渗透测试之信息收集下篇
华子目录
- 查找真实IP
-
- 多地ping确认是否使用CDN
- 查询历史DNS解析记录
-
- DNSDB
- 微步在线
- Ipip.net
- viewdns
- phpinfo
- 绕过CDN
- 旁站和C段
-
- 站长之家
- google hacking
-
- 网络空间搜索引擎
- 在线C段
- C段利用脚本
- Nmap,Msscan扫描等
- 常见端口表
- 网络空间搜索引擎
-
- FOFA的常用语法
- 扫描敏感目录/文件
-
- 御剑
- 7kbstorm
- bbscan
- dirmap
- dirsearch
- gobuster
- 网站文件
- 扫描网页备份
- 网站头信息收集
- 敏感文件搜索
-
- GitHub搜索
- Google-hacking
- wooyun漏洞库
- 网盘搜索
- 社工库
- 网站注册信息
- js敏感信息
-
- jsfinder
- Packer-Fuzzer
- SecretFinder
- cms识别
-
- 云悉
- 潮汐指纹
- cms指纹识别
- whatcms
- 御剑cms识别
- 非常规操作
- SSL/TLS证书查询
-
- SSL证书搜索引擎
- 查找厂商IP段
- 移动资产收集
-
- 微信小程序,支付宝小程序
- app软件搜索
- 社交信息搜索
- js敏感文件
- GitHub信息泄露监控
- 防护软件收集
- 社工相关
- 物理接触
- 社工库
- 资产收集神器
- 工具
查找真实IP
如果目标网站使用了CDN, 使用了CDN之后,网站的真实IP会被隐藏, 如果要查找真实的服务器就必须获取真实的IP, 根据这个IP继续查询旁站。
注:很多时候,真实网站虽然使用了CDN, 但子域名可能没有使用CDN,如果真实网站和子域名在一个IP段中, 那么找到子域名的真实IP也是一种途径。
多地ping确认是否使用CDN
http://ping.chinaz.com/

http://ping.aizhan.com/

查询历史DNS解析记录
在查询到的历史解析记录中,最早的历史解析IP很有可能记录的就是真实IP, 快速查找真实IP推荐此方法,但并不是所有网站都能查到。
DNSDB
微步在线
https://x.threatbook.cn/

Ipip.net
https://tools.ipip.net/cdn.php
viewdns
https://viewdns.info/

phpinfo
如果目标网站存在phpinfo泄露等, 可以在phpinfo中SERVER_ADDR或者_SERVER[“SERVER_ADDR”] 找到真实IP
绕过CDN
绕过CDN的多种方法具体可以参考https://www.cnblogs.com/qiudabai/p/9763739.html
旁站和C段
旁站往往存在业务功能站点,建议收集已有IP的旁站,再探测C段,确认C段目标后,再在C段的基础上再收集一次旁站。
旁站是和已知目标站点在同一服务器但不同端口的站点, 通过以下方法搜索到旁站后,先访问以下确定是不是自己需要的站点信息。
站长之家
http://stool.chinaz.com/same
https://chapangzhan.com/
google hacking
https://blog.csdn.net/qq_36119192/article/details/84029809
网络空间搜索引擎
如FOFA搜索旁站和C段
- 该方法效率较高,并能够直观地看到站点标题,但也有不常见端口未收录的情况,虽然这种情况很少,但之后补充资产的时候可以用下面的方法nmap扫描再收集一遍。
在线C段
https://c.webscan.cc/
C段利用脚本
pip install requests
#coding:utf-8
import requests
import json
def get_c(ip):
print("正在收集{}".format(ip))
url="http://api.webscan.cc/?action=query&ip={}".format(ip)
req=requests.get(url=url)
html=req.text
data=req.json()
if 'null' not in html:
with open("resulit.txt", 'a', encoding='utf-8') as f:
f.write(ip + '\n')
f.close()
for i in data:
with open("resulit.txt", 'a',encoding='utf-8') as f:
f.write("\t{} {}\n".format(i['domain'],i['title']))
print(" [+] {} {}[+]".format(i['domain'],i['title']))
f.close()
def get_ips(ip):
iplist=[]
ips_str = ip[:ip.rfind('.')]
for ips in range(1, 256):
ipadd=ips_str + '.' + str(ips)
iplist.append(ipadd)
return iplist
ip=input("请你输入要查询的ip:")
ips=get_ips(ip)
for p in ips:
get_c(p)
Nmap,Msscan扫描等
常见端口表
21,22,23,80-90,161,389,443,445,873,1099,1433,1521,1900,2082,2083,2222,2601,2604,3128,3306,3311,3312,3389,4440,4848,5432,5560,5900,5901,5902,6082,6379,7001-7010,7778,8080-8090,8649,8888,9000,9200,10000,11211,27017,28017,50000,50030,50060,135,139,445,53,88
注:探测C段时一定要确认IP是否归属于目标,因为一个C段中的所有IP不一定全部属于目标
网络空间搜索引擎
如果想要在短时间内快速收集资产, 那么利用网络空间搜索引擎是不错的选择。这样可以直观地看到旁站,端口,站点标题,IP等信息,点击列举出的站点可以直接访问, 以此来判断是否为自己需要的站点信息。
FOFA的常用语法
1、同IP旁站:ip="192.168.0.1"
2、C段:ip="192.168.0.0/24"
3、子域名:domain="baidu.com"
4、标题/关键字:title="百度"
5、如果需要将结果缩小到某个城市的范围,那么可以拼接语句 title="百度"&& region="Beijing"
6、特征:body="百度"或header="baidu"

扫描敏感目录/文件
扫描敏感目录需要强大的字典,需要平时积累,拥有强大的字典能够更高效地找出网站的管理后台,敏感文件常见的如.git文件泄露,.svn文件泄露,phpinfo泄露等,这一步一半交给各类扫描器就可以了, 将目标站点输入到域名中,选择对应字典类型,就可以开始扫描了,十分方便。
御剑
https://www.fujieace.com/hacker/tools/yujian.html
7kbstorm
https://github.com/7kbstorm/7kbscan-WebPathBrute
bbscan
https://github.com/lijiejie/BBScan
在pip已经安装的前提下,可以直接:
pip install -r requirements.txt
使用示例:
1. 扫描单个web服务 www.target.com
python BBScan.py --host www.target.com
2. 扫描www.target.com和www.target.com/28下的其他主机
python BBScan.py --host www.target.com --network 28
3. 扫描txt文件中的所有主机
python BBScan.py -f wandoujia.com.txt
4. 从文件夹中导入所有的主机并扫描
python BBScan.py -d targets/
–network 参数用于设置子网掩码,小公司设为28~30,中等规模公司设置26~28,大公司设为24~26
当然,尽量避免设为24,扫描过于耗时,除非是想在各SRC多刷几个漏洞。
该插件是从内部扫描器中抽离出来的,感谢 Jekkay Hu<34538980[at]qq.com>
如果你有非常有用的规则,请找几个网站验证测试后,再 pull request
脚本还会优化,接下来的事:
增加有用规则,将规则更好地分类,细化
后续可以直接从 rules\request 文件夹中导入HTTP_request
优化扫描逻辑
dirmap
pip install -r requirement.txt
https://github.com/H4ckForJob/dirmap
单个目标
python3 dirmap.py -i https://target.com -lcf
多个目标
python3 dirmap.py -iF urls.txt -lcf
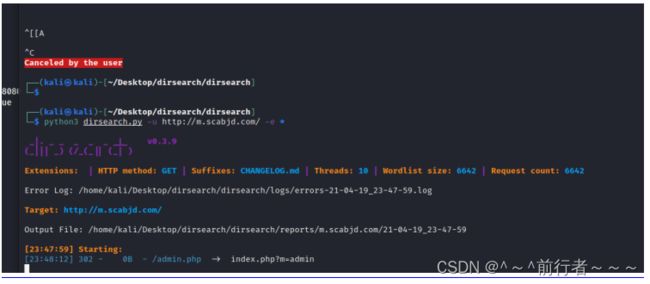
dirsearch
https://gitee.com/Abaomianguan/dirsearch.git
unzip dirsearch.zip
python3 dirsearch.py -u http://m.scabjd.com/ -e *
gobuster
sudo apt-get install gobuster
gobuster dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x php -t 50
dir -u 网址 w字典 -x 指定后缀 -t 线程数量
dir -u https://www.servyou.com.cn/ -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -x "php,html,rar,zip" -d --wildcard -o servyou.log | grep ^"3402"
网站文件
https://www.secpulse.com/archives/55286.html
1. robots.txt (存在不允许访问得目录)
2. crossdomin.xml
3. sitemap.xml
4. 后台目录
5. 网站安装包
6. 网站上传目录
7. mysql管理页面
8. phpinfo
9. 网站文本编辑器
10. 测试文件
11. 网站备份文件(.rar、zip、.7z、.tar.gz、.bak)
12. DS_Store 文件
13. vim编辑器备份文件(.swp)
14. WEB—INF/web.xml文件
15 .git
16 .svn
扫描网页备份
例如
config.php
config.php~
config.php.bak
config.php.swp
config.php.rar
conig.php.tar.gz
网站头信息收集
1、中间件 :web服务【Web Servers】 apache iis7 iis7.5 iis8 nginx WebLogic tomcat
2、网站组件: js组件jquery、vue 页面的布局bootstrap
通过浏览器获取,server
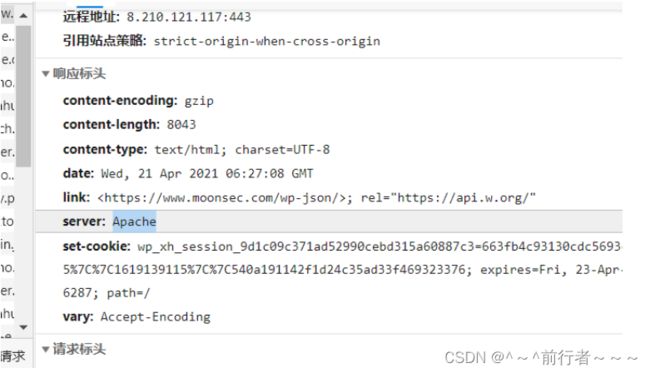
火狐的插件Wappalyzer

curl命令查询头信息
curl https://www.moonsec.com -i
敏感文件搜索
GitHub搜索
in:name test #仓库标题搜索含有关键字test
in:name huawei
in:descripton test #仓库描述搜索含有关键字
in:readme test #Readme文件搜素含有关键字
搜索某些系统的密码
https://github.com/search?q=smtp+58.com+password+3306&type=Code
github 关键词监控
https://www.codercto.com/a/46640.html
谷歌搜索
site:Github.com sa password
site:Github.com root password
site:Github.com User ID='sa';Password
site:Github.com inurl:sql
SVN 信息收集
site:Github.com svn
site:Github.com svn username
site:Github.com svn password
site:Github.com svn username password
综合信息收集
site:Github.com password
site:Github.com ftp ftppassword
site:Github.com 密码
site:Github.com 内部
https://blog.csdn.net/qq_36119192/article/details/99690742
http://www.361way.com/github-hack/6284.html
https://docs.github.com/cn/github/searching-for-information-on-github/searching-code
https://github.com/search?q=smtp+bilibili.com&type=code
Google-hacking
site:域名
inurl: url中存在的关键字网页
intext:网页正文中的关键词
filetype:指定文件类型
wooyun漏洞库
https://wooyun.website/
网盘搜索
凌云搜索 https://www.lingfengyun.com/
盘多多:http://www.panduoduo.net/
盘搜搜:http://www.pansoso.com/
盘搜:http://www.pansou.com/
社工库
名字/常用id/邮箱/密码/电话 登录 网盘 网站 邮箱 找敏感信息
tg机器人
网站注册信息
https://www.reg007.com
查询网站注册信息,查询曾经注册过得网站,要花钱,一般是配合社工库一起来使用。
js敏感信息
1.网站的url连接写到js里面
2.js的api接口 里面包含用户信息 比如 账号和密码
jsfinder
https://gitee.com/kn1fes/JSFinder
python3 JSFinder.py -u http://www.mi.com
python3 JSFinder.py -u http://www.mi.com -d
python3 JSFinder.py -u http://www.mi.com -d -ou mi_url.txt -os mi_subdomain.txt
当你想获取更多信息的时候,可以使用-d进行深度爬取来获得更多内容,并使用命令 -ou, -os来指定URL和子域名所保存的文件名
批量指定URL和JS链接来获取里面的URL。
指定URL:
python JSFinder.py -f text.txt
指定JS:
python JSFinder.py -f text.txt -j
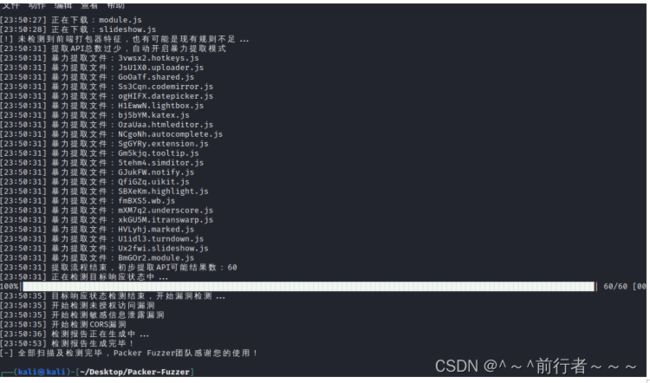
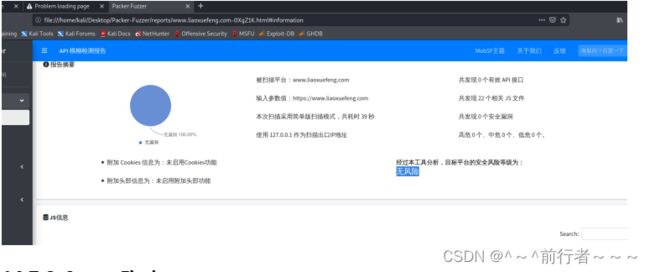
Packer-Fuzzer
- 寻找网站交互接口 授权key
随着WEB前端打包工具的流行,您在日常渗透测试、安全服务中是否遇到越来越多以Webpack打包器为代表的网站?这类打包器会将整站的API和API参数打包在一起供Web集中调用,这也便于我们快速发现网站的功能和API清单,但往往这些打包器所生成的JS文件数量异常之多并且总JS代码量异常庞大(多达上万行),这给我们的手工测试带来了极大的不便,Packer Fuzzer软件应运而生。 - 本工具支持自动模糊提取对应目标站点的API以及API对应的参数内容,并支持对:未授权访问、敏感信息泄露、CORS、SQL注入、水平越权、弱口令、任意文件上传七大漏洞进行模糊高效的快速检测。在扫描结束之后,本工具还支持自动生成扫描报告,您可以选择便于分析的HTML版本以及较为正规的doc、pdf、txt版本。
sudo apt-get install nodejs && sudo apt-get install npm
git clone https://gitee.com/keyboxdzd/Packer-Fuzzer.git
pip3 install -r requirements.txt
python3 PackerFuzzer.py -u https://www.liaoxuefeng.com
SecretFinder
一款基于Python脚本的JavaScript敏感信息搜索工具
https://gitee.com/mucn/SecretFinder
python3 SecretFinder.py -i https://www.moonsec.com/ -e
cms识别
收集好网站信息之后,应该对网站进行指纹识别,通过识别指纹, 确定目标的cms及版本,方便制定下一步的测试计划,可以用公开的poc或自己累积的对应手法等进行正式的渗透测试。
云悉
http://www.yunsee.cn/info.html
潮汐指纹
http://finger.tidesec.net/

cms指纹识别
whatcms

御剑cms识别
https://github.com/ldbfpiaoran/cmscan
https://github.com/theLSA/cmsIdentification/
非常规操作
1、如果找到了目标的一处资产,但是对目标其他资产的收集无处下手时,可以查看一下该站点的body里是否有目标的特征,然后利用网络空间搜索引擎(如fofa等)对该特征进行搜索,如:body=”XX公司”或body=”baidu”等。
该方式一般适用于特征明显,资产数量较多的目标,并且很多时候效果拔群。
2、当通过上述方式的找到test.com的特征后,再进行body的搜索,然后再搜索到test.com的时候,此时fofa上显示的ip大概率为test.com的真实IP。
3、如果需要对政府网站作为目标,那么在批量获取网站首页的时候,可以用上
http://114.55.181.28/databaseInfo/index
之后可以结合上一步的方法进行进一步的信息收集。
SSL/TLS证书查询
SSL/TLS证书通常包含域名,子域名和邮件地址等信息,结合证书中的信息,可以更快速的定位到目标资产,获取到更多目标资产的相关信息。
https://myssl.com/
https://crt.sh

https://censys.io
https://developers.facebook.com/tools/ct/

https://google.com/transparencyreport/https/ct/
SSL证书搜索引擎
https://crt.sh/?Identity=%.moonsec.com
https://censys.io/
查找厂商IP段
http://ipwhois.cnnic.net.cn/index.jsp

移动资产收集
微信小程序,支付宝小程序
现在很多企业都有小程序,可以关注企业的微信公众号或者支付宝小程序,或关注运营相关人员,查看朋友圈,获取小程序。
https://weixin.sogou.com/weixin?type=1&ie=utf8&query=拼多多
app软件搜索
https://www.qimai.cn/

社交信息搜索
QQ群 QQ手机号
微信群
领英
https://www.linkedin.com/
脉脉招聘
boss招聘
js敏感文件
https://github.com/m4ll0k/SecretFinder
https://github.com/Threezh1/JSFinder
https://github.com/rtcatc/Packer-Fuzzer
GitHub信息泄露监控
https://github.com/0xbug/Hawkeye
https://github.com/MiSecurity/x-patrol
https://github.com/VKSRC/Github-Monitor
防护软件收集
安全防护 云waf、硬件waf、主机防护软件、软waf
社工相关
微信或者QQ 混入内部群,蹲点观测。加客服小姐姐发一些连接。进一步获取敏感信息。测试产品,购买服务器,拿去测试账号和密码。
物理接触
企业办公层连接wifi,连同内网。丢一些带有后门的usb 开放免费的wifi截取账号和密码。
社工库
在tg找社工机器人 查找密码信息 或本地的社工库查找邮箱或者用户的密码或密文。组合密码在进行猜解登录。
资产收集神器
ARL(Asset Reconnaissance Lighthouse)资产侦察灯塔系统
https://github.com/TophantTechnology/ARL
AssetsHunter
https://github.com/rabbitmask/AssetsHunter
一款用于src资产信息收集的工具
https://github.com/sp4rkw/Reaper
domain_hunter_pro
https://github.com/bit4woo/domain_hunter_pro
LangSrcCurise
https://github.com/shellsec/LangSrcCurise
网段资产
https://github.com/colodoo/midscan
工具
Fuzz字典推荐:https://github.com/TheKingOfDuck/fuzzDicts
BurpCollector(BurpSuite参数收集插件):https://github.com/TEag1e/BurpCollector
Wfuzz:https://github.com/xmendez/wfuzz
LinkFinder:https://github.com/GerbenJavado/LinkFinder
PoCBox:https://github.com/Acmesec/PoCBox