企业级IT应用运维监控:层次架构设计与实践指南
前言
企业基本都有自己的IT系统,而每个IT系统都有自己的监控系统。企业级的IT应用监控架构是一种综合性的解决方案,涉及到很多层级和相应的工具。随着企业IT系统的规模和复杂程度的不断增加,监控和管理系统也面临着越来越大的挑战。大家有时在建立监控时,不知道从何处入手;有时建立监控系统后,发现很多的盲点无法监控到。
监控是IT运维系统中至关重要的一环,所以针对以上问题,本文将分享IT应用运维监控的基本原理、通用监控体系和应用场景、监控平台设计、智能监控的实现方法等方面的内容,以期对企业 IT 系统的监控和管理提供一定的帮助。
1.监控原理
企业级 IT 应用运维监控架构的基本原理是通过收集、存储、分析和展示各种监控数据,对企业 IT 系统进行全面的监控和管理。其中,监控数据包括系统、网络、应用等各种指标数据、事件数据和日志数据等,可以通过各种数据采集器进行收集。
收集到的数据可以存储在分布式数据库、NoSQL 数据库或者数据仓库等存储系统中,并通过数据分析和处理,将其转化为可视化的监控指标,并通过仪表盘、图表、报表等形式进行展示。同时,还可以通过警报系统对监控数据进行实时监测和告警,以及通过自动化运维等手段对 IT 系统进行自动化管理和优化。
2.监控层次
一般来说,有IT系统的地方都必须有监控,不同企业IT系统分布不一样。有的企业有大量的边缘系统,比如:电脑,工控机等;有的企业有自己的IDC机房,而自己的IT系统建立在IDC机房内;有的企业把自己的IT系统建立在公有云上;又有的企业建立的混合云架构,IDC机房和公有云兼而有之。
IT监控系统是依附在之上的,对于边缘系统,有类似于IOT的物联网监控系统;IDC机房有网络设备的监控系统(这一般由网络供应商提供);公有云上的系统由云商提供完整的监控系统,比如:AWS上的cloudwatch;如果有混合云的架构,那就需要由监控系统建设团队把云上云下的监控系统做融合提供统一的监控。
以上的这些监控是从系统角度进行分类的,做的是系统监控,而本文讨论的是,如何从应用运维的角度来进行层次划分。
2.1 APIs监控
APIs(应用程序编程接口)监控,又称为前端监控,是指对APIs的使用情况、性能、安全性等进行实时监控和管理的过程。通常包括:
A. 使用情况监控:监控APIs的调用情况、使用频率、错误率等,以便了解APIs的使用情况和流量状况。
B. 性能监控:监控APIs的响应时间、延迟、吞吐量等性能指标,以便及时发现APIs的性能问题和瓶颈。
C. 安全监控:监控APIs的安全性,包括身份验证、授权、访问控制等,以保护APIs免受安全威胁。
D. 错误监控:监控APIs的错误情况,包括错误类型、错误代码、错误频率等,以便及时发现和解决APIs的错误问题。
为了实现APIs监控,通常需要使用一些专门的工具和平台:
A. APIs监控工具:如:Pingdom、Datadog,通过收集、分析和可视化APIs的使用情况、性能、安全性和错误情况,以帮助开发人员和运维人员监控和管理APIs。
B. APIs管理平台:如Tingyun、Instana、Runscope,通过管理APIs的生命周期、版本控制、文档生成等,以确保APIs的稳定性和可靠性。
C. 日志管理工具:如Splunk、ELK,通过收集、分析和可视化APIs的日志信息,以帮助用户快速发现和解决APIs的问题和错误。
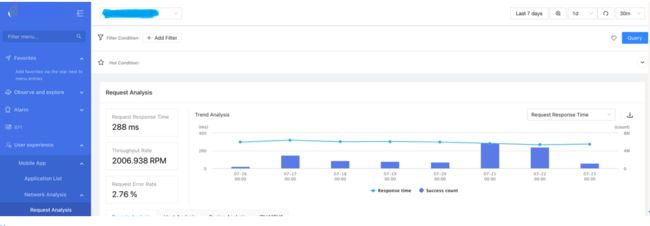
图一 Network Request监控

图二 Instana APIS监控
2.2 应用层监控
应用层监控是指对应用程序的性能、可用性、安全性等进行实时监控和管理的过程。通常包括:
A. 应用性能监控:监控应用程序的性能指标,包括请求响应时间、吞吐量、错误率饱和率等黄金四指标,以便及时发现应用程序的性能问题和瓶颈。
B. 可用性监控:监控应用程序的可用性,包括应用程序的运行状态、访问次数、错误率等,以保证应用程序的正常运行和可用性。
C. 安全监控:监控应用程序的安全性,包括应用程序的防火墙、入侵检测、安全事件等,以保护应用程序免受安全威胁,一般这是由安全团队负责,运维人员较少涉及。
D. 日志管理:收集、分析和可视化应用程序的日志信息,以帮助用户快速发现和解决应用程序问题和异常情况。
为了实现应用层监控,相对应的工具和平台:
A. 应用性能监控工具:通过监控应用程序的性能指标,以帮助用户快速发现应用程序的性能问题和瓶颈。
B. 可用性监控工具:通过监控应用程序的运行状态和访问次数,以保证应用程序的正常运行和可用性。
C. 安全监控工具:和APIs的监控类似,主要由漏洞扫描工具,入侵检测系统等工具构成,比如应用新上线的代码中使用了一个第三方的工具,此工具有后门漏洞,就会被监控到。
D. 日志管理工具:通过收集、分析和可视化应用程序的日志信息,以帮助用户快速发现和解决应用程序问题和异常情况。
应用性能监控工具和可用性监控工具,Zabbix在服务器时代是不二之选,但是随着kubernetes容器时代的到来,Zabbix渐渐淡出了,目前都以Exporter + Promethesu + Grafana,其中,Prometheus+Grafana就是为容器环境而生的。Exporter主要把关键的指标数据以抛出,然后有prometheus采集并加入时序数据库中,然后由Grafana展现。
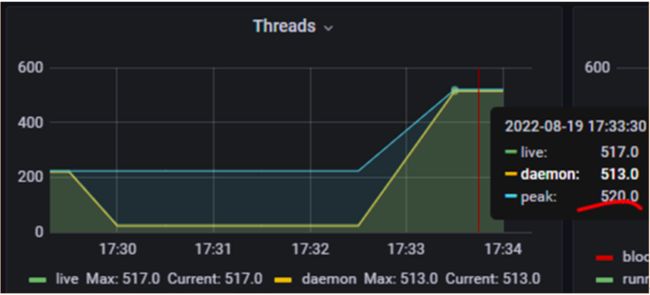
图三 Grafana JVM应用线程数监控
2.3 资源层监控
资源层监控是指对计算机系统的各种资源(如CPU、内存、磁盘、网络等)进行实时监控和管理的过程,这个不仅包括服务器,还包括容器,而对于容器集群,由于有了水平扩展的资源调度,所以还包括容器的数量及其状态的监控。
A. CPU监控:监控CPU的使用率、负载、温度等指标,以便及时发现CPU的问题和瓶颈。容器环境也就是容器的CPU reqirement和limit值。
B. 内存监控:监控内存的使用率、空闲率、交换空间等指标,以保证系统具有足够的内存资源。容器环境也就是内存的CPU reqirement和limit值。
C. 磁盘监控:监控磁盘的空间、I/O使用率、读写速度等指标,以保证系统磁盘的稳定性和可靠性。容器环境也就是持久化存储的空间监控。
D. 网络监控:监控网络的带宽、吞吐量、延迟等指标,以保证网络的性能和可靠性。容器环境也就是进出对应容器组的网络总流量。
为了实现资源层监控,通常需要使用一些工具和平台,过去也是Zabbix为主,现在容器环境的不二之选就是Prometheus+Grafana, 这是因为kubernetes内Cadvise会主动提供关于容器的性能和状态的指标。
对于服务器,我们可以利用Node Exporter+Prometheus+Grafana 在Grafana中展示,当然,也可以用Cloudwatch插件在Grafana中监控。
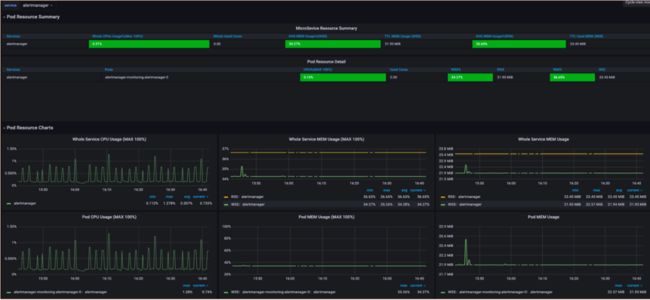
图四 Grafana Pod CPU和memory监控

图五 Grafana Pods number 监控
2.4 链路层监控
链路层监控是指对分布式系统中各个组件、模块之间的交互过程进行实时监控和管理的过程。链路层监控可以帮助用户快速发现和解决应用程序的问题和瓶颈,提高应用程序的可靠性和性能。
主要的开源工具就是skywalking,商业化工具有dynatrace和AppDynamics等,一般价格比较昂贵。这些工具一般有以下特点:
A. 链路追踪:这些工具可以对应用程序请求的链路进行追踪,并记录请求的每个环节,包括请求的来源、目的、处理过程等。
B. 性能监控:这些工具可以对请求的每个环节进行性能监控,包括请求响应时间、请求吞吐量、请求错误率等指标,以帮助用户快速发现和解决应用程序的性能问题和瓶颈。
C. 依赖分析:这些工具可以分析应用程序的依赖关系,包括服务之间的依赖、数据库之间的依赖等,并对依赖关系进行监控和分析。
D.飞行记录:这些工具可以将请求的链路信息进行记录和存储,以便后续的分析和查询,同时也支持对请求链路的回放和重放,以帮助用户深入分析和定位问题。
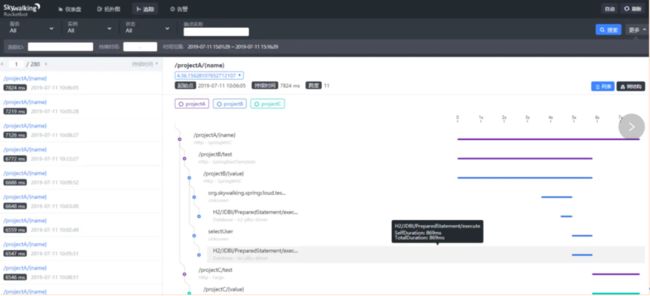
图六 Skywalking 链路追踪 监控
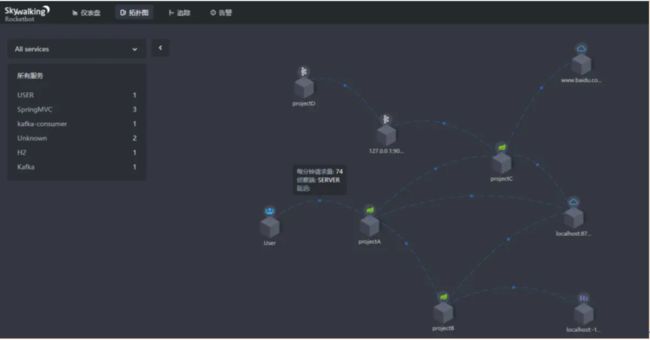
图七 Skywalking 应用依赖拓扑 展示
2.5 后端监控
后端监控是指对应用程序后端(如数据库、缓存、消息队列等)进行实时监控和管理的过程。数据库监控是后端监控中的一个重要部分,主要是对数据库的性能、可用性和安全性进行监控和管理,以保证应用程序的正常运行和稳定性。
后端监控的也包括,性能监控、可用性监控、安全监控、日志监控等同应用层监控类似的监控,除此之外,还包括特有的监控选项,如对于数据库而言,还包括:
A. 连接数
B. 操作数
C. 缓存命中率
D. 锁数
E. 复制集
F. 备份
在公有云大行其道的今天,越来越多的企业把后端(数据库,redis等)迁移到了公有云端,这些指标公有云都会提供,我们所要做的是把这些指标从公有云上引入到本地的Grafana上展示,比如:Grafana上有aws的cloudwatch插件,可以通过cloudwatch在本地grafana展示后端指标。

图八 Grafana MongoDB 重要指标 监控
2.6 业务监控
业务监控是指对应用程序的业务功能进行实时监控和管理的过程,主要关注应用程序的业务流程和业务指标,以保证应用程序的业务功能的正常运行和业务价值的实现。通常包括:
A. 业务流程监控:对应用程序的业务流程进行监控和管理,包括业务流程的状态、业务流程的耗时、业务流程的成功率等。通过业务流程监控,可以及时发现和解决业务流程的问题和瓶颈,提高业务流程的效率和可靠性。
B. 关键业务指标监控:对应用程序的关键业务指标进行监控和管理,包括业务量、转化率、用户满意度等。通过关键业务指标监控,可以及时发现和分析业务指标的异常情况,提高业务指标的稳定性和可靠性。
C. 用户行为监控:对应用程序用户的行为进行监控和管理,包括用户的访问量、访问路径、用户行为的转化率等。通过用户行为监控,可以及时了解用户的需求和行为模式,从而优化应用程序的用户体验和业务流程。
业务监控通常要和日志监控和后端监控结合,要从后者中取得业务相关的数据用于展示:

图九 Grafana 业务监控
2.7 运维能力的监控
SLA(Service Level Agreement)、SLO(Service Level Objective)和 SLI(Service Level Indicator)是衡量运维能力指标的重要指标。SLA 是一种衡量客户服务质量的协议,SLO 和SLO是一种衡量所运维的系统可靠性是否达标的指标。这方面的监控一般需要设立Error Budget,也就是在一定时间内(通常为2周)偏离目标的数值。一般包括:
A. 如果是乙方运维,和甲方在协议中约定了不同等级的故障响应时间的SLA,可以加入对SLA的Error budget监控。
B. 如果是甲方运维,对自身进行KPI考核的,可以加入对主要性能或可用性指标的Error budget监控。
这样做的目的,是控制好运维的节奏,如果Error Budget还很多,那么我们就可以对生产系统做比较激进的操作;反之,Error Budget偏少或在短期内已经消耗殆尽或已经超出了,那么就是减少运维操作,以较少发生更多故障的可能。
3.监控大盘与合成监控指标
如此之多的监控项一直被诟病,这看一遍都费力,怎么能做到实时监控呢?
这个问题的解决就要依赖监控大盘了,目前市场上没有统一的监控大盘的工具软件,毕竟每个公司的业务太不相同了,而且监控的投入也不一样,所以要生成监控大盘的软件过于复杂。目前基本上都是每家企业自行开发的。
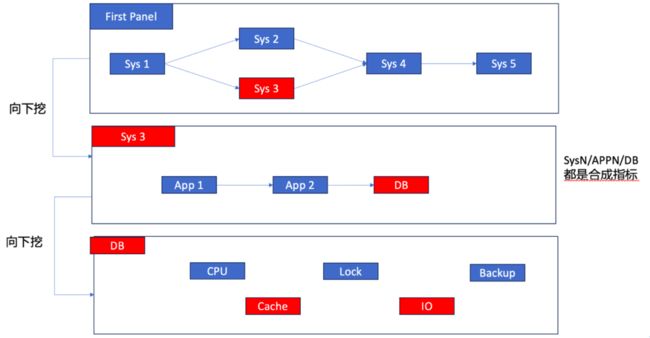
图十 监控大盘挖掘设计
既然,监控指标太多了,我们就要对其合成,于是合成监控指标就诞生了。
合成监控指标是指通过对多个监控指标进行组合和计算得到的综合性指标,用于判断应用程序的整体健康状况和性能状况。合成监控指标通常是由多个单独的指标组合而成,可以反映出应用程序的整体性能和健康状况。
合成监控指标的计算方式可以根据具体情况而定,常见的计算方式包括以下几种:
A. 平均值:对多个指标的平均值进行计算,如请求响应时间的平均值、服务器负载的平均值等。
B. 加权平均值:对多个指标的加权平均值进行计算,根据不同指标的重要性为其分配权重,如请求响应时间和服务器负载的加权平均值。
C. 百分位数:对多个指标的百分位数进行计算,反映出指标的分布情况和极端值情况,如请求响应时间的95th百分位数。
D. 综合指数:通过对多个指标进行加权和,生成一个综合指数,用于衡量应用程序的整体性能和健康状况,如应用程序健康得分、性能指数等。
合成监控指标可以帮助用户更全面地了解应用程序的性能和健康状况,更快速地发现和解决问题。
比如在Spring Boot中,提供了一个合成监控指 -- JVM的健康度;如果JVM单个指标不正常,但JVM仍然可用,健康度指标还是正常的,但如果JVM连接数据库出问题,健康度指标就直接报错。效仿这个指标,我们可以对企业内的其他应用创建出自己的健康度合成指标。
在Grafana中,我们可以利用功能插件大致设计出类似的监控大盘,并使用PQL语句编写合成监控指标。尽管没有自行开发的下钻功能,但也是可以在感知系统整体的基础上,避免过多的指标监控。
使用grafana的statusmap插件,可以把每个系统的合成监控指标集中显示。

图十一 Grafana 集中展示合成监控指标
4.智能监控告警
智能监控告警是指利用人工智能和机器学习技术对应用程序进行智能化监控和管理的过程。智能监控可以帮助用户更快速、更准确地发现和解决问题,提高应用程序的稳定性和可靠性。
A. 自动识别异常:不单独依赖于阈值进行告警,利用机器学习和统计分析等技术,对应用程序的监控指标进行分析和建模,自动识别异常情况并生成警报或自动触发预设的响应动作。
B. 自动调整配置:自动优化应用程序参数,利用机器学习和优化算法等技术,自动调整应用程序的配置参数,以优化应用程序的性能和稳定性。
C. 预测性分析:提前预测可能的故障风险,利用机器学习和时间序列分析等技术,对应用程序的历史数据进行分析和建模,预测未来的趋势和可能出现的问题,并提前采取措施防范和解决问题。
D. 减少重复告警:告警合并,利用机器学习对已经产生的告警进行判断,将不重要的告警级别降低或类似的告警合并,在告警中不触发或少触发。
E. 减少告警抖动:告警收敛,监控数据产生异常抖动时,监控系统到底要不要告警一直以来是个问题,利用机器学习多维度的监控数据、并用聚类算法进行分析,确定事件的关联性,以减少多告警或告错警的可能。
F. 告警场景生成:贴靠用户业务场景的告警,监控数据进行极值分析和降噪处理,将和用户业务相关的告警关联起来,和CI项关联,构成场景。
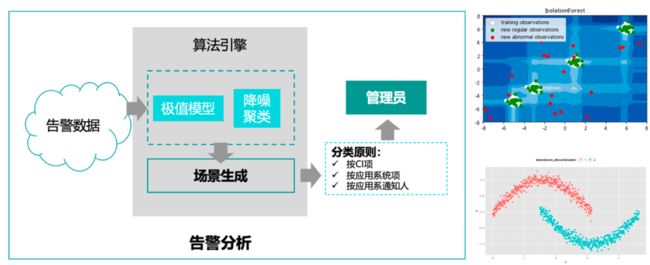
图十二 告警场景
智能监控告警并不是推翻原有的监控告警系统,它是原油监控告警的延伸,为企业提供更好的监控报警的体验。
5.总结
企业级IT监控是个很大的课题,其中应用运维的监控,是其中的一个重要组成部分。作为运维人员或SRE,能够时刻了解系统,并得到系统的林林总总的信息,是工作中至关重要的一环。希望本文能给大家打开一扇门,为指明方向起到起到作用。