十月学习笔记
知识点
什么是预训练模型
预训练模型是一个通过大量数据上进行训练并被保存下来的网络。可以将其通俗的理解为前人为了解决类似问题所创造出来的一个模型,有了前人的模型,当我们遇到新的问题时,便不再需要从零开始训练新模型,而可以直接用这个模型入手,进行简单的学习便可解决该新问题。
transformer的架构:基于encoder-only或decoder-only架构
Transformer模型由编码器(encoder)和解码器(decoder)组成,之所以这样设计是因为其能够处理机器翻译,编码-解码架构是过去在机器翻译取得成功的一大原因。
后来的很多研究发现,架构要么只用编码器,要么只用解码器,并将堆栈堆得尽可能高,输入大量文本进行训练,同样能获得很多的训练效果。
最具代表性的是基于Transformer框架两个最主要的预训练模型,一个是GPT模型(Generative Pre-Training),另一个是BERT模型(Bidirectional Encoder Representations from Transformers)。GPT是通过Transformer解码器模块构建的,BERT是通过Transformer的编码器构建的。
Tokenizer
Tokenizer是应该分词器,它会加载整个字典。根据词语查询序号的字典为tokenizer.encoder,如tokenizer.encoder[‘bot’];根据序号查询词语的字典为tokenizer.decoder,如tokenizer.decoder[13645]。需要注意,这个字典并不包含中文。因此,不同的自然语言处理任务所采用的分词字典也可能会出现差异。
Attention由来
Attention的由来是源于RNN,RNN的特点是每个RNN模块接收两个输入,输出一个hidden state。我们想要结果output能够编码所有前面的内容,但是输出output的生成方式天然会让它更容易注意到靠后的内容,而容易忽略靠前的输入,从而,人们提出能否让输出和前面的每个输入建立直接的联系,由此达到每个输入得到相同的注意力,从而提出来了attention。
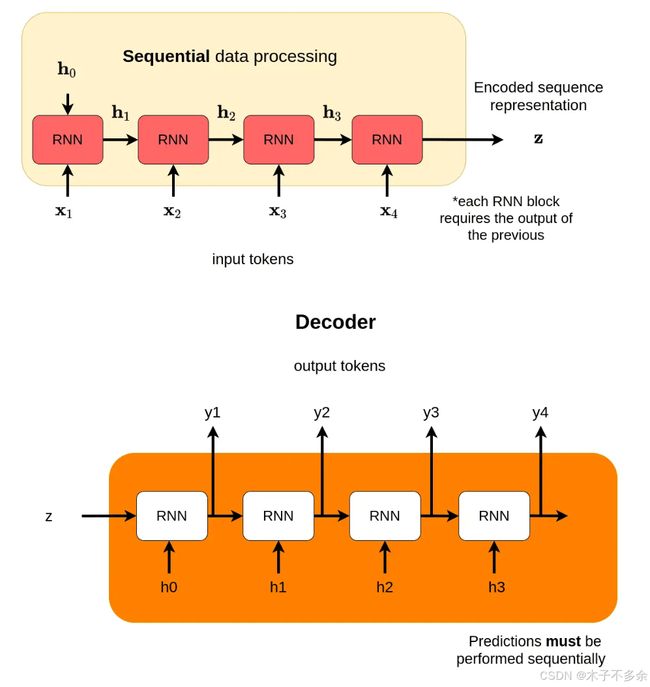
自注意力机制(self-attention)
自注意力机制是指模型进行特征提取时会关注到自身数据之间的相关性。注意力表示关注数据的权重大小。
检索增强生成(retrieval augmented generation, RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)旨在通过整合外部知识来源来提高大模型回答的质量。RAG也可以看作是在处理大量数据时提高推理效率的一种技术。RAG没有将所有信息合并到一个过长的prompt中,而是将检索到的相关信息添加到原始提示符中,从而确保模型在显著减少提示词长度的同时接收到必要的信息。
PagedAttention
利用 virtual memory with paging 的方式来充分利用 memory fragmentation。在 PagedAttention 中,KV Cache 没有必要存储在连续的内存中。因此,我们可以像 OS 的 virtual memory 一样更加灵活的管理 KV Cache:one can think of blocks as pages, tokens as bytes and requests as processes。
大模型推理
主流大模型是基于Transformer架构设计的。大模型推理的大量计算和内存需求对其在资源受限场景的部署提出了挑战。大模型推理过程中,三个重要因素将很大程度上影响上述指标。计算成本(computational cost),内存访问成本(memory access cost)和内存使用(memory usage)。大模型推理低效率的根本原因需要关注三个关键因素:模型大小、解码方法、注意力操作。
I have some puzzle
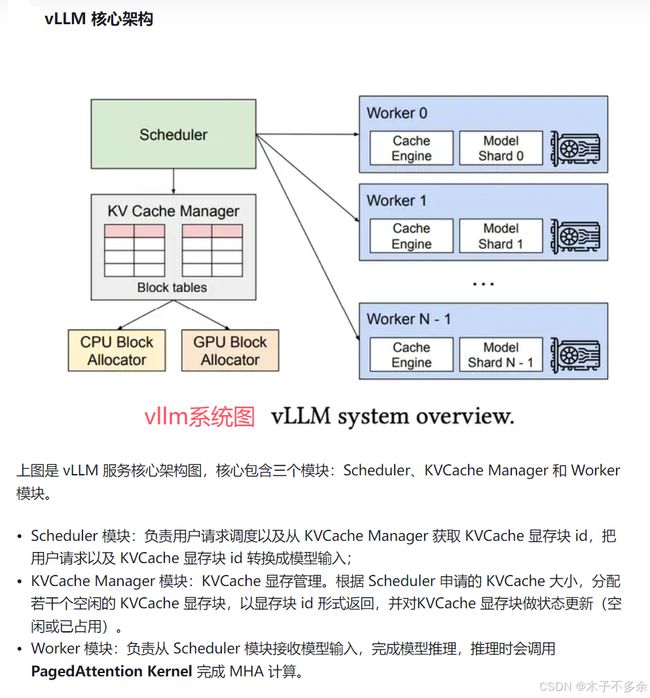
1、PageAttention是目前kv cache优化的重要技术手段,目前最炙手可热的大模型推理加速项目VLLM的核心就是PageAttention技术。什么是VLLM?
vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高24倍的吞吐量。
vllm是在orca的基础上进行优化,添加了分页注意力技术
vLLM 设计初衷:vLLM(非常大语言模型)设计的初衷主要是为了提升大语言模型的推理效率和资源利用率
2、模型服务最大的目标是在端到端延时满足要求的情况下,提升服务吞吐,从而降低部署成本。什么是端到端延时满足?
在网络、系统或应用中,从请求发起到响应完成的整个过程所需的时间是否满足预定的延时要求。
3、什么是nccl通信
NCCL(NVIDIA Collective Communications Library)是NVIDIA开发的一种高性能通信库,专为深度学习和大规模并行计算设计。它优化了多GPU和多节点的集体通信操作,例如广播、聚合和all-reduce等。NCCL利用GPU直接进行数据传输,减少了CPU的干预,提高了数据传输效率和速度,特别适合大规模深度学习训练。
4、什么是FlashAttention?
FlashAttention利用GPU硬件非均匀的存储器层次结构实现内存节省和推理加速。
FlashAttention通过重新组织注意力计算,实现了显著的性能提升,同时减少内存I\O
FlashAttention 的工作原理主要基于以下几个关键点:
- 内存优化:传统的注意力机制在处理长序列时,会消耗大量内存。FlashAttention通过使用分块处理和内存复用,减少了对显存的需求。
- 计算效率:它利用现代GPU的并行计算能力,通过减少冗余计算,将注意力计算过程优化为更高效的矩阵运算。这使得在大规模数据上进行训练时速度更快。
- 动态计算:FlashAttention根据输入序列的实际长度动态调整计算,避免了不必要的计算,提高了整体效率。
- 快速内存访问:通过优化内存访问模式,FlashAttention可以更有效地利用缓存,从而加速计算过程。
5、什么是Continous Batching?
它是一种不需要修改模型的内存优化技术。连续性批处理是一种在模型推理过程中动态调整批处理大小的技术。它允许在生成或处理数据序列时,一旦一个任务或序列完成,就立即用新的任务或序列替代它,从而优化资源利用和提高处理效率。
论文:《Orca: A Distributed Serving System for Transformer-Based Generative Models》

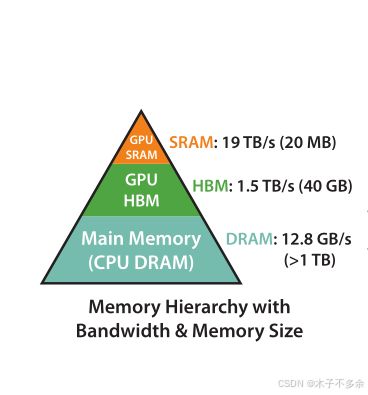
6、什么是HBM和SRAM。
HBM(High Bandwidth Memory)和 SRAM(Static Random Access Memory)是两种不同类型的存储器。HBM 存储空间大,但计算速度慢。 SRAM 计算速度快,但是容量小。
GPU物理内存包括寄存器,SRAM,L1Cache, L2 Cache, HBM等。
FlashAttention就是使用tiling来减少GPU高带宽内存(HBM)和GPU片上SRAM之间的内存读/写数量,比标准attention需要更少的HBM访问。
我们在计算attention的时候,kqv就是存储在HBM中,关于attention的计算是在SRAM中计算的,就导致需要多次在HBM和SRAM之间进行多次数据读写,导致内存访问开销过多。
7、什么是Tiling技术
Tiling 的主要目的是通过将大任务分解成更小的子任务来优化内存访问模式,从而提高性能和减少内存带宽需求。
在 Tiling 中,数据被分成较小的块(tiles),每个块可以独立处理。这样做的好处包括:
- 减少全局内存访问:通过将数据存储在共享内存或寄存器中,可以减少对全局内存的访问次数,从而提高性能。
- 提高缓存利用率:将数据组织成块可以更好地利用缓存,因为相邻的数据更有可能同时被访问。
- 更好的并行性:每个块可以由不同的线程块并行处理,从而提高整体并行度。
8、什么是投机推理
投机推理通常指的是模型在面对不完整或不确定信息时进行的推理过程。这种推理方法允许模型基于现有的知识和数据做出合理的假设或预测,并在此基础上继续推理或生成内容。
在大模型中,投机推理是指模型在面对不完整或不确定信息时,基于已有知识和上下文进行合理的假设和预测,并在此基础上继续推理或生成内容。这种能力使得大模型能够在多种任务中表现出强大的适应性和鲁棒性。
投机推理的每一轮的推理如下步骤: 1. 使用小模型自回归的生成N个token 2. 使用大模型并行验证N个token出现的概率,接受一部分或者全部token。
9、关于旋转式位置编码
旋转式位置编码(Rotary Position Embedding)来处理查询(query)、键(key)张量。这种处理方式在Transformer模型的自注意力机制中很常见,尤其是在处理序列数据时,为了引入位置信息而采用的技术。
旋转位置编码(Rotary Position Embedding,RoPE)是论文 Roformer: Enhanced Transformer With Rotray Position Embedding 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。而目前很火的 LLaMA、GLM 模型也是采用该位置编码方式。
位置编码包括绝对位置编码和相对位置编码。用sin、cos计算编码是一种绝对位置编码。
RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点。RoPE 具有更好的外推性,目前是大模型相对位置编码中应用最广的方式之一。RoPE的实现:
主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了。换言之就是,首先表达绝对位置信息,随后通过更新的信息引入相对位置信息,实现绝对位置和相对位置的融合。
m是位置信息,0,1,2,3,…表示下标
\theta 是 torch.pow(10000, -2 * ids / output_dim)(其中 ids = torch.arange(0, output_dim // 2, dtype=torch.float))
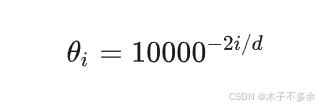

10、 投机采样
存在的原因:
① 对于部分token,因为其生成难度低,用小参数草稿模型(简称小模型)也能够比较好的生成。
② 在小批次情况下,原始模型(简称大模型)在前向推理的主要时间在加载模型权重上而在对token的计算生成没有花费太多的时间,因此批次数量对推理时间的影响非常小。
投机采样使用了特殊的采样方法,来保证投机采样获得的token分布符合原模型的分布,即使用投机采样对效果是无损的。
在一轮投机采样流程中,需要进行N次小batch采样和1次大batch采样
