Kafka_03_Consumer详解
Kafka_03_Consumer详解
- Consumer
-
- 消费消息
-
- 订阅/拉取
- ConsumerRecord
- 消费位移
-
- 位移提交
- 位移消费
- 实现原理
-
- Rebalance
- ConsumerInterceptor
- DeSerializer
- 多线程消费
-
- 消费线程
- 处理线程
Consumer
Consumer(消费者): 从Partition拉取并消费消息(非线程安全)
- Topic的Partition在每个消费者组中有且仅能由一个Consumer消费
- 若Consumer数量多于Partition, 则部分Consumer空闲(无对应Partition)
- 每个Consumer仅能消费从消费者组中分配到或单独订阅Partition所含消息
Partition分配策略: 定义Consumer对订阅Topic下的Partition的划分
| 分配策略 | 说明 |
|---|---|
| RangeAssignor (默认) |
Partition按跨度依次分配给Consumer (跨度 = Partition数量 / Consumer数量) |
| RoundRobinAssignor | 轮询方式依次将Partition分配给Consumer (轮询前会先按照字典序对Consumer和Partition进行排序) (分配给Consumer的Partition必须是订阅Topic下的Partition, 否则将略过) |
| StickyAssignor | 在RoundRobinAssignor的基础上尽可能保持黏性分配 |
// 以下均以RangeAssignor分配策略说明, 可通过partition.assignment.strategy参数更改
消费者组(Consumer Group): 多个Consumer组成的消费群体
- Topic可被订阅的消费者组下任意个Consumer消费
- Consumer通过
group.id参数指定所属消费者组 - 每个Consumer有且仅有一个消费者组
- 消费者组之间无法感知(互不影响)
如:A消费者组和B消费者组订阅相同的Topic
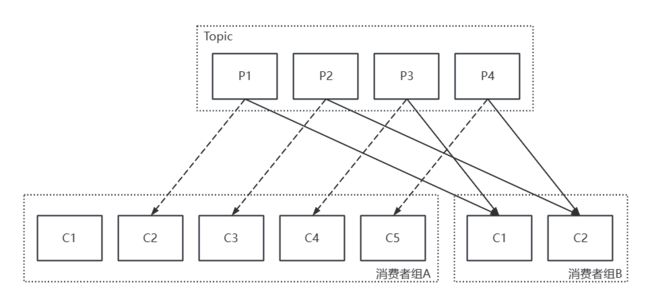
- 若Topic对应的所有Consumer都属于相同的消费者组, 则为点对点(P2P)
- 若Topic对应的所有Consumer属于不同的消费者组, 则为发布/订阅(Pub/Sub)
Consumer客户端消费消息大致逻辑:
- 配置Consumer客户端参数并创建该Consumer实例
- 订阅Topic, 拉取并消费消息(位移提交)
- 关闭实例
构建Consumer客户端必填的4个参数:
| 参数 | 说明 |
|---|---|
| bootstrap.servers | 引导程序的服务地址 格式: 地址1:端口1,地址N:端口N(建议指定两个以上的Broker地址以保证稳定性, 且使用主机名形式) |
| group.id | Consumer所属消费者组 |
| key.derializer | 消费时对Key调用的反序列化器 Broker仅能接受字节数组形式的消息 byte[] |
| value.derializer | 消费时对Value调用的反序列化器 Broker仅能接受字节数组形式的消息 byte[] |
// 序列化器必须以全限定名方式指定, Java的ConsumerConfig类中包含所有的配置参数
close()和wakeup()方法的定义:
// 关闭Consumer
// timeout参数指定关闭的超时时间(默认30s)
public void close();
public void close(Duration timeout);
// 唤醒Consumer
// 该方法是唯一的线程安全方法
// 若唤醒阻塞的Consumer, 则抛出WakeupException
public void wakeup();
消费消息
消费消息: 订阅Topic使Consumer消费特定Partition
Topic和Partition的定义:
// Partition构成
public final class TopicPartition implements Serializable {
private int hash = 0; // 每个TopicPartition的唯一标识
private final int partition; // 所属Topic
private final String topic; // Partition编号
// 其他方法省略(构造函数和属性提取等)
}
// Topic元数据信息
// 该信息可通过Consumer的partitionsFor()方法获取(List集合形式返回)
public class PartitionInfo {
private final String topic; // Topic编号
private final int partition; // Partition编号
private final Node leader; // leader副本所在的Partition
private final Node[] replicas; // AR
private final Node[] inSyncReplicas; // ISR
private final Node[] offlineReplicas; // OSR
// 其他方法省略(构造函数和属性提取等)
}
订阅/拉取
订阅(Subscribe): Consumer订阅个Topic/Partition以消费Partition
- Consumer可单独订阅Partition, 但其会脱离消费者组管理
- 单独订阅Partition还会导致Consumer的自动再均衡失效
- Consumer可订阅多个Topic(可分配到多个Partition)
- 若Conuser进行多次订阅操作, 则以最后次为准
- 两种形式的订阅都可被取消
subscribe()和assign()方法的定义:
// 订阅集合中所有的Topic
// ConsumerRebalanceListener(再均衡监听器):监听特殊事件以触发再均衡
public void subscribe(Collection<String> topics);
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener);
// 订阅所有匹配正则表达式的Topic
// 若后续新创建的Topic满足正则表达式, 则会自动订阅该Topic
// ConsumerRebalanceListener(再均衡监听器):监听特殊事件以触发再均衡
public void subscribe(Pattern pattern);
public void subscribe(Pattern pattern,
ConsumerRebalanceListener listener);
// 订阅指定集合中所有的Partition
public void assign(Collection<TopicPartition> partitions);
- 订阅状态分为:AUTO_TOPICS、AUTO_PATTERN、USER_ASSIGNED
- Consumer的订阅状态只能为其一(未订阅则为NONE)
- 建议通过
subscribe()方法订阅(具有再均衡的功能)
unsubscribe()方法的定义:
// 取消Consumer的所有订阅
// 效果等同于订阅空的集合/无匹配的正则表达式
public void unsubscribe();
拉取(Pull): Consumer的消费是基于拉模式
- 拉模式: 主动向服务端发起请求以获取消息消费
- Consumer可暂停/恢复对指定Partition的消费(不再拉取)
- 拉取会自动根据拉取请求的
session_id和epoc分为: 全量拉取、增量拉取
poll()方法的定义:
// 拉取Consumer绑定的Partition的消息
// timeout参数用于指定获取消息前阻塞等待的时间(0则立刻返回)
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(timeout.toMillis(), true);
}
// 拉取Consumer绑定的Partition的消息
// timeout参数用于指定获取消息前阻塞等待的时间(0则立刻返回)
// includeMetadataInTimeout参数指定阻塞等待时是否考虑元数据超时
//
// ConsumerRecords由多个ConsumerRecord组成的消息集(iterator()方法遍历)
// 还可通过records()方法获取消息集指定所属Topicd/Partition的消息
private ConsumerRecords<K, V> poll(final long timeoutMs, final boolean includeMetadataInTimeout)
pause()和resume()方法的定义:
// 暂停指定Partition的消费
// 该方法不会影响Consumer的订阅
// 可通过paused()获取所有被暂停的Partition
public void pause(Collection<TopicPartition> partitions);
// 恢复指定Partition的消费
// 若Partition未被暂停, 则直接返回
public void resume(Collection<TopicPartition> partitions);
ConsumerRecord
ConsumerRecord(消费消息): Consumer获取的消息体
- ConsumerRecord由多个属性构成(Topic和消息算基础属性)
- ConsumerRecord有多个构造方法(指定属性的个数)
- ConsumerRecord与ProducerRecord相对应
ConsumerRecord定义:
public class ConsumerRecord<K, V> {
private final String topic; // 所属Topic
private final int partition; // Partition编号
private final long offset; // 所在Partition的偏移量
private final long timestamp; // 时间戳
// 时间戳类型
// CreateTime类型: 创建消息时间
// LogAppendTime类型: 追加到日志的时间
private final TimestampType timestampType;
private final K key; // 键
private final V value; // 值
private final Headers headers; // 消息的头部内容
private final int serializedKeySize; // 键所对应的反序列化器
private final int serializedValueSize; // 值所对应的反序列化器
private volatile Long checksum; // CRC32校验值
// 其他方法省略
}
消费位移
消费位移: Consumer在Partition下个消费的ConsumerRecord位置
- 偏移量(Offset): ProducerRecord在Partition中的位置
- 消费位移均存储于内部Topic的
__consumer_offsets - Consumer在每个分区中都有个消费位移
position()和committed()方法的定义:
// 获取Consumer下条消费的ConsumerRecord在指定Partition中的位置
// timeout参数指定获取该信息的最大阻塞时间
public long position(TopicPartition partition);
public long position(TopicPartition partition, final Duration timeout);
// 获取Consumer最后次消费的ConsumerRecord在指定Partition中的位置
// timeout参数指定获取该信息的最大阻塞时间
public OffsetAndMetadata committed(TopicPartition partition);
public OffsetAndMetadata committed(TopicPartition partition, final Duration timeout);
如: Consumer消费Partition后的位置信息

// 从Broker拉取消息时, 会同时记录每条消息的具体位置
位移提交
位移提交: 持久化消费位移信息
- 位移提交并不总是与Position信息相同
- 位移提交策略分为:默认提交、手动提交
默认提交: 交由Kafka管理提交
enable.auto.commit参数配置是否开启- 默认5s提交次Partition中最大的消费位移, 其存在重复消费和消息丢失的风险
- Consumer每次拉取之前也会检查次是否可提交, 满足则先提交再拉取
- 默认Consumer在消费完消息集后进行位移提交(延迟提交)
如: 消费过程中出现异常后恢复导致的重复消费

// 若出现异常后未恢复, 且其他Consumer又进行位移提交则发送消息丢失
手动提交: 由用户决定位移提交
- 手动提交分为: 同步提交、异步提交
- 手动提交虽管理粒度更细, 但需消耗较多性能
commitSync()和commitAsync()方法的定义:
// 同步提交
// timeout参数指定提交的超时时间
// offsets参数指定提交具体Partition的(默认提前所有Partition的Position)
public void commitSync();
public void commitSync(Duration timeout);
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets);
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets, final Duration timeout);
// 异步提交
// callback参数指定提交完成后(调用onComplete()方法之后)的回调方法
// offsets参数指定提交具体Partition的(默认提前所有Partition的Position)
public void commitAsync();
public void commitAsync(OffsetCommitCallback callback);
public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback);
位移消费
位移消费(Seek): Consumer从指定位置处开始消费
auto.offset.reset参数指定Consumer没有消费位移时如何消费- 默认从Partition的末尾处开始(latest), 且位移越界也会触发该行为
seek()和其他相关方法的定义:
// 设置/覆盖指定Partition下次拉取时的消费位移
// 若Consumer多次调用该方法, 则以最后次调用为准
// 必须在Poll()方法之后调用该方法(必须分配Partition后)
public void seek(TopicPartition partition, long offset);
// 返回Consumer分配到的所有Partition
public Set<TopicPartition> assignment();
// 返回指定Partition集合的末尾消息位置(将要写入消息的位置)
public Map<TopicPartition, Long> endOffsets(Collection<TopicPartition> partitions);
public Map<TopicPartition, Long> endOffsets(Collection<TopicPartition> partitions, Duration timeout);
// 返回指定Partition集合的起始处消息位置(还未清理的最早消息)
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions);
public Map<TopicPartition, Long> beginningOffsets(Collection<TopicPartition> partitions,Duration timeout);
// 返回Partition集合中每个的消费位移, 其需大于等于设定的时间戳(最小的)
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch);
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch, Duration timeout);
// seekToBegining()/seekToEnd()方法可直接设为起始处/末尾
实现原理
Rebalance
Rebalance(再均衡): 重新分配Partition所对应的Consumer
- Rebalance期间消费者组内的Consumer不可拉取(消费者不可用)
- Partition被重新分配给新的Consumer时, 上个Consumer的状态会丢失
- 再均衡监听器(RebalanceListener): Rebalance发生前/后所就执行的操作
自动触发Rebalance的事件:
- 消费者组增加/减少Consumer
- Topic的Partition数量发生变化
- 消费者组中的Consumer主动取消订阅
- 消费者组所对应的GroupCoordinator节点发生变化
再均衡监听器的定义:
public interface ConsumerRebalanceListener {
// Rebalance之前和Consumer停止消费后调用
// partitions参数指定Rebalance前所分配到的Partition
void onPartitionsRevoked(Collection<TopicPartition> partitions);
// Rebalance之后和Consumer开始消费前调用
// partitions参数指定Rebalance后所分配到的Partition
void onPartitionsAssigned(Collection<TopicPartition> partitions);
}
Rebalance的具体流程:
- FIND_COORDINATOR: 找到消费者组对应的GroupCoordinator所在的Broker, 并与之建立连接
- JOIN_GROUP: 加入GroupCoordinator, 并配置相关信息(如: 心跳报文周期)
- SYNC_GROUP: GroupCoordinator同步由Consumer leader选举出的Partition分配策略
- HEARTBEAT: Consumer确定offset并开始工作, 通过独立的线程周期性向GroupCoordinator发送心跳报文
组协调器(GroupCoordinator): 管理消费者组的组件(Kafka服务端)
- 默认将首个加入消费者组的Consumer作为Consumer leader
- 根据Counsumer配置的Partition分配策略选举出消费者组的Partition分配策略(Consumer若不支持, 则抛出异常)
// 消费者协调器(ConsumerCoordinator): 与GroupCoordinator交互的组件(Kafka客户端)
ConsumerInterceptor
ConsumerInterceptor(拦截器): 拉取消息期间和位移提交前进行的操作
interceptor.classes参数指定Consumer使用的ConsumerInterceptor- 可指定多个ConsumerInterceptor(拦截链按配置时顺序执行)
ConsumerInterceptor的定义:
public interface ConsumerInterceptor<K, V> extends Configurable {
// 拉取消息期间所进行的操作
// 若抛出异常, 则会被捕获并记录到日志中(不会向上传递)
public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records);
// 位移提交后所进行的操作(也可进行位移提交)
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);
// 关闭拦截器
public void close();
}
DeSerializer
DeSerializer(反序列化器): 将字节数组转换成特定数据结构
- Consumer使用的DeSerializer需和Producer使用的序列化器对应
- Consumer指定DeSerializer时, 需通过全限定名方式指定(类的完整路径)
DeSerializer的定义:
public interface Deserializer<T> extends Closeable {
// 配置反序列化器
// 常用于指定编码类型(默认UTF-8)
void configure(Map<String, ?> configs, boolean isKey);
// 执行反序列化
// 若data参数为null, 则抛出异常
T deserialize(String topic, byte[] data);
// 关闭序列化器
// 需保证幂等性
void close();
}
// 不建议使用自定义Serializer或DeSerializer, 会增加耦合度
多线程消费
Consumer默认是非线程安全
- 通过
acquire()和release()方法确保单线程(加锁和解锁) acquire()方法为轻量级锁实现(检查标记以检测是否发生并发操作)- Consumer执行操作前都会调用
acquire()方法(wakeup()方法例外)
消费线程
消费线程: 每个线程代表个Consumer
- 消费线程可处理多个Partition(属于不同Topic)
- 若消费线程属于同一个消费者组, 则并发量受限于Partition数量
- 不建议让Partition对应多个消费线程, 需处理位移提交和顺序控制
如: 消费线程(不建议单独订阅Partition消费)

处理线程
处理线程: Consumer对应多个线程处理线程进行消费
- 相较于消费线程避免过多TCP连接的资源消耗和快速消费
- 该方式需解决消息的位移提交和顺序控制(可通过共享位移变量)
- 该方式还存在消息丢失的风险, 可通过滑动窗口解决(消费成功才移动)
如:处理线程
