SQL 分组(分区)排序获取第一条数据 ROW_NUMBER() OVER() PARTITION BY的使用
首先来看下应用场景:
有一张价格 “订单价格设置” 表如下:
商品编号,价格设置时间id(类似于创建时间,创建时间约早,则act_id越小) ,价格的时间段,商品价格
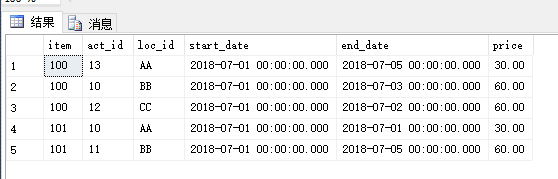
现在要求选出每个商品价格最大,价格设置时间id最大的那条记录,要求先考虑价格,再考虑设置时间
理想的结果:取出的是第3条记录 和第5条记录
思路:将数据根据item分区,再在每个分区中进行排序,先根据价格排序,再根据设置时间id排序,最后取出每个分组的第一条记录
实现:
利用 ROW_NUMBER() OVER(),PARTITION BY,ORDER BY
先直接上代码:
select item,act_id,loc_id,start_date,end_date,price, ROW_NUMBER() over( partition by item order by price desc,act_id desc) as new_index from test1
查询结果如下

可以看到查询出的结果已经进行了分区和进行了一次排序,并且增加了排序标记new_index
接下来只需从结果中查出new_index = 1的记录即为我们想要的结果:
select * from (select item,act_id,loc_id,start_date,end_date,price, ROW_NUMBER() over( partition by item order by price desc,act_id desc) as new_index from test1)b where b.new_index = 1
结果如下:

分析:什么是ROW_NUMBER() OVER()和 PARTITION BY
① ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,
在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
② PARTITION BY 分区函数可以根据某字段分区并返回所有结果集,作为分区函数一般与Row_Number() over()排序一起连用,可实现分区排序的功能
它和聚合函数不同的地方在于它能够返回一个分组中的多条记录,而聚合函数一般只有一个反映统计值的记录。
SqlServer 官方:ROW_NUMBER (Transact-SQL) - SQL Server | Microsoft DocsTransact-SQL reference for the ROW_NUMBER function. This function numbers the output of a result set. https://docs.microsoft.com/en-us/sql/t-sql/functions/row-number-transact-sql?view=sql-server-ver16
https://docs.microsoft.com/en-us/sql/t-sql/functions/row-number-transact-sql?view=sql-server-ver16