python大数据语言基础期末复习笔记
前言:
复习笔记,主要是对老师ppt和网上的一些资料进行汇总。
一、语言基础:(非重点)
- 命名规范:变量名、模块名、包名通常采用小写,可使用下划线,通常前缀有一个下划线的变量名为全局变量。例如:rulemodule.py #模块名,即文件名_rule=’rule information’
- python使用缩进来组织代码,而不是其他语言比如R、C++、java和Perl那样用大括号。
- python语句都不是以分号结尾,而分号也是可以用于在一行内将多条语句进行分隔。
- python语言的一个重要特征就是对象模型的一致性。每一个数值、字符串、数据结构、函数、类、模块以及所有存在于python解释器中的事物都是python的对象。每一个对象都会关联到一种数据类型和内部数据。(不需要理解)
- 检查两个引用是否指向同一个对象可以用 is 关键字。is not 在你检查两个关键字是不是相同对象时也是有效的。
- 可变对象与不可变对象。Python中的大部分对象,例如列表、字典、Numpy数组都是可变对象,大多数用户定义的类型(类)也是可变的。可变对象中包含的对象和值是可以被修改的。还有其他的对象是不可变的,比如字符串、元组。
- 数值类型。基础的python数字类型就是int 和 float。int 可以存储任意大小的数字。float表示浮点数,每一个浮点数都是双精度64位数值。
- 字符串。字符串是Unicode字符的序列,因此可以被看作是一种序列。
数据类型:(重点)
1.列表:
(1)创建列表:
- List_a = []
- List_a.append(1)
List_a=[] List_a.append(1) List_a.append(2) print(List_a) #[1,2] - List_a=list((1,2,3,4))
List_a=list((1,2,3,4)) print(List_a) #[1,2,3,4] - List_a=[I for I in range(4)](列表生成式)
List_a=[I for I in range(4)] print(List_a) #[0,1,2,3]
(2)常用方法:
- Insert(<下标>,<元素>):在指定下标的位置上面插入元素
List_a=[1,2,4] List_a.insert(3,2) print(List_a) #[1,2,3,4] - pop(<下标>):删除指定下标的元素
List_a = [1, 2, 4] List_a.pop(2) print(List_a) #[1,2] - remove(<元素>):删除一个指定元素,下标小的优先
List_a = [1, 2,3,2, 4] List_a.remove(2) print(List_a) #[1,3,2,4] - count(<元素>):返回指定列表中元素的数目
List_a = [1, 2,3,2, 4] a=List_a.count(2) print(a) #2 - index(<元素>):返回指定元素的下标,小的优先
List_a = [1, 2,3,2, 4] a=List_a.index(2) print(a) #1 - copy(): 复制列表(浅拷贝)
List_a = [[1], 2, 3, 2, 4] List_b = List_a.copy() print(List_a)#[[1], 2, 3, 2, 4] print(List_b)#[[1], 2, 3, 2, 4] List_a[0][0] = 6 print(List_b)#[[6], 2, 3, 2, 4] - sort(
List_a = [1, 5, 3, 2, 4] List_b=List_a.copy() List_b.sort() print(List_b)#[1, 2, 3, 4, 5] List_b=List_a.copy() List_b.sort(reverse=True) print(List_b)#[5, 4, 3, 2, 1] List_b=List_a.copy() List_b.sort(key=lambda x:-x) print(List_b)#[5, 4, 3, 2, 1] - reserve():反转函数
List_a = [1, 5, 3, 2, 4] List_b=List_a.copy() List_b.reverse() print(List_a)#[1, 5, 3, 2, 4] print(List_b)#[4, 2, 3, 5, 1] - clear():删除函数
List_a = [1, 5, 3, 2, 4] List_a.clear() print(List_a)#[]
(3)切片:
格式List_a[strat:end:step]:start 表示起始索引,end 表示结束索引,step 表示步长。
相当:b = [List_a[((i+len(List_a))% len(List_a))] for i in range(start,end,step)](列表生成式)
List_a=[‘one’,’twe’,’three’,’four’,’five’]
| 元素 |
one |
Twe |
three |
four |
Five |
| 正向索引 |
0 |
1 |
2 |
3 |
4 |
| 反向索引 |
-5 |
-4 |
-3 |
-2 |
-1 |
List_a = ['one', 'twe', 'three', 'four', 'five']
print(List_a[0: 5])#['one', 'twe', 'three', 'four', 'five']
print(List_a[0: 5: 2])#['one', 'three', 'five']
print(List_a[0:-1:1])#['one', 'twe', 'three', 'four'](4)列表拼接:
- List_c=List_a+List_b
List_a = ['one', 'twe', 'three', 'four', 'five'] List_b=[1,2,3,4] List_c=List_b+List_a print(List_c)#[1, 2, 3, 4, 'one', 'twe', 'three', 'four', 'five'] - List_a.extend(<列表>)
List_a = ['one', 'twe', 'three', 'four', 'five'] List_b = [1, 2, 3, 4] List_a.extend(List_b) print(List_a)#['one', 'twe', 'three', 'four', 'five', 1, 2, 3, 4]
2.内置函数
- len():返回列表长度
List_a = ['one', 'twe', 'three', 'four', 'five'] print(len(List_a))#5 - type():返回数据类型
List_a = ['one', 'twe', 'three', 'four', 'five'] print(type(List_a))#
3.元组:
(1)建立元组:
- Tup_a=1,2,3,4
Tup_a=1,2,3,4 print(Tup_a)#(1,2,3,4) - Tup_a=(1,2,3,4)
Tup_a=(1,2,3,4) print(Tup_a)#(1,2,3,4) - Tup_a=tuple(List_a)
List_a=[1,2,3,4] Tup_a=tuple(List_a) print(Tup_a)#(1,2,3,4) - Tup_a=tuple(String_a)
String_a = "1234" Tup_a = tuple(String_a) print(Tup_a) # ('1','2','3','4')
(2)元组拼接
- Tup_c=Tup_a+Tup_b
- Tup_b=Tup_a*4
4.字典:
(1)建立字典:
Dict_a={‘a’:”adn”,4:5}
Dict_a={'a':"adn",4:5}
print(Dict_a)#{'a': 'adn', 4: 5}(2)添加元素:
Dict_a[6]=90
Dict_a={'a':"adn",4:5}
Dict_a[6]=90
print(Dict_a)#{'a': 'adn', 4: 5,6:90}(3)常见方法:
| len() |
测量字典中键值对个数 |
| keys() |
返回字典中所有的key |
| values() |
返回包含value的列表 |
| items() |
返回包含(键值,实值)元组的列表 |
| in \ not in |
判断key是否存在字典中 |
| popitem() | 从字典中删除最后一个键值对 |
| pop( |
删除拥有指定键的元素 |
| get( |
查找拥有指定键的元素,如果当前查找的key不存在则返回第⼆个参数(默认值),如果省略第⼆个参数,则返回 None。 |
(4)遍历:
value:
for i in dict_a.values():
keys:
for i in dict_a.keys():
所有项:
for i in dict_a.items():
Dict_a = {'a': "adn", 4: 5}
Dict_a[6] = 90
for i in Dict_a.values():
print(i,end=' ')#adn 5 90
print()
for i in Dict_a.keys():
print(i,end=' ')#a 4 6
print()
for i,j in Dict_a.items():
print(f"{i}:{j}",end=' ')#a:adn 4:5 6:90 5.函数(重点):
(1)创建函数:
Python 中使用def语句创建函数,其一般的格式如下所示:
def <函数名>(<参数1>,<参数2>,<参数3>……):
<函数主体>
return <返回值>
例子:
def myfuns(a,b):
c=a**b
return c(2)调用函数
myfuns(2,2)
在 Python 中, 还允许在函数中返回多个值。 只需将返回值以逗号隔开, 放在return关键字后面即可。例子:
def myfuns(a,b):
return a-b,a+b,a/b,a**b
a,b,c,d=myfuns(2,3)
print(a,b,c,d)
#-1,5,0,8(3)参数传递:
实参与形参按照从左到右的位置顺序依次赋值。
def f(x,a,b,c):
return a*x**2+b*x+c
print (f(2,1,2,3))为了避免位置参数赋值带来的混乱,Python 允许调用函数时通过关键字参数的形式指定形参与实参的对应关系。 调用者使用name=value的形式来指定函数中的哪个形参接受某个值:
def fun(name,age,score):
print("姓名:{0},年龄:{1},分数:{2}".format(name,age,score))
fun("Tom",20,100)
fun(name="Tom",score=100,age=20)在定义函数时, 为形参指定默认值, 就可以让该形参在调用时变为可选
单个星号将一组可变数量的位置参数组合成参数值的元组。在函数内部可以通过访问元组中的每个元素来使用参数。
def variablefun(name,*args):
print("位置参数:",name)
print("可变参数:",args)
variablefun("Python","简洁","优雅","面向对象")针对形参的关键字参数赋值形式, 利用 Python 定义函数时, 在形参前面加上双星号**来定义收集关键字参数的形参。此时形参是字典类型。
def fun(**args):
print(args)
fun(a=1,b=2)
fun(1,2)#(错误)在调用函数时,实参也可以使用*和**语法。此时不是收集参数,正好相反, 实参前加上*或**执行的是参数解包。 通常来说, 在列表、元组等类型的实参值前加上*, 将这些类型的元素解包成位置参数的形式;在字典类型的实参值前加上**,将字典的元组解包成关键字参数的形式。
当调用者的数据存储在列表中时, 可以通过在列表前加上*对列表解包来实现位置参数形式的调用。
def myfun(a,b,c,d):
print(a,b,c,d)
mylist = [10,20,30,40]
myfun(*mylist)当调用者的数据存储在字典中时, 可以通过在字典前加上**对字典解包来实现关键字参数形式的调用。
def fun(name,age,sex):
print("姓名:",name)
print("年龄:",sex)
print("性别:",age)
mydict = {'name':'Tom','age':20,'sex':'男'}
fun(**mydict)6.类
(1)定义类:
class ClassName:
“”“类的帮助信息”“” # 类文本字符串
statement # 类体ClassName:用于指定类名,一般使用大写字母开头。
“类的帮助信息”:用于指定类的文档字符串。
statement:类体,主要由类变量(或类成员)、方法和属性等定义语句组成。
(2)创建类的对象:
class语句本身并不创建该类的对象。所以在类定义完成以后,可以通过以下方法实例化该类的对象:
MyOr= ClassName()
(3)初始化:
在创建类后,类通常会自动创建一个__init__()方法,类似C++中的构造方法。每当创建一个类的新实例时,Python都会自动执行它。__init__()方法必须包含一个参数self,并且必须是第一参数。(self参数是一个指向实例本身的引用,用于访问类中的属性和方法。)
class Animal:
def __init__(self):
print("我是动物类")
wild = Animal()(4)成员:
def <函数名>(self,<参数1>,<参数2>,<参数3>……):
<函数主体>
return <返回值>方法:
模板如下:
使用:
class Animal:
def __init__(self):
print("我是动物类")
def Eat(self):
print(“进食中”)
Wild=Animal()
Wild.Eat()self为必备参数
变量:
例子:
class Animal:
eatsound=”进食中”
def __init__(self):
print("我是动物类")
def Eat(self):
print(“进食中”)
Wild=Animal()
print(Wild.eatsound)(5)访问限制:
在Python中,以下划线开头的变量名和方法名有特殊的含义,尤其是在类的定义中。
_xxx:受保护成员,不能用'from module import *'导入;
__xxx__:系统定义的特殊成员;
__xxx:私有成员,只有类对象自己能访问,子类对象不能直接访问到这个成员,但在对象外部可以通过“对象名._类名__xxx”这样的特殊方式来访问。
注意:Python中不存在严格意义上的私有成员。
二.Numpy使用(重点)
1.建立数组的方法:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 序号 |
参数及描述 |
| 1. |
object 任何暴露数组接口方法的对象都会返回一个数组或任何(嵌套)序列。 |
| 2. |
dtype 数组的所需数据类型,可选。 |
| 3. |
copy 可选,默认为true,对象是否被复制。 |
| 4. |
order C(按行)、F(按列)或A(任意,默认)。 |
| 5. |
subok 默认情况下,返回的数组被强制为基类数组。 如果为true,则返回子类。 |
| 6. |
ndmin 指定返回数组的最小维数。 |
numpy.zeros(shape, dtype = float, order = 'C')(全为0的数组)
b = np.zeros((2,3))
print(b)
#[[0. 0. 0.]
# [0. 0. 0.]]
numpy.empty(shape, dtype = float, order = 'C')(空数组)
import numpy as np
b = np.empty((2,3))
print(b)
#[[1.e-323 0.e+000 0.e+000]
# [0.e+000 0.e+000 0.e+000]]
numpy.ones(shape, dtype = None, order = 'C')(全为1的数组)
import numpy as np
b = np.ones((2,3))
print(b)
#[[1. 1. 1.]
# [1. 1. 1.]]shape空数组的形状,整数或整数元组dtype所需的输出数组类型,可选order'C'为按行的 C 风格数组,'F'为按列的 Fortran 风格数组
numpy.asarray(a, dtype = None, order = None)(将Python序列转换为ndarray)
a为任意形式的Python序列
import numpy as np
a=[[1,2],[3,4]]
b = np.asarray(a)
print(b)
#[[1 2]
# [3 4]]linspace(start,stop,num)(等差数列)
- start:开始下标
- end:结束下标
- num:数列数目
arange(start,stop,step,dtype)(和range函数用法基本一致)import numpy as np b = np.linspace(1,5,9) print(b)#[1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. ]import numpy as np b = np.arange(1,10,2) print(b)#[1 3 5 7 9]
2.数据类型
| 1. |
bool_ 存储为一个字节的布尔值(真或假) |
| 2. |
int_ 默认整数,相当于 C 的long,通常为int32或int64 |
| 3. |
intc 相当于 C 的int,通常为int32或int64 |
| 4. |
intp 用于索引的整数,相当于 C 的size_t,通常为int32或int64 |
| 5. |
int8 字节(-128 ~ 127) |
| 6. |
int16 16 位整数(-32768 ~ 32767) |
| 7. |
int32 32 位整数(-2147483648 ~ 2147483647) |
| 8. |
int64 64 位整数(-9223372036854775808 ~ 9223372036854775807) |
| 9. |
uint8 8 位无符号整数(0 ~ 255) |
| 10. |
uint16 16 位无符号整数(0 ~ 65535) |
| 11. |
uint32 32 位无符号整数(0 ~ 4294967295) |
| 12. |
uint64 64 位无符号整数(0 ~ 18446744073709551615) |
| 13. |
float_ float64的简写 |
| 14. |
float16 半精度浮点:符号位,5 位指数,10 位尾数 |
| 15. |
float32 单精度浮点:符号位,8 位指数,23 位尾数 |
| 16. |
float64 双精度浮点:符号位,11 位指数,52 位尾数 |
| 17. |
complex_ complex128的简写 |
| 18. |
complex64 复数,由两个 32 位浮点表示(实部和虚部) |
| 19. |
complex128 复数,由两个 64 位浮点表示(实部和虚部) |
3.属性
- shape:返回数组大小,可通过直接改变shape属性调整数组大小。
- ndim:返回数组维度。
- itemsize:返回数组单个元素长度。
- flags:返回该数组的其他属性。
import numpy as np a=np.array([[1,2],[3,4]]) print(a.ndim)#2 print(a.shape)#(2, 2) print(a.itemsize)#4 print(a.flags) # C_CONTIGUOUS : True # F_CONTIGUOUS : False # OWNDATA : True # WRITEABLE : True # ALIGNED : True # WRITEBACKIFCOPY : False
4.常用方法
numpy.reshape(arr, newshape, order)(修改形状)
- arr:要修改形状的数组
- newshape:整数或者整数数组,新的形状应当兼容原有形状
a=np.array([[1,2],[3,4]]) b=np.reshape(a,(4)) print(b)#[1 2 3 4]
numpy.ndarray.T(数组转置)
import numpy as np
a=np.array([[1,2],[3,4]])
b=a.T
print(b)
#[[1 3]
# [2 4]]numpy.concatenate((arr1, arr2, ...), axis)
- arr1, arr2, ...:相同类型的数组序列
- axis:沿着它连接数组的轴,默认为 0
import numpy as np a=np.array([[1,2],[3,4]]) b=np.array([[5,6],[7,8]]) print(np.concatenate([a,b])) #[[1 2] # [3 4] # [5 6] # [7 8]] print(np.concatenate([a,b],axis=1)) #[[1 2 5 6] # [3 4 7 8]]
numpy.split(ary, indices_or_sections, axis)( 沿特定的轴将数组分割为子数组)
- ary:被分割的输入数组
- indices_or_sections:可以是整数,表明要从输入数组创建的,等大小的子数组的数量。 如果此参数是一维数组,则其元素表明要创建新子数组的点。
- axis:默认为 0
import numpy as np a=np.array([[1,2],[3,4],[5,6],[7,8]]) b,c=np.split(a,2) print(b) #[[1 2] # [3 4]] print(c) #[[5 6] # [7 8]] b,c=np.split(a,[1]) print(b) #[[1 2]] print(c) #[[3 4] # [5 6] # [7 8]] b,c=np.split(a,2,axis=1) print(b) #[[1] # [3] # [5] # [7]] print(c) #[[2] # [4] # [6] # [8]]
numpy.resize(arr, shape)
返回指定大小的新数组。 如果新大小大于原始大小,则包含原始数组中的元素的重复副本。 与reshape类似。
import numpy as np
a=np.array([[1,2],[3,4],[5,6],[7,8]])
b=np.resize(a,5)
print(b)#[1 2 3 4 5]
b=np.resize(a,10)
print(b)#[1 2 3 4 5 6 7 8 1 2]numpy.insert(arr, obj, values, axis)
arr:输入数组
obj:在其之前插入值的索引
values:要插入的值
axis:沿着它插入的轴,如果未提供,则输入数组会被展开
import numpy as np
a=np.array([[1,2],[3,4],[5,6],[7,8]])
b=np.insert(a,0,19)
print(b)#[19 1 2 3 4 5 6 7 8]
b=np.insert(a,0,10,axis=0)
print(b)
#[[10 10]
# [ 1 2]
# [ 3 4]
# [ 5 6]
# [ 7 8]]
b=np.insert(a,0,10,axis=1)
print(b)
#[[10 1 2]
# [10 3 4]
# [10 5 6]
# [10 7 8]]numpy.unique(arr)数组去重
import numpy as np
a=np.array([[1,2],[3,4],[3,2],[7,8]])
b=np.unique(a)
print(b)
#[1 2 3 4 7 8]三、Pandas使用
1.DataFrame构造
DataFrame(data , index , columns , dtype , copy )
data:数据
index:行标题
columns:列标题
dtype:类型
copy:是否深拷贝
如果data类型为字典,可省略列标题
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
print(a)
one twe three four
a 1 2 3 4
b 5 6 7 82.文件读取
read_csv(filepath_or_buffer, delimiter, header, engine, encoding)
filepath_or_buffer : 文件路径,
delimiter :分隔符
header : 是否第一行为列标题,
engine : 引擎
encoding : 编码
read_excel(filepath_or_buffer, header, names)
filepath_or_buffer:路径
header : 指定哪一行为标题
names : 指定列标题
3.常用函数
head(num=5)#查看前几行数据
tail(num=5)#查看后几行数据
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
print(a.head(1))
one twe three four
a 1 2 3 4
print(a.tail(1))
one twe three four
b 5 6 7 8info()#查看数据信息
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
print(a.info)
describe()#查看数据统计信息
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
print(a.describe())
one twe three four
count 2.000000 2.000000 2.000000 2.000000
mean 3.000000 4.000000 5.000000 6.000000
std 2.828427 2.828427 2.828427 2.828427
min 1.000000 2.000000 3.000000 4.000000
25% 2.000000 3.000000 4.000000 5.000000
50% 3.000000 4.000000 5.000000 6.000000
75% 4.000000 5.000000 6.000000 7.000000
max 5.000000 6.000000 7.000000 8.000000pandas.merge(left = dataFrame1,right = dataFrame2,left_index = True, right_index = True, how = 'inner') 用于合并两个 DataFrame 对象或 Series对象。只能用于两个表的拼接(左右拼接,不能用于上下拼接 。
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
b=pd.DataFrame([[11,12,13,14],[15,16,17,18]],index=['a','b'],columns=['one1','twe1','three1','four1'])
print(pd.merge(left=a,right=b,left_index=True,right_index=True,how = 'inner'))
one twe three four one1 twe1 three1 four1
a 1 2 3 4 11 12 13 14
b 5 6 7 8 15 16 17 18drop(key, axis = 1, inplace = False)(删除列或者行)
(使用, axis = 0表示对行操作, axis = 1表示针对列的操作, inplace为True, 则直接在源数据上进行修改, 否则源数据会保持原样)
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
print(a.drop('one',axis=1))
twe three four
a 2 3 4
b 6 7 8
DataFrame.loc[‘name’]=[](增加行)
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
a.loc['c']=[1,2,3,4]
print(a)
one twe three four
a 1 2 3 4
b 5 6 7 8
c 1 2 3 4DataFrame[‘name’]=[](增加列)
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
a['five']=[1,2]
print(a)
one twe three four five
a 1 2 3 4 1
b 5 6 7 8 2df.insert(loc, column, value, allow_duplicates=False)(增加列)
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
a.insert(loc=0,column='five',value=2)
print(a)
five one twe three four
a 2 1 2 3 4
b 2 5 6 7 8concat(dataFrame列表)( 将这些dataFrame的数据纵向叠加)
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,8]],index=['a','b'],columns=['one','twe','three','four'])
b=pd.DataFrame([[11,12,13,14],[15,16,17,18]],index=['a','b'],columns=['one','twe','three','five'])
c=pd.concat([a,b])
print(c)
one twe three four five
a 1 2 3 4.0 NaN
b 5 6 7 8.0 NaN
a 11 12 13 NaN 14.0
b 15 16 17 NaN 18.0dropna() (只要一行中任意一个字段为空,就会被删除)
import numpy as np
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,np.nan]],index=['a','b'],columns=['one','twe','three','four'])
print(a)
a=a.dropna()
print(a)
one twe three four
a 1 2 3 4.0
b 5 6 7 NaN
one twe three four
a 1 2 3 4.0isnull()(返回布尔DataFrame对象)
import numpy as np
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,np.nan]],index=['a','b'],columns=['one','twe','three','four'])
print(a)
a=a.isnull()
print(a)fillna(值)( 用值填充空值)
import numpy as np
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,np.nan]],index=['a','b'],columns=['one','twe','three','four'])
print(a)
a=a.fillna(109)
print(a)
one twe three four
a 1 2 3 4.0
b 5 6 7 NaN
one twe three four
a 1 2 3 4.0
b 5 6 7 109.0
drop_duplicates( keep = 'first' 或 'last')( 删除完全重复行, 可指定某字段重复时删除, 默认保留第一个, 后面重复的会删掉)
import numpy as np
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,np.nan]],index=['a','b'],columns=['one','twe','three','four'])
a=pd.concat([a,a])
print(a)
a=a.drop_duplicates()
print(a)
one twe three four
a 1 2 3 4.0
b 5 6 7 NaN
a 1 2 3 4.0
b 5 6 7 NaN
one twe three four
a 1 2 3 4.0
b 5 6 7 NaNsort_values(by = 列名, ascending = 是否升序)( 对指定列排序)
import numpy as np
import pandas as pd
a=pd.DataFrame([[1,2,3,4],[5,6,7,np.nan]],index=['a','b'],columns=['one','twe','three','four'])
a=pd.concat([a,a])
print(a)
a=a.sort_values('one')
print(a)
one twe three four
a 1 2 3 4.0
b 5 6 7 NaN
a 1 2 3 4.0
b 5 6 7 NaN
one twe three four
a 1 2 3 4.0
a 1 2 3 4.0
b 5 6 7 NaN
b 5 6 7 NaNsort_index(ascending=False,ignore_index=True)(可以将DataFrame按照索引的大小顺序重新排列)
groupby('列名')( 对指定列分组, 就是把该列值一样的分成一组)
cut(x = 切分数据, bins = 切分方式, right = 是否包含右区间, labels = 分割后每段的名字列表)( 对一个数组进行分段)
set_index(keys,drop=True)keys:列索引名称或者列索引名称的列表drop:默认为True,当作新的索引,删除原来索引(重新设置索引)
data[列索引].value_count()(统计每种数据的个数)
isin(值)(条件筛选)
4.索引
dataFrame.iloc[行下标, 列下标]
dataFrame.iloc[行下标数组, 列下标数组]
dataFrame.iloc[行布尔列表, 列布尔列表]
data.loc[行标签,列标签]
四、matplotlib使用(非重点)
1.折线图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.axes()
x = np.linspace(0, 10, 1000)
plt.plot(x, np.sin(x))
plt.plot(x, np.cos(x))
plt.show()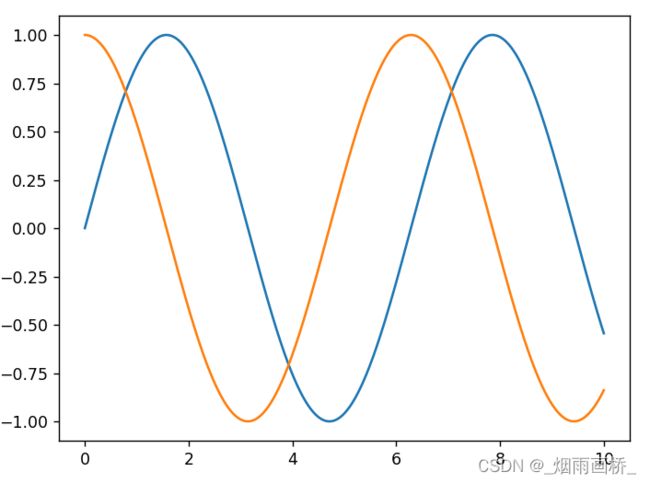
2.散点图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 30)
y = np.sin(x)
plt.plot(x, y, 'o', color='black')
plt.show()
3.条形图
import matplotlib.pyplot as plt
GDP = [12406.8,13908.57,9386.87,9143.64]
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']#显示中文
plt.rcParams['axes.unicode_minus'] = False
plt.bar(range(4), GDP, align = 'center',color='steelblue', alpha = 0.8)
plt.ylabel('GDP')
plt.title('四个直辖市GDP大比拼')
plt.xticks(range(4),['北京市','上海市','天津市','重庆市'])
plt.ylim([5000,15000])
for x,y in enumerate(GDP):
plt.text(x,y+100,'%s' %round(y,1),ha='center')
plt.show()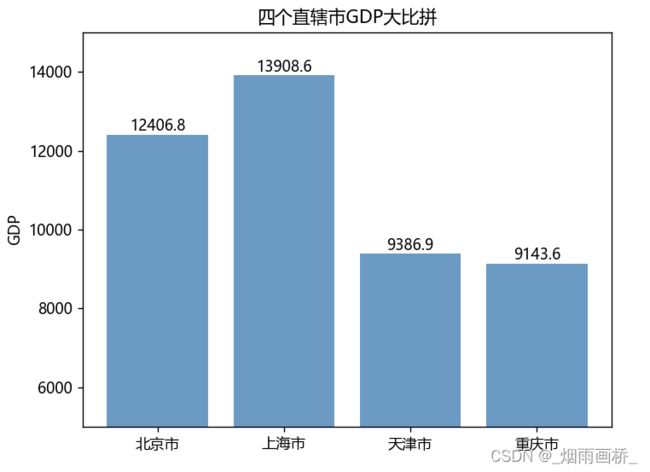
4.直方图
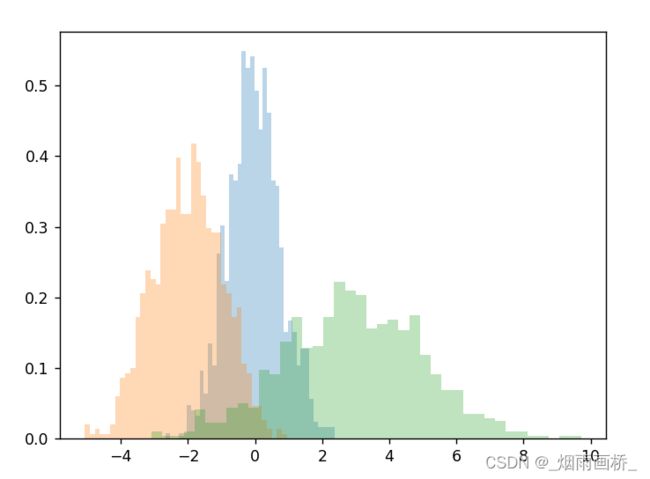
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
x1 = np.random.normal(0, 0.8, 1000)
x2 = np.random.normal(-2, 1, 1000)
x3 = np.random.normal(3, 2, 1000)
kwargs = dict(histtype='stepfilled', alpha=0.3, density=True, bins=40)
plt.hist(x1, **kwargs)
plt.hist(x2, **kwargs)
plt.hist(x3, **kwargs)
plt.show()