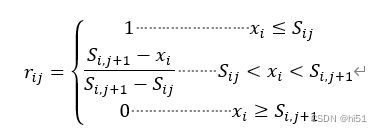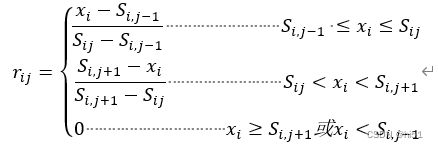| from flask import Flask,request,jsonify,Response
from flask.views import MethodView
import arcpy
import psycopg2
from flask_cors import CORS#跨域请求伪造
import geopandas as gpd
import json
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd @app.route('/mohupj')
def mohupj():
# 读取数据集
readfile = pd.read_excel(r"D:\junior_year_2\Webgis开发小组\data\上海站点\上海站点\shanghai0202.xlsx")
lists = [1, 2, 3, 4, 5, 6, 7, 8, 9] ##获取各个站点的行数据
jiancedianname = []
for n1 in lists:
jiance_ = readfile.iloc[n1 - 1, 1] ##获取城市名称
jiancedianname.append(jiance_)
print(jiancedianname) ##监测点名称
print("监测点数量:")
print(len(jiancedianname))
# 环境空气质量等级及对应的污染物项目浓度限值
dataparameters = [[15, 35, 75, 120],
[40, 70, 140, 210],
[20, 60, 100, 140],
[20, 40, 60, 80],
[100, 160, 220, 280],
[2, 4, 6, 8]]
parameters = pd.DataFrame(dataparameters, index=["PM2.5", "PM10", "SO2", "NO2", "O3", "CO"], columns=[0, 1, 2, 3])
# print(parameters.iloc[1,0]) #parameters.iloc[i,j]获得第i行第j列的数据
'''#建立隶属度函数 采用降半阶梯形隶属度函数'''
def lishudu(pollution):
V = pd.DataFrame({}, index=["PM2.5", "PM10", "SO2", "NO2", "O3", "CO"], columns=[0, 1, 2, 3])
colu = 0
while colu <= 3:
if colu == 0:
# 对于第1污染等级
row = 0
while row <= 5:
if (pollution.iloc[row, 0] <= parameters.iloc[row, colu]):
V.iloc[row, colu] = 1
if (pollution.iloc[row, 0] < parameters.iloc[row, colu + 1] and pollution.iloc[row, 0] >
parameters.iloc[row, colu]):
V.iloc[row, colu] = ((parameters.iloc[row, colu + 1]) - (pollution.iloc[row, 0])) / (
(parameters.iloc[row, colu + 1]) - (parameters.iloc[row, colu]))
if (pollution.iloc[row, 0] >= parameters.iloc[row, colu + 1]):
V.iloc[row, colu] = 0
row = row + 1
if colu == 1 or colu == 2: # 对于2 3等级
row = 0
while row <= 5:
if (pollution.iloc[row, 0] >= parameters.iloc[row, colu + 1] or pollution.iloc[row, 0] <
parameters.iloc[row, colu - 1]):
V.iloc[row, colu] = 0
if (parameters.iloc[row, colu] < pollution.iloc[row, 0] and pollution.iloc[row, 0] <
parameters.iloc[row, colu + 1]):
V.iloc[row, colu] = ((parameters.iloc[row, colu + 1]) - (pollution.iloc[row, 0])) / (
(parameters.iloc[row, colu + 1]) - (parameters.iloc[row, colu]))
if (parameters.iloc[row, colu - 1] <= pollution.iloc[row, 0] and pollution.iloc[row, 0] <=
parameters.iloc[row, colu]):
V.iloc[row, colu] = ((pollution.iloc[row, 0] - parameters.iloc[row, colu - 1])) / (
(parameters.iloc[row, colu] - parameters.iloc[row, colu - 1]))
row = row + 1
if colu == 3: # 对于4等级
row = 0
while row <= 5:
if (pollution.iloc[row, 0] >= parameters.iloc[row, colu]):
V.iloc[row, colu] = 1
if (pollution.iloc[row, 0] <= parameters.iloc[row, colu - 1]):
V.iloc[row, colu] = 0
if (parameters.iloc[row, colu - 1] < pollution.iloc[row, 0] and pollution.iloc[row, 0] <
parameters.iloc[row, colu]):
V.iloc[row, colu] = ((pollution.iloc[row, 0]) - (parameters.iloc[row, colu - 1])) / (
(parameters.iloc[row, colu]) - (parameters.iloc[row, colu - 1]))
row = row + 1
colu = colu + 1
return V
lishududangeresult = [] ##输入每个监测点的隶属度
jiancepollution = [] # 监测点中各个污染物的数据
for n1 in lists:
a = (readfile.iloc[(n1 - 1):n1, [6, 7, 8, 9, 10, 11]])
# #读取每个因素的值
datapollution = [int(a.iloc[0, 0]),
int(a.iloc[0, 1]),
int(a.iloc[0, 2]),
int(a.iloc[0, 3]),
int(a.iloc[0, 4]),
int(a.iloc[0, 5])]
pollution = pd.DataFrame(datapollution, index=["PM2.5", "PM10", "SO2", "NO2", "O3", "CO"], columns=[0])
jiancepollution.append(pollution) ###获得整体所有的污染物数据
result = lishudu(pollution)
lishududangeresult.append(result)
print("各个监测点隶属度结果:")
print(lishududangeresult)
print("第二个监测点隶属度结果:")
print(lishududangeresult[1])
pingjiaave = [] ##存储所有评价因子的平均值
'''求每个评价因子浓度限差平均值'''
for pjitem in dataparameters: ##pjitemave为每个类型评价因子对应的各个等级的限差
pjitemave = sum(pjitem) / len(pjitem)
pingjiaave.append(pjitemave) ##将各个评价因子的平均值存入列表
quanzhongall = [] ##存储所有监测点污染物权重值
print("所有评价因子的平均值")
print(pingjiaave)
for item in jiancepollution:
'''求权重系数分母'''
for n in range(len(pingjiaave)):
quanzhongFMsum = [] ##做为中间量存储单个监测点污染物权重值
m = len(item) ####评价因子的个数为 6
for p in range(m):
quanzhongFZ = item[0][p] / pingjiaave[n]
quanzhongFMsum.append(quanzhongFZ) ####将全部的分子结果存入列表中
p = p + 1
FM = sum(quanzhongFMsum) ##得到权重计算的分母
quanzhongtemp = [] ##得到单个监测点的权重
for i in range(m):
result1 = (item[0][i] / pingjiaave[n]) / FM
quanzhongtemp.append(result1) ###将单个监测点权重存入列表
quanzhongall.append(quanzhongtemp)
break ###跳出当前循环
continue ###跳出当前循环
n = n + 1
print("全部权重集:")
print(quanzhongall) #####获得9个监测点的污染物权重集
print("全部权重集长度:")
print(len(quanzhongall))
print("第二个测站点权重集:")
print(quanzhongall[1])
mohupjresultall_value = [] ##存储所有监测点模糊评价结果 数值
mohupjresultall_index = [] ##存储所有监测点模糊评价结果 等级
'''对每个监测点进行模糊评价'''
for num in range(len(jiancedianname)):
mohupjresult = [] ##存储单个监测点的评价结果
quanzhongdg = quanzhongall[num] ##单个监测点权重集
lishududg = lishududangeresult[num] ##单个监测点隶属度集
mohupjresult = np.dot(quanzhongdg, lishududg) # 矩阵乘法 得到复合运算结果
print("单个监测点模糊评价初步结果")
print(mohupjresult)
'''根据最大隶属度原则找到对应的等级以及其数值'''
max_value = max(mohupjresult)
max_index = np.where(mohupjresult == max_value)
mohupjresultall_index.append(max_index[0][0])
# mohupjresultfinal.append(max_index)
mohupjresultall_value.append(max_value)
num = num + 1
print("各个站点最终模糊评价结果:")
print("对应等级:")
print(mohupjresultall_index)
print("结果数值")
print(mohupjresultall_value)
##创建包含int64类型的数据数组
mohupjresultall_index_=np.array(mohupjresultall_index,dtype=np.int64)
#将int64类型的数据转换为int类型
mohupjresultall_index_2=mohupjresultall_index_.astype(int).tolist()
data = []
for value, level, name in zip(mohupjresultall_value,mohupjresultall_index_2, jiancedianname):
entry = {
"value": value,
"level": level,
"name": name
}
data.append(entry)
json_result = json.dumps(data, indent=4)
return json_result |