AI预测-Transformer模型及Paddle实现
AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合测略
- Transformer模型及Paddle实现
文章目录
- AI预测相关目录
- 一、Transformer背景
- 二、多头注意力机制
- 三、Paddle实现transformer
- 四、代码示例
- 总结
一、Transformer背景
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。 作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算是顺序的,RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片 tt 的计算依赖 t−1t−1 时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题:
- 首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;
- 其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
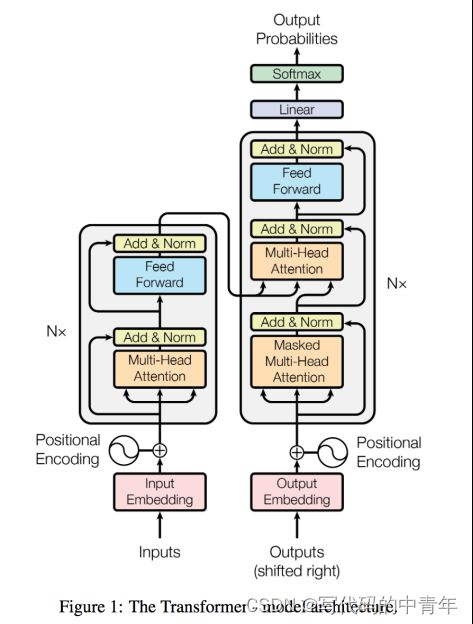
如上图,transformer模型本质上是一个Encoder-Decoder的结构。输入序列先进行Embedding,经过Encoder之后结合上一次output再输入Decoder,最后用softmax计算序列下一个单词的概率。
二、多头注意力机制
与自注意力机制(这个过程实际上是 Attention 缓解神经网络复杂度的体现,不需要将所有的 N 个输入都输入到神经网络进行计算,而是选择一些与任务相关的信息输入神经网络,与 RNN 中的门控机制思想类似。因此Self-Attention 能够捕获长距离依赖。)通过对数据拟合加权不同。

论文中表明,将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。上图中Multi-Head Attention 就是将 Scaled Dot-Product Attention 过程做 H 次,再把输出合并起来。
一个512x512的W投影再拆分和用八个512x64的W分别投影是等价的;
multi-head是通过reshape+transpose的方式把原来的向量空间分成了head_num份;
三、Paddle实现transformer
paddle是类似于pytorch的国产化深度学习框架,其中针对时序回归预测、时序分类预测、时序异常检测、集成学习等都做出了较高程度上的算法集成。
实现transformer算法,其框架设定的参数如下:
in_chunk_len: int,
out_chunk_len: int,
skip_chunk_len: int = 0,
sampling_stride: int = 1,
loss_fn: Callable[…, paddle.Tensor] = F.mse_loss,
optimizer_fn: Callable[…, Optimizer] = paddle.optimizer.Adam,
optimizer_params: Dict[str, Any] = dict(learning_rate=1e-3),
eval_metrics: List[str] = [],
callbacks: List[Callback] = [],
batch_size: int = 128,
max_epochs: int = 10,
verbose: int = 1,
patience: int = 4,
seed: Optional[int] = None,
d_model: int = 8,
nhead: int = 4,
num_encoder_layers: int = 1,
num_decoder_layers: int = 1,
dim_feedforward: int = 64,
activation: str = “relu”,
dropout_rate: float = 0.1,
custom_encoder: Optional[paddle.nn.Layer] = None,
custom_decoder: Optional[paddle.nn.Layer] = None,
部分具有释义,在对模型进行使用时,可参照释义对模型调参:
d_model (int,可选) - 编码器和解码器的输入输出的维度。默认值:512。
nhead (int,可选) - 多头注意力机制的 Head 数量。默认值:8。
num_encoder_layers (int,可选) - 编码器中 TransformerEncoderLayer 的层数。默认值:6。
num_decoder_layers (int,可选) - 解码器中 TransformerDecoderLayer 的层数。默认值:6。
dim_feedforward (int,可选) - 前馈神经网络中隐藏层的大小。默认值:2048。
dropout (float,可选) - 对编码器和解码器中每个子层的输出进行处理的 dropout 值。默认值:0.1。
activation (str,可选) - 前馈神经网络的激活函数。默认值:relu。
attn_dropout (float,可选) - 多头自注意力机制中对注意力目标的随机失活率。如果为 None 则 attn_dropout = dropout。默认值:None。
act_dropout (float,可选) - 前馈神经网络的激活函数后的 dropout。如果为 None 则 act_dropout = dropout。默认值:None。
normalize_before (bool,可选) - 设置对编码器解码器的每个子层的输入输出的处理。如果为 True,则对每个子层的输入进行层标准化(Layer Normalization),对每个子层的输出进行 dropout 和残差连接(residual connection)。否则(即为 False),则对每个子层的输入不进行处理,只对每个子层的输出进行 dropout、残差连接(residual connection)和层标准化(Layer Normalization)。默认值:False。
weight_attr (ParamAttr|tuple,可选) - 指定权重参数属性的对象。如果是 tuple,则只支持 tuple 长度为 1、2 或 3 的情况。如果 tuple 长度为 3,多头自注意力机制的权重参数属性使用 weight_attr[0],解码器的编码-解码交叉注意力机制的权重参数属性使用 weight_attr[1],前馈神经网络的权重参数属性使用 weight_attr[2];如果 tuple 的长度是 2,多头自注意力机制和解码器的编码-解码交叉注意力机制的权重参数属性使用 weight_attr[0],前馈神经网络的权重参数属性使用 weight_attr[1];如果 tuple 的长度是 1,多头自注意力机制、解码器的编码-解码交叉注意力机制和前馈神经网络的权重参数属性都使用 weight_attr[0]。如果该参数值是 ParamAttr,则多头自注意力机制、解码器的编码-解码交叉注意力机制和前馈神经网络的权重参数属性都使用 ParamAttr。默认值:None,表示使用默认的权重参数属性。具体用法请参见 ParamAttr 。
bias_attr (ParamAttr|tuple|bool,可选)- 指定偏置参数属性的对象。如果是 tuple,则只支持 tuple 长度为 1、2 或 3 的情况。如果 tuple 长度为 3,多头自注意力机制的偏置参数属性使用 bias_attr[0],解码器的编码-解码交叉注意力机制的偏置参数属性使用 bias_attr[1],前馈神经网络的偏置参数属性使用 bias_attr[2];如果 tuple 的长度是 2,多头自注意力机制和解码器的编码-解码交叉注意力机制的偏置参数属性使用 bias_attr[0],前馈神经网络的偏置参数属性使用 bias_attr[1];如果 tuple 的长度是 1,多头自注意力机制、解码器的编码-解码交叉注意力机制和前馈神经网络的偏置参数属性都使用 bias_attr[0]。如果该参数值是 ParamAttr,则多头自注意力机制、解码器的编码-解码交叉注意力机制和前馈神经网络的偏置参数属性都使用 ParamAttr。如果该参数为 bool 类型,只支持为 False,表示没有偏置参数。默认值:None,表示使用默认的偏置参数属性。具体用法请参见 ParamAttr 。
四、代码示例
from paddlets import TSDataset
from paddlets.models.model_loader import load
from paddlets.models.forecasting import RNNBlockRegressor
from paddlets.models.forecasting import TransformerModel
import pandas as pd
import numpy as np
from paddlets import TSDataset
x = np.array(pd.read_csv('train_data.csv',encoding='GB2312')['平均风速(m/s)'].tolist()[:1000])
df = pd.DataFrame(
{
'time_col': pd.date_range('2022-01-01', periods=len(x), freq='15min'),
'value': x
}
)
custom_dataset = TSDataset.load_from_dataframe(
df, #Also can be path to the CSV file
time_col='time_col',
target_cols='value',
freq='15min'
)
# 3 init the model instance.
model = TransformerModel(in_chunk_len=96, out_chunk_len=96)
# 4 fit
model.fit(train_tsdataset=custom_dataset)
# 5 predict
predicted_dataset = model.predict(custom_dataset)
# 6 recursive predict
recursive_predicted_dataset = model.recursive_predict(custom_dataset, predict_length= 3 * 96)
# 7 save the model
model.save("tfr")
总结
完结,撒花!