redis-----04-----redis-hash结构以及应用
1 hash
字典结构,通过 hash 函数(而不是通过比较 key 的方式)来确定节点的位置,很多高级语言包含
这个数据结构,例如 c++ 中 unordered_map,go 语言当中的 map 结构。
redis的底层是使用数组加双向链表来实现hash结构的。
2 基础命令
详细命令请查看http://redis.cn/commands.html。
2.1 HSET、HGET、HMSET、HMGET、HGETALL
# 设置 key 对应 hash 中的 field 对应的值。
# 返回值integer-reply:含义如下,
# 1 如果field是一个新的字段。
# 0 如果field原来在map里面已经存在。
HSET key field value
# 获取 key 对应 hash 中的 field 对应的值。
# 返回值bulk-string-reply:返回key对应字段field所关联的值。当字段不存在 或者 key 不存在时返回nil。
HGET key field
# 设置多个hash键值对。
# 返回值:成功是OK字符串,失败返回失败的字符串。
HMSET key field value [field value ...]
# 获取多个field的值。
# 返回值array-reply:含有给定字段及其值的列表,并保持与请求相同的顺序。
# 对于哈希集(指所有字段field或者指key)中不存在的每个字段,返回 nil 值。因为不存在的key被认为是一个空的哈希集,对一个不存在的 key 执行 HMGET 将返回一个只含有 nil 值的列表。
HMGET key field [field ...]
# 获取该key的所有fields。
# 返回值array-reply:哈希集中字段和值的列表。当 key 指定的哈希集不存在时返回空列表。
# 返回值中,每个字段名的下一个是它的值,所以返回值的长度是哈希集大小的两倍。
HGETALL key
- HSET、HGET结果:
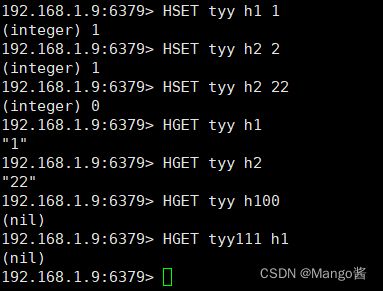
- HMSET、HMGET结果(都是主要按照上面的文字来进行验证的):
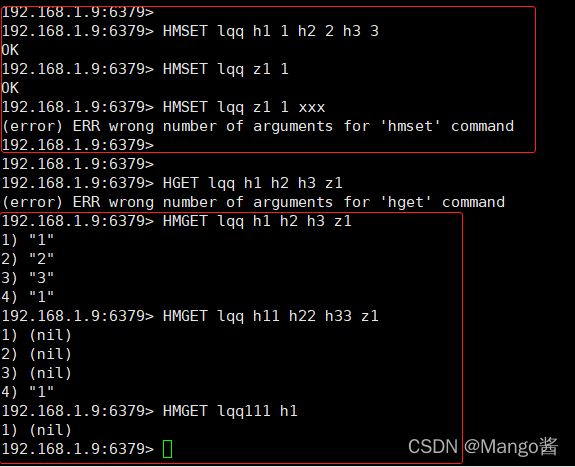
- HGETALL结果:

2.2 HINCRBY、HLEN、HDEL
# 给 key 对应 hash 中的 field 对应的值加一个整数值。
# 增加 key 指定的哈希集中指定字段的数值。
# 如果 key 不存在,会创建一个新的哈希集并与 key 关联。
# 如果字段不存在,则字段的值在该操作执行前被设置为 0。
# HINCRBY 支持的值的范围限定在 64位 有符号整数。
# 返回值integer-reply:增值操作执行后的该字段的值。
HINCRBY key field increment
# 获取 key 对应的 hash 有多少个键值对。
# 返回值integer-reply: 哈希集中字段的数量,当 key 指定的哈希集不存在即key不存在时返回 0。
HLEN key
# 删除 key 对应的 hash 的键值对,该键为field。
# 从 key 指定的哈希集中移除指定的域。在哈希集中不存在的域将被忽略。
# 如果 key 指定的哈希集即key不存在,它将被认为是一个空的哈希集,该命令将返回0。
# 返回值integer-reply: 返回从哈希集中成功移除的域的数量。
HDEL key field [field ...]
上面三个命令的结果(主要按照文字来验证):

3 存储结构
hash当节点数量少的时候(512个)且字符串长度小(64的长度)的时候,内部采用压缩列表存储,否则采用字典实现。
- 采用压缩列表存储,压缩列表也是数组实现的。在C/C++中,数组内存都是连续的。
- 如果节点太大或者字符串长度太大,那么采用字典,内部是采用数组加链表实现的。
实际上我们不需要记得那么清楚,只需要了解一下即可,我们只要记得hash是使用数组加链表实现即可,但它也有可能是只使用压缩列表即只用数组实现。
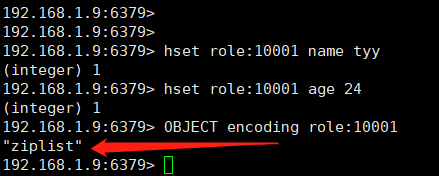
例如举个简单使用压缩列表(即数组)实现的hash结构的例子:
结果并分析:由于key的节点只有name和age,非常少,且字符串长度小,那么肯定会使用ziplist存储hash。
4 应用
4.1 存储对象
hash存储对象是非常方便的。且对该对象内容的添加、修改、删除也是非常方便的,我们只需要对某一个字段进行操作即可。例如:
1)先输入一个对象的信息。
hmset role:10001 name tyy age 18 sex male
2)此时对该对象增加money工资的字段。
hset role:10001 money 20000
# 查看添加money字段后的对象信息。
HGETALL role:10001
删除和添加同理,使用hdel即可,这里不演示了。
3)然后对该对象的money进行修改。
HSET role:10001 money 19000
HGETALL role:10001
#或者使用HINCRBY,效果一样。
HINCRBY role:10001 money -1000
HGETALL role:10001
结果:

之前讲过,string结构同样可以存储对象的信息,但是只能存储对象信息不经常改变或者固定的才行,否则效率非常低。如果对象的信息经常改动,那么应该使用上面的hash存储。
对比string:
使用string想要修改类似上面money的值,那么string需要这样处理:
1)首先加上redis已经存储有role:10001这个对象信息。
set role:10001 '{["name"]:"tyy",["sex"]:"male",["age"]:18, ["money"]:20000}'
2)那么程序需要先get获取信息。
get role:10001
3)将得到的字符串调用json.decode解密,取出字段,修改 money 值
4)# 再调用json加密。
5)最后set回字符串到redis。
set role:10001 '{["name"]:"tyy",["sex"]:"male",["age"]:18, ["money"]:18000}'
最终看到上面使用string对有修改需求的对象信息非常的麻烦。
而使用hash,只需要在代码执行一句命令即可,效率显而易见了。
HSET role:10001 money 18000
4.2 购物车

平时我们网购会经常看到购物车的功能实现。那么redis如何实现这个功能呢?
我们以购物车的举个例子:
- 1)分析实现购物车需要用到的redis结构。
# 1)
# 将用户id作为 key。
# 商品id作为 field。
# 商品数量作为 value。
# 所以这里需要用到一个hash结构。
# 注意:
# 2)由于还包含商品的图片、商品主题描述等其它属性,所以我们需要额外的hash结构来存储。其中key为上面第一点hash结构的商品id,field为商品属性,value为属性内容。
# 3)这些物品是按照我们添加顺序来显示的;所以需要一个链表来处理顺序的问题。其中key为用户id,value为商品id。
通过上面分析,我们就知道,实现这个购物车需要两个hash结构,以及一个链表结构。第一个hash用来区别不同用户保存的商品,第二个hash用来区别同一个用户中不同商品的属性,;链表则用来处理购物车的先后顺序。下面来操作一下命令:
- 2)具体操作:
# 1.添加商品:
HSET MyCart:10001 40001 1
HMSET Item:40001 picture xxx.png text "t-shift"
LPUSH MyItem:10001 40001
# 2.增加、减少某个商品的购买数量:
HINCRBY MyCart:10001 40001 2
HINCRBY MyCart:10001 40001 -1
# 3.显示某个用户购物车中所有的物品数量(例如上图中左上角的全部数量14):
HLEN MyCart:10001
# 4.删除用户购物车中的一个商品:
HDEL MyCart:10001 40001
DEL Item:40001
LREM MyItem:10001 1 40001
# 5.获取所有物品:
LRANGE MyItem:10001 0 -1
# 按照上面操作后此时是一个空链表,即购物车中没有物品,所以我们先添加几个进去,以便观察。
HSET MyCart:10001 40001 2
HMSET Item:40001 picture xxx.png text "t-shift"
LPUSH MyItem:10001 40002
HSET MyCart:10001 40002 1
HMSET Item:40002 picture xxx2.png text "computer"
LPUSH MyItem:10001 40002
HSET MyCart:10001 40003 1
HMSET Item:40003 picture xxx3.png text "iphone"
LPUSH MyItem:10001 40003
# 正式开始获取所有物品
LRANGE MyItem:10001 0 -1
HGET MyCart:10001 40001
HGET MyCart:10001 40002
HGET MyCart:10001 40003
运行结果:

- 3)思考,其实个人觉得,如果觉得上面结构用得比较多,我们可以减少一个hash结构的使用,即减少商品的属性的那个hash。但是这样在用户id为key的那个hash中,存储的value就不能是商品的数量了,而是商品的属性,以json字符串保存。这样处理,即使这个json经常会被修改,处理起来也是很方便的。大家可以按照自己的场景来实现,和上面的效率应该差不多,并且管理的数据结构减少了。
命令就不写出来了,直接看下图即可:

这样redis的hash结构就学习到这里了。