Mysql聚合函数
聚合函数又称分组函数 多行(一组)数据 返回一个结果
数据表
链接:https://pan.baidu.com/s/1dPitBSxLznogqsbfwmih2Q
提取码:b0rp
--来自百度网盘超级会员V5的分享
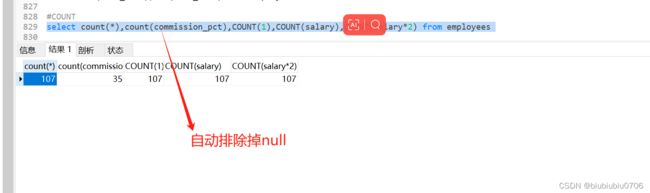
聚合函数会自动排除掉null字段
AVG SUM 适用于数值类型
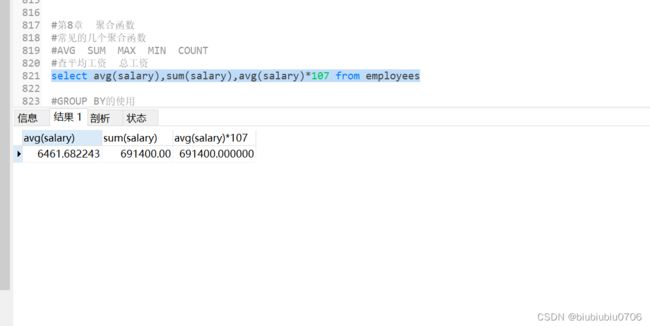
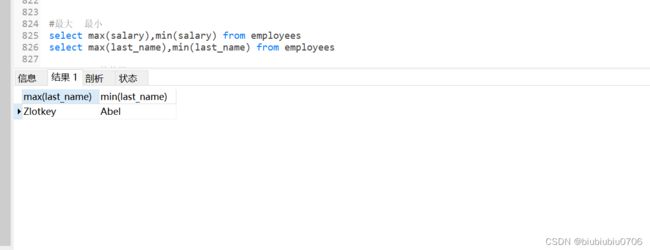
MIN MAX 适用于数值类型,字符串类型,日期时间类型的字段(或变量)
COUNT 作用:计算指定字段在查询结构中出现的个数
COUNT(*) COUNT(1) COUNT(2) 查询的是总条数
COUNT(字段) 会排除掉null
AVG=SUM/COUNT
SQL优化的一个点:
统计表中数据 用COUNT(*) COUNT(字段) COUNT(1) 哪种效率更高????
如果使用的是MyISAM引擎,是没有区别的.因该引擎内部有计数器维护行数
如果使用的是Innodb引擎,COUNT(*)=COUNT(1)>COUNT(字段)
因MyISAM不支持事务,现在普遍用的都是Innodb引擎,因此COUNT(*)或者COUNT(1)效率更高

GROUP BY的使用
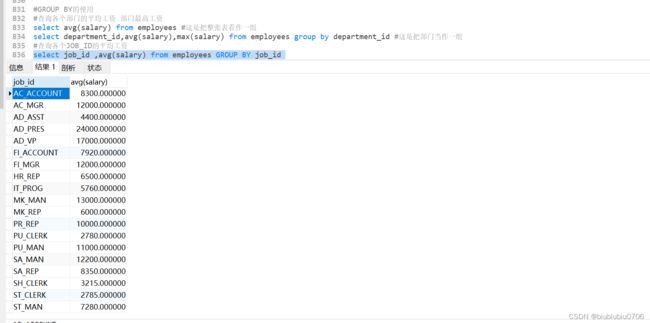
使用多个列分组

同样Oracle中也会报错
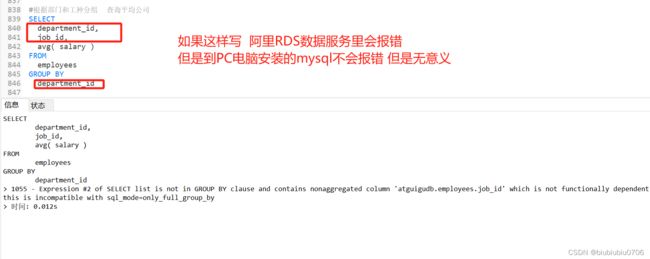
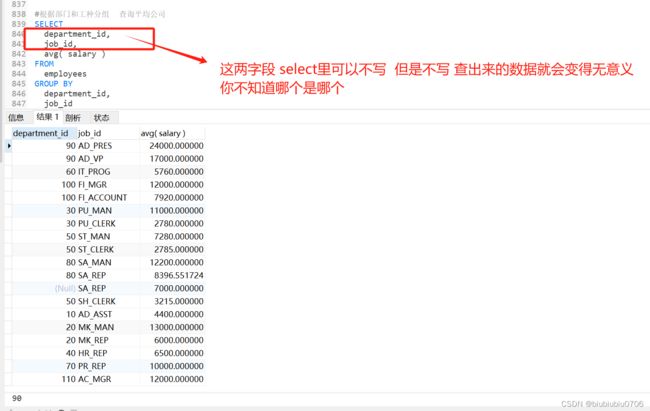
结论: SELECT中出现的非分组函数的字段必须声名在GROUP BY中.反之GROUP BY中的字段可以不出现在SELECT中,但是一般不出现的话 往往没有意义,不知道哪个是哪个
GROUP BY 在 FROM 后面 WHERE 后面 ORDER BY前面
新特性
GROUP BY 中使用 WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量
注意:当使用ROLLUP时候,不能同时使用ORDER BY进行结果排序,ROLLUP和ORDER BY互斥
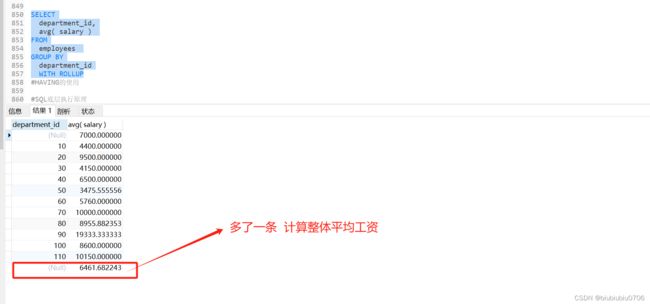
注意 WHERE执行之前 GROUP BY 还没有执行
HAVING的使用 (用来过滤分组之后数据)
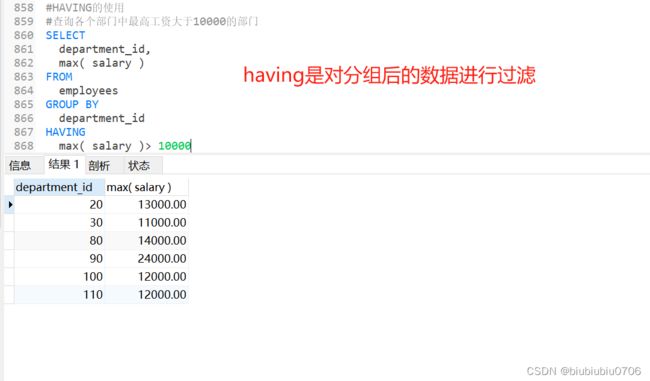

下面两种方式 推荐使用方式1 原因 方式1的执行效率高于方式2
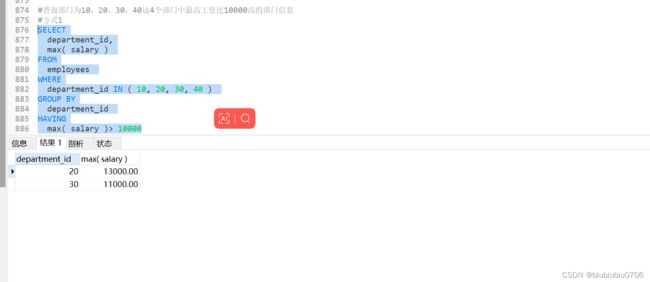
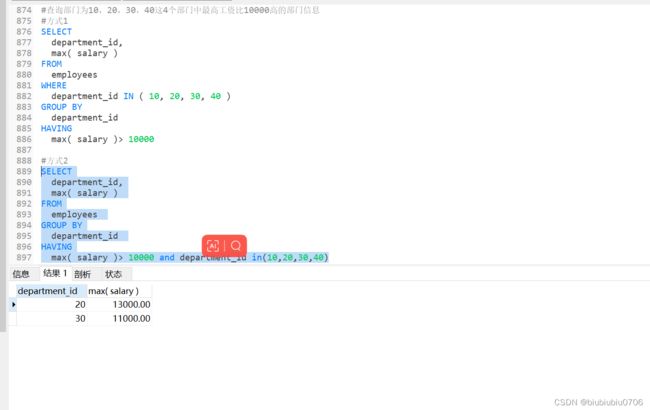

当过滤条件中有聚合时,则过滤条件必须声明在HAVING中,当过滤条件没有聚合函数,则此过滤条件声明在WHERE和HAVING中都是可以的,但是建议放在WHERE中,效率更高
一般没有聚合的条件放在WHERE 有聚合过滤放在HAVING
WHERE与HAVING对比:HAVING适用范围更广
WHERE效率更高


SQL底层的执行过程
SELECT语句的完整结构

SQL语句的执行过程


执行顺序



聚合函数练习
1.where子句可否使用组函数进行过滤? 不可以
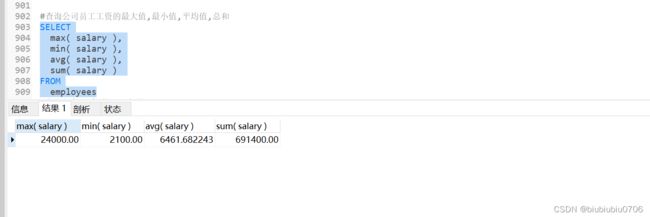
2.查询公司员工工资的最大值,最小值,平均值,总和
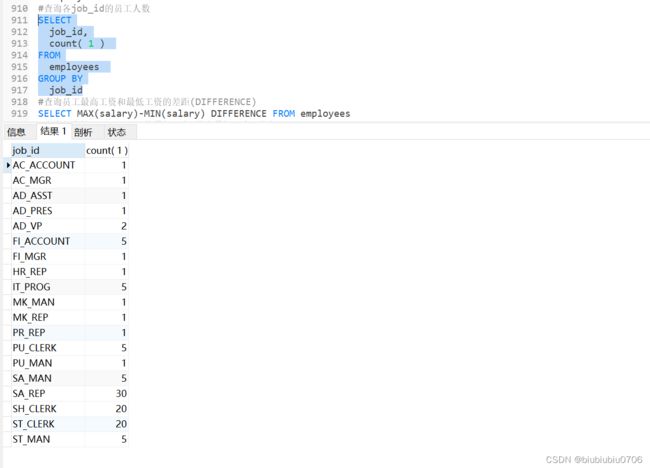
3.查询各job_id的员工人数
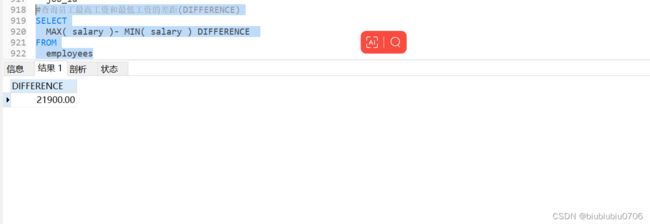
4.查询员工最高工资和最低工资的差距(DIFFERENCE)
5.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000

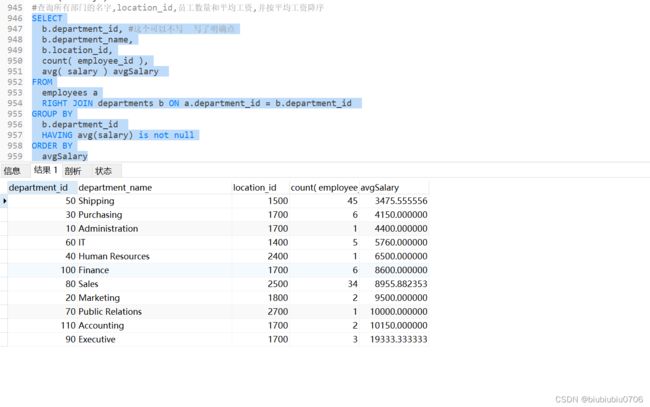
6.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
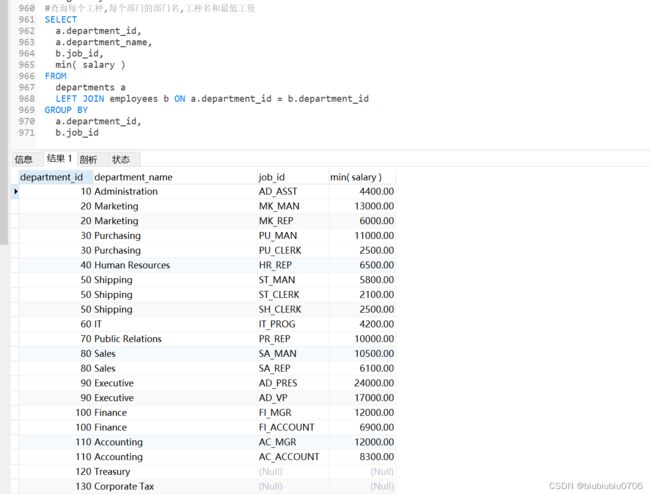
7.查询每个工种,每个部门的部门名,工种名和最低工资