Redis的bitmap使用不当,我内存爆了
背景
最近发现Redis的内存持续暴涨, 涨的有点吓人,机器都快扛不住了,不得不进行Redis内存可视化分析,发现大量的String类型的大key
经分析,最近上线了页面UV的统计,那目前如何做的呢?
- 通过访客的IP地址来标识和追踪访客。当一个访问者首次访问网站时,服务器会记录其IP地址,并将其计算为一个UV。随后,如果同一IP地址再次访问网站,服务器将不会将其计算为一个UV。
- 将IP地址转换为整数,用位图(Bitmap)进行存储IP,实现UV的统计
这方案看上去没啥问题,也达到了去重的效果,统计也比较精确,内存占用率也低(bitmap优势就是内存占用率低),那为什么实际内存占用的这么夸张呢?我接着继续分析。
IP4
IP4介绍
目前的全球因特网所采用的协议族是TCP/IP协议族。IP是TCP/IP协议族中网络层的协议,是TCP/IP协议族的核心协议。IP协议定义了一种地址编码,称为IP地址,它是网络中网络段、网络设备接口、主机的编码,它并不是一种物理地址,而是逻辑地址,即地址是可以被分配、并且非固定、可修改的。
IPv4,是互联网协议(Internet Protocol,IP)的第四版,也是第一个被广泛使用,构成现今互联网技术的基石的协议。1981年 Jon Postel 在RFC791中定义了IP,IP可以运行在各种各样的底层网络上,比如端对端的串行数据链路、卫星链路等等。局域网中最常用的是以太网。
IPv4的下一个版本就是IPv6,IPv6正处在不断发展和完善的过程中,它在不久的将来将取代目前被广泛使用的IPv4。
ip4构成
IP地址有是一个32位的二进制数逻辑地址。因此,除了全0,拥有2的32次方-1个地址。全0地址用来表示一个无效的,未知的,或者不可用的目标。
为了方便使用,把这32位二进制数分成八位一组,被称为八位组(octet)。每个八位组书写时用点分十进制的格式标识。每个八位组取值为0000000011111111(二进制数),使用十进制数表示则值为0255。
二进制与十进制的转化非常简单,用二进制数的每一位乘以2的N次方,N是相应的位,从低位到高位以0次方开始,将二进制是1的每位结果相加得到的就是相应的十进制数。
IP地址分类
IP地址(0.0.0.0——255.255.255.254)分类:
A类:
0.0.0.0—127.255.255.255 (其中私有:10.0.0.0—10.255.255.255,保留:0.0.0.0,127.0.0.0—127.255.255.255)
B类:
128.0.0.1—191.255.255.254(其中私有:172.16.0.0—172.31.255.255,保留:169.254.0.0-169.254.255.255,191.255.255.255是广播地址,不能分配)
C类:
192.0.0.1—223.255.255.254(其中:私有:192.168.0.0—192.168.255.255)
D类:
224.0.0.1—239.255.255.254
E类:
240.0.0.1—255.255.255.254
什么是公网IP(外网IP)
公网IP就是除了保留IP地址以外的IP地址,可以与Internet上的其他计算机随意互相访问。我们通常所说的IP地址,其实就是指的公网IP。互联网上的每台计算机都有一个独立的IP地址,该IP地址唯一确定互联网上的一台计算机。
IP如何转为整数
把一个IPv4地址的每段可以看成是一个0-255的整数,先把每段拆分成一个二进制形式组合起来,然后把这个二进制数转变成一个长整数。
以10.0.3.193这个IP地址为例:
| 每段数字 | 相对应的二进制数 |
|---|---|
| 10 | 00001010 |
| 0 | 00000000 |
| 3 | 00000011 |
| 193 | 11000001 |
组合起来即为:00001010 00000000 00000011 11000001,转换为十进制数就是:167773121,所以10.0.3.193这个IPv4地址转换为Int数字就是167773121。
得到数字 167773121,作为bitmap 的偏移量
BitMap
BitMap可以看下如何统计百万用户在线状态-bitmap这篇文章,有详细的介绍,这里就简单分析下:
BitMap 原本的含义是用一个比特位来映射某个元素的状态。由于一个比特位只能表示 0 和 1 两种状态,所以 BitMap 能映射的状态有限,但是使用比特位的优势是能大量的节省内存空间。
在 Redis 中,可以把 Bitmaps 想象成一个以比特位为单位的数组,数组的每个单元只能存储0和1,数组的下标在 Bitmaps 中叫做偏移量。

位图不是实际的数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全 blob,其最大长度为 512 MB,因此它们适合设置最多 2^32 个不同位。
例子: 10.0.3.193 ****这个IP访问了页面page1
10.0.3.193 转换为数字167773121,167773121作为bitmap 的偏移量,值设置为1
setbit uv:page1 167773121 1
# 统计
内存分析
页面page1,第一次被10.0.3.193 访问,进行记录,偏移量是167773121
1Byte(Byte 字节) = 8Bit
167773121/8/1024/1024=20MB
一次就分配了20mb的内存空间,前面的空间就造成了浪费,使用都是后面的位
如果IP是224开头,比如:224.1.2.1,转为数字3758162433
3758162433/8/1024/1024=448MB
一次就分配448mb,这样的统计页面如果有上万个,我们的资源根本没法承受,想想都可怕
如何优化呢?分段统计
分段统计
IPv4地址是一个32位的二进制数,每8位作为一段,分为四段进行储存,比如:10.255.1.12分割,如图:
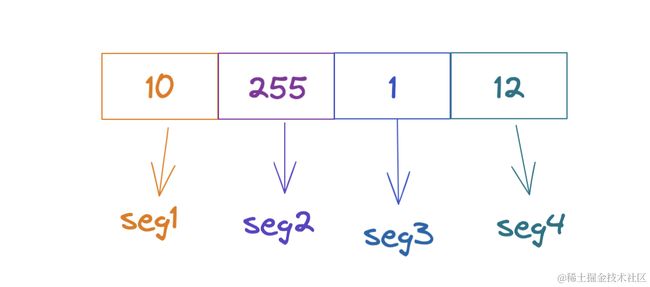
# 第一段
setbit uv:page1:seg1 10 1
# 第二段
setbit uv:page1:seg2 255 1
# 第三段
setbit uv:page1:seg3 1 1
# 第四段
setbit uv:page1:seg4 12 1
最大偏移量值是255位,四段占用内存:4*255/8/1024=0.12kb
假设10w个页面进行统计,10000*0.12kb=121mb ,最大内存也只占用121mb。统计的页面越多,效果也是明显。不过这里有个问题,都分段了,那如果统计这个页面的uv呢,没分段之前,我们可以
bitcount uv:page1
分段之后,
# 第一段
bitcount uv:page1:seg1
# 第二段
bitcount uv:page1:seg2
# 第三段
bitcount uv:page1:seg3
# 第四段
bitcount uv:page1:seg4
统计分段后的四个key,然后相加吗,明显不对,那怎么办呢?
# 第一段
setbit uv:page1:seg1 10 1
# 第二段
setbit uv:page1:seg2 255 1
# 第三段
setbit uv:page1:seg3 1 1
# 第四段
setbit uv:page1:seg4 12 1
# 记录UV,上面四个只要有一个返回0,说明是一个新的IP,那就加1
INCR uv:page1
#统计uv
get uv:page1
使用Jedis客户端代码实现
public static void main(String[] args) {
Jedis jedis = new Jedis("10.1.250.157", 6379);
jedis.auth("google00");
jedis.del("ip");
//添加四个IP统计uv,有一个是重复的,访问页面page1
List ipList = new ArrayList<>();
ipList.add("10.1.255.10");
ipList.add("255.1.255.10");
ipList.add("10.1.195.10");
ipList.add("10.1.255.10");
for (String ip : ipList) {
String[] ips = ip.split("\.");
boolean seg1 = jedis.setbit("uv:page1:seg1",Long.valueOf(ips[0]).longValue(),true);
boolean seg2 = jedis.setbit("uv:page1:seg2",Long.valueOf(ips[1]).longValue(),true);
boolean seg3 = jedis.setbit("uv:page1:seg3",Long.valueOf(ips[2]).longValue(),true);
boolean seg4 = jedis.setbit("uv:page1:seg4",Long.valueOf(ips[3]).longValue(),true);
if (seg1&&seg2&&seg3&seg4){
System.out.println(ip+"已访问过");
}else {
jedis.incr("uv:page1");
}
}
String uv = jedis.get("uv:page1");
System.out.println("页面page1的UV为:"+uv);
}
结果:
10.1.255.10已访问过
页面page1的UV为:3
小结
bitmap最大的优势是节约内存空间,但是在使用的时候,需要根据实际的场景分析,上面的例子,就是没考虑偏移量的浪费。好多时候,理论跟实际差距还是有的,多实践。