SSVEPNet:使用标签平滑与谱归一化的高效CNN-LSTM网络
SSVEPNet:使用标签平滑与谱归一化的高效CNN-LSTM网络
- 1.论文摘要
- 2.背景介绍
- 3.CNN-LSTM网络
- 4.正则化技术
-
- 4.1. 基于视觉注意力机制的标签平滑技术
- 4.2.谱归一化技术
- 5.实验结果
-
- 5.1 被试内实验结果
- 5.2 跨被试实验结果
- 5.3 消融实验结果
- 5.4 t-SNE可视化结果
- 6.讨论与思考
-
- 6.1 网络参数量对深度学习模型性能的影响
- 6.2 三层全连接层是否必要
- 6.3 缺陷与未来工作
- 7.结论
1.论文摘要
该论文发表在IOPScience旗下的Journal of Neural Engineering(JNE)期刊。JNE是BCI领域的老牌SCI期刊,在领域的影响力较大。期刊的JCR分区为2区,中科院分区为2区,2022影响因子IF为5.043。
原论文链接: An efficient CNN-LSTM network with spectral normalization and label smoothing technologies for SSVEP frequency recognition
公开代码链接:https://github.com/YuDongPan/SSVEPNet
目标:基于稳态视觉诱发电位(SSVEP)的脑机接口因其较高的信息传输速率与可使用的大量识别目标而备受研究人员青睐。然而,SSVEP的频率识别方法的性能在被试内实验中严重依赖于校准数据的数量。一些研究者尝试使用深度学习(DL)模型做跨被试实验,但它们的性能相比于被试内实验的效果而言仍具有较大的提升空间。
方法: 为了解决这些问题,本文提出了一个基于卷积神经网络-长短时记忆网络(CNN-LSTM)的高效SSVEP深度学习模型,称之为SSVEPNet。为了进一步提高SSVEPNet的性能,在实现网络的过程中我们采用了标签平滑机制与谱归一化技术。
主要结果:为了验证SSVEPNet的性能,SSVEPNet分别在两个数据集(12分类与4分类)、2个时窗(0.5s与1s)、3个不同规模的数据集上与其他传统的SSVEP识别方法与深度学习方法进行了对比。实验的结果表明,SSVEPNet的性能在所有情况下均优于其他方法。
重要意义: 大量的实验结果表明提出的模型有望提高基于SSVEP的脑机接口系统性能。额外的消融实验与t-SNE可视化实验论证了SSVEPNet结构设计的合理性、有效性与可解释性。使用CNN与LSTM结合的混合网络结构,以及标签平滑机制与谱归一化机制, 对于设计针对于脑电数据的模型而言可作为有效的优化策略。
2.背景介绍
纵使稳态视觉诱发电位(SSVEP)在诱发成分的基频与谐波上具有显著的峰值特性,大多数受欢迎的SSVEP频率识别方法都基于时域信号,如典型相关分析(CCA),多元同步索引(MSI)等。CCA,MSI方法作为无监督的频率识别方法,不需要使用BCI用户的校准数据便可以取得不错的识别性能 。然而,它们在识别短时窗(识别的信号长度)或具有较多刺激目标的SSVEP信号时性能急剧下降。
自2018年以来,基于个体校准数据的有监督范式SSVEP识别方法在清华大学公开的40分类数据集(Benchmark)取得了极佳的分类性能,显著优于CCA,MSI等无监督方法,如TRCA,CORRCA等算法,拉开了有监督范式SSVEP识别方法的正式帷幕。以TRCA与CORRCA算法为代表的有监督范式SSVEP识别方法在识别短时窗或具有较多刺激目标的SSVEP信号时也依旧能取得不错的性能,但它们的性能严重依赖于个体校准数据的数量。
事实上,采集BCI用户的校准数据是一个实时且费力的过程,且数据采集的质量会因用户长时间实验造成的疲劳反应而下降。因此,在提高SSVEP识别性能的过程中同时尽可能地减少个体校准数据的采集时间(即校准时间),是基于SSVEP的BCI系统中一个非常重要的研究问题。其中一个可行的方法设计依赖于较少校准数据的频率识别方法,另一个可行的方法则是利用已有的被试数据来促进新被试频率识别方法的实施。
近年来,基于深度学习模型的SSVEP频率识别方法,能够通过采用留一被试法(LOSO)的方法开展跨被试范式实验(即利用N-1个被试的数据训练得到模型,之后在剩余的1个被试上进行测试),并取得了不错的分类结果, 如EEGNet,C-CNN,FBtCNN等。然而,由于被试之间存在巨大的多样性差异,这些深度学习方法在跨被试实验中得到的结果相较于被试内实验而言仍具有较大的提升空间。除此之外,这些深度学习方法在进行被试内实验时常因数据量不足而性能欠佳。
为了弥补深度学习模型无法同时在数据量少的被试内实验下与数据量大的跨被试实验下取得较高性能的不足,我们提出了一个使用标签平滑机制与谱归一化技术的高效CNN-LSTM网络。其中,CNN用于提取SSVEP信号的时-空特征,而LSTM根据时-空特征之间的依赖性进行编码。最后,编码好的细粒度特征被输入至一个由3层全连接组成的大规模神经网络。为了解决可能存在的过拟合问题,我们使用了基于视觉注意力的标签平滑技术与谱归一化技术来缓解过拟合现象。通过在两个不同的数据集,两个不同的时窗大小,3个不同的数据规模下的被试内实验,以及跨被试实验下的结果,验证了我们所提方法的有效性。额外的消融实验与t-SNE特征可视化实验则说明了我们模型设计的合理性与可解释性。
3.CNN-LSTM网络
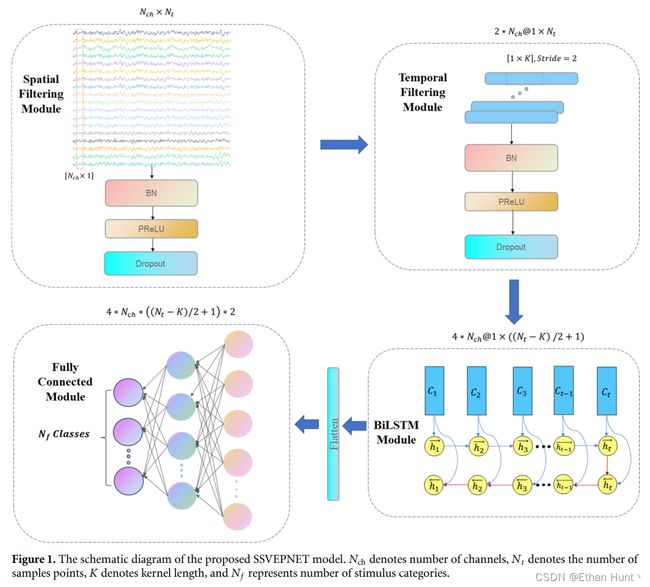
如图1所示,我们提出的CNN-LSTM网络主要由个4模块组成:空间滤波模块(Spatial Filtering Module),时间滤波模块(Temporal Filtering Module),双向长短时记忆网络模块(Bi-Long Short-Term Memory Module)与全连接模块(Fully Connected Module)。其中,空间滤波模块通过在空间维度上进行一维卷积操作模拟基于个体校准数据的传统方法,学习 2 ∗ N c 2*N_c 2∗Nc个标识每个电极通道重要性的空间滤波器,得到空间特征。时间滤波模块则利用在时间维度的一维卷积操作提取时间特征,进而得到脑电信号的时-空特征。由于卷积操作的局部性约束,卷积无法获得全局性信息,进而双向长短时记忆网络模块根据时-空特征之间彼此的依赖性对时-空特征进行编码。最后,编码好的细粒度特征被输入至1个由3层全连接层组成的全连接模块。每经过一层全连接层之后,时空特征将逐渐被压缩,进而特征信息与类别信息之间的关系将更加明确。
4.正则化技术
4.1. 基于视觉注意力机制的标签平滑技术
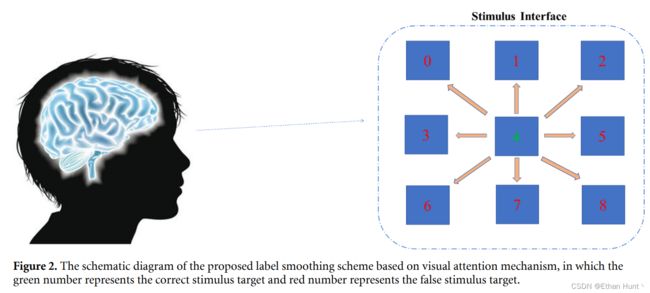
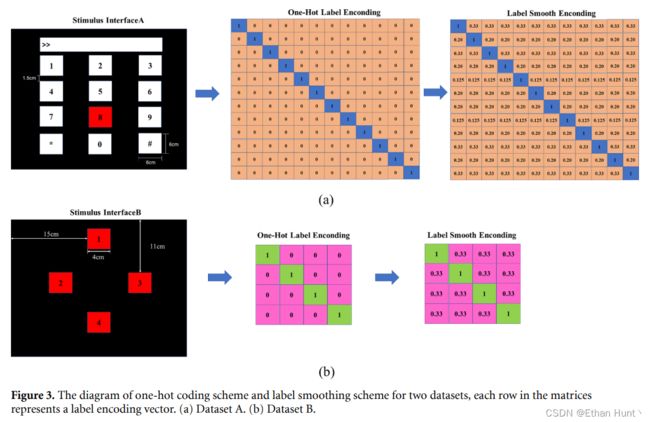
标签平滑是一种通过估计训练期间标签丢失的边缘化影响来规范分类层的技术。它常被用于缓解深度学习模型的过拟合问题,从而进一步地提升分类性能。然而,我们对标签平滑为什么起作用以及何时起作用知之甚少。在该项研究中,我们提出了基于视觉注意力机制的标签平滑技术。在SSVEP的数据采集过程中,被试通过线索被引导注视某个闪光刺激。然而,所有的刺激是同时闪烁的,从而非目标(non-target)闪光刺激不可避免地会干扰被试,进而诱发干扰频率识别过程的SSVEP成分。如上图2所示,刺激目标4是目标(target)闪光刺激,但被试可能会被周围的non-target闪光刺激0,1,2,3,5,6,7,8干扰。
为了缓解这个现象带来的不利影响,我们将原先的单标签(硬标签)拓展至多标签(软标签)。
更加具体地,假设 K K K个刺激呈现在刺激面板(interface)上,并构成了一个 n n n行 m m m列的刺激矩阵。之后,对于编号为 k k k的闪光刺激,它在刺激面板上的坐标 ( x , y ) (x,y) (x,y)为:
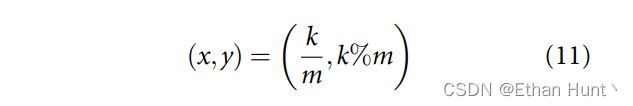
其中 x x x 代表行坐标 , y y y 代表列坐标。
假设受试者的视觉注意力被注视目标刺激的周围non-target刺激均匀分散。所有non-target刺激的注意力得分计算如下:
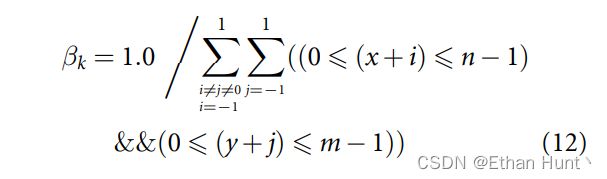
其中 β \beta β 为注意力分数, k ∈ [ 0 , K − 1 ] k\in[0,K-1] k∈[0,K−1]为刺激目标的编号, & & \&\& &&表示逻辑与操作。从而我们得到了基于注意力的多标签矩阵:

其中 A L S ALS ALS 代表基于注意力分数计算得到的软标签矩阵,而矩阵中的每一行代表的一个软标签的编码向量。为了避免软标签在实际的训练过程中带来过度的正则化效果,使得模型难以收敛,我们同时结合硬标签与软标签作为监督联合训练模型:
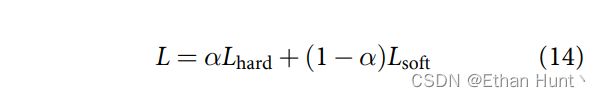
其中 L L L 代表总体的训练损失,而 L h a r d L_{hard} Lhard 与 L s o f t L_{soft} Lsoft 分别表示由独热(one-hot)编码的交叉熵损失与使用软标签所得的交叉熵损失。 α \alpha α 用于平衡 L h a r d L_{hard} Lhard 与 L s o f t L_{soft} Lsoft。我们仅想软标签作为一个辅助手段,从而在该项研究中 α \alpha α 设为了0.6。
下图3显示了在基于本研究中使用的两个数据集的刺激呈现面板所得的one-hot编码与 A L S ALS ALS编码示意图。
4.2.谱归一化技术
谱归一化(SN)在对抗生成网络中得到了广泛的应用,常用于鉴别器中,以防止梯度消失和梯度爆炸,从而抑制模式坍塌现象。
谱归一化的核心思想在于将神经网络中可更新的权重矩阵限制在Lipschitz条件下。直观理解来看,Lipschitz条件限制了函数梯度变化的剧烈程度。在1维空间中,函数 y = s i n ( x ) y=sin(x) y=sin(x) 满足1-Lipschitz,而它的最大斜率为1。为了让权重矩阵 W W W满足 K K K-Lipschitz连续, K K K的最小值为 σ ( W ) = λ 1 \sigma(W)=\sqrt{\lambda_1} σ(W)=λ1。其中 λ 1 \lambda_1 λ1为权重矩阵 W T W W^TW WTW的最大奇异值。因此,为了使得权重矩阵 W W W满足1-Lipschitz,从而使得模型训练的过程更加稳定,利于收敛,我们需要对 W W W中的所有元素作如下转换:
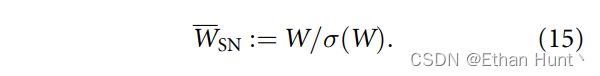
鉴于SN的功能特性,我们在提出的CNN-LSTM模型中的每一个全连接层与卷积层后都附上了一个谱归一化层。
CNN-LSTM模型结合ALS与SN正则化技术后,即得到了摘要所提的SSVEPNet。
5.实验结果
为了验证SSVEPNet的效果,本文采用了美国加州大学圣地亚哥的Masaki Nakanishi所提供的12分类公开数据集与美国里海大学Yu Zhang教授提供的4分类私人数据集。我们将这两个数据集分别命名为DatasetA与DatasetB。其中,DatasetA与DatasetB均包含10个被试,采样率分别为256Hz与250Hz,并选用了覆盖大脑枕叶区与额叶区常用的8个电极通道。DatasetA每个刺激包含15个试次(trial),而DatasetB每个刺激包含20个试次。两个数据集的每个试次的前0.5s与1s被用于实验评估。
5.1 被试内实验结果
在被试内实验中,两个传统算法ITCCA,TRCA与三个深度学习算法EEGNet,C-CNN,FBtCNN与SSVEPNet进行了对比。所有算法均在2个数据集(DatasetA与DatasetB),3种不同的训练集/测试集比例(8:2,5:5,2:8),2个不同的时窗大小(1s与0.5s上)进行了实验,得到的结果如下表3与表4所示。
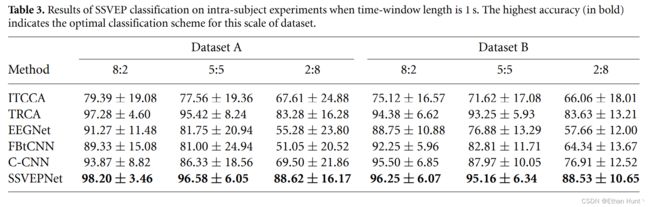
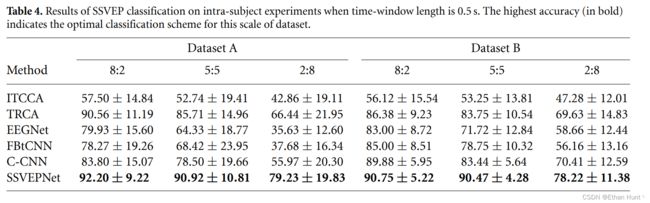
从表中可以看出,SSVEPNet在所有情况下均优于其他分类算法。而且当训练数据非常少时,SSVEPNet的优势十分明显,显著优于其它深度学习算法与传统方法。这说明SSVEPNet有望解决深度学习模型在被试内实验下因数据量不足而造成的性能较差现象。
5.2 跨被试实验结果
在跨被试实验中,由于采用LOSO范式,无法使用目标被试的数据,进而难以计算有效的模板信号,从而我们仅使用SSVEPNet与三个深度学习算法EEGNet,C-CNN,FBtCNN进行对比。实验过程中每个被试的分类结果与总体的平均分类结果均被记录,如下表5与表6所示。
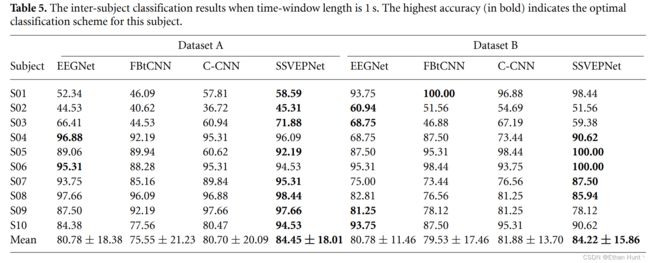
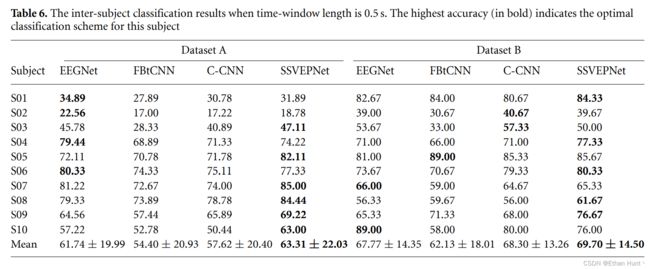
从表中的分类结果可以看出,SSVEPNet仍旧优于其他对比算法。但相较于被试内实验而言,优势相对较小。而且SSVEPNet在1s下的实验结果优势要比0.5s下的实验结果更好。这说明SSVEPNet在跨被试实验中的性能仍旧受到时窗大小的限制。
5.3 消融实验结果
深度学习模型在数据量小时极易产生过拟合现象,有3种抑制过拟合现象的正则化技术方式:
- 作用于网络参数的机制,如Dropout,Batch Normalization。
- 作用于模型输入的机制,如Data Augmentation或Data Corruption。
- 作用于模型输出的机制,如Label Smooth。
本文所提出的SSVEPNet使用的ALS与SN分别对应于作用于模型输出的机制与作用于网络参数的机制。为了验证这两个正则化技术的有效性,我们对这两个机制进行了消融实验,得到的结果如下图4所示。
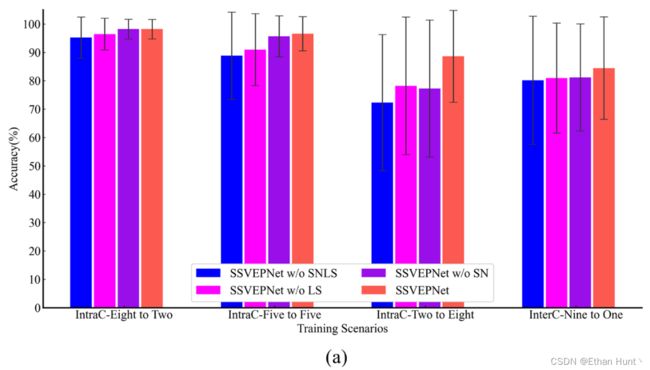

从图中可以看出,SSVEPNet在所有情况下均能通过ALS与SN技术进一步提升分类性能,且在被试内小规模训练数据量下效果十分明显。除此之外,当ALS与SN技术结合使用时,得到的结果显著优于其他模型。这说明在使用正则化技术时,我们可以结合使用正则化技术,进而取得更好的分类性能。
5.4 t-SNE可视化结果
为了探究SSVEPNet为什么能够在被试内小数据量规模下仍旧取得如此好的分类性能, 我们使用了Hinton等人在2007年提出的t-SNE降维技术可视化神经网络得到的分类特征。最优的深度学习模型SSVEPNet与次优的深度学习模型C-CNN在DatasetA中8号被试与DatasetB中5号被试的测试数据上提取的特征如下图5所示。
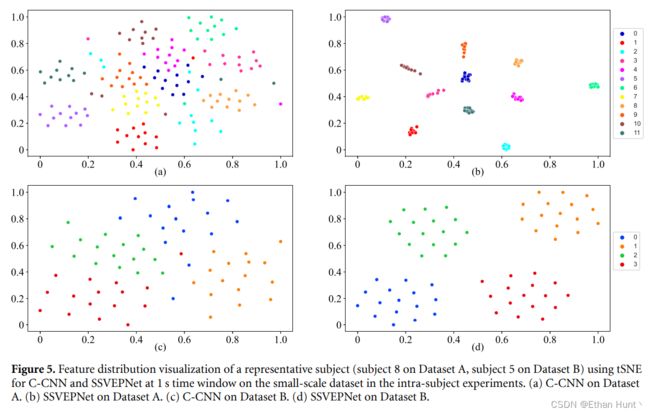
从图中可以看出,相较于C-CNN(图中左侧),SSVEPNet(图中右侧)在两个数据集上均能够提取更加具有代表性的特征,使得类内距离更小,类间距离更大,进而提升网络的分类性能,并减少对数据量的需求。
6.讨论与思考
6.1 网络参数量对深度学习模型性能的影响
深度学习模型的参数量对网络性能具有十分重要影响。理论上来说,网络参数量越大,模型能够学习更加复杂的映射函数,进而具有更强的学习能力与表征能力。然而,大模型通常需要大数据的帮助,否则极易因数据量不足而产生过拟合现象。但是采集数据是一个费时费力的过程,对于脑机接口领域亦是如此。为了保持大参数量模型强大的学习能力并同时抑制过拟合现象,有一些可行的方案,如模型压缩或设计更加轻便的网络。然而,压缩的模型通常依赖于人类的先验知识,而轻便的网络的表征能力通常受限,特别是对于非稳态且非线性的脑电数据。在本研究中,我们结合正则化技术构建了一个大参数量的神经网络模型SSVEPNet。如下表8所示,我们的模型在时窗为1s时具有高达约600W左右的网络参数,是EEGNet的140倍与FBtCNN的673倍。令人意外的是,如表3-6所示,我们的模型在具有更少数据与更短时窗的情况下均优于其他模型。这启示我们或许应该重新思考对于SSVEP信号或其他生物医学信号的深度模型设计方式,进而打破网络的性能瓶颈。

6.2 三层全连接层是否必要
经过详细的计算表明,SSVEPNet的网络参数量大多由3层全连接层所贡献。而在EEGNet,C-CNN,FBtCNN中,它们仅使用了一层全连接层。但我们相信,仅使用一层全连接层的设计思想对于我们的网络设计并不奏效,因为我们的网络在经过了在Bi-LSTM模块后得到的特征维度为7936(DatasetA的1s时窗数据下),模型难以使用如此高维的数据特征与低维的类别特征直接建立联系。为了探究3层全连接层是否必要,我们在DatasetA的被试内实验小规模数据集上对3层全连接层的输入特征进行了t-SNE可视化,如下图6所示。

从图中可以看出,随着全连接层的不断深入,数据特征的类内距离逐渐减小,类间距离逐渐增大,从而表明3层全连接层能够深入地挖掘Bi-LSTM编码的细粒度时-空特征并得到更加具有鉴别性的特征,进而有利于网络分类过程的进行。
6.3 缺陷与未来工作
本项研究的缺陷应被提及。我们仅在4分类与12分类数据集上对我们的模型进行了验证。在未来,我们需要将SSVEPNet用于实际的决策过程中,并在具有更多刺激目标的数据集上进行验证,如清华大学的Benchmark40分类数据集。在时窗大小为0.5s的跨被试实验下,我们的模型的结果优势相对薄弱,我们需要利用域适应(Domain Adaptation)或对抗生成网络(Generative Adversarial Network)技术进一步提高短时窗下的跨被试性能。此外,实验室环境与现实环境的差别十分显著,一个在1s下能取得高性能的方法将保证更加鲁棒的分类性能。例如,一个每秒都能够做出决定的系统对于重度残疾人士的沟通来说可能非常有用。此外,由于EEG数据的复杂性与非稳态性,BCI用户在不同时间段采集的数据也可能具有显著差异。当不同时期的数据输入BCI系统时,重新训练网络或许可以帮助取得更好的结果。域适应技术可以被用于摒弃旧数据并使用新数据进行代替,迁移学习(Transfer Learning)技术可被用于将旧数据的信息迁移至新数据上。除此之外,当BCI系统面临未出现在系统数据库的新被试时,增量学习(Incremental Learning)可被用于拓展先前获得的知识。
7.结论
当数据量不足且时窗长度较短时,设计一个高性能的频率识别方法是基于SSVEP的BCI系统的迫切需求。在本研究中,我们提出了一种高效的混合CNN-LSTM网络,该网络采用谱归一化和标签平滑技术,用于短时SSVEP分类。为了验证我们模型的有效性,我们在被试内和跨被试分类情况中两种不同的时间窗口长度(1s 和 0.5s)中,将所提出的模型与其他传统方法和深度学习方法进行了全面比较。结果表明,该模型优于其他方法,在被试内小规模数据量情况下尤为显著。进一步的消融实验检验了谱归一化和基于注意力的标签平滑在该模型中的作用。大量的实验结果表明,SSVEPNet是一个很有前途的SSVEP频率识别方法,而谱归一化和基于注意的标签平滑是具有潜力的优化策略。