Redis
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
守护进程: 守护进程(Daemon Process),也就是通常说的 Daemon 进程(精灵进程),是 Linux 中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。
守护进程是个特殊的孤儿进程,这种进程脱离终端,为什么要脱离终端呢?之所以脱离于终端是为了避免进程被任何终端所产生的信息所打断,其在执行过程中的信息也不在任何终端上显示。由于在 linux 中,每一个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端,这个终端就称为这些进程的控制终端,当控制终端被关闭时,相应的进程都会自动关闭。
·
Redis 数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
redis会周期性的把更新数据写入到磁盘当中或者把修改操作写入追加的记录文件中,并且在此基础上实现了master-slave(主从)同步;
mysql数据库:数据是以文件形式存储到硬盘当中。
运行速度:cpu》内存》硬盘
缓存分为两种:数据缓存,页面缓存(Smarty)
redis的key的限制:除了“/n”和空格不能做为key,剩下的都可以,并且长度不做限制。
redis的key和string类型value限制均为512MB。
springboot使用redisTemplate封装redis
1.连接池自动管理,提供了一个高度封装的“redisTemplate”类
2.针对对jedis的大量操作,封装了api,将同一类操作封装到了operation接口
valueOperations:简单的k-v操作
Setoperations:set类型数据操作
Zsetoperations:zset类型数据操作
HashOperations:针对map类型的数据操作
ListOperations:针对list类型的数据操作
3.提供了对key的bound便捷化操作,可以通过bound封装指定的key,然后进行一系列的操作而无需再次指定key,即boundKeyOperations:
BoundValueOperations
BoundSetOperations
BoundListOperations
BoundSetOperations
BoundHashOperations
4.将事物操作进行了封装,有容器控制
5.针对数据的序列化/反序列化,提供了多种可选择策略
redis的数据类型:
string,链表,集合,zset有序集合,hash map
springboot与redis整合:
1.首先导入依赖
org.springframework.boot
spring-boot-starter-data-redis
2.在配置文件中配置
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器地址
spring.redis.host=127.0.0.1
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1s
# 连接池中的最大空闲连接
spring.redis.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.pool.min-idle=0s
# 连接超时时间(毫秒)
spring.redis.timeout=0s
3,redisTemplate的配置,创建一个redisConfig类,进行相关bean的配置
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
/**
* 选择redis作为默认缓存工具
* @param redisTemplate
* @return
*/
@Bean
public CacheManager cacheManager() {
RedisCacheManager rcm = RedisCacheManager.create(redisConnectionFactory);
return rcm;
}
在springboot2.*中这个构建方法变更了
/**
* retemplate相关配置
* @param factory
* @return
*/
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
RedisTemplate template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
//使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值(默认使用JDK的序列化方式)
Jackson2JsonRedisSerializer jacksonSeial = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jacksonSeial.setObjectMapper(om);
// 值采用json序列化
template.setValueSerializer(jacksonSeial);
//使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
// 设置hash key 和value序列化模式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(jacksonSeial);
template.afterPropertiesSet();
return template;
}
/**
* 对hash类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public HashOperations hashOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForHash();
}
/**
* 对redis字符串类型数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ValueOperations valueOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForValue();
}
/**
* 对链表类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ListOperations listOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForList();
}
/**
* 对无序集合类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public SetOperations setOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForSet();
}
/**
* 对有序集合类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ZSetOperations zSetOperations(RedisTemplate redisTemplate) {
return redisTemplate.opsForZSet();
}
}
redisKit工具类:
@Autowired
protected RedisTemplate, Object> redisTemplate;
/**
* 设置过期时长,单位:秒,
*/
public static final long DEFAULT_EXPIRE = 60 * 60 * 24;
/**
* 不设置过期时长
*/
public static final long NOT_EXPIRE = -1;
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @param value 缓存的值
* @param expire 过期时间(单位:秒),传入 -1 时表示不设置过期时间
* @return 缓存的对象
*/
public boolean setCacheObject(String key, Object value, long expire) {
boolean result = false;
redisTemplate.opsForValue().set(key, value);
if (expire != -1) {
result = redisTemplate.expire(key, expire, TimeUnit.SECONDS);
}
return result;
}
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @return 缓存的对象
*/
public Long setINCR(String key) {
boolean result = false;
Long id = redisTemplate.opsForValue().increment(key, 1);
return id;
}
/**
* 缓存Set
*
* @param key 缓存的键值
* @param value 缓存的值
* @return 受影响行数
*/
public boolean addToSet(String key, String value) {
boolean flag = false;
SetOperations setOperations = redisTemplate.opsForSet();
int result = setOperations.add(key, value).intValue();
if (result > 0) {
flag = true;
}
return flag;
}
/**
* 移除Set集合中的成员
*
* @param key
* @param value
*/
public boolean Srem(String key, String value) {
boolean flag = false;
SetOperations setOperations = redisTemplate.opsForSet();
long result = setOperations.remove(key, value);
if (result > 0) {
flag = true;
}
return flag;
}
/**
* 获取set的值
*
* @param key 缓存的键值
* @return 受影响行数
*/
public Set getSet(String key) {
SetOperations setOperations = redisTemplate.opsForSet();
Set set = setOperations.members(key);
return set;
}
/**
* @param key set集合key
* @Name: 获取set集合元素个数
* @Author: 程文远(作者)
* @Version: V1.00 (版本号)
* @Create Date: 2018年1月29日下午4:05:35
* @Return: 返回个数
*/
public long getSetObjNum(String key) {
SetOperations setOperations = redisTemplate.opsForSet();
return setOperations.size(key);
}
/**
* 删除一个键值
*
* @param key 缓存的键
* @return void
*/
public void delete(String key) {
redisTemplate.delete(key);
}
/**
* 获得缓存的基本对象。
*
* @param key 缓存键值
* @return 缓存键值对应的数据
*/
public Object getCacheObject(String key) {
return redisTemplate.opsForValue().get(key);
}
/**
* 缓存List数据
*
* @param key 缓存的键值
* @param dataList 待缓存的List数据
* @return 缓存的对象
*/
public Object setCacheList(String key, ListdataList) {
ListOperations, Object> listOperation = redisTemplate.opsForList();
if (null != dataList) {
int size = dataList.size();
for (int i = 0; i < size; i++) {
listOperation.rightPush(key, dataList.get(i));
}
}
return listOperation;
}
/**
* 获得缓存的list对象
*
* @param key 缓存的键值
* @return 缓存键值对应的数据
*/
public ListgetCacheList(String key) {ListdataList =new ArrayList();
ListOperations, Object> listOperation = redisTemplate.opsForList();
Long size = listOperation.size(key);
for (int i = 0; i < size; i++) {
dataList.add(listOperation.leftPop(key));
}
return dataList;
}
/**
* 获得缓存的list对象
*
* @param key 缓存的键值
* @return 缓存键值对应的数据
*/
public ListgetCacheList(String key, int start) {
ListOperations, Object> listOperation = redisTemplate.opsForList();
Long size = listOperation.size(key);
return listOperation.range(key, start, size);
}
/**
* 获得缓存的list对象
*
* @param @param key
* @param @param start
* @param @param end
* @param @return
* @return ListT> 返回类型
* @throws
* @Title: range
* @Description: TODO(这里用一句话描述这个方法的作用)
*/
public Listrange(String key, long start, long end) {
ListOperations, Object> listOperation = redisTemplate.opsForList();
return listOperation.range(key, start, end);
}
/**
* list集合长度
*
* @param key
* @return
*/
public Long listSize(String key) {
return redisTemplate.opsForList().size(key);
}
/**
* @param key
* @param index 位置
* @param obj value 值
* @return 状态码
*/
public void listSet(String key, int index, Object obj) {
redisTemplate.opsForList().set(key, index, obj);
}
/**
* 向List尾部追加记录
*
* @param key
* @param obj
* @return 记录总数
*/
public long leftPush(String key, Object obj) {
return redisTemplate.opsForList().leftPush(key, obj);
}
/**
* 向List头部追加记录
*
* @param key
* @param obj
* @return 记录总数
*/
public long rightPush(String key, Object obj) {
return redisTemplate.opsForList().rightPush(key, obj);
}
/**
* 算是删除吧,只保留start与end之间的记录
*
* @param key
* @param start 记录的开始位置(0表示第一条记录)
* @param end 记录的结束位置(如果为-1则表示最后一个,-2,-3以此类推)
* @return 执行状态码
*/
public void trim(String key, int start, int end) {
redisTemplate.opsForList().trim(key, start, end);
}
/**
* 删除List中c条记录,被删除的记录值为value
*
* @param key
* @param i 要删除的数量,如果为负数则从List的尾部检查并删除符合的记录
* @param obj 要匹配的值
* @return 删除后的List中的记录数
*/
public long remove(String key, long i, Object obj) {
return redisTemplate.opsForList().remove(key, i, obj);
}
/**
* 获取key剩余时间
*
* @param key
* @return
*/
public long getTime(String key) {
return redisTemplate.getExpire(key);
}
redis的windows版本安装完毕后,进入到redis所在的目录
开启redis服务端:redis-server.exe redis.windows.conf
开启redis客户端: redis-cli.exe -h 127.0.0.1 -p 6379 -a root
redis深入学习:
redis的五种基本数据类型:string(字符串),hash(字典),list(列表),set(集合),zet(有序集合)
https://github.com/Snailclimb/JavaGuide/blob/master/docs/database/Redis/redis-collection/Redis(1)%E2%80%94%E2%80%945%E7%A7%8D%E5%9F%BA%E6%9C%AC%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84.md
(1)字符串string:
是一种动态字符串,即simple dynamic string。redis为了对内存做极致的优化,不同长度的字符串使用不同的结构体来表示。
C语言的string字符串的长度表示:N+1的字符数组表示长度为N的字符串,并且字符数组的结束的最后一个数组是'\0'结束。这样不符合redis对字符串的安全性和效率以及功能方面的要求。
C语言的存储字符串 的方式造成的问题:
1.获取字符串长度的复杂度为O(N)级别的操作:因为c不保存字符串的长度,每次都需要便利数组
2.不能很好杜绝缓冲区溢出/内存泄露
底层存储字符串的主要两种编码方式为:embstr和raw,一般默认的情况下都是embstr,当字符数大于44个字符的时候就会使用raw进行编码存储,
embstr 编码的存储方式为 将 RedisObject 对象头和 SDS 对象连续存在一起,使用 malloc 方法一次分配内存,而 raw 它需要两次 malloc 分配内存,两个对象头在内存地址上一般是不连续的,它们的结构如下所示:
(2)列表list:
Redis的列表相当于java的linkList,他是链表而不是数组。意为着他的插入和删除会很快,复杂度为O(1),但是索引定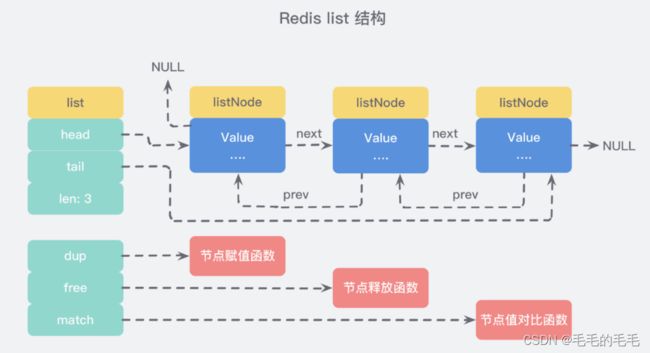 位会很慢,时间复杂度为O(n):
位会很慢,时间复杂度为O(n):
(1)链表的基本操作:
LPush和RPush分别可以向list的左边(头部)和右边(尾部)添加一个新元素
LRange:命令可以从list取出一定范围的
LIndex:命令可以从list中取出指定下表的元素,相当于get(index)操作
(2)list还可以实现队列:队列是先进先出,常用于消息队列和异步处理,他会确保元素的访问顺序
rpush books java python golang
Lpop books
调用三次那么books里的数据就会全部消费完毕
(3)list还可以实现栈,栈是先进后出
Rpush books java python golang
Rpop books
调用三次那么books里的数据就会全部消费完毕
(3)字典(hash)
redis中的字典是相当于java中的HashMap,都是通过“数组+链表”的链地址方法来解决部分哈希冲突的,
他会进行扩缩容的操作。redis中的hash存在两个哈希表,
基本操作:
> HSET books java "think in java" # 命令行的字符串如果包含空格则需要使用引号包裹
(integer) 1
> HSET books python "python cookbook"
(integer) 1
> HGETALL books # key 和 value 间隔出现
1) "java"
2) "think in java"
3) "python"
4) "python cookbook"
> HGET books java
"think in java"
> HSET books java "head first java"
(integer) 0 # 因为是更新操作,所以返回 0
> HMSET books java "effetive java" python "learning python" # 批量操作
OK
(4)set
redis的集合相当于java语言中的Hashset,它内部的键值对是无序的唯一的。他相当于一个特殊的字典,value是null值
> SADD books java
(integer) 1
> SADD books java # 重复
(integer) 0
> SADD books python golang
(integer) 2
> SMEMBERS books # 注意顺序,set 是无序的
1) "java"
2) "python"
3) "golang"
> SISMEMBER books java # 查询某个 value 是否存在,相当于 contains
(integer) 1
> SCARD books # 获取长度
(integer) 3
> SPOP books # 弹出一个
"java"
(5)有序列表Zset
它类似于Sortedsort和hashmap的结合体,一方面他是一个set,保证了内部value的唯一性,另一方面他可以为每个value富裕一个score的值,用来代表排序的权重,
> ZADD books 9.0 "think in java"
> ZADD books 8.9 "java concurrency"
> ZADD books 8.6 "java cookbook"
> ZRANGE books 0 -1 # 按 score 排序列出,参数区间为排名范围
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> ZREVRANGE books 0 -1 # 按 score 逆序列出,参数区间为排名范围
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> ZCARD books # 相当于 count()
(integer) 3
> ZSCORE books "java concurrency" # 获取指定 value 的 score
"8.9000000000000004" # 内部 score 使用 double 类型进行存储,所以存在小数点精度问题
> ZRANK books "java concurrency" # 排名
(integer) 1
> ZRANGEBYSCORE books 0 8.91 # 根据分值区间遍历 zset
1) "java cookbook"
2) "java concurrency"
> ZRANGEBYSCORE books -inf 8.91 withscores # 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代表 infinite,无穷大的意思。
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> ZREM books "java concurrency" # 删除 value
(integer) 1
> ZRANGE books 0 -1
1) "java cookbook"
2) "think in java"
zset使用跳跃表:因为他是随机插入并且使用权重来排序。他是一种随机化的结构,是一种可以媲美平衡树的层次化链表结构。可以快速的查找,删除,添加等。
1.性能考虑:在高并发的情况下,树形结构需要执行一些类似于rebalance这样的可能涉及到整棵树的操作,相对来说跳跃表的变化只涉及到局部
2.实现考虑:在复杂度与红黑树相同的情况下,跳跃表的实现更加简单。
redis的缓存穿透,缓存击穿,缓存雪崩:
缓存穿透:redis的key值所对应的数据源value并不存在,每次针对此key获取不到对应的value,都要去请求数据源mysql,给mysql造成极大压力,来压垮数据库。
解决方案:使用布隆过滤器。我们把所有有可能数据存储到一个较大的bitmap中,所有查询的key进行一遍过滤,不存在就不去查了,另外一种就是查不到去数据源查找也没有,就直接给他设置为null,不用频繁去数据源查询了。
缓存击穿:
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩:
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
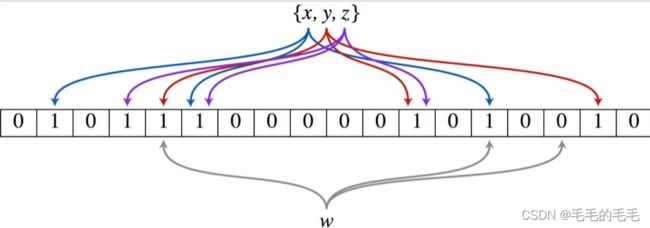
布隆过滤器:布隆过滤器其中重要的实现就是位图的实现,也就是位数组,并且在这个数组中每一个位置只占有1个bit,而每个bit只有0和1两种状态假设一种有k个哈希函数,且每个哈希函数的输出范围都大于m,接着将输出值对k取余(%m),就会得到k个[0, m-1]的值,由于每个哈希函数之间相互独立,因此这k个数也相互独立,最后将这k个数对应到bitarray上并标记为1(涂黑)。等判断时,将输入对象经过这k个哈希函数计算得到k个值,然后判断对应bitarray的k个位置是否都为1(是否标黑),如果有一个不为黑,那么这个输入对象则不在这个集合中,也就不是黑名单了!如果都是黑,那说明在集合中,但有可能会误,由于当输入对象过多,而集合也就是bitarray过小,则会出现大部分为黑的情况,那样就容易发生误判!因此使用布隆过滤器是需要容忍错误率的,即使很低很低!
:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
redis应用场景:
1.聊一聊redis的五大类型:string,hash,list,set,zset
2.绝大多数公司用于做缓存
3.为的是服务的无状态,解耦合,通过redis可以去做分布式锁
4.无锁化,所有操作是串行
redis是单线程还是多线程:
无论是什么版本的redis,工作线程就只有一个,6.*版本的高版本出现了IO多线程;面向IO编程,内核,从内核把数据搬运到程序,