机器学习_无监督学习之聚类
文章目录
- 介绍机器学习下的分类
- K均值算法
- K值的选取:手肘法
- 用聚类辅助理解营销数据
- 贴近项目实战
介绍机器学习下的分类
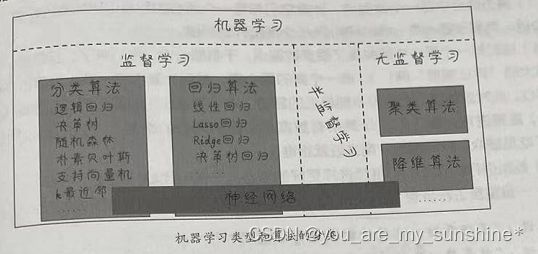
以下介绍无监督学习之聚类
聚类是最常见的无监督学习算法。人有归纳和总结的能力,机器也有。聚类就是让机器把数据集中的样本按照特征的性质分组,这个过程中没有标签的存在。
聚类和监督学习中的分类问题有些类似,其主要区别在于:传统分类问题“概念化在前”。机器首先是学习概念,然后才能够做分类、做判断。
而聚类不同,虽然本质上也是“分类”,但是“概念化在后”或者“不概念化”,在给一堆数据分组时,没有任何此类、彼类的概念。
聚类也有好几种算法,K均值(K-means)是其中最常用的一种。
K均值算法
K均值算法是最容易理解的无监督学习算法。算法简单,速度也不差,但需要人工指定K值,也就是分成几个聚类。具体算法流程如下。
- (1)首先确定K的数值,比如5个聚类,也叫5个簇。
- (2)然后在一大堆数据中随机挑选K个数据点,作为簇的质心(centroid )。这些随机质心当然不完美,别着急,它们会慢慢变得完美。
- (3)遍历集合中每一个数据点,计算它们与每一个质心的距离(比如欧氏距离)。数据点离哪个质心近,就属于哪一类。此时初始的K个类别开始形成。
- (4)这时每一个质心中都聚集了很多数据点,于是质心说,你们来了,我就要“退役”了(这个是伟大的“禅让制度”啊!),选一个新的质心吧。然后计算出每一类中最靠近中心的点,作为新的质心。此时新的质心会比原来随机选的靠谱一些(等会儿用图展示质心的移动)。
- (5)重新进行步骤(3),计算所有数据点和新的质心的距离,在新的质心周围形成新的簇分配(“吃瓜群众”随风飘摇,离谁近就跟谁)。
- (6)重新进行步骤(4),继续选择更好的质心(一代一代地“禅让”下去)。
- (7)一直重复进行步骤(5)和(6),不断更新簇中的数据点,不断找到新的质心,直至收敛。
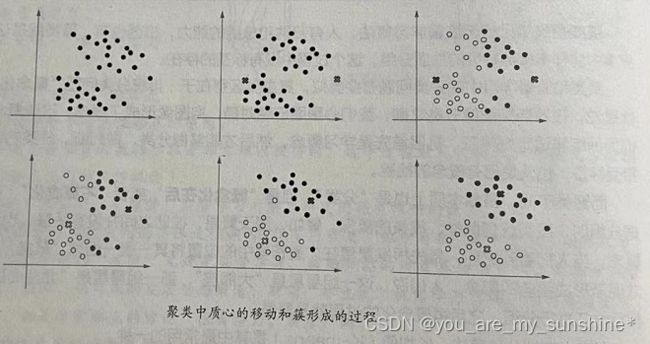
通过下面这个图,可以看到聚类中质心的移动和簇形成的过程。
K值的选取:手肘法
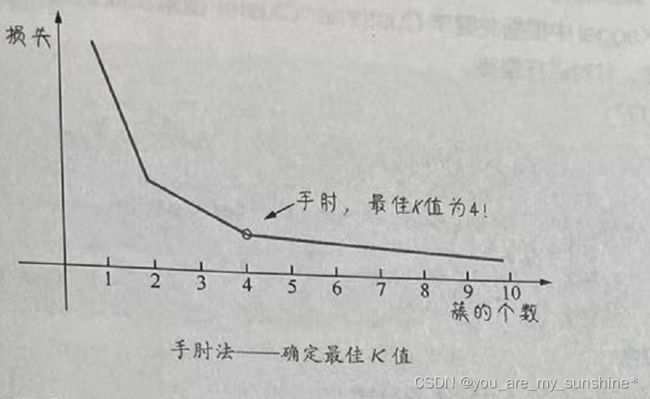
直观的手肘法(elbow method )进行簇的数量的确定。手肘法是基于对聚类效果的一个度量指标来实现的,这个指标也可以视为一种损失。在K值很小的时候,整体损失很大,而随着K值的增大,损失函数的值会在逐渐收敛之前出现一个拐点。此时的K值就是比较好的值。
大家看下面的图,损失随着簇的个数而收敛的曲线有点像只手臂,最佳K值的点像是手肘,因此取名为手肘法。
用聚类辅助理解营销数据
1.问题定义:为客户分组
(1)通过这个数据集,理解K均值算法的基本实现流程。
(2)通过K均值算法,给客户分组,了解每类客户消费能力的差别。
2.数据读入
import numpy as np # 导入NumPy
import pandas as pd # 导入pandas
import warnings
warnings.filterwarnings("ignore")
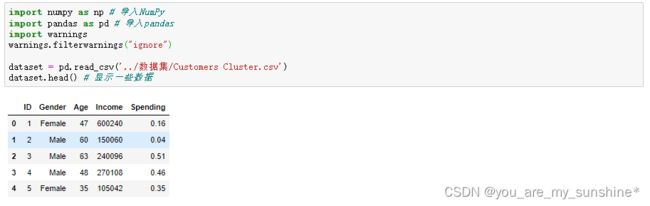
dataset = pd.read_csv('../数据集/Customers Cluster.csv')
dataset.head() # 显示一些数据
# 只针对两个特征进行聚类,以方便二维的展示
X= dataset.iloc[:, [2,4]].values
Spending Score:消费分数(归一化成一个0~1的分数)
3.聚类的拟合
下面尝试用不同的K值进行聚类的拟合:
from sklearn.cluster import KMeans # 导入聚类模型
cost=[] # 初始化损失(距离)值
for i in range(1,11): # 尝试不同的K值
kmeans = KMeans(n_clusters= i, init='k-means++', random_state=0)
kmeans.fit(X) # 拟合模型
cost.append(kmeans.inertia_) #inertia_是度量数据点到聚类中心的度量公式
4.绘制手肘图
import matplotlib.pyplot as plt # 导入Matplotlib
import seaborn as sns # 导入Seaborn
%matplotlib inline
# 绘制手肘图
plt.plot(range(1,11), cost)
plt.title('The Elbow Method')
plt.xlabel('no of clusters')
plt.ylabel('Cost')
plt.show()
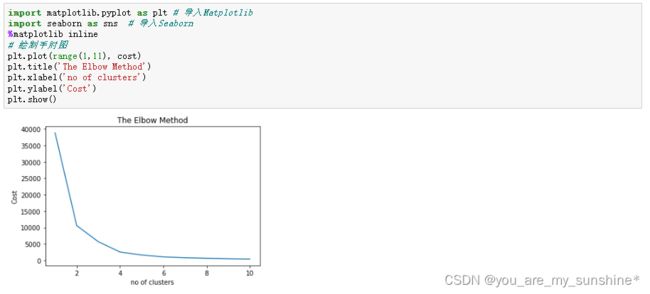
从手肘图上判断,肘部数字大概是3或4,我们选择4作为聚类个数
# 构建聚类模型
kmeansmodel = KMeans(n_clusters= 4, init='k-means++') # 选择4作为聚类个数
y_kmeans= kmeansmodel.fit_predict(X) # 进行聚类的拟合和分类
5.把分好的聚类可视化
# 把分好的聚类可视化
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X[y_kmeans == 3, 0], X[y_kmeans == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
# plt.scatter(X[y_kmeans == 4, 0], X[y_kmeans == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'yellow', label = 'Centroids')
plt.title('Clusters of customers')
plt.xlabel('Age')
plt.ylabel('Spending Score')
plt.legend()
plt.show()

这个客户的聚类问题就解决了。其中,黄色高亮的大点是聚类的质心,可以看到算法中的质心并不止一个。
贴近项目实战
可见 Python综合数据分析_RFM用户分组模型
学习机器学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
…