Java语法学习集合
Java语法学习集合
大纲
- 集合简介
- 集合的框架体系图
- Collection的常用方法
- List
- Set
- Map
- 集合的选择
- Collections工具类
- 练习题
具体案例
1. 集合简介

相对于数组,元素个数不限,而且能够存储不同的类型
2. 集合的框架体系图(基础的)
单列集合:

补充一个:LinkedHashSet
双列集合:
3. collection
基本介绍

常用方法

对于第一点
直接调用add方法添加
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
System.out.println(list);
}
对于第二点
可以指定删除的索引,返回布尔值,或者删除指定的对象,返回对象
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
//删除指定的索引,返回布尔值
System.out.println( list.remove(1));
//删除指定的对象,返回对象
System.out.println( list.remove(true));
System.out.println(list);
}
对于第三点
查找有没有指定的对象,返回布尔值
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
//查找有没有指定的对象,返回布尔值
System.out.println(list.contains("Tom"));
}
}
对于第四点
返回集合的长度
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
//返回集合的长度
System.out.println(list.size());
}
对于第五点
判断集合是不是空
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
//判断集合是不是空,返回布尔值
System.out.println(list.isEmpty());
}
对于第六点
清空集合的所有元素
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
//清空集合的所有元素
list.clear();
}
对于第七–九点
添加一个实现了collection接口的对象里的对象
查找一个实现了collection接口的对象里的对象
删除一个实现了collection接口的对象里的对象
都返回布尔值
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
List list1 = new ArrayList();
list1.add("你好");
//添加一个实现了collection接口的对象里的对象
list.addAll(list1);
//查找一个实现了collection接口的对象里的对象
list.containsAll(list1);
//删除一个实现了collection接口的对象里的对象
list.removeAll(list1);
}
接口/迭代器
快捷键:itit
迭代器的原理
案例:
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
}
}
如果还想再次用迭代器,此时的指针已经指向了最后一个元素了,所以需要重置迭代器
iterator = list.iterator();
增强for循环

其实底层依然是迭代器
代码实例:
public static void main(String[] args) {
List list = new ArrayList();
list.add("Tom");
list.add(19);
list.add(true);
for (Object obj:
list) {
System.out.println(obj);
}
}
4.List
基本介绍

- 元素可重复
- 支持调用get(索引)方法取出
- 每个元素有序,添加顺序和取出顺序一致
常用方法
对于第一点
通过索引,插入元素到指定位置
public static void main(String[] args) {
List list = new ArrayList();
list.add("李二");
list.add("王五");
list.add(1,"张三");
}
最后结果:李二,张三,王五
对于第二点
和collection的addall一样,还是可以指定开始添加索引的位置
对于第三点
通过get(索引)方法
public static void main(String[] args) {
List list = new ArrayList();
list.add("李二");
list.add("王五");
list.add(1,"张三");
System.out.println(list.get(2));
}
对于第四点
indexOf()返回我们查询对象第一次出现位置的索引
对于第五点
lastIndexOf()返回我们查询对象最后一次出现位置的索引
和上面一点类似于StringBuffer与StringBuilder的index方法
对于第六点
和collection接口的remove方法一样
public static void main(String[] args) {
List list = new ArrayList();
list.add("李二");
list.add("王五");
list.add(1,"张三");
list.remove(2);
}
对于第七点
注意:返回的是被替换的那个对象
public static void main(String[] args) {
List list = new ArrayList();
list.add("李二");
list.add("王五");
list.add(1,"张三");
//返回被替换的那个对象
System.out.println(list.set(1,"张麻子"));
}
对于第八点
实现对指定索引(前闭后开)的元素截取,返回截取元素构成的集合
public static void main(String[] args) {
List list = new ArrayList();
list.add("李二");
list.add("王五");
list.add(1,"张三");
//实现对指定索引(前闭后开)的元素截取,返回截取元素构成的集合
System.out.println(list.subList(0,2));
}
ArrayList
线程不安全,执行效率高,在底层是数组
底层机制
具体操作看源码(不同版本JDK可能不同)
Vector
基本介绍
线程安全
Vector与ArrayList的比较
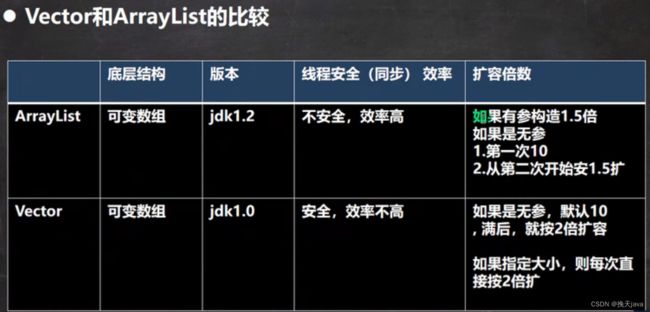
对于无参构造器,Vector是默认数组大小为十,而ArrayList默认为零,是在第一次添加后才变为十
LinkedList
底层结构
线程也不安全

LinkedList的方法与上面的没有什么区别,比如,增加,删除,修改,遍历等等
下面是比较
LinkedList与ArrayList的比较
都是线程不安全的,底层的结构不一样,一个适合改查,一个适合增删
5.Set

与List不同,Set无序且不允许重复
注意:这里的无序指的是存储时的位置是根据hash值来的,在数组里面存储是没有顺序的
实现了Collection接口的所有方法
HashSet
基本介绍
注意
这里对不能有重复对象的理解
先看代码结果
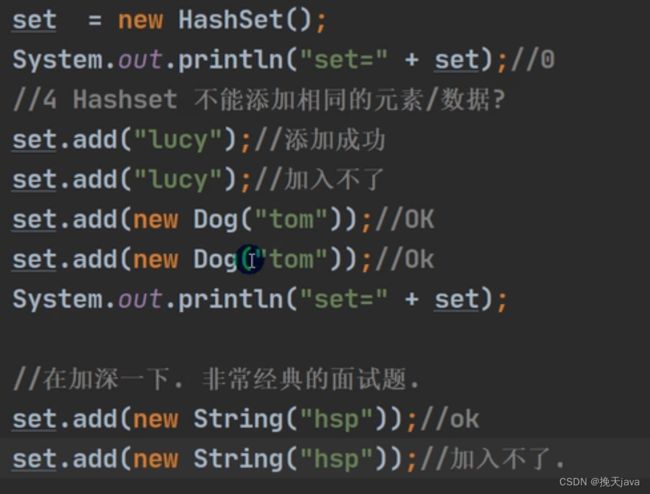
我们在前面知道,两个new String 是不同的对象,但是这里还是只能添加一个
这里是对无序的理解
因为我们的HashSet底层是数组 + 单向链表,存储在数组时,是根据hash值来存储到数组的不同位置上,所以当我们取出时,不是原来我们先后存储的顺序,而是根据在数组中排的位置来的
底层结构
数组+单向链表


添加/数组扩容
对于临界值,每次添加一个新结点,不管是不是table的某个元素的首位置,还是某个元素链表上的结点,都要算作一次添加,当添加次数达到临界值时,就会发生数组扩容
另外一种就是,当某条链表达到8个结点,但是table还没有达到64,如果该已经达到链表再增加结点,就会进行一次table的数组扩容
对于第二点
这个哈希值不hashcode,是在他的基础上,进行了一个算法后的结果
对于第五点
equals用什么标准,是我们程序员可以通过重写控制的(因为动态绑定机制)
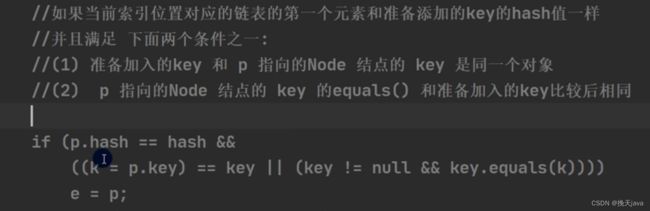
先比较哈希值是否相同,再在对象相同,或者equals方法比较中,满足一个后,如果为true,则代表相同
具体看源码
LinkedHashSet
基本介绍

注意
存储元素的位置是无序的,但是取出是有序的
理解:
因为我们LinkedHashSet的底层是 数组 + 双向链表,存储在数组时,是根据hash值来存储到数组的不同位置上,但是双向链表是有添加的先后顺序的,所以当我们取出时,也是原来的先后顺序
底层机制
数组 + 双向链表

具体看源码
TreeSet
底层是TreeMap
可以通过自己指定排序方式排序,如果不指定默认的是compare方法
public static void main(String[] args) {
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o1).length() - ((String) o2).length();
}
});
treeSet.add("张");
treeSet.add("王麻子");
treeSet.add("李四");
treeSet.add("陈平安");
//因为比较的是长度,所以添加不进去陈平安了;
System.out.println(treeSet);
}
而在添加数据的时候,就按照我们重写的compare方法比较是否相同,如上,我们比较的是长度,那如果再添加,就添加不进去了,就只会替换value的值
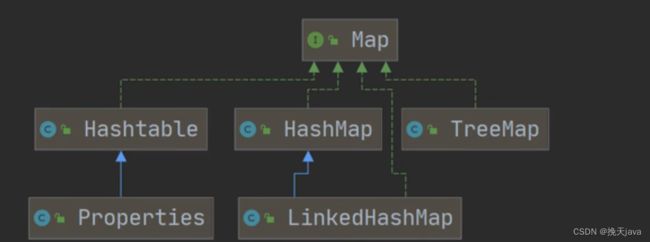
6.Map
可以理解为真正的数据还是存储在table当中,table存的结点,结点里面有key和value,而为了方便遍历,有一个EntrySet的集合,里面存放的是Entry(一种接口),但是Node(结点)实现了Entry,所以相当于也可以存放结点(引用结点的地址),而结点里面存放的是对key,value的地址(相当于引用,指向真正的table里面的k-v),
这种方式帮助我们更好的遍历集合。并且Entry里面提供了getKey()与getValue(),可以分别的单独取出key与value
keySet()可以返回Map集合中的key到一个Set集合中,value()可以返回Map集合中的value到一个Collection的集合中,当然这两种返回方式都是引用的地址
注意
如果这里的key重复了,会把对应的value值替换掉,而不是set的放不进去,对于第五点,如果key有重复的null,也会发生替换
常用方法

- Put
第一位放key,第二位value
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
}
- remove
直接删除key,key与value两个都写也行
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
}
- get
返回输入的一个key值对应的value的对象
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
Object object = map.get("一号");
}
- size
获取有几个键对值
int n = map.size();
- isEmpry
判断是否为空,返回布尔值
boolean n = map.isEmpty();
- clean
清楚所有键对值
map.clean();
- containKey
输入key值,查找是否存在,返回布尔值
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.containsKey("一号");
}
Map的六大遍历方式

1. keySet取key,再取value
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.put("二号","李四");
map.put("三号","王五");
Set keySet = map.keySet();
for (Object key:keySet
) {
System.out.println(key + "-" +map.get(key));
}
}
2.keySet的迭代器
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.put("二号","李四");
map.put("三号","王五");
Set keySet = map.keySet();
Iterator iterator = keySet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next + "-" + map.get(next));
}
}
3.value方法取值(增强for)
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.put("二号","李四");
map.put("三号","王五");
Collection value = map.values();
for (Object object : value) {
System.out.println(object);
}
}
4.value方法取值(迭代器)
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.put("二号","李四");
map.put("三号","王五");
Collection value = map.values();
Iterator iterator = value.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
5.通过EntrySet方法(增强for)
把EntrySet返回的对象转换为Map。Entry后,调用getkey,和getvalue方法来实现遍历
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.put("二号","李四");
map.put("三号","王五");
Set entry = map.entrySet();
for (Object object : entry) {
Map.Entry n = (Map.Entry)object;
System.out.println(n.getKey() + "-" + n.getValue());
}
}
6. 通过EntrySet方法(迭代器)
public static void main(String[] args) {
Map map = new HashMap();
map.put("一号","张三");
map.put("二号","李四");
map.put("三号","王五");
Set entrySet = map.entrySet();
Iterator iterator = entrySet.iterator();
while (iterator.hasNext()) {
Object object = iterator.next();
Map.Entry entry = (Map.Entry)object;
System.out.println(entry.getKey() + "-" + entry.getValue());
}
}
总结
其实主要还是分为迭代器和增强for循环两种,记住keyset,Values,和entryset返回的都是一个集合,然后用对集合的处理遍历方式就行,只不过对于entryset返回的对象,要转为Map.Entry后才能调用它的方法
HashMap
底层结构
具体的源码和hashset的一样,hashset的底层就是hashmap
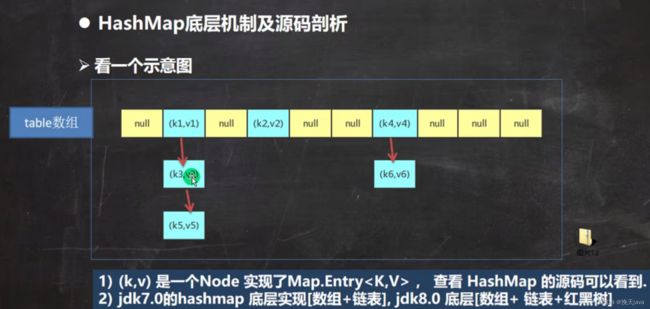
小结
- 线程不安全
- 可以存放null
Hashtable

扩容机制:
初始容量为11,临界因子为0.75,初始临界值为8.当达到临界值后,进行扩容,扩容是容量乘以2,再加1,最后再判断是否超过最大容量
注意:
线程安全,不能存放null,也是无序的
Hashtable与HashSet比较

properties
基本介绍

是Hashtable的子类,put方法和其一样,不能放null,也是无序的
常用方法:

LinkedHashMap
与LinkedHashSet一样,维护的是一个双向链表和数组,可以保证我们放入和取出顺序一致,LinkedHashSet的底层就是LinkedHashMap
TreeMap
TreeSet的底层就是TreeMap,与其基本一致
默认按照字母排序,自己也可以通过匿名内部类来重写比较的接口
如果按照我们的比较方式判断key相同,也只会替换value的值
7.集合的选择
当然这可以选择ArrayList和HashMap的时候,考虑线程安不安全,就可以对应用vector和Hashtable分别进行替换
8. Collections工具类
对于第五点,使用匿名内部类重写比较方法
对于第六点
在进行集合的拷贝时,要注意让两个集合的长度相同
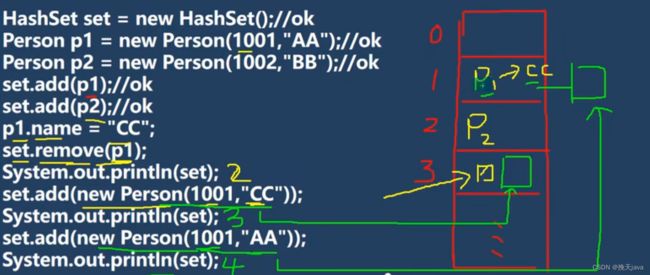
9. 练习题
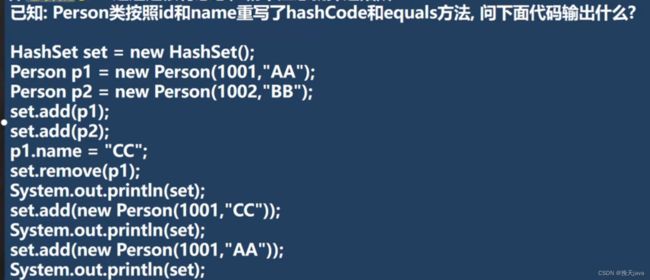
前提:注意题目重写了hashcode与equals方法
最后三个都能添加进去
分析:
因为在P1.name更改p1,所以在后面的删除remove(p1)时,重新按照p1计算哈希值,就定位不了原来的p1的哈希值确定的位置
而后面添加(1001,“cc”),计算出来的哈希值,和原来p1的哈希值不一样。所以即使p1已经是(1001,“cc”),也能添加进去
最后添加(1001,“AA”),添加的是原来p1的哈希值的位置,添加后因为内容不相同,比较后,添加到链表最后一位