Oracle 中 row_number()、rank()、dense_rank() 函数的用法
一、row_number() 函数
在前面使用 rownum 实现分页,虽然是可以实现的,但是看似是否有点别扭。因为当需要对分页排序时,rownum 总是先生成序列号再排序,其实这不时我们想要的。而 row_number() 函数则是先排序,再生成序列号。这也是 row_number 与 rownum 主要的区别。下面来看 row_number() 的使用:
语法:row_number() over([partition by col1] order by col2 [ASC | DESC] [,col3 [ASC | DESC]]...)
参数解释:
row_number() over(): 是固定写法,即不能单独使用 row_nubmer() 函数;
partition by: 可选的。用于指定分组(或分开依据)的列,类似 SELECT 中的 group by 子句;
order by: 用于指定排序的列,类似 SELECT 中的 order by 子句。
1. 基本用法
SELECT row_number() over(order by empno) AS rnum, t1.* FROM emp t1;

2. 使用 row_number() 分页
SELECT * FROM (
SELECT row_number() over(order by empno) AS rnum, t1.* FROM emp t1
) t WHERE t.rnum BETWEEN 4 AND 6;

3. 使用 partition by 参数分区生成序号
当使用 partition by 参数时,序号将可能不是唯一的,因为序号的生成只会在当前分区中唯一,下一个分区又将从1开始计算,例如:
SELECT row_number() over(partition by deptno order by empno) AS rnum, t1.* FROM emp t1;

二、 rank() 与 dense_rank() 函数
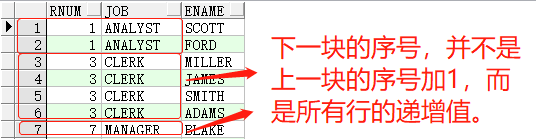
rank() 与 row_number() 的区别在于,rank() 会按照排序值相同的为一个序号(以下称为:块),第二个不同排序值将显示所有行的递增值,而不是当前序号加1。看示例:
SELECT rank() over(order by job) rnum, job, ename FROM emp t1;
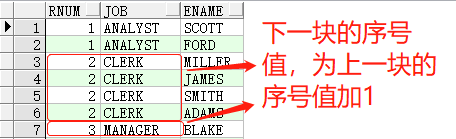
而 dense_rank() 函数,与 rank() 区别在于,第二个不同排序值,是对当前序号值加1,看示例:
SELECT dense_rank() over(order by job) rnum, job, ename FROM emp t1;
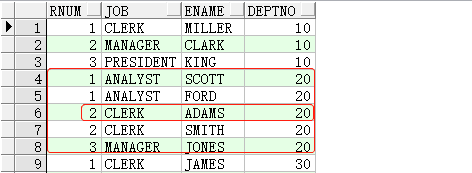
当指定 partition by 参数时,将根据指定的字段分组,进行分组计算序号值,序号值只在当前分组中有效,例如:
SELECT rank() over(partition by deptno order by job) rnum, job, ename, deptno FROM emp t1;

SELECT dense_rank() over(partition by deptno order by job) rnum, job, ename, deptno FROM emp t1;
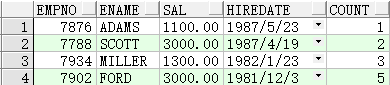
三、 over() 函数结合聚合函数的使用
SELECT empno, ename, sal, hiredate, COUNT(sal) OVER(ORDER BY hiredate DESC) count FROM emp;
SELECT empno, ename, sal, hiredate, MAX(sal) OVER(ORDER BY hiredate ASC) max FROM emp;
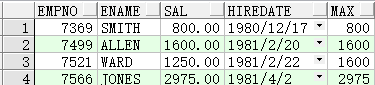
SELECT empno, ename, sal, hiredate, MIN(sal) OVER(ORDER BY hiredate DESC) min FROM emp;

SELECT empno, ename, sal, hiredate, AVG(sal) OVER(ORDER BY hiredate DESC) avg FROM emp;

SELECT empno, ename, sal, hiredate, SUM(sal) OVER(ORDER BY hiredate DESC) sum FROM emp;

四、 综合案例
1) 查询前 100 条记录
SELECT * FROM emp WHERE rownum <= 100;
注意:如果以上语句需要排序后再筛选,并不是能使用 rownum 实现,而需要使用 row_number() 函数。
2) 查出 4 ~ 6 条的记录,并按员工编号排序(分页运用)
SELECT * FROM (SELECT row_number() over(order by empno) rnum, t.* FROM emp t) t
WHERE t.rnum >= 4 AND t.rnum <= 6;

3) 查出每个部门工资最高的员工
SELECT * FROM (SELECT row_number() over(partition by deptno order by sal DESC) rnum, t.* FROM emp t) t WHERE t.rnum = 1;

4) 查出每个部门工资最高的所有员工(排名并列的)
SELECT * FROM (SELECT rank() over(partition by deptno order by sal DESC) rnum, t.* FROM emp t) t WHERE t.rnum = 1;

5) 查出每个部门工资排名第三的所有员工(排名并列的)
SELECT * FROM (SELECT dense_rank() over(partition by deptno order by sal ASC) rnum, t.* FROM emp t) t WHERE t.rnum = 3;

注意:如果使用 rank() 是不行的,因为20号部门并列第二的员工有2个,序号3就被跳掉了,直接跳到了序号4,使用以下语句可以查看到:
SELECT rank() over(partition by deptno order by sal ASC) rnum, t.* FROM emp t;

所以,使用 rank() 将会得到错误的结果:
SELECT * FROM (SELECT rank() over(partition by deptno order by sal ASC) rnum, t.* FROM emp t) t WHERE t.rnum = 3;

五、 总结
1. 如果需要取前多少条记录,就使用 rownum 伪列。rownum 就类似于 SQL Server TOP 子句的用法,但是 rownum 不能用于排序并过滤的场合
2. 如果取多少条到多少条的记录(分页),就是使用 row_number() 函数。
例如:查出 4 ~ 6 条的记录,并按员工编号排序
3. 如果取某个组别中最大值记录或最小值的记录,也可以使用 row_number() 函数,并结合 partition by 参数。
例如:查出每个部门工资最高的员工。
4. 如果取某个组别中并列最大值或最小值得记录,就使用 rank() 函数,并结合 partition by 参数。
例如:查出每个部门工资最高的所有员工。
5. 如果取某个组别中并列排名几记录,就使用 dense_rank() 函数,并结合 partition by 参数。
例如:查出每个部门工资排名第三的所有员工。