【牛B得一塌糊涂】窗口归一化技术,改进医学图像的分布外泛化能力
窗口归一化技术,改进医学图像的分布外泛化能力
- 提出背景
- WIN、WIN-WIN、无参数归一化、特征级别数据增强
- 如何提升分布外的泛化?
- 总结
- 子问题1: 医学图像中的局部特征表示不足
- 子问题2: 训练数据与新场景数据分布不一致
- 子问题3: 模型在分布外数据上泛化能力不足
- 子问题4: 训练与评估时的不一致性问题
- 子问题5: 传统数据增强方法不适用于医学图像
提出背景
论文:https://arxiv.org/pdf/2207.03366.pdf
代码:https://github.com/joe1chief/windowNormalizaion
窗口归一化(WIN)是一种为了提高深度学习模型在处理分布外数据时泛化能力的归一化技术。
分布外数据,指的是在模型训练阶段未曾见过的,分布与训练数据不同的新数据。
对于医学图像来说,这种情况尤为常见,因为不同的医疗设备、扫描协议或者病人的生理差异都可能导致测试时的图像与训练集在分布上有所差异。

上图是,7 个青光眼检测数据集的特征的 t-SNE 可视化。
t-SNE技术降低数据的维度,将高维数据集可视化为二维空间。
每种颜色代表来自不同数据集的数据,表明每个数据集捕获了整体数据分布的独特子集。
这表明任何两个数据集之间都存在分布偏移,这对机器学习模型在这些数据集之间泛化是一个挑战。
WIN、WIN-WIN、无参数归一化、特征级别数据增强
传统方法:
假设我们有一个由多个医院的医学图像构成的数据集,用于训练一个模型以检测肺部X光图像中的结节。
由于这些图像来自不同的X光机器,它们在亮度、对比度和噪声等方面存在差异。
传统的归一化方法,如批归一化(BN),可能会使用所有训练图像的平均亮度和对比度进行归一化。
当模型遇到新的医院提供的数据时,这些数据可能与训练数据在统计特性上有显著不同,导致模型性能下降。
WIN方法:
在同样的情景下,使用窗口归一化(WIN)技术,我们不是使用整个数据集的统计特性,而是在每个图像的局部区域内计算统计特性。
这意味着WIN可以考虑到图像中的局部特征和变异,从而使模型更加鲁棒,即使是在面对从未见过的、与训练数据分布不同的新图像时也能保持性能。
WIN-WIN 方法:
在分类任务中,比如将MRI图像分类为正常或含有肿瘤的类别,WIN-WIN方法通过在训练时考虑两种模式。
使用WIN进行特征归一化的模式和使用全局统计数据的模式。
在评估时,WIN-WIN强迫模型输出在这两种模式下保持一致,进一步增强了模型对新医院数据的适应性。
特征级别数据增强:
传统的数据增强技术可能包括在图像层面上应用变换,如旋转、缩放或添加噪声。
这对于自然图像来说可能很有效,但医学图像通常需要更细致的处理,因为它们包含重要的临床信息,而且可能会受到设备差异的影响。
使用WIN技术,数据增强发生在特征层面。
例如,对于从不同扫描仪来的CT扫描图像,WIN通过在每个图像的随机局部窗口内进行归一化来增强数据,而不是简单地应用全局变换。
这样可以模拟来自不同设备和条件的图像,增加数据的多样性,提高模型的泛化能力。
无参数归一化技术:
传统的归一化技术,比如BN,需要为每个特征通道学习一组参数来进行缩放和平移。
这可能会导致模型在面对分布偏移时变得不稳定。
相比之下,WIN作为一种无参数归一化技术,不需要额外的参数学习。
它只依赖于输入数据本身的统计特性。
这样一来,模型不会过分适应训练数据的特定特性,从而在应对新的、不同分布的测试数据时更加稳健。
WIN 和 WIN-WIN 方法通过在特征级别上引入局部统计信息和自我蒸馏机制,克服了传统归一化方法在医学图像分布外泛化上的不足。
这使得模型能够更好地适应新场景,提高了在实际临床应用中的可用性。
WIN、WIN-WIN、无参数归一化、特征级别数据增强的关系:
-
窗口归一化(WIN):
- 它是一种归一化技术,通过计算图像或特征映射中的小窗口内的局部统计量(平均值和方差)来代替传统的全局统计量。
- WIN是一个无参数的方法,因为它不需要像传统归一化方法(如批归一化)那样为每个特征通道学习额外的缩放和偏移参数。
- 这种方法可以被视为一种特征级别的数据增强技术,因为它通过在训练过程中使用不同窗口的统计量来引入变异性,这有助于模型学习到在面对新的、未见过的数据分布时也能保持性能的特征表示。
-
WIN-WIN:
- WIN-WIN建立在WIN的基础上,是一种自我蒸馏方法。在训练过程中,模型会有两次前向传播,一次使用WIN的局部统计量,另一次使用全局统计量。
- WIN-WIN通过最小化两次前向传播结果之间的差异来增强模型的泛化能力,这个过程称为一致性约束。
- WIN-WIN进一步提升了模型在分布外数据上的性能,因为它鼓励模型在不同的统计视角下产生相似的输出。
-
无参数归一化:
- WIN作为一种无参数归一化技术,意味着它不依赖于训练期间学习的参数来执行归一化操作。
- 无参数归一化减少了模型的复杂性,避免了在新数据集上应用模型时可能出现的过拟合问题。
-
特征级别数据增强:
- WIN和WIN-WIN都利用了特征级别的数据增强。这种增强不是在输入图像上直接进行(如旋转、缩放、剪切等),而是在模型的内部特征表示上进行,通过改变特征的统计属性来实现。
WIN是一个无参数的归一化和特征级数据增强方法,而WIN-WIN是一个在WIN基础上进一步通过自我蒸馏提高模型泛化能力的方法。
如何提升分布外的泛化?
子问题1: 医学图像数据稀缺和异质性导致的分布外泛化问题
- 子解法1: 窗口归一化(WIN)
- 原因: 传统归一化方法,如BN和IN,在分布偏移下的训练-测试统计不一致性问题上存在基本缺陷。
- WIN 通过在每个实例中引入基于随机窗口的统计扰动(即噪声注入),实现特征级别的数据增强,从而提高模型对分布外数据的泛化能力。
- WIN作为一种无需调参的归一化技术,直接作为归一化层使用,既简化了模型设计又提升了分布外泛化性能,特别是在异质性医学图像数据上。

上图(a)展示了批归一化(BN),(b)展示了实例归一化(IN)。
而©展示了所提出的窗口归一化(WIN)。
立方体中的蓝色方块表示聚合计算均值和方差以进行归一化的像素。
子图(d)是WIN-WIN方法的示意图,演示了它如何在训练期间应用WIN技术,并在评估期间切换到全局统计。
窗口采样是窗口归一化(WIN)技术中的一个关键步骤:

上图是窗口采样的算法描述,用于数据增强。
算法通过重复选择一个随机大小和位置的窗口,直到其面积超过了特定阈值τ(窗口大小)。
-
选择局部区域:窗口采样算法定义了如何在图像或特征映射上选择局部区域。这通常涉及到随机选择一个窗口的大小和位置,以便在该窗口内计算统计量。
-
计算局部统计量:在所选的窗口内,计算像素或特征值的局部平均值和方差。
-
数据增强:通过使用不同窗口的局部统计量进行标准化,模型能够学习到更加泛化的特征表示,从而提高对新见(未在训练集中出现)数据的泛化能力。
这个过程对于实现窗口归一化(WIN)来说是关键,它使得在特征空间内可以对特征进行局部化的归一化处理。

山兔是,在CIFAR-10-C数据集上,使用不同归一化方法(BN、IN、WIN)得到的t-SNE特征可视化图。
子问题2: 现有归一化技术在医学图像分布外泛化上的不足
- 子解法2: WIN-WIN自我蒸馏方法
- 原因: 传统归一化技术如批归一化(BN)和实例归一化(IN)在处理医学图像分布偏移时存在局限性。
- WIN-WIN 通过两次前向传递和一致性约束来充分利用WIN,提供了一种简单扩展现有方法的方式,进一步提升模型在分类任务中的分别外泛化能力。
子问题3: 数据增强方法在医学图像分别外泛化上的限制
- 子解法3: 特征级别数据增强
- 原因: 传统的数据增强方法主要针对自然图像,对于医学图像这样的具有大域间差异的数据,效果不佳且可能增加计算负担和阻碍模型收敛。
- 通过在CNN的必要归一化层实施特征级别的数据增强,WIN方法避免了额外的计算开销,有效提升了分布外泛化能力。
这个研究提出的解决方案,聚焦于通过窗口归一化(WIN)和 WIN-WIN 自我蒸馏方法,解决医学图像数据在分布外场景下泛化能力不足的问题,通过特征级别数据增强和无参数归一化技术,简化模型设计的同时提高泛化性能。
不过新方法,也会遇到新问题:
子问题1: 在一致性背景下模型性能下降
- 子解法1: Block策略
- 原因: 对于具有一致性背景的图像(如染色体图像),WIN通过计算多个小窗口内的统计量来增强模型的泛化能力。
- 这种策略有效避免了零方差问题,并通过引入更多样化的扰动来提升模型性能。
传统方法:
考虑用于细胞分类的医学图像集,这些图像可能都有相似的背景,但细胞类型各不相同。
如果使用传统的归一化技术,如批归一化(BN),它可能会将背景的一致性误认为是一个有用的特征,而不是专注于细胞本身的变异性。
当模型遇到具有不同背景特征的新图像时,其性能可能会下降,因为模型已经适应了训练集中背景的统计特征。
Block策略:
使用Block策略,我们可以将每个图像分成多个块,然后在这些块的基础上独立计算局部统计信息。
在细胞分类的例子中,这意味着即使背景相同,模型也可以通过专注于每个块中细胞的特征来提高其区分不同细胞类型的能力。
这种方法提高了模型对背景变化的鲁棒性,因此在新的图像集上表现更好,即使这些新图像的背景与训练数据不同。
子问题2: 训练和评估统计不一致导致的泛化能力下降
- 子解法2: WIN-WIN 自我蒸馏
- 原因: 为了解决训练和评估时使用不同统计量导致的模型泛化能力下降问题,提出WIN-WIN自我蒸馏方法。
- 该方法通过两次前向传递 —— 一次使用混合统计量(训练模式),另一次使用全局统计量(评估模式)
- 并通过最小化两者之间的 Jensen-Shannon 散度和 交叉熵损失 来鼓励模型在不同视图之间保持一致性,从而提高模型在分布外数据上的泛化能力。
子问题3: 如何选择WIN中的统计量µ和σ以提升分布外泛化能力?
- 子解法3: 统计量混合
- 原因: 统计量混合有利于改善分布外泛化性能。
- 单独使用局部统计量会显著降低分布外泛化能力,而通过混合全局和局部统计量,可以在保持IND数据性能的同时提升分布外数据的泛化能力。
在心脏病变检测的任务中,训练数据可能主要来自一个地区的患者,这些患者的图像具有相似的成像特征。
传统方法可能会仅使用这些图像的全局统计量进行归一化处理,导致模型对于具有不同成像特征的其他地区患者的心脏图像泛化能力不足。
而WIN方法则会混合使用全局统计量和每个患者图像局部区域的统计量(例如,心脏特定区域的亮度和对比度),这样的混合策略能够让模型在遇到分布外的数据时,仍能准确识别病变。
子问题4: WIN中的不同局部统计计算方法对模型性能的影响
- 子解法4: 窗口和块(Window and Block)方法
- 原因: 窗口和块方法作为计算局部统计的最佳实践,相比于使用全局统计(如IN)或其他局部统计(如像素或掩膜)方式,这两种方法能更有效地改善分布外泛化能力。

假设一个用于皮肤病诊断的模型,传统方法可能会在全图像上计算统计量,而忽略了皮肤病征兆通常只出现在皮肤的小部分区域这一点。
相比之下,WIN方法使用窗口和块策略,专注于这些小区域内的统计量,使得模型能够更加精细地捕捉皮肤病变的特征,即使在病变特征在图像中占比非常小的情况下也能有效工作。
子问题5: 训练和评估不一致导致模型性能下降
- 子解法5: 统计混合与一致性约束的结合
- 原因: 单独移除统计混合或一致性约束只能边际性地帮助分布外泛化。
- 结合这两种机制可以互补地提升模型的分布外泛化能力,因为它们共同促进了训练和评估阶段特征的一致性。
设想一个在多个医院间部署的肺部CT扫描分类模型,这些医院使用不同的扫描设备。
传统方法可能会导致模型在面对一个新医院的扫描图像时性能下降。
传统方法:
由于设备差异,图像的分布可能有所不同。
如果在训练和评估时仅依赖于全局统计信息,如实例归一化(IN),模型可能无法很好地泛化到新数据集。
WIN-WIN 自我蒸馏:
在WIN-WIN方法中,模型在训练过程中使用两种归一化策略:
- 一种侧重于训练数据的局部统计特征(WIN)
- 另一种则使用更全面的全局统计信息
这使得模型在实际部署时,能够更好地适应新医院的数据分布,因为它已经学会了如何处理来自不同统计分布的数据。
子问题6: WIN和WIN-WIN策略的超参数敏感性
- 子解法6: 超参数调整
- 原因: 分布外泛化性能主要受窗口比例阈值τ的影响,而对δ(用于平衡交叉熵损失和Jensen-Shannon散度损失)不太敏感。
- 合理选择 τ (窗口大小的比例)可以优化模型性能,而 δ 的选择对性能的影响较小。
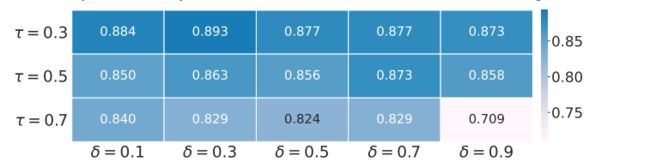
通过细粒度地探索统计量的选择、局部统计的计算方法以及WIN-WIN中的关键机制,研究人员能够明显提高模型对分布外数据的泛化能力。
同时,通过超参数的敏感性分析,确定了影响模型性能的关键因素,为进一步优化提供了方向。
比如,在对磁共振成像(MRI)进行肿瘤分割的任务中,训练数据集的大小可能会影响模型学习的统计特性。
传统方法可能会在固定的超参数设置下运行,而不考虑不同大小数据集的特性。
而WIN方法通过调整窗口比例阈值τ,能够根据数据集的特点优化性能,例如,小数据集可能需要更大的窗口来捕捉足够的上下文信息,而大数据集则可能需要较小的窗口以避免过拟合。
总结
子问题1: 医学图像中的局部特征表示不足
- 子解法1: 局部统计计算
- 原因: 传统归一化技术往往采用全局统计量,可能忽略了图像中的局部特征差异,这在医学图像中尤为重要,因为它们通常包含具有关键诊断信息的细微局部特征。
子问题2: 训练数据与新场景数据分布不一致
- 子解法2: 动态窗口采样
- 原因: 医学图像可能来自不同的设备或条件,这导致新场景(分布外)数据的分布与训练数据不同。动态窗口采样允许模型学习更通用的特征,使其对于分布变化更加鲁棒。
子问题3: 模型在分布外数据上泛化能力不足
- 子解法3: 统计量混合
- 原因: 单一来源的统计量可能会导致模型过度适应训练数据,而混合不同来源(如局部与全局)的统计量可以提高模型对未见过数据的适应能力。
子问题4: 训练与评估时的不一致性问题
- 子解法4: WIN-WIN自我蒸馏
- 原因: 训练与评估时使用不同的统计量可能导致模型的不一致性,WIN-WIN通过在训练过程中强制一致性,减少了这种不一致性,提高了模型的泛化能力。
子问题5: 传统数据增强方法不适用于医学图像
- 子解法5: 特征级数据增强
- 原因: 医学图像的关键信息通常位于小的局部区域,传统的像素级数据增强可能破坏这些关键信息。特征级数据增强通过在特征表示上实施增强,保留了这些关键局部信息。