图中object label;又如分类任务中,只有一级类目label,缺乏子级类目的label。
4.2 不准确(inaccurate)监督
标注信息不准确,比如本来是苹果,结果标注成梨子。
4.3 不完全(incomplete)监督
可视为小样本的监督学习
4.3.1主动学习(active learning)
解决不完全监督问题(小样本监督问题)——通过策略精选出对模型而言的高价值样本,从而减少标注员工作量。
推荐文献:主动学习-Active Learning:如何减少标注代价
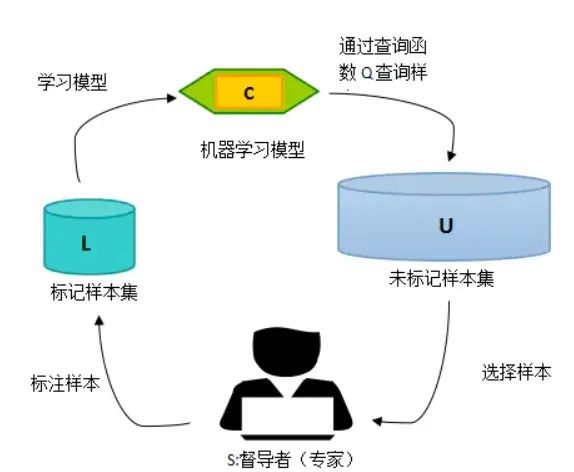
4.3.2 半监督学习(semi-supervised)
解决不完全监督问题(小样本监督问题)——(大量)无标注数据和少量有标注数据一起训练
推荐文献:
知乎——半监督深度学习小结
论文——Semi-Supervised Learning Literature Survey

4.3.2.1 纯半监督/归纳学习(pure semi-/inductive)
从训练样本中学习规则然后应用在测试样本中,换句话说就是,测试集与训练集无交集
4.3.2.2 直推学习(transductive learning)
同时使用训练样本和测试样本来训练模型,然后再次使用测试样本来测试模型效果,即测试集和训练集有交集
4.3.2.3 自训练(self-training)
使用模型本身给无标注数据打上伪标签(pseudo label),然后迭代训练
4.3.2.4 联合训练、多视角学习(co、multi-view)
联合训练属于多视角学习,即将特征拆分为多个子集,每个子集对应一个分类器,分类器A的标注信息,由其他分类器给出
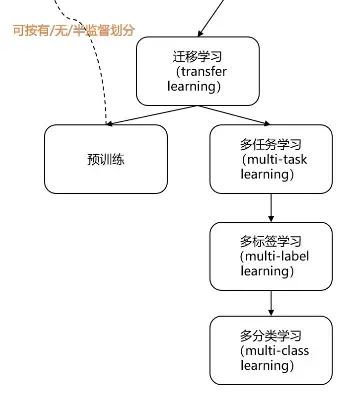
5 迁移学习(transfer learning)
迁移学习科普(知乎高票回答)——什么是迁移学习 (Transfer Learning)?这个领域历史发展前景如何?
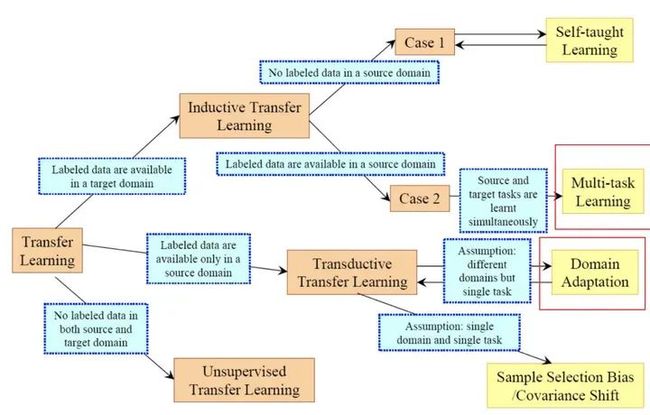
迁移学习简单来说,就是在源域(source domain)上学习好后,将学到的东西迁移到目标域(target domain),是个很广的概念,与各种范式都可以扯上关系(包括知识蒸馏都可以看做源域与目标域相同的迁移学习),需要注意的是,迁移学习不局限于深度学习,但确实是深度学习将它发扬光大的。下图是早期,从源/目标域的标注信息维度,对迁移学习的分类法,其中self-taught(不是self-training)在深度学习中没有再被提起。
介于深度学习这么火热,本文将重点介绍深度学习中的迁移学习:
推荐文献——综述论文:四大类深度迁移学习
| 方法类别 | 简介 | 相关算法 |
| 基于实例(instances-based) | 使用特定的权重调整策略,通过为那些选中的实例分配适当的权重,从源域中选择部分实例作为目标域训练集的补充。它基于这个假设:「尽管两个域之间存在差异,但源域中的部分实例可以分配适当权重供目标域使用」 | 1、TrAdaBoost2、双权重域自适应(BIW) |
| 基于映射(Mapping-based) | 将源域和目标域中的实例映射到新的数据空间。在这个新的数据空间中,来自两个域的实例都相似且适用于联合深度神经网络。基于假设:尽管两个原始域之间存在差异,但它们在精心设计的新数据空间中可能更为相似 | 1、迁移成分分析(TCA)2、多核变量 MMD(MK-MMD)距离代替 MMD 距离3、联合最大均值差异(JMMD)来衡量联合分布的关系 |
| 基于网络(network based) | 复用在源域中预先训练好的部分网络,包括其网络结构和连接参数,将其迁移到目标域中使用的深度神经网络的一部分。基于假设:神经网络类似于人类大脑的处理机制,它是一个迭代且连续的抽象过程。网络的前面层可被视为特征提取器,提取的特征是通用的 | 各种预训练 |
| 基于对抗(adversarial-based) | 引入受生成对抗网络(GAN)启发的对抗技术,以找到适用于源域和目标域的可迁移表征。基于假设:为了有效迁移,良好的表征应该为主要学习任务提供辨判别力,并且在源域和目标域之间不可区分。 | 见论文文献 |
以上可以看到,迁移学习太多太杂了,所以本文关系图中只给出了两个比较热门的方向:预训练、多任务学习
5.1 预训练
上面介绍过,预训练是基于网络的迁移学习,即在源域训练好预训练模型,然后拿到目标域去微调。至于有什么算法?!那说来话长,还是直接上文献和图吧(NLP的):
PTMs| 2020 NLP预训练模型综述
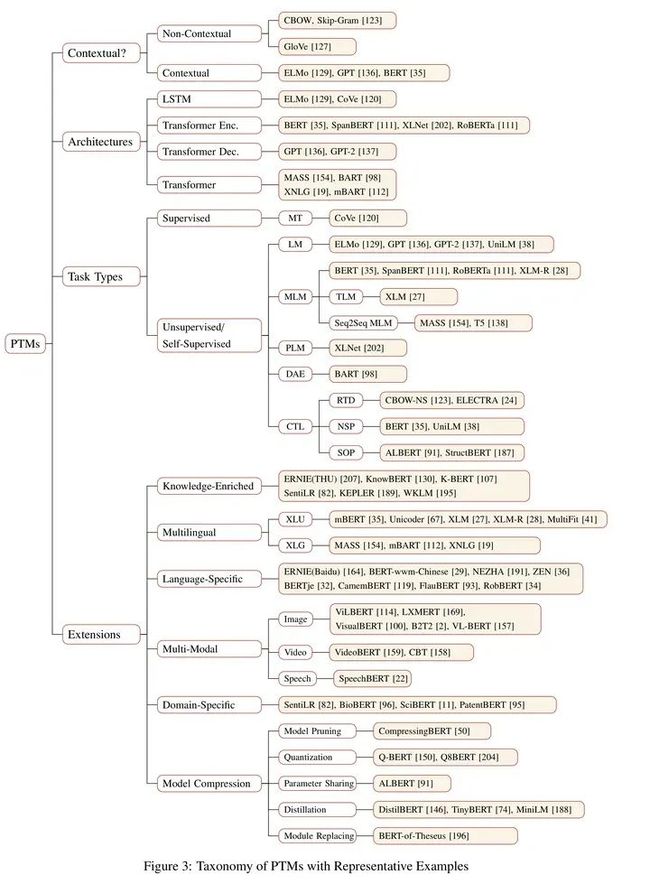
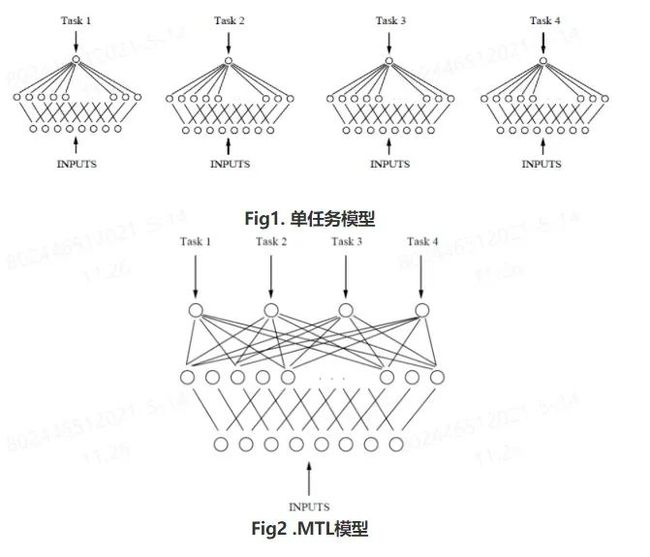
5.2 多任务学习(multi-task)
多任务学习是什么?看这一篇文章就够了:当我们在谈论多任务学习
6 表征/特征学习(representation/feature)
机器学习算法的work与否不仅仅取决于算法的正确选用,也取决于数据的质量和有效的表示(representation)。针对不同类型的数据(text,image,video),不同的表示可能会导致有效信息的缺失或是曝露,这决定了算法能否有效地解决问题。表征学习的目的是对复杂的原始数据化繁为简,把原始数据的无效的或者冗余的信息剔除,把有效信息进行提炼,形成特征(feature)。特征提取可以人为地手工处理,也可以借助特定的算法自动提取。Roughly Speaking, 前者为特征工程,后者为表征学习(Representation Learning)。如果数据量较小,我们可以根据自身的经验和先验知
识,人为地设计出合适的特征,用作下游的任务,比如分类;但数据量很大且复杂时,则需要依赖自动化的表征学习。
什么是Representation Learning?(点我)
虽然在图中表征学习无依无靠,但他跟其他范式都能扯上关系,所以干脆不画了......
7 知识蒸馏(knowledge distillation)
可视为源与目标相同的迁移学习,至于为社么要叫蒸馏,是因为引入T-softmax(带温度的sotmax)后,整个过程跟传统蒸馏过程很像。
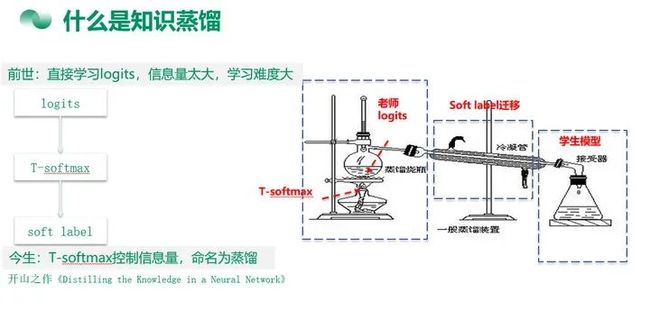
推荐文献:
广告行业中那些趣事系列21:从理论到实战BERT知识蒸馏
广告行业中那些趣事系列67:基于知识蒸馏的在线分类模型
7.1 离线蒸馏(offline)

先离线训练好一个teacher model,然后再进行蒸馏,且蒸馏时只更新student model
7.2 在线蒸馏/互学习(mutual learning)

不用事先训练好teacher model,在蒸馏的过程中同时训练teacher和student,为互学习(mutual learning)
7.3 自蒸馏
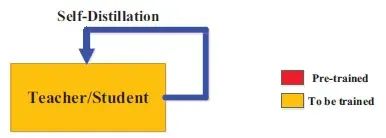
teacher和student一样的结构,相当于teacher在教自己。它跟自训练(self-training)很像,区别是自训练用的是模型自己标注的伪标签(pseudo label),但自蒸馏用的是软标签(soft label)
8 终生学习/元学习/连续学习
名字很多,有lifelong/meta/continual/continuous/never-ending learning,指模型通过不断地学习,具备处理多个task的能力,他跟迁移学习有点像——将已学到的知识用于下一个task的学习中,但与迁移学习不同的是,lifelong的目的是要处理所有task,如同时处理task1和task2,而迁移学习只管将task1的知识迁移到task2,但并不关心是否忘记task1。
推荐文献——2020机器学习前沿技术----LifeLong learning